数据同步实战篇
文章目录
- 数据同步实战篇
- 1. mysql数据同步
- 1.1 mysql集群部署
- 1.2 数据同步
- 1.2.1 同步复制
- 1.2.2 异步复制
- 1.2.3 半同步复制
- 2. redis数据同步
- 2.1 redis集群部署
- 2.2 数据同步
- 3. mq数据同步
- 3.1 mq集群部署
- 3.2 数据同步
- 4. es数据同步
- 4.1 es集群部署
- 4.2 数据同步
数据同步实战篇
- 数据作为系统运行的核心资产,数据同步则是保障数据一致性、可用性的关键纽带。无论是mysql关系型数据库的结构化数据迁移,还是redis缓存数据的高效同步;无论是mq消息队列中数据的可靠流转,亦或是es搜索引擎数据的实时更新,每一种数据同步场景都蕴涵了丰富的经验。从解决数据延迟、冲突,到保障数据完整性与实时性,不同类型的数据同步各有其道。
1. mysql数据同步
1.1 mysql集群部署
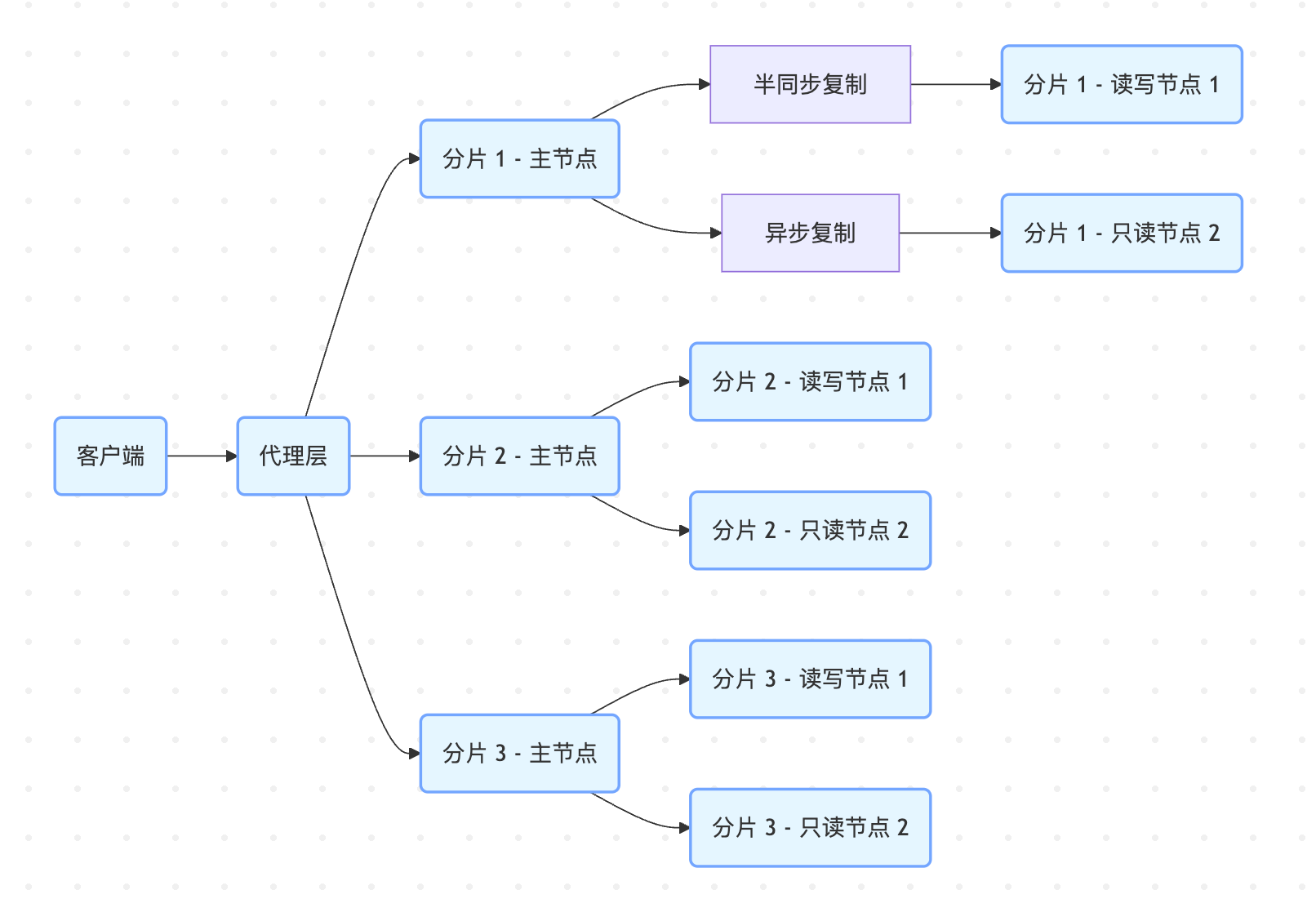
- 如上图所示,mysql集群式部署,一般采用分片库,对于不需要分片的数据表,使用其中的单个分片即可。
- 使用分片表时,根据分片字段路由到不同的分片,然后执行对应的读写逻辑。
1.2 数据同步
mysql数据同步,如上图,一般分为同步复制、半同步复制、异步复制。主要依赖于binlog,relay log。
1.2.1 同步复制
原理:在同步复制模式下,主服务器在执行完客户端提交的事务后,会等待至少一个从服务器确认已经接收并将该事务的二进制日志写入到中继日志(relay log)中,才会将结果返回给客户端。只有当从服务器确认后,主服务器才会认为事务提交成功。
优点:数据一致性高。由于主服务器会等待从服务器的确认,因此可以确保在主服务器提交事务时,至少有一个从服务器已经拥有了该事务的数据,大大降低了数据丢失的风险。
缺点:性能较低。因为主服务器需要等待从服务器的响应,这会增加事务的提交时间,尤其是在网络延迟较高的情况下,性能影响更为明显。
适用场景:对数据一致性要求极高的场景,如金融交易系统、核心业务系统等。
1.2.2 异步复制
原理:在异步复制模式下,主服务器(Master)在执行完客户端提交的事务后,会立即将结果返回给客户端,而不会等待从服务器(Slave)确认是否已经接收并处理了该事务的二进制日志(binlog)。主服务器会将二进制日志发送给从服务器,从服务器会在后台异步地接收和执行这些日志。
优点:由于主服务器不需要等待从服务器的响应,因此可以显著提高主服务器的性能,尤其是在高并发写入的场景下。
缺点:数据一致性较差。如果主服务器在从服务器还未接收或执行完二进制日志时发生故障,那么这些未同步的数据将会丢失。
适用场景:对数据实时一致性要求不高,但对性能要求较高的场景,如一些统计分析系统、日志记录系统等。
1.2.3 半同步复制
原理:半同步复制是异步复制和同步复制的折中方案。在半同步复制模式下,主服务器在执行完客户端提交的事务后,会等待至少一个从服务器确认已经接收并将该事务的二进制日志写入到中继日志中,但这个等待有一个时间限制。如果在规定的时间内没有收到从服务器的确认,主服务器会自动切换到异步复制模式,继续处理后续的事务,直到有从服务器恢复并确认接收日志后,再切换回半同步复制模式。
优点:在一定程度上保证了数据的一致性,同时也能在从服务器响应较慢时保证系统的性能。
缺点:需要额外的配置和管理,以确保时间限制的设置合理。如果时间限制设置过短,可能会频繁切换到异步复制模式,影响数据一致性;如果时间限制设置过长,可能会影响系统的性能。
适用场景:对数据一致性有一定要求,同时也需要保证一定性能的场景,如大多数企业的业务系统。
2. redis数据同步
2.1 redis集群部署
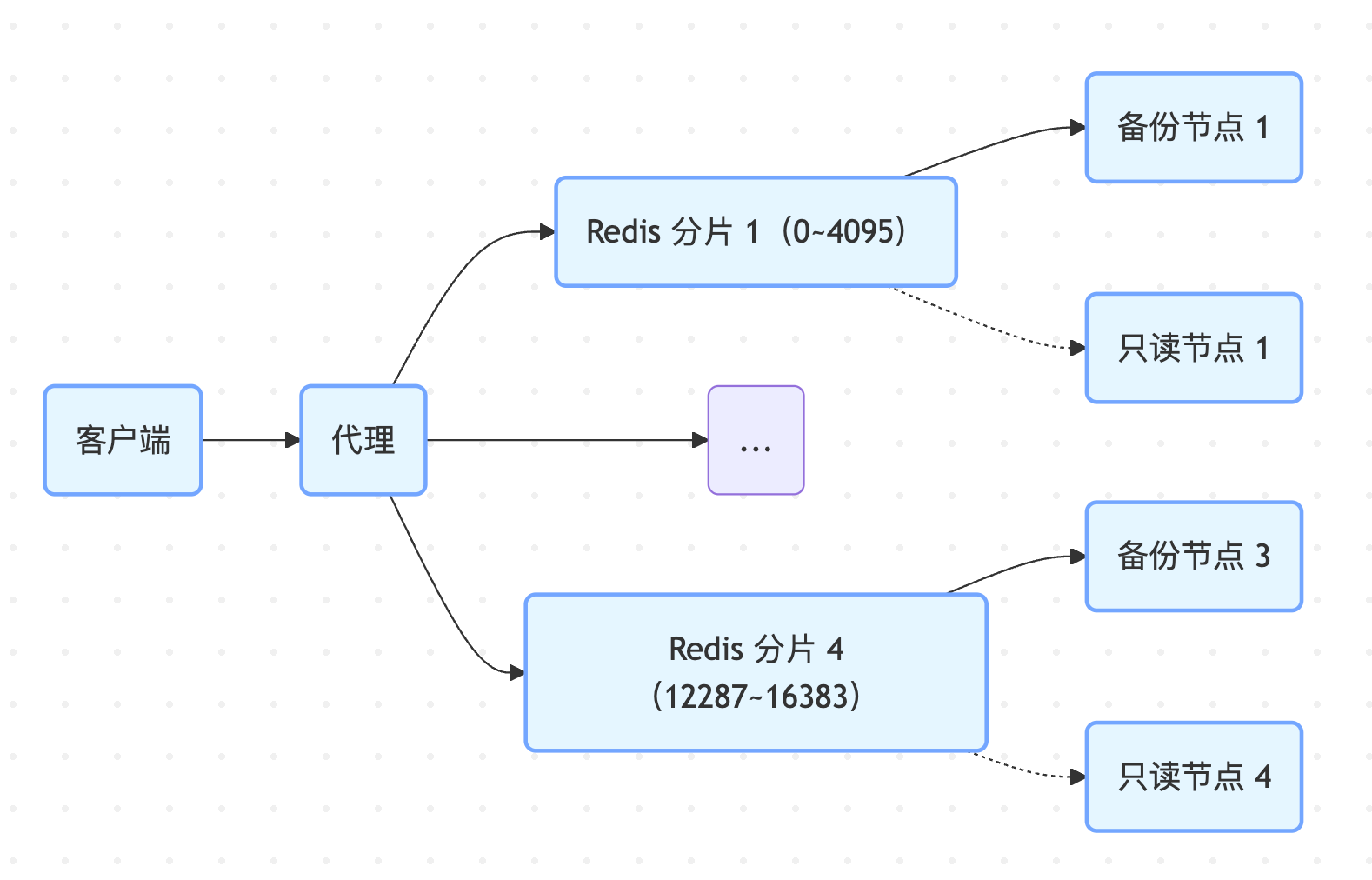
- 如上图所示redis集群一般以redis cluster方式部署,每个分片(节点)负责一部分slots。key先路由到对应的槽位,然后分发到对应的分片处理。
- 同时通过redis 哨兵来监控集群,对 Redis 主节点和从节点进行监控,在主节点出现故障时实施自动故障转移。通常会部署多个哨兵来构成一个哨兵集群,以此增强可靠性。它们相互协作,通过投票机制来决定是否进行故障转移以及选择新的主节点。
2.2 数据同步
- Redis 主从复制是一种异步复制机制。主节点(Master)负责处理写操作,从节点(Slave)则从主节点复制数据。当主节点接收到写命令时,会将这些命令记录在内存缓冲区中,并异步地将其发送给从节点。从节点接收到这些命令后,会在本地执行,从而实现数据的同步。
3. mq数据同步
3.1 mq集群部署
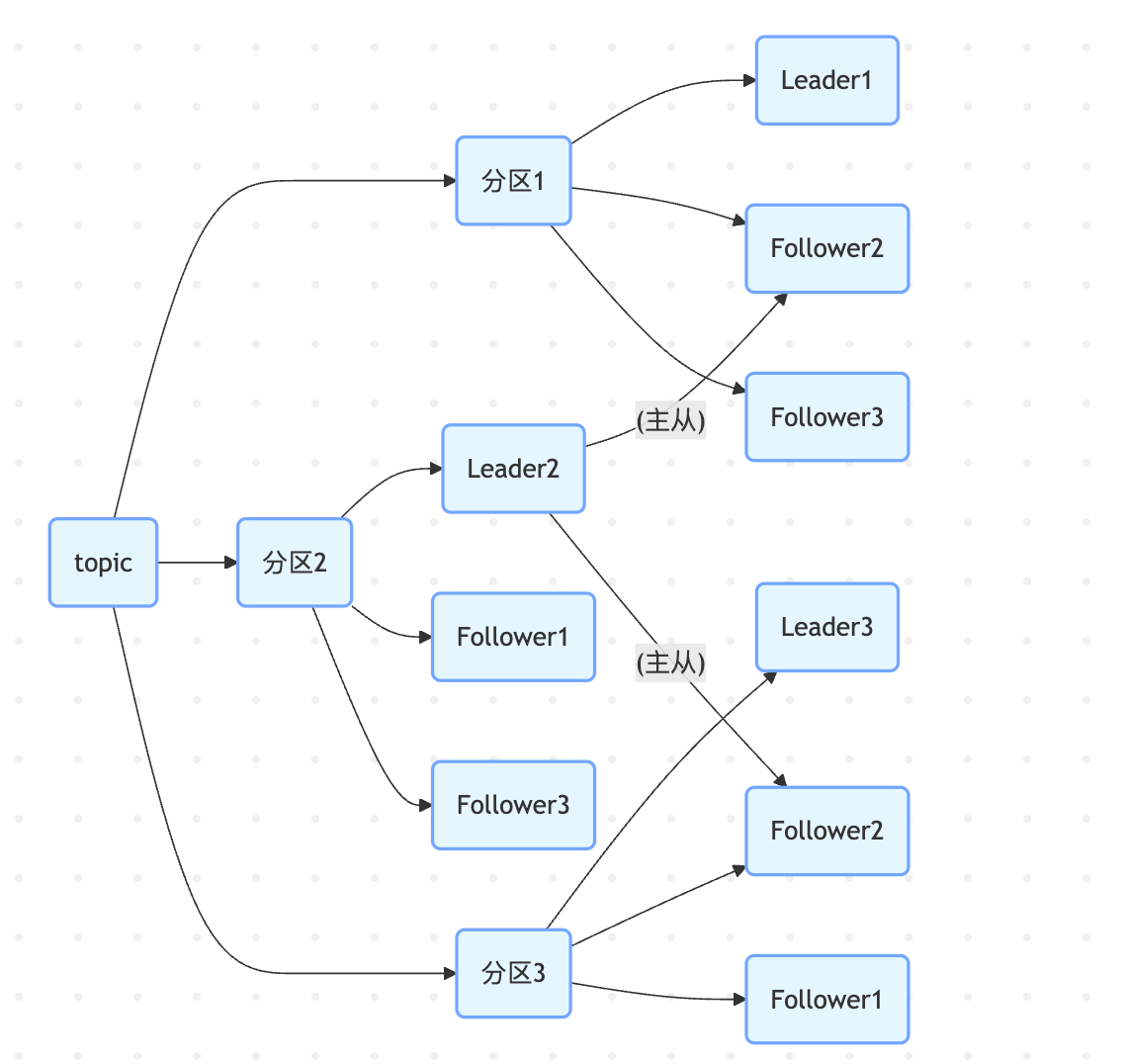
- 如上图所示,一个topic下存在多个分区,每个分区中都有自己的leader和其他分区的floower。分片 + 副本的方式保障了mq集群高可用。
3.2 数据同步
这里以kafka为例说明:
- 消息写入 Leader:生产者将消息发送到分区的 Leader 副本。Leader 接收到消息后,会将消息追加到本地的日志文件中。
- Follower 发起拉取请求:Follower 副本会定期向 Leader 副本发送 Fetch 请求,请求中包含了 Follower 当前的日志偏移量(offset),用于告知 Leader 它已经同步到了哪个位置。
- Leader 响应请求:Leader 接收到 Follower 的 Fetch 请求后,会根据 Follower 的偏移量,从本地日志中读取相应的消息,并将消息作为响应返回给 Follower。
- Follower 写入本地日志:Follower 接收到 Leader 返回的消息后,将这些消息追加到自己的本地日志中,并向 Leader 发送 ACK(确认),告知 Leader 自己已经成功同步了这些消息。
- 高水位标记:Leader 会维护一个高水位(High Watermark)标记,它表示所有副本都已经成功同步的消息偏移量。只有高水位之前的消息才被认为是已提交的消息,消费者只能消费已提交的消息。
4. es数据同步
4.1 es集群部署
4.2 数据同步
更多内容,详见:《系统频繁故障?让我来带你搭建坚不可摧的稳定性体系》
https://blog.csdn.net/for62/article/details/147673818