体系结构论文(八十二):A Comprehensive Analysis of Transient Errors on Systolic Arrays
研究背景与动机
-
TPU架构(Tensor Processing Unit)广泛应用于DNN推理,其核心是脉动阵列,由大量的乘加单元(MAC)组成。
-
由于使用了纳米级CMOS技术,TPU对辐射引发的瞬态错误(SET)高度敏感。
-
现有研究多关注存储器中的永久性错误,对组合逻辑中的瞬态传播关注较少。
研究方法
作者提出一种两阶段评估方法:
-
静态分析(Static Analysis):
-
利用自研工具 SETA,分析电路拓扑结构,识别最易受SET影响的节点。
-
模拟不同脉冲宽度,观察SET脉冲的传播与展宽特性。
-
在敏感触发器(FF)前加入延迟滤波器进行缓解。
-
-
动态分析(Dynamic Analysis):
-
在运行时(如执行图像卷积任务中)注入SET,评估对输出结果的影响(软错误率)。
-
分析不同数据模式(如滤波器权重)下的SET敏感性。
-
一、intro
近年来,深度神经网络(DNN)技术在多个领域的广泛应用推动了对新型硬件架构的需求,以支持其高计算负载。
TPU 是一种为 AI 推理设计的专用硬件,其核心是脉动阵列型矩阵乘法单元(MMU),以高并发乘加运算结构闻名,广泛应用于深度学习任务。
本研究聚焦于瞬态单粒子翻转(SET)对 TPU 中 MMU 的影响,这种错误由高能粒子辐射引起,在高性能计算芯片中尤为关键。
作者通过图像滤波任务评估 SET 对 MMU 功能正确性的干扰影响,揭示其在执行任务时可能引发的软错误(Soft Error)。
研究通过实验,分别进行了静态敏感性分析和动态注入评估,并发现错误影响与滤波器权重(kernel)值存在显著的数据依赖性。
1. 深度学习的计算需求推动硬件演化
DNN 在图像分类、自动驾驶、医疗等领域中快速发展,为了实现并行计算与实时响应,需要高计算能力硬件平台。
2. 传统架构的局限
传统 CPU/GPU 架构在 DNN 推理中效率受限,主要瓶颈在于频繁的中间结果读写,带来高延迟与能耗。
3. TPU的优势
TPU 专为 DNN 推理优化,核心目标是减少内存访问次数、提高乘法密集型运算性能(如矩阵乘加)。
TPU 的计算核心是脉动阵列(systolic array),由多个乘加单元(MAC)组成,支持流水线式的矩阵计算,实现高效并行处理。
4. 研究背景:SET问题
由于采用纳米级 CMOS 工艺,TPU 极易受到辐射导致的瞬态单粒子翻转(SET)影响,这是一种非永久性硬件故障,但在关键路径上可引发严重错误。
尽管已有研究关注了 SET 导致的 bit-flip 问题,但大多集中在存储器上,对组合逻辑中 SET 的传播特性和采样机制缺乏系统研究。
本文贡献点:
双阶段 SET 敏感性评估方法
-
静态评估(Static Assessment):构建电路拓扑图,识别易传播 SET 的节点。
-
动态评估(Dynamic Assessment):在运行时注入脉冲,观察是否导致实际输出错误。
非侵入式缓解策略
-
不改动架构,而是在敏感节点前加延迟电路实现 SET 过滤。
-
实验验证其有效性。
二、背景
DNN在推理阶段本质上是多个大矩阵的乘法(如输入 × 权重),对乘法运算的效率提出极高要求。
虽然GPU具备强大的通用并行计算能力,但其通用性也带来:
-
多任务支持需求,导致资源共享;
-
需要频繁地访问寄存器或共享内存,进而引起高延迟与能耗;
-
结构无法专门优化乘加运算路径。
TPU 是为 DNN 推理定制的专用硬件,加速目标清晰:
-
固定连接的脉动阵列结构避免了中间结果频繁存取;
-
每个 Processing Element(PE) 中包含一个 MAC单元(Multiply-Accumulate)。
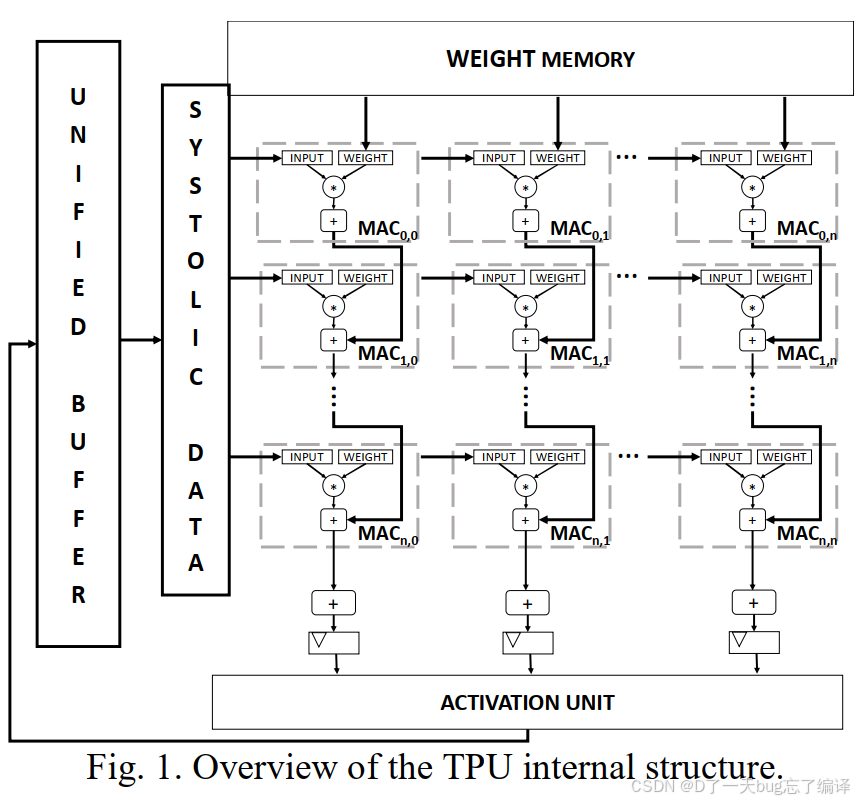
| 图中模块 | 说明 |
|---|---|
| Unified Buffer | 存储输入特征图与输出结果的共享缓存区。 |
| Systolic Data | 输入数据流横向(从左至右)传播通道。 |
| Weight Memory | 储存权重,向所有列同步广播(垂直流动)。 |
| MAC<sub>i,j</sub> 单元 | 第 i 行、第 j 列的乘加器单元:执行 input × weight + previous_sum。 |
| Activation Unit | 最后一层对累加结果进行激活函数处理(如ReLU)。 |
如图所示,PE 垂直连接:每列中上一个MAC的结果,作为下一行MAC的加法输入,实现乘加累加流。
-
横向数据流(输入):从左到右依次传入 MAC;
-
纵向数据流(权重结果):从上到下传递累加结果;
-
实现了流水线式矩阵乘法。
每个 MAC 的权重是静态不变的(称为 weight stationary 策略),只传输输入激活值。这减少了频繁的数据调入调出,优化能效。
由于DNN层的权重矩阵巨大,无法一次性映射进固定大小的脉动阵列(如 256×256)。因此需要按块切分、多轮运行(tiling),每轮的结果通过累加器(accumulator)暂存,直到全部计算完成。
三、SINGLE EVENT TRANSIENT ANALYSIS ON TPU
整体目标:
对基于 45nm 工艺实现的 TPU 脉动阵列执行 两阶段 SET 敏感性分析流程:
-
静态分析(Static Analysis):识别哪些电路节点易受 SET 干扰;
-
动态分析(Dynamic Analysis):在运行时仿真中注入脉冲,评估软错误率。
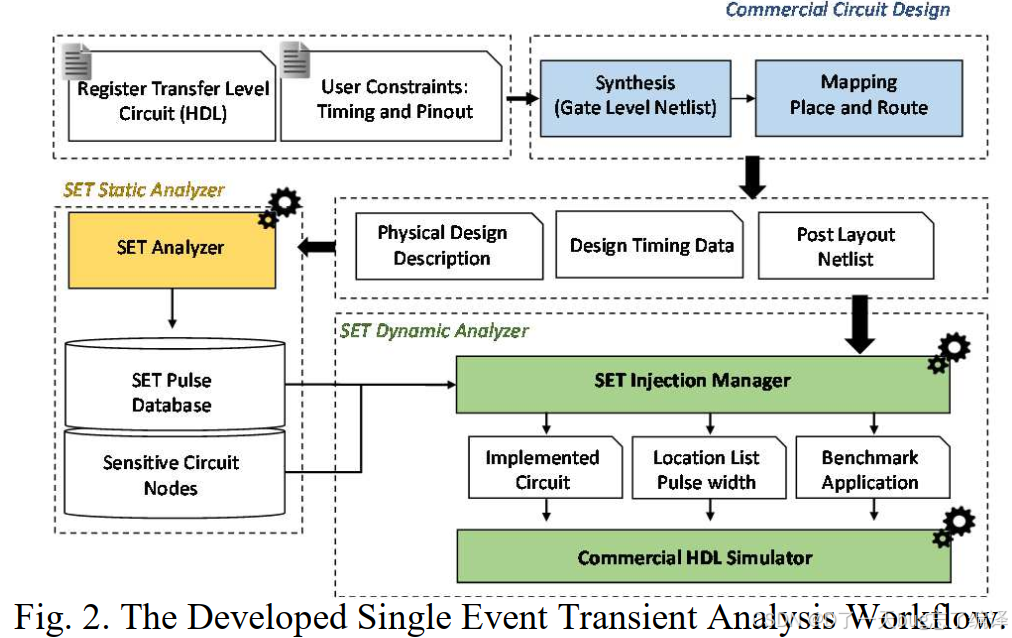
图2可分为三大模块:
1. Commercial Circuit Design 流程(上方蓝色区域)
这是常规芯片设计流程:
-
输入:HDL代码 + 时序/引脚约束
-
工艺步骤:合成、布局布线
-
输出:Post-layout Netlist + 时序数据 + 物理设计描述
这些信息将用于后续SET分析。
2. SET Static Analyzer(左侧橙色区域)
这是 静态SET敏感性分析 流程:
-
使用作者开发的 SETA 工具,以“物理设计描述(PDD)”为输入。
-
SETA 将电路建模为图结构,组合逻辑节点为中间节点,触发器/端口为终端节点。
-
工具会向每个组合逻辑节点注入SET脉冲,并模拟其传播是否可达终端节点(即是否可能采样进FF)。
-
分析中考虑脉冲传播时的展宽效应(broadening)。
-
输出:
-
SET Pulse Database(各类SET脉冲模式)
-
Sensitive Circuit Nodes(易受影响的触发器等)
-
3. SET Dynamic Analyzer(下方绿色区域)
这是 动态SET注入仿真流程:
-
使用来自静态分析的脉冲位置与宽度信息;
-
搭建运行时仿真环境,在执行实际应用(如2D卷积)过程中注入脉冲;
-
注入方式:通过强制信号为高电平一段时间来模拟SET;
-
将输出结果与“golden model”对比,检测是否发生软错误(Soft Error);
-
通过多轮仿真统计动态错误率。
输入:
-
电路的后布局网表(post-layout netlist)
-
电路的时序信息
-
电路的物理描述文件(PDD)
分析方法:
-
将组合逻辑抽象为图结构;
-
向每个中间节点注入SET;
-
模拟其传播路径,判断是否能在终端节点被采样;
-
记录 SET 被传播的脉冲宽度变化(broadening);
-
无需实际设备运行,完全基于仿真。
优势:
-
提前识别脆弱区域;
-
为后续的硬件增强或设计优化提供依据。
目的:
在真实应用执行中评估 SET 对系统的功能影响(是否导致输出错误)。
方法:
-
使用 SET Injection Manager 模块,在敏感节点注入SET;
-
应用场景如图像卷积处理;
-
通过 HDL 仿真器执行任务,收集输出;
-
输出与正确结果比对,判断软错误(soft error)是否发生。
特点:
-
不仅关注 SET 是否被采样,还考虑:
-
当前时钟周期是否使用该数据;
-
错误是否传播至最终输出;
-
电路逻辑/物理屏蔽效应对SET的过滤作用。
-
四、分析
设计选择:
-
使用了基于开源 TinyTPU 的 3x3 MAC 脉动阵列(MMU) 作为实验模型;
-
输入数据为 8-bit 整数;
-
采用 45nm FreePDK 工艺综合布局;
-
目标是以简化模型全面评估SET传播路径与关键节点。
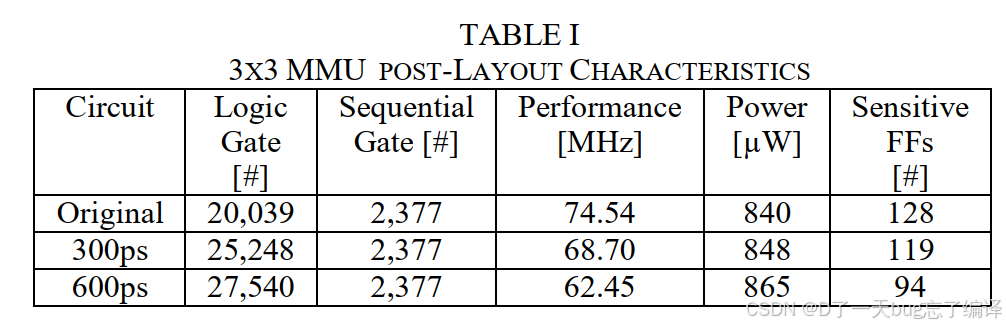
-
插入 SET 过滤延迟后,有效减少敏感触发器数量;
-
但随着延迟加深,电路性能下降(频率降低)、功耗上升、逻辑门数增加;
-
600ps方案虽然代价高,但最有效缓解SET传播。

-
对 250ps 的SET注入,平均传播宽度分别为:
-
原始电路:367ps
-
300ps延迟电路:385ps(更宽,有副作用)
-
600ps延迟电路:276ps(展宽减少,效果理想)
-
结论:
-
300ps反而导致展宽更严重,可能加剧错误采样概率;
-
600ps 延迟可同时减少敏感FF数与SET展宽效应。
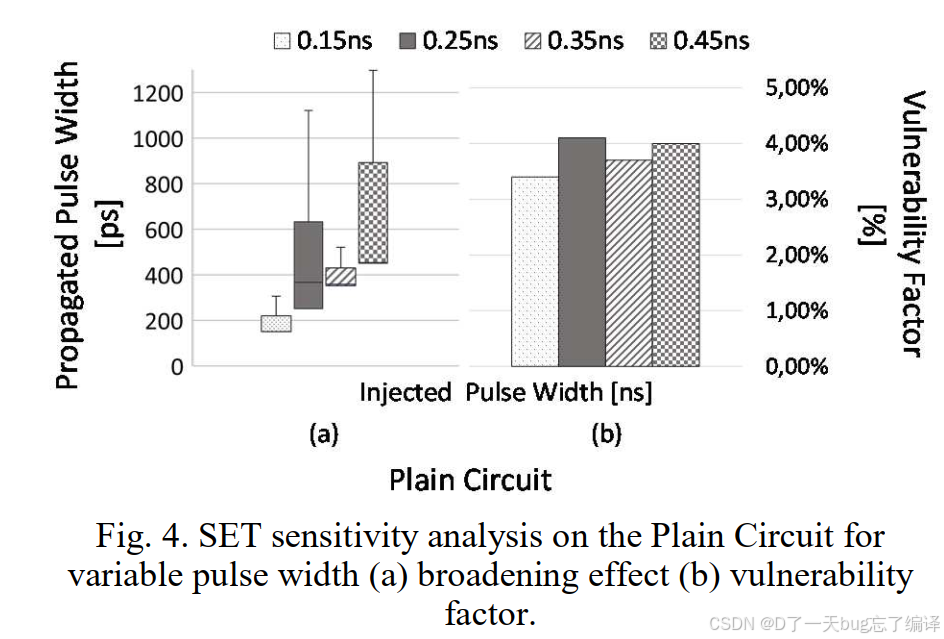
图 4(a)(b):不同脉冲宽度下的SET敏感性分析
(a) 脉冲展宽统计:
-
原始电路在注入不同宽度(150–450ps)SET下,展宽差异显著;
-
特别是 250ps 和 450ps 被电路拓扑扩展得更明显,说明电路结构对某些宽度更“敏感”。
(b) 脆弱度指标 Vulnerability Factor:
-
定义:传播成功的路径数 / 注入总数;
-
各脉冲宽度下脆弱度大致稳定在3.8%;
-
表明 SET 传播成功概率受限于拓扑结构,与脉冲宽度并不线性相关。
主要目的:在 DNN 推理过程中评估 SET(瞬态单粒子翻转)在实际任务运行下对输出结果的影响。
分析策略分两步:
-
在原始电路上注入 SET,看是否影响图像滤波任务结果(软错误);
-
对比插入 SET 过滤器(600ps 延迟)后系统的表现。

-
采用了四种经典图像滤波器作为工作负载(见 Fig. 5):
-
Edge Detection(边缘检测)
-
Sharpen(锐化)
-
Emboss(浮雕)
-
Bottom Sobel(下Sobel)
-
-
每种滤波器通过 3×3 kernel 执行卷积;
-
所有 SET 注入目标为静态分析中识别出的敏感触发器;
-
每个 FF 注入 100 次 SET,注入时间为随机但固定(控制变量);
-
SET 模拟方式为“强制某一位为高电平一段时间”。
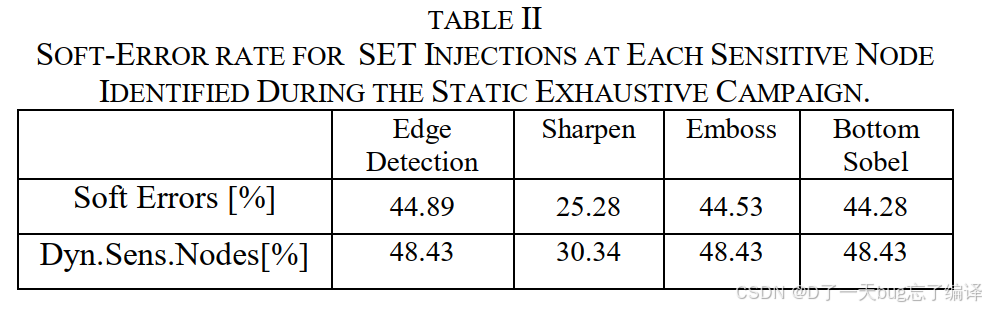
-
大多数滤波器下,约 44–45% 的注入导致软错误,敏感节点数接近一半;
-
Sharpen 滤波器异常鲁棒,软错误率显著下降(约低 20%);
-
表明:数据模式(权重矩阵)对 SET 传播有影响。

-
上图:正常结果;
-
下图:SET 被采样后输出失真,明显看出图像异常;
说明SET可能影响多个像素输出,若传播至激活单元则会“放大影响”。
-
动态仿真确认了静态分析的趋势;
-
采用延迟缓解方法后,系统在运行时的SET敏感度和软错误率均下降。
五、通过数据模式调整来实现非侵入式SET缓解
-
尽管脉动阵列的流水结构对 SET 有天然抑制能力,但关键的寄存器(特别是权重和输入寄存器)影响范围广、易引发连锁错误;
-
简单的脉冲注入就可能改变整个卷积核的作用,从而在输出图像中引入明显错误(如 Fig. 6)。
传统硬件缓解 vs 数据模式缓解
-
硬件延迟过滤器(如300ps/600ps) 能减少SET敏感性,但需要额外电路和功耗;
-
数据感知缓解(Data-aware mitigation):
-
某些权重配置(如 Sharpen filter 的稀疏交替零值)天然“阻断”SET传播;
-
图像卷积中有 0 的位置,即使输入被SET影响,也会被卷积乘 0 “抹掉”,从而阻止错误传播。
-
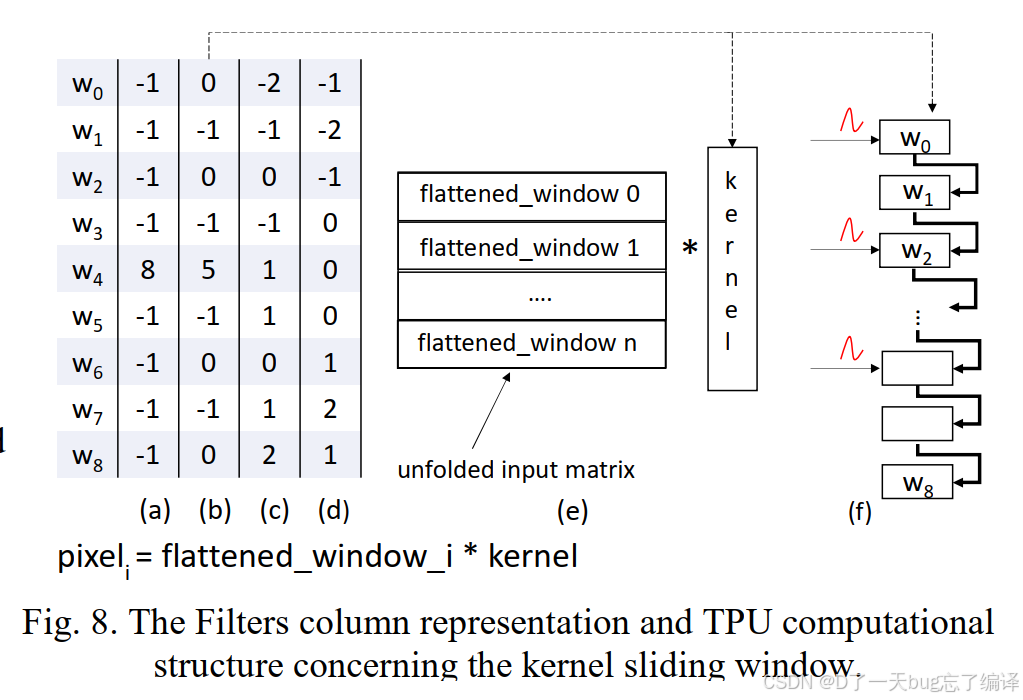
-
左侧 (a)-(d):四种卷积核展开后的列向量形式;
-
中部 (e):输入图像按滑动窗口展开为矩阵;
-
右侧 (f):每个
w_i映射到固定的 MAC 单元,采用 Weight Stationary 策略; -
所有输入与内核做点积生成像素输出
pixel_i = flattened_window_i * kernel。
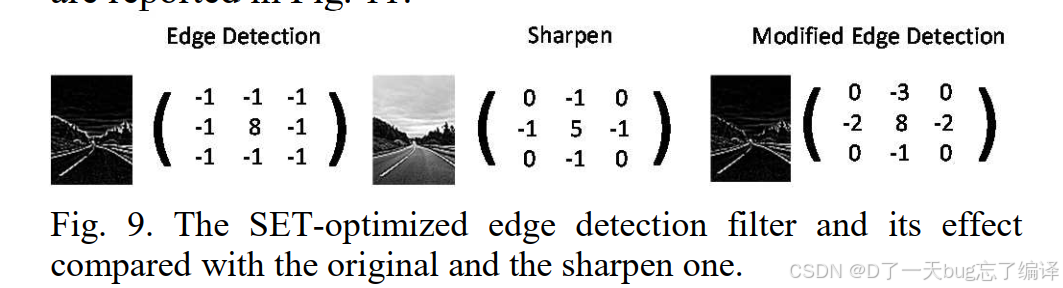
| Filter | 样例权重 | 视觉效果 |
|---|---|---|
| Edge Detection | [-1 -1 -1; -1 8 -1; -1 -1 -1] | 轮廓锐利,敏感FF多 |
| Sharpen | [0 -1 0; -1 5 -1; 0 -1 0] | 比较平衡,错误传播少 |
| Modified Edge | [0 -3 0; -2 8 -2; 0 -1 0] | 类似视觉效果,但鲁棒性大增 |

-
在自动驾驶场景中使用 Modified Edge 检测车道线(绿色) vs 原始版本(红色);
-
两者功能相近,说明新内核在功能层面有效保持精度;
-
同时为下一步注入SET测试提供真实场景保障。
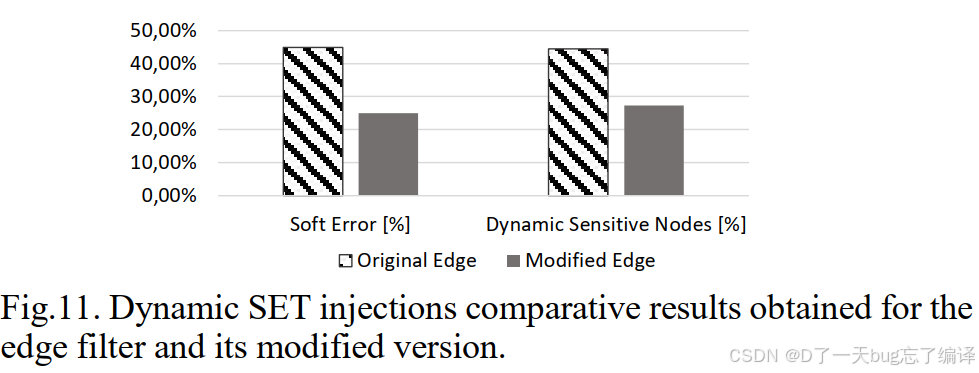
| 项目 | 原始 Edge | 修改版 Edge | 改进幅度 |
|---|---|---|---|
| Soft Error Rate | ≈45% | ≈25% | ↓约50% |
| Dynamic Sens. FFs | ≈48% | ≈28% | ↓约40% |
-
非侵入式容错设计新方向:
-
在神经网络训练前通过策略性初始化 kernel(如加入稀疏、零值交错);
-
可借助已有深度学习框架中的 weight freezing / initialization 技术实现;
-
兼顾性能与可靠性,在嵌入式/安全关键场景(如自动驾驶)极具实用价值。
-