强化微调:以Swift框架进行GRPO多模态模型强化微调为例
一、TL;DR
- 整体介绍:强化微调RFT的原因、步骤、作用以及常见的rft方式
- dmeo举例:以Swift给的Qwen2.5-Math-7B-Instruct为例介绍了整个RFT的流程和代码细节
- 实际强化微调:以qwen/internVL为例完成一次指令微调并且使用强化学习进一步提升指标
二、整体介绍
2.1 为什么要做强化微调
掉点/回退现象:
基础MLLM经过含有CoT训练集上做SFT后,发现在test集上掉点,可以通过强化微调来确保不会发生这种情况
- 在LLaMA3上,使用gsm8k训练集训练llama3.1-8b-instruct,对生成的ckpt使用test集进行评测,会发现掉点。
原因:
模型的知识遗忘,举例如下:
- 正常流程:在微调的时候会加入非常多的CoT数据集
- 造成结果:在继续训练通用任务后,知识遗忘破坏了模型原有能力,导致了掉点。
- 原因分析:当模型在解决数学任务的时候,用到的能力很有可能不是来自于math数据集,而是来自arc数据集,
2.2 什么时候可以使用强化微调
当有如下条件之一时使用强化微调:
- 已经微调过模型,能力不满足需求
- 需要更强的CoT能力
- 对基模型训练通用能力,而原始数据集已经导致模型效果无法提升
-
对应query的输出结果可以相对准确地评估好坏,例如结果清晰(数学,代码),过程清晰(翻译,风格)等
强化微调非常依赖于reward评估是否准确。如果评估结果不准确,可能导致模型训练原地震荡,甚至越训越差。
2.3 强化微调的步骤
2.3.1 使用某个模型生成数据/进行原始数据扩充然后采样
-
大模型生成数据:使用GPT、Qwen-Max、DeepSeek-V3/R1等生成和扩充数据,则该强化微调可以理解为蒸馏
- 模型本身生成数据:可以理解为自我提升(self-improvement)微调
- 采样过程-on-policy算法:采样一个batch,然后通过KL散度和reward进行拟合训练并不断循环
- 采样算法:包含蒙特卡洛采样、do_sample采样、group beam search、dvts等
- 采样过程额外引入细节:可以引入ORM(结果判断),PRM(过程打分),多样性过滤,语种过滤等
2.3.2 使用数据训练目标模型
训练的方式:
- 如果使用SFT,则称为拒绝采样微调
- 如果是强化学习,则称为强化学习微调
2.3.3 根据需要判断是否重复上述过程
-
如果使用更大的模型蒸馏,例如更大模型的蒙特卡洛采样蒸馏,一般不会有循环
-
如果使用本模型进行采样,或者PPO等算法,则会有循环
2.4 常见的强化微调方式
- 蒸馏:使用蒙特卡洛、do_sample等方式从超大模型中采样大量优质数据,训练小模型
- 自我提升:从本模型中采样部分优质数据,筛选后训练本模型,循环执行
- on-policy RL:使用PPO、GRPO等方式循环训练
2.5 ms-swift的展示demo
SFT和RFT的区别:
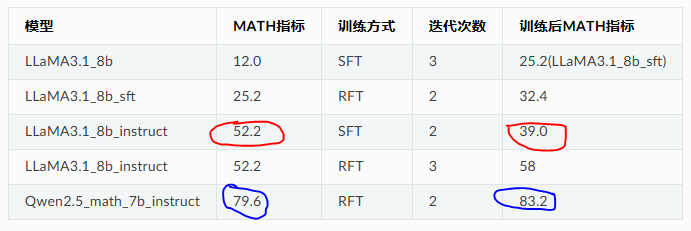
使用competition_math直接SFT后,instruct模型的掉点十分严重。而RFT后模型能力有提升,即使对Qwen2.5_math_7b_instruct这个SOTA的math模型也同样有一定提升空间。

同样可以发现,Qwen2.5这个模型经过RFT后在原有的其他数据集gsm8k上也没有出现大幅度回退(这就是为什么比SFT好的原因,新数据集上有效果,旧数据集上不坍塌)。
参考资料:强化微调 — swift 3.8.0.dev0 文档
三、demo代码分析
3.1 main函数分析
遵循第二节的流程:
- 先采样;
- 再做RLT
- 再做循环-5次
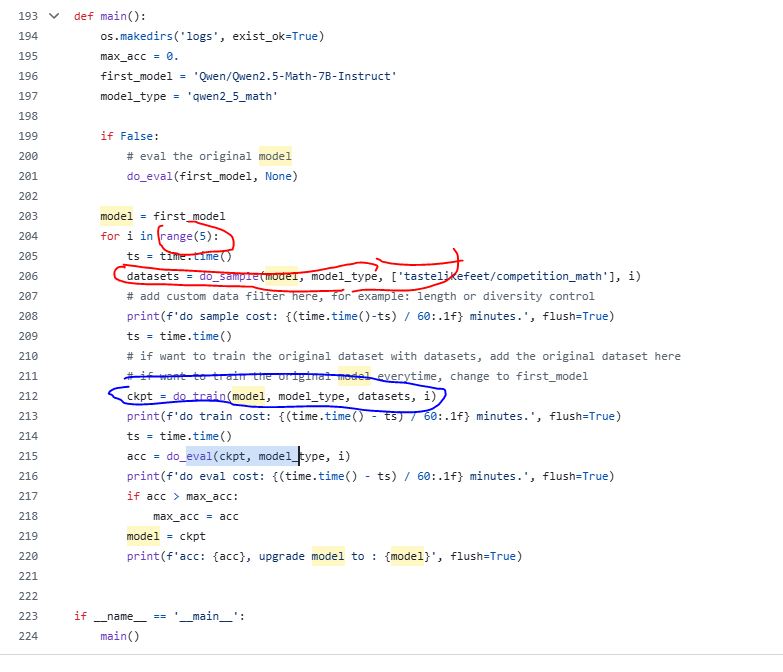
注意:以上这些流程都是使用python拼接输入命令行,不是一个函数就搞定了所有的代码哈,核心的这些命令行的功能都被swift封装在框架里面了,尤其是PRM模型的选取这些。
3.2 do-sample采样函数
如下图所示,过程奖励模型使用了Qwen2.5-Math-PRM-7B模型,为每一块GPU上生成了一个采样的RFT数据集
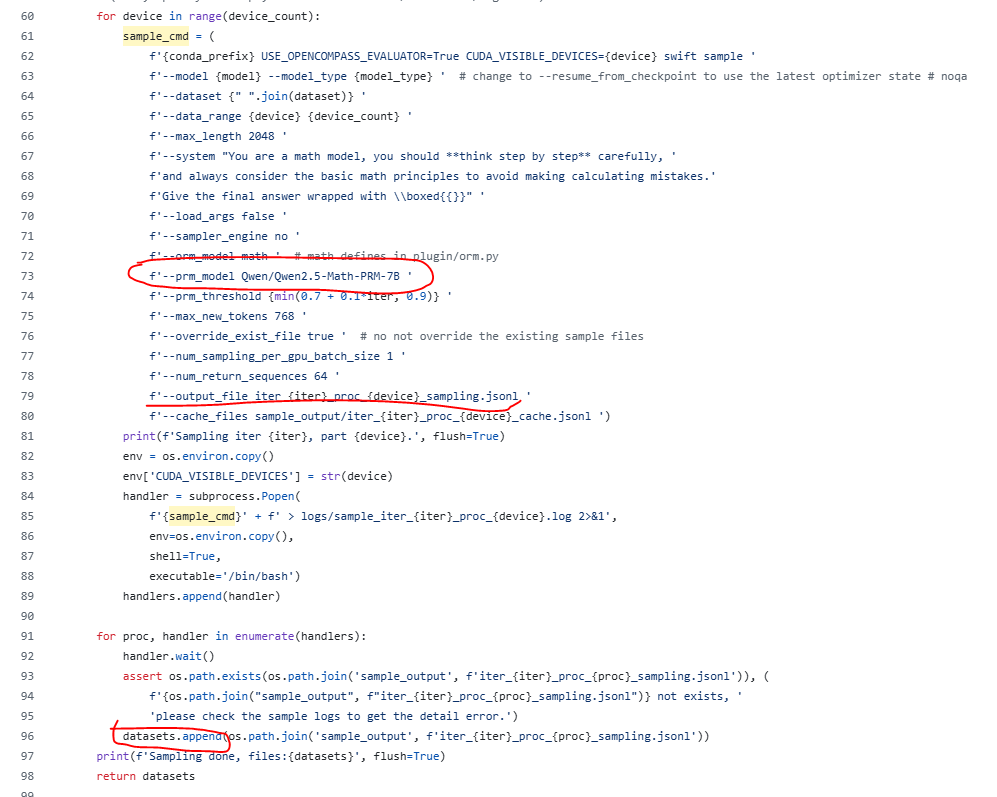
PRM模型和PRM_threshold如何配合形成采样数据集:



3.3 do_train训练函数
直接将rlhf的训练type写入启动脚本,开始强化微调:
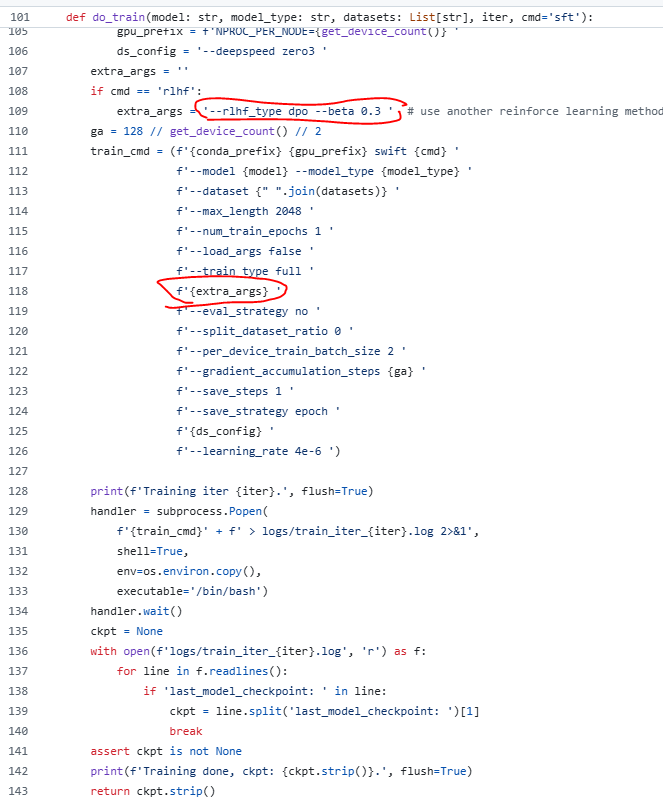
代码参考:https://github.com/modelscope/ms-swift/blob/main/examples/train/rft/rft.py
四、实际项目举例
闲下来再写吧 这个要记录自己的实验结果,我后续截图补充再写