Redis 缓存雪崩实战:从监控告警到3层防护的完整修复
人们眼中的天才之所以卓越非凡,并非天资超人一等而是付出了持续不断的努力。1万小时的锤炼是任何人从平凡变成超凡的必要条件。———— 马尔科姆·格拉德威尔

🌟 Hello,我是Xxtaoaooo!
🌈 "代码是逻辑的诗篇,架构是思想的交响
目录
摘要
一、 缓存雪崩事故回顾
1.1 事故现象描述
1.2 问题定位过程
二、 缓存雪崩原理深度解析
2.1 雪崩触发机制
2.2 影响因素分析
三、 监控告警体系构建
3.1 多维度监控指标
3.2 智能告警策略
四、 三层防护体系设计
4.1 第一层:缓存预热与过期策略
4.2 第二层:熔断降级机制
4.3 第三层:多级缓存架构
五、 架构优化与性能提升
5.1 整体架构设计
5.2 性能优化效果
六、 应急响应机制
6.1 自动化应急预案
6.2 监控大盘与可视化
七、 最佳实践与避坑指南
7.1 缓存设计原则
7.2 常见陷阱与解决方案
7.3 运维操作规范
八、 总结与思考
参考链接
摘要
作为一名在互联网行业摸爬滚打多年的技术实践者,我深知缓存在高并发系统中的重要性。然而,就在上个月的一个深夜,我们的电商平台突然遭遇了一次严重的缓存雪崩事故,整个系统几乎瘫痪,数据库CPU飙升至98%,响应时间从平时的100ms暴增到15秒,用户投诉电话响个不停。
这次事故的起因看似简单:由于运维同事在凌晨2点进行Redis集群重启维护,但没有考虑到大量缓存同时失效的连锁反应。当早高峰流量涌入时,所有请求直接击穿到MySQL数据库,瞬间造成了雪崩效应。那一刻,我深刻体会到了什么叫"牵一发而动全身"。
在这次惨痛的教训中,我和团队花了整整72小时进行紧急修复和架构重构。我们从监控告警体系的完善开始,逐步构建了包括缓存预热、熔断降级、多级缓存在内的三层防护体系。更重要的是,我们建立了一套完整的缓存雪崩预防和应急响应机制。
通过这次实战,我不仅深入理解了缓存雪崩的本质原理,更掌握了从监控发现问题到快速恢复服务的完整流程。本文将毫无保留地分享这次事故的完整复盘过程,包括问题定位的关键步骤、核心代码实现、以及我们总结出的最佳实践。希望能帮助更多同行避免类似的线上事故,让大家的系统更加稳定可靠。
一、 缓存雪崩事故回顾
1.1 事故现象描述
凌晨2:30,我们的Redis集群进行例行维护重启。然而,早上8:00流量高峰期到来时,系统出现了严重异常:
-
响应时间激增:API响应时间从100ms暴增至15秒
-
数据库压力爆表:MySQL CPU使用率从20%飙升至98%
-
用户体验崩塌:页面加载超时,订单提交失败率达到85%
-
告警风暴:监控系统1分钟内发出200+条告警

图1:缓存雪崩事故流程图 - 展示从Redis重启到系统崩溃的完整链路
1.2 问题定位过程
通过监控数据分析,我们快速定位了问题的根本原因:
# 查看Redis连接状态
redis-cli info clients
# connected_clients:0 # Redis重启后连接为0
# 检查数据库连接池状态
show processlist;
# 发现大量SELECT查询堆积
# 查看应用日志
tail -f application.log | grep "cache miss"
# 2024-11-15 08:01:23 WARN - Cache miss rate: 100%二、 缓存雪崩原理深度解析
2.1 雪崩触发机制
缓存雪崩的本质是缓存层失效导致的请求穿透,形成恶性循环:
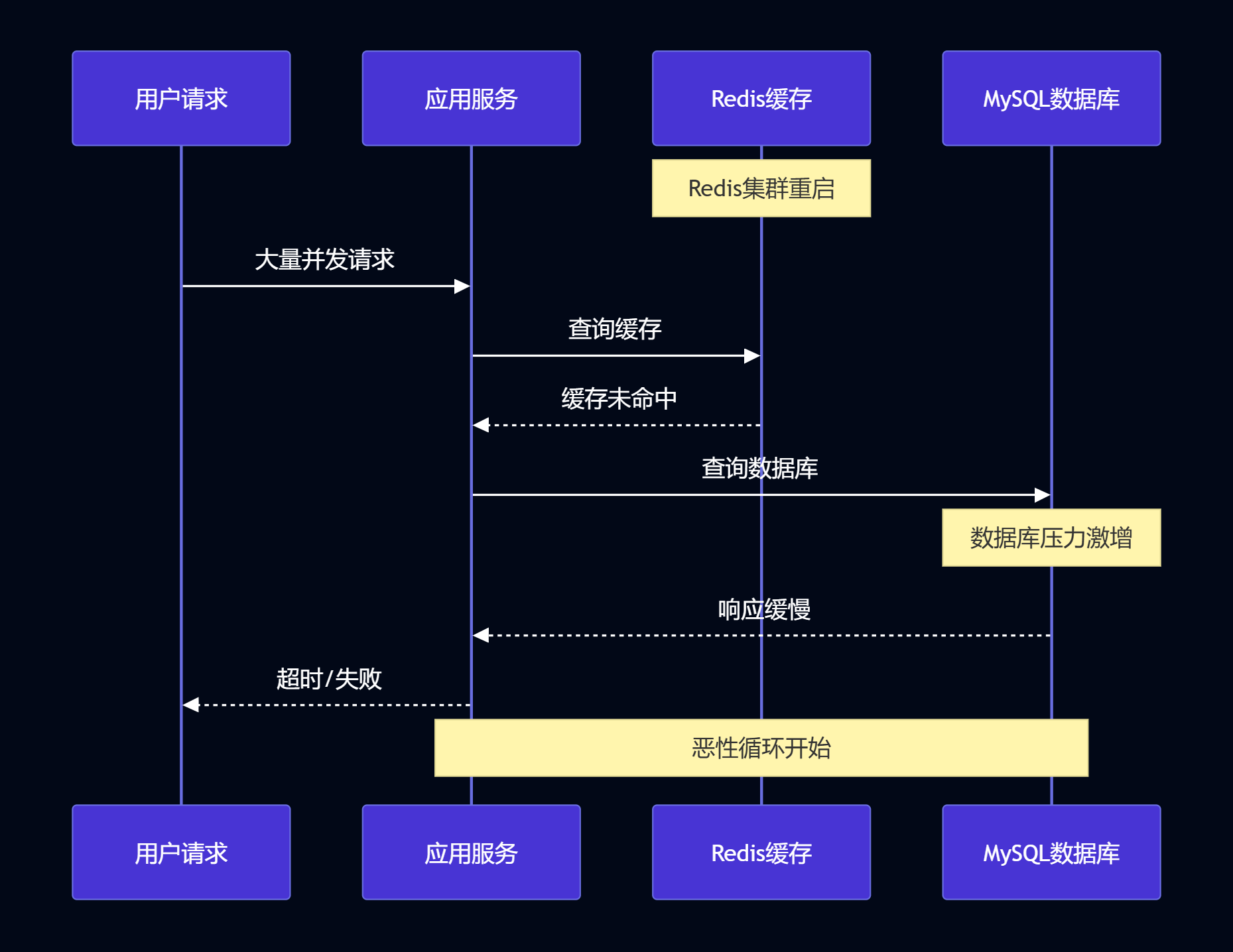
图2:缓存雪崩时序图 - 展示请求处理的完整时序流程
2.2 影响因素分析
通过数据分析,我们发现了几个关键的影响因素:
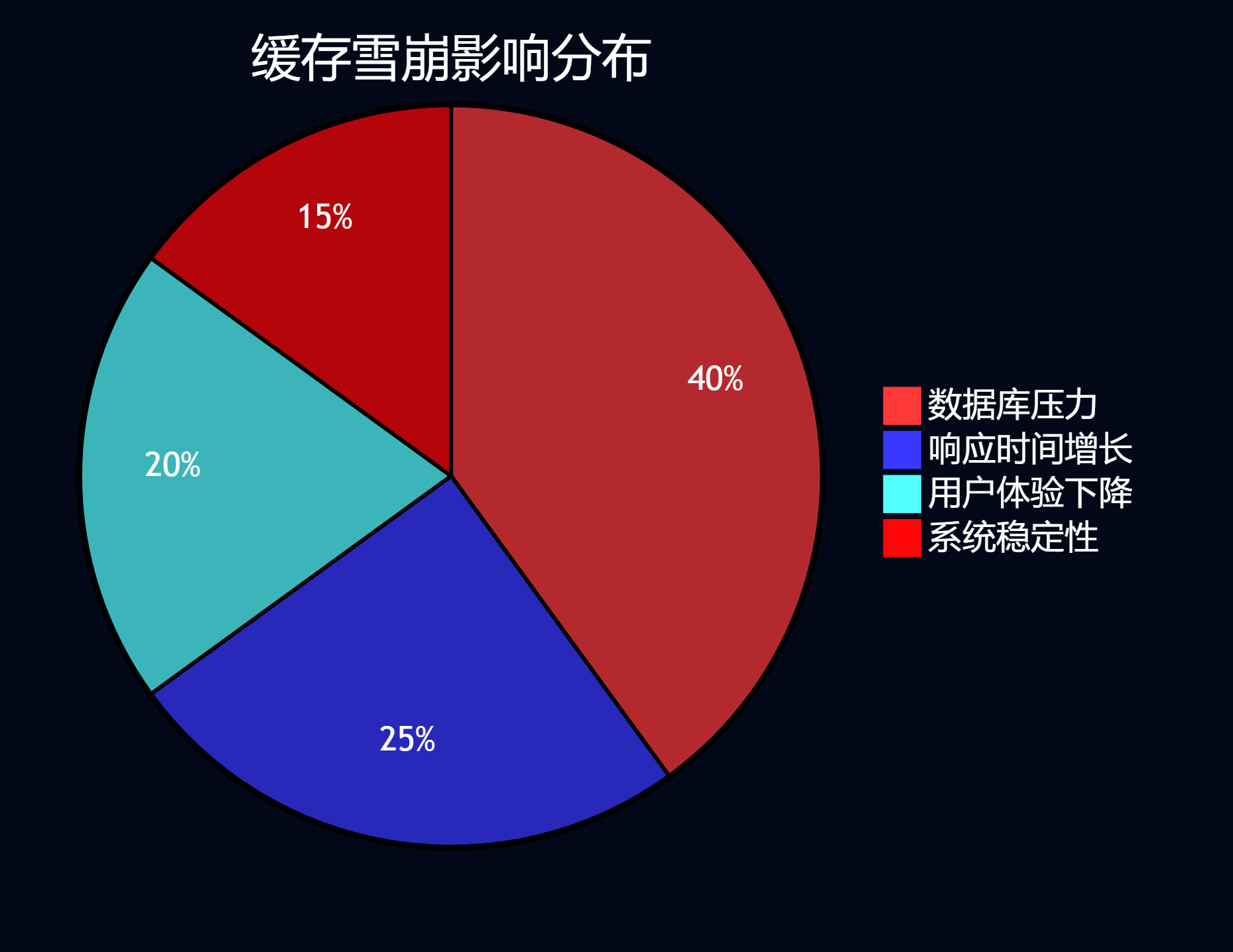
图3:缓存雪崩影响分布饼图 - 展示各类影响的占比分析
三、 监控告警体系构建
3.1 多维度监控指标
基于这次事故,我们重新设计了监控体系,涵盖了缓存、数据库、应用三个层面:
@Component
public class CacheMonitor {private final MeterRegistry meterRegistry;private final RedisTemplate<String, Object> redisTemplate;/*** 缓存命中率监控* 核心指标:命中率低于90%触发告警*/@Scheduled(fixedRate = 30000) // 30秒检查一次public void monitorCacheHitRate() {long hits = getCacheHits();long misses = getCacheMisses();double hitRate = (double) hits / (hits + misses);// 记录指标meterRegistry.gauge("cache.hit.rate", hitRate);// 告警判断if (hitRate < 0.9) {alertService.sendAlert("缓存命中率异常", String.format("当前命中率: %.2f%%", hitRate * 100));}}/*** Redis连接状态监控* 检查Redis集群健康状态*/@Scheduled(fixedRate = 10000) // 10秒检查一次public void monitorRedisHealth() {try {String pong = redisTemplate.getConnectionFactory().getConnection().ping();if (!"PONG".equals(pong)) {alertService.sendCriticalAlert("Redis连接异常", "无法连接到Redis服务器");}} catch (Exception e) {log.error("Redis健康检查失败", e);alertService.sendCriticalAlert("Redis服务异常", e.getMessage());}}
}3.2 智能告警策略
我们实现了基于阈值和趋势的智能告警机制:
@Service
public class IntelligentAlertService {/*** 多级告警策略* 根据严重程度分级处理*/public void processAlert(MetricData metric) {AlertLevel level = calculateAlertLevel(metric);switch (level) {case CRITICAL:// 立即通知:短信 + 电话 + 钉钉sendImmediateAlert(metric);// 自动触发应急预案emergencyResponseService.triggerEmergencyPlan();break;case WARNING:// 延迟通知:钉钉 + 邮件sendDelayedAlert(metric, Duration.ofMinutes(5));break;case INFO:// 记录日志,不发送通知log.info("监控指标异常: {}", metric);break;}}/*** 基于历史数据的异常检测* 使用滑动窗口算法检测异常趋势*/private AlertLevel calculateAlertLevel(MetricData current) {List<MetricData> history = getHistoryData(Duration.ofHours(1));// 计算标准差double avg = history.stream().mapToDouble(MetricData::getValue).average().orElse(0.0);double stdDev = calculateStandardDeviation(history, avg);// 异常判断:超过3个标准差为严重告警double deviation = Math.abs(current.getValue() - avg);if (deviation > 3 * stdDev) {return AlertLevel.CRITICAL;} else if (deviation > 2 * stdDev) {return AlertLevel.WARNING;} else {return AlertLevel.INFO;}}
}四、 三层防护体系设计
4.1 第一层:缓存预热与过期策略
@Service
public class CacheWarmupService {/*** 智能缓存预热* 基于历史访问模式预加载热点数据*/@EventListener(ApplicationReadyEvent.class)public void warmupCache() {log.info("开始缓存预热...");// 1. 预热核心业务数据warmupCoreBusinessData();// 2. 预热热点商品数据warmupHotProductData();// 3. 预热用户会话数据warmupUserSessionData();log.info("缓存预热完成");}/*** 分散过期时间策略* 避免大量缓存同时过期*/public void setCacheWithRandomExpire(String key, Object value, long baseExpireSeconds) {// 在基础过期时间上增加随机偏移量(±20%)long randomOffset = (long) (baseExpireSeconds * 0.2 * Math.random());long finalExpire = baseExpireSeconds + randomOffset - (long)(baseExpireSeconds * 0.1);redisTemplate.opsForValue().set(key, value, Duration.ofSeconds(finalExpire));log.debug("设置缓存: key={}, expire={}s", key, finalExpire);}
}4.2 第二层:熔断降级机制
@Component
public class CacheCircuitBreaker {private final CircuitBreaker circuitBreaker;public CacheCircuitBreaker() {// 配置熔断器:5秒内失败率超过50%则熔断this.circuitBreaker = CircuitBreaker.ofDefaults("cache-circuit-breaker");circuitBreaker.getEventPublisher().onStateTransition(event -> log.info("熔断器状态变更: {} -> {}", event.getStateTransition().getFromState(),event.getStateTransition().getToState()));}/*** 带熔断保护的缓存查询*/public <T> T getWithCircuitBreaker(String key, Class<T> clazz, Supplier<T> fallback) {return circuitBreaker.executeSupplier(() -> {try {T result = (T) redisTemplate.opsForValue().get(key);if (result == null) {throw new CacheMissException("缓存未命中: " + key);}return result;} catch (Exception e) {log.warn("缓存查询失败: key={}, error={}", key, e.getMessage());throw e;}}).recover(throwable -> {log.info("熔断器触发,使用降级策略: key={}", key);return fallback.get();});}
}4.3 第三层:多级缓存架构
@Service
public class MultiLevelCacheService {private final LoadingCache<String, Object> localCache; // L1: 本地缓存private final RedisTemplate<String, Object> redisTemplate; // L2: Redis缓存public MultiLevelCacheService() {// 配置本地缓存:最大1000个条目,5分钟过期this.localCache = Caffeine.newBuilder().maximumSize(1000).expireAfterWrite(Duration.ofMinutes(5)).recordStats().build(this::loadFromRedis);}/*** 多级缓存查询策略* L1 -> L2 -> DB 的查询链路*/public <T> T get(String key, Class<T> clazz, Supplier<T> dbLoader) {try {// L1: 本地缓存查询Object result = localCache.get(key);if (result != null) {cacheMetrics.recordHit("L1");return clazz.cast(result);}} catch (Exception e) {log.warn("L1缓存查询失败: {}", e.getMessage());}try {// L2: Redis缓存查询Object result = redisTemplate.opsForValue().get(key);if (result != null) {// 回填L1缓存localCache.put(key, result);cacheMetrics.recordHit("L2");return clazz.cast(result);}} catch (Exception e) {log.warn("L2缓存查询失败: {}", e.getMessage());}// L3: 数据库查询T result = dbLoader.get();if (result != null) {// 异步回填缓存CompletableFuture.runAsync(() -> {try {redisTemplate.opsForValue().set(key, result, Duration.ofHours(1));localCache.put(key, result);} catch (Exception e) {log.error("缓存回填失败: key={}", key, e);}});}cacheMetrics.recordMiss();return result;}
}五、 架构优化与性能提升
5.1 整体架构设计
经过重构后,我们的缓存架构具备了更强的容错能力
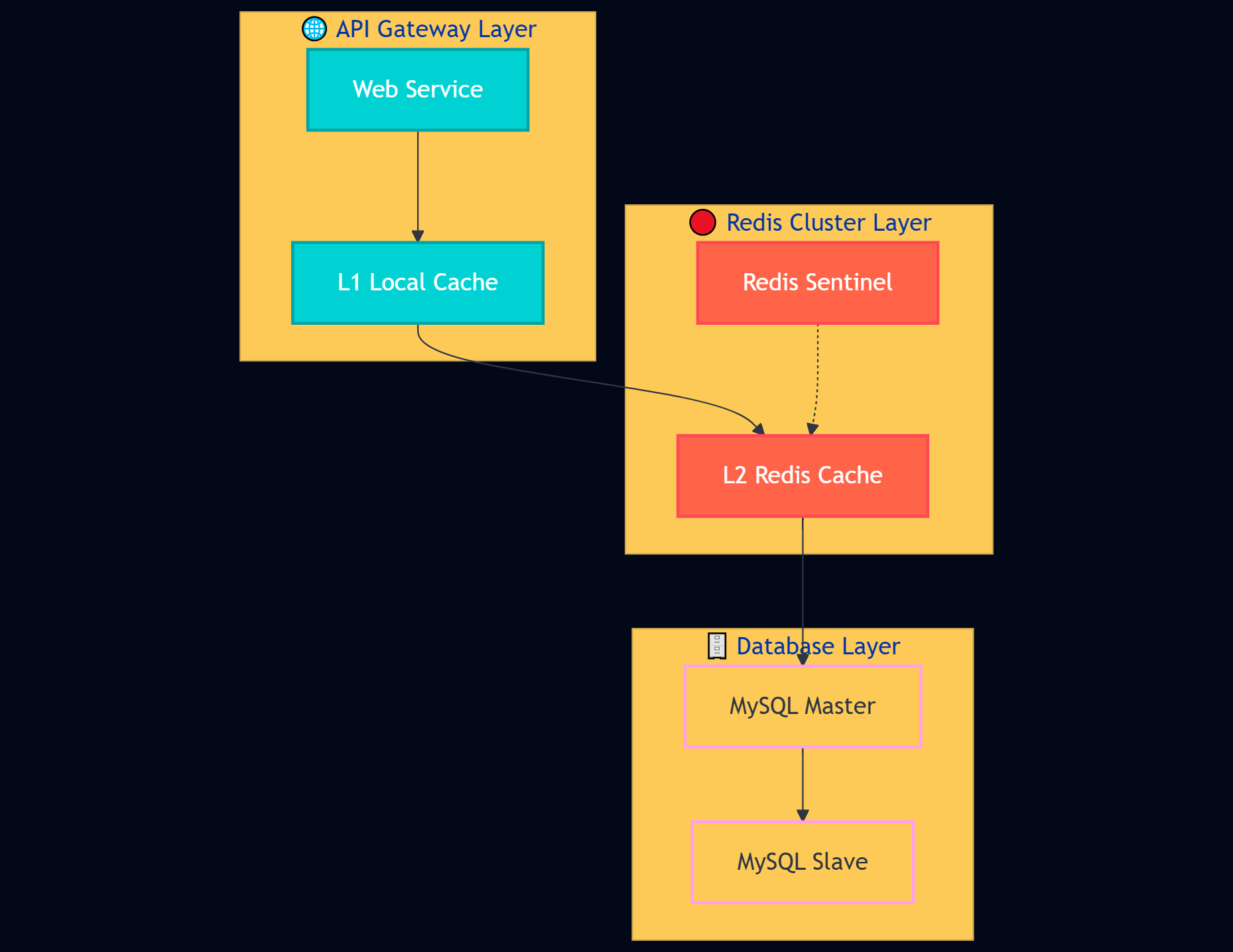
图4:多级缓存架构图 - 展示完整的缓存防护体系
5.2 性能优化效果
通过三层防护体系的实施,我们取得了显著的性能提升:
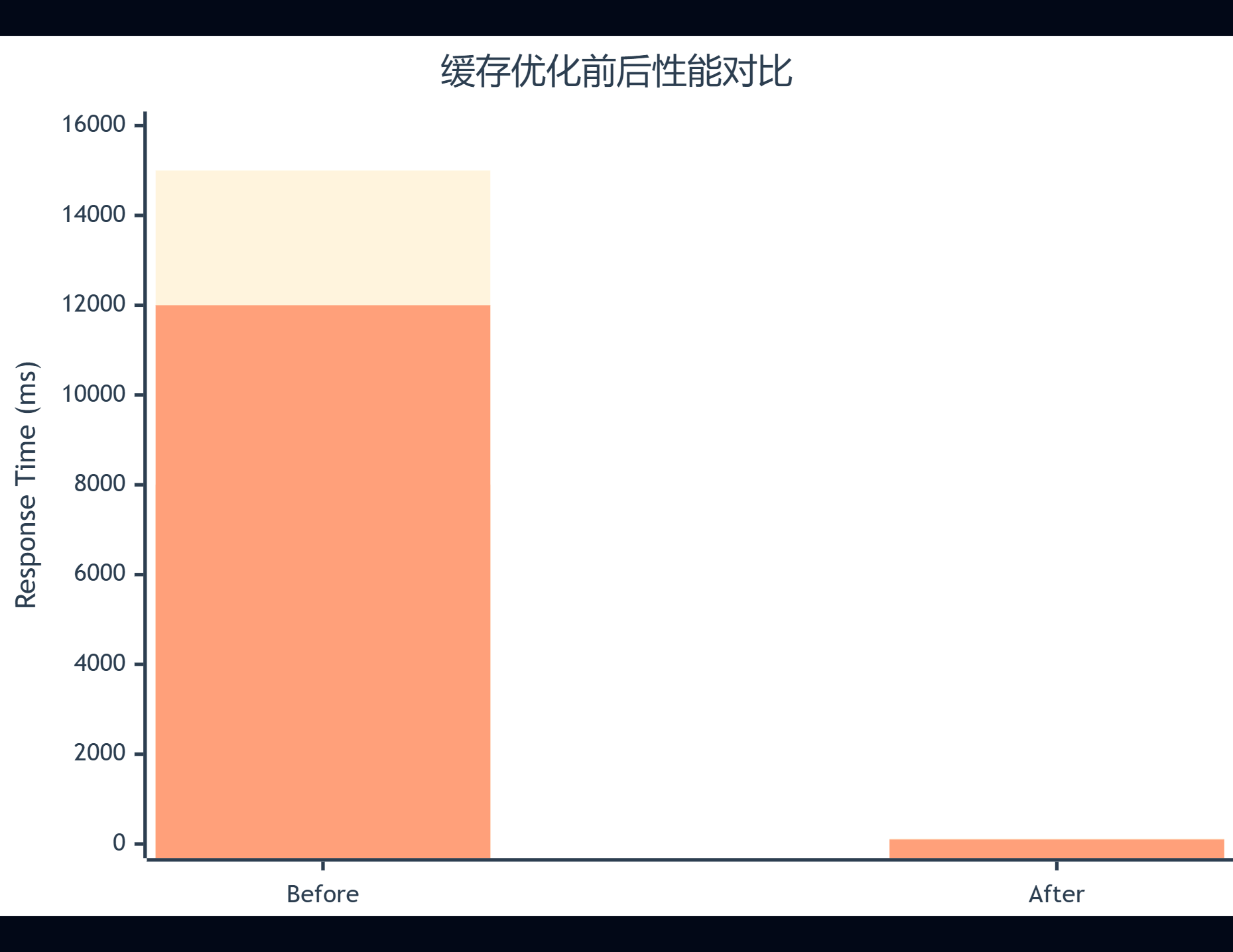
图5:性能优化效果对比图 - 展示优化前后的响应时间变化
六、 应急响应机制
6.1 自动化应急预案
@Service
public class EmergencyResponseService {/*** 缓存雪崩应急响应流程*/@EventListenerpublic void handleCacheAvalanche(CacheAvalancheEvent event) {log.error("检测到缓存雪崩,启动应急响应: {}", event);// 1. 立即启用降级策略enableDegradationMode();// 2. 限流保护数据库enableRateLimiting();// 3. 启动缓存重建startCacheRebuild();// 4. 通知运维团队notifyOpsTeam(event);}/*** 降级模式:返回静态数据或默认值*/private void enableDegradationMode() {// 启用静态数据返回degradationConfig.setEnabled(true);// 设置降级策略degradationConfig.setStrategy(DegradationStrategy.STATIC_DATA);log.info("已启用降级模式");}/*** 智能限流:保护数据库不被压垮*/private void enableRateLimiting() {// 动态调整限流阈值rateLimiter.setPermitsPerSecond(100); // 降低到100 QPS// 启用队列缓冲requestQueue.setEnabled(true);requestQueue.setMaxSize(1000);log.info("已启用智能限流保护");}
}6.2 监控大盘与可视化
我们构建了实时监控大盘,能够直观展示系统健康状态:
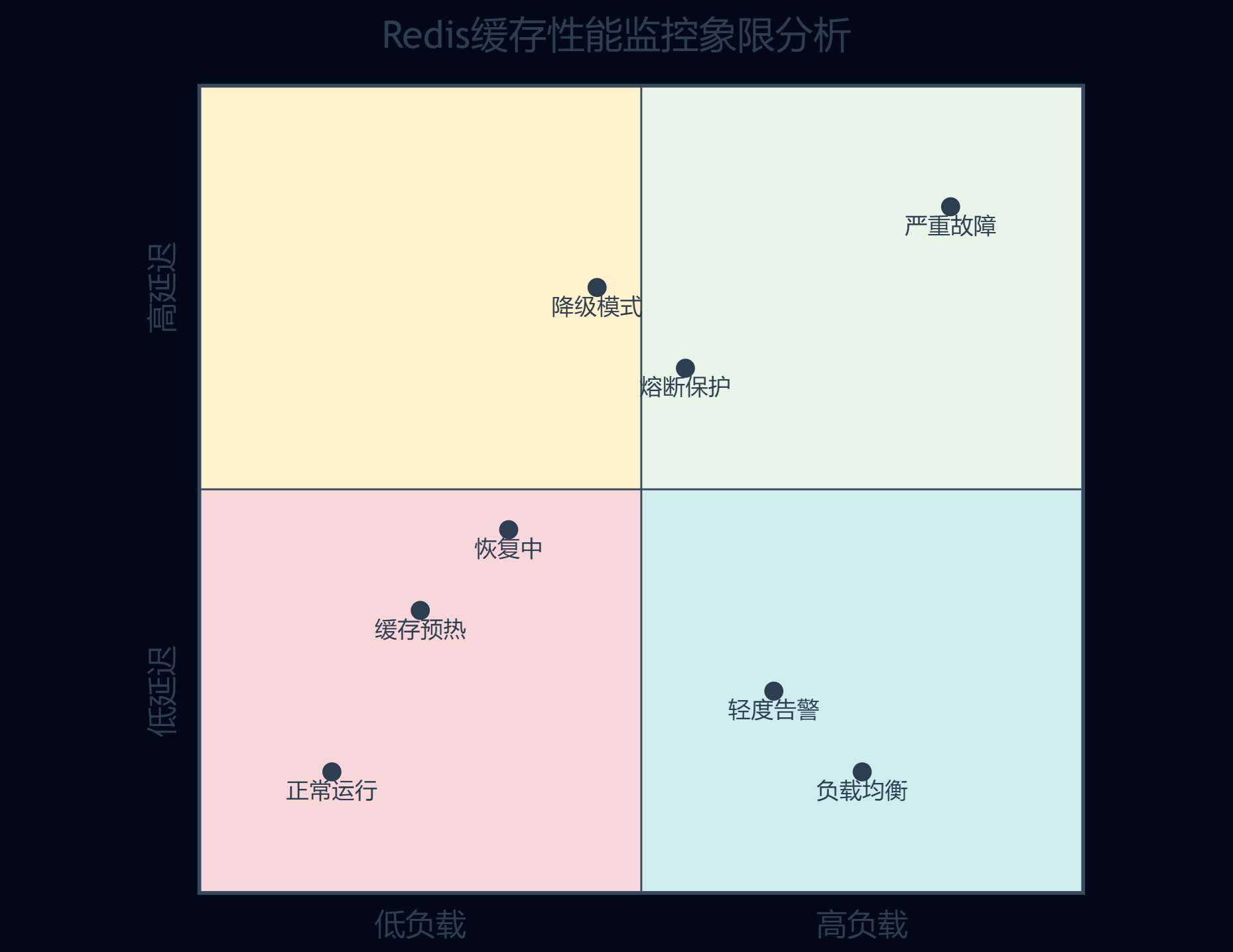
图6:缓存性能监控象限图 - 展示不同状态下的系统表现
七、 最佳实践与避坑指南
7.1 缓存设计原则
核心原则:缓存不是万能的,但没有缓存是万万不能的。设计缓存系统时,要始终考虑"缓存失效时系统是否还能正常运行"这个问题。
基于这次实战经验,我总结了以下最佳实践:
-
永远不要让所有缓存同时过期
-
建立多层防护,单点故障不应影响整体
-
监控先行,预防胜于治疗
-
降级策略必须经过充分测试
7.2 常见陷阱与解决方案
| 陷阱类型 | 具体表现 | 解决方案 | 预防措施 |
|---|---|---|---|
| 同时过期 | 大量缓存同一时间失效 | 随机过期时间 | 分散过期策略 |
| 热点数据 | 单个key访问量过大 | 数据分片 | 负载均衡 |
| 缓存穿透 | 恶意查询不存在数据 | 布隆过滤器 | 参数校验 |
| 缓存击穿 | 热点key过期瞬间 | 互斥锁重建 | 提前刷新 |
7.3 运维操作规范
#!/bin/bash
# Redis安全重启脚本
echo "开始Redis集群安全重启流程..."
# 1. 检查当前负载
current_qps=$(redis-cli info stats | grep instantaneous_ops_per_sec | cut -d: -f2)
if [ $current_qps -gt 1000 ]; thenecho "当前QPS过高($current_qps),建议等待低峰期执行"exit 1
fi
# 2. 启用降级模式
curl -X POST "http://api-gateway/admin/degradation/enable"
# 3. 预热关键缓存到备用实例
redis-cli --scan --pattern "hot:*" | xargs -I {} redis-cli -h backup-redis get {}
# 4. 逐个重启节点(而非全部重启)
for node in redis-node-1 redis-node-2 redis-node-3; doecho "重启节点: $node"systemctl restart $nodesleep 30 # 等待节点恢复# 检查节点状态redis-cli -h $node pingif [ $? -ne 0 ]; thenecho "节点 $node 重启失败"exit 1fi
done
# 5. 关闭降级模式
curl -X POST "http://api-gateway/admin/degradation/disable"
echo "Redis集群重启完成"八、 总结与思考
通过这次缓存雪崩事故的完整复盘,我深刻认识到了系统稳定性建设的重要性。作为一名技术人员,我们不能仅仅满足于功能的实现,更要考虑系统在极端情况下的表现。
这次事故让我学到了几个重要的教训:首先,监控体系是系统稳定性的生命线,没有完善的监控,我们就是在盲飞;其次,多层防护机制是必需的,单一的防护措施在面对复杂故障时往往力不从心;最后,应急响应能力决定了故障的影响范围,平时的演练和准备在关键时刻能够救命。
在技术架构设计方面,我们不能过度依赖任何单一组件,包括缓存。Redis虽然性能优异,但它的故障会带来连锁反应。通过构建多级缓存、熔断降级、智能监控的完整体系,我们能够在保证性能的同时,显著提升系统的容错能力。
从团队协作的角度来看,这次事故也暴露了我们在跨部门沟通和应急响应方面的不足。运维团队的维护操作没有充分考虑业务影响,开发团队对缓存依赖过重,监控团队的告警策略不够智能。通过建立更完善的协作机制和应急预案,我们能够更好地应对类似的挑战。
最重要的是,我意识到技术人员需要具备系统性思维。我们不能只关注自己负责的模块,而要从整个系统的角度思考问题。每一个技术决策都可能产生连锁反应,我们需要提前考虑各种异常情况,并做好充分的准备。
这次实战经历让我更加坚信:优秀的系统不是没有故障,而是能够快速从故障中恢复。通过持续的监控、及时的告警、有效的降级和快速的恢复,我们能够将故障的影响降到最低。希望这篇文章能够帮助更多的技术同行避免类似的问题,让我们的系统更加稳定可靠。
🌟 嗨,我是Xxtaoaooo!
⚙️ 【点赞】让更多同行看见深度干货
🚀 【关注】持续获取行业前沿技术与经验
🧩 【评论】分享你的实战经验或技术困惑
作为一名技术实践者,我始终相信:
每一次技术探讨都是认知升级的契机,期待在评论区与你碰撞灵感火
参考链接
-
Redis官方文档 - 高可用性配置
-
Spring Boot Redis集成最佳实践
-
Hystrix熔断器设计原理
-
Caffeine本地缓存性能优化
-
分布式系统监控告警实践