论文阅读:ICLR 2021 BAG OF TRICKS FOR ADVERSARIAL TRAINING
https://arxiv.org/pdf/2010.00467
https://www.doubao.com/chat/19485126050819586
速览
这篇论文(发表在ICLR 2021会议)核心是解决一个反直觉的问题:之前很多人研究“对抗训练”(让AI模型不怕被恶意篡改的图片骗到)时,总说自己提出的新方法比老方法好,但后来发现——其实不用搞复杂方法,只要“早点停止训练”,效果就和那些新方法差不多。
作者团队觉得不对劲,就去扒了几十篇对抗训练相关论文的细节,结果发现了关键问题:不同论文里的基础训练设置(比如权重衰减、学习率调整、批量大小这些“小参数”)差别特别大,而且没人重视。比如有的论文用“权重衰减=2e-4”,有的用“5e-4”;有的生成对抗样本时用“批量归一化的训练模式”,有的用“评估模式”——这些看似不起眼的差别,居然能让模型的“抗骗能力”差出5%甚至7%,比很多新方法宣称的提升还大。
于是他们做了一件事:在CIFAR-10数据集上,把这些容易被忽略的“训练小技巧”和参数,一个个拿出来测试效果,最后总结出一套“标准基础设置”,还验证了这套设置的通用性。
下面用更通俗的话拆解关键内容:
1. 先搞懂:什么是“对抗训练”?
AI模型(比如看图识物)很容易被“骗”——比如给一张猫的图片加一点点人眼看不见的噪音,模型就会把它认成狗。这种“骗人图片”叫“对抗样本”。
“对抗训练”就是训练时故意往数据里加这些“骗人图片”,让模型提前适应,变得更“抗骗”。目前最常用的基础框架是“PGD-AT”,很多新方法都是在它上面改的。
2. 核心发现:“小参数”比“新方法”影响更大
作者对比了20多篇论文的训练设置(比如表1里列的),发现大家虽然都用“对抗训练”,但基础参数乱得很:
- 权重衰减(防止模型过拟合的参数):有人用1e-4,有人用2e-4,有人用5e-4;
- 批量大小(一次训练用多少张图):从32到512都有;
- 学习率调整:有的训练200轮,有的只训30轮;
- 甚至生成“对抗样本”时,批量归一化(BN层)用“训练模式”还是“评估模式”,都不一样。
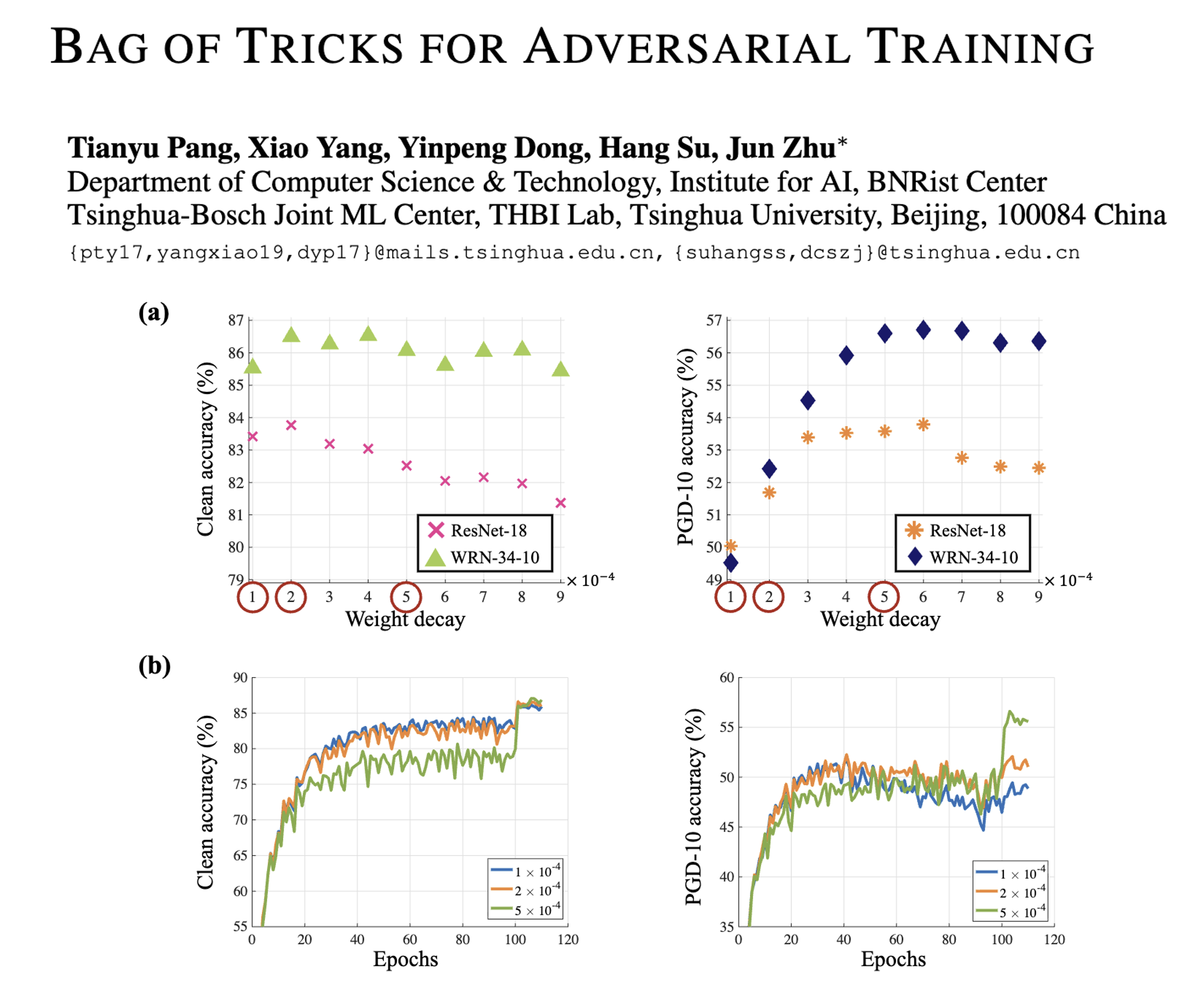
更要命的是:这些小差别对“抗骗能力”影响极大。比如权重衰减从1e-4改成5e-4,模型“抗PGD攻击”的准确率能差出7%;BN层用“评估模式”比“训练模式”,干净图片的识别准确率能高1%左右,抗骗能力还不下降。
之前很多论文说“我的新方法比老方法好”,其实可能只是他们的基础参数调得更合理,不是方法本身厉害——甚至有些真正有用的新方法,因为参数没调好,效果被低估了。
3. 哪些“小技巧/参数”真正重要?
作者做了大量实验,筛选出对“对抗训练”影响最大的几个点:
- 权重衰减:最关键!用5e-4比用1e-4/2e-4抗骗能力强很多(比如WRN-34-10模型,用5e-4时抗PGD攻击准确率56.6%,用2e-4只有52.08%);
- 标签平滑(LS):给标签加一点点“模糊”(比如把“100%是猫”改成“90%是猫,10%是其他”),能让抗骗能力提升0.5%-1%,还不影响干净图片的识别;
- 批量大小+学习率缩放:批量大小不是越大越好,CIFAR-10上128最合适;如果批量改大(比如256),要按比例把学习率也改大(比如从0.1改成0.2),不然效果会差;
- BN层模式:生成“对抗样本”时用“评估模式”,比“训练模式”更稳定,还能提高干净图片的准确率;
- 激活函数:小模型(比如ResNet-18)用“Softplus”比常用的“ReLU”抗骗能力强一点,但大模型(比如WRN-34-10)差别不大;
- 早期停止/预热:之前有人说“早点停止训练能抗过拟合”,但作者发现:只停训练轮次有用,但如果“提前停止生成对抗样本的步数”,反而会让模型更怕强攻击;学习率“预热”(刚开始慢慢升学习率)几乎没效果。
4. 他们给了一套“标准基础设置”
既然参数这么重要,作者针对CIFAR-10的“对抗训练”(PGD-AT框架),总结了一套“保底设置”,新手照着用就能出不错的效果:
- 批量大小:128;
- 优化器:SGD(带动量);
- 权重衰减:5e-4;
- 生成对抗样本时:BN层用“评估模式”;
- 不用搞学习率预热;
- 可以加一点标签平滑(0.1-0.2),小模型可以用Softplus激活函数;
- 模型选带“残差连接”的(比如ResNet、WRN),抗骗能力更强。
5. 验证:这套设置真的有用
作者用这套设置重新训练了之前很火的“TRADES”方法(原本TRADES用2e-4权重衰减),结果:
- 干净图片识别准确率提升1%;
- 抗“AutoAttack”(一种更强的攻击)的准确率提升了4%;
- 直接冲到了当时AutoAttack benchmark的榜首,比原来的TRADES强很多。
他们还测试了其他对抗训练框架(比如FastAT、FreeAT),发现这套设置同样适用——说明不是只对某一种方法有效,是通用的。
6. 最后想告诉大家什么?
这篇论文不是要提出新的对抗训练方法,而是想提醒整个领域:
- 做对抗训练时,别光顾着搞复杂的新方法,先把基础参数调对、统一;
- 以后比不同方法的效果时,必须用一样的基础设置(比如权重衰减、BN模式这些),不然比出来的结果没意义;
- 很多之前被“低估”的方法,可能只是参数没调好,重新用标准设置训一遍,效果可能会更好。