大模型——剪枝、量化、蒸馏、二值化
大语言模型的参数量现在十分惊人,GPT3的参数量已经达到1750亿。GPT3在fp16的精度下仍需要325G的存储空间,推理时至少需要5张80G的A100GPU。高参数量意味着对内存要求很高,以至于对终端部署有着极高要求。
而为了能在更多的设备上运行大模型,就需要模型压缩技术。
四大模型压缩技术:量化、剪枝、蒸馏和二值化
模型压缩主要有几个需求:1.降低模型所占空间。2.降低模型计算复杂度。3.降低能耗,提高续航。4.保证模型性能
量化
压缩每个权重参数存储的比特数,以达到降低内存需求的目的。传统的深度学习,参数一般用32位浮点数存储。量化可以将32位浮点数,量化成8位整数。这样,模型存储空间将直降至四分之一。而且,低精度的整数运算比浮点数运算高效的多。
对于1位量化,理想条件下,模型大小甚至可以降低至原来的三十二分之一。
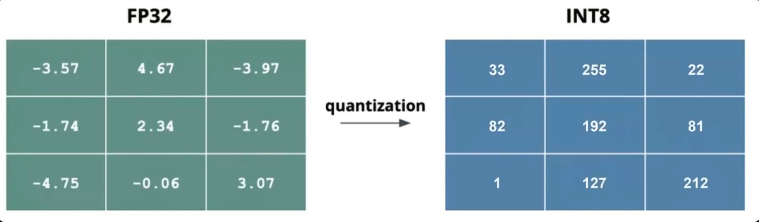
量化方法主要有三类:训练后量化(PTQ)、量化感知训练(QAT)、量化感知微调(QAF)
训练后量化
模型训练后,对权重进行量化。
TensorFlow lite提供工具,可以将32位浮点数,量化成8位整数。
缺点:量化时无法考虑训练中的动态变化,会使模型的精度下降
量化感知训练
在训练中就进行量化,让模型提前适应低精度。
TensorRT支持这种方法,在训练中模拟量化,保持模型性能。
缺点:运算更加复杂,需要更高的运算资源
训练感知微调
基于预训练模型进行微调,同时加入量化操作。结合了预训练模型的优势和量化的高效性。
在NLP中,研究人员经常在预训练的BERT中进行量化感知微调。他能快速适应特定任务,减少计算开销。性能上不如从头训练的量化感知模型。
量化存在的问题
- 精度下降。量化的位数越低,精度下降越大
- 模型敏感度不同。不同模型,对量化的敏感程度不同,对于有些模型,量化后性能依然出色,但有些模型,量化对其影响会非常大。
量化友好模型:传统CNN(如ResNet, VGG, MobileNet)、轻量级设计模型。
敏感模型:包含Transformer架构的模型、某些循环神经网络(RNN/LSTM)、超小模型、包含特定算子(如Depthwise卷积)的模型。 - 量化感知训练、训练感知微调需要修改训练过程,从而加大了训练的难度和计算资源的需求。
剪枝
去除神经网络中的不必要的连接,或者让一些神经元失活。以减少模型参数,降低计算量。
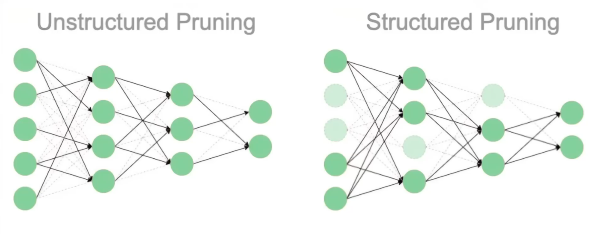
剪枝方法主要有两种:结构化剪枝、非结构化剪枝
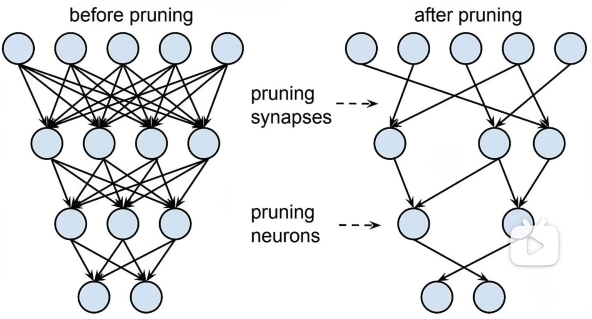
基于权重重要性的剪枝方法
通过分析权重对模型输出的影响,将影响小的权重减掉。在不怎么影响模型性能的情况下,大幅度降低模型的参数数量。

非结构化剪枝
随机移除单个权重和连接。
可以很好提高压缩比,直接移除对模型影响很小的权重。非结构化剪枝可以把模型参数减少50%以上
缺点:产生的稀疏结构在硬件上很难高效运算,因为硬件更喜欢规整的矩阵操作。参数量虽然减少很多,但推理速度减少并不明显。
结构化剪枝
按照一定规则剪枝,比如移除一定的神经元、滤波器、隐藏层。
压缩比上不如非结构化剪枝,但是推理速度优化方面表现更好,在CNN中可以将推理速度提升2~3倍,并降低能耗。
剪枝总结
- 精度损失问题。剪枝比例高时,精度损失严重。
- 可以降低参数量50%以上,对于结构化剪枝,还可以提升计算速度,降低能耗,这对于移动设备和嵌入式设备非常友好。
- 由于剪枝去除了冗余信息,模型的泛化能力也更好。
- 不同硬件平台对剪枝的接受程度不一样,可能需要额外优化
- 不同模型对剪枝敏感度不一样
蒸馏
分为教师模型和学生模型。
首先,训练一个大型、复杂、性能优异的教师模型,让其在大规模的数据集上学习,积累丰富的知识。
其次,选择一个较小的模型作为学生模型,进行初始化,要求结构简单但有一定的学习能力。
然后,进行训练。将教师模型的输出作为额外的监督信息,和学生模型的输出对比,通过优化损失函数来训练学生模型。损失函数包含两部分:学生模型原始损失、两个模型差异损失(一般选KL散度)
最后,对学生模型微调。
蒸馏涉及到一个温度参数,意义为难度程度。在高温模式下,可以学习到复杂的关联关系。低温模式下,答案接近原始分布,适合简单任务。(也可以选择动态,初期高温学习更多信息,后期低温聚焦特征)
NLP中,通常以BERT作为教师模型,LSTM作为学生模型。
蒸馏总结
优势
模型压缩效果显著,学生相较于教师,参数可以达到十分之一甚至更少。
推理速度快几倍
泛化能力更强
应用范围广:图像分类、目标检测、NLP
缺点
学生模型性能严重依赖教师模型的质量
训练时同时考虑学生和教师的训练过程
对于复杂任务,学生模型精度处理不如教师模型
需要合适且匹配的学生模型和教师模型
二值化
二值化可以在一些低功耗的物联网设备中,实现高精度的图像识别和语音识别,且由于计算简单不需要复杂的硬件支持。
二值化是一种极端的量化技术,把神经网络的权重和激活值限制在两个值上,通常为+1和-1。
二值化后,参数只需要1个bit就可以表示,极大程度降低模型复杂度,传统32位浮点数相比,缩小32倍。
由于只有两个值,乘法计算也可以通过转化为加法和移位替代。二值化网络卷积通过 同或XNOR 和 位操作 实现。
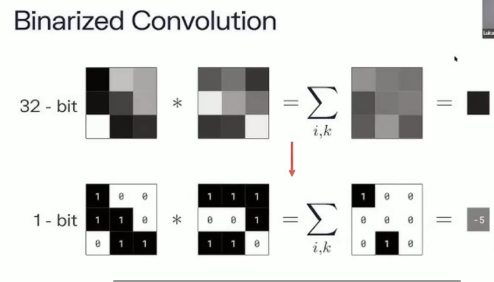
二值化总结
在神经网络训练中,研究人员也通过二值化技术压缩预训练的Transformer模型,显著减少模型存储空间和推理延迟。
二值化压缩率极高
推理速度提升明显,在一些网络中可以加快10倍以上
计算简单,可以进行硬件优化,使用专门的二值化硬件加速器
缺点:
精度损失严重,在复杂任务中更为明显
训练时需要特殊处理,如用直通估计器处理不可导的二值化操作
不同模型对二值化敏感度不同
场景分析
资源受限的场景
二值化适合精度要求不高的任务。量化可以调整量化精度控制压缩效果和模型性能之间的平衡。
要求计算速度,对精度有要求
量化和结构化剪枝
要求高性能
蒸馏
展望
多种压缩方法组合
量化+剪枝
蒸馏+量化感知训练
论文
https://arxiv.org/pdf/1603.05279
https://arxiv.org/pdf/2004.09602
https://arxiv.org/pdf/1511.00363
https://static.googleusercontent.com/media/research.google.com/en//pubs/archive/37631.pdf