大模型 RAG 项目必看:技术架构拆解 + 实战步骤,新手也能快速上手
注:此文章内容均节选自充电了么创始人,CEO兼CTO陈敬雷老师的新书《GPT多模态大模型与AI Agent智能体》(跟我一起学人工智能)【陈敬雷编著】【清华大学出版社】
清华《GPT多模态大模型与AI Agent智能体》书籍配套视频课程【陈敬雷】
文章目录
- GPT多模态大模型与AI Agent智能体系列一百一二十三
- 大模型 RAG 项目必看:技术架构拆解 + 实战步骤,新手也能快速上手
- 更多技术内容
- 总结
GPT多模态大模型与AI Agent智能体系列一百一二十三
大模型 RAG 项目必看:技术架构拆解 + 实战步骤,新手也能快速上手
5.1.2 RAG技术架构
RAG基础技术架构始于一个庞大的文本文档语料库,其核心在于通过检索技术辅助大模型生成答案,使得模型的回答不仅仅依赖于其自身的预测,而是有实际的、可查证的信息作为支撑。RAG的基础技术架构可以分为以下几个关键环节:
(1)数据准备:首先,需要将大量的文本数据加载并准备好,这通常由功能强大的开源数据加载工具来完成,这些工具能够连接到各种数据源,如YouTube、Notion等。
(2)分块与向量化:将文本切分为多个段落,并利用Transformer编码器模型将这些段落转换成向量形式。这一步骤的目的是为了将非结构的文本数据转化为计算机可以高效处理的数值型数据。
(3)建立索引:将所有向量汇集到一个索引中,这个索引将作为后续检索操作的基石。
(4)检索过程:当用户提出一个查询时,同样的编码器模型会将这个查询转换成向量,然后系统会在索引中搜索与查询向量最相近的前k个结果。
(5)上下文提供:从数据库中提取与查询最相关的文本段落,并将这些段落作为上下文信息提供给大语言模型。
(6)生成答案:大语言模型根据所提供的上下文信息和原始查询生成最终的答案。
(7)后处理:在某些情况下,可能需要对检索结果进行进一步的过滤、重新排序或转换,以优化最终输出的答案。
RAG基础技术架构如图5-1所示。
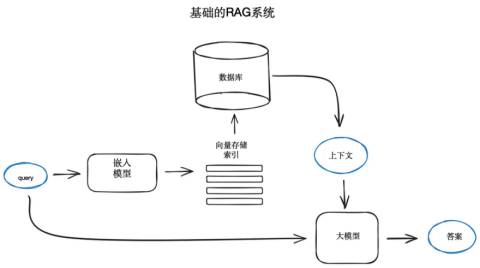
图5-1 RAG基础技术架构
RAG技术的发展不仅限于上述基础架构,还包括了多种高级技术和优化策略,如查询转换、智能体行为、聊天引擎开发、查询路由决策等,这些高级技术使得RAG系统更加灵活和智能,能够更好地适应用户多样化的需求。RAG高级技术架构如图5-2所示。
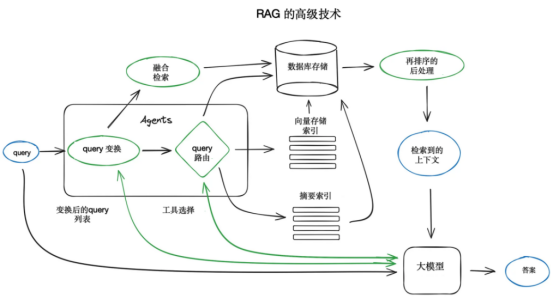
图5-2 RAG高级技术架构
RAG高级技术架构主要包括以下几个方面:
(1)分块和矢量化:将文档分割成块,并为每个块生成向量表示,以便后续索引和检索。
(2)搜索的索引:构建索引以存储文档块的向量,并使用向量搜索技术如Faiss来高效检索与查询向量最接近的文档块。
(3)Rerank重排序和过滤:对检索结果进行过滤和重新排序,以提高答案的相关性和准确性。
(4)Query变换:通过大模型修改用户输入以提高检索质量,包括查询分解、后退提示和查询重写等技术。
(5) 聊天引擎:支持连续对话,考虑对话历史和上下文,适用于多轮交互式问答场景。
(6)Query路由:根据用户查询动态决定检索路径,例如选择不同的索引或数据存储。
(7)智能体Agent:利用大模型作为推理引擎,结合一系列工具和任务,形成能够自主决策的智能体。
(8)响应合成:将检索到的上下文与用户查询结合,通过大模型生成最终的答案。
接下来深入讲解每个关键环节。
5.1.3分块和矢量化
为了在RAG系统中实现高效的信息检索,首先需要将文档内容转换为向量索引。这一过程涉及到将文本数据分块并转换为向量表示,以便在运行时搜索与查询向量最接近的语义匹配。由于Transformer模型具有固定的输入序列长度限制,因此对数据进行分块是一种有意义的技术。通过将初始文档分成一定大小的块,可以确保每个块都能代表其所包含的一个或几个句子的语义意义。这样,即使输入上下文的窗口很大,一个或几个句子的向量也比一个在几页文本上取平均值的向量更能代表它们的语义意义。在进行数据分块时,可以采用各种现有的文本分割器实现,例如在LlamaIndex中,NodeParser提供了一些高级选项,如定义自己的文本分割器、元数据、节点/块关系等。数据块的大小是一个重要的参数,它取决于所使用的嵌入模型及其Token容量。标准的Transformer编码模型,如BERT的句子转换器,最多只能使用512个Token。而OpenAI的ada-002模型能够处理更长的序列,如8191个Token。然而,在选择数据块大小时,需要在足够的上下文和特定的足够文本嵌入之间进行权衡,以便有效地执行搜索。接下来,需要选择一个模型来生成所选块的嵌入。有许多方法可供选择,例如搜索优化的模型(如bge-large-zh或E5系列),MTEB排行榜可以提供最新的一些方法信息。此外,还可以考虑使用中文Embedding模型,如gte-large-zh、bge-large-zh-v1.5、multilingual-e5-large、m3e-base和bce-embedding-base v1等。总之,在RAG系统中,分块和向量化是实现高效信息检索的关键步骤。通过合理地划分数据块并选择合适的模型生成嵌入,可以在保持语义准确性的同时提高搜索效率。
下一篇内容详解更多…
更多技术内容
更多技术内容可参见
清华《GPT多模态大模型与AI Agent智能体》书籍配套视频【陈敬雷】。
更多的技术交流和探讨也欢迎加我个人微信chenjinglei66。
总结
此文章有对应的配套新书教材和视频:
【配套新书教材】
《GPT多模态大模型与AI Agent智能体》(跟我一起学人工智能)【陈敬雷编著】【清华大学出版社】
新书特色:《GPT多模态大模型与AI Agent智能体》(跟我一起学人工智能)是一本2025年清华大学出版社出版的图书,作者是陈敬雷,本书深入探讨了GPT多模态大模型与AI Agent智能体的技术原理及其在企业中的应用落地。
全书共8章,从大模型技术原理切入,逐步深入大模型训练及微调,还介绍了众多国内外主流大模型。LangChain技术、RAG检索增强生成、多模态大模型等均有深入讲解。对AI Agent智能体,从定义、原理到主流框架也都进行了深入讲解。在企业应用落地方面,本书提供了丰富的案例分析,如基于大模型的对话式推荐系统、多模态搜索、NL2SQL数据即席查询、智能客服对话机器人、多模态数字人,以及多模态具身智能等。这些案例不仅展示了大模型技术的实际应用,也为读者提供了宝贵的实践经验。
本书适合对大模型、多模态技术及AI Agent感兴趣的读者阅读,也特别适合作为高等院校本科生和研究生的教材或参考书。书中内容丰富、系统,既有理论知识的深入讲解,也有大量的实践案例和代码示例,能够帮助学生在掌握理论知识的同时,培养实际操作能力和解决问题的能力。通过阅读本书,读者将能够更好地理解大模型技术的前沿发展,并将其应用于实际工作中,推动人工智能技术的进步和创新。
【配套视频】
清华《GPT多模态大模型与AI Agent智能体》书籍配套视频【陈敬雷】
视频特色: 前沿技术深度解析,把握行业脉搏
实战驱动,掌握大模型开发全流程
智能涌现与 AGI 前瞻,抢占技术高地
上一篇:《GPT多模态大模型与AI Agent智能体》系列一》大模型技术原理 - 大模型技术的起源、思想
下一篇:DeepSeek大模型技术系列五》DeepSeek大模型基础设施全解析:支撑万亿参数模型的幕后英雄