详解如何压测RocketMQ

目录
1.如何设计压测
2.压测工具
3.硬件配置
4.写代码压测
5.自带压测脚本
1.如何设计压测
-
二八定律法则:按业务峰值的 120% 设计压测目标(若线上峰值1000TPS,压测目标至少1200TPS)
-
关注三个指标
-
吞吐量(TPS)
-
延迟:所有业务线可接受的最低阈值(如整个系统中订单系统要求最高,要求<200ms。必须按它来)
-
错误率:至少<0.1%
-
2.压测工具
两种:
-
RocketMQ自带的压测脚本
-
写代码通过线程并发的方式来压测
3.硬件配置
查看cpu相关信息:
lscpu
查看核心数:
lscpu | grep -E '^(CPU(s)|Core|Socket)'
结果示例
CPU(s): 16 # 逻辑CPU总数(总线程数) Socket(s): 2 # 物理CPU个数 Core(s) per socket: 8 # 每个物理CPU的核心数 Thread(s) per core: 1 # 每个核心的线程数(1=未超线程)
计算核心数:
物理核心总数 = Socket(s) × Core(s) per socket (示例中物理核心总数 = 2 × 8 = 16核)
4.写代码压测
一分钟100并发:
@org.junit.jupiter.api.Testpublic void test3() throws Exception {String namesrv = "192.168.31.10:9876";String topic = "stress_topic";int CONCURRENCY = 100; // 并发数int DURATION_SECONDS = 60; // 压测时长(秒)
DefaultMQProducer producer = new DefaultMQProducer("stress_pool_producer_group");producer.setNamesrvAddr(namesrv);producer.start();
// 线程池配置(核心=最大=10,队列无限)ExecutorService executor = new ThreadPoolExecutor(CONCURRENCY,CONCURRENCY,0L, TimeUnit.MILLISECONDS,new LinkedBlockingQueue<>());
AtomicLong successCount = new AtomicLong(0);AtomicLong failureCount = new AtomicLong(0);long startTime = System.currentTimeMillis();long endTime = startTime + DURATION_SECONDS * 1000;
// 持续提交任务(直到达到压测时长)while (System.currentTimeMillis() < endTime) {executor.submit(() -> {try {Message msg = new Message(topic,message.getBytes());SendResult result = producer.send(msg);if (result.getSendStatus() == SendStatus.SEND_OK) {successCount.incrementAndGet();}} catch (Exception e) {failureCount.incrementAndGet();}});}
// 关闭线程池(停止接收新任务)executor.shutdown();// 等待剩余任务完成(最多等30秒)executor.awaitTermination(30, TimeUnit.SECONDS);producer.shutdown();
// 打印结果printStats(startTime, System.currentTimeMillis(),successCount.get(), failureCount.get());
}
private static void printStats(long start, long end, long success, long fail) {System.out.println("\n======= 压测结果 =======");System.out.println("总消息数: " + (success + fail));System.out.println("成功: " + success);System.out.println("失败: " + fail);System.out.printf("耗时: %d ms\n", (end - start));System.out.printf("TPS: %.2f\n", (success * 1000.0 / (end - start)));}5.自带压测脚本
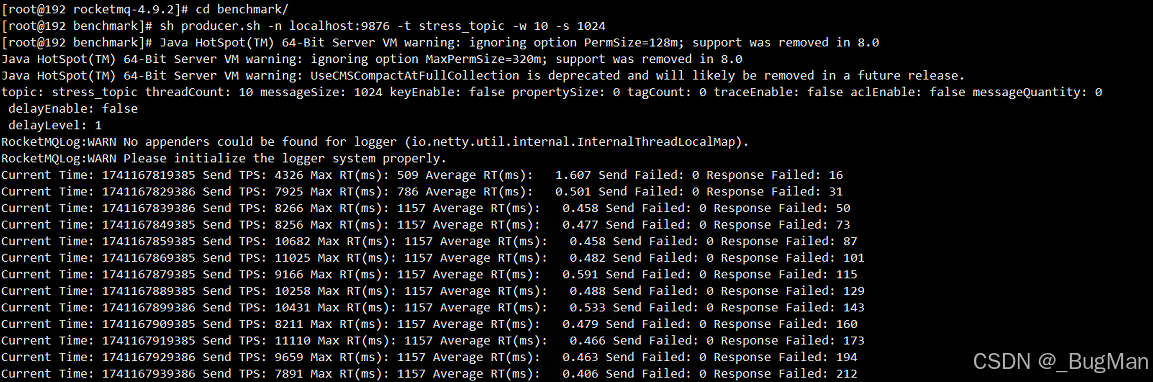
输出解读:
Current Time: 1741168049385 Send TPS: 6093 Max RT(ms): 2445 Average RT(ms): 0.562 Send Failed: 0 Response Failed: 399
-
Current Time:这是时间戳,表示测试的当前时间。不过用户可能更关心的是各个性能指标,时间戳可能只是记录测试的时间点,暂时不用深入分析。
-
Send TPS:每秒发送的事务数,即生产者每秒能成功发送多少条消息。这里显示6093,说明当前的生产者每秒发送约6093条消息。这个数值越高越好,但需要结合其他指标来看是否合理。
-
Max RT(ms):最大响应时间,即所有发送请求中最长的耗时,这里是2445毫秒。这意味着某一条消息从发送到收到响应用了2.4秒,这个值偏高,可能需要关注是否有某些消息处理异常或系统瞬时负载过高。
-
Average RT(ms):平均响应时间,这里是0.562毫秒,看起来非常低。平均响应时间低通常是一个好现象,说明大多数请求处理很快,但要注意与最大响应时间的差异,可能存在某些异常情况导致个别请求耗时剧增。
-
Send Failed:发送失败的消息数,这里是0,说明所有消息都成功发送出去了,没有因网络或客户端问题导致的失败。
-
Response Failed:响应失败的数量,这里显示399。这个指标可能需要进一步理解。响应失败通常指消息被发送到Broker,但Broker处理失败,比如存储失败、Topic不存在、权限问题等。需要检查Broker的日志,看看具体是什么原因导致这些失败。