【PostgreSQL数据分析实战:从数据清洗到可视化全流程】3.4 数据重复与去重(IDENTITY COLUMN/UNIQUE约束)
👉 点击关注不迷路
👉 点击关注不迷路
👉 点击关注不迷路
文章大纲
- PostgreSQL数据分析实战:数据质量分析之数据重复与去重(IDENTITY COLUMN/UNIQUE约束)
- 3.4 数据重复与去重
- 3.4.1 数据重复的影响与识别
- 3.4.2 IDENTITY COLUMN
- 3.4.3 UNIQUE约束
- 3.4.4 数据去重操作
- 总结
- 数据重复会影响分析结果的准确性和效率,PostgreSQL 提供了多种处理数据重复的方法。
- 接下来我将围绕
IDENTITY COLUMN 和 UNIQUE 约束,结合实际数据案例,详细讲解数据重复识别与去重的操作。
PostgreSQL数据分析实战:数据质量分析之数据重复与去重(IDENTITY COLUMN/UNIQUE约束)
在数据分析的流程中,数据质量直接关系到分析结果的可靠性和有效性。
- 而数据重复是影响数据质量的常见问题之一,不仅会占用额外的存储空间,还可能导致统计结果偏差、模型训练异常等问题。
- 在PostgreSQL中,我们可以借助
IDENTITY COLUMN和UNIQUE约束等功能,高效地处理数据重复问题。 - 本文将深入探讨这两种方式,结合具体数据和表格进行详细讲解。
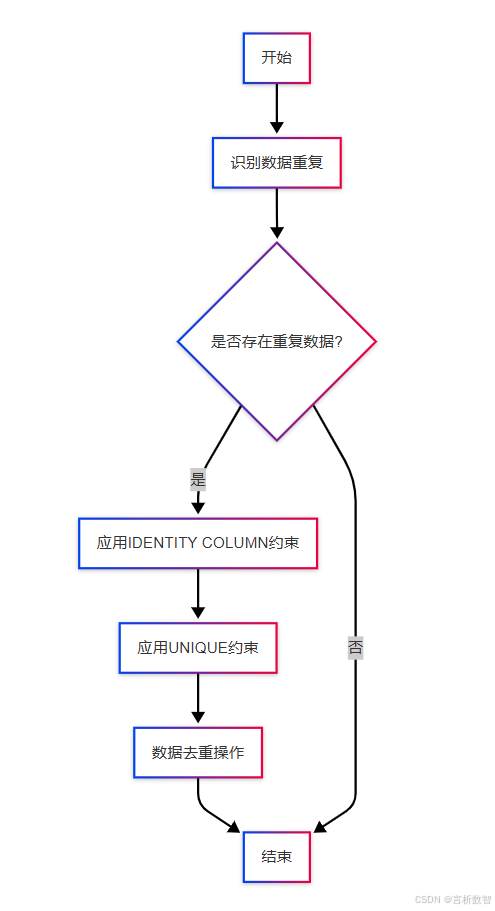
3.4 数据重复与去重

3.4.1 数据重复的影响与识别
数据重复是指数据集中存在多条内容完全相同或部分字段内容重复的记录。
- 例如,在一个存储用户订单信息的表
orders中,可能由于数据录入错误、系统故障等原因,出现重复的订单记录。 - 这些重复数据会干扰数据分析的准确性,如在统计订单数量、计算销售额时,重复数据会使结果虚高。
识别数据重复的方法较为简单,以orders表为例,表中包含order_id(订单ID)、user_id(用户ID)、product_name(产品名称)、order_amount(订单金额)、order_date(订单日期)等字段。我们可以通过以下SQL语句找出完全重复的记录:
SELECT order_id,user_id,product_name,order_amount,order_date
FROM orders
GROUP BY order_id,user_id,product_name,order_amount,order_date
HAVING COUNT(*) > 1;
假设执行上述查询后,得到如下结果:
| order_id | user_id | product_name | order_amount | order_date |
|---|---|---|---|---|
| 1001 | 501 | 笔记本电脑 | 5000 | 2024-01-01 |
| 1002 | 502 | 手机 | 3000 | 2024-01-02 |
从结果可以看出,存在重复的订单记录(有结果输出),需要进行去重处理。
3.4.2 IDENTITY COLUMN
IDENTITY COLUMN是PostgreSQL中用于生成唯一标识符的一种列类型,它能有效避免数据插入时产生重复的主键值。
在创建表时,可以通过IDENTITY关键字定义IDENTITY COLUMN。
例如,创建一个新的用户表users,其中user_id字段使用IDENTITY COLUMN:
CREATE TABLE users (user_id SERIAL PRIMARY KEY,username VARCHAR(50),email VARCHAR(100)
);
在上述代码中,SERIAL是INT类型加上IDENTITY属性的简写形式,它会自动为每一条新插入的记录生成一个唯一的user_id值。
当尝试插入两条user_id相同的记录时,PostgreSQL会抛出主键冲突的错误,从而保证数据的唯一性。
INSERT INTO users (username, email) VALUES ('user1', 'user1@example.com');INSERT INTO users (username, email) VALUES ('user2', 'user2@example.com');-- 尝试插入重复user_id的记录,会报错
INSERT INTO users (user_id, username, email) VALUES (1, 'user3', 'user3@example.com');
使用IDENTITY COLUMN不仅可以在数据插入阶段防止重复主键的产生,还能为后续的数据管理和分析提供唯一的标识,方便数据的关联和查询。
但它主要针对的是主键列的唯一性保障,对于其他字段的重复数据,还需要结合其他方法处理。
3.4.3 UNIQUE约束
UNIQUE约束用于确保表中某一列或多列组合的值具有唯一性,与PRIMARY KEY约束不同的是,UNIQUE约束允许列中出现NULL值,且一个表中可以有多个UNIQUE约束,而只能有一个PRIMARY KEY约束。
例如,在users表中,为了保证email字段的唯一性,可以添加UNIQUE约束:
ALTER TABLE users ADD CONSTRAINT unique_email UNIQUE (email);添加约束后,如果尝试插入email相同的记录,PostgreSQL会阻止插入操作,并抛出错误。
INSERT INTO users (username, email) VALUES ('user4', 'user4@example.com');-- 尝试插入email重复的记录,会报错
INSERT INTO users (username, email) VALUES ('user5', 'user4@example.com');
当需要对多列组合进行唯一性约束时,也可以使用UNIQUE约束。
比如,在orders表中,为了保证每个用户在同一日期下的订单唯一,可以对user_id和order_date列组合添加UNIQUE约束:
ALTER TABLE orders ADD CONSTRAINT unique_user_date_order
UNIQUE (user_id, order_date);
添加约束后,若插入user_id和order_date都相同的记录,将无法成功插入。
通过UNIQUE约束,我们可以有效地控制数据的重复性,确保关键数据的唯一性,提升数据质量。
3.4.4 数据去重操作
在识别出数据重复后,我们需要进行去重操作。
除了通过上述约束在数据插入阶段防止重复外,对于已经存在的重复数据,可以使用多种方式进行清理。
- 一种常见的方法是使用
DISTINCT关键字。例如,从orders表中查询不重复的记录:
SELECT DISTINCTuser_id,product_name,order_amount,order_date
FROM orders;
DISTINCT会对指定的列进行去重,返回唯一的记录组合。
- 另一种方法是使用窗口函数结合
ROW_NUMBER()来给重复记录编号,然后删除编号大于1的记录。以orders表为例:
WITH RankedOrders AS (SELECT *,ROW_NUMBER() OVER (PARTITION BY user_id, product_name, order_amount, order_date ORDER BY order_id) AS row_numFROM orders
)
DELETE FROM orders
WHERE order_id IN (SELECT order_id FROM RankedOrders WHERE row_num > 1);
上述代码首先使用窗口函数ROW_NUMBER()对重复记录进行编号,然后删除编号大于1的重复记录,从而实现数据去重。
总结
在PostgreSQL数据分析中,IDENTITY COLUMN和UNIQUE约束是处理数据重复问题的重要工具。
IDENTITY COLUMN能保障主键的唯一性,UNIQUE约束则可针对单列或多列组合确保数据的唯一性。- 结合
DISTINCT关键字、窗口函数等操作,我们能够有效地识别和去除重复数据,提升数据质量,为后续的数据分析和可视化工作奠定坚实基础。- 在实际应用中,应根据数据特点和业务需求,合理选择和运用这些方法,以达到最佳的数据处理效果。
- 以上系统介绍了PostgreSQL中数据重复与去重的相关知识。若你在实际操作中遇到问题,或想了解更多数据清洗技巧,欢迎随时交流。
- 希望这些内容能帮助你掌握数据重复与去重的方法。如果在实践中有任何疑问,或者想了解其他数据清洗技巧,随时和我沟通。