【ElasticSearch实用篇-04】Boost权重底层原理和基本使用
ElasticSearch实用篇整体栏目
| 内容 | 链接地址 |
|---|---|
| 【一】需求分析和数据制造 | https://zhenghuisheng.blog.csdn.net/article/details/149178534 |
| 【二】基本增删改查 | https://zhenghuisheng.blog.csdn.net/article/details/149202330 |
| 【三】QueryDsl高阶用法以及缓存机制 | https://zhenghuisheng.blog.csdn.net/article/details/150560441 |
| 【四】Boost权重底层原理和基本使用 | https://zhenghuisheng.blog.csdn.net/article/details/151071140 |
Boost权重控制
- 一,Boost权重控制
- 1,Boost的底层算法
- 1.1,TF/IDF算法
- 1.1.1,TF设计
- 1.1.2,IDF设计
- 1.1.3,最终算分
- 1.2,BM25算法
- 2,Field Boost
- 2.1,单字段算分
- 2.2,多字段算分
- 2.3,使用场景
- 3,Query Boost
- 4,QueryBoost 和Field Boost区别
如需转载,请附上链接:https://blog.csdn.net/zhenghuishengq/article/details/151071140
一,Boost权重控制
前面讲解了es的基本查询以及常用的高级查询,接下来这篇开始讲解es的核心重点权重设计,就是我们平常时所说的打分,给某某打更高分,这样谁的优先级就会更高,谁就能出现在前面。
- 比较经典的就是百度里面的广告,谁给的多就能把广告放在浏览器页面的前面
- 比如电商行业,比如在查询某个手机或者品牌时,需要将标题的权重高于商品描述的权重
- 比如现在比较火热的boss直聘,想要找到java开发的候选人,那么就会把标题设置的权重高于简历内容,或者直接通过标签进行筛选查询
- 比如社交类产品,想要优先找到同城异性到的高学历的用户匹配,那么会对异性和同城设置权重
在了解这些功能的底层到底是怎么实现的,那么就得深入的对这个boost权重进行分析,在了解之前,依旧是需要先看官网:https://www.elastic.co/guide/cn/elasticsearch/guide/current/scoring-theory.html
1,Boost的底层算法
虽然这个系列讲解的是如何使用系列,但本博主还是觉得很有必要的对这个底层算法进行讲解一遍,因为后面的 Field Boost、Query Boost、Function Score 这些打分方式都会依赖于boost的底层实现,除非全用脚本打分,脚本打分可以绕过这个BM25
1.1,TF/IDF算法
官方也介绍了词的权重的设计由三个因素决定:词频、逆向文档频率、字段长度归一值,看到这三个前应该是满脑子雾水,该算法指的就是将tf算法得到的值和idf算法得到的值就行相乘得到最终得分。下面分别讲解一下tf和idf的设计。
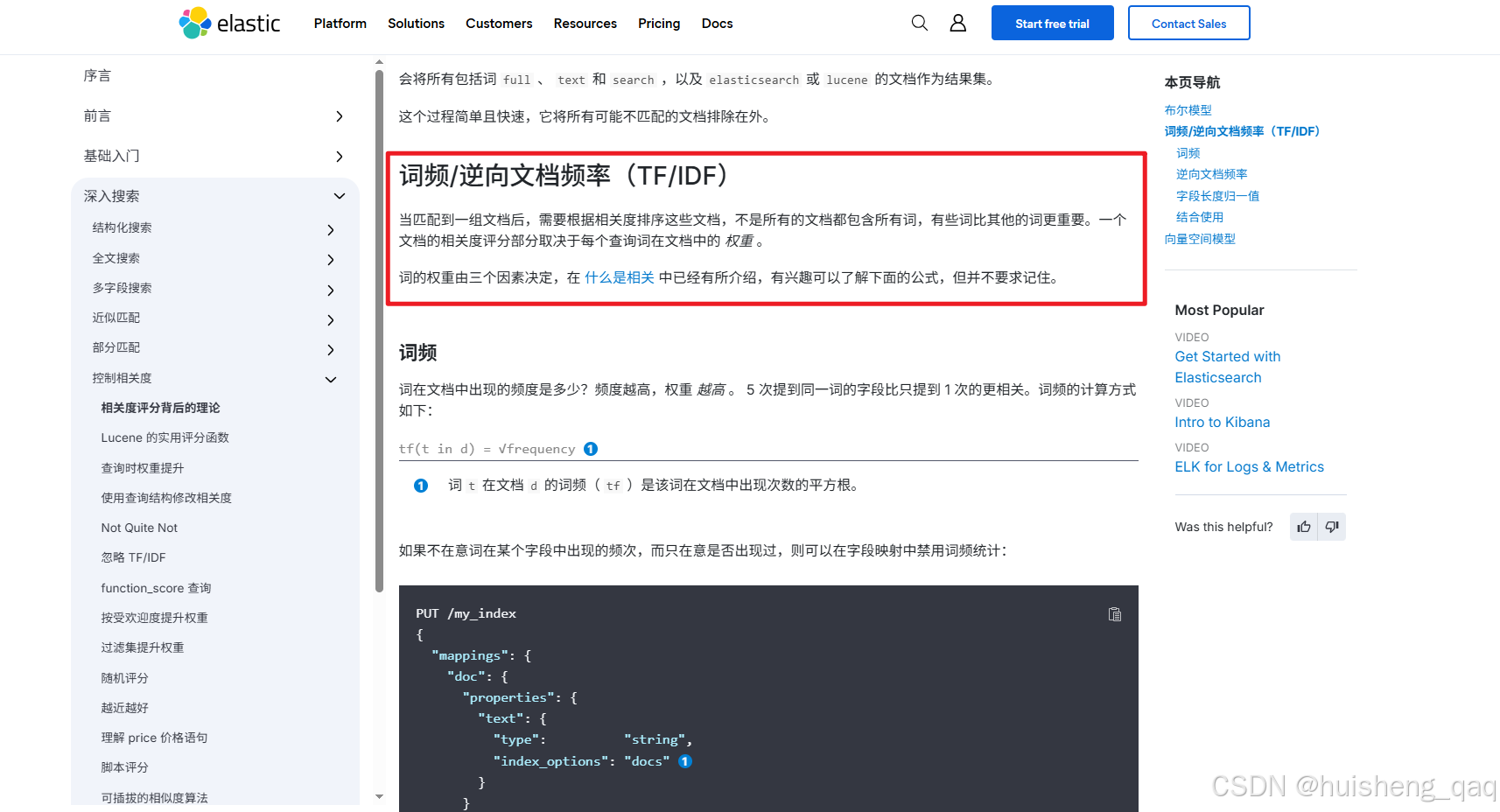
1.1.1,TF设计
先说结论,tf设计指的是在单个文档中,某个词出现的个数占所有分词后的词总个数的百分比,举个例子:通过ik分词器的ik_max_word分词器对title进行分词,title的内容为中华人民共和国
["我", "爱", "中华", "中华人民共和国", "中华人民", "人民共和国", "人民", "共和国"]
分词后的内容如上,接下来获取 人民 的tf值,人民出现的个数为1,总词数的总个数为8,那么tf的值为1/8=0.125,所以说tf的设计就是,在单个文档中,谁占比越大谁tf值就越高。
其公式如下,f(t,d) 表示分词后该词的总个数,|d|表示分词后全部词的总个数。
TF(t,d)=f(t,d)∣d∣TF(t,d) = \frac{f(t,d)}{|d|} TF(t,d)=∣d∣f(t,d)
1.1.2,IDF设计
上面的tf是在单个文档中谁值越多占比越大,而这个idf与tf就相反,首先其作用域就是针对于全部文档,其次就是其占比越大其idf值约小,主要是为了过滤一些常用词,比如是,你,我,呀,啊等,反而对那些出现概率较小的词得分越高比如出现elasticsearch、kafka、rocketmq、mongodb 这些,应该是在全部文档中出现的概率都会比较小,所以获取的值就会更大,其公式如下
N表示总文档数,就是总数据条数,df(t) 表示包含词t的文档数,分母还需要+1,并且在外面取一个对数
IDF(t)=logN1+df(t)IDF(t) = \log \frac{N}{1+df(t)} IDF(t)=log1+df(t)N
1.1.3,最终算分
tf和idf的乘积就是TF/IDF算分的最终算分,其公式如下,总结就是文档里出现的多,那么TF值高;在全库里比较稀缺,那么IDF高
TF−IDF(t,d)=TF(t,d)×IDF(t)TF-IDF(t,d) = TF(t,d) \times IDF(t) TF−IDF(t,d)=TF(t,d)×IDF(t)
1.2,BM25算法
BM25算法属于是TF/IDF的一个2.0优化版本,解决TF/IDF一些极端操作所带来的算分不准确的问题,存在的问题有如下几点:
- tf算法中,如果全部都是叠词或者存在大量相同的叠词,那么这个词就会趋近于100%
- tf算法中,短文档的tf算分会比长文挡的值高,比如我喜欢java和我们今年开学第一节课是java,看公式分子一样都是1,短文档分母小
- idf算法中,如果刚好每个文档都有 java ,那么这个权重值就会被压缩成接近log(1),其值就是0
- idf算法中,如果刚好有一个稀奇的词 比如狂风绝息斩,但是实际上这个词并不重要,但是IDF值会给的特别大,对实际业务没意义
- idf算法中,小语库不准,因为和实际的文档数相关,一次数据量小的时候,增加一两条数据变化量就会特别大
因此BM算法先对tf算法进行优化,解决文档趋近饱和以及关键词出现叠词堆砌,相对之前的来说是复杂了很多
TFBM25(t,d)=f(t,d)⋅(k1+1)f(t,d)+k1⋅(1−b+b⋅∣d∣avgdl)TF_{BM25}(t,d) = \frac{f(t,d) \cdot (k_1+1)}{f(t,d) + k_1 \cdot (1-b+b \cdot \tfrac{|d|}{avgdl})} TFBM25(t,d)=f(t,d)+k1⋅(1−b+b⋅avgdl∣d∣)f(t,d)⋅(k1+1)
- 解决词频增加的问题,当分数递增时区域无穷大,TF的部分分数就会趋近于(k1+1),不会无限上涨
- 解决短文档高于长文档问题,通过添加的参数,让长文档不会吃亏,短文档不会被夸大
再对IDF算法进行优化,分母分钟自都加一个0.5,同时分子再减去有关键词的文档数,其算法如下
IDF(t)=logN−df(t)+0.5df(t)+0.5IDF(t) = \log \frac{N - df(t) + 0.5}{df(t) + 0.5} IDF(t)=logdf(t)+0.5N−df(t)+0.5
- 高频词不会直接为0以及稀有词不会被无限放大
- 文档小的情况更加稳定,波动不会那么大
最后的算法如下,解决了原来算法的极端问题,让整个算法更加的平滑
score(q,d)=∑t∈qIDF(t)⋅f(t,d)⋅(k1+1)f(t,d)+k1⋅(1−b+b⋅∣d∣avgdl)score(q,d) = \sum_{t \in q} IDF(t) \cdot \frac{f(t,d) \cdot (k_1+1)}{f(t,d) + k_1 \cdot (1-b+b \cdot \tfrac{|d|}{avgdl})} score(q,d)=t∈q∑IDF(t)⋅f(t,d)+k1⋅(1−b+b⋅avgdl∣d∣)f(t,d)⋅(k1+1)
2,Field Boost
上面是简单的过了一下boost的底层原理,BM25最终是取代了tf/idf算法,弥补了极端情况下的缺陷。接下来要讲解的 Field Boost、Query Boost、Function Score底层都是基于BM25实现,就是在外层又加了不同的权重调价方式。
2.1,单字段算分
首先要讲解的是Field Boost,顾名思义,就是在某个字段上对权重的操作,首先来谈一下这个Field底层是如何调节BM25的分值的,对单字段操作的公式如下,其实比较简单,就是在原先的BM25算分的基础上,进行分数的相乘
score(q,d,f)=boostf⋅(IDF(t)⋅TFBM25(t,d,f))score(q,d,f) = boost_f \cdot \Big( IDF(t) \cdot TF_{BM25}(t,d,f) \Big) score(q,d,f)=boostf⋅(IDF(t)⋅TFBM25(t,d,f))
比如我要找老家省份是上海市的用户,并且设置他的boost分值为1,他的分数是3.553834,设置为2的时候,那么他的分数直接翻倍,他的大值为7.107668,其sql脚本如下,单纯的对单字段进行数据的查询
GET /user/_search
{"query": {"bool": {"should": [{"match": {"regProvince.keyword": {"query": "上海市","boost": 2}}}]}}
}
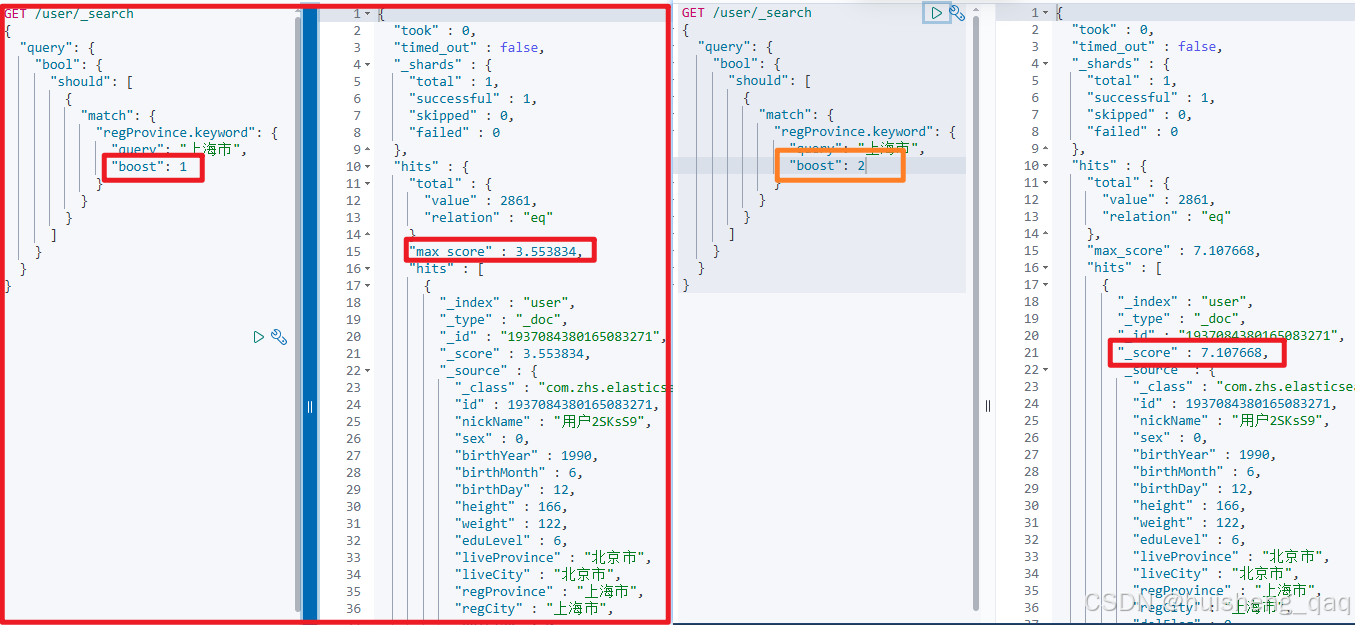
单字段对应的java代码为,依旧是使用高阶querydsl的方式进行获取
BoolQueryBuilder boolQueryBuilder = QueryBuilders.boolQuery();
boolQueryBuilder.should(QueryBuilders.matchQuery("regProvince.keyword", "上海市").boost(2));
2.2,多字段算分
多字段查询他的打分模式也是基于单个字段的打分模式,就是将每个字段的打分进行累加就是多字段的打分模式,其打分公式如下
score(q,d)=∑f∈fields(boostf⋅scoreBM25(q,d,f))score(q,d) = \sum_{f \in fields} \Big( boost_f \cdot score_{BM25}(q,d,f) \Big) score(q,d)=f∈fields∑(boostf⋅scoreBM25(q,d,f))
接下来对多字段进行操作,比如我要找居住城市或者老家城市是在北京市的用户,并且生活城市权重设置为3,老家城市设置的权重值为2
GET /user/_search
{"query": {"bool": {"should": [{"multi_match": {"query": "北京市","fields": ["liveCity.keyword^3","regCity.keyword^2" ]}}]}}
}
可以发现左边的多字段查询,就是等于右边的多个单字段查询的总和
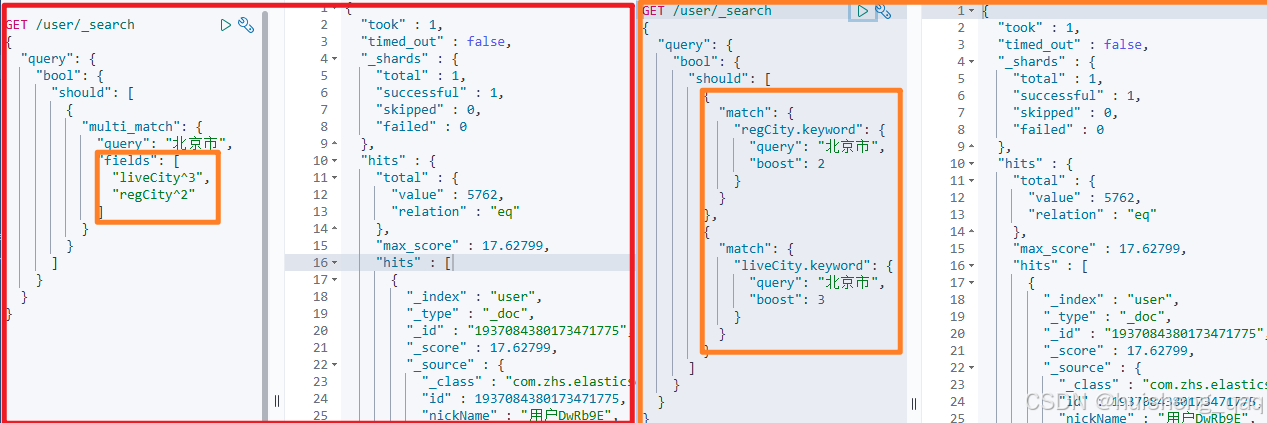
多字段查询对应的java代码如下,可以直接使用 multiMatchQuery 查询
BoolQueryBuilder boolQueryBuilder = QueryBuilders.boolQuery();
QueryBuilders.multiMatchQuery("北京市", "liveCity.keyword^3", "regCity.keyword^2");
最后,再通过表格将两种方式进行对比,可以发现主要是对每个字段的boost影响,多个就进行累加
| 查询方式 | 表达式 | 效果 |
|---|---|---|
| 单字段 boost | "match": {"regProvince": {"query": "上海市", "boost": 2}} | 单字段 BM25 × 2 |
| 多字段 boost | "multi_match": {"query": "北京市", "fields": ["liveCity^3","regCity^2"]} | 各字段打分相加 |
2.3,使用场景
既然是根据就某个数据data进行搜索,那么就表明字段之间都存在着这个data数据,如果想要让字段A的优先级高于字段B的优先级,那么就需要使用这种字段打分的场景进行权重设计。在实际开发中,一般在这些场景可以优先考虑对字段进行打分:
- 博客场景中,那么就可以调整标题权重大于正文权重
- 电商场景中,搜索iphone的商品的商品名称权重大于商品描述
- 招聘场景中,职位标题的权重大于职位描述的权重
3,Query Boost
上面讲解对于Field字段查询,主要是针对字段进行分数的加权,接下来讲解的是对于查询语句的权重影响,Query Boost也是通过操作BM25的方式来影响打分,其主要是提高或者降低某个子查询的重要性或者优先级
单字段查询的公式如下,在单字段查询时,可以将QueryBoost和FieldBoost查询等价,可以参考上面的FieldBoost单字段查询
score(q,d)=boostq⋅scoreBM25(q,d)score(q,d) = boost_q \cdot score_{BM25}(q,d) score(q,d)=boostq⋅scoreBM25(q,d)
多字段查询公式如下,其最终打分也是计算多个子查询的总分的和,然后通过总和进行排序
score(q,d)=∑qi∈queries(boostqi⋅scoreBM25(qi,d))score(q,d) = \sum_{q_i \in queries} \left( boost_{q_i} \cdot score_{BM25}(q_i,d) \right) score(q,d)=qi∈queries∑(boostqi⋅scoreBM25(qi,d))
如我需要查询生活城市在北京市或者上海市的用户,设置上海市的权重为5,北京市的权重为4,那么优先会将上海市的先查询出来,再将北京市的用户数据排在后面
GET /user/_search
{"query": {"bool": {"should": [{ "match": { "liveCity.keyword": { "query": "上海市", "boost": 5 } } },{ "match": { "liveCity.keyword": { "query": "北京市", "boost": 4 } } }]}}
}
多字段对应的java代码如下,就是对不同的子句设置不同的权重
BoolQueryBuilder boolQueryBuilder = QueryBuilders.boolQuery();
boolQueryBuilder.should(QueryBuilders.termQuery("regCity.keyword", "上海市").boost(5)).should(QueryBuilders.termQuery("liveCity.keyword", "北京市").boost(4));
4,QueryBoost 和Field Boost区别
queryBoost和Field字段的区别如下,一句话总结:
- Field Boost → 在字段层面调权重,决定“命中字段的价值”。
- Query Boost → 在子查询层面调权重,决定“命中条件的价值”。
| 对比维度 | Field Boost(字段加权) | Query Boost(查询子句加权) |
|---|---|---|
| 定义位置 | 查询 DSL 中,给某个字段加权(如 multi_match 里的 title^3) | 查询 DSL 中,给某个子查询整体加权(如 .boost(2f)) |
| 作用范围 | 针对某个字段的匹配结果进行放大或缩小 | 针对某个子查询的整体得分进行放大或缩小 |
| 应用场景 | 需要控制不同字段在搜索结果中的优先级 例:标题 > 描述 > 标签 | 需要控制不同查询条件在搜索结果中的优先级 例:上海市 > 北京市 |
| 实现方式 | 在 fields 参数里使用 ^n 或在 match/term 子句里 .boost(n) | 在 bool 查询里对不同的 should/must 子句 .boost(n) |
| 典型 DSL 示例 | "multi_match": {"query": "iphone","fields": ["title^3","desc^1"]} | bool: { should: [ {"match": {"city":"上海市","boost":5}}, {"match": {"city":"北京市","boost":4}} ] } |
| 影响范围 | 同一个 query 内,字段级别的打分权重调整 | 同一个 query 内,子查询整体的重要性调整 |
在后文会继续的 Function Score,因为Function Score比较重要,实际开发中用得到也比较多,因此单独用一篇文章来写