第2.4节:大模型之LLaMA系列(Meta)

🏆作者简介,黑夜开发者,CSDN领军人物,全栈领域优质创作者✌,CSDN博客专家,阿里云社区专家博主,2023年6月CSDN上海赛道top4。
🏆数年电商行业从业经验,历任核心研发工程师,项目技术负责人。
🏆本文已收录于专栏:智能时代:人人都要知道的AI课
🎉欢迎 👍点赞✍评论⭐收藏
本篇聚焦 Meta 推出的开源代表性大语言模型 LLaMA 系列(含 LLaMA 2/3 及指令微调衍生),梳理其版本谱系、模型架构、推理与微调方式、生态工具链与部署路径,帮助读者快速完成从实验到生产的闭环。
文章目录
- 🚀一、引言
- 🚀二、发展历程与版本谱系
- 🔎2.1 能力基线(示意)
- 🚀三、架构特点与训练要点
- 🔎3.1 模型架构
- 🔎3.2 训练与对齐
- 🔎3.3 提示工程策略
- 🚀四、推理与部署路径
- 🔎4.1 Hugging Face Transformers 推理
- 🔎4.2 llama.cpp 本地量化推理
- 🔎4.3 Ollama 一键运行
- 🔎4.4 批量与并发(Transformers 伪代码)
- 🚀五、轻量微调与适配(LoRA/QLoRA)
- 🔎5.1 LoRA 思路
- 🔎5.2 QLoRA 实践示例(伪代码)
- 🔎5.3 数据与评测
- 🔎5.4 DPO/ORPO 简述
- 🚀六、RAG 与企业知识场景
- 🔎6.1 标准流程
- 🔎6.2 实践守则
- 🔎6.3 简易 RAG 代码(Transformers + FAISS 伪代码)
- 🚀七、安全、合规与治理
- 🔎7.1 模型侧
- 🔎7.2 平台侧
- 🔎7.3 常见局限与避坑
- 🚀八、应用案例
- 🔎8.1 企业落地清单
- 🚀九、FAQ 与最佳实践
🚀一、引言
LLaMA 以开放可用、性能优良与生态繁荣著称,是企业与个人自建大模型的首选之一。相比闭源模型,LLaMA 在本地化部署、隐私合规、可控成本与二次开发方面具有显著优势,适合知识问答、代码助手、内容生成、多工具智能体等场景。

🚀二、发展历程与版本谱系
- LLaMA(v1):研究性质开源,点燃社区生态
- LLaMA 2:更强的指令遵循与对话能力,商用许可友好
- LLaMA 3 家族:更强推理与对齐能力,覆盖多尺寸(例如 8B、70B 等)
- 指令/聊天变体:LLaMA-2-Chat / LLaMA-3-Instruct 等
定位建议:
- 小尺寸(7B/8B):本地开发、边缘推理、单机实时场景
- 中尺寸(13B/34B):更强语义表达与稳健性
- 大尺寸(65B/70B):复杂推理与企业生产,需更强算力
🔎2.1 能力基线(示意)
- 小模型:响应快、成本低,适合Agent工具路由与摘要
- 中模型:通用任务性价比高
- 大模型:复杂推理/对话连贯性更强
🚀三、架构特点与训练要点
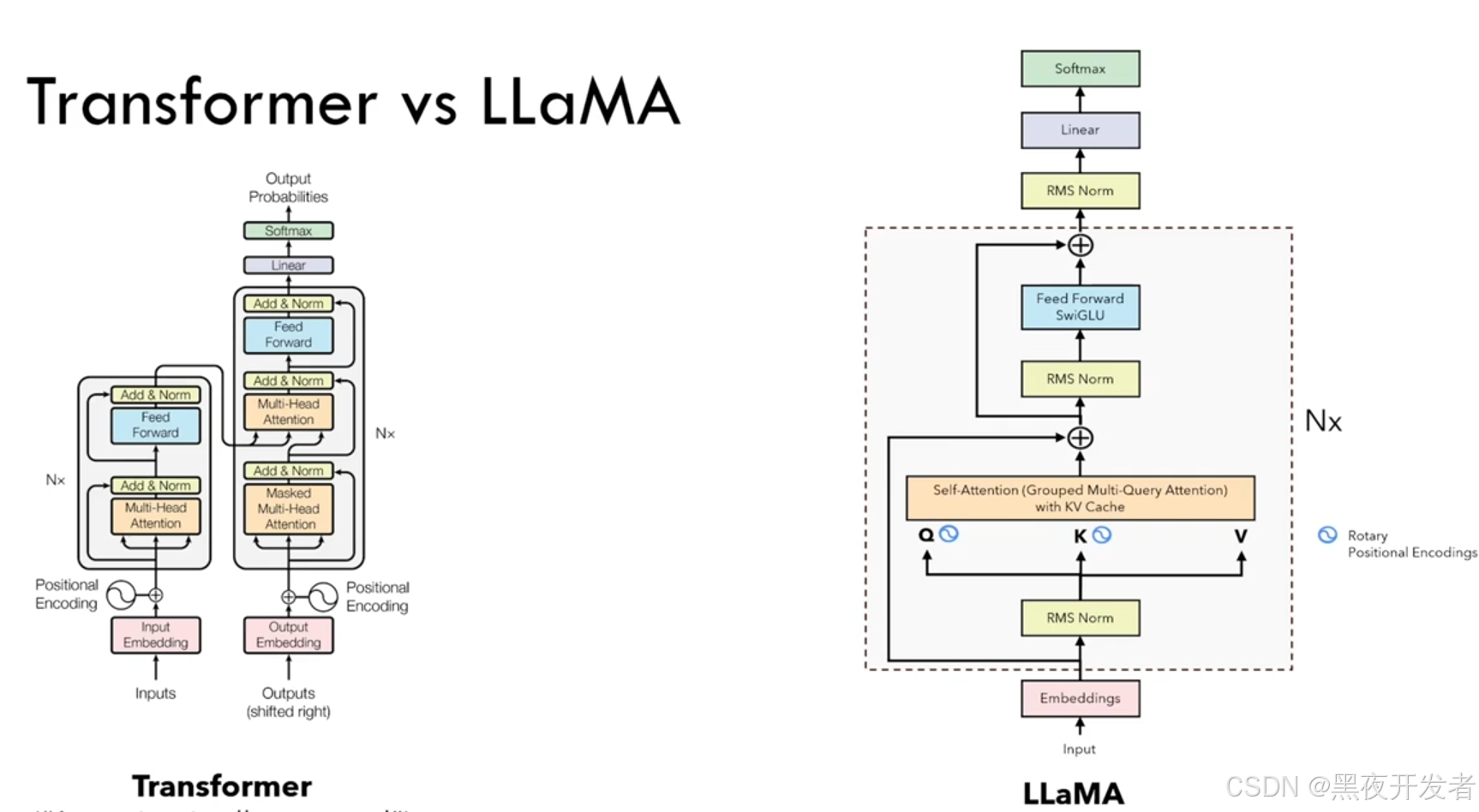
🔎3.1 模型架构
- 基于 Transformer 的解码器(Decoder-only)结构
- 多头自注意力、旋转位置编码(RoPE)等增强
- 训练时长与数据质量对性能影响显著
🔎3.2 训练与对齐
- 预训练:大规模多语料、去重清洗与质量控制
- 指令微调(SFT):高质量对话/任务数据
- 反馈对齐(RLHF/DPO):偏好建模,提升对齐与安全
🔎3.3 提示工程策略
- 明确角色与约束格式;要求分步/列点回答
- 长上下文分段引用与编号,便于对齐
- 输出 JSON 模板,便于解析与评测
🚀四、推理与部署路径
🔎4.1 Hugging Face Transformers 推理
from transformers import AutoModelForCausalLM, AutoTokenizer
import torchmodel_id = "meta-llama/Meta-Llama-3-8B-Instruct"
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(model_id,torch_dtype=torch.float16,device_map="auto"
)prompt = "写一段100字的品牌Slogan,风格简洁有记忆点"
inputs = tokenizer(prompt, return_tensors="pt").to(model.device)
outputs = model.generate(**inputs, max_new_tokens=128)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
🔎4.2 llama.cpp 本地量化推理
# 将权重转换为 gguf 并量化
./convert.py --model meta-llama/Meta-Llama-3-8B-Instruct --to gguf --q 4_k_m# 本地推理
./main -m ./llama3-8b-instruct-q4_k_m.gguf -p "用一句话介绍你的产品"
🔎4.3 Ollama 一键运行
ollama pull llama3:8b-instruct
ollama run llama3:8b-instruct
🔎4.4 批量与并发(Transformers 伪代码)
from torch.utils.data import DataLoaderprompts = ["总结: "+p for p in docs]
loader = DataLoader(prompts, batch_size=8)
for batch in loader:inputs = tokenizer(batch, return_tensors="pt", padding=True).to(model.device)outputs = model.generate(**inputs, max_new_tokens=128)texts = tokenizer.batch_decode(outputs, skip_special_tokens=True)
🚀五、轻量微调与适配(LoRA/QLoRA)
🔎5.1 LoRA 思路
- 冻结大部分权重,仅训练少量低秩适配参数,显著降低显存与算力需求
🔎5.2 QLoRA 实践示例(伪代码)
from peft import LoraConfig, get_peft_model
from transformers import AutoModelForCausalLMmodel = AutoModelForCausalLM.from_pretrained(model_id, load_in_4bit=True)
lora = LoraConfig(r=16, lora_alpha=32, lora_dropout=0.05, task_type="CAUSAL_LM")
model = get_peft_model(model, lora)
# 继续常规 Trainer 训练流程……
🔎5.3 数据与评测
- 领域高质量数据优先;数据清洗与指令多样性
- 小样本自动化评测基线(准确、流畅、事实一致、拒绝合理性)
🔎5.4 DPO/ORPO 简述
- 偏好优化替代RLHF的轻量做法,基于成对样本优化偏好一致性
🚀六、RAG 与企业知识场景
🔎6.1 标准流程
文档清洗与分块 → Embedding → 检索(向量/关键词)→ 重排 → 构造上下文 → 生成 → 引用与审计
🔎6.2 实践守则
- 控制上下文长度与噪声;要求逐段引用来源
- 对生成做模板化与结构化,降低幻觉与跑偏
🔎6.3 简易 RAG 代码(Transformers + FAISS 伪代码)
index = faiss.IndexFlatIP(emb_dim)
index.add(doc_embeddings)
D, I = index.search(query_emb, k=5)
context = "\n".join(docs[i] for i in I[0])
prompt = f"仅基于上下文回答,无法回答则说不知道。\n{context}\n问题: {q}"
inputs = tokenizer(prompt, return_tensors="pt").to(model.device)
outputs = model.generate(**inputs, max_new_tokens=200)
🚀七、安全、合规与治理
🔎7.1 模型侧
- 系统提示明确拒绝策略;毒性/越权测试集常态化
🔎7.2 平台侧
- 权限最小化、数据脱敏与加密、可审计留痕
- 金丝雀与回滚、SLO/SLA 与容量治理
🔎7.3 常见局限与避坑
- 领域外知识不足:优先RAG而非强行微调
- 幻觉与格式漂移:固定模板与正则/JSON 校验
- 资源瓶颈:量化/张量并行/批处理与缓存
🚀八、应用案例
- 开发者本地 Copilot、企业知识助手、AI 客服与表单自动化
- 多工具智能体:搜索→抽取→生成→校对→发布
🔎8.1 企业落地清单
- 架构图/接口契约/RACI 明确
- 压测报告与容量计划、SLO/SLA 定义
- 灰度/回滚与审计链路
🚀九、FAQ 与最佳实践
Q1:如何选择合适的 LLaMA 规模?
结合任务复杂度、延迟预算与部署资源,小模型优先满足实时性,大模型用于复杂推理。
Q2:微调还是 RAG?
优先 RAG,应对知识更新与可解释需求;若需风格/能力个性化,再考虑 LoRA/QLoRA。
Q3:如何降低成本?
量化(4bit/8bit)、批量推理、缓存与模板化输出、边缘/本地化部署。
Q4:与闭源模型如何协同?
将复杂推理与高风险问题路由到闭源模型;LLaMA 负责实时与低成本任务,网关统一编排与观测。
写在最后:LLaMA 系列兼具开放性与强性能,配合轻量微调与RAG,可在可控成本内实现高质量企业级应用落地。
以上问题欢迎大家评论区留言讨论,我们下期见。