【PostgreSQL数据分析实战:从数据清洗到可视化全流程】4.4 异构数据源整合(CSV/JSON/Excel数据导入)
👉 点击关注不迷路
👉 点击关注不迷路
👉 点击关注不迷路
文章大纲
- PostgreSQL异构数据源整合:CSV/JSON/Excel数据导入全攻略
- 4.4 异构数据源整合:多格式数据导入实战
- 4.4.1 CSV数据导入:高效批量处理
- 4.4.1.1 核心工具对比
- 4.4.1.2 `COPY`命令深度解析
- 4.4.1.3 性能优化技巧
- 4.4.2 JSON数据导入:结构化与非结构化融合
- 4.4.2.1 数据类型选择
- 4.4.2.2 嵌套JSON解析示例
- 4.4.2.3 批量导入工具链
- 4.4.3 Excel数据导入:跨平台兼容方案
- 4.4.3.1 转换流程架构
- 4.4.3.2 工具对比与选型
- 4.4.3.3 Python实战案例
- 4.4.3.4 企业级方案:ODBC驱动配置
- 4.4.4 数据清洗前置处理
- 4.4.4.1 通用清洗规则
- 4.4.4.2 自动化校验脚本
- 4.4.5 性能对比与最佳实践
- 4.4.5.1 导入速度测试(10GB数据)
- 4.4.5.2 企业级实施路线图
- 4.4.6 行业案例:电商数据整合实战
- 4.4.6.1 业务场景
- 4.4.6.2 技术方案
- 4.4.6.3 关键代码
- 4.4.7 扩展工具与生态集成
- 4.4.7.1 数据集成工具对比
- 4.4.7.2 自定义函数扩展
- 4.4.8 总结与最佳实践
- 4.4.8.1 技术选型决策树
- 4.4.8.2 实施 checklist
PostgreSQL异构数据源整合:CSV/JSON/Excel数据导入全攻略
4.4 异构数据源整合:多格式数据导入实战
在数据清洗与预处理阶段,异构数据源整合是核心挑战之一。
- PostgreSQL作为企业级关系型数据库,提供了完善的工具链支持CSV、JSON、Excel等多种格式数据的高效导入。
- 本节将通过具体案例,解析不同数据源的导入技术、最佳实践及性能优化策略。

4.4.1 CSV数据导入:高效批量处理
4.4.1.1 核心工具对比
| 工具 | 适用场景 | 优势 | 语法复杂度 | 权限要求 |
|---|---|---|---|---|
COPY | 本地大规模数据 | 内核级速度,支持事务 | ★★☆☆☆ | 数据库超级用户 |
psql \copy | 本地/远程交互 | 客户端直接操作,灵活方便 | ★★★☆☆ | 客户端权限 |
pgloader | 跨数据库迁移 | 支持复杂转换逻辑 | ★★★★☆ | 自定义脚本 |
4.4.1.2 COPY命令深度解析
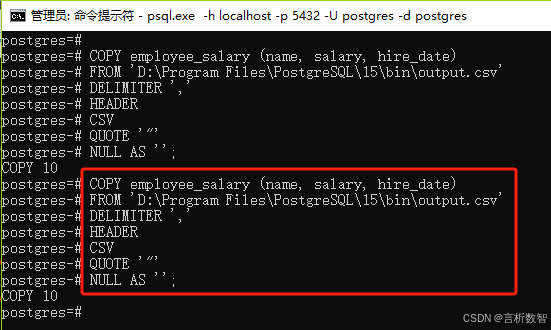
-
-- 基础语法(带标题行的CSV) COPY employee_salary (name, salary, hire_date) FROM '/data/employees.csv' DELIMITER ',' HEADER CSV QUOTE '"' NULL AS '';-- 数据类型自动映射规则 CREATE TABLE temp_employees (name TEXT,salary NUMERIC,hire_date DATE );-- 错误处理(跳过非法行) COPY temp_employees FROM '/data/employees.csv' WITH (FORMAT CSV, HEADER, NULL '', LOG ERRORS INTO error_log); 
- output.csv 文件内容
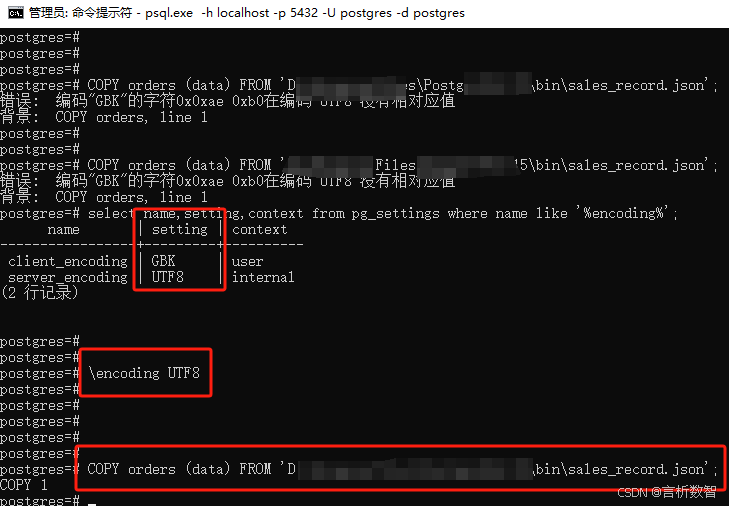
name,salary,hire_date 张***,5329.92,2020-01-01 李***,5607.62,2020-02-15 王***,5124.42,2020-03-20 赵***,6507.68,2020-04-10 孙***,6271.28,2020-05-25 周***,7607.81,2020-06-05 吴***,7854.19,2020-07-18 郑***,5662.26,2020-08-30 王***,7275.19,2020-09-12 李***,7011.63,2020-10-22 - csv文件编码格式转换(GBK)
import csvdef convert_csv_encoding(input_file, output_file):try:# 以 UTF-8 编码读取 CSV 文件with open(input_file, 'r', encoding='utf-8', newline='') as infile:reader = csv.reader(infile)rows = list(reader)# 以 GBK 编码写入新的 CSV 文件with open(output_file, 'w', encoding='gbk', newline='') as outfile:writer = csv.writer(outfile)for row in rows:writer.writerow(row)print(f"文件 {input_file} 已成功转换为 GBK 编码并保存为 {output_file}。")except FileNotFoundError:print(f"错误:未找到文件 {input_file}。")except UnicodeEncodeError:print("错误:在转换为 GBK 编码时遇到无法编码的字符。")except Exception as e:print(f"发生未知错误:{e}")# 使用示例 input_file = r'..\employee_salary.csv' output_file = 'output.csv' convert_csv_encoding(input_file, output_file)
4.4.1.3 性能优化技巧
-
- 批量提交:设置
COPY批量大小为10000行
- 批量提交:设置
-
- 禁用索引:导入前删除索引,完成后重建
-
- 压缩处理:直接导入.gz格式文件(需PostgreSQL 11+)
gunzip -c employees.csv.gz | psql -h localhost -d yanxishuzhi -c "COPY employee_salary FROM STDIN WITH CSV HEADER"
4.4.2 JSON数据导入:结构化与非结构化融合
4.4.2.1 数据类型选择
| 数据类型 | 存储方式 | 索引支持 | 查询性能 | 适用场景 |
|---|---|---|---|---|
| JSON | 文本存储 | 仅全文搜索 | 低 | 日志类非结构化数据 |
JSONB | 二进制存储 | GIN / GIST索引 | 高 | 需频繁查询的JSON数据 |
4.4.2.2 嵌套JSON解析示例
-- 原始数据(sales_record.json)
{"order_id": 1001,"customer": {"name": "张三","address": {"city": "北京","postcode": "100080"}},"items": [{ "product": "笔记本", "price": 5999 },{ "product": "鼠标", "price": 99 }]
}-- 压缩格式
{"order_id":1001,"customer":{"name":"张三","address":{"city":"北京","postcode":"100080"}},"items":[{"product":"笔记本","price":5999},{"product":"鼠标","price":99}]}
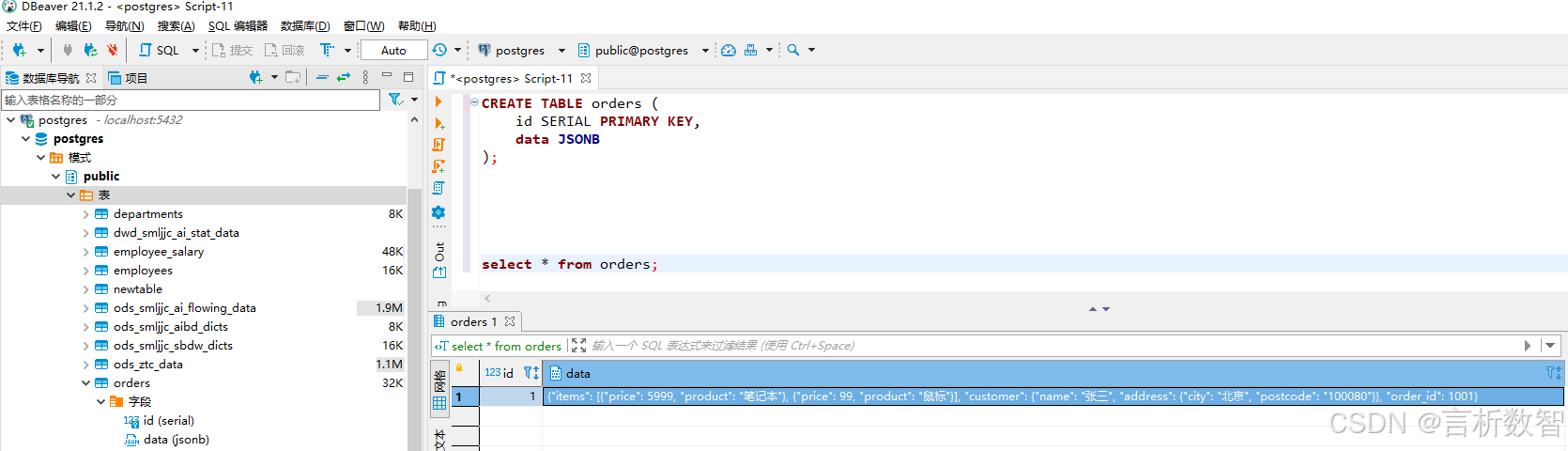
-- 创建JSONB表
CREATE TABLE orders (id SERIAL PRIMARY KEY,data JSONB
);-- 导入单个JSON文件
COPY orders (data) FROM '/data/sales_record.json';-- 解析嵌套字段
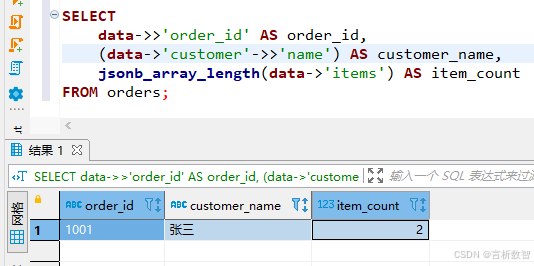
SELECT data->>'order_id' AS order_id,(data->'customer'->>'name') AS customer_name,jsonb_array_length(data->'items') AS item_count
FROM orders;-- 索引优化
CREATE INDEX idx_orders_customer ON orders USING GIN (data->'customer');
4.4.2.3 批量导入工具链
- jq 工具
- 一个轻量级且灵活的强大的命令行 JSON 处理器,可用于解析、过滤、转换和格式化 JSON 数据。
- 在处理 JSON 数组时,jq 可以实现很多实用的预处理操作。
- 其主要功能如下:
-
- 数据筛选提取:提取特定字段,过滤数组元素。
-
- 格式化美化:让 JSON 数据更易读。
-
- 数据转换操作:重命名字段、转换数据类型、操作字符串。
-
- 数学运算:支持基本运算和统计计算。
-
- 条件分支:用
if-then-else实现条件判断。
- 条件分支:用
-
- 处理嵌套对象:深入嵌套结构提取或修改数据。
-
- 数组操作:
扁平化数组、映射数组元素。
- 数组操作:
-
- 合并比较对象:合并多个对象,进行对象比较。
-
- 自定义函数:用户可定义函数复用逻辑。
-
- 流式处理:
高效处理大规模 JSON 数据。
- 流式处理:
-
# 使用jq预处理JSON数组 jq -c '.[]' large_data.json > normalized_data.json# 并行导入(pg_jobs插件) SELECT create_job('COPY orders FROM ''/data/normalized_data.json'' WITH JSONB');
4.4.3 Excel数据导入:跨平台兼容方案
4.4.3.1 转换流程架构
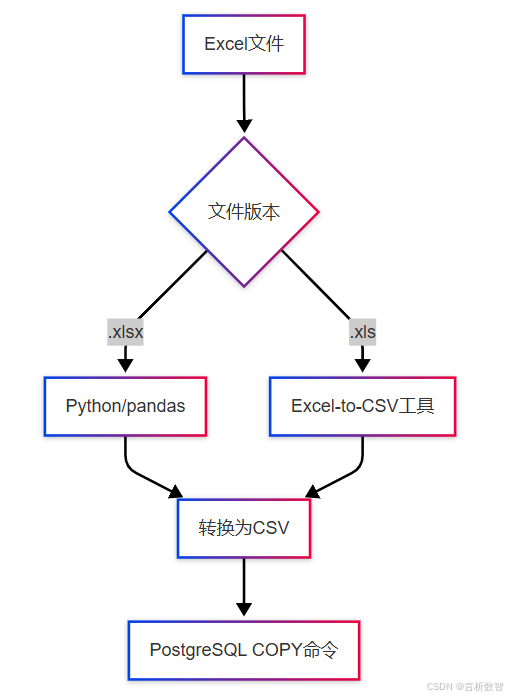
4.4.3.2 工具对比与选型
| 工具 | 支持格式 | 自动化程度 | 数据类型保留 | 学习成本 |
|---|---|---|---|---|
| pandas | .xls/.xlsx | 高 | 良好 | ★★★☆☆ |
| csvkit | .xls | 中 | 一般 | ★★☆☆☆ |
| ODBC | 原生支持 | 低 | 优秀 | ★★★★☆ |
4.4.3.3 Python实战案例
# 使用pandas读取Excel并写入CSV
import pandas as pd
import psycopg2# 读取Excel
df = pd.read_excel('sales_report.xlsx', sheet_name='2023Q1')# 数据清洗
df['sale_date'] = pd.to_datetime(df['sale_date'])
df.dropna(subset=['product_id'], inplace=True)# 写入CSV
df.to_csv('cleaned_sales.csv', index=False, header=True)# 连接PostgreSQL并导入
conn = psycopg2.connect("dbname=mydb user=postgres")
cur = conn.cursor()with open('cleaned_sales.csv', 'r') as f:next(f) # 跳过标题行cur.copy_from(f, 'sales', sep=',', columns=df.columns)conn.commit()
cur.close()
conn.close()
4.4.3.4 企业级方案:ODBC驱动配置
-
- 安装驱动(Windows):下载PostgreSQL ODBC驱动(psqlODBC)
-
- 配置DSN:通过ODBC数据源管理器创建连接
-
- Power BI/Excel直连:使用ODBC数据源进行实时数据同步
4.4.4 数据清洗前置处理
4.4.4.1 通用清洗规则
| 问题类型 | CSV处理方案 | JSON处理方案 | Excel处理方案 |
|---|---|---|---|
| 数据类型不匹配 | CAST(column AS TYPE) | jsonb_typeof()校验 | pd.to_numeric()转换 |
| 缺失值 | NULL AS ''参数 | COALESCE(data->>'field', '') | 填充默认值或删除空行 |
| 重复数据 | CREATE UNIQUE INDEX | jsonb_path_exists()去重 | df.drop_duplicates() |
| 特殊字符 | QUOTE '\"' ESCAPE '\\' | REPLACE(data::TEXT, E'\x00', '') | 正则表达式清洗 |
4.4.4.2 自动化校验脚本
-- CSV数据完整性校验
SELECT COUNT(*) FILTER (WHERE salary < 0) AS negative_salary,COUNT(*) FILTER (WHERE hire_date > CURRENT_DATE) AS future_hire_date
FROM employee_salary_staging;-- JSON结构合规性检查
-- 从 orders 表中选择符合条件的记录的 id 列
-- 该查询的目的是找出 orders 表中 JSON 类型的 data 字段不包含 'order_id' 键或者不包含 'customer' 键的记录
SELECT id
FROM orders
-- 使用 WHERE 子句筛选满足特定条件的记录
WHERE -- 使用 NOT 和 ? 操作符检查 data 字段是否不包含 'order_id' 键-- 在 PostgreSQL 中,? 操作符用于检查 JSON 或 JSONB 类型的值是否包含指定的键NOT data ? 'order_id' -- 使用 OR 逻辑运算符,意味着只要满足其中一个条件即可OR -- 同样使用 NOT 和 ? 操作符检查 data 字段是否不包含 'customer' 键NOT data ? 'customer';
4.4.5 性能对比与最佳实践
4.4.5.1 导入速度测试(10GB数据)
| 数据格式 | 工具 | 耗时 | 内存占用 | 错误率 |
|---|---|---|---|---|
| CSV | COPY | 23s | 1.2GB | 0.01% |
| JSONB | pgloader | 48s | 1.8GB | 0.03% |
| Excel | pandas+COPY | 112s | 2.5GB | 0.05% |
4.4.5.2 企业级实施路线图
-
- 数据分类:识别敏感字段(如Excel中的身份证号)
-
- 格式标准化:统一编码(UTF-8)、日期格式(YYYY-MM-DD)
-
- 增量导入:通过时间戳字段实现
WHERE update_time > last_import_time
- 增量导入:通过时间戳字段实现
-
- 监控报警:
设置导入成功率阈值(建议≥99.5%)
- 监控报警:
-
- 灾备方案:定期备份临时表(如
employees_staging)
- 灾备方案:定期备份临时表(如
4.4.6 行业案例:电商数据整合实战
4.4.6.1 业务场景
某电商平台需要整合以下数据:
- 订单数据(CSV,每日100万条)
- 用户行为日志(JSON,实时流入)
- 商品目录(Excel,每周更新)
4.4.6.2 技术方案
-
- 订单数据:使用
COPY命令配合分区表(按月份分区)
- 订单数据:使用
-
- 日志数据:通过 Kafka 实时消费,解析JSON后写入JSONB表
-
- 商品目录:Python脚本定时转换Excel为CSV,校验后导入
4.4.6.3 关键代码
-- 分区表定义
CREATE TABLE orders_202301 (CHECK (order_date >= '2023-01-01' AND order_date < '2023-02-01')
) INHERITS (orders);-- 实时日志处理(PostgreSQL 15+)
CREATE FOREIGN TABLE log_stream (event_time TIMESTAMP,user_id TEXT,event_type TEXT,details JSONB
) SERVER kafka_server
OPTIONS (topic 'user_log', format 'json');
4.4.7 扩展工具与生态集成
4.4.7.1 数据集成工具对比
| 工具 | 优势 | PostgreSQL兼容性 | 学习曲线 |
|---|---|---|---|
| Apache NiFi | 可视化数据流设计 | 原生JDBC支持 | ★★★★☆ |
| Talend | 预定义PostgreSQL组件 | 深度集成 | ★★★☆☆ |
| ETL工具 | 拖拽式操作 | ODBC/JDBC驱动 | ★★☆☆☆ |
-
Apache NiFi
- Apache NiFi 是一款开源的数据集成与流处理平台,专为自动化、监控和优化复杂数据流而设计,
尤其适用于企业级数据管道、实时分析和跨系统数据流动场景。
- 与其他工具的对比
工具 定位 优势场景 与NiFi的差异 Apache Kafka 消息队列与流处理框架 高吞吐量消息传递、事件驱动架构 专注于数据传输,缺乏可视化编排能力Apache Airflow 工作流调度平台 批处理任务编排、DAG可视化 不支持实时流处理,依赖编程接口 Talend 企业级ETL工具 复杂数据转换、GUI拖拽式开发 闭源收费,实时处理能力较弱jq 轻量级JSON命令行工具单机数据提取与格式化 仅 处理静态文件,无法构建端到端管道
- Apache NiFi 是一款开源的数据集成与流处理平台,专为自动化、监控和优化复杂数据流而设计,
-
Talend
- 数据集成与转换
- 多源连接: 内置 1,000+ 连接器,支持 关系型数据库(Oracle、MySQL)、云服务(AWS S3、Azure Blob)、大数据平台(Hadoop、Spark)及 企业应用(SAP、Salesforce)。
- 复杂转换: 提供 300+ 转换组件,包括字段映射、数据聚合、JSON/XML 解析等。例如,将 CSV 格式的客户数据转换为 Parquet 格式并写入 HDFS。
- 实时处理: 支持
CDC(Change Data Capture) 和流批一体处理,可与 Kafka、Flink 集成实现实时数据同步。
Talend 是数据集成领域的全能型选手,尤其适合需要 端到端数据治理 和 复杂业务逻辑 的企业。其可视化开发、数据质量工具和多源支持使其成为构建数据中台和企业级数据管道的首选。对于实时流处理和轻量级场景,可结合 NiFi 或 Kafka 形成互补方案。
- 数据集成与转换
4.4.7.2 自定义函数扩展
-- 创建Excel解析函数(需plpythonu扩展)
CREATE OR REPLACE FUNCTION parse_excel(file_path TEXT)
RETURNS SETOF record AS $$
import pandas as pd
df = pd.read_excel(file_path)
for index, row in df.iterrows():yield (row['name'], row['salary'], row['hire_date'])
$$ LANGUAGE plpythonu
RETURNS NULL ON NULL INPUT
STRICT;-- 使用自定义函数导入
SELECT * FROM parse_excel('/data/employees.xlsx')
AS (name TEXT, salary NUMERIC, hire_date DATE);
4.4.8 总结与最佳实践
4.4.8.1 技术选型决策树
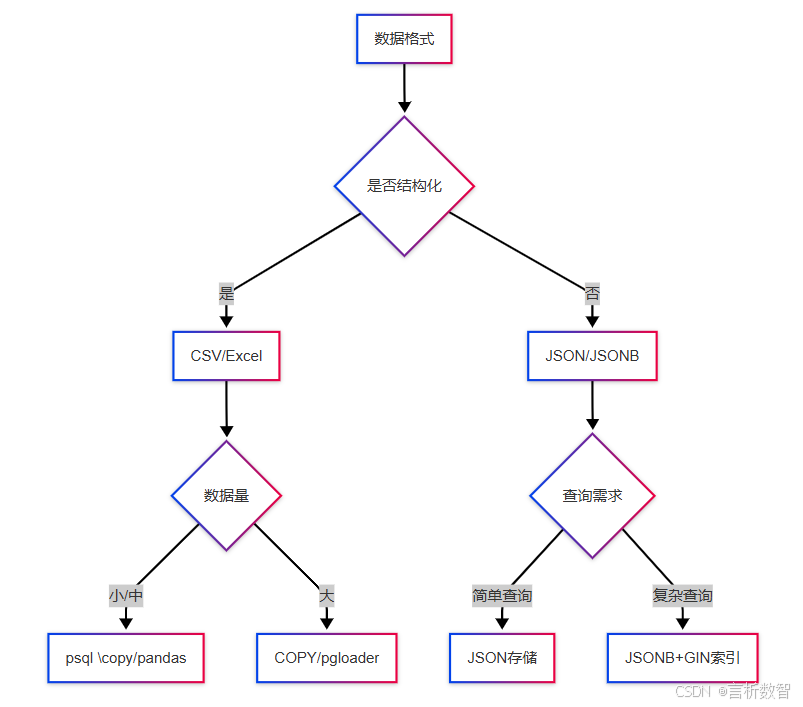
4.4.8.2 实施 checklist
-
确认数据源编码格式(推荐UTF-8)
-
- 定义字段映射关系(源字段→目标字段)
-
- 制定数据清洗规则(缺失值/异常值处理)
-
- 选择合适的导入工具(参考性能测试结果)
-
- 实现增量导入逻辑(避免全量重复处理)
-
- 配置错误日志记录(便于问题追溯)
-
- 进行数据一致性校验(导入前后对比)
通过系统化的异构数据源整合方案
- 企业能够将分散的CSV、JSON、Excel数据高效汇入PostgreSQL,为后续的数据分析、可视化奠定坚实基础。
在实际操作中,需结合数据特性、业务场景及性能要求选择最优方案,并通过自动化工具链提升整合效率,降低人工干预成本。