VQ-VAE-2:开启高保真多样化图像生成的新范式
本文为《Generating Diverse High-Fidelity Images with VQ-VAE-2》的阅读笔记,原文链接:https://proceedings.neurips.cc/paper/2019/hash/5f8e2fa1718d1bbcadf1cd9c7a54fb8c-Abstract.html
《Generating Diverse High-Fidelity Images with VQ-VAE-2》提出向量量化变分自编码器(VQ-VAE-2),通过分层离散潜在空间和自回归先验,生成高保真、多样图像。在 ImageNet 上,其 FID 低至 10,分类准确率 Top-1 达 54.83%,超越 BigGAN;FFHQ 数据集上能生成 1024×1024 高清人脸,兼顾细节与多样性。

文章《Generating Diverse High-Fidelity Images with VQ-VAE-2》发表于《33rd Conference on Neural Information Processing Systems (NeurIPS 2019)》。文章针对生成模型在高保真与多样性间的矛盾,提出 VQ-VAE-2 架构,以向量量化技术构建离散潜在空间,结合分层设计与自回归先验,在 ImageNet 和 FFHQ 等数据集上验证了其生成高分辨率、多样化图像的能力,为图像生成领域提供新方向。
一、图像生成领域的挑战与创新方向
在深度学习驱动的图像生成领域,研究者们一直致力于突破两大核心难题:如何在保证生成图像高保真度的同时,兼顾样本的多样性;以及如何提升模型在处理高分辨率图像时的效率与稳定性。此前,生成对抗网络(GANs)凭借其强大的生成能力,在高保真图像生成方面取得了显著进展,但这类模型普遍存在 “模式崩溃” 的问题 —— 即生成的样本往往局限于数据集中的少数模式,难以覆盖全部的多样性,例如在生成鸟类图像时,可能只擅长生成某几种特定姿态或颜色的鸟,而忽略了其他种类或形态。
与之相对,基于似然的生成模型,如变分自编码器(VAE)和自回归模型,虽然理论上能够覆盖数据集中的所有模式,避免模式崩溃,但在生成高分辨率图像时,却面临着采样速度慢、细节保真度不足等问题。正是在这样的背景下,DeepMind 的研究团队提出了向量量化变分自编码器(VQ-VAE-2),通过创新的离散潜在空间设计和分层架构,成功地在高保真度、多样性和生成效率之间找到了平衡点,为图像生成领域带来了新的突破。
二、VQ-VAE-2 的核心机制解析
VQ-VAE-2 的核心创新在于引入了向量量化(Vector Quantization)技术,将传统 VAE 中的连续潜在空间转换为离散空间,这一转变不仅解决了传统 VAE 在建模复杂分布时的局限,还为后续的高效生成奠定了基础。具体而言,VQ-VAE-2 的工作流程主要分为编码、量化和解码三个关键步骤。

图1 VQ-VAE-2 生成的 ImageNet 类别条件样本图
2.1 向量量化:从连续到离散的转换
编码过程中,编码器将输入图像x转换为一组高维特征向量E(x),这些向量包含了图像的关键特征信息。随后进入量化阶段,模型会从一个预设的 “码本”(codebook)中选取与每个特征向量E(x)最接近的原型向量ek,量化操作可表示为:

这里的码本类似于一本 “字典”,原型向量则是字典中的 “词条”,量化过程就像是将编码器输出的特征向量 “翻译” 成字典中最匹配的词条,从而实现了特征的离散化。这种离散化处理不仅降低了后续生成过程的计算复杂度,还增强了模型对特征的鲁棒性。
2.2 损失函数:协同优化的关键
解码阶段则是编码和量化的逆过程,解码器接收量化后的原型向量ek,并通过一系列非线性变换重建出与输入图像尽可能相似的图像。为了确保编码器、解码器和码本能够协同优化,VQ-VAE-2 设计了独特的损失函数:
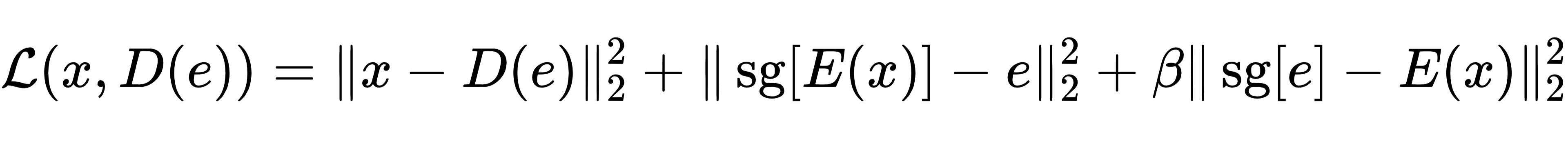
其中,第一项是重建损失,用于衡量重建图像与输入图像之间的差异,确保解码过程的准确性;第二项为码本损失,通过停止梯度操作(sg)使得码本向量能够逐步逼近编码器输出的特征向量;第三项是承诺损失,由超参数β控制,其作用是鼓励编码器的输出尽可能接近码本中的原型向量,避免特征向量在码本中频繁跳变,保证量化过程的稳定性。
2.3 码本更新:指数移动平均策略
为了进一步提升码本的质量和稳定性,VQ-VAE-2 采用指数移动平均的方式更新码本向量,公式如下:
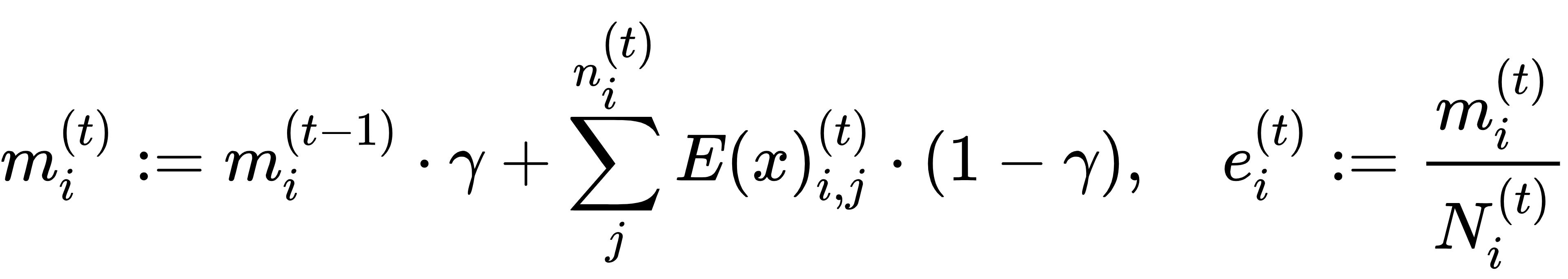
其中,γ为衰减参数(默认值为 0.99),ni(t)表示在第t次迭代中,被量化到第i个码本向量的样本数量,mi(t)和Ni(t)分别用于累积特征向量的总和与样本数量,最终通过两者的比值更新码本向量ei(t)。
三、分层架构与生成策略
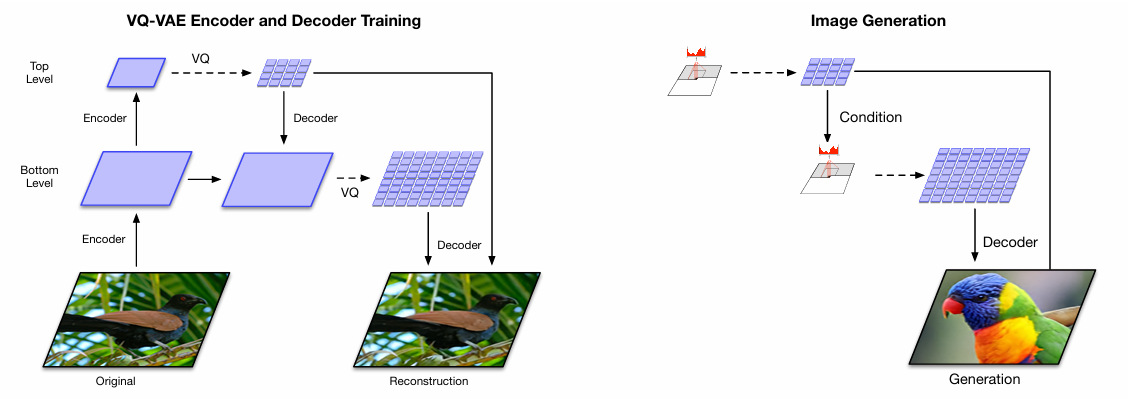
图2 VQ-VAE-2 模型架构图
为了有效处理高分辨率图像(如 256×256 甚至 1024×1024),VQ-VAE-2 采用了多层级的潜在空间架构和分阶段的生成策略,实现了全局与局部特征的高效建模。
3.1 多层级潜在空间:全局与局部的分离
VQ-VAE-2 包含底层和顶层两个潜在映射:底层潜在映射的尺寸较大(如 64×64),主要负责捕捉图像的局部细节信息,如纹理、颜色变化等;顶层潜在映射的尺寸相对较小(如 32×32),则专注于编码图像的全局结构,如物体的形状、姿态和空间布局等。
在解码过程中,解码器会同时接收来自底层和顶层的量化潜在向量,通过一系列残差块和转置卷积操作,逐步将潜在向量 upsample 到原始图像的尺寸,最终重建出高分辨率图像。这种分层设计的优势在于,能够让模型针对不同尺度的特征进行专门学习,顶层潜在映射专注于全局关联的建模,底层则聚焦于局部细节的刻画,两者协同工作,使得模型在生成高分辨率图像时既能保证整体结构的合理性,又能呈现丰富的细节。
3.2 两步走生成策略:从压缩到采样
VQ-VAE-2 的生成过程采用 “两步走” 的策略:首先训练编码器和解码器完成图像的压缩与重建,然后在压缩后的离散潜在空间上训练自回归先验模型,学习潜在向量的分布规律。这里所使用的自回归先验模型是 PixelSnail,一种带有自注意力机制的强大模型。针对分层架构,先验模型的设计也有所不同:顶层先验模型配备了多头自注意力层,能够捕捉潜在空间中远距离位置之间的关联,从而更好地建模全局结构;底层先验模型则主要依赖于顶层潜在向量的条件信息,专注于局部细节的分布学习,同时避免了因分辨率较高而带来的内存限制问题。
这种生成策略的优势十分明显,由于潜在空间的维度远小于原始像素空间(通常是 1/30 甚至更小),在潜在空间上进行采样和生成的速度要比直接在像素空间快得多,尤其对于大尺寸图像,这种效率提升更为显著。同时,自回归先验模型能够充分学习潜在向量之间的依赖关系,确保生成的潜在向量符合真实数据的分布,进而通过解码器生成高质量的图像。
四、实验表现与优势分析
4.1 高分辨率图像生成
在 ImageNet 和 FFHQ 等大规模数据集上的实验结果,充分验证了 VQ-VAE-2 的卓越性能。在 ImageNet 数据集上,VQ-VAE-2 生成的 256×256 类别条件样本,在保真度上能够与当时的顶级生成模型 BigGAN 相媲美,而在多样性方面则表现更为出色。例如,在生成 “鱼” 和 “鸵鸟” 等类别的图像时,VQ-VAE-2 能够涵盖多种不同的姿态、角度和形态,而 BigGAN 生成的样本则相对单一,往往局限于少数几种常见模式。

图3 VQ-VAE-2 与 BigGAN-deep 样本多样性对比图
在 FFHQ 人脸数据集(1024×1024)上,VQ-VAE-2 展现出了强大的捕捉长距离依赖关系的能力。它能够保证生成人脸的双眼颜色匹配、面部特征对称等细节,甚至能够生成绿色头发等相对罕见但合理的样本,这表明模型不仅能够学习数据集中的主流模式,还能覆盖那些出现频率较低的 “小众” 模式,充分体现了其在多样性上的优势。
4.2 客观指标的突破
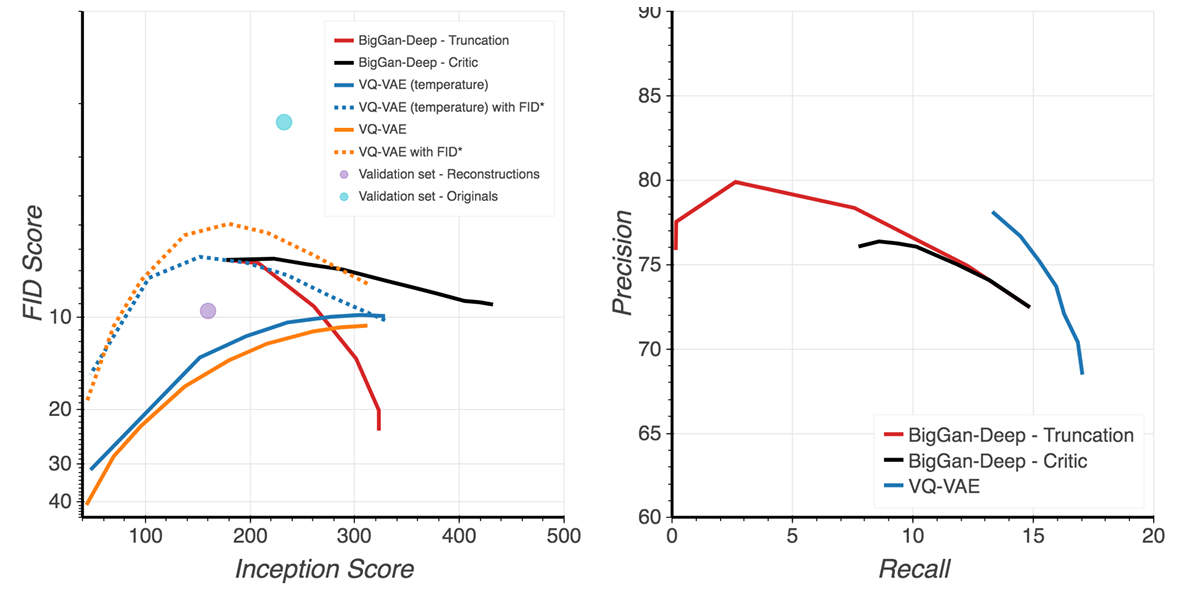
图4 VQ-VAE-2 量化评估指标图
从客观指标来看,分类准确率得分(CAS)显示,使用 VQ-VAE-2 生成的样本训练的分类器,在真实图像测试集上的 Top-1 准确率达到 54.83%,显著高于 BigGAN 生成样本训练的分类器(42.65%),这一结果表明 VQ-VAE-2 生成的图像分布更接近真实数据分布。在精确率 - 召回率指标中,VQ-VAE-2 虽然在精确率上略低于 BigGAN,但召回率明显更高,进一步印证了其在覆盖数据模式多样性A方面的优势。
此外,VQ-VAE-2 还通过 “分类器引导的拒绝采样” 方法,实现了生成质量与多样性的灵活平衡。通过预训练的分类器对生成样本进行评分,保留那些分类置信度高的样本,能够将 FID(Fréchet Inception Distance,用于衡量生成图像与真实图像相似度的指标)从约 30 降低到 10 左右,接近顶级 GAN 模型的水平,同时保持了样本的多样性。
五、总结与展望
VQ-VAE-2 通过向量量化技术、分层架构和高效的生成策略,成功地在高保真度、多样性和生成效率之间取得了平衡,为高分辨率图像生成提供了一种新的有效范式。其创新的离散潜在空间设计,不仅解决了传统连续潜在空间模型的局限,还为与其他技术(如量子计算)的结合提供了可能,因为离散特性更容易与量子系统中的离散变量相兼容。
从应用角度来看,VQ-VAE-2 的轻量级编码器和解码器设计,使其在图像压缩、超分辨率重建、实时图像生成等领域具有广阔的应用前景。未来,随着码本设计的进一步优化、先验模型能力的增强以及训练策略的改进,VQ-VAE-2 有望在更高分辨率、跨模态生成(如图文生成)等任务中取得更大的突破,持续推动图像生成技术的发展,为人工智能在视觉创作、内容生成等领域的应用注入新的活力。
点击更多,学习更多精彩内容。