从零开始的python学习——函数(2)
ʕ • ᴥ • ʔ
づ♡ど
🎉 欢迎点赞支持🎉

个人主页:励志不掉头发的内向程序员;
专栏主页:python学习专栏;
文章目录
前言
一、变量作用域
二、函数执行过程
三、链式调用
四、嵌套调用
五、函数递归
六、参数默认值
七、关键字参数
总结
前言
上一章节我们了解到了 Python 中的函数的最基本的定义和调用规则,本章节我们继续来深入函数学习,来学习函数的不同结构以及不同的调用方法。我们一起来看看吧。

一、变量作用域
来观察以下代码。
def getPoint():x = 10y = 20return x, yx, y = getPoint()在这个代码中,函数内部存在 x,y,函数外部也有 x,y。但其实这两个 x,y 不是相同的变量,而只是恰好有一样的名字而已。
我们可能会经常发现有的时候同一个变量名在不同的地方多次出现。但是这个同一个变量名并不意味着是同一个变量。就比如我管我最喜欢的东西叫做 “宝贝儿”,但是大家肯定也有自己的 “宝贝儿”。虽然都是 “宝贝儿”,但是显而易见不是同一个东西。
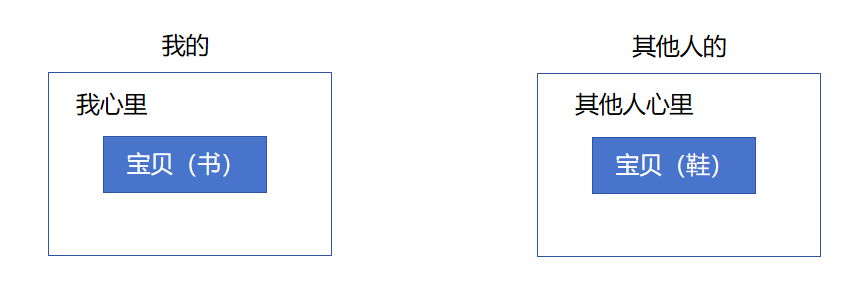
虽然名字一样,但其实也是不会混淆的。因为它是在各自不同的范围生效的。我叫我的宝贝是我和我宝贝之间的事情,而其他人叫他的宝贝也只是他和他宝贝之间的事情。它们互不影响。
以上的一个情况就描述了一个概念,那就是变量的作用域。一个变量名的有效范围是一定的,只在一个固定的区域内生效。
我们刚才的那一串代码。
def getPoint():x = 10y = 20return x, yx, y = getPoint()getPoint() 中的 x,y 是函数内部的变量名,函数内部的变量名只能在函数内部生效,出了函数就无效了。
def getPoint():x = 10y = 20return x, ygetPoint()
print(x, y)我们来尝试直接在函数外面打印我们函数内部的变量名。
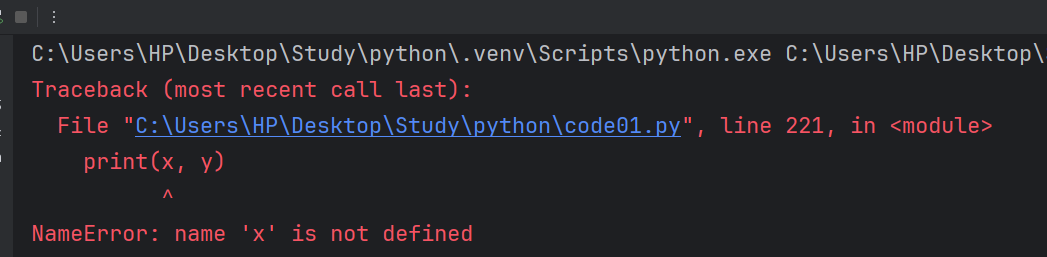
它会报错,并且说 x 未定义。既然我们函数内部的变量在函数外部无法生效,这也就意味着我们在函数外面同样可以使用 x,y 的变量名。此时,这两个 x,y 就是完全不相同的变量。
我们再来看看这个例子。
x = 10def test():x = 20print(f"函数内部:{x}")test()
print(f"函数外部:{x}")此时我们就能更加清楚的看到相同变量名的区别了。
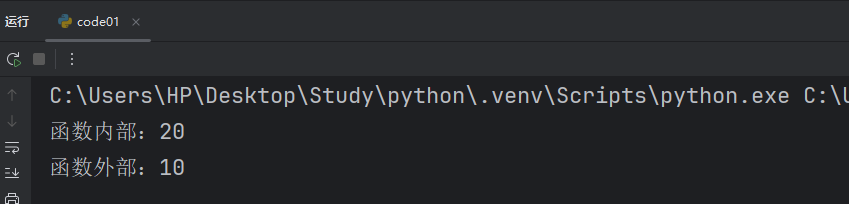
我们把 x = 10 代码所处的位置叫做全局变量,全局变量是在整个程序中都有效的。而函数内部的 x = 20 叫做局部变量,只在函数内部有效。由于全局变量是在整个程序中都有效的,所以我们函数中也是可以使用我们的全局变量的。
x = 10def test():print(f"函数内部:{x}")test()当函数访问某个变量的时候,会先尝试在局部变量中查找,如果找到,就直接访问,如果没找到,就会往上一级作用域中进行查找。test 再往上一级作用域,就是全局了。

可以如愿的输出我们的 10。
我们读取还是比较简单的,但是我们修改操作就没那么容易了。
x = 10
# 使用这个函数,把全局变量 x 改成20
def test():x = 20test()
print(f"x = {x}")我们如果直接修改是不行的。
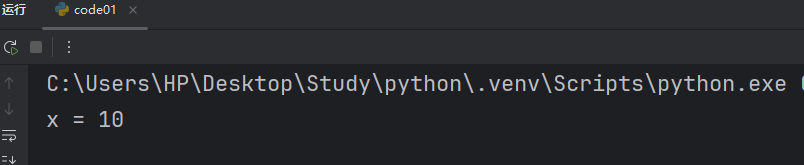
这是因为我们 x = 20 的 x 被当成函数内部创建的一个局部变量。所以没办法改,如果想要改成20,我们就得使用 Python 中的一个关键字 global 声明一下我们的 x,我们的就能修改全局变量的 x 了。
x = 10
# 使用这个函数,把全局变量 x 改成20
def test():global xx = 20test()
print(f"x = {x}")此时我们的修改就是针对全局的修改了。

当然,像 if,else,while,for 这些关键字也会引入 “代码块”,但是这些代码块不会对变量的作用域产生影响。在上述语句代码块内部定义的变量,可以在外面被访问。
for i in range(1, 11):print(i)print("--------------------")
print(i)我们可以看到,我们在 for 循环里面创建的变量 i,在外面也能打印出来。
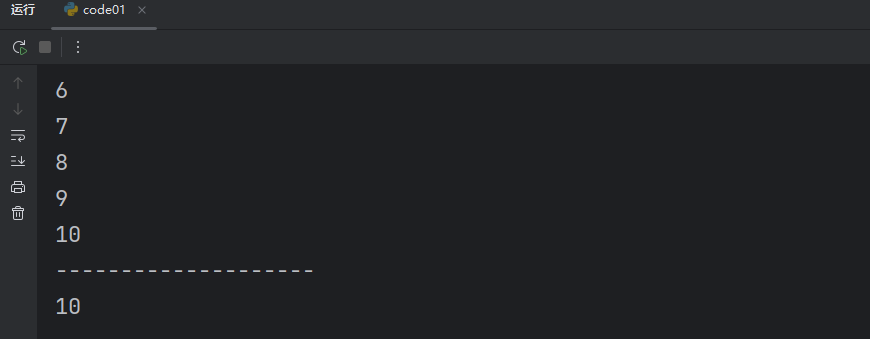
其他的也是同理。所以说不是遇到代码块就一定会影响作用域,在 Python 中只要函数和类里面的代码块才会涉及到作用域。
二、函数执行过程
- 调用函数才会执行函数体代码,不调用则不会执行。
- 函数体执行结束(或者遇到 return 语句),则回到函数调用位置,继续往下执行。
def test():print("执行函数体代码")print("执行函数体代码")print("执行函数体代码")print("111111")
test()
print("222222")
test()
print("333333")
test()
print("444444")我们通过这个代码来尝试看看我们函数的执行过程。
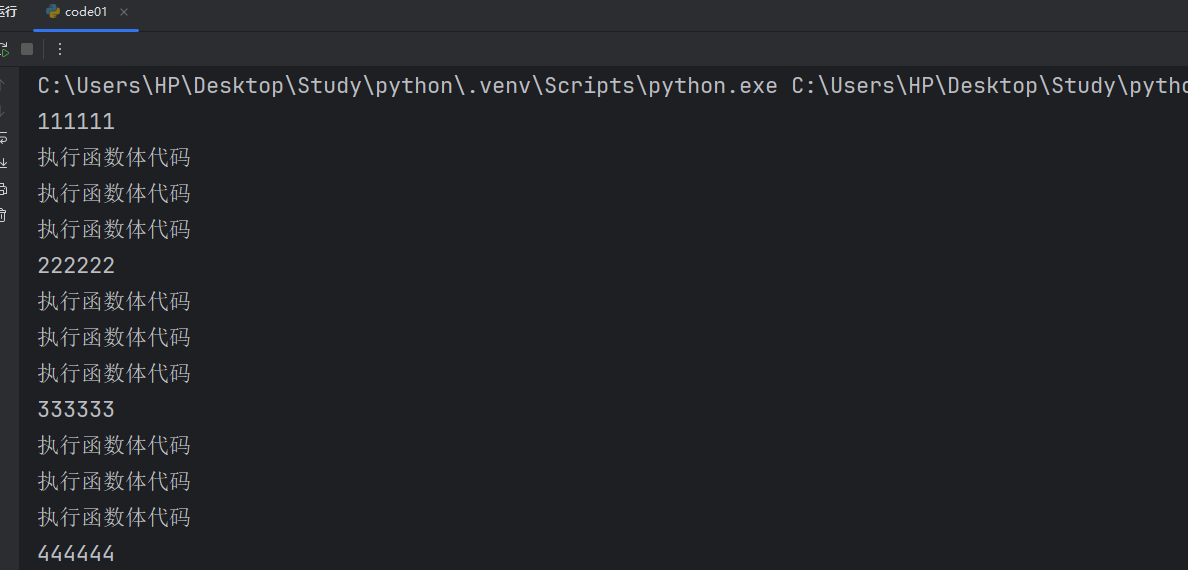
我们可以通过执行结果来简单分析一下。
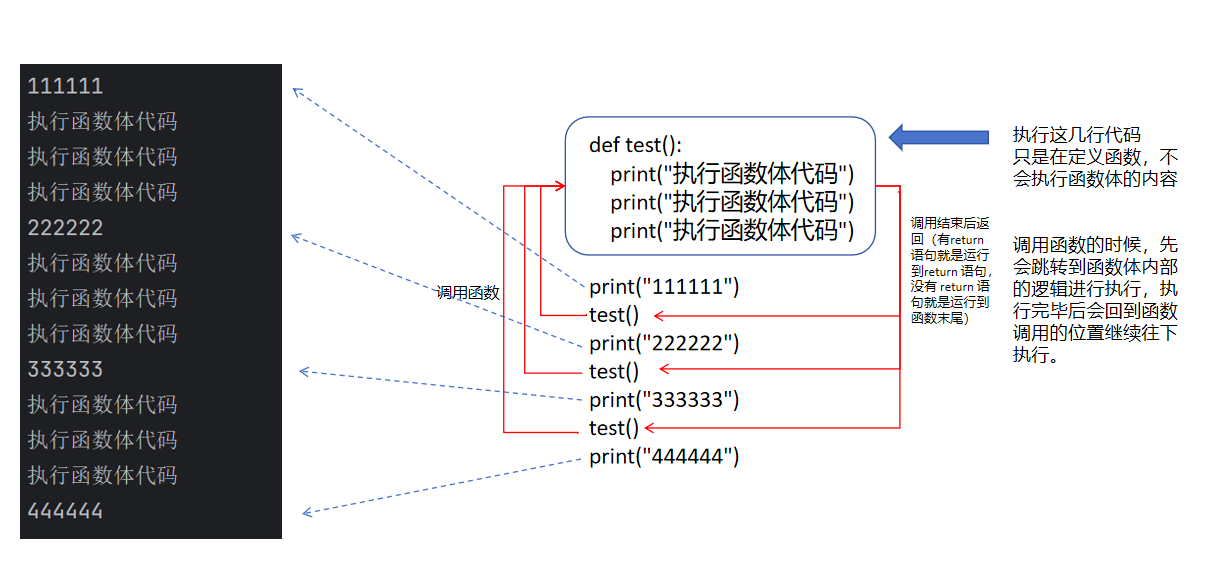
我们程序的运行就是在这些各种函数之间不断的跳转,就像盗梦空间一样,可以在梦里做梦,当梦醒了就又跳转回原来的梦中,就在这些梦中不断的跳转。
我们刚才是通过函数结果来一一分析的,其实我们还可以调用 PyCharm 中的调试器,也能看到一样的效果。我们可以在行首部分点击一下就可以打一个断点,再点一下就会取消。

当我们右键时不要选择运行,而是选择下面的调试。
我们的程序就会执行到调试执行的模式。我们调试执行和运行的区别就在于我们调试执行遇到断点就会停下来,也可以随时停下来,方便我们程序猿去观察程序的中间过程。
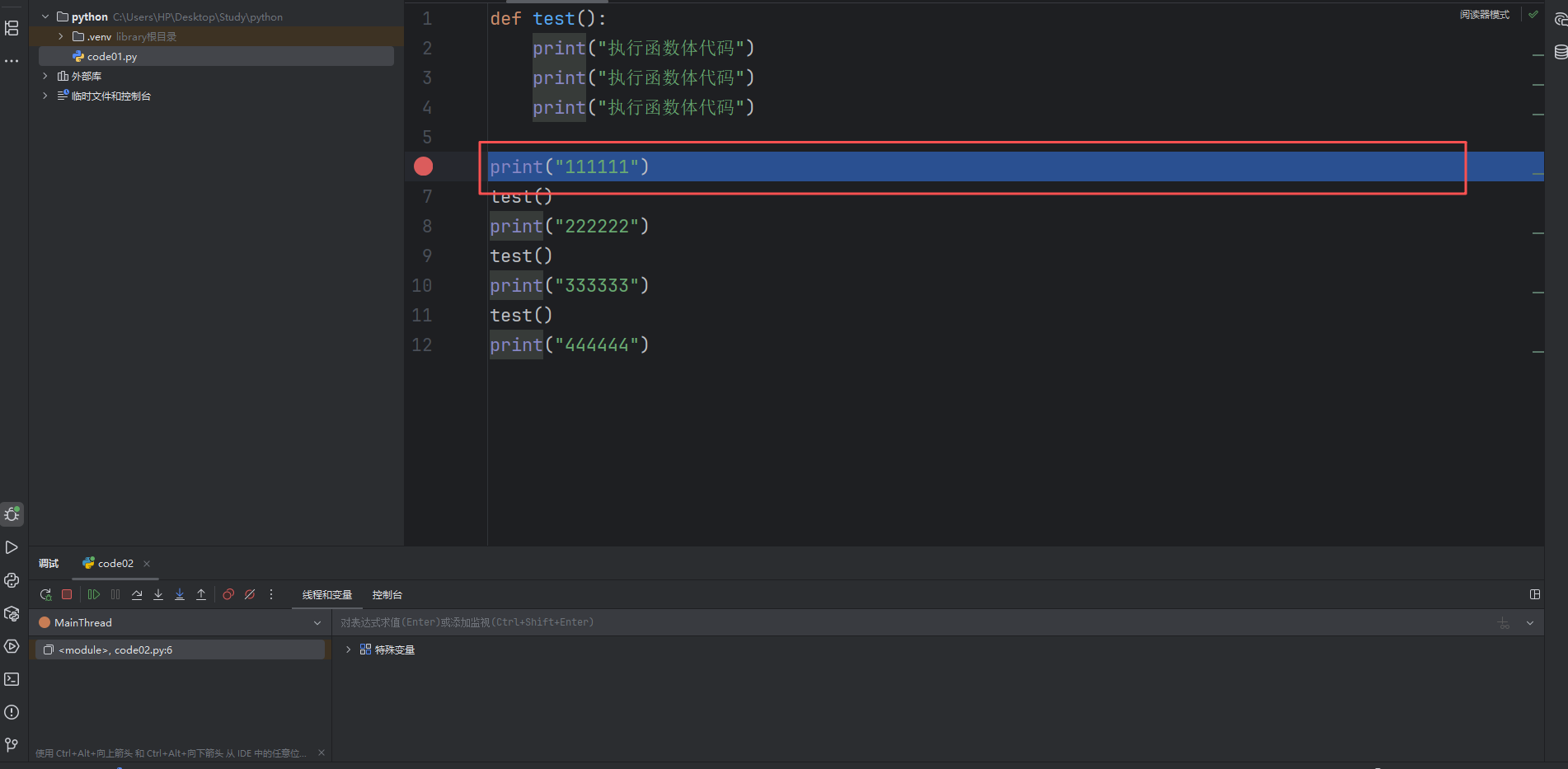
此时我们的程序运行到我们断点处就停下来了。此时我们就可以让我们程序一步一步的走。

我们可以在这个地方看到好几个按钮。
我们选择这个按钮,它就是单步执行我们的代码,并且遇到自己的函数,能够进入到函数里面。当然只有调试才可以,运行不行。大家可以自己去尝试一下,可以看到我们程序的执行过程就和刚才推测的一样。
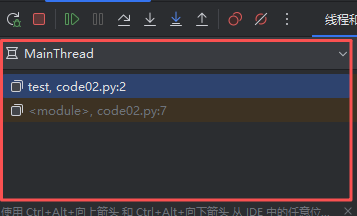
按钮下面是函数调用栈,描述了当时的代码是怎么跳转过去的(进一步的也就是函数之间的调用关系)。
三、链式调用
所谓的链式调用,就是用一个函数的返回值作为另一个函数的参数。
我们之前写过一个代码。
def isOdd(num):if num % 2 == 0:return Falsereturn Trueresult = isOdd(10)
print(result)直接运行就能打印出我们正确的值。
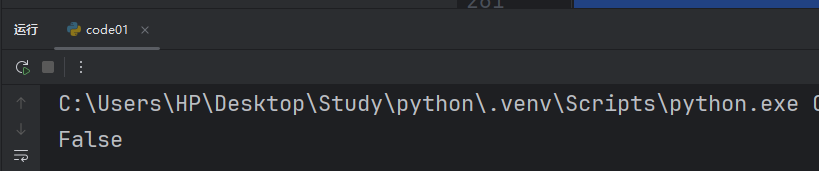
当然,这个代码我们可以直接简化成这个样子。
def isOdd(num):if num % 2 == 0:return Falsereturn Trueprint(isOdd(10))形如这样的代码,就叫做函数的链式调用。当然,我们的链式调用还可以有多层。
def isOdd(num):if num % 2 == 0:return Falsereturn Truedef add(x, y):return x + yprint(isOdd(add(10, 3)))此时就相当于又来了一层链式调用,此时我们add算出来返回值为 13,我们返回值13就变成了isOdd 的参数了,然后 isOdd 判断出来是奇数,返回值 True 又变成了 print 后输出。
在链式调用中,先执行 ( ) 里面的函数,后执行外面的函数。换句话说,调用一个函数,就需要先对他的参数求值。
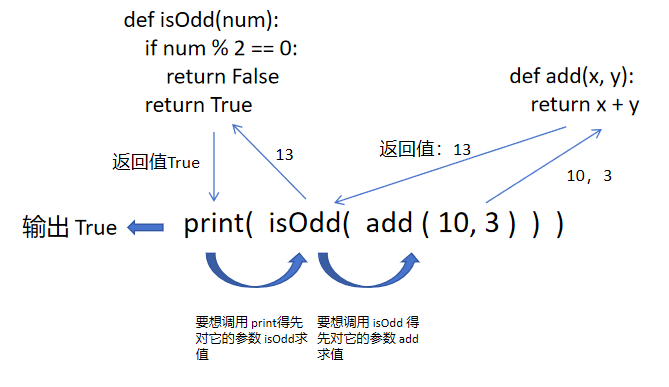
虽然我们链式嵌套是很常见的,但是我们也不用嵌套层次太深,因为这样会影响我们的可读性。
四、嵌套调用
一个函数的函数体内部,还可以调用其他函数。
举一个简单的例子。
def test():print("hello")test()这就属于一个嵌套调用,我们的 test 中嵌套了一个 print,虽然不是我们自己写的,但它也是一个函数。
同时,我们嵌套调用的层次可以有很多层
def a():print("函数 a")def b():print("函数 b")a()def c():print("函数 c")b()def d():print("函数 d")c()d()这就是我们比较复杂一点的函数嵌套。
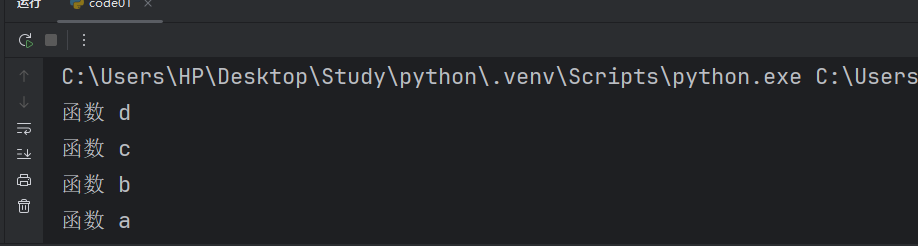
我们来看看这个代码的执行过程。
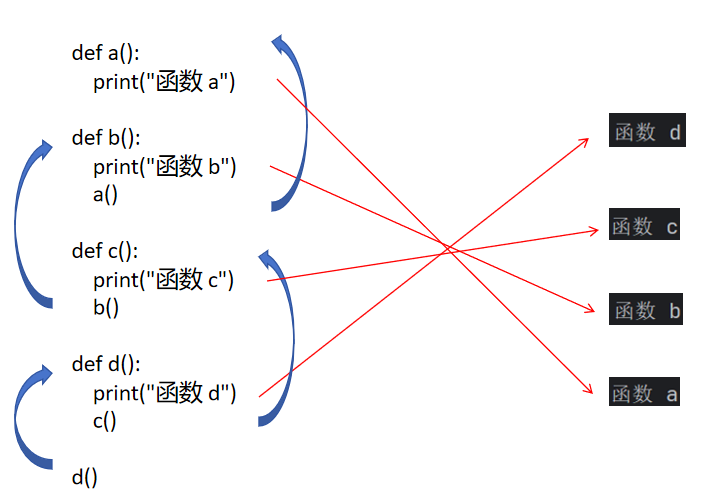
虽然我们函数嵌套了多层,但是函数的执行逻辑是没有什么变化的。
如果我们把代码的位置稍微修改一下,我们的执行结果就会天差地别。
def a():print("函数 a")def b():a()print("函数 b")def c():b()print("函数 c")def d():c()print("函数 d")d()我们这里先调用在打印,结果完全相反。
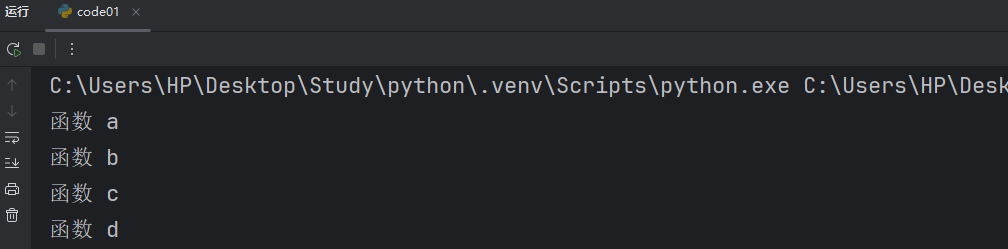
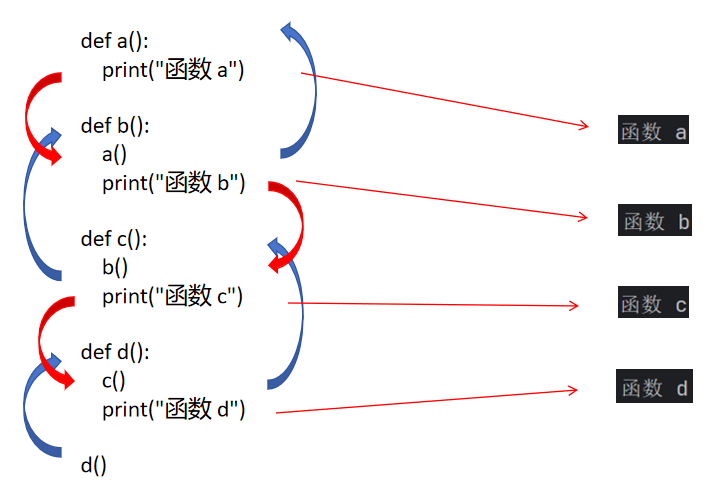
我们代码稍微微调了一下后就出现了截然相反的结果,所以我们一定要搞明白函数调用的基本过程。当然我们上述过程依然可以用调试器分析。
五、函数递归
递归时嵌套调用中的一种特殊情况,即一个函数嵌套调用自己。
我们大部分人可能小时候就听过一个故事:从前有座山,山里有座庙,庙里有个老和尚再给小和尚讲故事,故事的内容是:从前做山........

这个故事永远没有尽头。
我们可以来试着用上面的逻辑来生成一个代码。
# 写一个函数,来求 n 的阶乘(n 是正整数)
def factor(n):result = 1for i in range(1, n + 1):result *= ireturn resultprint(factor(5))这是我们通过循环的方式来写的求阶乘的方法。

我们觉得没啥意思,于是决定换一种方式,通过递归的方式来写。
我们可以发现:
n! => n * ( n - 1 )! // 递推公式
1! == 1 // 初始条件
我们知道了递推公式和初始条件,我们就能来写递归函数了。
def factor(n):if n == 1:return 1return n * factor(n - 1)print(factor(5))我们 return n * factor(n - 1) 其实就是我们的递推公式,而 return 1 就是我们的初始条件。

这一串代码虽然写起来没几行,但是其实理解起来还挺困难的,我们来看看它的执行过程。
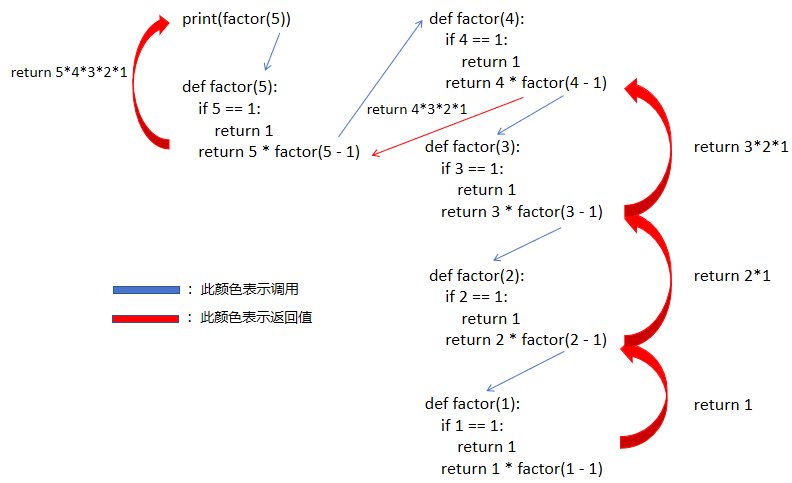
我们可以看到,虽然都是 n,但是 n是函数形参,形参相当于函数的局部变量。我们的递归代码,不会无限的往下执行,会在每一次递归的时候,都会无限逼近递归的结束条件。
我们递归的代码,虽然很多时候看起来写法很简单,但是执行过程可能会非常复杂,在分析递归代码的时候,光靠脑子想,是很困难的。所以在分析递归过程时,最好就是画图,或者借助调试器去进一步了解递归的过程。
我们递归代码必须有两个要素,第一就是递归结束条件,第二就是递归的递推公式。这和数学归纳法很相像(也是两个条件:初始条件和递推公式)。
我们递归的缺点在于:
1、执行过程非常复杂,难以理解。
2、递归代码容易出现栈溢出的情况。
3、递归代码一般都是可以转换成等价的循环代码的,并且循环的版本通常运行速度比递归版本有优势。
我们的递归代码,不会无限的往下执行,会在每一次递归的时候,都会无限逼近递归的结束条件,但是如果我们的代码写错了,就会导致我们每次递归参数不能正确的接近递归结束条件,就会出现无限递归的情况。
def factor(n):if n == 1:return 1return n * factor(n)print(factor(5))假如是这样就会报错。
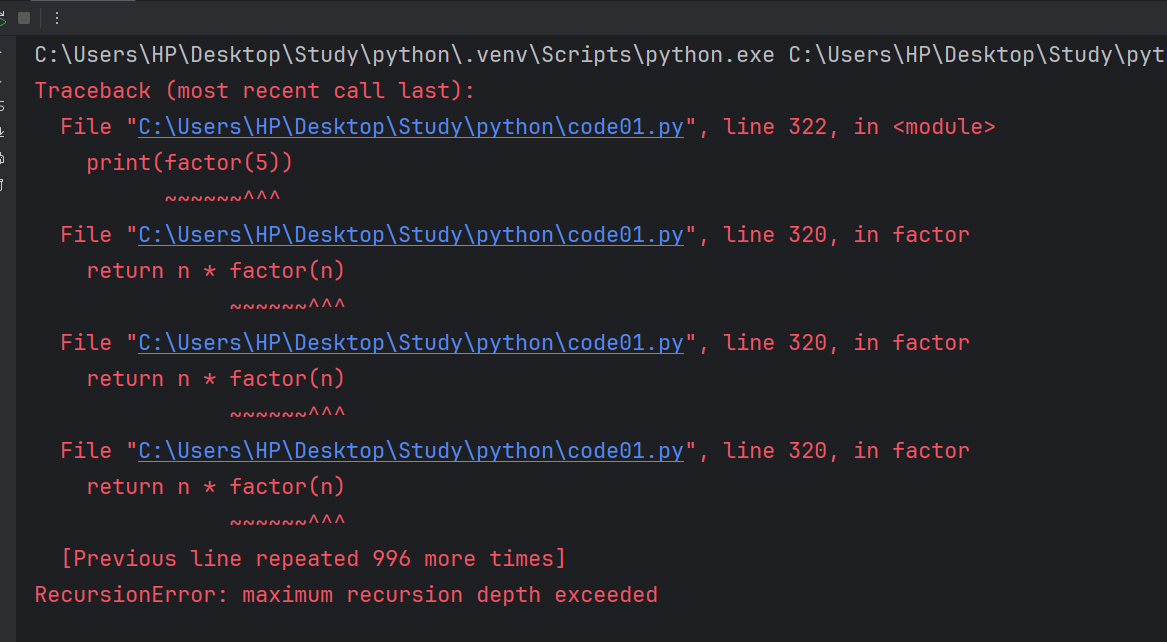
递归的优点就在于代码非常简洁,尤其是处理一些 “问题本身就是通过递归的方式定义的”。
六、参数默认值
Python 中的函数,可以给形参指定默认值。
带有默认值的参数,可以在调用的时候不传参
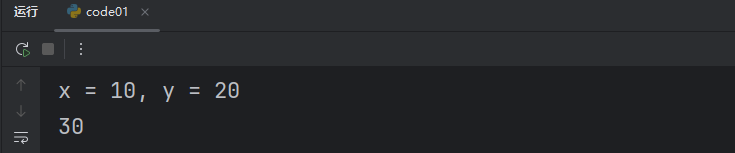
def add(x, y):print(f"x = {x}, y = {y}")return x + yresult = add(10, 20)
print(result)我们完成了一个基本的函数调用。
在函数内部加上打印信息,可以方便我们进行调试。但是像这种调试信息,我们希望在正式发布的时候不要有,只是在调试阶段才有,此时我们可以给我们代码增加一个条件语句。
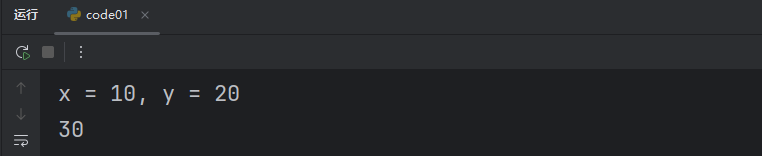
def add(x, y, debug):if debug:print(f"x = {x}, y = {y}")return x + yresult = add(10, 20, True)
print(result)此时我们可以在调用函数时传递 True/False,当传递 True 时就有调试信息,传递 False 时就没有。
True:
False:
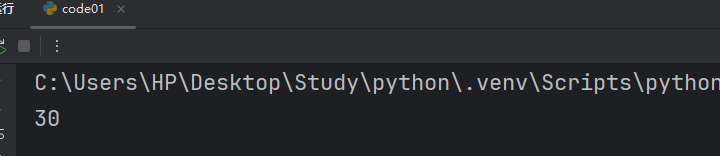
但是这样每次传递函数都得传一个 True/False,看上去比较丑,所以我们可以在 debug 上指定一个默认参数。
def add(x, y, debug = False):if debug:print(f"x = {x}, y = {y}")return x + yresult = add(10, 20)
print(result)此时如果我们不传 debug 的参数,就默认是 False。
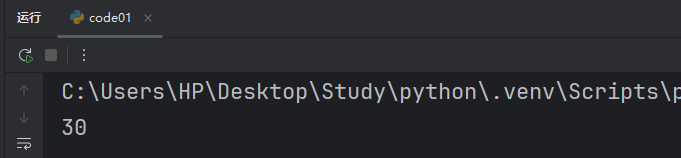
如果我们想要调试,只需要手动加上我们的 True即可。
result = add(10, 20, True)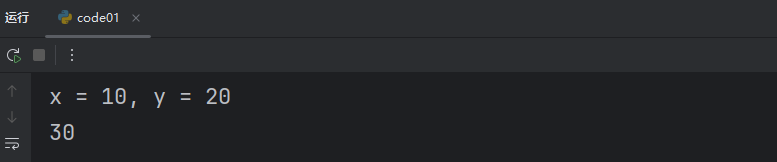
我们此处的 debug = False 就是我们形参的默认值,带有默认值的形参就可以在调用函数时不必传参,不传参就是使用我们的默认值。通过这样的默认值,就可以让我们函数设计的更加灵活。
我们默认值也有一些要求,它要求带有默认值的形参,得在形参列表后面,而不能在中间。
def add(x, debug = False, y):if debug:print(f"x = {x}, y = {y}")return x + y这样是不允许的,这样我们传递第二个参数时不知道是给 debug 还是给 y 的。
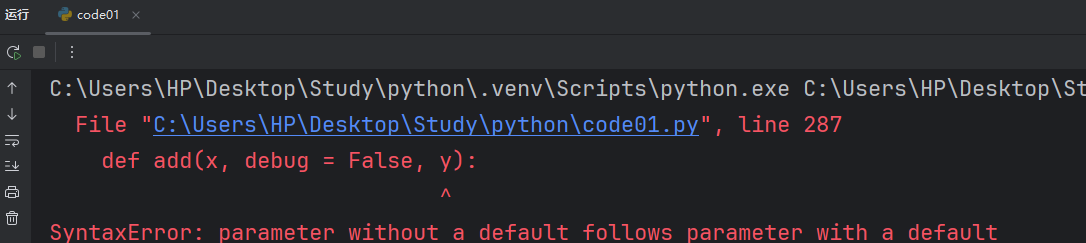
错误提示是不能把非默认参数放到默认参数前。所以如果多个带有默认参数的形参,这些都得放到后面。
七、关键字参数
在调用函数的时候,需要给函数指定的实参,一般默认情况下是按照形参顺序,来依次传递实参的。但是我们也可以通过关键字参数来调整这里的传参顺序,显式指定当前实参传递给哪个形参。
def add(x, y):return x + yadd(10, 20)我们的第一个实参 10 就是传递给我们第一个形参 x 的,而第二个实参 20 就是传递给我们第二个形参 y 的。这种按照先后顺序来传参的这种传参风格称为 “位置参数”。这是各个编程语言中最普遍的方式。
除了上种方式外,Python 还有一中非常有特色的传参方式,那就是关键字传参,也就是按照形参的名字来进行传参。
def test(x, y):print(f'x = {x}')print(f'y = {y}')test(x = 10, y = 20)我们调用的参数中的 x、y 就是从形参而来。此时我们运行程序。

使用这种关键字参数的最大意义就是能够非常明显的告诉我们程序猿说我们的这些参数是要传给谁。另外可以无视形参和实参的顺序。
test(y = 100, x = 200)倒过来写也是完全可以的。

我们位置参数和关键字参数还可以混合使用,只不过混合使用时我们要求位置参数在前,关键字参数在后。
而我们关键字参数一般都是搭配默认参数来使用的。一个函数,可以提供很多参数来实现对这个函数内部功能做出一些调整设定,但是为了降低调用者的使用成本,就可以把大部分参数设定出默认值。当调用者需要调整其中的一部分参数时,就可以搭配关键字参数来进行操作。
总结
以上便是我们函数主要的内容,比起其他的语言,多了不少新的特性,我们可以多加感悟它的新特性,但是想要熟练掌握还是得多多刷题,多多敲代码,练习也是学习的一部分。
🎇坚持到这里已经很厉害啦,辛苦啦🎇
ʕ • ᴥ • ʔ
づ♡ど
