【mmcv自己理解】
mmcv自己理解
- 一、TPVformer为例理解注册机制
- 二、deformable为例理解注册机制
- 1
- 2 同样,DetrTransformerEncoder类中__init__函数有
一、TPVformer为例理解注册机制
config文件
self_cross_layer = dict(type='TPVFormerLayer',attn_cfgs=[dict(type='TPVCrossViewHybridAttention',tpv_h=tpv_h_,tpv_w=tpv_w_,tpv_z=tpv_z_,num_anchors=hybrid_attn_anchors,embed_dims=_dim_,num_heads=num_heads,num_points=hybrid_attn_points,init_mode=hybrid_attn_init,),dict(type='TPVImageCrossAttention',pc_range=point_cloud_range,num_cams=_num_cams_,deformable_attention=dict(type='TPVMSDeformableAttention3D',embed_dims=_dim_,num_heads=num_heads,num_points=num_points,num_z_anchors=num_points_in_pillar,num_levels=_num_levels_,floor_sampling_offset=False,tpv_h=tpv_h_,tpv_w=tpv_w_,tpv_z=tpv_z_,),embed_dims=_dim_,tpv_h=tpv_h_,tpv_w=tpv_w_,tpv_z=tpv_z_,)],feedforward_channels=_ffn_dim_,ffn_dropout=0.1,operation_order=('self_attn', 'norm', 'cross_attn', 'norm', 'ffn', 'norm')
)self_layer = dict(type='TPVFormerLayer',attn_cfgs=[dict(type='TPVCrossViewHybridAttention',tpv_h=tpv_h_,tpv_w=tpv_w_,tpv_z=tpv_z_,num_anchors=hybrid_attn_anchors,embed_dims=_dim_,num_heads=num_heads,num_points=hybrid_attn_points,init_mode=hybrid_attn_init,)],feedforward_channels=_ffn_dim_,ffn_dropout=0.1,operation_order=('self_attn', 'norm', 'ffn', 'norm')
)
model = dict(type='TPVFormer',use_grid_mask=True,tpv_aggregator=dict(type='TPVAggregator',tpv_h=tpv_h_,tpv_w=tpv_w_,tpv_z=tpv_z_,nbr_classes=nbr_class,in_dims=_dim_,hidden_dims=2*_dim_,out_dims=_dim_,scale_h=scale_h,scale_w=scale_w,scale_z=scale_z),img_backbone=dict(type='ResNet',depth=101,num_stages=4,out_indices=(1, 2, 3),frozen_stages=1,norm_cfg=dict(type='BN2d', requires_grad=False),norm_eval=True,style='caffe',dcn=dict(type='DCNv2', deform_groups=1, fallback_on_stride=False), # original DCNv2 will print log when perform load_state_dictstage_with_dcn=(False, False, True, True)),img_neck=dict(type='FPN',in_channels=[512, 1024, 2048],out_channels=_dim_,start_level=0,add_extra_convs='on_output',num_outs=4,relu_before_extra_convs=True),tpv_head=dict(type='TPVFormerHead',tpv_h=tpv_h_,tpv_w=tpv_w_,tpv_z=tpv_z_,pc_range=point_cloud_range,num_feature_levels=_num_levels_,num_cams=_num_cams_,embed_dims=_dim_,encoder=dict(type='TPVFormerEncoder',tpv_h=tpv_h_,#200tpv_w=tpv_w_,#200tpv_z=tpv_z_,#16num_layers=tpv_encoder_layers,#5pc_range=point_cloud_range,#[-51.2, -51.2, -5.0, 51.2, 51.2, 3.0]num_points_in_pillar=num_points_in_pillar,# [4, 32, 32]num_points_in_pillar_cross_view=[16, 16, 16],return_intermediate=False,transformerlayers=[self_cross_layer,self_cross_layer,self_cross_layer,self_layer,self_layer,]),positional_encoding=dict(type='CustomPositionalEncoding',num_feats=_pos_dim_,#[24, 24, 16]h=tpv_h_, #200w=tpv_w_, #200z=tpv_z_ #16)))
TPVFormer函数实现在tpvformer.py里
#通过注册创建tpv_head类
self.tpv_head = builder.build_head(tpv_head)
self.img_backbone = builder.build_backbone(img_backbone)
self.img_neck = builder.build_neck(img_neck)
tpv_head、img_backbone、img_neck是函数名字,具体实现TPVFormerHead、ResNet、FPN
调用tpv_head
img_feats = self.img_backbone(img)
img_feats = self.img_neck(img_feats)
outs = self.tpv_head(img_feats, img_metas)#img_feats[1,6,3,928,1600]
TPVFormerHead函数的实现注册在tpv_head.py里
TPVFormerHead类中用到encoder函数,encoder具体实现在TPVFormerEncoder
self.encoder = build_transformer_layer_sequence(encoder)
tpv_embed = self.encoder([tpv_queries_hw, tpv_queries_zh, tpv_queries_wz],#[1,4000,64][1,3200,64][1,3200,64]feat_flatten,#[6, 30825, 1, 64]feat_flatten,#[6, 30825, 1, 64]tpv_h=self.tpv_h,#200tpv_w=self.tpv_w,#200tpv_z=self.tpv_z,#16tpv_pos=tpv_pos,#[1,4000,64][1,3200,64][1,3200,64]spatial_shapes=spatial_shapes,#[4,2]level_start_index=level_start_index,#尺寸4,值[0, 23200, 29000, 30450]img_metas=img_metas,)
TPVFormerEncoder类中应包含transformerlayers函数,transformerlayers具体实现在self_cross_layer(即TPVFormerLayer)
二、deformable为例理解注册机制
1
config文件
bbox_head=dict(type='DeformableDETRHead',num_query=300,num_classes=2,in_channels=2048,sync_cls_avg_factor=True,as_two_stage=False,transformer=dict(type='DeformableDetrTransformer',encoder=dict(type='DetrTransformerEncoder',num_layers=1,transformerlayers=dict(type='BaseTransformerLayer',attn_cfgs=dict(type='MultiScaleDeformableAttention', embed_dims=256),feedforward_channels=1024,ffn_dropout=0.1,operation_order=('self_attn', 'norm', 'ffn', 'norm'))),decoder=dict(type='DeformableDetrTransformerDecoder',num_layers=6,return_intermediate=True,transformerlayers=dict(type='DetrTransformerDecoderLayer',attn_cfgs=[dict(type='MultiheadAttention',embed_dims=256,num_heads=8,dropout=0.1),dict(type='MultiScaleDeformableAttention',embed_dims=256)],feedforward_channels=1024,ffn_dropout=0.1,operation_order=('self_attn', 'norm', 'cross_attn', 'norm','ffn', 'norm')))),
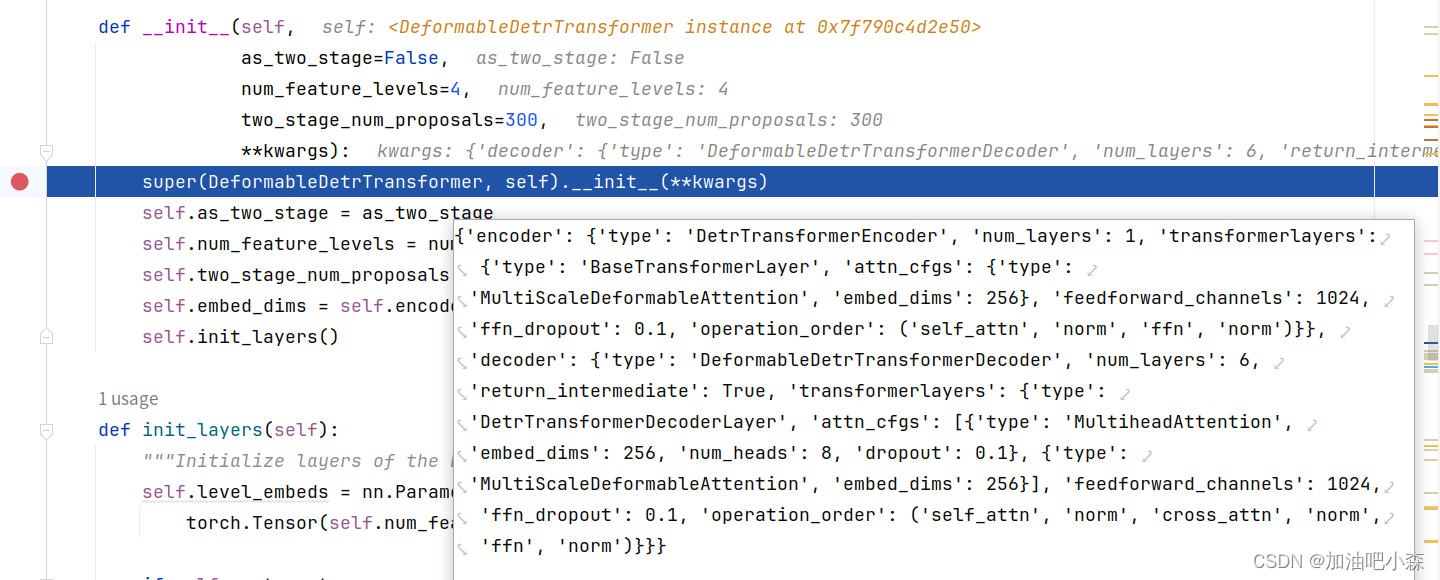
transformerlayers中DeformableDetrTransformer类__init__函数有
encoder=dict(type='DetrTransformerEncoder',num_layers=1,transformerlayers=dict(type='BaseTransformerLayer',attn_cfgs=dict(type='MultiScaleDeformableAttention', embed_dims=256),feedforward_channels=1024,ffn_dropout=0.1,operation_order=('self_attn', 'norm', 'ffn', 'norm'))),decoder=dict(type='DeformableDetrTransformerDecoder',num_layers=6,return_intermediate=True,transformerlayers=dict(type='DetrTransformerDecoderLayer',attn_cfgs=[dict(type='MultiheadAttention',embed_dims=256,num_heads=8,dropout=0.1),dict(type='MultiScaleDeformableAttention',embed_dims=256)],feedforward_channels=1024,ffn_dropout=0.1,operation_order=('self_attn', 'norm', 'cross_attn', 'norm','ffn', 'norm')))),
2 同样,DetrTransformerEncoder类中__init__函数有
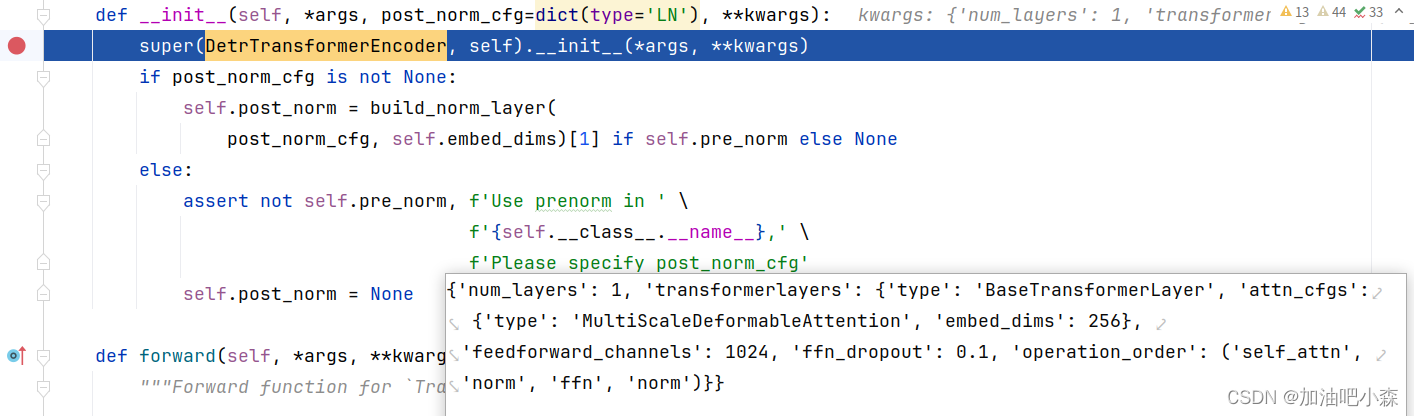
num_layers=1,transformerlayers=dict(type='BaseTransformerLayer',attn_cfgs=dict(type='MultiScaleDeformableAttention', embed_dims=256),feedforward_channels=1024,ffn_dropout=0.1,operation_order=('self_attn', 'norm', 'ffn', 'norm'))),