【Hive入门】Hive与Spark SQL深度集成:Metastore与Catalog兼容性全景解析
目录
引言
1 元数据管理体系架构对比
1.1 Hive Metastore架构解析
1.2 Spark Catalog系统设计
2 元数据兼容性深度剖析
2.1 元数据模型映射关系
2.2 元数据同步机制
3 生产环境配置指南
3.1 基础兼容性配置
3.1.1 Spark连接Hive Metastore
3.1.2 多引擎共享配置
3.2 高级集成方案
3.2.1 跨Catalog访问
3.2.2 元数据缓存优化
4 常见问题解决方案
4.1 元数据不一致场景
场景1:表结构变更不同步
场景2:分区信息不一致
4.2 性能调优策略
5 实践分析
5.1 统一元数据治理架构
5.2 多租户隔离方案
6 总结
引言
在企业级数据平台架构中,Hive Metastore与Spark Catalog的兼容性设计是构建统一数据治理体系的核心支柱。本文将全面剖析两者间的数据共享机制,深入解读元数据兼容原理。
1 元数据管理体系架构对比
1.1 Hive Metastore架构解析
Hive Metastore作为Hive生态的元数据管理中心,采用三层架构设计:
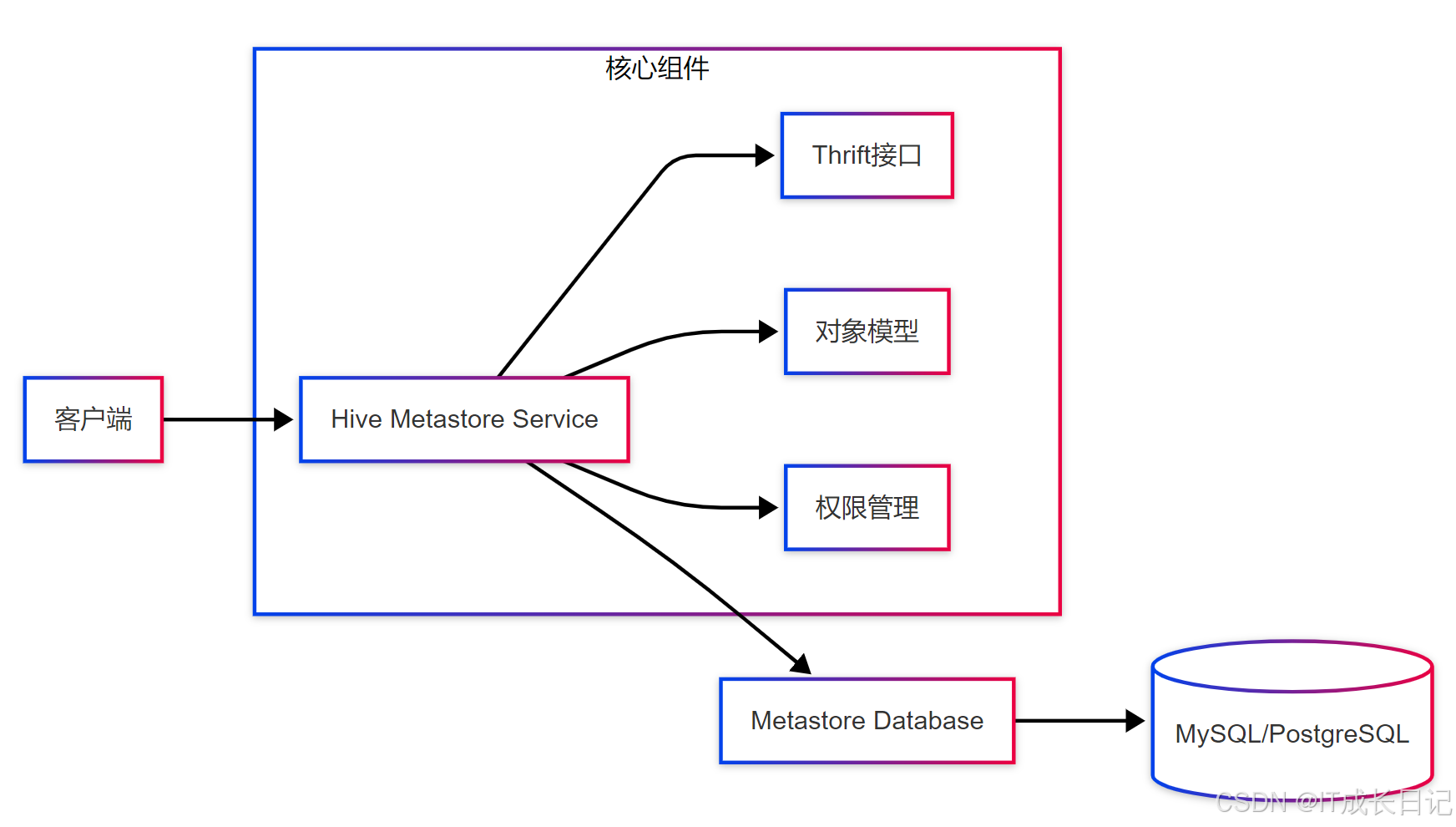
核心功能组件:
- Thrift接口:提供跨语言元数据访问能力(支持Java/C++/Python等)
- 对象模型:定义表、分区、列等元数据实体及其关系
- 权限管理:集成Ranger/Sentry实现列级权限控制
关键元数据表:
- TBLS:存储表基本信息
- DBS:记录数据库信息
- PARTITIONS:管理分区元数据
- COLUMNS_V2:保存字段定义
1.2 Spark Catalog系统设计
Spark 2.x+引入的Catalog插件体系支持多种元数据源:
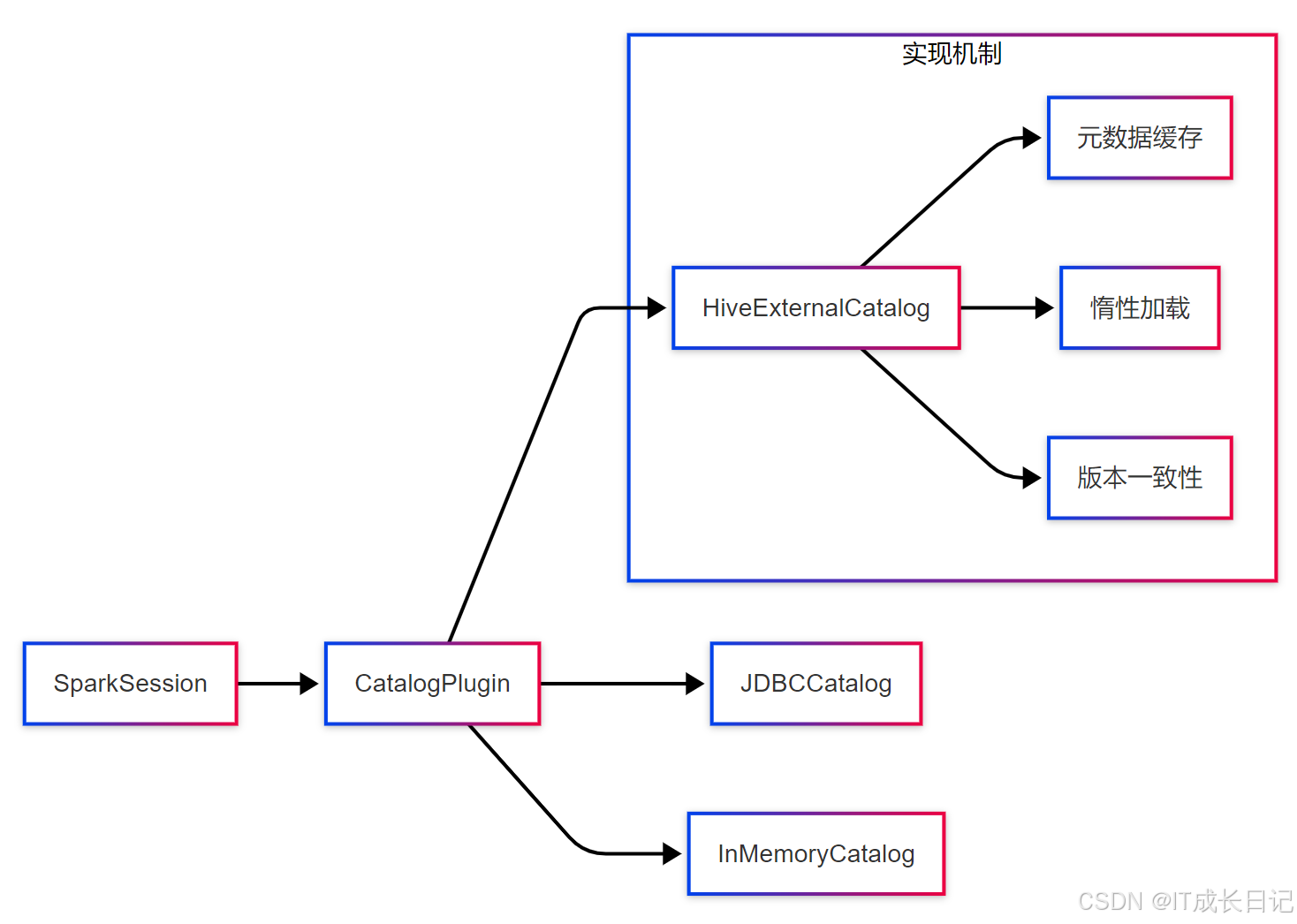
核心特性:
- 多Catalog支持:通过spark.sql.catalog.[name]配置多个数据目录
- 扩展接口:开发者可自定义Catalog实现
- 层级命名空间:支持catalog.database.table三级引用
2 元数据兼容性深度剖析
2.1 元数据模型映射关系
Hive与Spark的元数据对象转换逻辑:
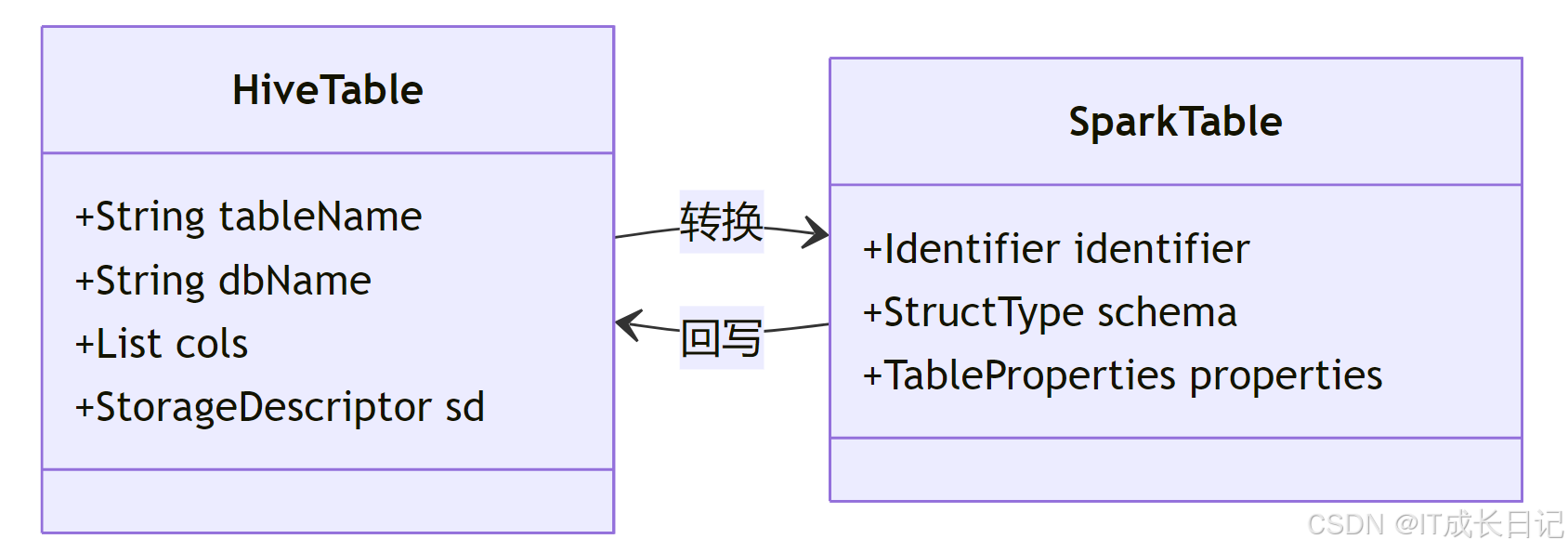
字段映射关键点:
- 数据类型转换:处理DECIMAL(precision,scale)等类型的精度差异
- 存储格式适配:确保ORC/Parquet等格式的读写兼容
- 分区策略对齐:动态分区与静态分区的协同处理
2.2 元数据同步机制
Spark访问Hive Metastore的工作流程:
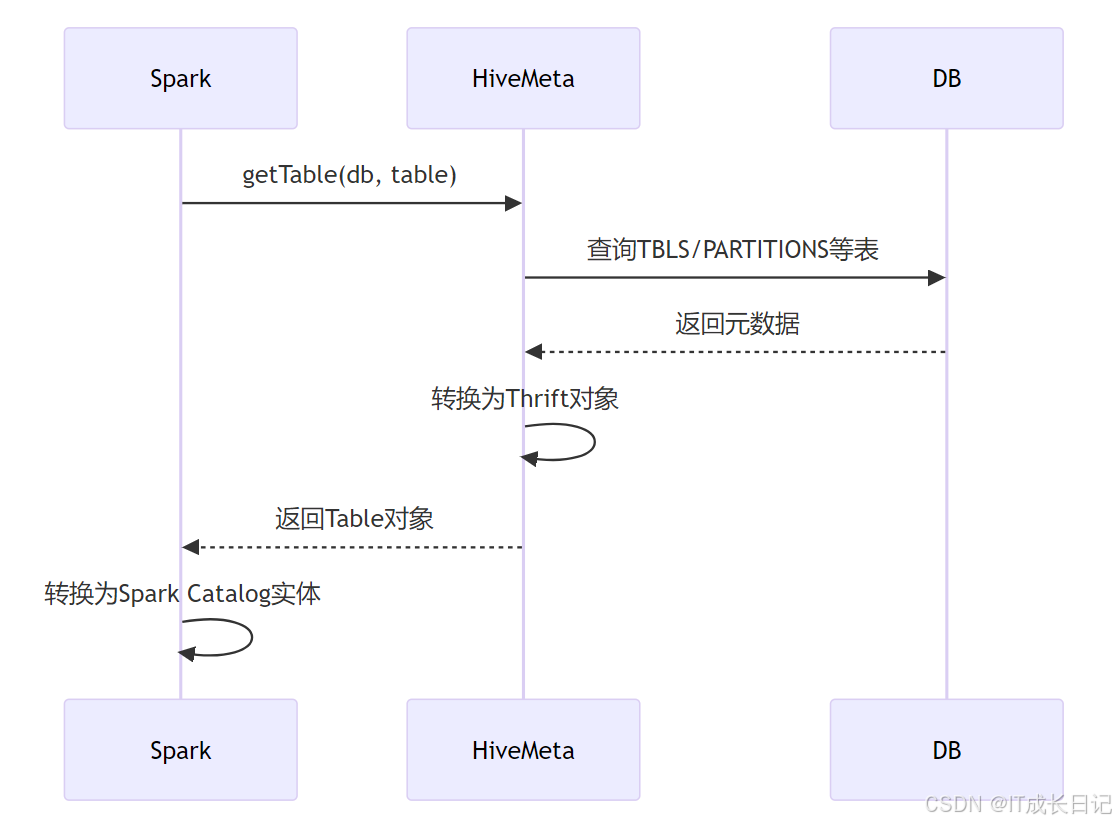
同步触发条件:
- 首次访问表元数据时(惰性加载)
- 执行REFRESH TABLE命令后
- Metastore通知机制触发(需配置Hive Hook)
3 生产环境配置指南
3.1 基础兼容性配置
3.1.1 Spark连接Hive Metastore
# spark-defaults.conf关键配置
spark.sql.catalogImplementation=hive
spark.hadoop.hive.metastore.uris=thrift://metastore-host:9083
spark.sql.hive.metastore.version=3.1.2
spark.sql.hive.metastore.jars=path/to/hive-metastore-jars/*3.1.2 多引擎共享配置
<!-- hive-site.xml统一配置 -->
<property><name>metastore.storage.schema.reader.impl</name><value>org.apache.hadoop.hive.metastore.SerDeStorageSchemaReader</value>
</property><property><name>metastore.table.type</name><value>EXTERNAL_TABLE</value>
</property>3.2 高级集成方案
3.2.1 跨Catalog访问
-- 在Spark中访问不同Catalog
USE catalog.hive_catalog;
SELECT * FROM db.table;
USE catalog.spark_catalog;
CREATE TABLE new_table AS ...;
-- 跨Catalog查询
SELECT * FROM hive_catalog.db.table t1
JOIN spark_catalog.db.table t2 ON t1.id = t2.id;3.2.2 元数据缓存优化
# 缓存相关参数
spark.sql.hive.metastorePartitionPruning=true
spark.sql.hive.manageFilesourcePartitions=true
spark.sql.hive.caseSensitiveInferenceMode=INFER_AND_SAVE4 常见问题解决方案
4.1 元数据不一致场景
场景1:表结构变更不同步
- 解决方案流程:
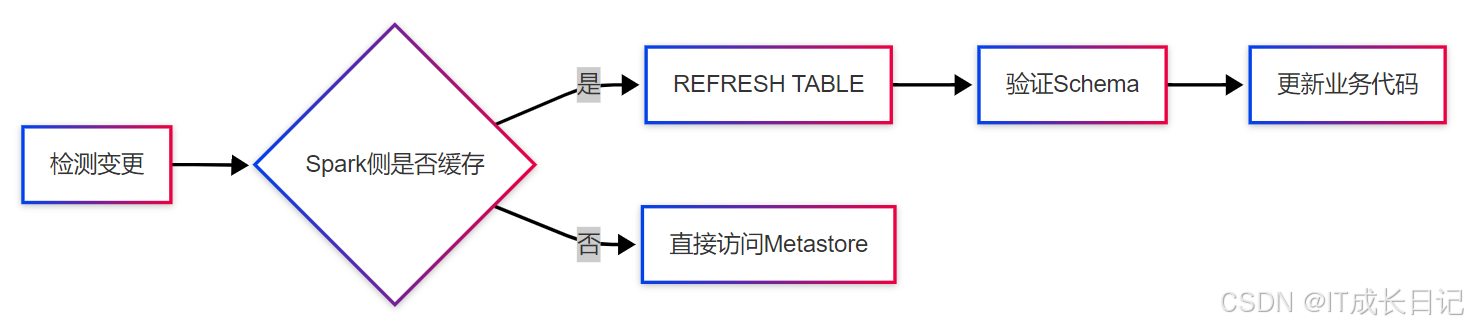
- 自动化检测脚本:
def check_schema_diff(spark, hive):spark_schema = spark.table("db.table").schemahive_schema = hive.execute("DESCRIBE db.table")return compare_schemas(spark_schema, hive_schema)场景2:分区信息不一致
- 修复命令集:
-- Spark侧修复
MSCK REPAIR TABLE db.table;
-- Hive侧修复
ALTER TABLE db.table RECOVER PARTITIONS;4.2 性能调优策略
- 优化1:元数据批量访问
# 批量获取分区参数
spark.sql.hive.metastore.batch.retrieve.table.partition.max=2000- 优化2:缓存控制
// 编程式缓存管理
spark.catalog.cacheTable("db.table")
spark.catalog.uncacheTable("db.table")5 实践分析
5.1 统一元数据治理架构
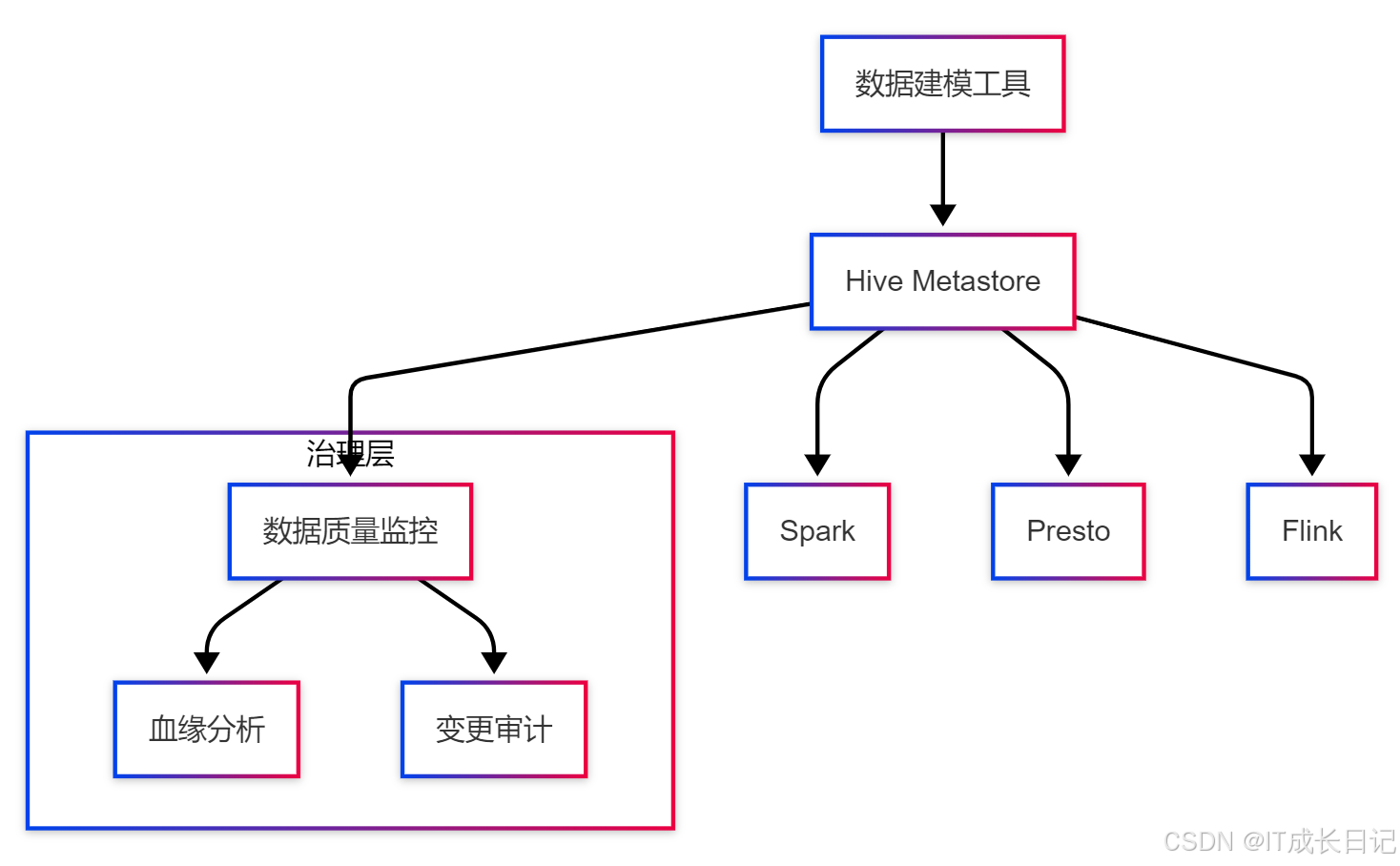
实施要点:
- 所有引擎共用Metastore服务
- 通过Hook机制捕获元数据变更
- 定期执行元数据一致性检查
5.2 多租户隔离方案
- 方案1:数据库级隔离
-- 为每个租户创建独立数据库
CREATE DATABASE tenant_a LOCATION 'hdfs:///tenant_a';
CREATE DATABASE tenant_b LOCATION 'hdfs:///tenant_b';
-- 配置权限
GRANT ALL ON DATABASE tenant_a TO USER user_a;- 方案2:Catalog级隔离
# 定义多Catalog
spark.sql.catalog.tenant_a=org.apache.spark.sql.hive.HiveExternalCatalog
spark.sql.catalog.tenant_a.uri=thrift://metastore-a:9083spark.sql.catalog.tenant_b=org.apache.spark.sql.hive.HiveExternalCatalog
spark.sql.catalog.tenant_b.uri=thrift://metastore-b:90836 总结
Hive Metastore与Spark Catalog的深度兼容为企业数据平台带来三大核心价值:
- 元数据一致性:确保各引擎对数据定义的统一理解
- 运维效率提升:避免多套元数据系统的维护成本
- 计算灵活性:根据场景自由选择执行引擎
生产环境实施建议:
- 版本控制:严格匹配Hive与Spark版本
- 监控体系:建立元数据变更的监控告警
- 定期维护:执行MSCK REPAIR等维护命令
- 权限统一:集成企业级权限管理系统
随着数据湖架构的普及,Hive Metastore作为元数据中枢的角色将进一步强化。通过本文介绍的集成方案,企业可以构建既满足当前需求又具备未来扩展性的元数据管理体系。