Stack--Queue 栈和队列
一、Stack--栈
1.1 什么是栈?
堆栈是一种容器适配器,专门设计用于在 LIFO 上下文(后进先出)中运行,其中元素仅从容器的一端插入和提取。
 第一个模版参数T:元素的类型;第二个模版参数Container:底层容器:分配器的类型。
第一个模版参数T:元素的类型;第二个模版参数Container:底层容器:分配器的类型。
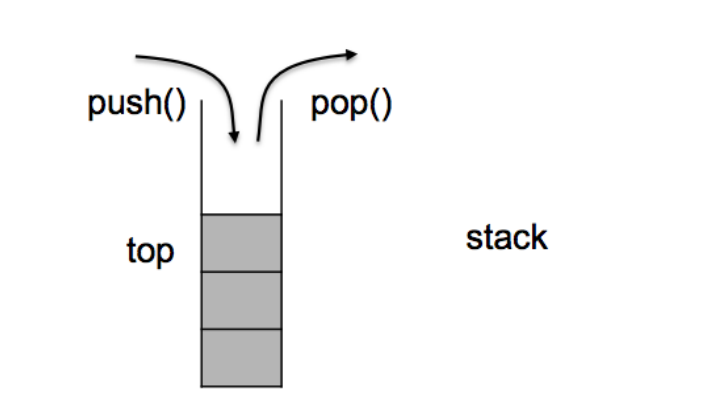
1.2 栈内部成员函数

stack():创建空的栈

empty():检测栈是否为空

如果栈为空,返回true,否则返回false。
int main()
{int sum = 0;stack<int> mystack;for (int i = 1; i <= 10; i++){mystack.push(i);}while (!mystack.empty()){sum += mystack.top();mystack.pop();}cout << sum << endl;return 0;
}size():返回stack中的元素个数

stack<int> mystack;
for (int i = 1; i <= 10; i++)
{mystack.push(i);
}
cout << mystack.size() << endl;top():返回栈顶元素的引用

stack<int> mystack;
for (int i = 1; i <= 10; i++)
{mystack.push(i);
}
cout << mystack.top() << endl;push():将元素val压入stack中

stack<int> mystack;
for (int i = 1; i <= 10; i++)
{mystack.push(i);
}
while (!mystack.empty())
{cout << mystack.top() << " ";mystack.pop();
}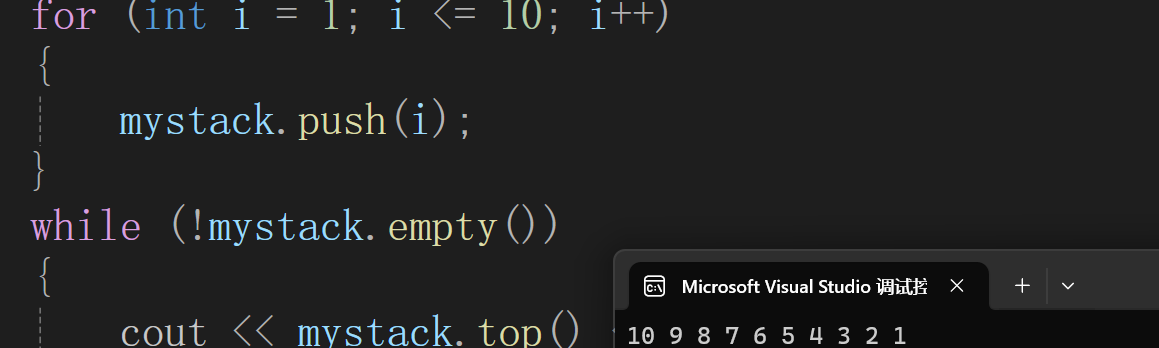 stack是一个先进后出或后进先出的模式容器,相当于倒序输出数据。
stack是一个先进后出或后进先出的模式容器,相当于倒序输出数据。
pop():将stack尾部的元素弹出

for (int i = 1; i <= 10; i++)
{mystack.push(i);
}
while (!mystack.empty())
{cout << mystack.top() << " ";mystack.pop();
}1.3 栈中题的解析
逆波兰表达式求值:
泥波兰表达式又称后缀表达式:
如:我们平时写a+b,这是中缀表达式,写成后缀表达式就是:ab+
(a+b)*c-(a+b)/e的后缀表达式为:
(a+b)*c-(a+b)/e
→((a+b)*c)((a+b)/e)-
→((a+b)c*)((a+b)e/)-
→(ab+c*)(ab+e/)-
→ab+c*ab+e/-
class Solution
{
public:int evalRPN(vector<string>& tokens) {stack<int> s;for (size_t i = 0; i < tokens.size(); i++){string& str = tokens[i];// str为数字if (!("+" == str || "-" == str || "*" == str || "/" == str)){s.push(atoi(str.c_str()));}else{// str为操作符int right = s.top();s.pop();int left = s.top();s.pop();switch (str[0]){case '+':s.push(left + right);break;case '-':s.push(left - right);break;case '*':s.push(left * right);break;case '/':// 题目说明了不存在除数为0的情况s.push(left / right);break;}}}return s.top();}
};二、Queue -- 队列
2.1 什么是队列?
1、队列是一种容器适配器,专门设计用于在 FIFO 上下文(先进先出)中运行,其中 elements入到容器的一端并从另一端提取。
2、队列作为容器适配器实现,容器适配器即将特定容器类封装作为其底层容器类,queue提供 一组特定的成员函数来访问其元素。元素从队尾入队列,从队头出队列。

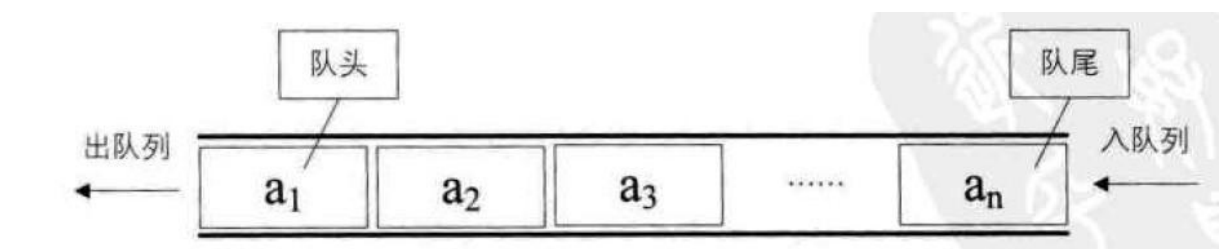
2.2 队列的使用
队列的使用函数接口与栈的类似:
queue():构造空的队列

queue<int> q1;empty(): 检测队列是否为空,是返回true,否则返回false
queue<int> myqueue1;
for (int i = 1; i <= 10; i++)
{myqueue1.push(i);
}
cout << myqueue1.empty() << endl;
queue<int> myqueue2;
cout << myqueue2.empty() << endl;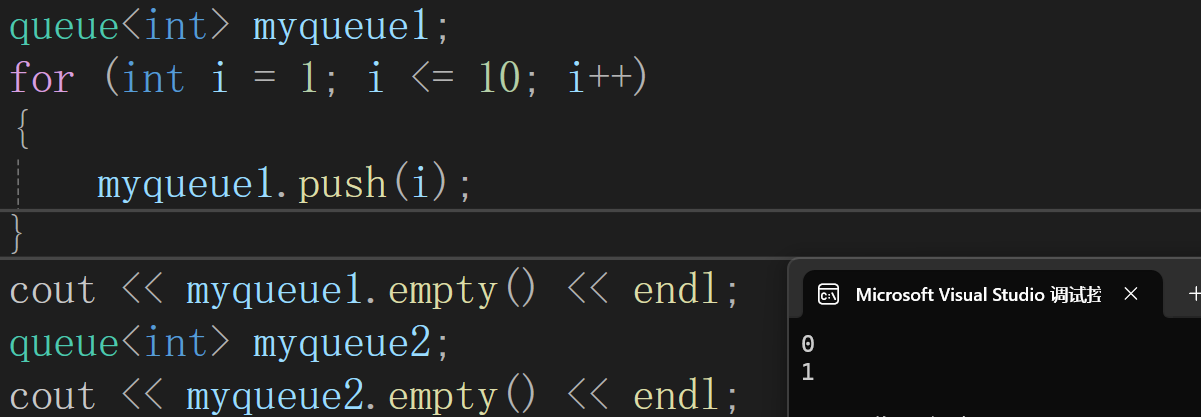
size(): 返回队列中有效元素的个数

queue<int> myqueue1;
for (int i = 1; i <= 10; i++)
{myqueue1.push(i);
}
cout << myqueue1.size() << endl;front():返回队头元素的引用

queue<int> myqueue1;
for (int i = 1; i <= 10; i++)
{myqueue1.push(i);
}
cout << myqueue1.front() << endl;back(): 返回队尾元素的引用
queue<int> myqueue1;
for (int i = 1; i <= 10; i++)
{myqueue1.push(i);
}
cout << myqueue1.back() << endl;push(): 在队尾将元素val入队列
for (int i = 1; i <= 10; i++)
{myqueue1.push(i);
}pop():将队头元素出队列

queue<int> myqueue1;
for (int i = 1; i <= 10; i++)
{myqueue1.push(i);
}
while (!myqueue1.empty())
{cout << myqueue1.front() << " ";myqueue1.pop();
}三、 priority_queue的介绍和使用
3.1 什么是优先级队列(priority_queue)?

1. 优先队列是一种容器适配器,根据严格的弱排序标准,它的第一个元素总是它所包含的元素中最大的。
2. 此上下文类似于堆,在堆中可以随时插入元素,并且只能检索最大堆元素(优先队列中位于顶 部的元素)。
3. 优先队列被实现为容器适配器,容器适配器即将特定容器类封装作为其底层容器类,queue提供一组特定的成员函数来访问其元素。元素从特定容器的“尾部”弹出,其称为优先队列的 顶部。
4. 需要支持随机访问迭代器,以便始终在内部保持堆结构。容器适配器通过在需要时自动调用 算法函数make_heap、push_heap和pop_heap来自动完成此操作。
在算法中,没有纯粹的使用queue来解题,大多需要使用优先级队列的特性。
3.2 priority_queue的使用
优先级队列默认使用vector作为其底层存储数据的容器,在vector上又使用了堆算法将vector中 元素构造成堆的结构,因此priority_queue就是堆,所有需要用到堆的位置,都可以考虑使用 priority_queue。
注意:默认情况下priority_queue是大堆。
priority_queue(): 构造一个空的优先级队列 
 (1) priority_queue 在内部将 comparing 函数和容器对象保存为 data,它们分别是 comp 和 ctnr 的副本。
(1) priority_queue 在内部将 comparing 函数和容器对象保存为 data,它们分别是 comp 和 ctnr 的副本。
(2) 位于其顶部,在 first 和 last 之间插入元素(在容器转换为堆之前)
注意:范围是左闭右开:[first,last)
empty(): 检测优先级队列是否为空,是返回true,否 则返回false

std::priority_queue<int> mypq;for (int i = 1; i <= 10; i++) mypq.push(i);while (!mypq.empty())
{cout << mypq.top() << " ";mypq.pop();
}top(): 返回优先级队列中最大(最小元素),即堆顶元素
因为在使用priority_queue时,是大根堆还是小根堆是我们自己来决定的
vector<int> v{ 3,2,7,6,0,4,1,9,8,5 };
priority_queue<int> q1;
for (auto& e : v)
{q1.push(e);
}
cout << q1.top() << endl;在priority_queue,还有第三个参数,可以使得大堆与小堆的修改:
#include <functional> // greater算法的头文件
// 如果要创建小堆,将第三个模板参数换成greater比较方式priority_queue<int, vector<int>, greater<int>> q2(v.begin(), v.end());cout << q2.top() << endl;
push(): 在优先级队列中插入元素x
vector<int> v{ 3,2,7,6,0,4,1,9,8,5 };
priority_queue<int> q1;
for (auto& e : v)
{q1.push(e);
}但push()的数据必须具有常量的性质。
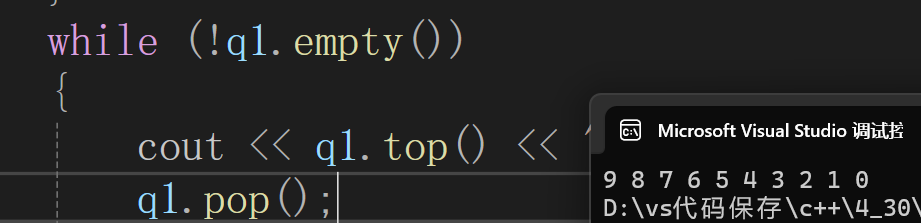
pop(): 删除优先级队列中最大(最小)元素,即堆顶元素
vector<int> v{ 3,2,7,6,0,4,1,9,8,5 };
priority_queue<int> q1;
for (auto& e : v)
{q1.push(e);
}
while (!q1.empty())
{cout << q1.top() << " ";q1.pop();
}
3.3 最具有代表性的一道题
数组中第K个大的元素
class Solution {
public:int findKthLargest(vector<int>& nums, int k) {// 将数组中的元素先放入优先级队列中priority_queue<int> p(nums.begin(), nums.end());// 将优先级队列中前k-1个元素删除掉for (int i = 0; i < k - 1; ++i){p.pop();}return p.top();}
};四、 适配器
4.1 什么是适配器?
我们之前就提到无论是stack、queue还是我们现在学习的priority_queue,它的构造函数中class Container=deque<T>


 它是什么呢?
它是什么呢?
适配器是一种设计模式(设计模式是一套被反复使用的、多数人知晓的、经过分类编目的、代码设 计经验的总结),该种模式是将一个类的接口转换成客户希望的另外一个接口。
4.2 STL标准库中stack和queue的底层结构
我之前说stack与queue是容器,这是一个错误的说法:
虽然stack和queue中也可以存放元素,但在STL中并没有将其划分在容器的行列,而是将其称为 容器适配器,这是因为stack和队列只是对其他容器的接口进行了包装,STL中stack和queue默认 使用deque。
4.2.1 duque的原理介绍
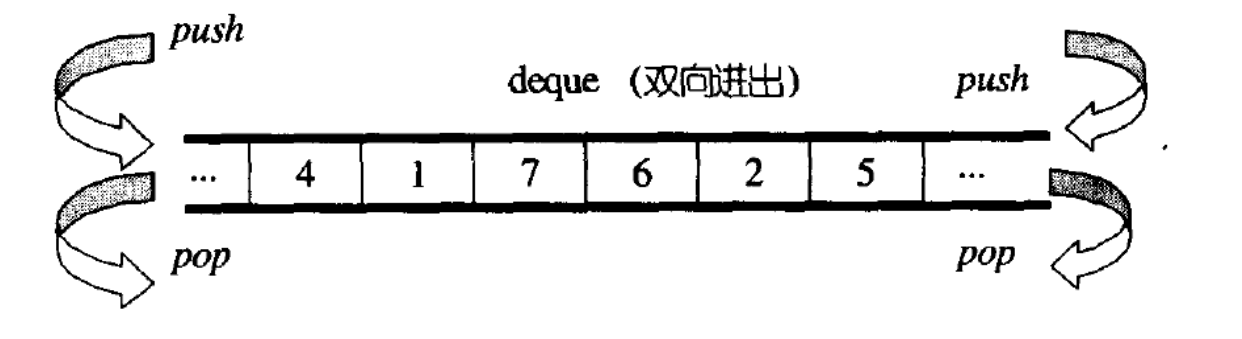
deque(双端队列):是一种双开口的"连续"空间的数据结构,双开口的含义是:可以在头尾两端 进行插入和删除操作,且时间复杂度为O(1),与vector比较,头插效率高,不需要搬移元素;与 list比较,空间利用率比较高。
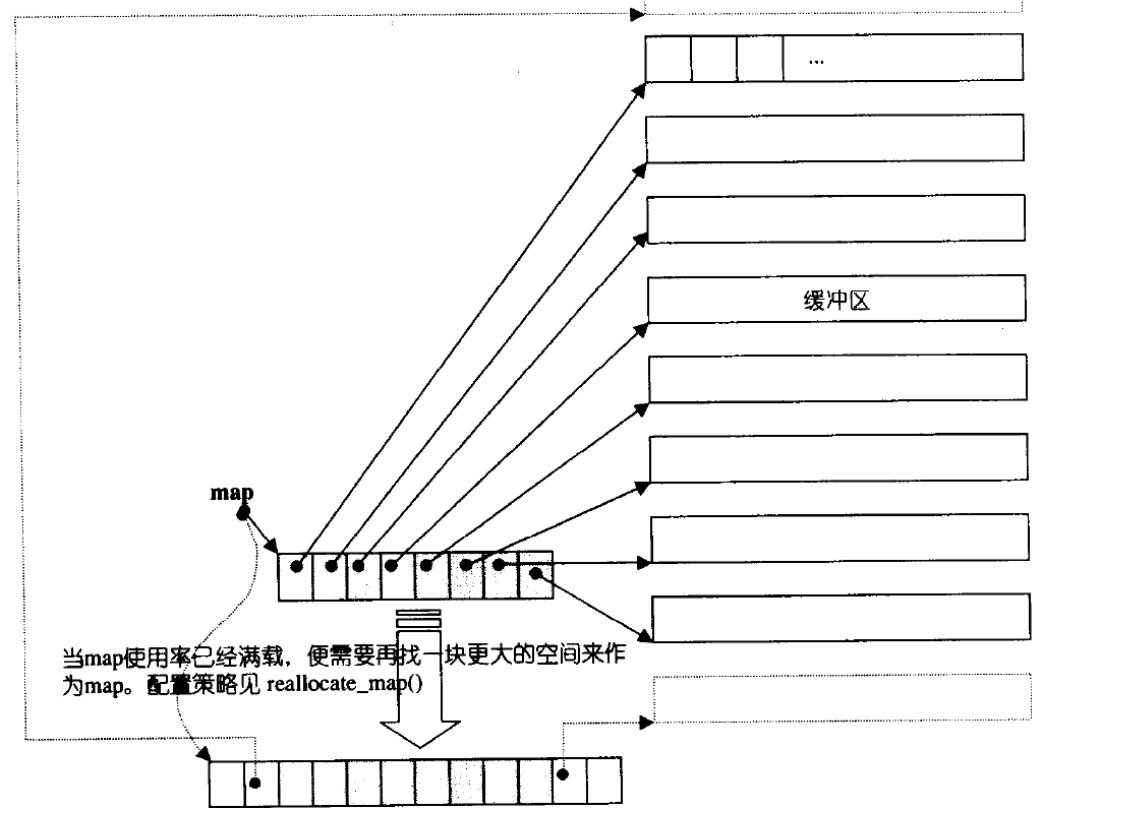
deque并不是真正连续的空间,而是由一段段连续的小空间拼接而成的,实际deque类似于一个 动态的二维数组。
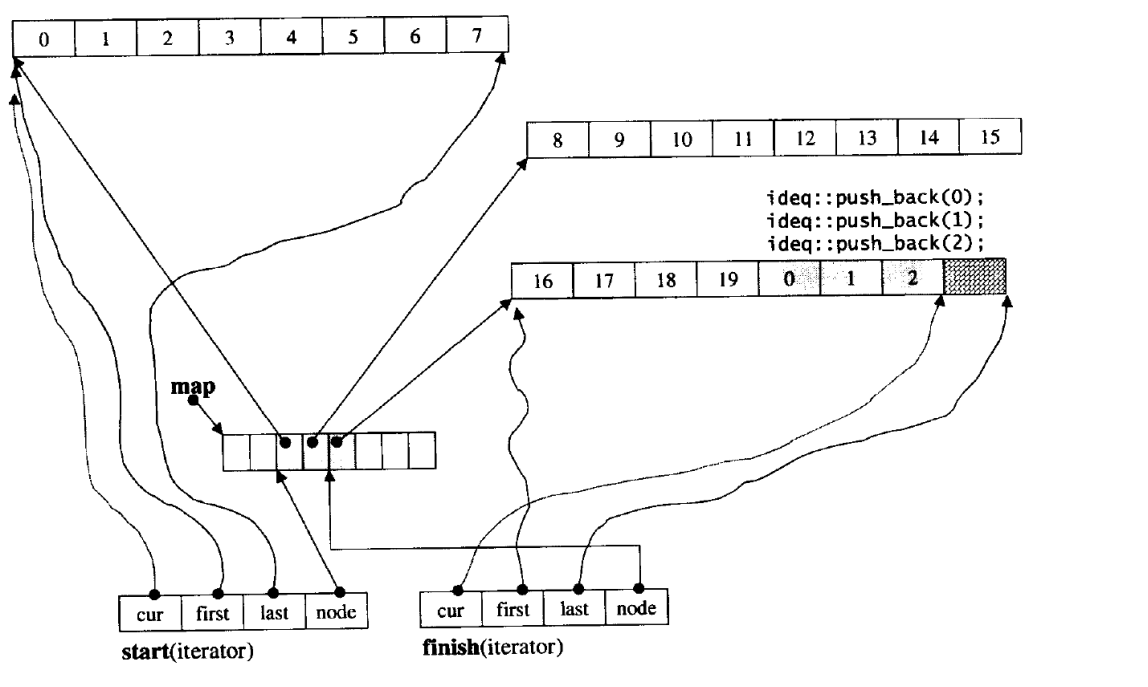
双端队列底层是一段假象的连续空间,实际是分段连续的,为了维护其“整体连续”以及随机访问 的假象,落在了deque的迭代器身上,因此deque的迭代器设计就比较复杂:
它是如何借助迭代器来维护自己开辟的空间呢?
这里它通过指针,以结构体的形式来链式链接每个节点。
4.2.2 deque的缺陷
与vector比较,deque的优势是:头部插入和删除时,不需要搬移元素,效率特别高,而且在扩 容时,也不需要搬移大量的元素,因此其效率是必vector高的。 与list比较,其底层是连续空间,空间利用率比较高,不需要存储额外字段。 但是,deque有一个致命缺陷:不适合遍历,因为在遍历时,deque的迭代器要频繁的去检测其 是否移动到某段小空间的边界,导致效率低下,而序列式场景中,可能需要经常遍历,因此在实 际中,需要线性结构时,大多数情况下优先考虑vector和list,deque的应用并不多,而目前能看 到的一个应用就是,STL用其作为stack和queue的底层数据结构。
4.3 为什么选择deque作为stack和queue的底层默认容器
stack是一种后进先出的特殊线性数据结构,因此只要具有push_back()和pop_back()操作的线性 结构,都可以作为stack的底层容器,比如vector和list都可以;queue是先进先出的特殊线性数据 结构,只要具有push_back和pop_front操作的线性结构,都可以作为queue的底层容器,比如 list。但是STL中对stack和queue默认选择deque作为其底层容器,主要是因为: 1. stack和queue不需要遍历(因此stack和queue没有迭代器),只需要在固定的一端或者两端进 行操作。 2. 在stack中元素增长时,deque比vector的效率高(扩容时不需要搬移大量数据);queue中的 元素增长时,deque不仅效率高,而且内存使用率高。 结合了deque的优点,而完美的避开了其缺陷。
那么到这里我们就学完了栈与队列最简单的认识,继续努力加油吧!!!
