C++日志系统实现(二)
C++日志系统实现(二)
作者: aderversa
前置文章:C++日志系统实现(一) – 大道三千
在上一篇文章中,我简单了解了一个同步日志系统是如何实现的。本篇文章来讲述如何实现一个异步的日志系统。
为什么需要异步地输出日志呢?因为很多日志输出的操作都会涉及到I/O操作,比如:输出到文件、输出到网络等,这些操作的耗时高,会阻塞正常业务代码的运行,影响处理业务请求的效率。
因此,我们希望业务的运行和日志的I/O可以分开来运行,这样业务就不会因为日志的I/O而阻塞。
生产者和消费者
生产者从字面意思上理解就是生产某种产品的人,消费者则是消费某种产品的人。
生产者将产品生产出来然后放到某个地方,比如:先使用货车将其运到超市,然后由超市员工将其放到货架上。消费者从超市货架上拿到产品,然后购买并使用完这个产品就算作消费了产品。
生产者不需要管产品会被消费者以什么样的方式消费,只需要不断地生产出产品然后运输到货架上。消费者也不需要关心产品怎样被生产出来,只需要按照它的方式对产品进行消费。
从上述场景中我们可以抽象出三个对象:Producer(生产者)、Container(容器)、Consumer(消费者)。
在计算机的世界中,Producer可以是任何可运行的线程,它们在任意时刻往Container中添加产品。Consumer则是不断地从Container中取出产品,然后消费它。
这里有几个东西描述地比较抽象:
- 产品是怎么样的?
- 容器是怎样的?
- 消费者如何消费容器中的产品?
这些不明确的描述,对应了我们程序中的生产者消费者模型的不同实现。比如在日志系统中我们可以规定:
- 产品就是一个
std::string对象,里面存放一条格式化后的日志记录; - 容器是一个
std::queue; - 消费者从
std::queue中取出一条格式化后的日志记录,然后将其输出到某个地方;
按照上述描述实现的生产者和消费者模型,就是一个以消息队列作为中间件的异步模型。
我们当然可以使用上述模型将日志I/O操作异步化。但该模型存在以下问题:
- 容器是
std::queue,意味着当日志的生产速度大于日志的消耗速度,并且这种状态维持很长一段时间时,容器会不断地存储新的日志输出请求。这样的话,日志输出请求会占用大量的内存空间,最终使得程序被OS回收掉。 - 输出的单位是一条日志,每一条日志都需要系统调用来进行输出。队列中存在N条记录,那就需要进行N次系统调用进行输出。输出的效率低。
因此,我们需要改进容器,使其占用的内存空间能够得到限制,以此换取系统的稳定性,这就需要使用到池化技术。为了能够批量写入多条日志,我们需要一种新的消费方式以此提高消费的效率。
Buffer
我们可以将std::string看做是对const char*和大小size的封装,它指向的是内存中的一片区域,我们将其写入文件或者输出到的网络的时候,实际上就是读取这片内存区域:
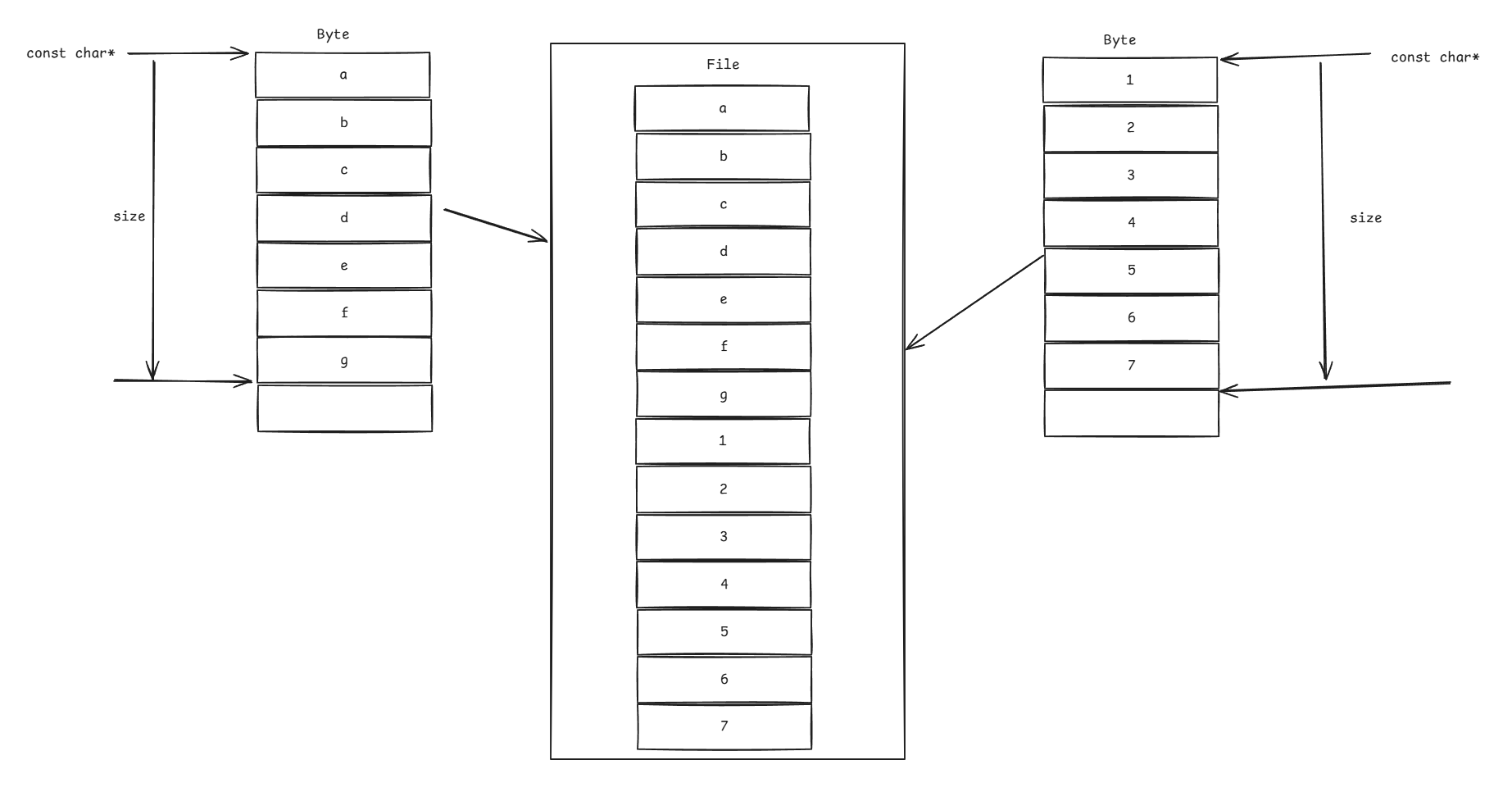
我们有两种方式将"abcdefg"和"1234567"输出到File中:
- 在内存中将两个字符串拼接成
"abcdefg1234567"后,调用一次磁盘I/O将其输出到File中。 - 调用两次磁盘I/O将两个字符串按顺序输出到File中。
我们知道,在内存中操作数据的时间是远小于进行磁盘I/O的时间的。因此,我们在内存中拼接的字符串的日志记录越多,那么输出的效率肯定是会比对每一条日志记录都调用一次磁盘I/O要赚得多的。
因此,我们的Container具有这样的行为,在往Container中添加字符串时,它会将字符串拼接起来放在一块连续的内存区域中。这样消费者就可以调用一次磁盘I/O直接消费整片内存区域的日志记录,而不是单个日志记录。
消费者需要在内存区域不能再写日志的时候消费Container,因为这样可以尽可能减少磁盘I/O。
这种Container我们可以叫它Buffer(缓冲区)。缓冲区与实际的数据类型无关,它只是一片存储字节数据的固定大小的内存区域。
实现Buffer
我将缓冲区分为了三个部分:已读部分、可读部分、可写部分
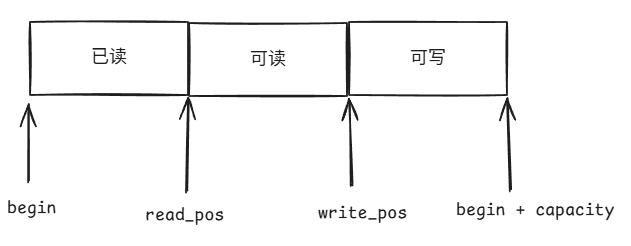
我们有四个指针begin,read_pos,write_pos和begin + capacity。
begin和read_pos之间的是已读区域,此区域不再可读且不可写。read_pos和write_pos之间是可读区域,此区域可读,用户能够选择向右移动或者不移动read_pos,以此来标志已读区域。read_pos不能够超越write_pos。write_pos和begin + capacity是可写区域,当此区域不为空时,可以写入数据。用户写入数据时必然会使得write_pos向右移动,移动多少取决于用户写入了多少数据。
capacity是Buffer的内存区域的大小。使用读写指针分离的好处是:
- 读写互不阻塞。
因此,我们可以这样定义Buffer:
#pragma once
#include <cassert>
#include <vector>
#include <atomic>
#include <cstddef>namespace adalog
{class Buffer{public:Buffer();/*** @param data 指向数据的第一个字节的指针* @param len 数据的字节数,即数据的长度*/void Push(const char* data, size_t len);/*** @param len 要读取的数据的长度,若没有那么多可读取数据,则会发出警告 * @return 返回指向数据首字节的char指针,需要注意读取之后若下一次需要获取下一个数据则需要调用一次moveReadPos()*/char* ReadBegin(size_t len);/*** @return 缓冲区为空(可读取数据为空)则为true;否则返回false*/bool IsEmpty() const;/*** 将本缓冲区和buf的缓冲区做交换,并不会复制buf的元素,而是交换二者的一些指针数据* @param buf 要交换的缓冲区*/void Swap(Buffer& buf);/*** @return 返回缓冲区可写的空间大小*/size_t WritableSize() const;/*** @return 返回缓冲区中可读的空间大小*/size_t ReadableSize() const;/*** @return 返回指向缓冲区可读的首字节的const char指针*/const char* Begin() const;/*** 将写指针向后移len个字节* @param len 移动的字节数*/void MoveWritePos(size_t len);/*** 将读指针向后移len个字节* @param len 移动的字节数*/void MoveReadPos(size_t len);/*** 重置缓冲区的读、写指针,使得之前读取的区域可以被再次利用,否则会缓冲区会无限扩容*/void Reset();protected:/*** 当可写的空间大小小于len的时候,进行扩容。若不想要Buffer在Push的过程中扩容,就需要Push方法的调用者自行确保可写的空间大小大于len* @param len */void ToBeEnouth(size_t len);private:std::vector<char> buffer_;std::atomic<size_t> write_pos_;size_t read_pos_;// 缓冲区大小增长的阈值,超过该阈值线性增长;低于该阈值指数增长size_t threshold_;// 线性增长的大小size_t linear_growth_;};} // namespace adalog使用Buffer的异步模型
在日志输出量不大时,Buffer可以显著降低日志输出时磁盘I/O的次数。
由于只有一个Buffer,因此时间轴上使用Buffer的时间分布应该会是这样的:生产满Buffer占用一段时间,然后消费满Buffer占用一段时间。消费的过程中由于Buffer是满的,因此生产者们无法继续生产,只能等待消费者消费完Buffer然后重置它,才能继续生产。
用具体的数值来描述就是,生产一个满Buffer耗费1T,消费一个满Buffer耗费4T。如果生产者运气不好,刚好在消费的4T中输出生产日志,那么就最坏需要阻塞4T的时间。
有什么办法解决这个问题呢?在一个满Buffer被消费的4T的时间内,如果有4个空闲的Buffer,那么就可以撑过这4T,然后产出一个新的空闲Buffer。
如果只有一个消费者,那么空闲Buffer的数量还是会逐渐减少,最终形成类似于单个Buffer的情况,因此为了避免这种情况,还要配备多个消费者来消费多个满Buffer,来尽可能缩短生产者等待可写Buffer的时间。
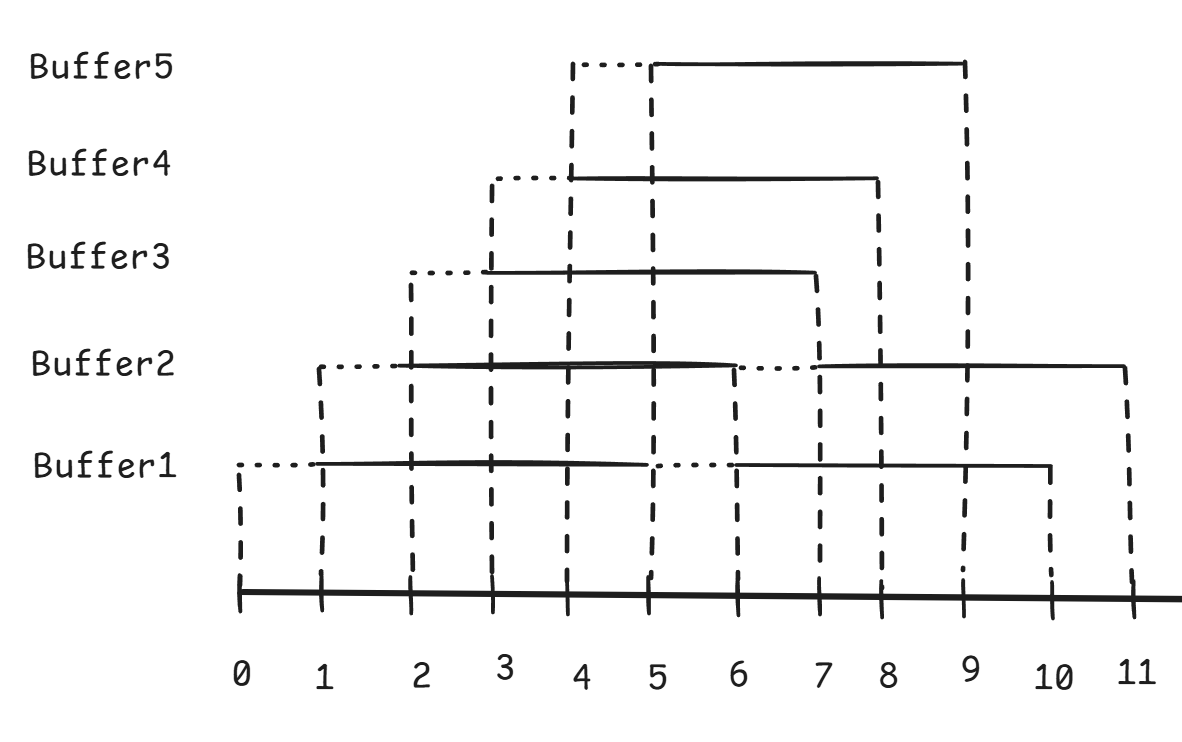
在生产一个满Buffer消耗1T时间,消费一个满Buffer消耗4T时间,配备5个Buffer和5个消费者线程,那么理论上恰好可以保证每个时间内都有一个Buffer可以接收生产者的数据。
因此,减少生产者的阻塞时间的关键在于根据生产一个满Buffer的时间和消费一个满Buffer的时间,配备合适的Buffer数量和消费者线程的数量。由于硬件和软件方面的原因,生产和消费一个满Buffer的时间是很难预估的。
我们只能大致增加一些Buffer,同时在允许的范围内多加几个消费者去消费Buffer,以此来应对日志输出量大的情况。
多个Buffer和多个消费者线程也就引出了缓冲池和线程池。
缓冲池
池化技术是一种资源管理策略,通过预先创建并复用资源来提升系统性能、资源利用率和稳定性。
缓冲池就是使用池化技术来管理Buffer。
那么怎样实现一个缓冲池呢?首先我们需要准备多个Buffer,并为这些Buffer编号,如:0,1,2,3。然后我们可以使用编号向缓冲池申请访问该Buffer。
比如,我们向缓冲池申请访问编号为1的Buffer,那么缓冲池就会让申请者可以访问编号为1的Buffer。
那么问题又来了,给一个编号了编号,缓冲池该怎样向申请者开放Buffer的访问权限呢?你可能会想,指向返回Buffer的引用或者指针什么的不就可以了吗?这样不就可以让申请者访问Buffer了。
这样做可能会有以下问题:
- 实际上,这样做的话是线程不安全的,因为你将Buffer直接交给申请者,有可能会有多个线程访问Buffer,就会出现同步问题。由于我的Buffer并不是线程安全的,只保证了读写分离。那么就不能够直接返回Buffer出去。
- 将缓冲区的具体实现暴露给申请者,修改Buffer的代码会导致使用缓冲池的地方需要进行修改。
我的想法是:将访问分为共享和独占。如果是共享访问就返回一个ReadBufferGuard对象,如果是独占访问就返回一个WriteBufferGuard对象。
同一个Buffer的ReadBufferGuard和WriteBufferGuard遵循以下规则:
- 由于读写分离,因此
ReadBufferGuard和WriteBufferGuard可以同时存在,这是我们Buffer的底层实现决定的。 - 缓冲池之外,可以存在多个
ReadBufferGuard和最多一个WriteBufferGuard。限制只能有一个WriteBufferGuard是因为不支持多个线程写的线程安全。 - 当缓冲池外已经存在一个
WriteBufferGuard时,申请独占该缓冲区的线程将会阻塞。但申请共享缓冲区的线程都能够以不阻塞的方式获取到ReadBufferGuard。 - 获取到
ReadBufferGuard之后,可以使用该对象的方法来获取缓冲区在内存的起始地址和可读大小,方便用户以更底层的接口访问可读数据。 - 获取到
WriteBufferGuard之后,可以使用ReadBufferGuard中存在的方法,同时还能够往缓冲区中写入数据或者重置缓冲区,注意当写入的数据大小超过了缓冲区的可写区域时,缓冲区将会自动扩容,因此,如果不想要自动扩容请提供额外机制来防止它扩容。之所有不提供机制来处理不扩容的情况,是因为Buffer无法知道空间不够时该进行什么操作,如果直接阻塞的话会导致原有的线程无法进行应有的操作。
BufferPoolManager
#pragma once#include "adalog/buffer/Buffer.h"
#include <cstddef>
#include <memory>
#include <atomic>
#include <optional>
#include <mutex>namespace adalog
{class BufferPoolManager;class ReadBufferGuard;class WriteBufferGuard;class BufferHeader{friend class BufferPoolManager;friend class ReadBufferGuard;friend class WriteBufferGuard;public:explicit BufferHeader(std::size_t buffer_id);private:size_t GetBufferId() const;const char* GetDataBegin() const;size_t ReadableSize() const;void WriteData(const char* data, size_t len);size_t WritableSize() const;void Reset();private:const size_t buffer_id_;std::mutex rwlatch_;/*** @brief Buffer的引用计数*/std::atomic<size_t> pin_count_;std::unique_ptr<Buffer> buffer_;};class BufferPoolManager{public:BufferPoolManager(size_t num_buffer);~BufferPoolManager();/*** @return 缓冲池中Buffer的数量,Buffer的编号从0开始,到Size() - 1结束。*/size_t Size() const;/*** @brief 获取指定编号的Buffer的读缓冲区。* @param buffer_id Buffer的编号,从0开始,到Size() - 1结束。* @return 读缓冲区的Guard对象。若指定编号的Buffer不存在,则返回std::nullopt。*/std::optional<ReadBufferGuard> GetReadBuffer(size_t buffer_id);/*** @brief 获取指定编号的Buffer的写缓冲区。* @param buffer_id Buffer的编号,从0开始,到Size() - 1结束。* @return 读缓冲区的Guard对象。若指定编号的Buffer不存在,则返回std::nullopt。*/std::optional<WriteBufferGuard> GetWriteBuffer(size_t buffer_id);std::optional<size_t> GetPinCount(size_t buffer_id);private:const size_t num_buffers_;std::vector<std::shared_ptr<BufferHeader>> buffers_;};
} // namespace adalogReadBufferGuard
#pragma once#include "adalog/buffer/BufferPoolManager.h"namespace adalog
{class ReadBufferGuard{friend class BufferPoolManager;public:/*** @brief 只有BufferPoolManager能够创建有效的ReadBufferGuard对象,该默认构造函数是为了外部能够预先创建一个ReadBufferGuard对象,以便跨作用域传递*/ReadBufferGuard() = default;/*** @brief 禁止拷贝构造和赋值构造*/ReadBufferGuard(const ReadBufferGuard&) = delete;ReadBufferGuard& operator=(const ReadBufferGuard&) = delete;/*** @brief 允许移动构造和移动赋值*/ReadBufferGuard(ReadBufferGuard&& other) noexcept;ReadBufferGuard& operator=(ReadBufferGuard&& other) noexcept;~ReadBufferGuard();size_t GetBufferId() const;/*** @brief 获取缓冲区中可读数据的起始地址,从该起始地址开始有ReadableSize()个字节的数据可读,超出该范围的数据不可读。* @return 缓冲区中可读数据的起始地址*/const char* GetDataBegin() const;/*** @return 从缓冲区的起始地址开始,到可读数据的末尾的字节数*/size_t ReadableSize() const;/*** @brief 将缓冲区中的数据转换为指定类型的指针,方便读取该类型的数据*/template<class T>const T* As() const { return reinterpret_cast<const T*>(GetDataBegin()); }bool IsValid() const { return is_valid_; }private:/*** @brief 只允许BufferPoolManager创建有效的ReadBufferGuard对象*/explicit ReadBufferGuard(std::shared_ptr<BufferHeader> buffer);private:std::shared_ptr<BufferHeader> buffer_;bool is_valid_ = false;};
} // namespace adalogWriteBufferGuard
#pragma once#include "adalog/buffer/BufferPoolManager.h"namespace adalog
{class WriteBufferGuard{friend class BufferPoolManager;public:/*** @brief 只有BufferPoolManager能够创建有效的WriteBufferGuard对象,该默认构造函数是为了外部能够预先创建一个WriteBufferGuard对象,以便跨作用域传递*/WriteBufferGuard() = default;/*** @brief 禁止拷贝构造和赋值构造*/WriteBufferGuard(const WriteBufferGuard&) = delete;WriteBufferGuard& operator=(const WriteBufferGuard&) = delete;/*** @brief 允许移动构造和移动赋值*/WriteBufferGuard(WriteBufferGuard&& other) noexcept;WriteBufferGuard& operator=(WriteBufferGuard&& other) noexcept;~WriteBufferGuard();size_t GetBufferId() const;/*** @brief 获取缓冲区中可读数据的起始地址,从该起始地址开始有ReadableSize()个字节的数据可读,超出该范围的数据不可读。* @return 缓冲区中可读数据的起始地址*/const char* GetDataBegin() const;/*** @return 从缓冲区的起始地址开始,到可读数据的末尾的字节数*/size_t ReadableSize() const;/*** @brief 重置缓冲区*/void Reset();/*** @brief 将从data开始的len字节数据追加写入缓冲区* @param data 待写入的数据的起始地址* @param len 待写入的数据的字节数。若len <= WritableSize(),则正常写入;否则,缓冲区会进行扩容以保证能够写入len个字节的数据。*/void WriteData(const char* data, size_t len);/*** @return 缓冲区的可写入字节数。*/size_t WritableSize() const;/*** @brief 将缓冲区中的数据转换为指定类型的指针,方便读取该类型的数据*/template<class T>const T* As() const { return reinterpret_cast<const T*>(GetDataBegin()); }bool IsValid() const { return is_valid_; }private:/*** @brief 只允许BufferPoolManager创建有效的WriteBufferGuard对象*/explicit WriteBufferGuard(std::shared_ptr<BufferHeader> buffer);private:std::shared_ptr<BufferHeader> buffer_;bool is_valid_ = false;std::unique_lock<std::mutex> lock_;};
} // namespace adalog线程池
线程池使用池化技术预先准备好几个线程,若有想要执行的函数我们可以交给它,它会让线程池中的线程执行这个函数。
本质上也是生产者、消费者模型。
生产者往线程池的任务队列中加任务,消费者就是在线程池中的线程,它们从任务队列中取出任务,然后执行这些任务。
这里我提供一种实现方式:
#pragma once
#include <atomic>
#include <vector>
#include <queue>
#include <memory>
#include <thread>
#include <mutex>
#include <condition_variable>
#include <future>
#include <functional>
#include <stdexcept>class ThreadPool
{
public:ThreadPool(size_t threads) // 启动部分线程: stop(false){for (size_t i = 0; i < threads; ++i){workers.emplace_back([this]{for (;;){std::function<void()> task;{std::unique_lock<std::mutex> lock(this->queue_mutex);// 等待任务队列不为空或线程池停止this->condition.wait(lock,[this]{ return this->stop || !this->tasks.empty(); });if (this->stop && this->tasks.empty())return;//取出任务task = std::move(this->tasks.front());this->tasks.pop();}task();}});}}template <class F, class... Args>auto Enqueue(F &&f, Args &&...args)-> std::future<typename std::result_of<F(Args...)>::type>{using return_type = typename std::result_of<F(Args...)>::type;// 创建一个打包任务auto task = std::make_shared<std::packaged_task<return_type()>>(std::bind(std::forward<F>(f), std::forward<Args>(args)...));std::future<return_type> res = task->get_future();{std::unique_lock<std::mutex> lock(queue_mutex);if (stop)// 如果线程池已停止,抛出异常throw std::runtime_error("enqueue on stopped ThreadPool");// 将任务添加到任务队列tasks.emplace([task](){ (*task)(); });}condition.notify_one();return res;}~ThreadPool(){{std::unique_lock<std::mutex> lock(queue_mutex);stop = true;}condition.notify_all();for (std::thread &worker : workers){worker.join();}}private:std::vector<std::thread> workers; // 线程们std::queue<std::function<void()>> tasks; // 任务队列std::mutex queue_mutex; // 任务队列的互斥锁std::condition_variable condition; // 条件变量,用于任务队列的同步std::atomic<bool> stop{false};
};线程安全的队列
每次我们要使用队列当做生产者、消费者的中间件时,都需要重写一遍类似的同步机制,我们完全可以封装一个队列,这样就不需要每次用到队列都搞一次相似的同步机制了:
#pragma once#include <condition_variable>
#include <mutex>
#include <queue>
#include <utility>namespace adalog
{template <class T>class Channel {public:Channel() = default;~Channel() = default;void Put(T element) {std::unique_lock<std::mutex> lk(m_);q_.push(std::move(element));lk.unlock();cv_.notify_all();}auto Get() -> T {std::unique_lock<std::mutex> lk(m_);cv_.wait(lk, [&]() { return !q_.empty(); });T element = std::move(q_.front());q_.pop();return element;}auto Size() -> size_t {std::unique_lock<std::mutex> lk(m_);return q_.size();}private:std::mutex m_;std::condition_variable cv_;std::queue<T> q_;};
} // namespace adalogAsyncProxyAppender
前期准备已经完毕,接下来就是使用缓冲池和线程池实现一个AsyncProxyAppender。
下图展示了AsyncProxyAppender的异步模型。
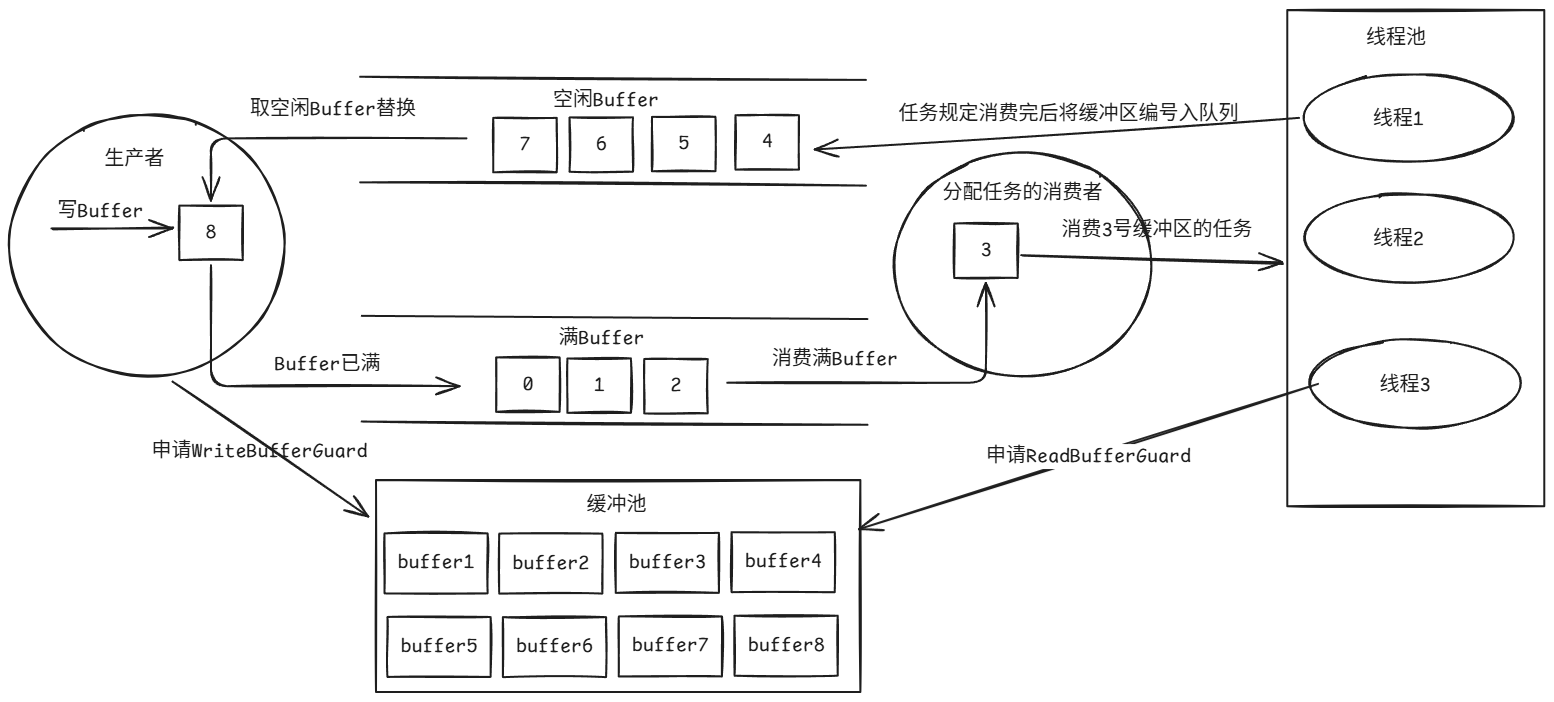
- 生产者写入数据时,会判断当前的缓冲区是否有足够的空间写入日志数据,若足够则直接写入;若不够,那么就会在空闲Buffer队列中取出空闲Buffer的编号,然后向缓冲池申请新的
WriteBufferGuard,并把已满的Buffer的编号加入到满Buffer队列中。若WriteBufferGuard非法,写入不够的操作。 - 分配任务的消费者线程,并不直接消费缓冲区,而是从满Buffer队列中取出已满缓冲区的编号,并封装一个消费该缓冲区的任务给线程池来完成。任务的具体内容为:向缓冲池申请一个读取缓冲区的
ReadBufferGuard,然后让LogAppender输出里面的内容,最后将该缓冲区的编号加入空闲Buffer的队列。
注意,你可能会想要将“分配任务的消费者线程”放在线程池中运行,这样的话线程池中的一个线程将会被长时间占用,此时你需要确保线程池中有足够的线程来消费Buffer。
我们可以发现采用了缓冲池和线程池之后,AsyncProxyAppender中减少了很多同步机制的。如果我们直接在AsyncProxyAppender中创建多个Buffer,那么AsyncProxyAppender中必然添加一些同步机制来保证Buffer的访问线程安全。
那么最终的视线是怎样的呢?
AsyncProxyAppender.h
#pragma once#include "adalog/LogAppender.h"
#include "adalog/buffer/BufferPoolManager.h"
#include "adalog/buffer/WriteBufferGuard.h"
#include "adalog/util/Channel.h"
#include "adalog/util/ThreadPool.h"
#include <list>
#include <thread>
#include <atomic>namespace adalog
{class AsyncProxyAppender : public LogAppender{public:AsyncProxyAppender(std::list<LogAppender::Ptr> appenders);~AsyncProxyAppender();void Append(const char* data, size_t len) override;private:void ConsumerThread();private:std::list<LogAppender::Ptr> appenders_;Channel<size_t> free_buffer_queue_;Channel<size_t> full_buffer_queue_;WriteBufferGuard current_buffer_;BufferPoolManager buffer_pool_;std::thread consumer_;ThreadPool thread_pool_;std::atomic<bool> stop_{false};};} // namespace adalogAsyncProxyAppender.cpp
#include "adalog/appender/AsyncProxyAppender.h"
#include "adalog/LogAppender.h"
#include "adalog/buffer/BufferPoolManager.h"
#include "adalog/Logger.h"
#include "adalog/buffer/ReadBufferGuard.h"
#include <optional>namespace adalog
{AsyncProxyAppender::AsyncProxyAppender(std::list<LogAppender::Ptr> appenders): appenders_(appenders.begin(), appenders.end()), buffer_pool_(10), thread_pool_(3), consumer_(&AsyncProxyAppender::ConsumerThread, this){for (int i = 0; i < buffer_pool_.Size(); ++i)free_buffer_queue_.Put(i);}AsyncProxyAppender::~AsyncProxyAppender() {if (current_buffer_.IsValid())full_buffer_queue_.Put(current_buffer_.GetBufferId());stop_.store(true);consumer_.join();}void AsyncProxyAppender::Append(const char* data, size_t len){if (!current_buffer_.IsValid()){size_t free_buffer_id = free_buffer_queue_.Get();auto opt = buffer_pool_.GetWriteBuffer(free_buffer_id);if (!opt.has_value())ADALOG_DEFAULT_ERROR("Can not get write buffer guard.");current_buffer_ = std::move(opt.value());}if (len > current_buffer_.WritableSize()){full_buffer_queue_.Put(current_buffer_.GetBufferId());size_t free_buffer_id = free_buffer_queue_.Get();auto opt = buffer_pool_.GetWriteBuffer(free_buffer_id);if (!opt.has_value())ADALOG_DEFAULT_ERROR("Can not get write buffer guard.");current_buffer_ = std::move(opt.value());current_buffer_.Reset();// 空闲的缓冲区若还是放不下就只能截断日志了if (len > current_buffer_.WritableSize())ADALOG_DEFAULT_ERROR("log record too long, it will be truncated.")len = std::min(current_buffer_.WritableSize(), len);}current_buffer_.WriteData(data, len);}void AsyncProxyAppender::ConsumerThread(){while(!stop_ || full_buffer_queue_.Size() != 0){size_t full_buffer_id = full_buffer_queue_.Get();std::shared_ptr<std::atomic<int>> task_undo_count = std::make_shared<std::atomic<int>>(appenders_.size());for (auto& appender : appenders_){thread_pool_.Enqueue([this, full_buffer_id, task_undo_count, appender](){auto opt = buffer_pool_.GetReadBuffer(full_buffer_id);if (!opt.has_value())ADALOG_DEFAULT_ERROR("Can not get read buffer guard.");auto read_guard = std::move(opt.value());appender->Append(read_guard.GetDataBegin(), read_guard.ReadableSize());if (task_undo_count->fetch_sub(1) == 0)free_buffer_queue_.Put(full_buffer_id);});}}}} // namespace adalog