8.31【A】scons,带宽,语义semantic,读论文颜色规范,系统运行命令
scons
scons是一个现代化的软件构建工具。你可以将其理解为make的进阶版。它的任务是自动化编译链接过程,将源代码(C++, Python等)转换成可执行文件(如gem5.opt)、库文件或其他目标产物。- •
它是一个用 Python 编写的程序。这意味着构建描述文件(通常是根目录下的
SConstruct文件和目录中的SConscript文件)本质上也是 Python 脚本
选择合适的 J 值: 16是一个经验值。理想值是略小于或等于你的 CPU 物理核心数。可通过 nproc(Linux) 或 sysctl hw.ncpu(macOS) 命令查看核心数
gem5: 核心模拟器二进制
考虑内存: 编译gem5这样的庞然大物,每个g++进程可能消耗数百MB内存。并行16个任务意味着需要充足的物理内存(RAM)。如果内存不足导致频繁交换(Swap),并行提速效果反而会下降甚至系统卡死。
scons执行过程
- .
初始化:
- •
你在项目根目录执行
scons ...。 - •
SCons 引擎首先加载并执行根目录的
SConstruct文件。这是整个构建过程的主入口和总控脚本。
- •
- 2.
环境与配置:
- •
SConstruct初始化构建环境(Environment),设置全局编译选项(CC,CXX,CFLAGS,CXXFLAGS,LINKFLAGS,LIBS等),检测平台特性(操作系统、编译器版本等)。 - •
解析命令行参数(如
build/X86/gem5.opt,-j16)。
- •
- 3.
扫描
SConscript文件与依赖分析:- •
SConstruct通过SConscript()函数调用加载各子目录(如src/,src/cpu/,src/mem/等)的SConscript文件。 - •
在这些
SConscript文件中:- •
使用
Source(源文件列表) 和env(构建环境) 定义具体的构建规则。 - •
使用
,精确建立env.Object()构建器描述如何将每个.cc/.cpp文件编译成.o文件。SCons 在此时自动扫描源文件中#include语句.cc/.cpp -> .h/.hh -> 其他 .h/.hh的依赖树。这一步是实现正确增量编译的核心。 - •
使用
env.Program()或更复杂的自定义规则描述如何将大量的.o文件链接(ld/g++)成最终的可执行文件gem5.opt,也可能指定需要链接的库。 - •
处理其他需要构建的目标(如protobuf生成的代码、Python绑定、辅助工具等)。
- •
- •
SCons 引擎在内存中构建一个庞大而完整的全局依赖关系图。
- •
- 4.
决策与并行执行:
- •
引擎根据依赖图、目标文件(
build/X86/gem5.opt)和时间戳(或更重要的:内容哈希值),精确计算出需要重新编译的源文件列表(脏文件集)和需要重新链接的步骤。 - •
-j16选项生效,引擎调度器将独立的编译任务分派给最多16个工作线程(进程)并发执行。
- •
- 5.
输出:
- •
所有编译命令 (
g++ -I... -c -o ... file.cc) 和链接命令 (g++ -o ... 大量的 .o 文件 ...) 会被SCons打印到控制台(除非指定-Q安静模式)。 - •
中间文件(
.o)和最终可执行文件(gem5.opt)被写入build/X86/目录下对应的路径。 - •
构建成功/失败信息输出。
- •
缺少 pre-commit工具
pre-commit是一个 Python 框架,用于管理 Git 钩子
# 安装所有依赖(包括 pre-commit)
pip install -r requirements.txt
python3 -m venv .venv
# 创建隐藏的虚拟环境目录
带宽测试STREAM
STREAM(Sustainable Memory Bandwidth in Real Applications)是一种实测可持续内存带宽的基准测试工具,由John McCalpin提出。其核心目标是模拟真实应用中内存子系统的持续数据吞吐能力,而非硬件理论峰值

带宽
核心定义
在计算机体系结构中,带宽指的是在单位时间内,通过某个通道或接口能够成功传输的最大数据量。
- •
公式表达:
Bandwidth = (Data_Transferred) / (Time) - •
关键特性:它是一个速率概念,衡量的是“数据流动的持续吞吐量”,类似于水管单位时间内的出水量。
 一个系统可以拥有低延迟但低带宽(例如,L1缓存:响应极快,但容量小,总传输能力有限),也可以拥有高延迟但高带宽(例如,CXL内存:访问慢一些,但一旦开始传输,数据流很大)。理想状态是高带宽、低延迟
一个系统可以拥有低延迟但低带宽(例如,L1缓存:响应极快,但容量小,总传输能力有限),也可以拥有高延迟但高带宽(例如,CXL内存:访问慢一些,但一旦开始传输,数据流很大)。理想状态是高带宽、低延迟
延迟就是反应响应速度的参数
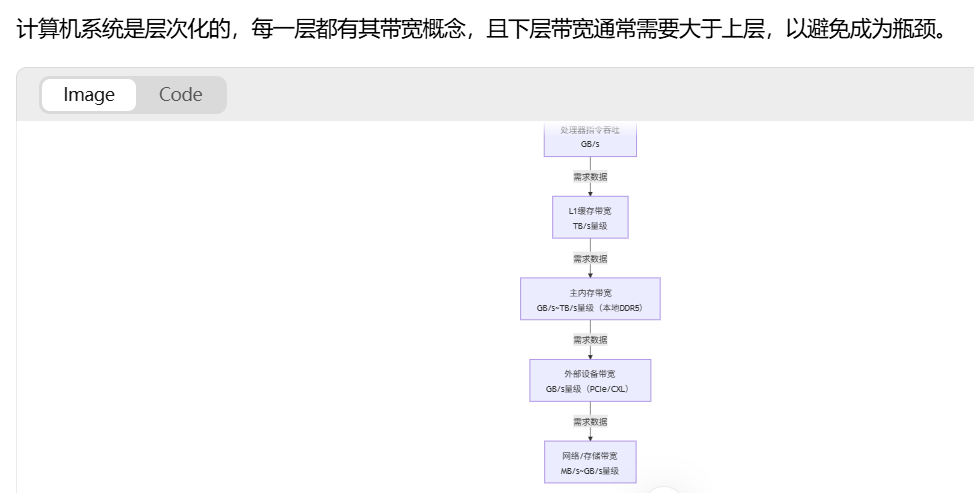 下层带宽 > 上层带宽:例如,内存带宽必须远大于网络带宽,否则CPU处理完的数据无法及时写入内存,会阻塞网络接收新数据
下层带宽 > 上层带宽:例如,内存带宽必须远大于网络带宽,否则CPU处理完的数据无法及时写入内存,会阻塞网络接收新数据
- •
内存带宽:限制了CPU/GPU数据处理的速度上限。无论你的CPU算力多强,如果数据无法从内存中快速加载,计算单元就会“饿死”(Stall),利用率下降。这就是所谓的“内存墙”(Memory Wall) 问题。
- •
I/O带宽(PCIe, 网络):决定了CPU与加速器(GPU、FPGA)、存储(NVMe SSD)及其他节点(InfiniBand)之间的数据交换能力。低I/O带宽会使昂贵的加速器无法充分发挥性能。
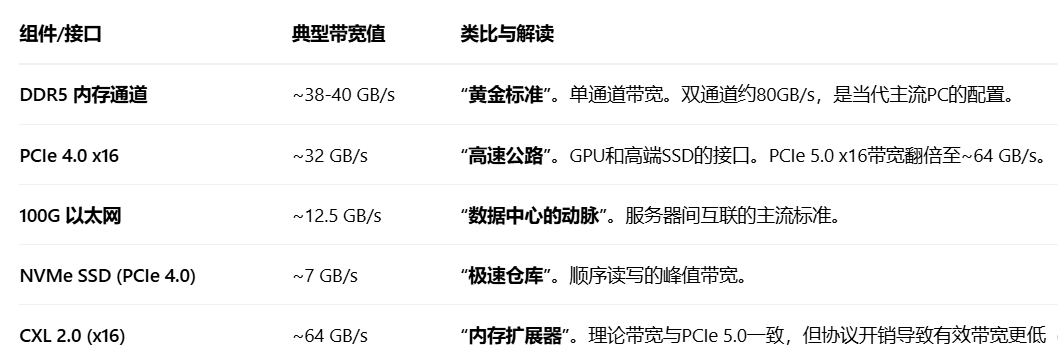
聚合带宽
通过并行使用多个独立的内存通道、控制器或内存域所获得的总体数据吞吐能力。它不是简单的数值相加,而是系统层面协同工作的结果。
核心思想:将单一的内存访问请求流,拆分(Striping) 到多个并行的内存路径上,从而同时利用这些路径的传输能力
形象比喻:
- •
单一DDR通道:像一条单向单车道的公路,单位时间内只能通过有限数量的车辆(数据)。
- •
聚合带宽(内存交错):像一条宽阔的多车道高速公路,多条车道同时通车,总通车量(总带宽)远高于单条车道。
内存交错(Memory Interleaving)
内存控制器将物理地址空间以特定的交错粒度(Interleave Granularity,通常为4KB或64KB)轮询映射到不同的内存通道或内存域上。

访问模式是关键:
- •
顺序访问(STREAM):完美契合交错策略,能最大化聚合带宽。
- •
随机访问:效果大打折扣。因为访问无法被预测,预取失效,CXL较高的延迟可能会凸显出来,反而可能使平均访问时间变长。
语义semantic
在体系结构语境中,“语义”指的是中央处理器(CPU)执行核心与外部设备进行交互时所遵循的约定、规则和机制。
- •
核心问题:CPU如何命令一个设备(如网卡、GPU、内存扩展卡)去执行一项任务(如传输数据)?
- •
不同语义:给出了这个问题的不同答案,每种答案都伴随着一系列不同的硬件和软件设计决策。
IO语义(I/O Semantics),在此上下文中,特指一种基于负载/存储(Load/Store)指令之外的特殊操作来完成数据交换的通信模型。它的核心特征是:数据移动需要软件的显式介入,并通过一个与内存空间隔离的、独立的地址空间(I/O空间)来完成。



规范
红色——论文实验效果,结论
蓝色——该研究领域的现状和重要性是什么?
橙色——现有工作的关键局限
黄色——本文的主要贡献,主要工作
紫色——未来工作
绿色——技术细节,主要方法
搁浅论文
Meta, “Reimagining memory expansion for single socket servers with CXL,” 2021, Accessed: Jan. 5, 2025. [Online]. Available: https: //146a55aca6f00848c565-a7635525d40ac1c70300198708936b4e.ssl. cf1.rackcdn.com/images/fa0cc66ccd41ff51dcbb4a7b5b311c8e338b482a. pdf.

H. Al Maruf et al., “Memory disaggregation: advances and open challenges,” SIGOPS Oper. Syst. Rev., vol. 57, pp. 29–37, Jun. 2023, doi:10.1145/3606557.3606562. [5] J. Gu et al., “Efficient memory disaggregation with INFINISWAP,” in Proc. 14th USENIX Conf. Netw. Syst. Des. Implement. (NSDI), 2017, pp. 649–667, doi:10.5555/3154630.3154683. [6] M.K. Aguilera et al., “Remote regions: a simple abstraction for remote memory,” in Proc. USENIX Annu. Tech. Conf. (ATC), 2018, pp. 775787, doi:10.5555/3277355.3277430. [7] J. Nelson et al., “Latency-tolerant software distributed shared memory,” in Proc. USENIX Annu. Tech. Conf. (ATC), 2015, pp. 291–305, doi:10.5555/2813767.2813789. [8] S.Y. Tsai et al., “Disaggregating persistent memory and controlling them remotely: an exploration of passive disaggregated key-value stores,” in Proc. USENIX Annu. Tech. Conf. (ATC), 2020, pp. 33–48, doi:10.5555/3489146.3489149. [9] Z. Ruan et al., “AIFM: High-performance, application-integrated far memory,” in Proc. 14th USENIX Symp. Oper. Syst. Des. Implement. (OSDI), 2020, pp. 315–332, doi:10.1145/3606557.3606562.

命令
build/X86/gem5.opt -d "output/fs_lmbench_dram" configs/example/gem5_library/x86-cxl-run.py --test_cmd lmbench_dram.sh --cpu_type TIMING