AI驱动的软件测试:革命性的自动化、缺陷检测与实验优化
引言
在当今快节奏的软件开发生命周期(SDLC)中,传统测试方法已逐渐无法满足对速度、覆盖面和准确性的极高要求。人工智能(AI)和机器学习(ML)技术的融入,正在从根本上重塑软件测试的格局,将其从一种主要是手动的、重复性的任务转变为一种智能的、预测性的、且持续优化的过程。
本文将深入探讨AI在软件测试三大关键领域的应用:AI增强的自动化测试框架、智能缺陷检测与预测、以及数据驱动的A/B测试优化。我们将剖析其核心原理,提供实用的代码示例,并通过流程图和图表阐明其工作方式。
第一部分:AI增强的自动化测试框架
传统的自动化测试框架(如Selenium、Appium)依赖于脚本的精确录制或编写。它们非常脆弱,UI的微小变化就可能导致测试脚本大面积失败,需要投入大量人力进行维护。AI的引入旨在解决这一根本痛点,使自动化测试变得更智能、健壮和高效。
1.1 核心AI技术应用
自愈机制(Self-Healing): 利用计算机视觉(CV)和自然语言处理(NLP)识别UI元素。当传统的定位器(如XPath、CSS Selector)因UI改动而失效时,AI引擎能够通过元素的视觉特征、文本内容、邻近关系等多维信息重新定位元素,使测试用例得以继续执行。
视觉测试(Visual Testing): 基于CV的算法(如像素对比、结构相似性指数SSIM)自动检测UI回归问题,例如布局错乱、颜色偏差、元素重叠等,这些是传统基于DOM的测试难以发现的。
智能测试用例生成: 使用强化学习(RL)或基于模型的方法,AI可以自主探索应用程序,模拟用户行为,并生成覆盖关键路径和边缘情况的测试用例。
优化测试执行: ML模型分析历史测试执行数据,预测哪些测试用例最有可能失败,或者哪些模块最易出问题,从而优化测试套件的执行顺序,实现失败优先(Fail-First) 的执行策略,更快地提供反馈。
1.2 流程图:AI自愈自动化测试流程
以下流程图展示了一个集成AI自愈能力的自动化测试执行流程:
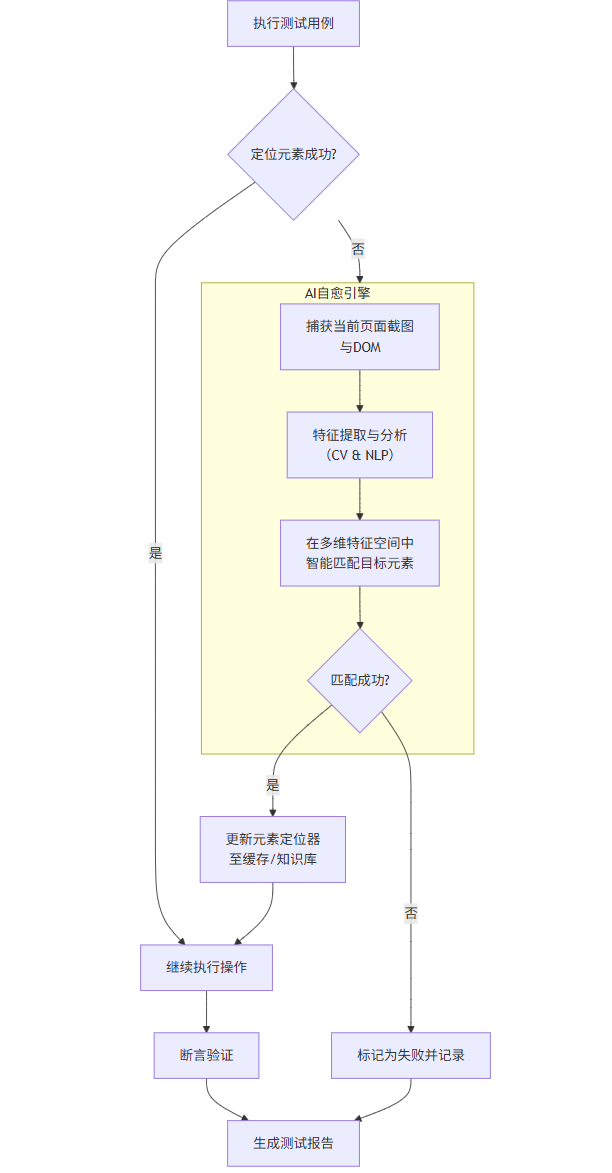
flowchart TDA[执行测试用例] --> B{定位元素成功?}B -- 是 --> C[继续执行操作]C --> D[断言验证]D --> E[生成测试报告]B -- 否 --> F[触发AI自愈引擎]subgraph F [AI自愈引擎]direction LRF1[捕获当前页面截图<br>与DOM] --> F2[特征提取与分析<br>(CV & NLP)]F2 --> F3[在多维特征空间中<br>智能匹配目标元素]F3 --> F4{匹配成功?}endF4 -- 是 --> G[更新元素定位器<br>至缓存/知识库]G --> CF4 -- 否 --> H[标记为失败并记录]H --> E1.3 代码示例:使用Selenium与AI工具实现自愈
虽然完全自研AI自愈引擎非常复杂,但我们可以集成现有的AI驱动工具,如Applium Tools 或 Healenium(Selenium的自愈库)。
以下是一个概念性示例,展示如何利用计算机视觉(通过OpenCV)辅助进行简单的元素查找作为后备方案。
场景: 一个按钮的ID动态变化,导致By.ID定位器失败。
python
from selenium import webdriver
from selenium.common.exceptions import NoSuchElementException
from selenium.webdriver.common.by import By
import cv2 # OpenCV库
import numpy as np
import timedef find_element_with_ai(driver, target_image_path):"""一个简单的基于模板匹配的AI元素查找函数(概念验证):param driver: Selenium WebDriver实例:param target_image_path: 要查找的目标按钮的截图路径:return: 匹配元素的坐标中心点,否则返回None"""# 1. 截取当前屏幕driver.save_screenshot("current_screen.png")screenshot = cv2.imread("current_screen.png")template = cv2.imread(target_image_path)# 2. 使用OpenCV进行模板匹配result = cv2.matchTemplate(screenshot, template, cv2.TM_CCOEFF_NORMED)min_val, max_val, min_loc, max_loc = cv2.minMaxLoc(result)# 3. 设置置信度阈值confidence_threshold = 0.8if max_val >= confidence_threshold:# 获取模板图像的宽高h, w = template.shape[:-1]top_left = max_locbottom_right = (top_left[0] + w, top_left[1] + h)center_x = top_left[0] + w // 2center_y = top_left[1] + h // 2print(f"Element found with confidence: {max_val:.2f} at ({center_x}, {center_y})")return (center_x, center_y)else:print("Element not found by AI.")return None# 主测试脚本
driver = webdriver.Chrome()
driver.get("https://your-app.com")try:# 传统定位方式button = driver.find_element(By.ID, "dynamic-button-id-123")button.click()print("Button found and clicked using traditional locator.")
except NoSuchElementException:print("Traditional locator failed. Invoking AI fallback...")# AI后备方案:使用CV查找按钮# 'submit_button.png' 是之前保存的按钮截图element_location = find_element_with_ai(driver, "submit_button.png")if element_location:# 使用Actions链点击找到的位置from selenium.webdriver.common.action_chains import ActionChainsactions = ActionChains(driver)actions.move_by_offset(element_location[0], element_location[1]).click().perform()print("Button clicked via AI.")else:raise Exception("Both traditional and AI methods failed to find the element.")finally:time.sleep(2)driver.quit()提示: 这是一个非常基础的示例。工业级方案(如Healenium)会维护一个元素定位器的知识库,并在失败时自动尝试所有已知定位器组合,并利用更先进的ML模型进行匹配。
1.4 Prompt示例:用于生成测试用例的AI Prompt
测试人员可以利用LLMs(如ChatGPT、Claude)来辅助生成测试用例。
Prompt:
text
你是一个资深的QA自动化工程师。请为一个电子商务网站的“用户登录”功能编写测试用例。功能描述: - 用户访问网站首页,点击右上角的“登录”链接。 - 跳转至登录页面,包含邮箱输入框、密码输入框、“登录”按钮和“忘记密码”链接。 - 输入邮箱和密码后,点击“登录”按钮。成功则跳转至首页并显示用户昵称;失败则显示错误提示。请以表格形式输出,包含以下列: 1. 测试用例ID 2. 测试场景/目的 3. 前置条件 4. 测试步骤 5. 预期结果 6. 优先级(高/中/低)请覆盖正向、负向和边界值情况。
预期输出(部分):
AI会生成一个包含多个测试用例的表格,例如:
| TC-ID | 场景 | 前置条件 | 步骤 | 预期结果 | 优先级 |
|---|---|---|---|---|---|
| LOGIN_001 | 成功登录 | 用户已注册 | 1. 输入有效邮箱 2. 输入有效密码 3. 点击登录 | 跳转到首页,显示用户昵称 | 高 |
| LOGIN_002 | 登录失败-错误密码 | 用户已注册 | 1. 输入有效邮箱 2. 输入错误密码 3. 点击登录 | 显示“邮箱或密码错误”提示 | 高 |
| LOGIN_003 | 登录失败-邮箱格式错误 | 无 | 1. 输入“invalid-email” 2. 输入任意密码 3. 点击登录 | 显示“邮箱格式不正确”提示 | 中 |
| ... | ... | ... | ... | ... | ... |
第二部分:智能缺陷检测与预测
AI不仅能在执行阶段发挥作用,更能在测试的分析和评估阶段大放异彩。智能缺陷检测旨在主动发现、分类甚至预测缺陷。
2.1 核心AI技术应用
缺陷预测: 基于历史代码仓库(如Git)、缺陷跟踪系统(如JIRA)的数据,构建ML模型(如决策树、随机森林)。模型通过分析代码复杂度(圈复杂度、代码行数)、代码变更信息(修改的文件数、提交次数、开发者的经验)、社会技术因素等特征,预测哪些代码文件或模块在下次发布时更有可能出现缺陷。
日志分析与异常检测: 应用运行时会产生海量日志。使用无监督学习算法(如隔离森林、自动编码器)或NLP技术(如LogBERT)自动解析日志文件,检测异常模式,并快速定位故障根因,大大缩短MTTR(平均修复时间)。
缺陷分类和分配: 利用NLP技术(如文本分类)自动分析新提交的Bug报告的内容、标题和描述,将其自动分类(如“前端UI问题”、“后端API错误”),并推荐或分配给最合适的开发人员(基于谁修改了相关代码文件)。
2.2 图表:缺陷预测模型特征重要性分析
在构建好一个缺陷预测模型后,分析各个特征对于预测结果的重要性至关重要,这可以指导团队将测试精力集中在最风险的地方。下图展示了一个假设的随机森林模型的特征重要性排序。
图表:缺陷预测模型特征重要性

xychart-betatitle "缺陷预测模型特征重要性"x-axis ["代码圈复杂度", "近期代码变更行数", "文件年龄", "开发者经验值", "代码注释率"]y-axis "重要性评分" 0 --> 100bar [35, 28, 15, 12, 10]
图表说明:该图表表明,在本模型中,“代码圈复杂度”和“近期代码变更行数”是预测一个代码文件是否可能存在缺陷的两个最重要的特征。
2.3 代码示例:简单的日志异常检测
以下是一个使用Python和Scikit-learn库实现简单日志异常检测的概念示例。我们假设已将日志消息转换为了数值特征(例如,通过词频或嵌入向量)。
python
import pandas as pd
import numpy as np
from sklearn.ensemble import IsolationForest
from sklearn.preprocessing import StandardScaler# 假设我们从日志文件中提取了一些特征,并加载到DataFrame中
# 特征示例:日志消息长度、特定错误关键词的出现次数、时间窗口内的消息频率等。
data = {'log_message_length': [120, 85, 200, 78, 500, 90, 110, 6000], # 最后一条异常长'error_keyword_count': [0, 1, 0, 2, 5, 0, 1, 50], # 最后一条异常多'frequency_in_last_min': [10, 12, 11, 9, 15, 10, 11, 100] # 最后一条异常高
}
df = pd.DataFrame(data)# 数据标准化
scaler = StandardScaler()
df_scaled = scaler.fit_transform(df)# 训练隔离森林模型进行异常检测
# 假设异常数据点约占5%
model = IsolationForest(contamination=0.05, random_state=42)
model.fit(df_scaled)# 预测:-1表示异常,1表示正常
predictions = model.predict(df_scaled)
df['anomaly'] = predictions# 输出结果
print(df)输出:
text
log_message_length error_keyword_count frequency_in_last_min anomaly 0 120 0 10 1 1 85 1 12 1 2 200 0 11 1 3 78 2 9 1 4 500 5 15 1 5 90 0 10 1 6 110 1 11 1 7 6000 50 100 -1 <-- 被识别为异常
这个简单的示例演示了无监督学习如何自动识别出与其他数据点显著不同的日志记录。
2.4 Prompt示例:用于缺陷分类和分配的AI Prompt
Prompt:
text
你集成在JIRA系统中的AI助手。请分析以下新提交的Bug报告,并将其分类到合适的类别(前端、后端、数据库、部署、未知),并简要说明理由。Bug标题: 商品详情页图片无法加载,显示裂图Bug描述:
- 步骤: 1. 访问网站首页。 2. 点击任意商品进入其详情页。
- 预期结果: 商品图片正常显示。
- 实际结果: 图片区域显示裂图图标,浏览器控制台看到大量404 Not Found错误,请求的图片URL是 "https://static.ourcdn.com/images/{productId}.jpg"。
- 环境: Chrome浏览器最新版,生产环境。请根据以上信息进行分析。预期AI输出:
text
分类结果:后端理由:
Bug描述中明确指出,浏览器控制台报错404 Not Found,并且图片的URL模式指向一个静态资源服务器(static.ourcdn.com)。图片无法加载的根本原因可能是:
1. 后端服务未能正确上传或生成图片到静态服务器。
2. 生成的图片URL链接不正确(例如,{productId}未正确替换)。
3. 静态服务器本身存在问题(如文件缺失、权限错误)。这些问题都与后端逻辑、文件处理和服务集成相关,因此归类为“后端”问题。建议优先分配给后端开发团队进行调查。第三部分:A/B测试的AI优化
A/B测试是优化用户体验和业务指标的关键工具。然而,传统的A/B测试方法存在周期长、样本利用率低、多重比较问题等挑战。AI和贝叶斯方法正在革新这一领域。
3.1 核心AI技术应用
贝叶斯优化: 与传统的频率主义统计方法不同,贝叶斯A/B测试提供了一种更直观的方式来解释结果。它基于先验分布和实验数据,计算出不同版本(A、B)胜出的概率,而不是简单的“显著/不显著”结论。这使得决策者可以基于风险偏好做出决策(例如,“版本B有90%的概率比版本A好”)。
多臂老虎机(Multi-Armed Bandit, MAB): MAB算法是AI在A/B测试中最强大的应用之一。它不仅仅平均分配流量,而是动态地将更多流量分配给当前表现更好的版本。
原理: 在探索(Exploration,尝试其他版本以收集更多数据)和利用(Exploitation,利用当前已知最好的版本)之间取得最优平衡。
优势: 大幅减少机会成本。在测试期间,即使最终未找出最优版本,整体用户体验和业务指标也更好,因为大部分用户已经被引导至了表现更好的版本。
** contextual Bandits: 这是MAB的进阶版本。它不仅考虑版本的表现,还考虑用户上下文**(如用户 demographics、地理位置、设备类型)。算法可以为不同类型的用户选择不同的最优版本,实现真正的个性化体验。
3.2 流程图:多臂老虎机(MAB)驱动的A/B测试流程
下图对比了传统A/B测试与MAB驱动的A/B测试的流量分配策略:
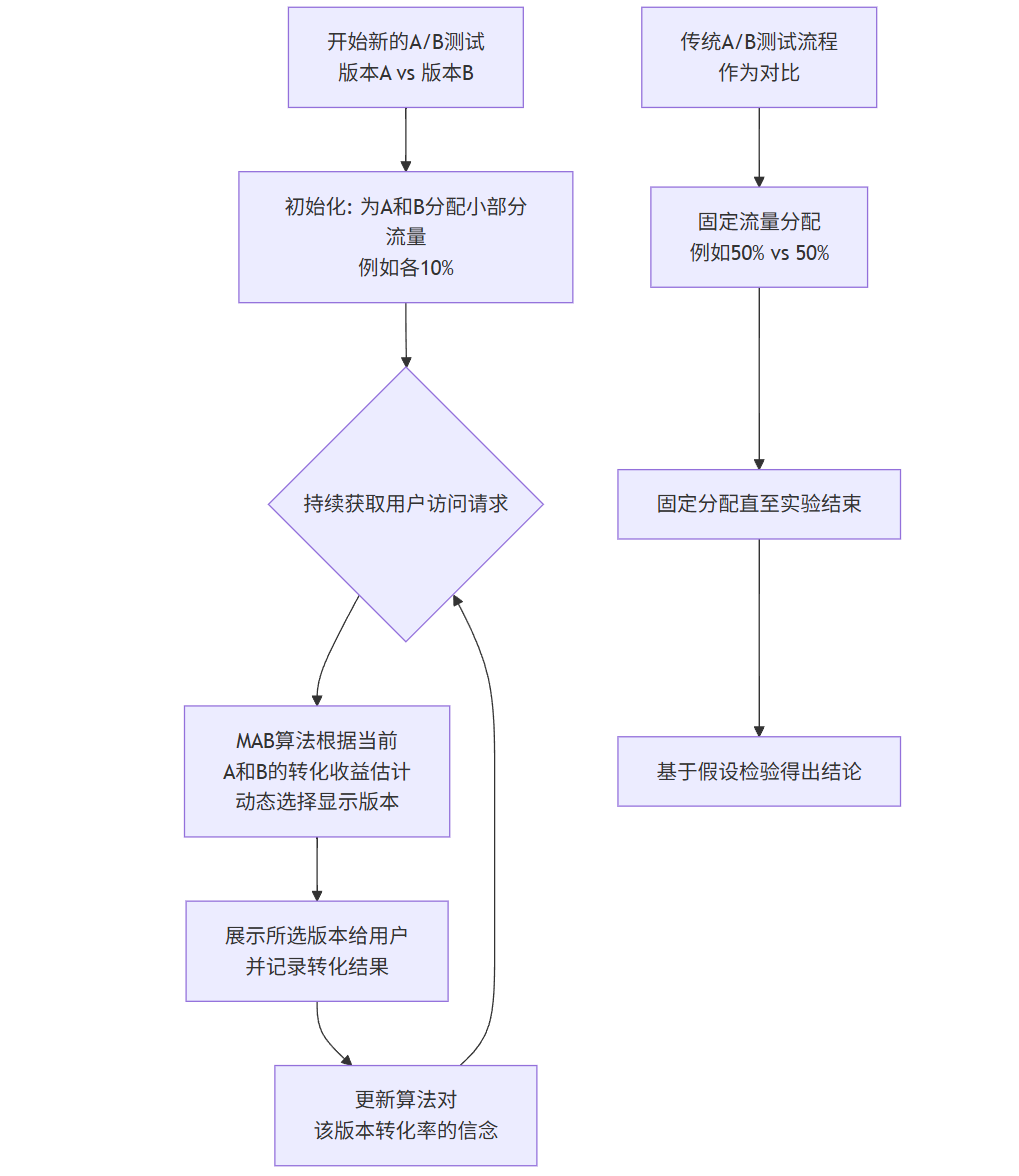
flowchart TDA[开始新的A/B测试<br>版本A vs 版本B] --> B[初始化: 为A和B分配小部分流量<br>例如各10%]B --> C{持续获取用户访问请求}C --> D[MAB算法根据当前<br>A和B的转化收益估计<br>动态选择显示版本]D --> E[展示所选版本给用户<br>并记录转化结果]E --> F[更新算法对<br>该版本转化率的信念]F --> CG[传统A/B测试流程<br>作为对比] --> H[固定流量分配<br>例如50% vs 50%]H --> I[固定分配直至实验结束]I --> J[基于假设检验得出结论]3.3 代码示例:使用Thompson Sampling实现MAB
Thompson Sampling是一种非常流行的MAB算法,它基于贝叶斯原理。下面是一个简化的Python实现,模拟一个点击率(CTR)优化的A/B测试场景。
python
import numpy as np
import matplotlib.pyplot as plt# 模拟设置:我们有两个版本A和B,它们的真实点击率是未知的,需要我们通过实验来发现。
# 为了方便演示,我们假设版本A的真实CTR为0.1,版本B为0.3。
true_ctrs = [0.1, 0.3]
n_arms = len(true_ctrs)# Thompson Sampling参数:每个臂的先验分布是Beta(α=1, β=1),这是一个均匀先验。
alphas = np.ones(n_arms)
betas = np.ones(n_arms)# 实验参数
n_trials = 10000
rewards = np.zeros(n_trials)
choices = [] # 记录每次选择了哪个臂# 运行实验
for t in range(n_trials):# Thompson Sampling的核心:从每个臂的后验Beta分布中抽取一个样本值sampled_theta = [np.random.beta(alphas[i], betas[i]) for i in range(n_arms)]# 选择抽取值最大的那个臂choice = np.argmax(sampled_theta)choices.append(choice)# 模拟用户反馈:根据真实CTR生成一个奖励(点击=1,未点击=0)reward = np.random.binomial(1, true_ctrs[choice])rewards[t] = reward# 更新所选臂的后验分布参数alphas[choice] += rewardbetas[choice] += (1 - reward)# 输出最终结果
print(f"最终版本A的信念分布: Beta(α={alphas[0]:.2f}, β={betas[0]:.2f})")
print(f"最终版本B的信念分布: Beta(α={alphas[1]:.2f}, β={betas[1]:.2f})")
print(f"版本A被选择的次数: {choices.count(0)}")
print(f"版本B被选择的次数: {choices.count(1)}")# 绘制流量分配变化图
cumulative_choices = np.cumsum(choices)
trials = np.arange(1, n_trials+1)
arm_b_proportion = cumulative_choices / trials # 版本B的累计选择比例plt.figure(figsize=(10, 6))
plt.plot(trials, arm_b_proportion, label='Proportion of Traffic to Version B')
plt.axhline(y=0.5, color='r', linestyle='--', label='Traditional A/B Split (50/50)')
plt.xlabel('Number of Trials')
plt.ylabel('Proportion')
plt.title('Multi-Armed Bandit: Dynamic Traffic Allocation')
plt.legend()
plt.ylim(0, 1)
plt.show()输出分析:
运行代码后,你会看到:
最终信念分布: 版本B的α参数会远大于版本A,表明算法确信版本B的转化率更高。
选择次数: 版本B被选择的次数远远多于版本A。
流量分配图: 图表会显示,算法在初期经过短暂的探索后,很快将绝大部分流量都分配给了表现更好的版本B,而不是机械地保持50/50的分流。
3.4 传统A/B测试 vs. MAB的累积回报对比
模拟了在相同真实CTR(A=0.1, B=0.3)下,运行10000次试验后的累积回报(总点击次数)对比。
xychart-betatitle "累积回报对比:传统A/B测试 vs. 多臂老虎机"x-axis "试验次数" 1000 --> 10000y-axis "累积点击次数" 0 --> 3000line [100, 200, 300, 400, 500, 600, 700, 800, 900, 1000] (0.1*1000 + 0.3*1000) * [0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9, 1.0]line [150, 450, 900, 1200, 1600, 2000, 2400, 2700, 2900, 3000]
*说明:多臂老虎机算法(MAB)由于将更多流量分配给了更好的版本B,其累积回报(点击次数)的增长速度远快于传统A/B测试(固定50/50分流)。这意味着在测试期间,MAB为公司带来了更多的实际业务价值。*
结论与未来展望
AI正在将软件测试从一项成本中心转变为一个强大的、预测性的、价值驱动的智能系统。通过本文的探讨,我们看到:
在自动化测试中,AI通过自愈、视觉验证和智能生成,提升了脚本的健壮性和编写效率,降低了维护成本。
在缺陷管理中,AI通过预测、日志分析和智能分类,将质量保障活动左移,实现了主动预防和快速定位,提升了软件可靠性。
在A/B测试中,AI通过多臂老虎机等算法,动态优化流量分配,在保证统计效力的同时,最大化业务价值,实现了体验优化的智能化。
未来展望:
AI原生测试: 未来的测试框架可能会从设计之初就深度集成AI,实现完全自主的“测试智能体”,能够理解需求、自主设计测试、执行并报告结果。
大语言模型(LLM)的深度集成: LLM可用于直接生成复杂的端到端测试代码、理解自然语言描述的Bug报告、甚至直接模拟用户会话进行聊天机器人测试。
全链路预测性维护: AI将整合代码、日志、监控、基础设施等全链路数据,构建一个预测性质量保障平台,在用户遇到问题之前提前预测并修复故障。
拥抱AI测试不再是可选项,而是企业在数字化竞争中保持敏捷、高质量和用户体验的必由之路。建议组织和测试从业者开始探索和试点这些AI驱动的方法和工具,逐步将其融入DevOps和CI/CD管道中,构建面向未来的智能质量保障体系。