Linux之Shell编程(四)函数、数组、正则
1. 函数使用
1.1 函数定义与基础规则
- 定义方式:有两种定义形式,一是
function 函数名(),二是直接函数名(),函数体用{}包裹,可加return int返回值(不加则以最后一条命令结果为返回值)。 - 使用前提:Shell 中函数需先定义后使用,需放在脚本开始部分,调用时仅用函数名即可。
1.2 函数的简单使用
- 示例代码:
#!/bin/bash
# 定义函数print
function print()
{echo "hello"echo "你好"
}
# 调用print函数
print
- 执行结果:运行脚本后会依次输出 “hello” 和 “你好”。
1.3 函数的参数
- 参数获取:函数体内部通过
$n(n为数字)获取参数,$1是第一个参数,$2是第二个参数,当n≥10时需用${n}。 - 参数相关变量:
$#获取参数总数,$*将所有参数作为一个字符串输出。 - 示例代码:
#!/bin/bash
# 定义带参数的函数funWithParam
funWithParam()
{echo "第一个参数为 $1"echo "第二个参数为 $2"echo "第十个参数为 ${10}"echo "第十一个参数为 ${11}"echo "参数总数有 $# 个"echo "作为一个字符串输出所有参数 $*"
}
# 调用函数并传递参数
funWithParam 1 2 3 4 5 6 7 8 9 34 73
- 执行结果:会分别输出对应参数信息,如 “第一个参数为 1”“参数总数有 11 个” 等。
1.4 函数的返回值
- 返回方式:函数内用
return 数据值返回,且只能返回一个值。 - 返回值获取:函数调用后,返回值默认存储在
$?中,可通过$?获取。 - 示例代码:
#!/bin/bash
# 定义获取最大值的函数getMax
function getMax()
{if [ $1 -lt $2 ]; thenreturn $2elsereturn $1fi
}
# 调用函数
getMax $1 $2
# 输出最大值
echo "最大值::$?"
- 执行结果:运行脚本并传递两个参数,会输出较大的那个参数值。


2. 数组
2.1 数组定义
- 定义方式:Bash Shell 仅支持一维数组,初始化无需指定大小。一种是
array_name=(value1 value2 ... valueN),元素用空格分隔;另一种是array_name[索引]=元素值,索引从 0 开始。 - 示例:
my_array=(A B "C" D)或my_array[0]=A。
2.2 数组读取
2.2.1 读取单个元素
- 格式:
${array_name[index]},index为数组索引(从 0 开始)。 - 示例代码:
#!/bin/bash
my_array=(A B "C" D)
echo "第一个元素为: ${my_array[0]}"
echo "第二个元素为: ${my_array[1]}"
- 执行结果:输出 “第一个元素为: A”“第二个元素为: B” 等。
2.2.2 读取所有元素
- 格式:
${array_name[*]}或${array_name[@]},两者都能获取数组所有元素。 - 示例代码:
#!/bin/bash
my_array[0]=A
my_array[1]=B
echo "数组的元素为: ${my_array[*]}"
echo "数组的元素为: ${my_array[@]}"
- 执行结果:均输出 “数组的元素为: A B”。
2.2.3 获取数组长度
- 格式:
${#array_name[*]}或${#array_name[@]},用于获取数组元素个数。 - 示例代码:
#!/bin/bash
my_array[0]=A
my_array[1]=B
echo "数组元素个数为: ${#my_array[*]}"
- 执行结果:输出 “数组元素个数为: 2”。
2.3 数组遍历
2.3.1 方式一
- 代码:
#!/bin/bash
my_arr=(AA BB CC)
for var in ${my_arr[*]}
doecho $var
done
- 原理:通过
for循环遍历${my_arr[*]}获取的所有数组元素,依次输出。
2.3.2 方式二
- 代码:
#!/bin/bash
my_arr=(AA BB CC)
my_arr_num=${#my_arr[*]}
for((i=0;i<my_arr_num;i++));
doecho ${my_arr[$i]}
done
- 原理:先获取数组长度
my_arr_num,再通过for循环(从 0 到数组长度 - 1),根据索引$i获取并输出每个元素。
3. 加载其它文件的变量
3.1 加载语法与作用
- 语法格式:有两种方式,一是
. filename(注意点号和文件名间有空格),二是source filename。 - 作用:在一个 Shell 程序中包含外部 Shell 脚本,便于封装公用代码,实现数据源和业务处理分离,提升代码复用性和扩展性。
3.2 示例操作
3.2.1 步骤一:创建 test1.sh
- 代码:
#!/bin/bash
my_arr=(AA BB CC)
- 功能:定义数组
my_arr。
3.2.2 步骤二:创建 test2.sh
- 代码:
#!/bin/bash
# 加载test1.sh的内容
source /export/shelldemo/test1.sh
# 循环打印数组元素
for var in ${my_arr[*]}
doecho $var
done
- 功能:加载
test1.sh中的数组my_arr,并通过循环输出数组元素。 - 执行结果:运行
test2.sh,会依次输出 “AA”“BB”“CC”。
4. 正则表达式
4.1正则表达式基础
1. 定义与功能
- 定义:正则表达式(Regular Expression,简称 regex/regexp/RE)是描述字符串模式的规则。
- 功能:实现对字符串的检索、替换、过滤,筛选符合特定规则的内容。
2. 用途
- 系统日志筛选,如定位 “登录失败”“服务启动失败” 相关日志。
- 配置文件解析,提取或验证配置项内容。
- 文本查找替换,批量修改符合规则的文本。
- 脚本编程中的条件匹配,判断字符串是否符合预设格式。
3. Linux 正则表达式分类
| 类别 | 特点 | 常用工具 | 关键语法差异 | |
|---|---|---|---|---|
| BRE(基础正则表达式) | 传统语法,功能有限 | grep、sed | 量词{}需转义为\{n,m\};+、?、()需转义 | |
| ERE(扩展正则表达式) | 功能更强,语法简洁 | egrep(grep -E)、awk | +、?、()、{}、` | ` 等无需转义 |
4.2 正则表达式组成
1. 普通字符
- 包括字母(a-z、A-Z)、数字(0-9)、标点符号(如.、,、!)等,匹配自身。
2. 元字符(核心规则)
| 元字符 | 含义 | 示例 |
|---|---|---|
. | 匹配任意单个字符(除 \r\n) | a.b可匹配 aab、acb,不匹配 a\nb |
[] | 匹配字符集中的任意一个字符 | go[ola]d可匹配 gold、golad、good;[a-z0-9]匹配小写字母或数字 |
[^list] | 匹配不在字符集中的任意一个字符 | [^a-z]匹配非小写字母的字符 |
^ | 匹配行首 | ^the匹配以 “the” 开头的行 |
$ | 匹配行尾 | \.$匹配以 “.” 结尾的行(\.转义 “.” 的特殊意义) |
\ | 转义符,忽略后续字符的特殊意义 | a\.b仅匹配 a.b,不匹配 ajb |
3. 重复次数限定符
| 限定符 | 含义 | 示例 | 适用类别差异 | |||
|---|---|---|---|---|---|---|
* | 匹配前面子表达式 0 次或多次 | goo*d可匹配 gd、god、good | BRE/ERE 通用 | |||
+ | 匹配前面子表达式至少 1 次 | wo+d可匹配 wod、wood、woood | BRE 需转义\+,ERE 无需转义 | |||
? | 匹配前面子表达式 0 次或 1 次 | bes?t可匹配 bet、best | BRE 需转义\?,ERE 无需转义 | |||
{n} | 匹配前面子表达式恰好 n 次 | go\{2\}d(BRE)、go{2}d(ERE),均匹配 good | ||||
{n,m} | 匹配前面子表达式 n 到 m 次 | wo\{2,5\}d(BRE)、wo{2,5}d(ERE),匹配 wood 到 woooood | ||||
{n,} | 匹配前面子表达式至少 n 次 | [0-9]\{2,\}(BRE)、[0-9]{2,}(ERE),匹配两位及以上数字 | ||||
| ` | ` | 逻辑 “或”,匹配多个表达式之一 | `of | is | on` 可匹配 of、is、on | BRE 需转义|,ERE 无需转义 |
() | 分组,将多个字符视为一个整体 | `t(a | e) st` 可匹配 tast、test | BRE 需转义\(\),ERE 无需转义 | ||
()+ | 匹配重复的分组(至少 1 次) | A(xyz)+C可匹配 AxyzC、AxyzxyzC | 仅 ERE 支持(无需转义) |
4.3 文本处理器:grep 工具
1. 常用选项
| 选项 | 功能 | 示例 |
|---|---|---|
-E | 启用扩展正则表达式(等价于 egrep) | grep -E 'wo{2}d' test.txt |
-c | 统计匹配内容的行数 | grep -c root /etc/passwd(统计含 root 的行数) |
-i | 忽略大小写匹配 | grep -i "the" web.sh(匹配 the、The、THE) |
-o | 只输出匹配的内容,不输出整行 | grep -o '[0-9]' test.txt(仅输出所有数字) |
-v | 反向匹配,输出不包含匹配内容的行 | grep -v root /etc/passwd(输出不含 root 的行) |
-n | 显示匹配内容所在的行号 | grep -n 'the' test.txt |
--color=auto | 高亮显示匹配的内容 | grep --color=auto 'root' /etc/passwd |
2. 典型示例
- 提取 IP 地址:
grep -o '[0-9]\+\.[0-9]\+\.[0-9]\+\.[0-9]\+' ifconfig.out | head -1 - 匹配以 “the” 开头的行:
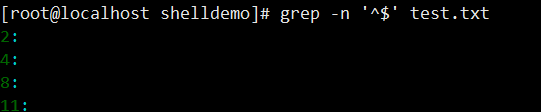
grep -n '^the' test.txt - 匹配空行:
grep -n '^$' test.txt
4.4 基础正则(BRE)与扩展正则(ERE)对比
1. BRE 常见元字符
- 包含
^(行首)、$(行尾)、.(任意单字符)、[list](字符集)、[^list](反向字符集)、*(0 或多次)。 - 次数限定需转义:
\{n\}(精确 n 次)、\{n,\}(至少 n 次)、\{n,m\}(n~m 次)。
2. ERE 新增功能(无需转义)
- 支持
+(至少 1 次)、?(0 或 1 次)、|(或逻辑)、()(分组)、()+(重复分组)。 - 次数限定直接用
{n}、{n,}、{n,m}。
4.5 元字符操作案例(基于 grep)
查找特定字符:
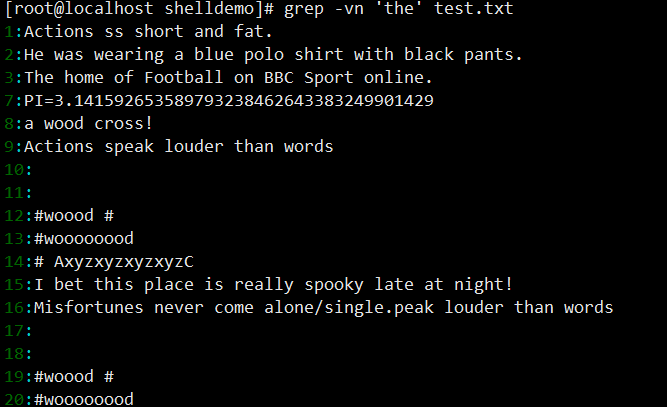
grep -n 'the' test.txt(匹配含 “the” 的行并显示行号);

grep -vn 'the' test.txt(反向匹配,输出不含 “the” 的行)。
中括号集合:
grep -n 'sh[io]rt' test.txt(匹配 shirt 或 short);
![]()
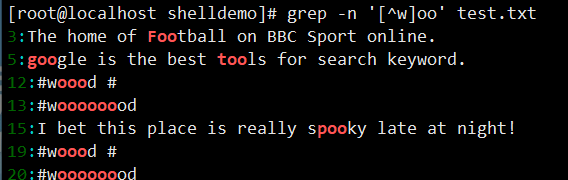
grep -n '[^w]oo' test.txt(匹配前面不是 w 的 “oo”,如 foo、too)。
定位符:
grep -n '^the' test.txt(行首是 “the”);

grep -n '\.$' test.txt(行尾是 “.”);

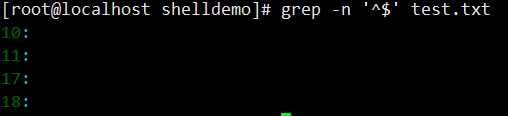
grep -n '^$' test.txt(匹配空行)。
点与星:
grep -n 'w..d' test.txt(w 开头、d 结尾,中间 2 个任意字符,如 ward、wind);

grep -n 'woo*d' test.txt(w 开头、d 结尾,中间 o 可有可无,如 wd、wod);
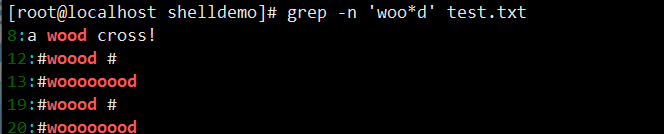
grep -n 'w.*d' test.txt(w 开头、d 结尾,中间任意字符,如 wad、wabcd)。
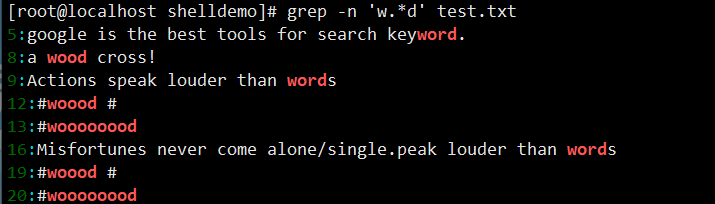
次数限定符:
grep -n 'o\{2\}' test.txt(匹配含 “oo” 的行);
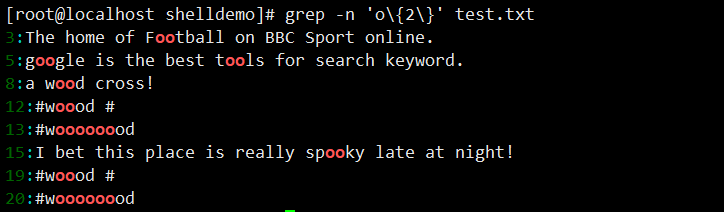
grep -n 'wo\{2,5\}d' test.txt(w 开头、d 结尾,中间 2-5 个 o,如 wood、woood);

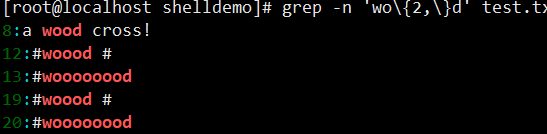
grep -n 'wo\{2,\}d' test.txt(w 开头、d 结尾,中间至少 2 个 o,如 wood、woooood)。
5. 总结
函数:
- 参数:用
$n接收($1、${10}),调用时直接跟在函数名后 - 返回值:
return输出,结果存于$?中
- 参数:用
数组:
- 定义:
数组名=(元素...)或数组名[索引]=值 - 访问:
${数组名[索引]}取单个,${数组名[@/*]}取所有 - 遍历:
for循环遍历元素或通过索引(结合长度${#数组名[@]})
- 定义:
正则与 grep:
- 功能:按模式匹配字符串,用于文本处理
- grep 常用选项:
-E(扩展正则)、-c(计数)、-i(忽略大小写)等 - 核心元字符:
^(行首)、$(行尾)、.(任意字符)、*(0 + 次)、[](字符集)、{n,m}(次数范围)等