如何让模型聪明地选择特征:一种“蒸馏及选择”的方法
引言
传统的模型如_XGBoost_或_LightGBM_在做出准确预测方面非常出色 - 但它们常常像黑匣子一样运作。这些模型通常会使用数十个(甚至上百个)特征,其中许多特征高度相关。当然,你可以查看它们的"特征重要性"排名,但这些排名可能会产生误导。例如,两个相似的特征可能都会排名很高,即使只有一个才是真正的关键。而在逻辑回归中,使用标准化系数可以有所帮助,但它仍然无法解决特征相关或存在噪声时的问题。
这就是我们想法的由来。
受大语言模型中模型蒸馏技术的启发,我们提出了一种简单而强大的方法:训练一个强大的教师模型(如_XGBoost_)来完成复杂任务,然后将其知识蒸馏到一个轻量级的学生模型 - 具体来说,是一个稀疏的逻辑回归模型。这就像从一位智者那里学习:教授知道所有细节,但学生用最简明的要点写出清晰的总结。
我们的初步实验表明,这种蒸馏模型的表现几乎和完整的教师模型一样好,同时更容易理解和解释。而且,它能自动突出最重要的特征 - 不需要依赖嘈杂的重要性排名,也不需要寄希望于标准化系数能讲述完整的故事。
这种教师-学生设置为更多灵活性打开了大门。你可以调整损失权重,尝试不同类型的教师模型,甚至将其适应到其他类型的学生模型。总的来说,这是一种将预测建模中的力量与简洁性相结合的新鲜而实用的方法。
直觉与算法机制
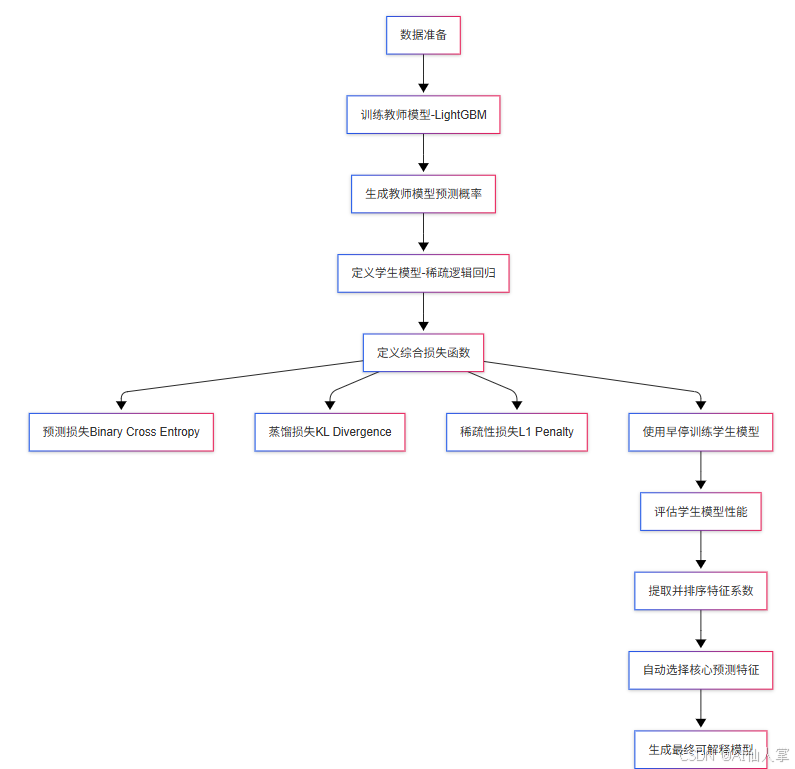
要理解我们的模型如何工作,需要逐步了解这个教师-学生蒸馏过程背后的直觉和数学公式。我们的目标是使高性能模型更容易解释,并在特征使用上更具选择性,而不牺牲预测质量。
为什么不直接使用特征重要性?
像_LightGBM_或_XGBoost_这样的流行模型通常会根据分割增益或频率报告"特征重要性"值。然而,这些分数是启发式的,并不一定反映特征的因果或预测价值,尤其是在变量相关的情况下。例如,如果"年龄"和"收入"高度相关,两个都可能显示为"重要",即使只有一个真正驱动预测。相比之下,逻辑回归使用系数大小来暗示重要性,但这些同样会在多重共线性或噪声存在时产生误导。
我们的方法通过引入模型蒸馏来"总结"复杂模型的决策边界,解决这一挑战。这种方法生成一个简单、稀疏且可解释的模型,基于特征如何影响真实决策来选择特征,而不仅仅是它们在树中被使用的频率。
教师-学生设置
这个过程从训练一个复杂的教师模型开始,比如_LightGBM_,在整个数据集上。这个教师模型学习映射:
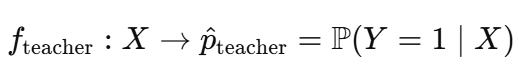
这里,_X ∈ Rd_是完整的特征集,_pteacher ∈ [0,1]_是教师预测的正类概率。期望教师表现良好,利用所有特征 - 无论是相关的还是不相关的。
接下来,我们引入一个学生模型,具体来说是一个带有_L1_正则化的逻辑回归,设计用于复制教师的行为,但使用尽可能少的特征。学生模型估计:
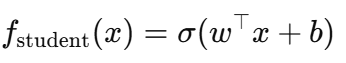
其中,_σ(z)_是sigmoid函数,_w ∈ R^d_是权重向量,_b_是偏置项。
综合损失函数
我们使用结合三个元素的综合损失函数来训练学生:
预测损失(二元交叉熵)
这确保学生从真实标签中学习:
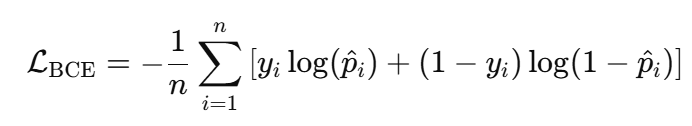
其中,
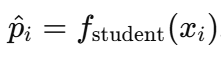
蒸馏损失(KL散度)
这鼓励学生模仿教师预测的概率:
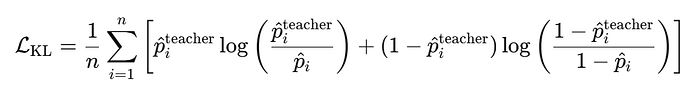
这个术语是知识蒸馏的核心:学生不只是拟合数据,而是复制更表达能力更强的教师的决策边界。
稀疏性损失(L1惩罚)
这鼓励学生保持稀疏并进行特征选择:
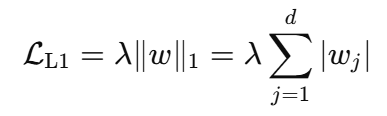
完整的优化目标变成:
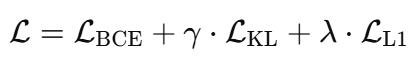
其中:
- _γ_控制学生模仿教师的程度
- _λ_控制稀疏性
这种设计在准确性和可解释性之间创造了平衡。
为什么有效
- 教师捕捉了全部信号和非线性交互。
- 学生将这些提炼成一个线性边界,只保留重要的部分。
- L1惩罚会修剪那些对学生的模仿或真实标签拟合没有贡献的特征。
与传统的特征重要性排名相比,这些排名是事后的且对相关性敏感,我们的方法进行模型内选择,直接优化性能和简洁性的组合。这就像是获得教师思维的精选摘要 - 干净、直接且可操作。
营销活动数据集演示
数据及代码:https://github.com/xrzlizheng/FeatureDistiller
为了说明Distill-to-Select框架在实践中是如何工作的,我们设计了一个模拟营销活动场景的现实但合成的数据集。目标是预测客户在收到促销优惠后是否购买,包含_125,000_条治疗组记录,包括几个通常影响购买决策的客户属性。
数据集描述
特征包括:
- 年龄:客户年龄(按年计算)。
- 收入:年收入。
- 自上次购买以来的天数:上次交易的最近性度量。
- 假日:二进制指标,表示促销是否发生在节假日期间。
- 渠道:分类变量,表示购物方式 - 在线、店内或移动。
- 忠诚度评分:客户忠诚度的连续度量。
所有特征都进行了标准化,分类变量进行了独热编码,以确保与基于树和线性模型的兼容性。
以下是代码:
import numpy as np
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.metrics import roc_auc_score, accuracy_score
from scipy.stats import ks_2samp
import lightgbm as lgb
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader, TensorDataset###########################
# 加载数据
###########################df = pd.read_csv('purchase_binary.csv')# 只使用治疗数据
df = df[df["Promo"] == 1]###########################
# 数据预处理
###########################
df_encoded = pd.get_dummies(df, columns=["Channel"], drop_first=True)
print("虚拟列:", [col for col in df_encoded.columns if "Channel_" in col])
# 例如,假设列 "Channel_Mobile" 和 "Channel_Online" 存在。
features = ["Age", "Income", "Days", "Holiday", "Loyalty", "Channel_Mobile", "Channel_Online"]
target = "Purchase"X = df_encoded[features].values.astype(np.float32)
y = df_encoded[target].values.astype(np.int64)scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)###########################
# 训练-测试拆分 (65% / 35%)
###########################
X_train, X_test, y_train, y_test = train_test_split(X_scaled, y, test_size=0.35, random_state=42, stratify=y)###########################
# 训练教师模型 (LightGBM)
###########################
teacher = lgb.LGBMClassifier(random_state=42)
teacher.fit(X_train, y_train)teacher_train_prob = teacher.predict_proba(X_train)[:, 1]
teacher_test_prob = teacher.predict_proba(X_test)[:, 1]teacher_auc = roc_auc_score(y_test, teacher_test_prob)
teacher_acc = accuracy_score(y_test, teacher.predict(X_test))
teacher_ks = ks_2samp(teacher_test_prob[y_test == 1], teacher_test_prob[y_test == 0]).statisticprint("\n教师 (LightGBM) 性能:")
print(f"AUC = {teacher_auc:.4f}, KS = {teacher_ks:.4f}, ACC = {teacher_acc:.4f}")###########################
# 定义学生模型 (逻辑回归)
###########################
class LogisticRegressionStudent(nn.Module):def __init__(self, input_dim):super(LogisticRegressionStudent, self).__init__()self.linear = nn.Linear(input_dim, 1)def forward(self, x):logit = self.linear(x)prob = torch.sigmoid(logit)return probstudent = LogisticRegressionStudent(input_dim=X_train.shape[1])###########################
# 定义综合损失函数
###########################
def kl_divergence(p_teacher, p_student, eps=1e-8):p_teacher = torch.clamp(p_teacher, eps, 1.0 - eps)p_student = torch.clamp(p_student, eps, 1.0 - eps)kl = p_teacher * torch.log(p_teacher / p_student) + (1 - p_teacher) * torch.log((1 - p_teacher) / (1 - p_student))return torch.mean(kl)# 蒸馏超参数
gamma = 1.0 # KL损失的权重
lambda_l1 = 1e-4 # L1正则化的权重###########################
# 使用早停训练学生模型 (蒸馏)
###########################
X_train_tensor = torch.from_numpy(X_train)
y_train_tensor = torch.from_numpy(y_train.reshape(-1, 1)).float()
train_dataset = TensorDataset(X_train_tensor, y_train_tensor)
train_loader = DataLoader(train_dataset, batch_size=256, shuffle=True)optimizer = optim.Adam(student.parameters(), lr=0.001)
num_epochs = 100# 用于早停
best_val_loss = float('inf')
patience = 10
best_epoch = 0
best_student_state = None# 从X_test和y_test创建验证张量
X_val_tensor = torch.from_numpy(X_test)
y_val_tensor = torch.from_numpy(y_test.reshape(-1, 1)).float()student.train()
for epoch in range(num_epochs):epoch_loss = 0.0for batch_X, batch_y in train_loader:optimizer.zero_grad()student_prob = student(batch_X) # 学生预测# 简单起见,我们使用前N个teacher_train_prob值作为这个批次batch_indices = np.arange(batch_X.shape[0])teacher_probs = torch.from_numpy(teacher_train_prob[batch_indices]).float().unsqueeze(1)# 计算BCE损失(真实标签)bce_loss = nn.BCELoss()(student_prob, batch_y)# 计算KL散度损失(蒸馏)kl_loss = kl_divergence(teacher_probs.squeeze(), student_prob.squeeze())# 计算学生权重的L1惩罚(LASSO)l1_loss = torch.norm(student.linear.weight, 1)loss = bce_loss + gamma * kl_loss + lambda_l1 * l1_lossloss.backward()optimizer.step()epoch_loss += loss.item() * batch_X.size(0)epoch_loss /= len(train_dataset)# 在测试集上评估验证损失student.eval()with torch.no_grad():val_prob = student(X_val_tensor)val_loss = nn.BCELoss()(val_prob, y_val_tensor).item()student.train()print(f"Epoch {epoch+1}/{num_epochs} - 训练损失: {epoch_loss:.4f} - 验证损失: {val_loss:.4f}")# 检查早停条件if val_loss < best_val_loss:best_val_loss = val_lossbest_epoch = epochbest_student_state = student.state_dict()elif epoch - best_epoch >= patience:print(f"在epoch {epoch+1}触发早停")break# 加载最佳模型状态
if best_student_state is not None:student.load_state_dict(best_student_state)###########################
# 在测试数据上评估学生模型
###########################
student.eval()
with torch.no_grad():X_test_tensor = torch.from_numpy(X_test)student_test_prob = student(X_test_tensor).cpu().numpy().flatten()student_pred = (student_test_prob >= 0.5).astype(int)
student_auc = roc_auc_score(y_test, student_test_prob)
student_acc = accuracy_score(y_test, student_pred)
student_ks = ks_2samp(student_test_prob[y_test == 1], student_test_prob[y_test == 0]).statisticprint("\n学生 (蒸馏逻辑回归) 性能:")
print(f"AUC = {student_auc:.4f}, KS = {student_ks:.4f}, ACC = {student_acc:.4f}")###########################
# 模型可解释性:打印系数和特征重要性
###########################
# 从学生的线性层提取权重和偏置
weights = student.linear.weight.detach().cpu().numpy().flatten()
bias = student.linear.bias.detach().cpu().numpy()[0]# 将每个特征与其系数配对并按绝对值排序
feature_importance = list(zip(features, weights))
feature_importance = sorted(feature_importance, key=lambda x: abs(x[1]), reverse=True)print("\n学生模型系数和特征重要性:")
print(f"截距 (偏置): {bias:.4f}")
for feature, coef in feature_importance:print(f"特征: {feature:20s} 系数: {coef:.4f}")# 定义特征选择的阈值(例如,绝对系数 > 0.1)
threshold = 0.1
selected_features = [feat for feat, coef in feature_importance if abs(coef) > threshold]
print("\n选定特征 (|系数| > 0.1):")
print(selected_features)
以下是结果:
教师 (LightGBM) 性能:
#######################################################
AUC = 0.7566, KS = 0.3824, ACC = 0.6948
Epoch 1/100 - 训练损失: 0.7836 - 验证损失: 0.6190
Epoch 2/100 - 训练损失: 0.7400 - 验证损失: 0.6103
Epoch 3/100 - 训练损失: 0.7382 - 验证损失: 0.6100
Epoch 4/100 - 训练损失: 0.7380 - 验证损失: 0.6083
Epoch 5/100 - 训练损失: 0.7380 - 验证损失: 0.6095
Epoch 6/100 - 训练损失: 0.7380 - 验证损失: 0.6089
Epoch 7/100 - 训练损失: 0.7383 - 验证损失: 0.6091
Epoch 8/100 - 训练损失: 0.7373 - 验证损失: 0.6084
Epoch 9/100 - 训练损失: 0.7387 - 验证损失: 0.6096
Epoch 10/100 - 训练损失: 0.7376 - 验证损失: 0.6085
Epoch 11/100 - 训练损失: 0.7378 - 验证损失: 0.6093
Epoch 12/100 - 训练损失: 0.7379 - 验证损失: 0.6088
Epoch 13/100 - 训练损失: 0.7376 - 验证损失: 0.6087
Epoch 14/100 - 训练损失: 0.7377 - 验证损失: 0.6094
在epoch 14触发早停学生 (蒸馏逻辑回归) 性能:
#######################################################
AUC = 0.7585, KS = 0.3822, ACC = 0.6846学生模型系数和特征重要性:
#######################################################
截距 (偏置): 0.2965
特征: 收入 系数: 0.4101
特征: 年龄 系数: 0.1721
特征: 节日 系数: 0.1065
特征: 天 系数: -0.0312
特征: 忠诚度 系数: -0.0076
特征: 渠道_在线 系数: -0.0051
特征: 渠道_移动 系数: 0.0024选定特征 (|系数| > 0.1):
['收入', '年龄', '节日']
解释:
- 教师模型 (***LightGBM*)**
我们首先使用所有特征训练了一个_LightGBM_分类器。正如预期的那样,该模型表现出色:
- AUC = 0.7566
- 准确率 = 0.6948
- KS统计量 = 0.3824
然而,虽然这个模型准确性高,但它依赖于所有特征 - 即使那些可能对解释或决策并不重要的特征。例如,_LightGBM_可能会给"渠道_在线"和"渠道_移动"分配重要性,因为它们与购买相关,即使只有一个对建模真正有用。特征重要性评分本身并不能提供清晰的路径来选择一个稀疏且可操作的特征集。
2. 通过蒸馏的学生模型
接下来,我们使用Distill-to-Select框架训练了一个_逻辑回归_模型作为学生。这个学生学习:
- 预测实际购买标签(真实监督),
- 模仿_LightGBM_的概率输出(蒸馏),
- 并通过_L1_正则化项消除不重要的特征(稀疏性)。
学生使用我们的综合损失进行训练:
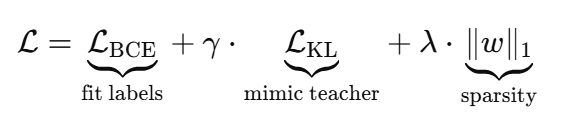
超参数_γ_和_λ_在性能和可解释性平衡方面进行了调整。训练期间,使用早停来防止在最近的验证损失上过拟合。
3. 结果和解释
蒸馏的逻辑回归模型达到了与教师相当的性能:
- AUC = 0.7585
- 准确率 = 0.6846
- KS统计量 = 0.3822
更重要的是,学生模型产生了稀疏且可解释的表示:
- 它只保留了_3-4_个有意义的特征。
- 最大的系数分配给了"收入" (0.41),“年龄” (0.17)和"节日" (0.11)。
- 像"渠道_在线"和"忠诚度"这样的特征具有可忽略不计的权重,实际上被剪枝了。
通过应用简单的系数阈值(例如,∣β_j∣>0.1),我们自动选择了核心预测特征并排除了噪声。最终的学生模型变成了一个紧凑、可读的方程,业务分析师可以轻松解释:
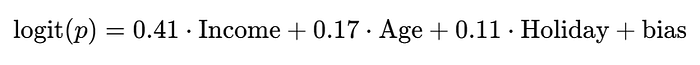
结论
Distill-to-Select方法表明,模型蒸馏不仅对简化复杂模型有用 - 它也是一种智能的特征选择方法。与传统的特征重要性评分或标准化系数不同,这种方法将特征选择构建到训练过程中本身。通过将标签准确性、教师模仿和特征稀疏性结合到一个损失函数中,得到的模型既紧凑又与高性能教师的推理一致。
更重要的是,这不仅限于_XGBoost_或逻辑回归。Distill-to-Select是一种灵活的、与模型无关的框架。教师可以是任何复杂模型 - XGBoost、深度神经网络,甚至是像_BERT_这样的_LLM_。学生可以是任何简单、可解释的模型 - 不只是逻辑回归。例如,这个框架可以扩展到_RAG_-based _LLM_系统,帮助在检索时间选择更少、更相关的文档,使流程更精简、更透明。
有很多方法可以进一步发展这个方法。我们可以探索非线性学生模型(如稀疏神经网络或浅层树),开发自适应损失权重以更好地平衡性能和简洁性,甚至实现动态蒸馏,其中学生在教师随时间演变时定期更新。
简而言之,Distill-to-Select是一种将任何黑箱模型转化为清晰、高效且可操作模型的实用配方。无论你从事医疗保健、金融、市场营销还是_NLP_,这种方法都能帮助你专注于真正重要的东西 - 而不牺牲准确性。