ROPE(旋转位置编码)简述
十分推荐看这个UP主的视频,没有特别复杂的数学推导,但是也有一定的深度,看完相信一定会有收获,同时本Blog也可以看成对该视频的总结记录

1.旋转矩阵:
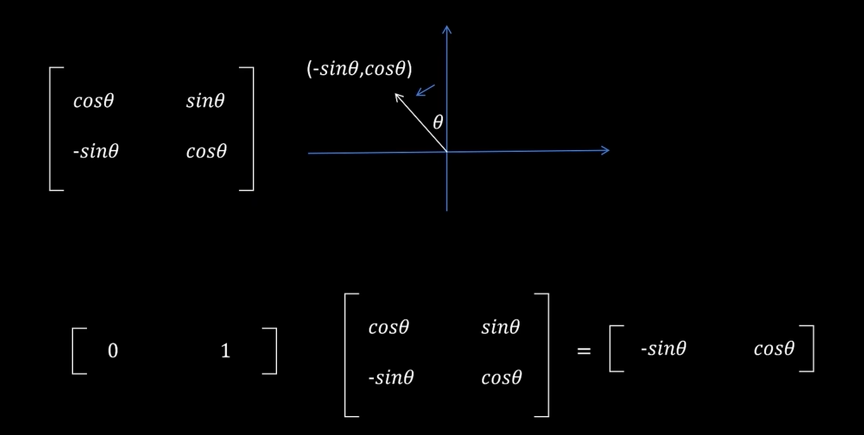
等价于将一个向量逆时针旋转度
我们规定如下记号:
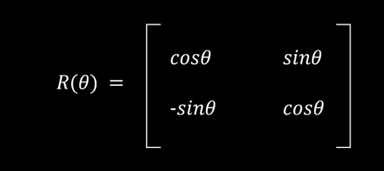
那么有下面几个性质成立:
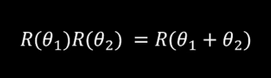
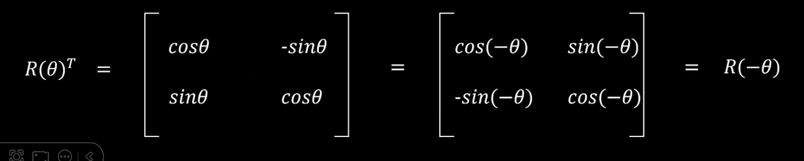
2.注意力机制:
由于我们现在考虑的都是二维情景,我们就不妨将一个词的Q,K都看成二维向量,也就是:
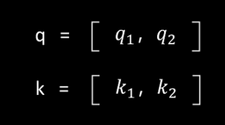
这样我们可以计算出Q,K的近似度:
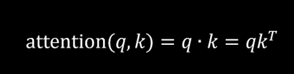
但是这个式子没有考虑位置信息,于是我们尝试把刚刚的旋转矩阵融合进来:

其中,m,n就是每个词的位置编号信息,这样我们就考虑到了这两个向量的夹角也就是相对位置信息,接下来让我们拓展成高维形式:

这里我们把一个向量的维度两个分为一组进行维度的扩升,比较直观的理解就是:
我们可以把一个d维的向量看成d//2个平面的叠加,每一个平面我们利用刚刚的旋转矩阵得到,同时注意到这个f随着维度越来越高不断减小,类似于时间的年月日,以此定义一个词的位置信息
这样我们将q,k和改矩阵相乘就添加了位置信息:

最后,考虑到该矩阵为稀疏矩阵,我们可以直接转换成如下形式:
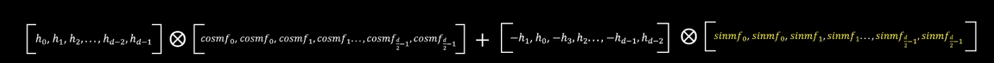
至此,ROPE的介绍就结束了
下面是代码的实现:
import torch
import torch.nn as nn
import torch.nn.functional as F
import math# %%def sinusoidal_position_embedding(batch_size, nums_head, max_len, output_dim, device):# (max_len, 1)position = torch.arange(0, max_len, dtype=torch.float).unsqueeze(-1)# (output_dim//2)ids = torch.arange(0, output_dim // 2, dtype=torch.float) # 即公式里的i, i的范围是 [0,d/2]theta = torch.pow(10000, -2 * ids / output_dim)# (max_len, output_dim//2)embeddings = position * theta # 即公式里的:pos / (10000^(2i/d))# (max_len, output_dim//2, 2)embeddings = torch.stack([torch.sin(embeddings), torch.cos(embeddings)], dim=-1)# (bs, head, max_len, output_dim//2, 2)embeddings = embeddings.repeat((batch_size, nums_head, *([1] * len(embeddings.shape)))) # 在bs维度重复,其他维度都是1不重复# (bs, head, max_len, output_dim)# reshape后就是:偶数sin, 奇数cos了embeddings = torch.reshape(embeddings, (batch_size, nums_head, max_len, output_dim))embeddings = embeddings.to(device)return embeddings# %%def RoPE(q, k):# q,k: (bs, head, max_len, output_dim)batch_size = q.shape[0]nums_head = q.shape[1]max_len = q.shape[2]output_dim = q.shape[-1]# (bs, head, max_len, output_dim)pos_emb = sinusoidal_position_embedding(batch_size, nums_head, max_len, output_dim, q.device)# cos_pos,sin_pos: (bs, head, max_len, output_dim)# 看rope公式可知,相邻cos,sin之间是相同的,所以复制一遍。如(1,2,3)变成(1,1,2,2,3,3)cos_pos = pos_emb[..., 1::2].repeat_interleave(2, dim=-1) # 将奇数列信息抽取出来也就是cos 拿出来并复制sin_pos = pos_emb[..., ::2].repeat_interleave(2, dim=-1) # 将偶数列信息抽取出来也就是sin 拿出来并复制# q,k: (bs, head, max_len, output_dim)q2 = torch.stack([-q[..., 1::2], q[..., ::2]], dim=-1)q2 = q2.reshape(q.shape) # reshape后就是正负交替了# 更新qw, *对应位置相乘q = q * cos_pos + q2 * sin_posk2 = torch.stack([-k[..., 1::2], k[..., ::2]], dim=-1)k2 = k2.reshape(k.shape)# 更新kw, *对应位置相乘k = k * cos_pos + k2 * sin_posreturn q, k# %%def attention(q, k, v, mask=None, dropout=None, use_RoPE=True):# q.shape: (bs, head, seq_len, dk)# k.shape: (bs, head, seq_len, dk)# v.shape: (bs, head, seq_len, dk)if use_RoPE:q, k = RoPE(q, k)#q,k维度不变,只是添加了位置编码d_k = k.size()[-1]att_logits = torch.matmul(q, k.transpose(-2, -1)) # (bs, head, seq_len, seq_len)att_logits /= math.sqrt(d_k)if mask is not None:att_logits = att_logits.masked_fill(mask == 0, -1e9) # mask掉为0的部分,设为无穷大att_scores = F.softmax(att_logits, dim=-1) # (bs, head, seq_len, seq_len)if dropout is not None:att_scores = dropout(att_scores)# (bs, head, seq_len, seq_len) * (bs, head, seq_len, dk) = (bs, head, seq_len, dk)return torch.matmul(att_scores, v), att_scoresif __name__ == '__main__':# (bs, head, seq_len, dk)q = torch.randn((8, 12, 10, 32))k = torch.randn((8, 12, 10, 32))v = torch.randn((8, 12, 10, 32))res, att_scores = attention(q, k, v, mask=None, dropout=None, use_RoPE=True)# (bs, head, seq_len, dk), (bs, head, seq_len, seq_len)print(res.shape, att_scores.shape)该程序实现了一个带ROPE编码的多头注意力机制,理解起来还是不困难的。下一节就是介绍如何构建deepseek用到的MLA注意力机制。