unsloth笔记:基本介绍
更快的速度、更省的内存训练、运行、评估大模型
1 支持的模型
All Our Models | Unsloth Documentation
1.1 Dynamic GGUF/instruct 4-bit
- llama.cpp使用的新模型格式,专为高效、本地推理设计
- 注:GGUF无法微调
- 只保留推理所需的内容,如量化后的权重、推理元信息
-
不包含训练所需的梯度结构、参数层名、优化器状态
-
不支持反向传播
-
通常是 4-bit 静态量化,已经丢失了训练精度所需的权重信息
-
Instruct 4-bit (safetensors)
-
Instruct:代表模型是指令微调(Instruction-Tuned)版本,即已经训练过能更好理解指令/对话任务
-
4-bit:表示该模型已经被4-bit 量化(通常用于 QLoRA),显著降低了显存需求。
-
safetensors:是一种更安全的模型文件格式(相对
.bin),支持高效加载、避免执行恶意代码。 -
可直接用于低成本推理或继续进行LoRA / QLoRA 微调
-
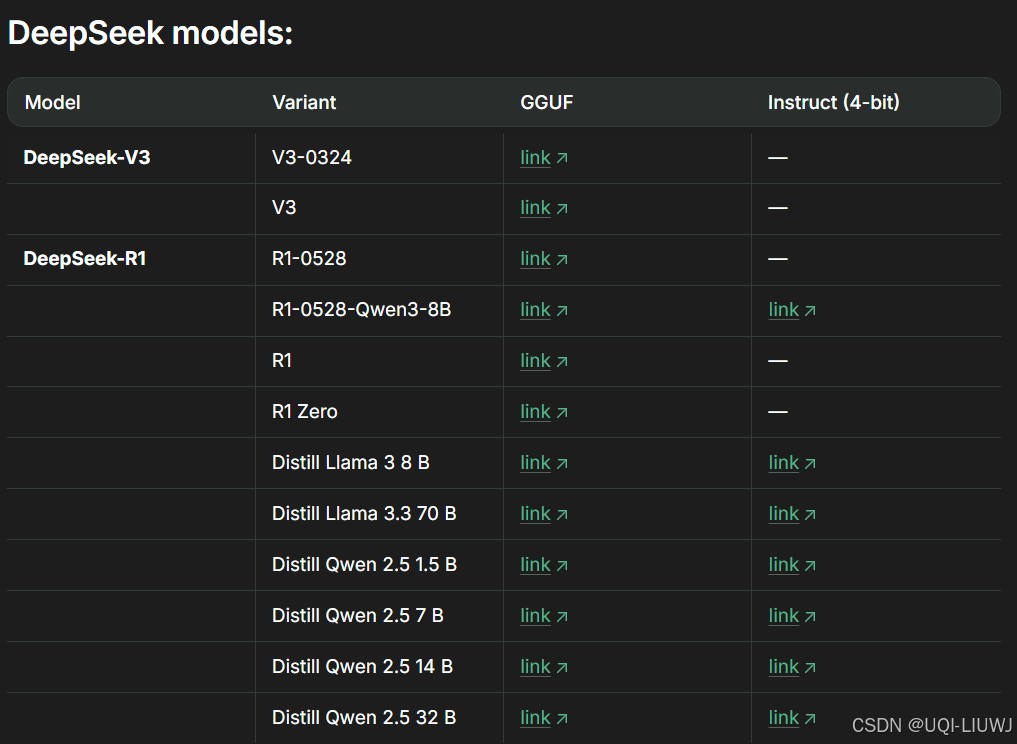
1.1.1 deepseek家族
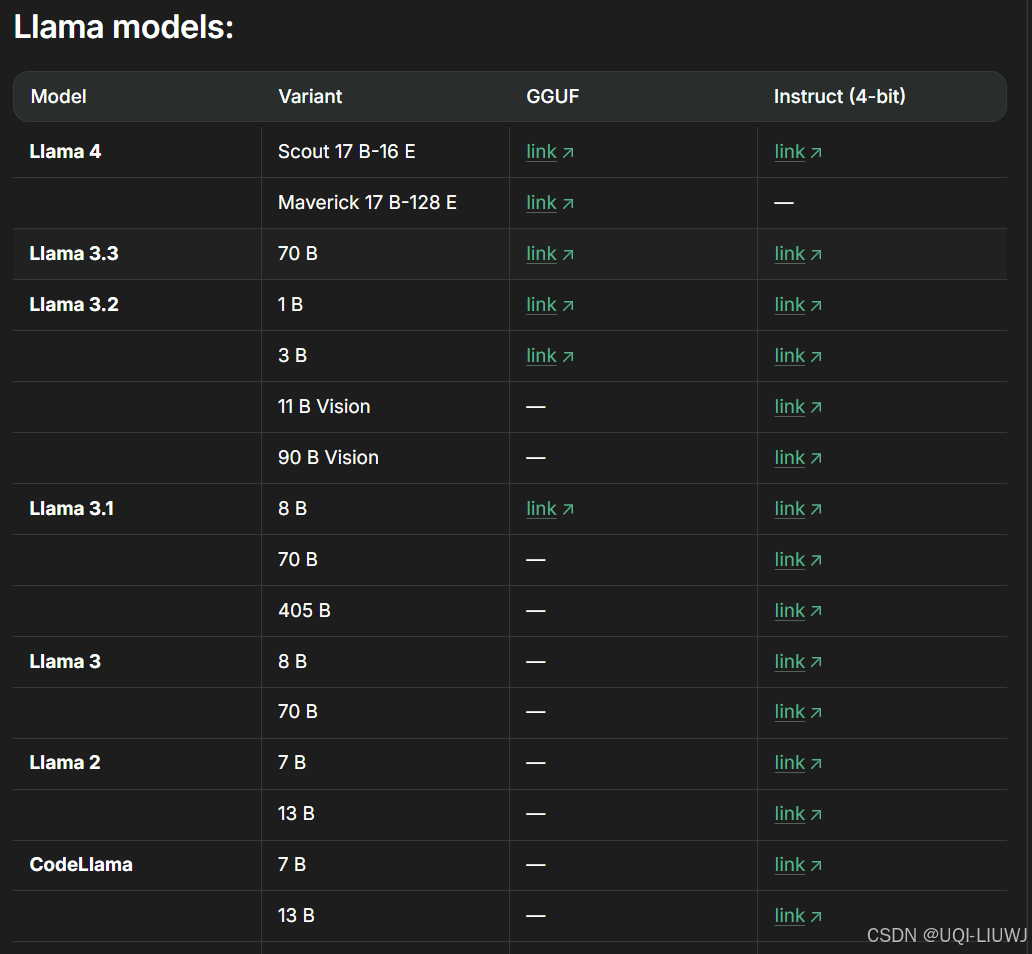
1.1.2 llama家族
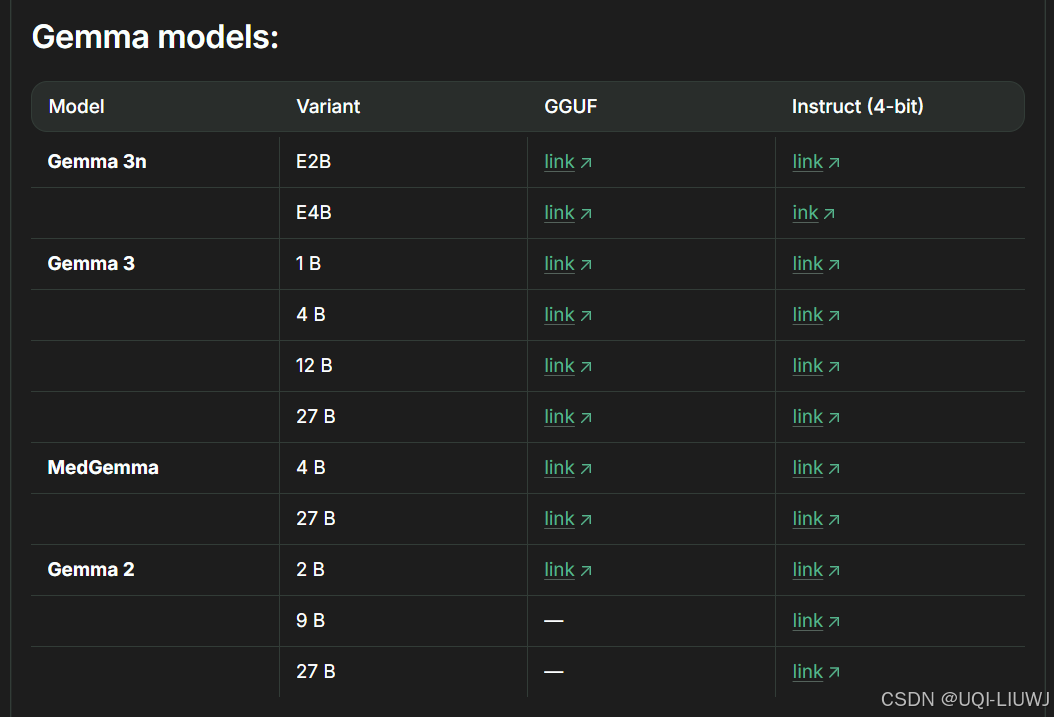
1.1.3 gemma家族
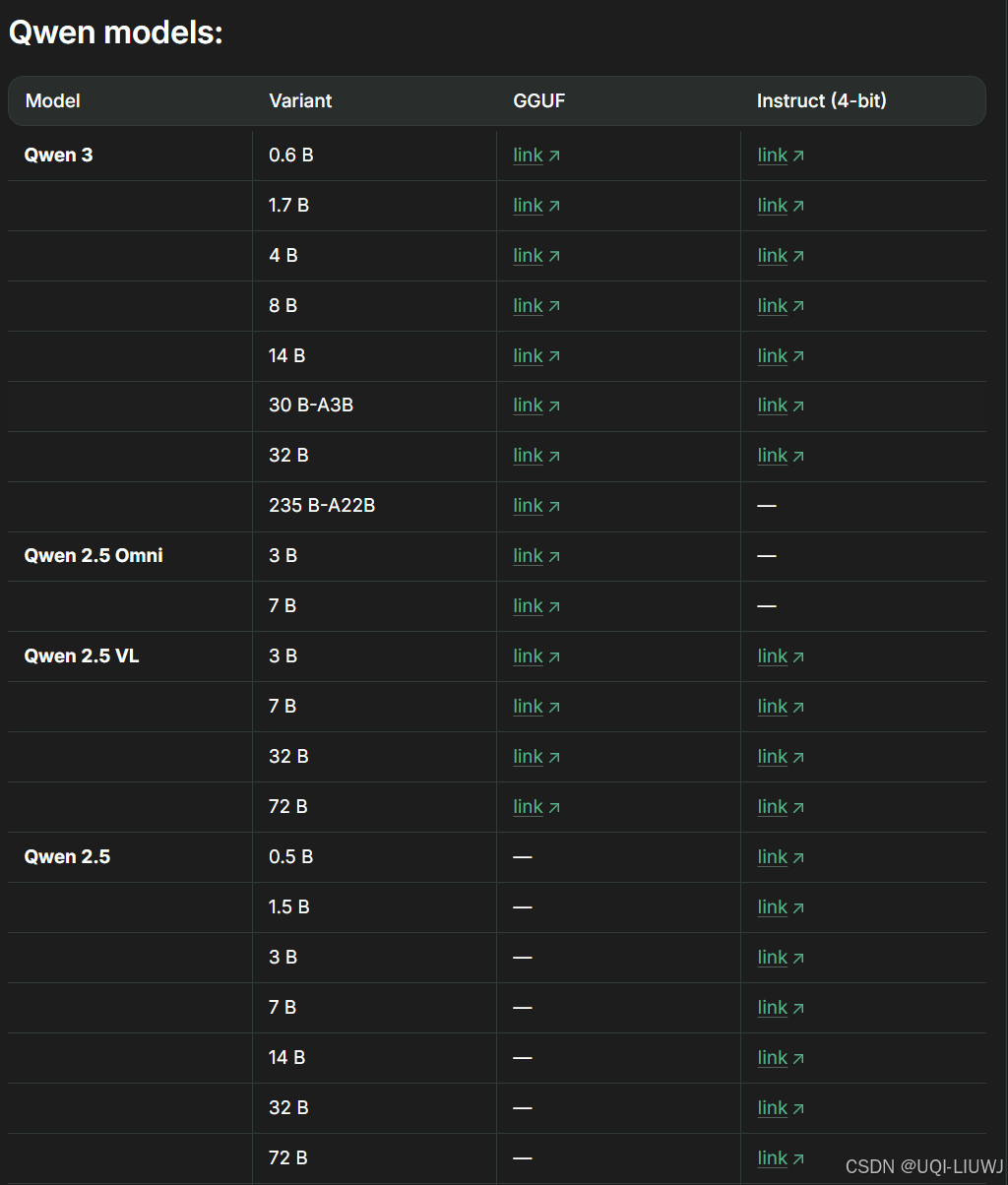
1.1.4 Qwen家族
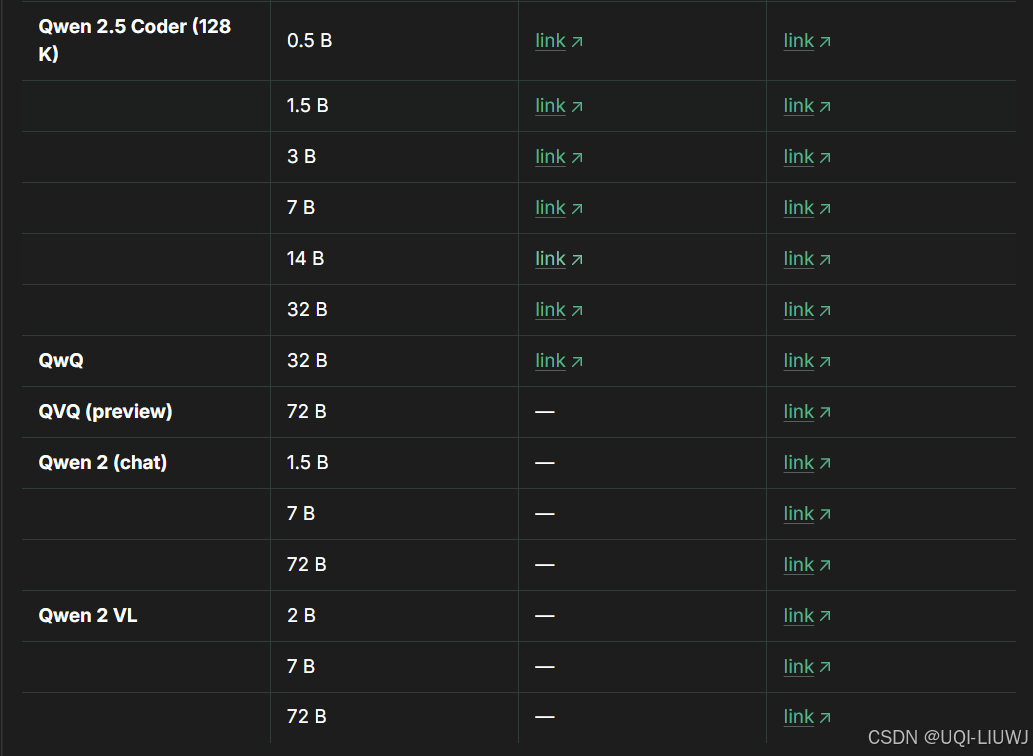
1.1.5 mistral家族
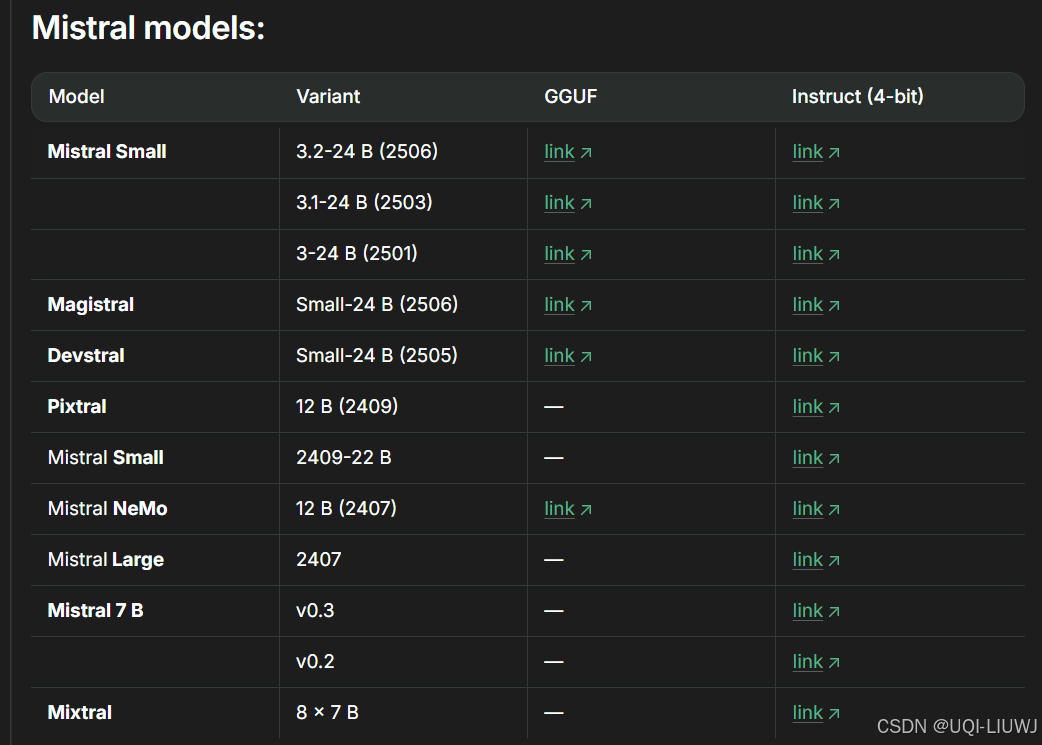
1.1.6 Phi家族
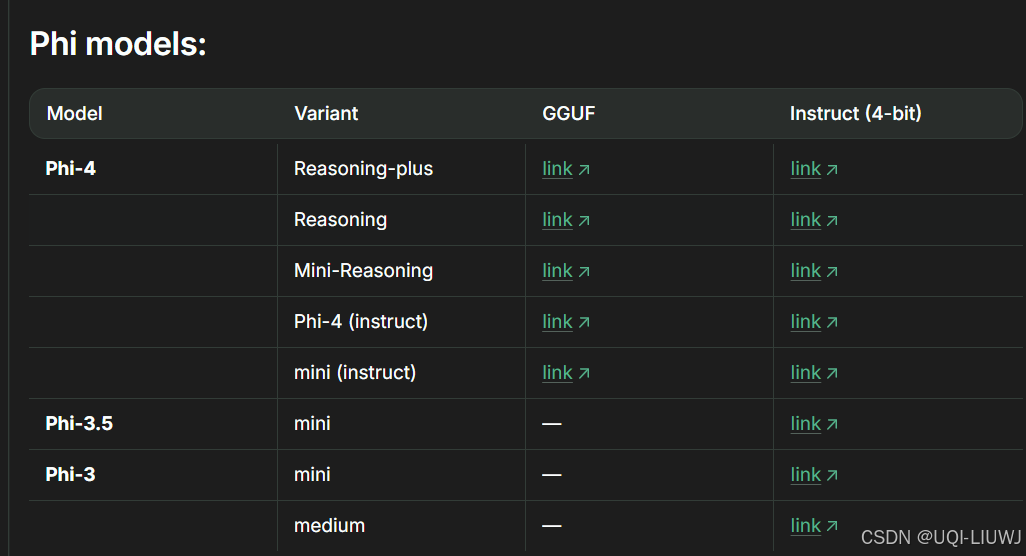
1.1.7 其他
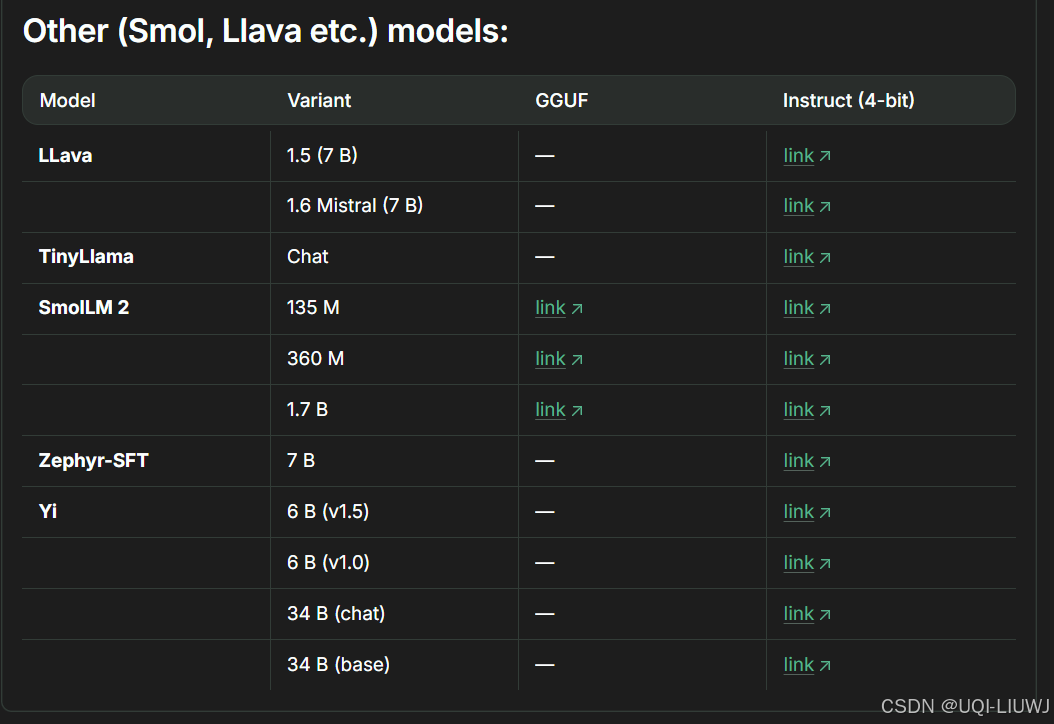
1.2 16-bit and 8-bit Instruct
基本上instruct 4-bit的有的这边都有
也可用于推理和微调,区别主要在于精度和资源消耗
1.3 Base 4 + 16-bit
未经过指令微调的模型的4-bit和16-bit量化版本
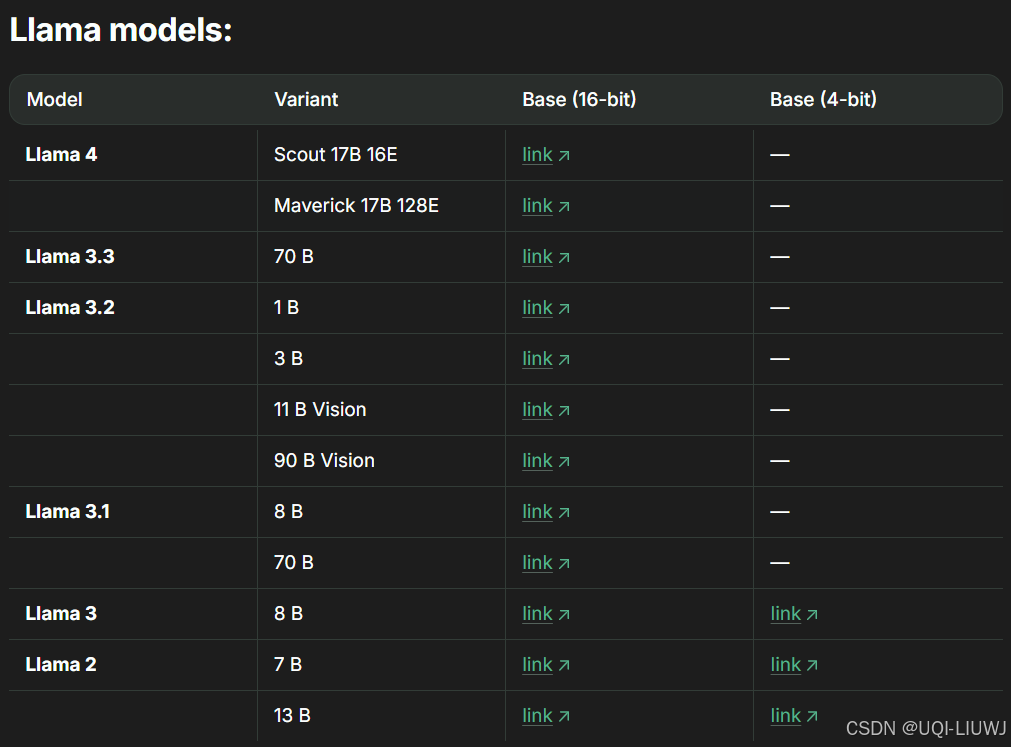
1.3.1 llama家族
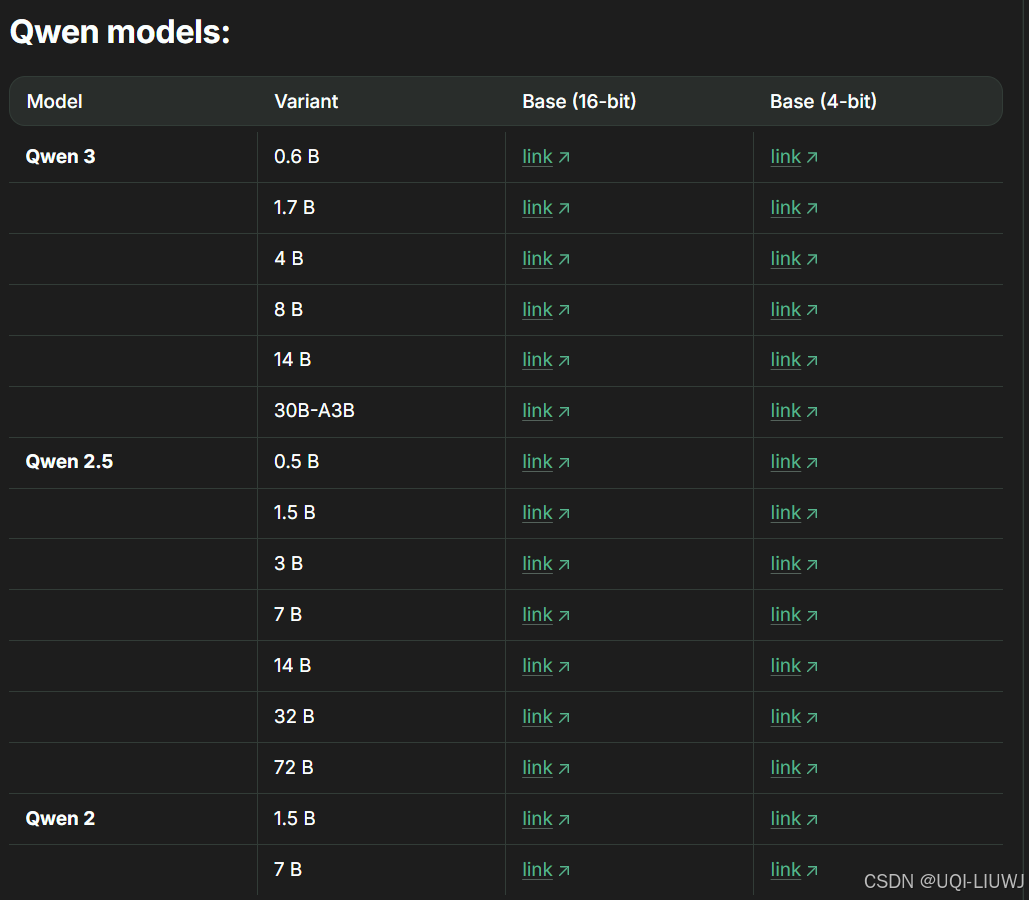
1.3.2 qwen家族
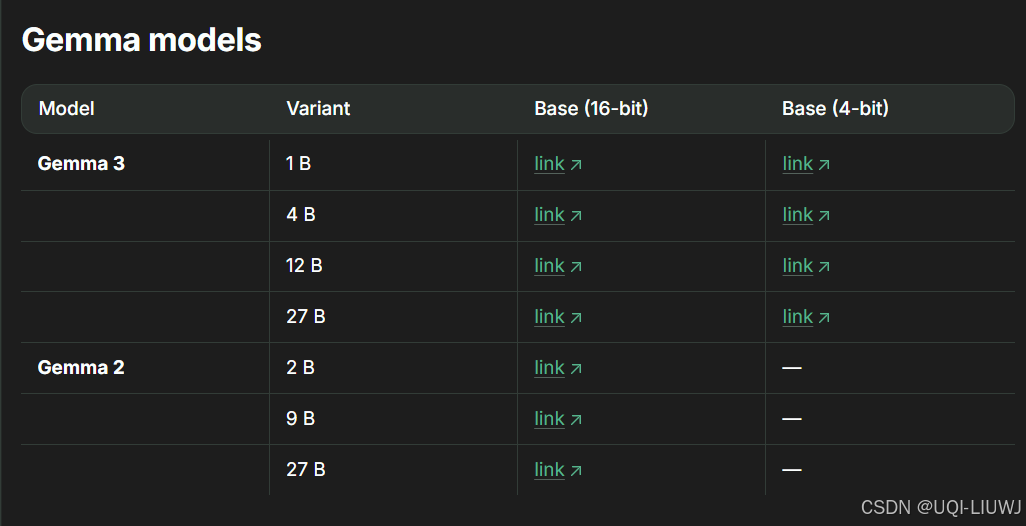
1.3.3 gemma 家族
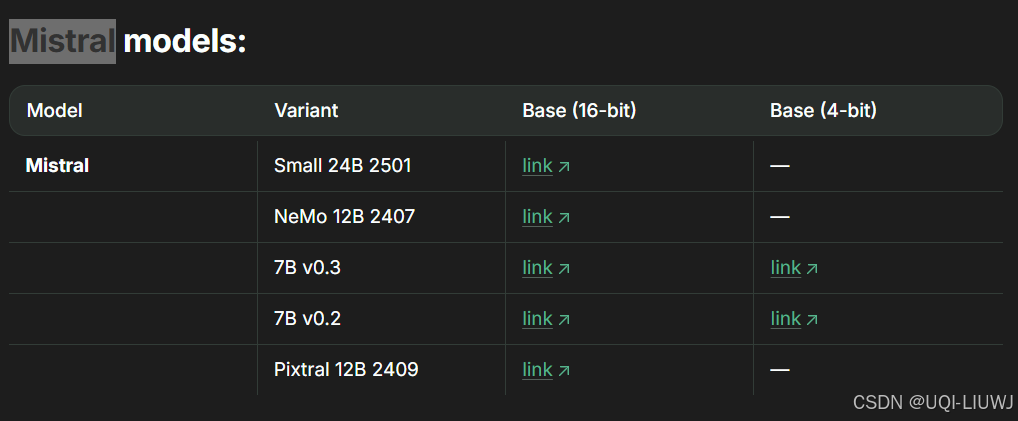
1.3.4 Mistral家族
1.4 unsloth版本模型命名后缀说明
| unsloth-bnb-4bit | Unsloth 的动态 4bit 量化模型,精度更高,占用略多显存 |
| bnb-4bit | 普通 BitsAndBytes 4bit 量化模型 |
| 无后缀 | 原始模型(16/8bit) |
2 可调参数推荐
| max_seq_length | 下文长度,Llama-3 支持到 8192,但建议先用 2048 测试 |
| dtype | 默认None,若使用新 GPU 可设为 torch.float16 或 bfloat16 |
| load_in_4bit | 启用 QLoRA,减少 4 倍显存消耗 QLoRA 的准确性如今已经接近甚至超过 LoRA,建议默认使用 |
| full_finetuning | 若设为 True,则执行全参数微调(不推荐) |
3 选择instruct模型还是base模型
| 数据量情况 | 推荐选择 | 说明 |
|---|---|---|
| 超过 1000 行 | Base 模型 | 数据量充足,能充分训练出新行为 |
| 300–1000 行高质量数据 | Base 或 Instruct | 视任务而定,两者都可以 |
| 少于 300 行 | Instruct 模型 | 小样本建议保留已有指令能力,仅做轻微定制 |
-
任务明确 + 数据少 → 用 Instruct 模型做轻微定制即可
-
任务复杂 / 数据多 → 从 Base 模型开始训练,得到效果更稳的定制模型