ICCV2023 | 视觉Transformer的Token-标签对齐
Token-Label Alignment for Vision Transformers
- 摘要-Abstract
- 引言-Introduction
- 相关工作-Related Work
- 提出的方法-Proposed Method
- 预备知识-Preliminaries
- Token波动现象-The Token Fluctuation Phenomenon
- Token-标签对齐-Token-Label Alignment
- 实验-Experiments
- 结论-Conclusion

论文链接
GitHub链接
本文 “Token-Label Alignment for Vision Transformers” 提出了用于视觉 Transformer(ViTs)训练的Token-Label Alignment(TL-Align)方法,旨在解决数据混合策略应用于 ViTs 时出现的token波动现象。通过追踪输入和转换后token的对应关系,为每个输出token获取对齐的标签,以提供更准确的训练信号。实验表明,TL-Align 在多种 ViT 架构上均提升了性能,在图像分类、语义分割、目标检测和迁移学习任务中效果显著,且具有良好的鲁棒性和泛化能力。
摘要-Abstract
Data mixing strategies (e.g., CutMix) have shown the ability to greatly improve the performance of convolutional neural networks (CNNs). They mix two images as inputs for training and assign them with a mixed label with the same ratio. While they are shown effective for vision transformers (ViTs), we identify a token fluctuation phenomenon that has suppressed the potential of data mixing strategies. We empirically observe that the contributions of input tokens fluctuate as forward propagating, which might induce a different mixing ratio in the output tokens. The training target computed by the original data mixing strategy can thus be inaccurate, resulting in less effective training. To address this, we propose a token-label alignment (TL-Align) method to trace the correspondence between transformed tokens and the original tokens to maintain a label for each token. We reuse the computed attention at each layer for efficient token-label alignment, introducing only negligible additional training costs. Extensive experiments demonstrate that our method improves the performance of ViTs on image classification, semantic segmentation, objective detection, and transfer learning tasks.
数据混合策略(例如CutMix)已被证明能够显著提升卷积神经网络(CNNs)的性能。它们将两张图像混合作为训练输入,并为其分配具有相同比例的混合标签。尽管这些策略在视觉Transformer(ViTs)中也显示出了一定效果,但我们发现了一种token波动现象,这种现象抑制了数据混合策略的潜力。通过实证观察,我们发现输入token在前向传播过程中的贡献会发生波动,这可能会导致输出token的混合比例有所不同。因此,原始数据混合策略计算出的训练目标可能不准确,从而导致训练效果不佳。
为了解决这个问题,我们提出了一种Token-标签对齐(TL-Align)方法,用于追踪变换后的token与原始token之间的对应关系,以便为每个token保留一个标签。我们在每一层重用计算得到的注意力,以高效地实现token-标签对齐,仅引入了可忽略不计的额外训练成本。大量实验表明,我们的方法在图像分类、语义分割、目标检测和迁移学习任务中均提升了视觉Transformer的性能。
引言-Introduction
这部分内容主要介绍了视觉Transformer(ViTs)的发展、数据混合策略的应用,指出ViTs中存在的token波动现象影响数据混合策略效果,并提出了token-标签对齐(TL-Align)方法,具体内容如下:
- ViTs的发展与数据混合策略的应用:ViTs在计算机视觉领域取得显著进展,革新了多个任务的技术水平,其成功的结构也推动了其他架构的发展。同时,数据混合策略作为一种数据增强方式,被广泛应用于现代深度架构的训练中,能有效提升模型的泛化性能,如CutMix通过空间域的复制粘贴操作生成混合图像。
- ViTs中token波动现象及影响:虽然数据混合策略在CNNs中研究广泛,但在ViTs中的兼容性研究较少。研究发现,ViTs中的自注意力机制会破坏输入的空间结构,导致token与标签错位,引发token波动现象。这使得输出token的混合比例与预期不同,进而导致原始数据混合策略计算的训练目标不准确,影响训练效果。
- 提出TL-Align方法:为解决上述问题,提出了TL-Align方法。该方法通过追踪变换后token与原始token的对应关系,为每个token分配标签。具体操作是根据token来源为混合图像的输入token分配标签,再利用计算的注意力线性混合输入token的标签,迭代进行token-标签对齐,从而获得更准确的训练目标。此方法仅用于训练阶段,不增加推理时的额外工作量。实验显示,TL-Align能提升多种ViT模型的性能,在多个任务中验证了其鲁棒性和泛化能力 。
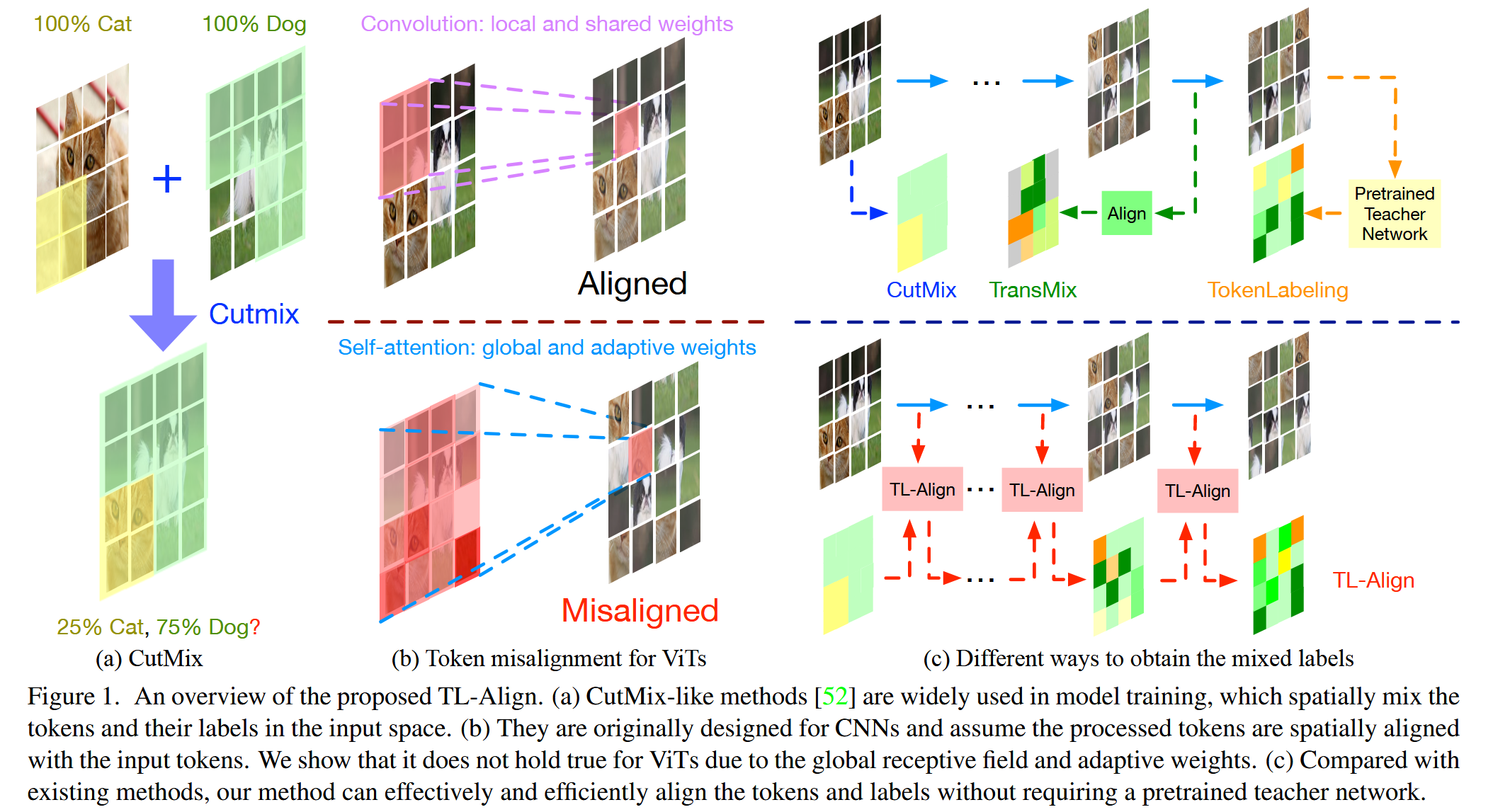
图1. 所提出的TL-Align方法概述。(a) 类似CutMix的方法在模型训练中被广泛使用,这些方法在输入空间中对token及其标签进行空间混合。(b) 它们最初是为卷积神经网络(CNNs)设计的,并且假设处理后的token在空间上与输入token对齐。我们发现,由于视觉Transformer(ViTs)具有全局感受野和自适应权重,这一假设并不适用于ViTs。© 与现有方法相比,我们的方法无需预训练的教师网络,就能有效且高效地对齐token和标签。
相关工作-Related Work
这部分主要介绍了视觉Transformer和数据混合策略的相关研究,突出本文方法与已有研究的差异和创新点,具体如下:
- 视觉Transformer:在自然语言处理成功后被引入计算机视觉领域,在图像分类、目标检测、语义分割等任务表现出色。如Dosovitskiy将其用于图像分类,Liu提出层次化特征图适用于密集预测任务。近期有研究致力于优化训练目标提升其性能,如DeiT引入知识蒸馏降低训练成本,TokenLabeling利用预训练教师网络标注token标签。与这些方法不同,本文的TL-Align方法无需预训练网络,能逐层对齐标签,实现端到端训练。
- 数据混合策略:作为数据增强的重要方式,能提升CNNs泛化性能。从最初的线性插值(MixUp),到采用区域复制粘贴的CutMix,再到利用显著区域的Puzzle Mix、SaliencyMix和Attentive CutMix,以及在特征空间对齐图像的AlignMixUp和基于历史信息的RecursiveMix等。然而,多数方法专为CNNs设计,在ViTs上的有效性未充分探索。TransMix虽针对ViTs调整混合目标,但未考虑token波动导致的标签分配不准确问题。本文提出的TL-Align方法通过逐层追踪token与标签对应关系来对齐两者,弥补了现有方法的不足。
提出的方法-Proposed Method
预备知识-Preliminaries
这部分内容主要介绍了卷积神经网络(CNN)、视觉Transformer(ViT)的基本架构,以及数据混合策略中的CutMix方法,为后续阐述研究问题和提出解决方法做铺垫,具体如下:
- CNN与ViT架构:在深度学习时代,CNN是计算机视觉领域的主流架构,对众多任务性能提升显著。但近年来,ViT的出现对其主导地位构成挑战。ViT将图像“分块”成token,通过交替的自注意力(SA)和多层感知器(MLP)进行处理。
- 数据混合策略之CutMix:训练策略对模型性能影响重大,数据混合是CNNs和ViTs训练中重要的数据增强手段,可提升模型泛化能力。CutMix是常用的数据混合策略,旨在从给定训练样本 ( X , y ) (X, y) (X,y) 创建虚拟训练样本。它从一个输入图像 X 1 X_{1} X1 中随机选择局部区域,替换另一个输入图像 x 2 x_{2} x2 相同区域的像素,生成新样本 x ~ \tilde{x} x~。新样本标签 y ˉ \bar{y} yˉ 是原始标签 y 1 y_{1} y1 和 y 2 y_{2} y2 的组合,计算公式为 { X ~ = M ⊙ X 1 + ( 1 − M ) ⊙ X 2 y ~ = λ y 1 + ( 1 − λ ) y 2 \begin{cases}\tilde{X} =M \odot X_{1}+(1 - M) \odot X_{2}\\\tilde{y} =\lambda y_{1}+(1-\lambda) y_{2}\end{cases} {X~=M⊙X1+(1−M)⊙X2y~=λy1+(1−λ)y2。其中, M M M 是表示像素所属图像的二进制掩码, λ \lambda λ 反映两个标签的混合比例,由从 x 1 x_{1} x1 裁剪区域的像素占比确定。
Token波动现象-The Token Fluctuation Phenomenon
该部分内容主要阐述了在视觉Transformer(ViT)中发现的token波动现象,分析了其产生的原因及对训练造成的影响,具体如下:
- 现象发现:CutMix原本为CNNs设计,其假设特征提取过程不会改变混合比例。但研究发现,ViT中的自注意力机制与CNNs不同,会导致部分token出现波动。
- 理论分析
- 用 z i z_{i} zi 表示图像 Z Z Z 的一个token,经过空间操作后的第 i i i 个变换token z ^ i \hat{z}_{i} z^i 可表示为 z ^ i = ∑ j = 1 N w i , j s z j \hat{z}_{i}=\sum_{j = 1}^{N}w_{i, j}^{s}z_{j} z^i=∑j=1Nwi,jszj,其中 w i , j s w_{i, j}^{s} wi,js 是空间混合矩阵 w s ( z ) w^{s}(z) ws(z) 的元素。在此基础上,定义原始token z i z_{i} zi 对混合token z ^ j \hat{z}_{j} z^j 的贡献 c ( z i , z ^ j ) = ∣ w i , j s ∣ ∑ k = 1 N ∣ w k , j s ∣ c(z_{i}, \hat{z}_{j})=\frac{|w_{i, j}^{s}|}{\sum_{k = 1}^{N}|w_{k, j}^{s}|} c(zi,z^j)=∑k=1N∣wk,js∣∣wi,js∣,token z i z_{i} zi 在所有混合图像token中的存在性 p ( z i ) = ∑ j = 1 N c ( z i , z ^ j ) p(z_{i})=\sum_{j = 1}^{N}c(z_{i}, \hat{z}_{j}) p(zi)=∑j=1Nc(zi,z^j)。
- 对于非步长深度卷积,由于平移不变性, ∑ l = 1 N ∣ w i , l s ∣ = ∑ j = 1 N ∣ w k , j s ∣ = ∑ k = 1 , l = 1 M ∣ K k , l ∣ \sum_{l = 1}^{N}|w_{i, l}^{s}|=\sum_{j = 1}^{N}|w_{k, j}^{s}|=\sum_{k = 1, l = 1}^{M}|K_{k, l}| ∑l=1N∣wi,ls∣=∑j=1N∣wk,js∣=∑k=1,l=1M∣Kk,l∣,可推出内部token的 p ( z i ) = 1 p(z_{i}) = 1 p(zi)=1 ,即卷积过程中内部token的效果不变。然而,ViT中的自注意力机制不存在平移不变性,上述等式不成立,且自注意力引起的空间混合矩阵 w s ( z ) w^{s}(z) ws(z) 的输入依赖性会进一步放大 p ( z ) p(z) p(z) 的波动,极端情况下某些token的 p ( z ) p(z) p(z) 可能接近0或1。
- 影响阐述:token的波动会改变混合比例(即 λ \lambda λ),使网络可能完全忽略其中一个混合图像,导致处理后token的实际标签偏离按原公式计算的混合标签,进而降低训练效果。
Token-标签对齐-Token-Label Alignment
这部分主要介绍了Token-标签对齐(TL-Align)方法,通过一系列具体操作,解决了视觉Transformer(ViT)中token与标签不匹配的问题,为模型训练提供更准确的标签,具体内容如下:
- 方法提出背景:ViT中自注意力机制使处理后的token与初始token不匹配,为解决该问题,提出TL-Align方法,通过追踪输入和转换后token的对应关系,获取对齐的标签。
- 具体操作流程
- 初始token及标签处理:将CutMix后的混合输入 x ~ \tilde{x} x~ 分割并展平为原始图像token { x ~ 1 , x ~ 2 , ⋯ , x ~ N } \{\tilde{x}_{1}, \tilde{x}_{2}, \cdots, \tilde{x}_{N}\} {x~1,x~2,⋯,x~N},投影并添加位置嵌入得到 Z 0 Z^{0} Z0。同时,为每个token z i z_{i} zi 分配标签嵌入 y i y_{i} yi,形成初始标签嵌入 Y 0 Y^{0} Y0,初始化方式依据不同数据混合范式而定。
- 基于注意力的标签更新:ViT通常采用多头自注意力(MSA),在计算中,先计算 Q = Z ⋅ W Q Q = Z \cdot W_{Q} Q=Z⋅WQ、 K = Z ⋅ W K K = Z \cdot W_{K} K=Z⋅WK、 V = Z ⋅ W V V = Z \cdot W_{V} V=Z⋅WV,得到注意力矩阵 A ( Q , K ) = S o f t m a x ( Q ⋅ K T / d ) \mathcal{A}(Q, K) = Softmax\left(Q \cdot K^{T} / \sqrt{d}\right) A(Q,K)=Softmax(Q⋅KT/d),进而计算 Z ^ = S A ( Z ) = A ( Q , K ) ⋅ V \hat{Z} = SA(Z)=\mathcal{A}(Q, K) \cdot V Z^=SA(Z)=A(Q,K)⋅V。为对齐标签,使用相同注意力矩阵 A ( Q , K ) \mathcal{A}(Q, K) A(Q,K) 更新标签嵌入 Y Y Y,即 Y ^ = A ( Q , K ) ⋅ Y \hat{Y}=\mathcal{A}(Q, K) \cdot Y Y^=A(Q,K)⋅Y。对于MSA,通过对所有注意力矩阵求平均来对齐标签,公式为 Y ^ = TL-Align-S ( Z , Y ) : = 1 H ∑ i = 1 H A i ( Q , K ) ⋅ Y \hat{Y}= \text{TL-Align-S}(Z, Y):=\frac{1}{H} \sum_{i = 1}^{H} \mathcal{A}_{i}(Q, K) \cdot Y Y^=TL-Align-S(Z,Y):=H1∑i=1HAi(Q,K)⋅Y,其中 H H H 为头数, A i \mathcal{A}_{i} Ai 是第 i i i 个头的注意力矩阵。
- 逐层对齐与最终标签确定:每个Transformer块通过空间和通道混合处理token,TL-Align以类似方式对齐标签嵌入。对于层次化视觉Transformer如Swin,合并token时采用添加标签嵌入并归一化的方式获取对齐标签。经过逐层对齐,得到最终的对齐token Z L Z^{L} ZL 和标签 Y L Y^{L} YL,根据模型不同,图像的最终对齐标签 y a l i g n y_{align} yalign 为类token的标签 y c l s L y_{cls}^{L} yclsL 或所有空间token标签的平均值 1 N ∑ i = 1 N y i L \frac{1}{N} \sum_{i = 1}^{N} y_{i}^{L} N1∑i=1NyiL,并用于训练网络。
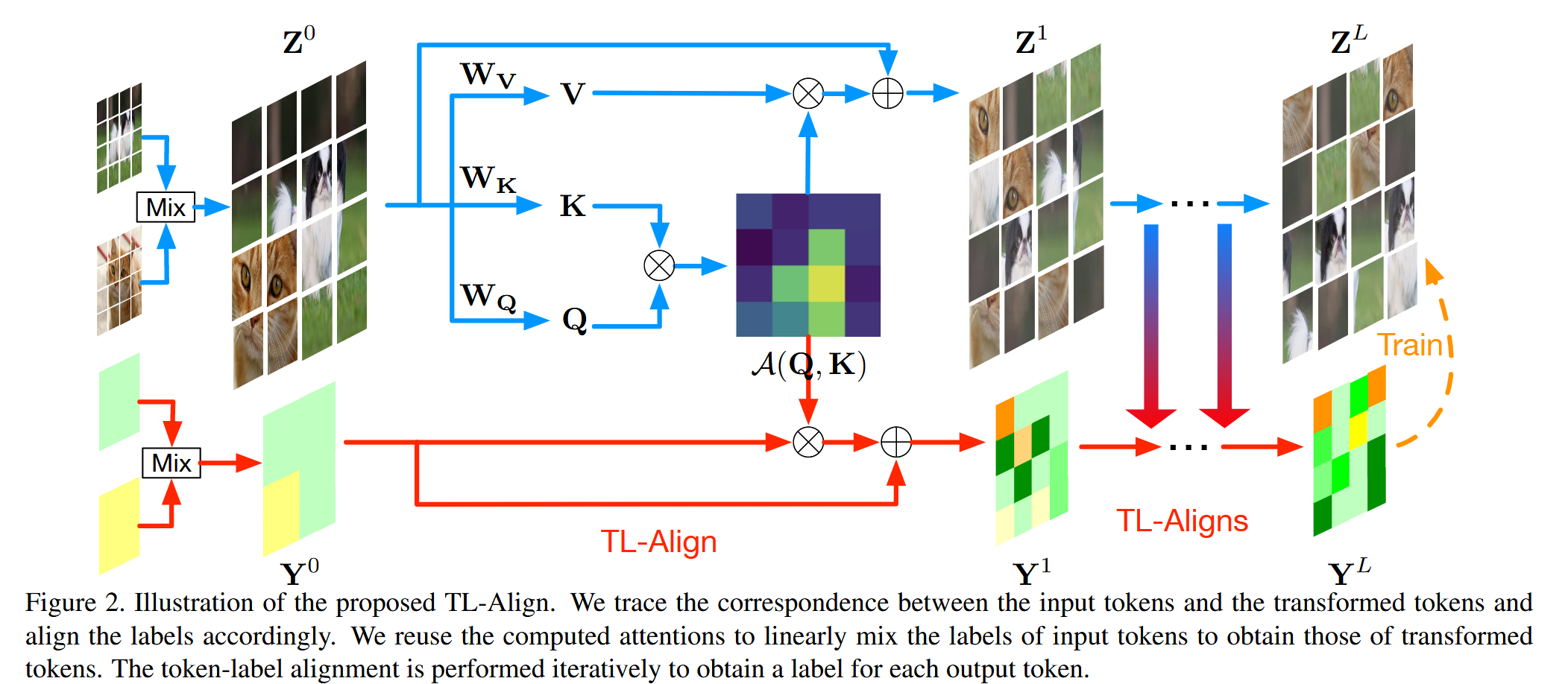
图2. 所提出的TL-Align方法示意图。我们追踪输入token和转换后token之间的对应关系,并据此对齐标签。我们重用计算得到的注意力,对输入token的标签进行线性混合,以获得转换后token的标签。通过迭代进行token-标签对齐,为每个输出token获取一个标签。
- 方法优势:TL-Align作为一个即插即用模块,在训练过程中自适应调整每个token的标签,在保持token和标签对齐的同时,仅引入可忽略的训练成本,且在推理时不增加额外计算成本。
实验-Experiments
这部分主要通过多组实验,全面评估了TL-Align方法的性能,验证了其有效性、鲁棒性和泛化性,具体内容如下:
-
ImageNet分类实验
- 实验设置:基于PyTorch和timm库,在多种ViT架构(DeiT、PVT、Swin的不同变体)上进行实验。小模型从 scratch 训练300轮,使用CutMix且保持其他设置不变,仅将CutMix的混合目标替换为TL-Align得到的标签;大模型则微调预训练模型。
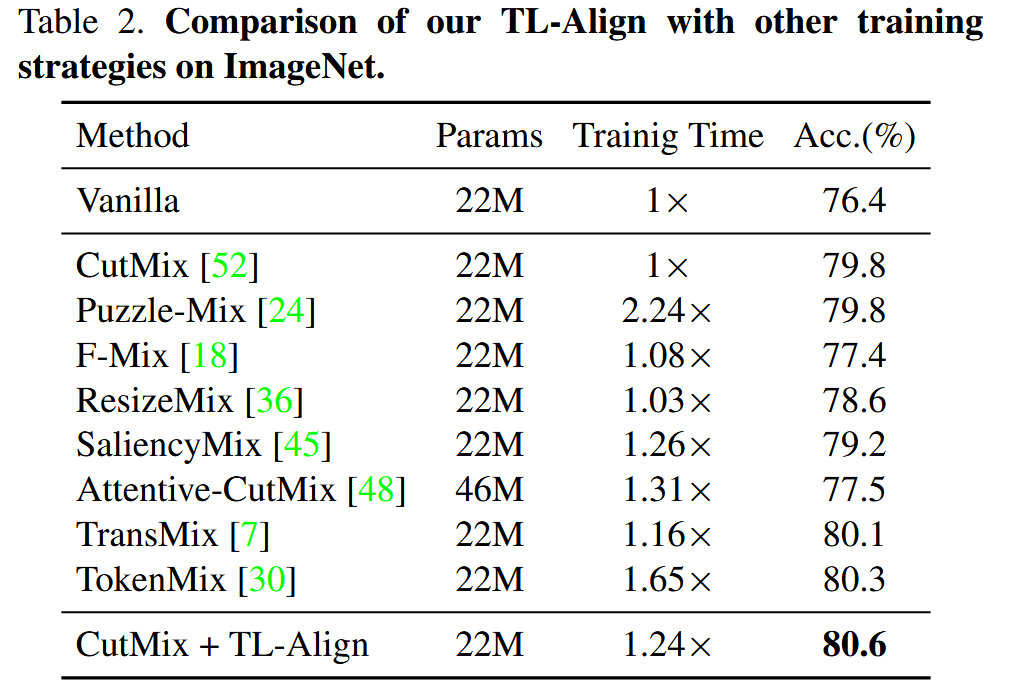
- 实验结果:TL-Align提升了不同架构模型的性能,如DeiT-T、DeiT-S、DeiT-B的Top-1准确率分别提升1.0%、0.8%、0.5% 。与其他训练策略相比,在保持参数数量和训练速度的同时,TL-Align性能更优。
表1. ImageNet图像分类任务的结果。我们比较了不同视觉Transformer骨干网络在使用和不使用我们的TL-Align方法时的参数数量、浮点运算次数(FLOPs)和准确率。
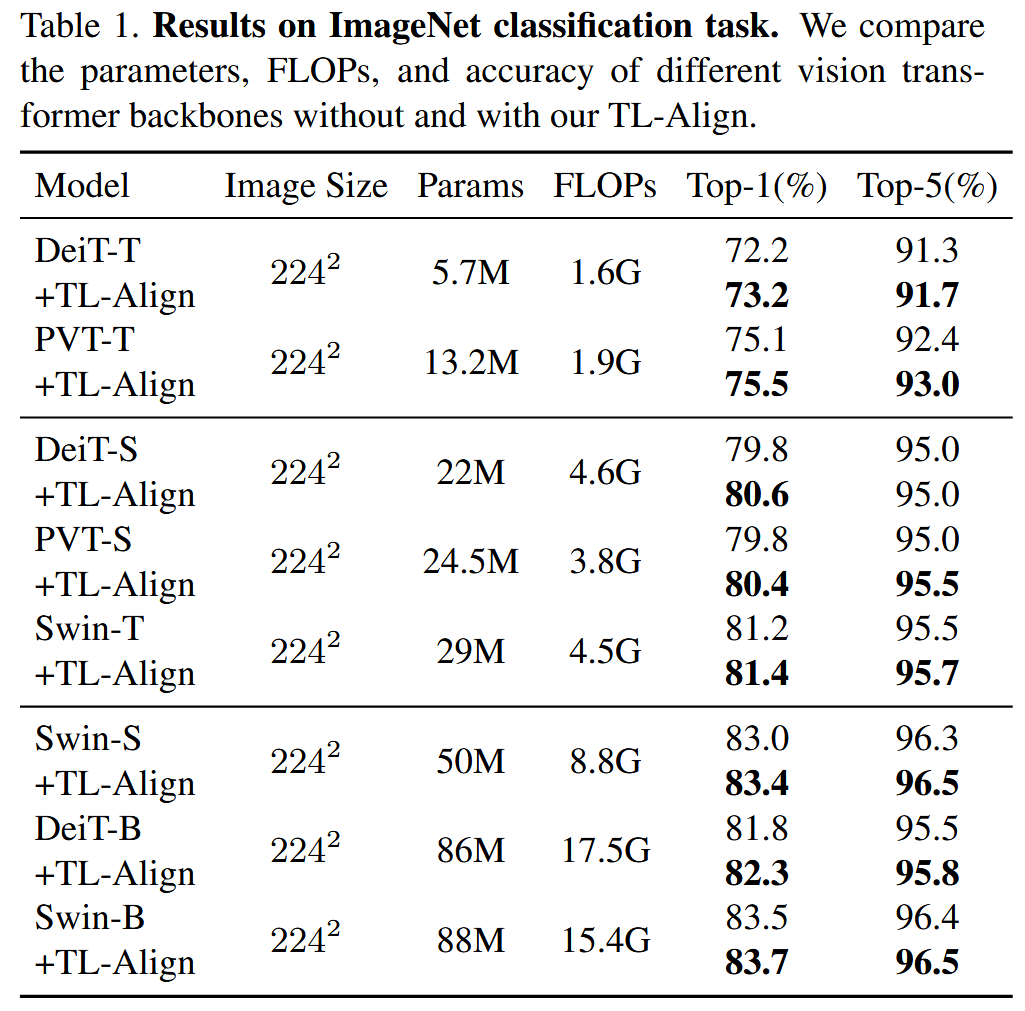
表2. 在ImageNet上我们的TL-Align方法与其他训练策略的比较。
-
下游任务实验
-
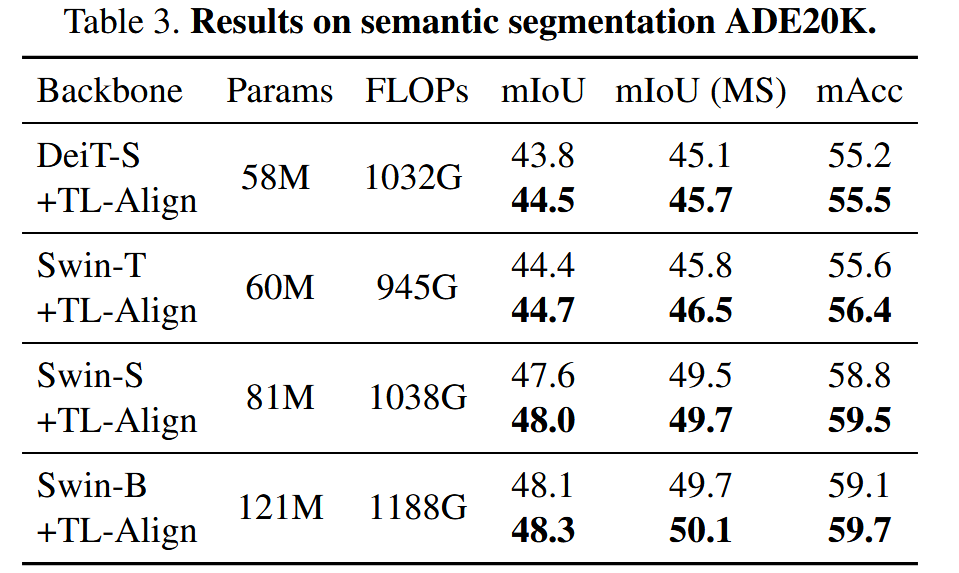
语义分割:在ADE20K数据集上,以DeiT-S和Swin系列为骨干网络,TL-Align提高了不同模型尺度的分割性能。
表3. ADE20K语义分割任务的结果。
-
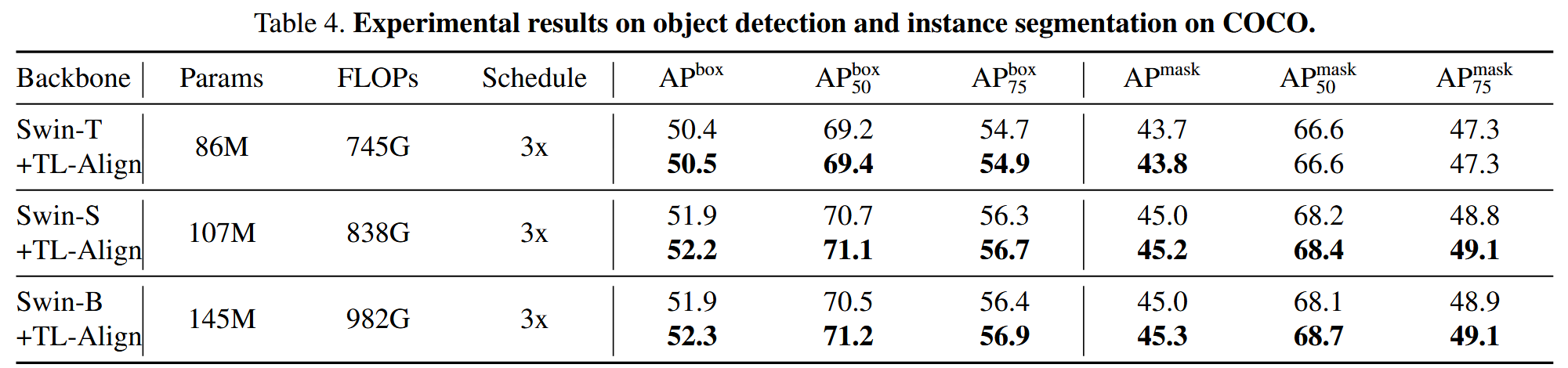
目标检测和实例分割:在COCO 2017数据集上,将TL-Align应用于Swin,采用Cascade Mask-RCNN框架和3x训练策略,所有Swin变体模型性能均有提升。
表4. 在COCO数据集上进行目标检测和实例分割的实验结果。
-
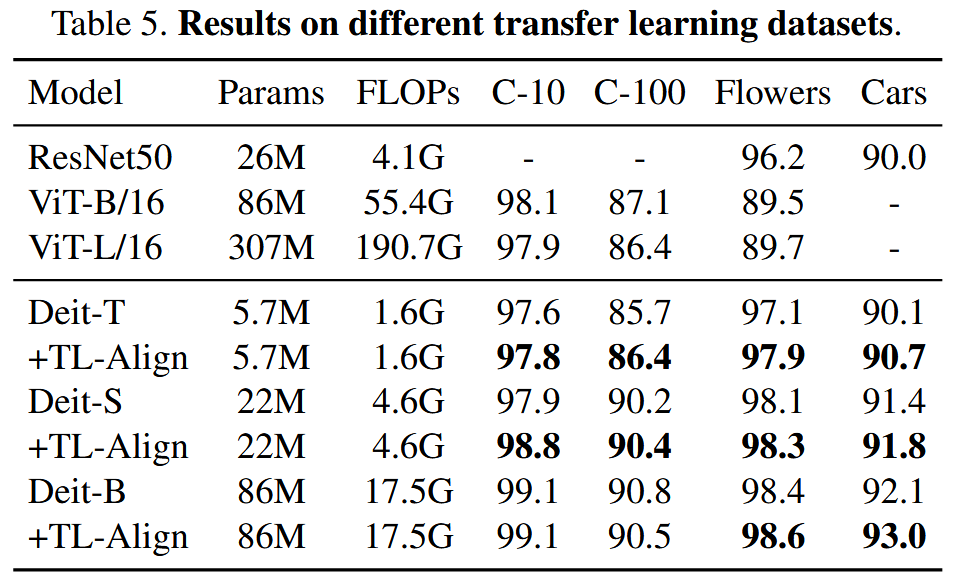
迁移学习:在CIFAR-10、CIFAR-100、Flowers和Cars数据集上,对ImageNet预训练模型微调,TL-Align使DeiT不同变体模型性能显著提升。
表5. 不同迁移学习数据集上的结果。
-
-
性能分析和可视化实验
-
token-标签对齐有效性:计算原始目标和对齐标签的均方根误差(RMSE),发现模型越大,RMSE越小,Swin的RMSE低于相似大小的DeiT,表明小模型和DeiT类骨干网络受token波动影响大,TL-Align对其提升更显著。
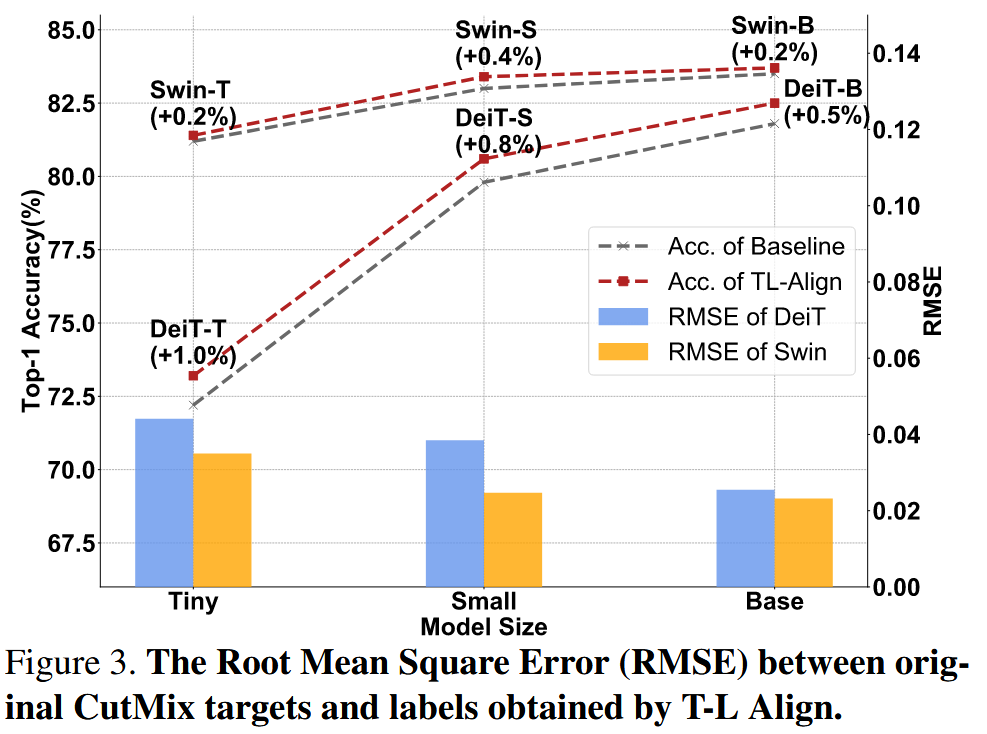
图3. 原始CutMix目标与通过TL-Align获得的标签之间的均方根误差(RMSE)。 -
波动token混合比例可视化:计算基于相似性的“真实”混合比例,与其他方法对比,发现CutMix等方法假设输出token与输入token空间对应,计算固定混合比例,而TL-Align通过逐层对齐为token分配动态标签,更准确。
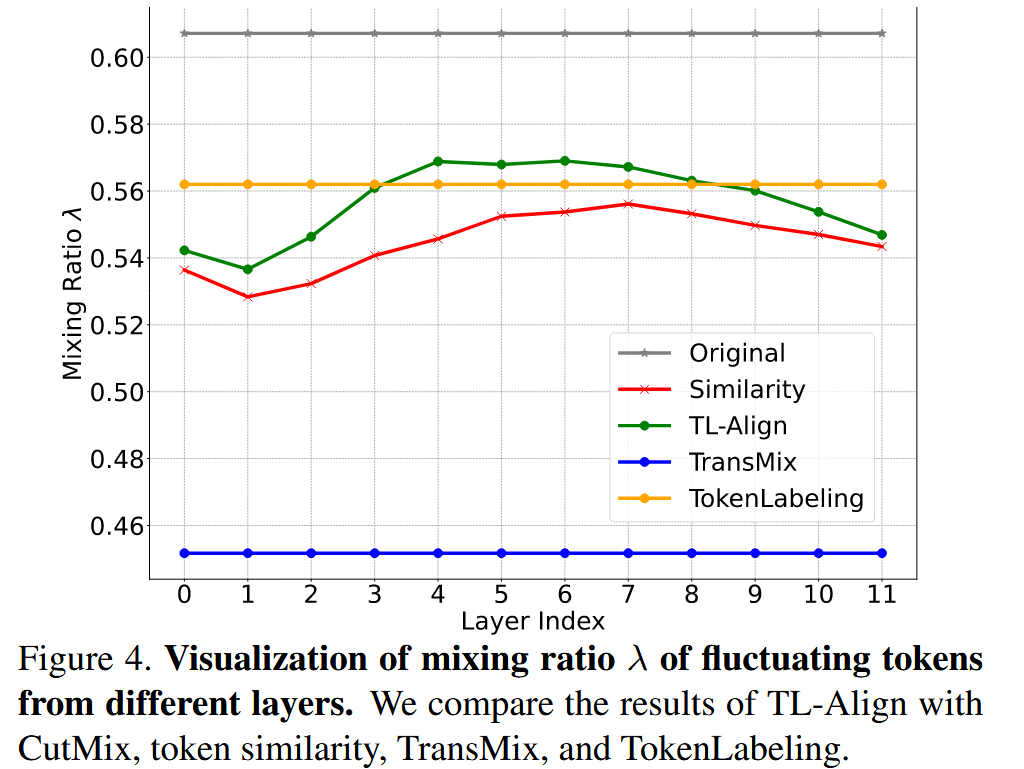
图4. 不同层波动token的混合比例 λ λ λ 可视化。我们将TL-Align的结果与CutMix、token相似度、TransMix和TokenLabeling的结果进行了比较。 -
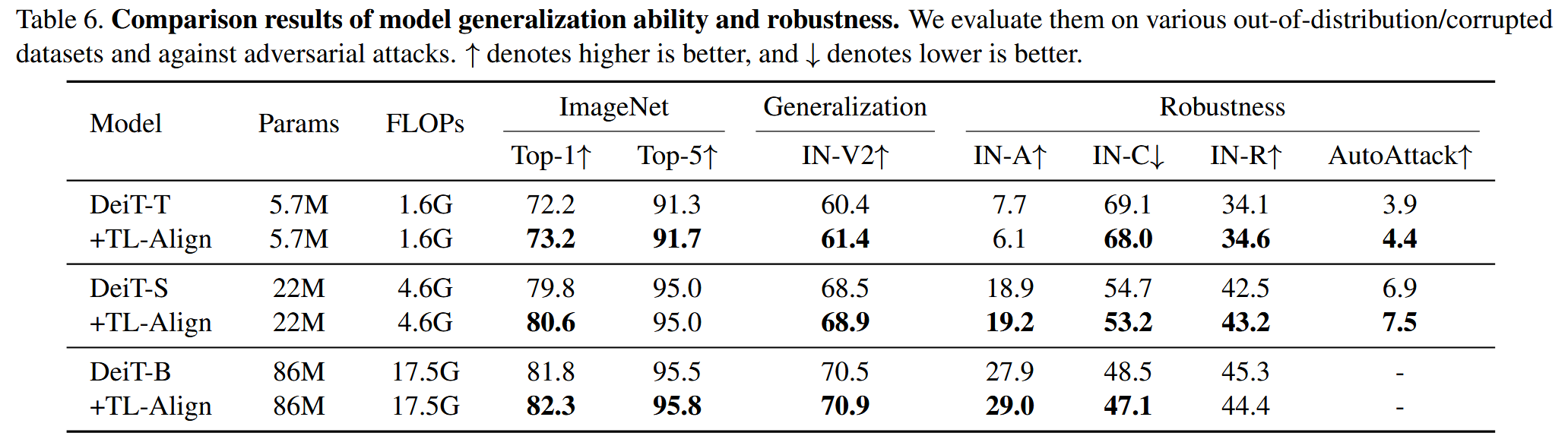
鲁棒性和泛化性评估:在多个损坏和分布外数据集上评估,采用AutoAttack评估对抗鲁棒性,结果表明TL-Align提高了模型的鲁棒性和泛化性。
表7. 使用不同数据混合策略的消融实验。
-
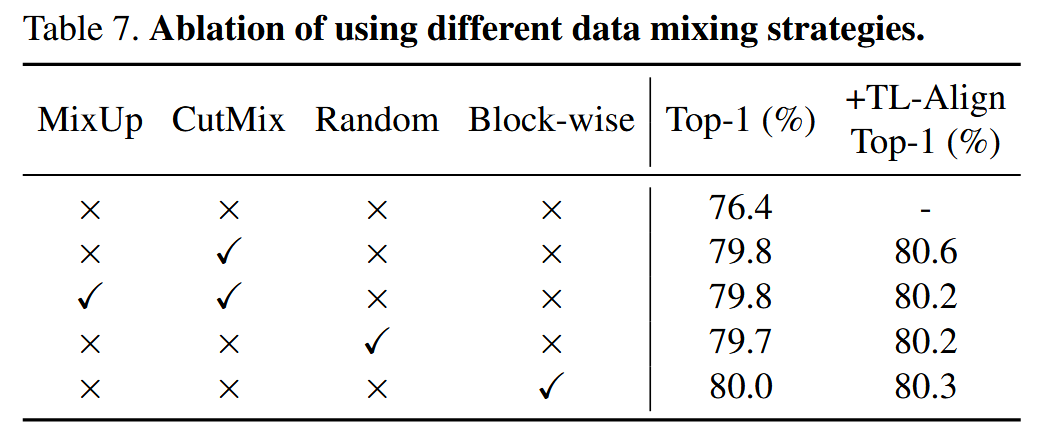
不同数据混合策略的消融实验:将TL-Align应用于多种数据混合策略,结果显示均有性能提升,验证了其泛化性。
表7. 使用不同数据混合策略的消融实验。
-
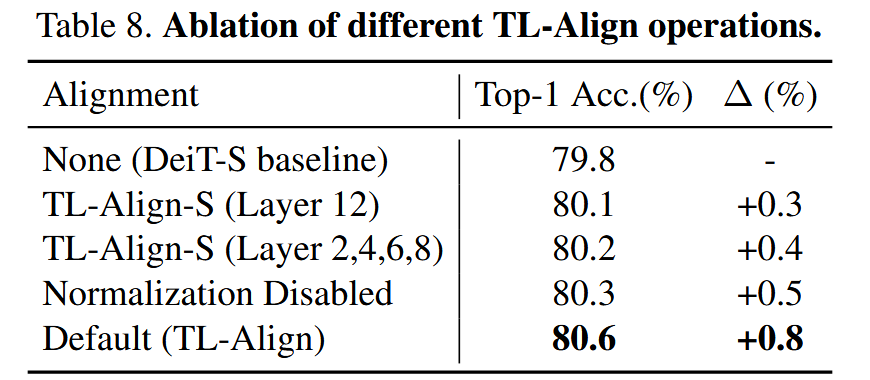
不同标签对齐操作的消融实验:对DeiT-S进行实验,发现仅用第12层注意力图对齐或部分层对齐且禁用归一化,性能提升有限或下降,证明了TL-Align中利用注意力和归一化逐层对齐的重要性。
表8. 不同TL-Align操作的消融实验。
-
对齐标签可视化:可视化DeiT-S和Swin-S的对齐标签,发现其与原始标签不同,使用原始比例作为训练目标可能产生错误信号,TL-Align可纠正标签。

图5. 在DeiT-S和Swin-S上的结果可视化。我们对输入图像、混合图像、原始标签嵌入以及经过token-标签对齐后的标签嵌入进行了可视化展示。
-
结论-Conclusion
这部分内容总结了TL-Align方法的研究成果,并对未来研究方向进行了展望,具体如下:
- 研究成果总结:本文提出的Token-标签对齐(TL-Align)方法有效解决了视觉Transformer(ViTs)训练中由于token波动导致的训练信号不准确问题。数据混合策略虽能提升CNNs和ViTs性能,但ViTs中的token波动现象限制了其效果。TL-Align通过追踪token对应关系获取准确训练信号,实验表明该方法能持续提升多种ViT模型在不同任务上的性能。
- 未来研究方向展望:TL-Align在其他架构(如MLP-like模型)上的泛化性能尚不清楚,这为后续研究提供了一个具有潜力的探索方向。