见多识广4:Buffer与Cache,神经网络加速器的Buffer
目录
- 前言
- 传统意义上的Buffer与Cache
- 一言以蔽之
- 定义与主要功能
- Buffer
- Cache
- 数据存储策略
- 二者对比
- 神经网络加速器的buffer
- Input Buffer
- Weight Buffer
- Output Buffer
- 与传统buffer的核心区别
- 总结
前言
知识主要由Qwen和Kimi提供,我主要做笔记。
参考文献:
https://zhuanlan.zhihu.com/p/563185831
https://blog.csdn.net/bay_Tong/article/details/108737980
写这篇笔记是因为我在神经网络加速器里面老是看到各种buffer设计,而它和传统的buffer似乎又不一样。另外,一些cache机制也弄得我有点晕。我在这里先贴一张计算机存储层级的图片:
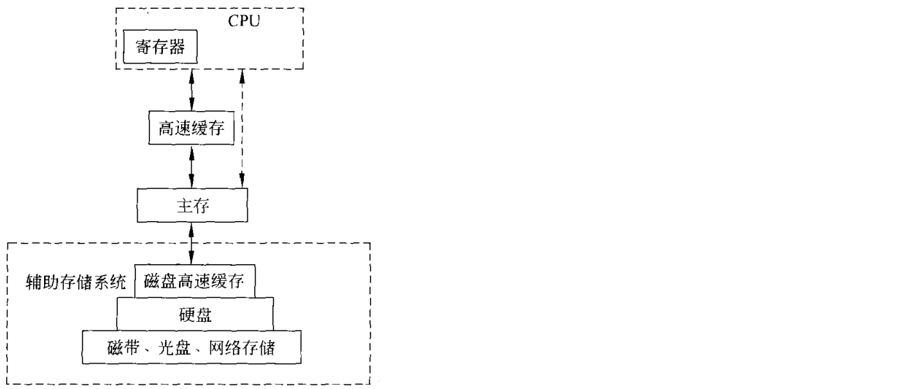
其中,高速缓存就是cache,而buffer则是在主存(也就是内存)中间开辟的一小块儿存储单元。
传统意义上的Buffer与Cache
一言以蔽之
Buffer是内存中的一块区域,可以暂存数据,匹配不同设备的速度差异,减少数据在CPU和磁盘间的读取次数。
Cache是内存和CPU寄存器之间的一块高速缓存,用来加快CPU的数据读取速度。
定义与主要功能
Buffer
缓冲区(buffer)是内存空间的一部分。也就是说,在内存空间中预留了一定的存储空间,这些存储空间用来缓冲输入或输出的数据,这部分预留的空间就叫做缓冲区。缓冲区根据其对应的是输入设备还是输出设备,分为输入缓冲区和输出缓冲区。
高速设备和低速设备的数据读取速度不匹配,这样会让高速设备花很长的时间等待低速设备,那么如果在两者之间建立一个缓冲区,会有以下好处:
(1)解决两者之间的制约关系,提高计算机的效率。比如,从CPU往磁盘中存储数据,可以让CPU存到buffer中,然后CPU就可以去做别的事情了。
(2)减少数据读写次数。如果每次数据只传输一点数据,就需要传送很多次,这样会浪费很多时间,因为开始读写与终止读写所需要的时间很长,如果将数据送往缓冲区,待缓冲区满后再进行传送会大大减少读写次数,这样就可以节省很多时间。另外,这也能够保护磁盘不轻易损坏。
Buffer分为三种类型:全缓冲,行缓冲,不带缓冲。
Cache
Cache主要用来解决CPU与内存读写速度不匹配的问题。由于CPU执行太快,内存读写速度跟不上,所以就设置了一个cache(它的读写速度和CPU几乎一样快),使得CPU需要的数据能被快速获取。
当计算机执行程序时,数据与地址管理部件会预测可能要用到的数据和指令,并将这些数据和指令预先从内存中读出送到Cache。一旦需要时,先检查Cache,若有就从Cache中读取,若无再访问内存,现在的CPU还有一级cache,二级cache。简单来说,Cache就是用来解决CPU与内存之间速度不匹配的问题,避免内存与辅助内存频繁存取数据,这样就提高了系统的执行效率。
磁盘也有cache,硬盘的cache作用就类似于CPU的cache,它解决了总线接口的高速需求和读写硬盘的矛盾以及对某些扇区的反复读取。
数据存储策略
- Buffer存储的是即将被处理或传输的数据。它通常是一个先进先出(FIFO)的队列结构,数据按照到达的顺序被存储和取出。它的数据更新通常是由外部数据源驱动的。例如,当磁盘读取数据时,数据被依次放入缓冲区,当数据被处理或传输完成后,缓冲区中的数据会被清空。
- Cache存储的是主存储器中数据的副本,通常是最近访问或频繁访问的数据。缓存的大小有限,因此需要采用一定的策略来决定哪些数据应该被存储在缓存中。常见的cache更新策略有:
(1)最近最少使用(LRU)算法:将最近最少使用的数据替换掉。
(2)先进先出(FIFO)算法:将最早进入缓存的数据替换掉。
(3)随机替换算法:随机选择缓存中的数据进行替换。
二者对比

神经网络加速器的buffer
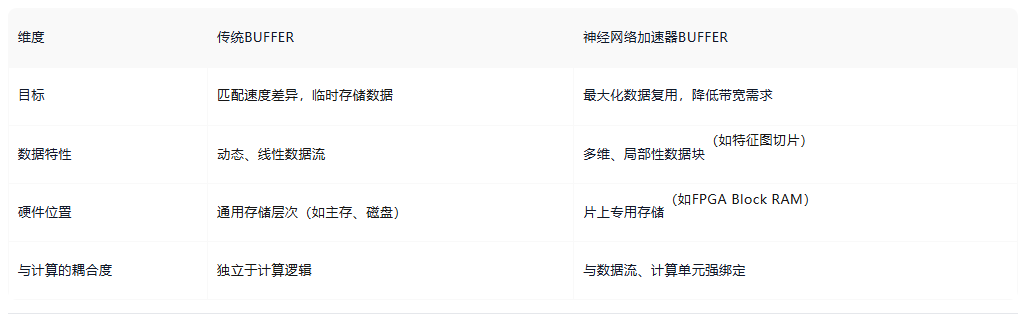
在神经网络加速器的论文中,我们经常看到各种片上buffer的设计,比如global buffer, weight buffer, input buffer, output buffer。它们的设计概念确实和传统的buffer有所不同。传统缓冲区(如操作系统或存储系统中的Buffer)主要用于 临时存储数据以匹配速度差异 (如磁盘与内存之间的数据传输),而神经网络加速器中的Buffer更注重数据复用、带宽优化和计算流水线效率提升 。以下是具体分类和理解:
Input Buffer
- 功能 :存储输入特征图(Feature Map)或激活值(Activations),供后续计算复用。
- 设计特点 :通过数据重排 (如Winograd算法中的输入转换)或分块存储 (Tiling)提高局部性,减少外部存储访问。在卷积计算中,输入特征图通常需要被多次复用(例如滑动窗口操作),Input Buffer可暂存这些数据以避免重复从外部DRAM读取。
Weight Buffer
- 功能 :缓存神经网络的权重参数(Weights),供计算单元快速访问。
- 设计特点 :权重在推理过程中是静态的(不随输入变化),因此可通过预加载 (Prefetching)到片上Buffer中减少外部访存。对于低精度网络(如二值化网络),Weight Buffer可能设计为压缩存储格式以节省带宽。
Output Buffer
- 功能:暂存卷积或全连接层的中间计算结果,最终输出到下一层或外部存储。
- 设计特点:在并行计算中,Output Buffer需支持多计算单元的结果聚合 (如多个PE的累加结果合并)。部分设计会结合流水线机制 ,在计算未完成时暂存中间结果。
与传统buffer的核心区别
总结
神经网络加速器的buffer其实和传统的buffer也有点像,也能匹配计算单元(如PE阵列)和外部存储(片外存储)之间的速度。但是,考虑到数据复用,这些buffer内部的数据可能会多次读写,与计算单元绑定关系也很强,这些和传统buffer不一样。