batch normalization和layer normalization区别
Normalization无非就是这样一个操作:
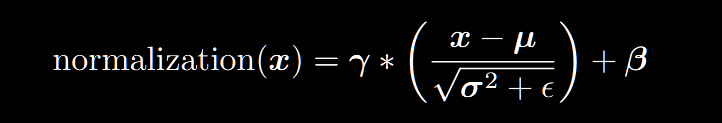
其中x是输入数据,维度为(B,T,C),其中B是batchsize,T是序列长度,C是embedding维度;括号内是标准化操作,γ和β是仿射变换参数。
BN和LN的不同,仅仅在于均值和方差的计算方式而已,下面给出计算公式:
1.Batch Normalization
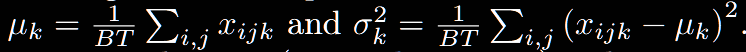
2.Layer Normalization
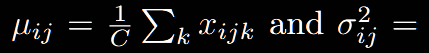
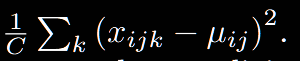
可以发现,BN是对前2个维度进行统计计算,LN是对最后一个维度进行统计计算。公式很简单,怎么理解呢?
先看LN。可以理解为:对于每个样本(batch)中的每个token,都分别统计其自身所包含的所有特征维度,作为归一化的依据。在大语言模型中,输入序列的长度通常是不固定的,因此对每个 token 单独进行归一化,是一种更合理、灵活的方式。
再来看 BN,它更常用于固定长度的序列或图像任务中。以等长序列为例,BN 的归一化是对所有 batch 中相同位置(如第一个 token、第二个 token 等)上的特征维度进行统计。因此,它统计的是同一维度在不同样本、不同 token 上的分布。由于序列长度一致,数据结构规整,就不需要像 LN 那样对每个 token 单独归一化。
参考链接
https://arxiv.org/abs/2503.10622