K8s Pod CrashLoopBackOff:从镜像构建到探针配置的排查过程

K8s Pod CrashLoopBackOff:从镜像构建到探针配置的排查过程
🌟 Hello,我是摘星!
🌈 在彩虹般绚烂的技术栈中,我是那个永不停歇的色彩收集者。
🦋 每一个优化都是我培育的花朵,每一个特性都是我放飞的蝴蝶。
🔬 每一次代码审查都是我的显微镜观察,每一次重构都是我的化学实验。
🎵 在编程的交响乐中,我既是指挥家也是演奏者。让我们一起,在技术的音乐厅里,奏响属于程序员的华美乐章。
目录
K8s Pod CrashLoopBackOff:从镜像构建到探针配置的排查过程
摘要
1. CrashLoopBackOff 状态机制深度解析
1.1 状态转换机制
1.2 重启策略影响
2. 镜像构建层面的问题排查
2.1 基础镜像选择与构建优化
2.2 镜像构建验证脚本
2.3 镜像安全扫描
3. 容器运行时环境问题分析
3.1 资源限制配置
3.2 环境变量与配置管理
3.3 启动顺序与依赖管理
4. 健康检查探针配置优化
4.1 探针类型与配置策略
4.2 自定义健康检查端点
4.3 探针配置最佳实践
5. 系统性排查方法论
5.1 分层排查策略
5.2 问题分类与解决方案矩阵
5.3 自动化修复脚本
6. 监控与预警机制
6.1 Prometheus 监控配置
6.2 Grafana 仪表板配置
6.3 自动化响应机制
7. 最佳实践与预防措施
7.1 开发阶段最佳实践
7.2 CI/CD 集成检查
7.3 运维监控清单
总结
参考链接
关键词标签
摘要
作为一名在云原生领域摸爬滚打多年的工程师,我深知 CrashLoopBackOff 是 Kubernetes 运维中最令人头疼的问题之一。这个看似简单的状态背后,往往隐藏着复杂的技术细节和多层次的故障原因。在我的实际工作中,遇到过无数次 Pod 反复重启的场景,从最初的手忙脚乱到现在的有条不紊,这个过程让我深刻理解了容器化应用的生命周期管理。
CrashLoopBackOff 状态表示 Pod 中的容器反复崩溃并重启,Kubernetes 会采用指数退避策略来延长重启间隔,避免资源浪费。但这个状态的触发原因却千差万别:可能是镜像构建时的基础环境问题,可能是应用代码的逻辑错误,也可能是资源限制配置不当,更可能是健康检查探针的配置失误。
在我处理过的案例中,最复杂的一次涉及到微服务架构下的依赖链问题。一个看似独立的服务因为数据库连接池配置错误,导致启动时间过长,而我们设置的 livenessProbe 超时时间过短,形成了一个恶性循环。这个问题的排查过程让我意识到,解决 CrashLoopBackOff 不仅需要技术功底,更需要系统性的思维和全链路的分析能力。
本文将基于我的实战经验,从镜像构建的底层细节开始,逐步深入到容器运行时环境、资源配置、健康检查机制等各个层面,为大家提供一套完整的 CrashLoopBackOff 问题排查方法论。我会通过具体的代码示例、配置文件和排查命令,帮助大家建立起系统性的问题解决思路,让这个令人头疼的问题变得可控可解。
1. CrashLoopBackOff 状态机制深度解析
1.1 状态转换机制
CrashLoopBackOff 是 Kubernetes 中一个特殊的 Pod 状态,它表示容器在反复崩溃和重启。理解其状态转换机制是排查问题的基础。
# Pod 状态示例
apiVersion: v1
kind: Pod
metadata:name: crash-demo
spec:containers:- name: appimage: nginx:latestcommand: ["/bin/sh"]args: ["-c", "exit 1"] # 故意让容器退出restartPolicy: Always# 查看 Pod 状态变化
kubectl get pods -w
# 输出示例:
# NAME READY STATUS RESTARTS AGE
# crash-demo 0/1 CrashLoopBackOff 5 5mKubernetes 采用指数退避算法来控制重启间隔:
// 重启延迟计算逻辑(简化版)
func calculateBackoffDelay(restartCount int) time.Duration {// 基础延迟 10 秒baseDelay := 10 * time.Second// 最大延迟 5 分钟maxDelay := 300 * time.Second// 指数退避:10s, 20s, 40s, 80s, 160s, 300s...delay := baseDelay * time.Duration(1<<uint(restartCount))if delay > maxDelay {delay = maxDelay}return delay
}1.2 重启策略影响
不同的重启策略会影响 CrashLoopBackOff 的行为:
# 重启策略对比配置
apiVersion: v1
kind: Pod
metadata:name: restart-policy-demo
spec:# Always: 总是重启(默认)# OnFailure: 仅在失败时重启# Never: 从不重启restartPolicy: Alwayscontainers:- name: appimage: busyboxcommand: ["sh", "-c", "echo 'Starting...' && sleep 30 && exit 1"]图1:Pod 状态转换流程图
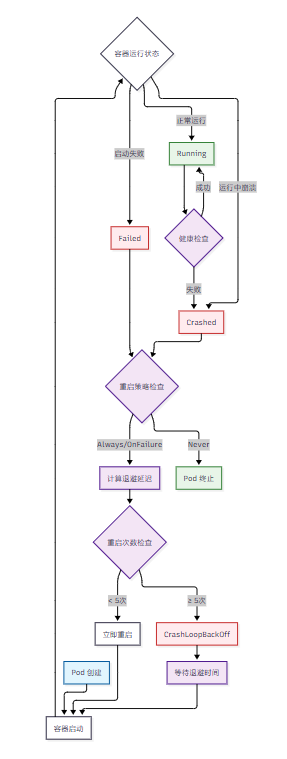
2. 镜像构建层面的问题排查
2.1 基础镜像选择与构建优化
镜像构建是容器运行的基础,错误的基础镜像选择或构建配置常常是 CrashLoopBackOff 的根源。
# 问题示例:使用了不兼容的基础镜像
FROM alpine:3.18
COPY app /usr/local/bin/app
CMD ["/usr/local/bin/app"]# 问题:Alpine 使用 musl libc,而应用可能是基于 glibc 编译的# 优化后的 Dockerfile
FROM ubuntu:20.04 as builder# 安装构建依赖
RUN apt-get update && apt-get install -y \gcc \libc6-dev \&& rm -rf /var/lib/apt/lists/*# 编译应用
COPY src/ /src/
WORKDIR /src
RUN gcc -o app main.c# 多阶段构建,减小镜像体积
FROM ubuntu:20.04
RUN apt-get update && apt-get install -y \ca-certificates \&& rm -rf /var/lib/apt/lists/* \&& groupadd -r appuser \&& useradd -r -g appuser appuserCOPY --from=builder /src/app /usr/local/bin/app
RUN chmod +x /usr/local/bin/app# 使用非 root 用户运行
USER appuser
EXPOSE 8080# 添加健康检查
HEALTHCHECK --interval=30s --timeout=3s --start-period=5s --retries=3 \CMD curl -f http://localhost:8080/health || exit 1CMD ["/usr/local/bin/app"]2.2 镜像构建验证脚本
#!/bin/bash
# build-and-test.sh - 镜像构建验证脚本set -eIMAGE_NAME="myapp:latest"
CONTAINER_NAME="test-container"echo "🔨 构建镜像..."
docker build -t $IMAGE_NAME .echo "🧪 测试镜像基本功能..."
# 测试容器能否正常启动
docker run --name $CONTAINER_NAME -d $IMAGE_NAME# 等待容器启动
sleep 5# 检查容器状态
if docker ps | grep -q $CONTAINER_NAME; thenecho "✅ 容器启动成功"
elseecho "❌ 容器启动失败"docker logs $CONTAINER_NAMEexit 1
fi# 测试健康检查
echo "🏥 测试健康检查..."
for i in {1..10}; doif docker exec $CONTAINER_NAME curl -f http://localhost:8080/health; thenecho "✅ 健康检查通过"breakelseecho "⏳ 等待应用启动... ($i/10)"sleep 3fi
done# 清理测试容器
docker stop $CONTAINER_NAME
docker rm $CONTAINER_NAMEecho "🎉 镜像构建验证完成"2.3 镜像安全扫描
# .github/workflows/image-scan.yml
name: Image Security Scan
on:push:branches: [main]pull_request:branches: [main]jobs:scan:runs-on: ubuntu-lateststeps:- uses: actions/checkout@v3- name: Build imagerun: docker build -t myapp:${{ github.sha }} .- name: Run Trivy vulnerability scanneruses: aquasecurity/trivy-action@masterwith:image-ref: 'myapp:${{ github.sha }}'format: 'sarif'output: 'trivy-results.sarif'- name: Upload Trivy scan resultsuses: github/codeql-action/upload-sarif@v2with:sarif_file: 'trivy-results.sarif'图2:镜像构建流程架构图
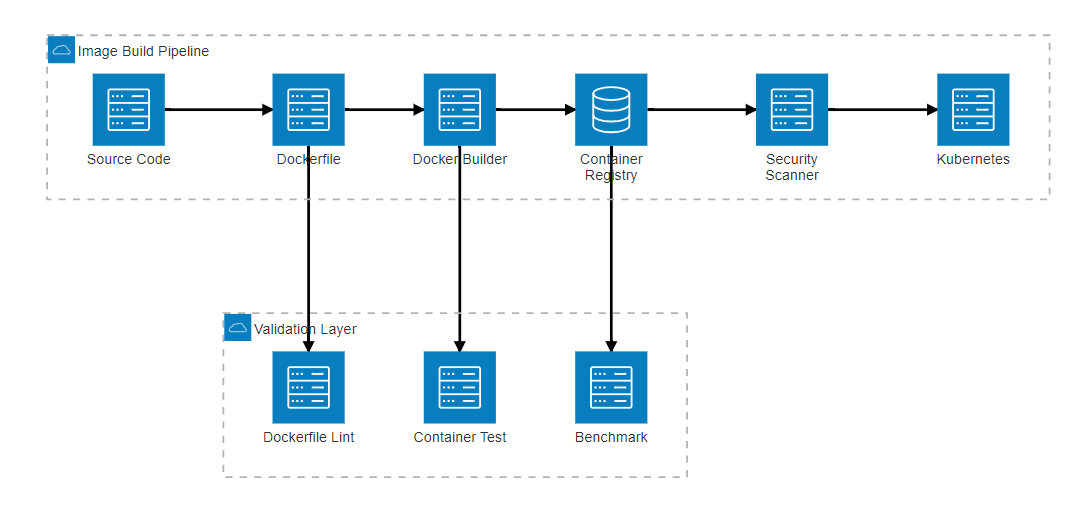
3. 容器运行时环境问题分析
3.1 资源限制配置
资源限制配置不当是导致 CrashLoopBackOff 的常见原因,特别是内存限制过低或 CPU 限制过严格。
# 资源配置示例
apiVersion: apps/v1
kind: Deployment
metadata:name: resource-demo
spec:replicas: 3selector:matchLabels:app: resource-demotemplate:metadata:labels:app: resource-demospec:containers:- name: appimage: myapp:latestresources:requests:# 请求资源:调度时的最小保证memory: "128Mi"cpu: "100m"limits:# 限制资源:运行时的最大允许memory: "512Mi"cpu: "500m"env:- name: JAVA_OPTSvalue: "-Xmx400m -Xms128m" # JVM 堆内存不能超过容器内存限制3.2 环境变量与配置管理
# ConfigMap 配置管理
apiVersion: v1
kind: ConfigMap
metadata:name: app-config
data:application.properties: |server.port=8080spring.datasource.url=jdbc:mysql://mysql:3306/mydbspring.datasource.username=userspring.datasource.password=passwordlogging.level.root=INFO---
apiVersion: v1
kind: Secret
metadata:name: app-secrets
type: Opaque
data:# base64 编码的敏感信息db-password: cGFzc3dvcmQ=api-key: YWJjZGVmZ2hpams=---
apiVersion: apps/v1
kind: Deployment
metadata:name: app-with-config
spec:template:spec:containers:- name: appimage: myapp:latestenvFrom:- configMapRef:name: app-config- secretRef:name: app-secretsvolumeMounts:- name: config-volumemountPath: /etc/config- name: secret-volumemountPath: /etc/secretsreadOnly: truevolumes:- name: config-volumeconfigMap:name: app-config- name: secret-volumesecret:secretName: app-secrets3.3 启动顺序与依赖管理
# Init Container 处理依赖
apiVersion: apps/v1
kind: Deployment
metadata:name: app-with-deps
spec:template:spec:initContainers:# 等待数据库就绪- name: wait-for-dbimage: busybox:1.35command: ['sh', '-c']args:- |echo "等待数据库启动..."until nc -z mysql 3306; doecho "数据库未就绪,等待 5 秒..."sleep 5doneecho "数据库已就绪"# 数据库迁移- name: db-migrationimage: migrate/migrate:v4.15.2command: ["/migrate"]args:- "-path=/migrations"- "-database=mysql://user:password@mysql:3306/mydb"- "up"volumeMounts:- name: migrationsmountPath: /migrationscontainers:- name: appimage: myapp:latest# 应用容器配置...volumes:- name: migrationsconfigMap:name: db-migrations图3:容器资源使用分布饼图
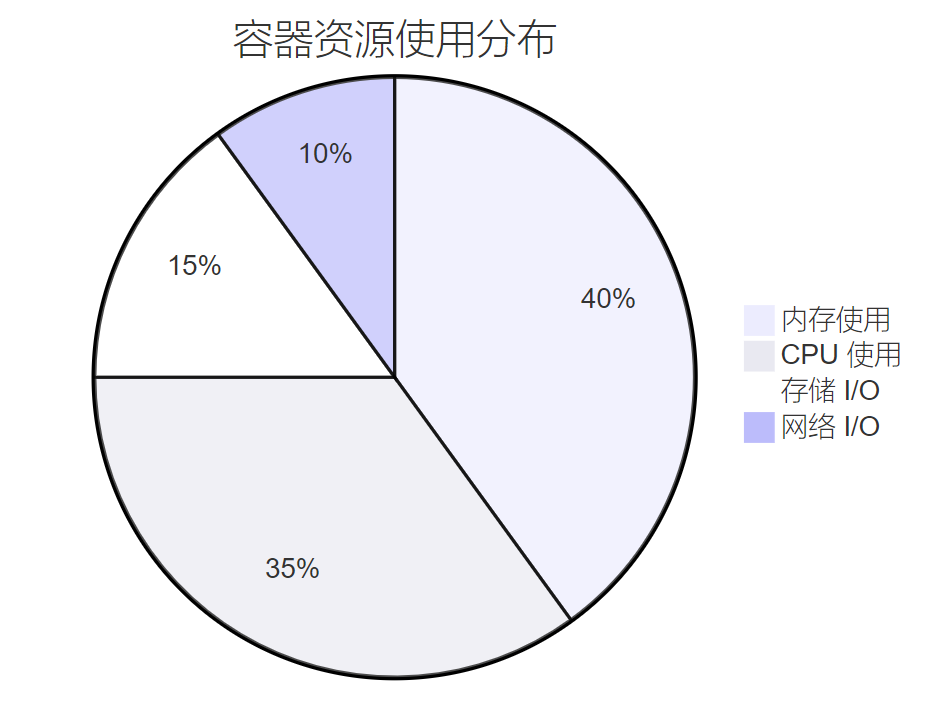
4. 健康检查探针配置优化
4.1 探针类型与配置策略
Kubernetes 提供三种类型的探针,每种都有其特定的用途和配置要点。
# 完整的探针配置示例
apiVersion: apps/v1
kind: Deployment
metadata:name: probe-demo
spec:template:spec:containers:- name: appimage: myapp:latestports:- containerPort: 8080# 启动探针:确保容器成功启动startupProbe:httpGet:path: /actuator/health/readinessport: 8080initialDelaySeconds: 10 # 首次检查延迟periodSeconds: 5 # 检查间隔timeoutSeconds: 3 # 超时时间failureThreshold: 30 # 失败阈值(总启动时间 = 30 * 5 = 150s)successThreshold: 1 # 成功阈值# 存活探针:检测容器是否需要重启livenessProbe:httpGet:path: /actuator/health/livenessport: 8080initialDelaySeconds: 30periodSeconds: 10timeoutSeconds: 5failureThreshold: 3 # 连续 3 次失败后重启successThreshold: 1# 就绪探针:检测容器是否准备好接收流量readinessProbe:httpGet:path: /actuator/health/readinessport: 8080initialDelaySeconds: 5periodSeconds: 5timeoutSeconds: 3failureThreshold: 3successThreshold: 14.2 自定义健康检查端点
// Spring Boot 健康检查实现
@RestController
@RequestMapping("/actuator/health")
public class HealthController {@Autowiredprivate DatabaseHealthIndicator databaseHealth;@Autowiredprivate RedisHealthIndicator redisHealth;// 存活探针端点 - 检查应用基本功能@GetMapping("/liveness")public ResponseEntity<Map<String, Object>> liveness() {Map<String, Object> response = new HashMap<>();try {// 检查关键组件状态boolean isHealthy = checkCriticalComponents();if (isHealthy) {response.put("status", "UP");response.put("timestamp", Instant.now());return ResponseEntity.ok(response);} else {response.put("status", "DOWN");response.put("reason", "Critical component failure");return ResponseEntity.status(503).body(response);}} catch (Exception e) {response.put("status", "DOWN");response.put("error", e.getMessage());return ResponseEntity.status(503).body(response);}}// 就绪探针端点 - 检查是否准备好处理请求@GetMapping("/readiness")public ResponseEntity<Map<String, Object>> readiness() {Map<String, Object> response = new HashMap<>();Map<String, String> checks = new HashMap<>();// 检查数据库连接boolean dbReady = databaseHealth.isHealthy();checks.put("database", dbReady ? "UP" : "DOWN");// 检查 Redis 连接boolean redisReady = redisHealth.isHealthy();checks.put("redis", redisReady ? "UP" : "DOWN");// 检查外部依赖boolean externalReady = checkExternalDependencies();checks.put("external", externalReady ? "UP" : "DOWN");boolean allReady = dbReady && redisReady && externalReady;response.put("status", allReady ? "UP" : "DOWN");response.put("checks", checks);response.put("timestamp", Instant.now());return allReady ? ResponseEntity.ok(response) : ResponseEntity.status(503).body(response);}private boolean checkCriticalComponents() {// 检查 JVM 内存使用率MemoryMXBean memoryBean = ManagementFactory.getMemoryMXBean();MemoryUsage heapUsage = memoryBean.getHeapMemoryUsage();double memoryUsageRatio = (double) heapUsage.getUsed() / heapUsage.getMax();if (memoryUsageRatio > 0.9) {log.warn("Memory usage too high: {}%", memoryUsageRatio * 100);return false;}return true;}private boolean checkExternalDependencies() {// 检查外部 API 可用性try {RestTemplate restTemplate = new RestTemplate();ResponseEntity<String> response = restTemplate.getForEntity("http://external-api/health", String.class);return response.getStatusCode().is2xxSuccessful();} catch (Exception e) {log.warn("External API health check failed", e);return false;}}
}4.3 探针配置最佳实践
#!/bin/bash
# probe-tuning.sh - 探针配置调优脚本# 获取 Pod 启动时间统计
get_startup_stats() {local deployment=$1echo "📊 分析 $deployment 的启动时间..."kubectl get pods -l app=$deployment -o json | jq -r '.items[] | select(.status.phase == "Running") |{name: .metadata.name,created: .metadata.creationTimestamp,started: (.status.containerStatuses[0].state.running.startedAt // "N/A"),ready: (.status.conditions[] | select(.type == "Ready") | .lastTransitionTime)} | "\(.name): 创建=\(.created), 启动=\(.started), 就绪=\(.ready)"'
}# 分析探针失败原因
analyze_probe_failures() {local pod=$1echo "🔍 分析 $pod 的探针失败..."# 获取事件信息kubectl describe pod $pod | grep -A 5 -B 5 "probe failed"# 获取容器日志echo "📋 容器日志:"kubectl logs $pod --tail=50# 检查资源使用情况echo "💾 资源使用情况:"kubectl top pod $pod
}# 探针配置建议
suggest_probe_config() {local app_type=$1case $app_type in"spring-boot")cat << EOF
建议的 Spring Boot 应用探针配置:startupProbe:httpGet:path: /actuator/healthport: 8080initialDelaySeconds: 30periodSeconds: 10timeoutSeconds: 5failureThreshold: 18 # 3 分钟启动时间livenessProbe:httpGet:path: /actuator/health/livenessport: 8080initialDelaySeconds: 60periodSeconds: 30timeoutSeconds: 10failureThreshold: 3readinessProbe:httpGet:path: /actuator/health/readinessport: 8080initialDelaySeconds: 10periodSeconds: 5timeoutSeconds: 3failureThreshold: 3
EOF;;"nodejs")cat << EOF
建议的 Node.js 应用探针配置:startupProbe:httpGet:path: /healthport: 3000initialDelaySeconds: 10periodSeconds: 5timeoutSeconds: 3failureThreshold: 12 # 1 分钟启动时间livenessProbe:httpGet:path: /healthport: 3000initialDelaySeconds: 30periodSeconds: 15timeoutSeconds: 5failureThreshold: 3readinessProbe:httpGet:path: /readyport: 3000initialDelaySeconds: 5periodSeconds: 5timeoutSeconds: 3failureThreshold: 3
EOF;;esac
}# 主函数
main() {case $1 in"stats")get_startup_stats $2;;"analyze")analyze_probe_failures $2;;"suggest")suggest_probe_config $2;;*)echo "用法: $0 {stats|analyze|suggest} [参数]"echo " stats <deployment> - 获取启动时间统计"echo " analyze <pod> - 分析探针失败原因"echo " suggest <app-type> - 获取探针配置建议";;esac
}main "$@"图4:健康检查探针时序图
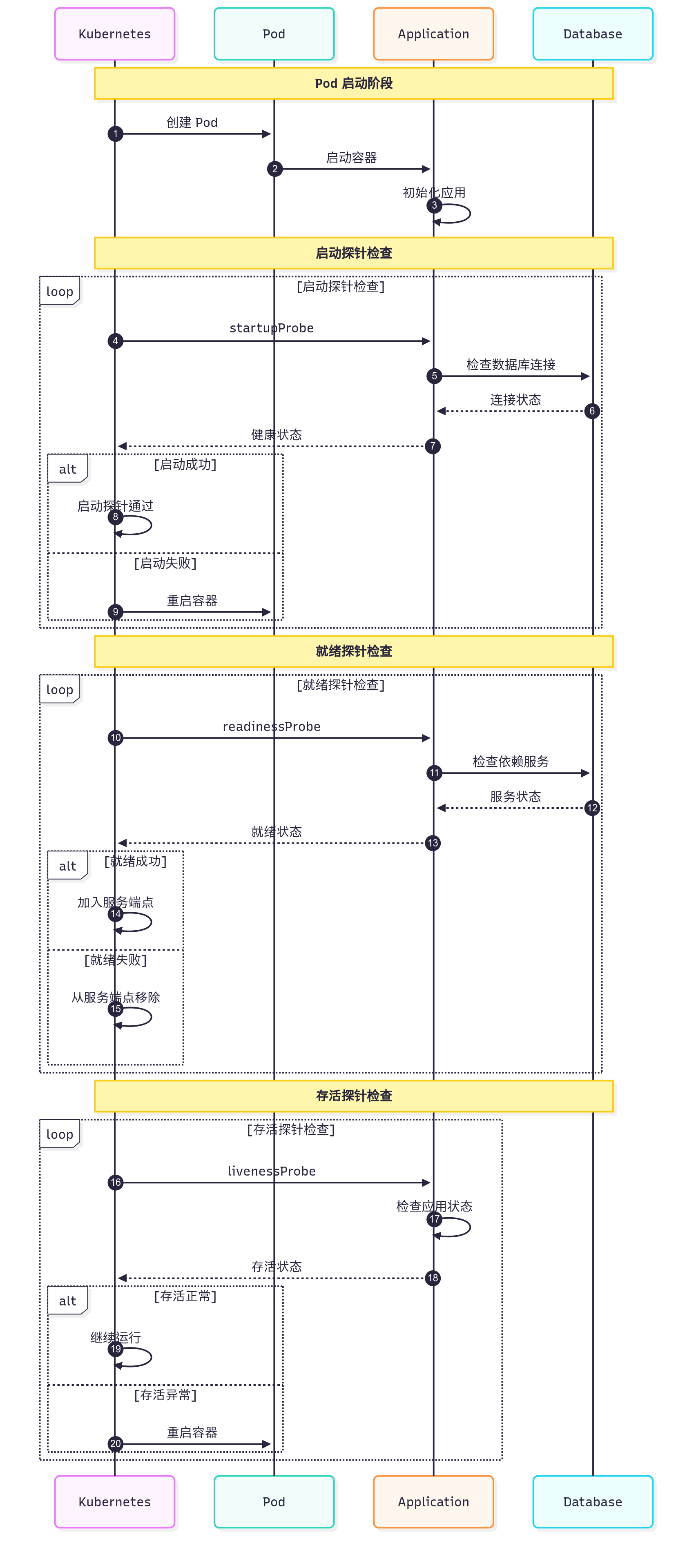
5. 系统性排查方法论
5.1 分层排查策略
建立系统性的排查方法论是快速定位 CrashLoopBackOff 问题的关键。
#!/bin/bash
# crash-diagnosis.sh - CrashLoopBackOff 系统性排查脚本set -ePOD_NAME=""
NAMESPACE="default"
VERBOSE=false# 解析命令行参数
while [[ $# -gt 0 ]]; docase $1 in-p|--pod)POD_NAME="$2"shift 2;;-n|--namespace)NAMESPACE="$2"shift 2;;-v|--verbose)VERBOSE=trueshift;;*)echo "未知参数: $1"exit 1;;esac
doneif [[ -z "$POD_NAME" ]]; thenecho "用法: $0 -p <pod-name> [-n <namespace>] [-v]"exit 1
fiecho "🔍 开始排查 Pod: $POD_NAME (namespace: $NAMESPACE)"
echo "=================================================="# 1. 基础信息收集
collect_basic_info() {echo "📋 1. 收集基础信息"echo "-------------------"# Pod 状态echo "Pod 状态:"kubectl get pod $POD_NAME -n $NAMESPACE -o wide# Pod 详细信息echo -e "\nPod 详细信息:"kubectl describe pod $POD_NAME -n $NAMESPACE# 重启次数统计echo -e "\n重启统计:"kubectl get pod $POD_NAME -n $NAMESPACE -o jsonpath='{.status.containerStatuses[*].restartCount}' | \awk '{print "重启次数: " $1}'
}# 2. 日志分析
analyze_logs() {echo -e "\n📝 2. 日志分析"echo "---------------"# 当前容器日志echo "当前容器日志 (最近 50 行):"kubectl logs $POD_NAME -n $NAMESPACE --tail=50# 前一个容器日志(如果存在)echo -e "\n前一个容器日志 (最近 50 行):"kubectl logs $POD_NAME -n $NAMESPACE --previous --tail=50 2>/dev/null || \echo "无前一个容器日志"
}# 3. 资源使用分析
analyze_resources() {echo -e "\n💾 3. 资源使用分析"echo "-------------------"# 资源配置echo "资源配置:"kubectl get pod $POD_NAME -n $NAMESPACE -o jsonpath='{.spec.containers[*].resources}' | jq .# 实际资源使用echo -e "\n实际资源使用:"kubectl top pod $POD_NAME -n $NAMESPACE 2>/dev/null || \echo "无法获取资源使用数据(需要 metrics-server)"# 节点资源状态NODE=$(kubectl get pod $POD_NAME -n $NAMESPACE -o jsonpath='{.spec.nodeName}')if [[ -n "$NODE" ]]; thenecho -e "\n节点 $NODE 资源状态:"kubectl describe node $NODE | grep -A 5 "Allocated resources"fi
}# 4. 网络连接检查
check_network() {echo -e "\n🌐 4. 网络连接检查"echo "-------------------"# Service 配置echo "相关 Service:"kubectl get svc -n $NAMESPACE --field-selector metadata.name=$POD_NAME 2>/dev/null || \echo "未找到对应的 Service"# Endpoint 状态echo -e "\nEndpoint 状态:"kubectl get endpoints -n $NAMESPACE 2>/dev/null | grep $POD_NAME || \echo "未找到对应的 Endpoints"# 网络策略echo -e "\n网络策略:"kubectl get networkpolicy -n $NAMESPACE 2>/dev/null || \echo "未配置网络策略"
}# 5. 配置检查
check_configuration() {echo -e "\n⚙️ 5. 配置检查"echo "----------------"# ConfigMapecho "ConfigMap:"kubectl get configmap -n $NAMESPACE 2>/dev/null | head -10# Secretecho -e "\nSecret:"kubectl get secret -n $NAMESPACE 2>/dev/null | head -10# 环境变量echo -e "\n环境变量:"kubectl get pod $POD_NAME -n $NAMESPACE -o jsonpath='{.spec.containers[*].env}' | jq .
}# 6. 事件分析
analyze_events() {echo -e "\n📅 6. 事件分析"echo "---------------"# Pod 相关事件echo "Pod 相关事件:"kubectl get events -n $NAMESPACE --field-selector involvedObject.name=$POD_NAME \--sort-by='.lastTimestamp' | tail -20# 节点相关事件NODE=$(kubectl get pod $POD_NAME -n $NAMESPACE -o jsonpath='{.spec.nodeName}')if [[ -n "$NODE" ]]; thenecho -e "\n节点 $NODE 相关事件:"kubectl get events --field-selector involvedObject.name=$NODE \--sort-by='.lastTimestamp' | tail -10fi
}# 7. 生成诊断报告
generate_report() {echo -e "\n📊 7. 诊断建议"echo "==============="# 分析重启原因RESTART_COUNT=$(kubectl get pod $POD_NAME -n $NAMESPACE -o jsonpath='{.status.containerStatuses[0].restartCount}')LAST_STATE=$(kubectl get pod $POD_NAME -n $NAMESPACE -o jsonpath='{.status.containerStatuses[0].lastState}')echo "重启次数: $RESTART_COUNT"echo "最后状态: $LAST_STATE"# 常见问题检查echo -e "\n🔧 常见问题检查:"# 检查镜像拉取IMAGE_PULL_POLICY=$(kubectl get pod $POD_NAME -n $NAMESPACE -o jsonpath='{.spec.containers[0].imagePullPolicy}')echo "- 镜像拉取策略: $IMAGE_PULL_POLICY"# 检查探针配置LIVENESS_PROBE=$(kubectl get pod $POD_NAME -n $NAMESPACE -o jsonpath='{.spec.containers[0].livenessProbe}')if [[ -n "$LIVENESS_PROBE" ]]; thenecho "- 存活探针: 已配置"elseecho "- 存活探针: 未配置"fiREADINESS_PROBE=$(kubectl get pod $POD_NAME -n $NAMESPACE -o jsonpath='{.spec.containers[0].readinessProbe}')if [[ -n "$READINESS_PROBE" ]]; thenecho "- 就绪探针: 已配置"elseecho "- 就绪探针: 未配置"fi# 资源限制检查MEMORY_LIMIT=$(kubectl get pod $POD_NAME -n $NAMESPACE -o jsonpath='{.spec.containers[0].resources.limits.memory}')CPU_LIMIT=$(kubectl get pod $POD_NAME -n $NAMESPACE -o jsonpath='{.spec.containers[0].resources.limits.cpu}')if [[ -n "$MEMORY_LIMIT" ]]; thenecho "- 内存限制: $MEMORY_LIMIT"elseecho "- 内存限制: 未设置(可能导致 OOM)"fiif [[ -n "$CPU_LIMIT" ]]; thenecho "- CPU 限制: $CPU_LIMIT"elseecho "- CPU 限制: 未设置"fi
}# 主执行流程
main() {collect_basic_infoanalyze_logsanalyze_resourcescheck_networkcheck_configurationanalyze_eventsgenerate_reportecho -e "\n✅ 排查完成!"echo "建议根据以上信息分析问题原因,并参考相应的解决方案。"
}# 执行主函数
main5.2 问题分类与解决方案矩阵
| 问题类型 | 症状表现 | 排查重点 | 解决方案 |
| 镜像问题 | ImagePullBackOff → CrashLoopBackOff | 镜像标签、仓库权限、网络连接 | 修复镜像构建、更新拉取凭证 |
| 资源不足 | OOMKilled、CPU 节流 | 内存/CPU 使用率、节点资源 | 调整资源限制、扩容节点 |
| 配置错误 | 环境变量、挂载失败 | ConfigMap、Secret、Volume | 修正配置文件、检查挂载路径 |
| 依赖服务 | 连接超时、服务不可达 | 网络连接、DNS 解析 | 修复依赖服务、调整超时配置 |
| 探针配置 | 健康检查失败 | 探针端点、超时设置 | 优化探针参数、修复健康检查 |
5.3 自动化修复脚本
#!/bin/bash
# auto-fix.sh - 自动修复常见 CrashLoopBackOff 问题fix_common_issues() {local deployment=$1local namespace=${2:-default}echo "🔧 尝试自动修复 $deployment 的常见问题..."# 1. 增加资源限制echo "1. 调整资源限制..."kubectl patch deployment $deployment -n $namespace -p '{"spec": {"template": {"spec": {"containers": [{"name": "'$deployment'","resources": {"requests": {"memory": "256Mi","cpu": "200m"},"limits": {"memory": "512Mi","cpu": "500m"}}}]}}}}'# 2. 调整探针配置echo "2. 优化探针配置..."kubectl patch deployment $deployment -n $namespace -p '{"spec": {"template": {"spec": {"containers": [{"name": "'$deployment'","livenessProbe": {"initialDelaySeconds": 60,"periodSeconds": 30,"timeoutSeconds": 10,"failureThreshold": 5},"readinessProbe": {"initialDelaySeconds": 10,"periodSeconds": 5,"timeoutSeconds": 3,"failureThreshold": 3}}]}}}}'# 3. 添加启动探针echo "3. 添加启动探针..."kubectl patch deployment $deployment -n $namespace -p '{"spec": {"template": {"spec": {"containers": [{"name": "'$deployment'","startupProbe": {"httpGet": {"path": "/health","port": 8080},"initialDelaySeconds": 10,"periodSeconds": 5,"timeoutSeconds": 3,"failureThreshold": 30}}]}}}}'echo "✅ 自动修复完成,等待 Pod 重新部署..."kubectl rollout status deployment/$deployment -n $namespace
}# 使用示例
# ./auto-fix.sh my-app production
fix_common_issues "$@"6. 监控与预警机制
6.1 Prometheus 监控配置
# prometheus-rules.yml
apiVersion: monitoring.coreos.com/v1
kind: PrometheusRule
metadata:name: crashloopbackoff-alertsnamespace: monitoring
spec:groups:- name: crashloopbackoff.rulesrules:# CrashLoopBackOff 告警- alert: PodCrashLoopBackOffexpr: |rate(kube_pod_container_status_restarts_total[15m]) * 60 * 15 > 0andkube_pod_container_status_waiting_reason{reason="CrashLoopBackOff"} == 1for: 5mlabels:severity: criticalcategory: availabilityannotations:summary: "Pod {{ $labels.namespace }}/{{ $labels.pod }} 处于 CrashLoopBackOff 状态"description: |Pod {{ $labels.namespace }}/{{ $labels.pod }} 在过去 15 分钟内重启了 {{ $value }} 次,当前处于 CrashLoopBackOff 状态。排查步骤:1. 检查 Pod 日志: kubectl logs {{ $labels.pod }} -n {{ $labels.namespace }}2. 检查 Pod 事件: kubectl describe pod {{ $labels.pod }} -n {{ $labels.namespace }}3. 检查资源使用: kubectl top pod {{ $labels.pod }} -n {{ $labels.namespace }}# 高重启率告警- alert: HighPodRestartRateexpr: |rate(kube_pod_container_status_restarts_total[1h]) * 3600 > 5for: 10mlabels:severity: warningcategory: stabilityannotations:summary: "Pod {{ $labels.namespace }}/{{ $labels.pod }} 重启频率过高"description: |Pod {{ $labels.namespace }}/{{ $labels.pod }} 在过去 1 小时内重启了 {{ $value }} 次,重启频率异常,需要关注。# 探针失败告警- alert: PodProbeFailureexpr: |kube_pod_container_status_waiting_reason{reason=~".*Probe.*"} == 1for: 3mlabels:severity: warningcategory: health-checkannotations:summary: "Pod {{ $labels.namespace }}/{{ $labels.pod }} 探针检查失败"description: |Pod {{ $labels.namespace }}/{{ $labels.pod }} 的健康检查探针失败,原因: {{ $labels.reason }}6.2 Grafana 仪表板配置
{"dashboard": {"title": "CrashLoopBackOff 监控仪表板","panels": [{"title": "Pod 重启趋势","type": "graph","targets": [{"expr": "rate(kube_pod_container_status_restarts_total[5m])","legendFormat": "{{namespace}}/{{pod}}"}]},{"title": "CrashLoopBackOff Pod 数量","type": "stat","targets": [{"expr": "count(kube_pod_container_status_waiting_reason{reason=\"CrashLoopBackOff\"})"}]},{"title": "探针失败分布","type": "piechart","targets": [{"expr": "count by (reason) (kube_pod_container_status_waiting_reason{reason=~\".*Probe.*\"})"}]}]}
}6.3 自动化响应机制
# auto_response.py - 自动化响应脚本
import time
import logging
from kubernetes import client, config
from prometheus_api_client import PrometheusConnectclass CrashLoopBackOffHandler:def __init__(self):config.load_incluster_config() # 或 load_kube_config()self.k8s_client = client.CoreV1Api()self.apps_client = client.AppsV1Api()self.prometheus = PrometheusConnect(url="http://prometheus:9090")logging.basicConfig(level=logging.INFO)self.logger = logging.getLogger(__name__)def detect_crashloop_pods(self):"""检测处于 CrashLoopBackOff 状态的 Pod"""query = 'kube_pod_container_status_waiting_reason{reason="CrashLoopBackOff"} == 1'result = self.prometheus.custom_query(query=query)crashloop_pods = []for item in result:pod_info = {'name': item['metric']['pod'],'namespace': item['metric']['namespace'],'container': item['metric']['container']}crashloop_pods.append(pod_info)return crashloop_podsdef analyze_pod_issues(self, pod_name, namespace):"""分析 Pod 问题"""try:# 获取 Pod 详细信息pod = self.k8s_client.read_namespaced_pod(name=pod_name, namespace=namespace)issues = []# 检查资源限制for container in pod.spec.containers:if not container.resources or not container.resources.limits:issues.append("missing_resource_limits")# 检查探针配置if not container.liveness_probe:issues.append("missing_liveness_probe")if not container.readiness_probe:issues.append("missing_readiness_probe")# 检查重启次数if pod.status.container_statuses:for status in pod.status.container_statuses:if status.restart_count > 10:issues.append("high_restart_count")return issuesexcept Exception as e:self.logger.error(f"分析 Pod {pod_name} 时出错: {e}")return []def auto_fix_pod(self, pod_name, namespace, issues):"""自动修复 Pod 问题"""try:# 获取对应的 Deploymentpods = self.k8s_client.list_namespaced_pod(namespace=namespace)deployment_name = Nonefor pod in pods.items:if pod.metadata.name.startswith(pod_name.rsplit('-', 2)[0]):if pod.metadata.owner_references:for ref in pod.metadata.owner_references:if ref.kind == "ReplicaSet":rs = self.apps_client.read_namespaced_replica_set(name=ref.name, namespace=namespace)if rs.metadata.owner_references:for rs_ref in rs.metadata.owner_references:if rs_ref.kind == "Deployment":deployment_name = rs_ref.namebreakbreakif not deployment_name:self.logger.warning(f"未找到 Pod {pod_name} 对应的 Deployment")return False# 应用修复deployment = self.apps_client.read_namespaced_deployment(name=deployment_name, namespace=namespace)modified = False# 修复资源限制问题if "missing_resource_limits" in issues:for container in deployment.spec.template.spec.containers:if not container.resources:container.resources = client.V1ResourceRequirements()container.resources.limits = {"memory": "512Mi","cpu": "500m"}container.resources.requests = {"memory": "256Mi","cpu": "200m"}modified = True# 修复探针问题if "missing_liveness_probe" in issues:for container in deployment.spec.template.spec.containers:container.liveness_probe = client.V1Probe(http_get=client.V1HTTPGetAction(path="/health",port=8080),initial_delay_seconds=60,period_seconds=30,timeout_seconds=10,failure_threshold=3)modified = Trueif modified:self.apps_client.patch_namespaced_deployment(name=deployment_name,namespace=namespace,body=deployment)self.logger.info(f"已自动修复 Deployment {deployment_name}")return Trueexcept Exception as e:self.logger.error(f"自动修复 Pod {pod_name} 时出错: {e}")return Falsedef run(self):"""主运行循环"""self.logger.info("启动 CrashLoopBackOff 自动处理程序")while True:try:# 检测问题 Podcrashloop_pods = self.detect_crashloop_pods()for pod_info in crashloop_pods:self.logger.info(f"发现 CrashLoopBackOff Pod: "f"{pod_info['namespace']}/{pod_info['name']}")# 分析问题issues = self.analyze_pod_issues(pod_info['name'], pod_info['namespace'])if issues:self.logger.info(f"检测到问题: {issues}")# 尝试自动修复if self.auto_fix_pod(pod_info['name'], pod_info['namespace'], issues):self.logger.info("自动修复成功")else:self.logger.warning("自动修复失败,需要人工介入")# 等待下一次检查time.sleep(60)except Exception as e:self.logger.error(f"运行时出错: {e}")time.sleep(30)if __name__ == "__main__":handler = CrashLoopBackOffHandler()handler.run()图5:监控告警流程时序图
7. 最佳实践与预防措施
7.1 开发阶段最佳实践
# 开发环境 Pod 模板
apiVersion: v1
kind: Pod
metadata:name: dev-best-practicesannotations:# 添加有意义的注解description: "开发环境最佳实践示例"version: "1.0.0"maintainer: "dev-team@company.com"
spec:# 使用非 root 用户securityContext:runAsNonRoot: truerunAsUser: 1000runAsGroup: 1000fsGroup: 1000containers:- name: appimage: myapp:v1.0.0 # 使用具体版本标签,避免 latest# 明确指定资源需求resources:requests:memory: "128Mi"cpu: "100m"limits:memory: "512Mi"cpu: "500m"# 配置完整的探针startupProbe:httpGet:path: /actuator/health/readinessport: 8080initialDelaySeconds: 10periodSeconds: 5timeoutSeconds: 3failureThreshold: 30livenessProbe:httpGet:path: /actuator/health/livenessport: 8080initialDelaySeconds: 60periodSeconds: 30timeoutSeconds: 10failureThreshold: 3readinessProbe:httpGet:path: /actuator/health/readinessport: 8080initialDelaySeconds: 5periodSeconds: 5timeoutSeconds: 3failureThreshold: 3# 优雅关闭配置lifecycle:preStop:exec:command: ["/bin/sh", "-c", "sleep 15"]# 环境变量配置env:- name: SPRING_PROFILES_ACTIVEvalue: "development"- name: JVM_OPTSvalue: "-Xmx400m -Xms128m -XX:+UseG1GC"# 挂载配置volumeMounts:- name: configmountPath: /etc/configreadOnly: true- name: logsmountPath: /var/log/appvolumes:- name: configconfigMap:name: app-config- name: logsemptyDir: {}# 重启策略restartPolicy: Always# 容忍度配置tolerations:- key: "node.kubernetes.io/not-ready"operator: "Exists"effect: "NoExecute"tolerationSeconds: 3007.2 CI/CD 集成检查
# .github/workflows/k8s-validation.yml
name: Kubernetes Validation
on:pull_request:paths:- 'k8s/**'- 'Dockerfile'jobs:validate-k8s:runs-on: ubuntu-lateststeps:- uses: actions/checkout@v3- name: Validate Kubernetes manifestsrun: |# 安装 kubevalwget https://github.com/instrumenta/kubeval/releases/latest/download/kubeval-linux-amd64.tar.gztar xf kubeval-linux-amd64.tar.gzsudo mv kubeval /usr/local/bin# 验证 YAML 语法find k8s/ -name "*.yaml" -o -name "*.yml" | xargs kubeval- name: Check resource limitsrun: |# 检查是否设置了资源限制if ! grep -r "limits:" k8s/; thenecho "❌ 未找到资源限制配置"exit 1fiecho "✅ 资源限制配置检查通过"- name: Check probes configurationrun: |# 检查探针配置if ! grep -r "livenessProbe:" k8s/; thenecho "⚠️ 建议配置存活探针"fiif ! grep -r "readinessProbe:" k8s/; thenecho "⚠️ 建议配置就绪探针"fiecho "✅ 探针配置检查完成"- name: Security scanuses: azure/k8s-lint@v1with:manifests: |k8s/deployment.yamlk8s/service.yaml7.3 运维监控清单
CrashLoopBackOff 预防清单
📋 镜像构建阶段
- 使用稳定的基础镜像版本
- 多阶段构建优化镜像大小
- 安全扫描通过
- 健康检查端点实现
🔧 配置管理阶段
- 资源请求和限制合理设置
- 探针参数根据应用特性调优
- 环境变量和配置文件正确
- 依赖服务连接配置验证
📊 监控告警阶段
- Pod 重启率监控
- 资源使用率监控
- 探针失败率监控
- 自动化响应机制
总结
经过多年的云原生实践,我深刻体会到 CrashLoopBackOff 问题的复杂性和多样性。这个看似简单的状态背后,往往涉及到容器化应用的方方面面:从底层的镜像构建到上层的业务逻辑,从资源配置到网络连接,从健康检查到依赖管理。每一个环节的疏忽都可能导致 Pod 陷入无限重启的循环。
在我处理过的众多案例中,最让我印象深刻的是一次生产环境的故障。一个微服务因为数据库连接池配置错误,启动时间从原来的 10 秒延长到了 2 分钟,而我们的 livenessProbe 超时设置只有 30 秒。这个看似微小的配置差异,导致了整个服务链的雪崩效应。那次事故让我意识到,解决 CrashLoopBackOff 不仅需要技术深度,更需要系统性思维。
通过本文的系统性梳理,我希望能够帮助大家建立起完整的问题排查思路。从镜像构建的基础环节开始,到容器运行时的资源管理,再到健康检查机制的精细调优,每一个步骤都需要我们用工程师的严谨态度去对待。特别是在微服务架构日益复杂的今天,单一组件的问题往往会被放大,影响整个系统的稳定性。
我始终相信,最好的故障处理是预防。通过建立完善的 CI/CD 流程、实施全面的监控告警、制定标准化的配置模板,我们可以在很大程度上避免 CrashLoopBackOff 问题的发生。当然,即使有了完善的预防机制,问题仍然会出现,这时候系统性的排查方法论就显得尤为重要。
在云原生技术快速发展的今天,Kubernetes 已经成为容器编排的事实标准。掌握 CrashLoopBackOff 问题的排查和解决能力,不仅是每个云原生工程师的必备技能,更是保障生产环境稳定性的重要基石。
希望通过这篇文章的分享,能够帮助更多的技术同仁在面对 CrashLoopBackOff 问题时,不再手忙脚乱,而是能够有条不紊地进行系统性排查。记住,每一次故障都是学习和成长的机会,每一次成功的问题解决都会让我们在技术的道路上更进一步。让我们一起在云原生的浪潮中,用专业的技能和严谨的态度,构建更加稳定可靠的系统架构。
我是摘星!如果这篇文章在你的技术成长路上留下了印记
👁️ 【关注】与我一起探索技术的无限可能,见证每一次突破
👍 【点赞】为优质技术内容点亮明灯,传递知识的力量
🔖 【收藏】将精华内容珍藏,随时回顾技术要点
💬 【评论】分享你的独特见解,让思维碰撞出智慧火花
🗳️ 【投票】用你的选择为技术社区贡献一份力量
技术路漫漫,让我们携手前行,在代码的世界里摘取属于程序员的那片星辰大海!
参考链接
- Kubernetes 官方文档 - Pod 生命周期
- Kubernetes 最佳实践 - 健康检查配置
- Docker 最佳实践 - 多阶段构建
- Prometheus 监控 - Kubernetes 集群监控
- CNCF 云原生技术栈 - 容器运行时最佳实践
关键词标签
Kubernetes CrashLoopBackOff Pod故障排查 容器健康检查 云原生