SVD降维详解
1. SVD基本概念
**奇异值分解(Singular Value Decomposition, SVD)**是一种强大的矩阵分解技术,可以将任意矩阵分解为三个特殊矩阵的乘积。SVD在降维、数据压缩、推荐系统等领域有广泛应用。
核心公式
对于任意m×n矩阵A,其SVD分解为:
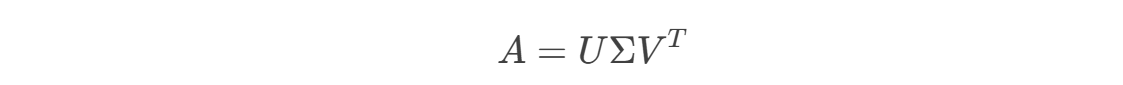
其中:
- U:m×m正交矩阵(左奇异向量)
- Σ:m×n对角矩阵(奇异值矩阵,按降序排列)
- V:n×n正交矩阵(右奇异向量)
2. SVD降维原理
SVD降维的核心思想是保留较大的奇异值,舍弃较小的奇异值,实现数据的低秩近似。
降维步骤
-
对原始数据矩阵A进行SVD分解
-
选择前k个最大的奇异值(及对应的奇异向量)
-
重构近似矩阵:
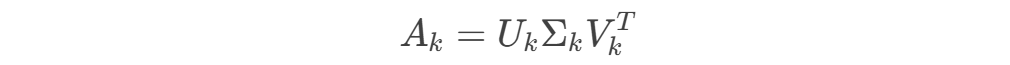
其中下标k表示只取前k列/行
3. SVD与PCA的关系
- PCA可以通过对协方差矩阵的特征值分解实现
- SVD可以直接对数据矩阵进行分解
- 当数据已经中心化时,PCA等价于对数据矩阵的SVD
4. Python实现SVD降维
4.1 使用NumPy实现
import numpy as np
from sklearn.preprocessing import StandardScaler
from sklearn.datasets import load_iris
import matplotlib.pyplot as plt# 加载并标准化数据
iris = load_iris()
X = iris.data
y = iris.targetscaler = StandardScaler()
X_std = scaler.fit_transform(X)# 进行SVD分解
U, s, Vt = np.linalg.svd(X_std)# 选择前2个主成分
k = 2
Sigma_k = np.diag(s[:k])
X_svd = U[:, :k] @ Sigma_k # 等价于 X_std @ Vt[:k].T# 可视化
plt.figure(figsize=(8, 6))
plt.scatter(X_svd[:, 0], X_svd[:, 1], c=y, cmap='viridis')
plt.xlabel('SVD Component 1')
plt.ylabel('SVD Component 2')
plt.title('SVD of IRIS Dataset')
plt.colorbar()
plt.show()
4.2 使用scikit-learn实现
from sklearn.decomposition import TruncatedSVDsvd = TruncatedSVD(n_components=2)
X_svd = svd.fit_transform(X_std)print("解释方差比例:", svd.explained_variance_ratio_)
print("累计解释方差:", svd.explained_variance_ratio_.sum())
5. SVD关键参数
n_components
- 要保留的奇异值/成分数量
algorithm
- 求解算法:‘arpack’或’randomized’
6. SVD应用场景
- 图像压缩:通过低秩近似减少存储空间
- 推荐系统:协同过滤(如Netflix推荐)
- 自然语言处理:潜在语义分析(LSA)
- 信号处理:噪声去除
7. SVD优缺点
优点
- 适用于任意矩阵(不要求方阵)
- 数值稳定性好
- 可以逐步增加成分数量
- 提供数据的最佳低秩近似(Eckart-Young定理)
缺点
- 计算复杂度较高(对大型矩阵)
- 需要中心化处理(类似PCA)
- 对缺失值敏感
8. 实战技巧
8.1 如何选择k值
# 绘制奇异值衰减曲线
plt.plot(s, 'r-', linewidth=2)
plt.xlabel('Components')
plt.ylabel('Singular Values')
plt.title('Singular Values Decay')
plt.show()
通常选择奇异值下降的"拐点"作为k值。
8.2 稀疏矩阵的SVD
对于大型稀疏矩阵,使用scipy.sparse.linalg.svds:
from scipy.sparse.linalg import svdsU, s, Vt = svds(X_sparse, k=2)
9. SVD与PCA比较
| 特性 | SVD | PCA |
|---|---|---|
| 输入矩阵 | 任意矩阵 | 协方差矩阵 |
| 计算方式 | 直接矩阵分解 | 特征值分解 |
| 中心化需求 | 需要 | 需要 |
| 实现复杂度 | 较高 | 较低 |
| 数值稳定性 | 更好 | 稍差 |
SVD是更通用的矩阵分解方法,而PCA可以视为SVD在特定情况下的应用。在实际应用中,两者常常可以互换使用,但SVD通常具有更好的数值稳定性。