可解释人工智能XAI
可解释人工智能(XAI)方法(例如常见的XGBoost-SHAP方法)可以捕捉到非线性的关系,但这种方法忽略了地理单元之间的空间效应;而传统的空间模型(例如常见的GWR)虽然考虑了空间效应,却仍然是基于线性的假设。因此,为了兼顾空间效应与非线性,一种可解释的地理人工智能(GeoXAI)方法,即顾及地理位置的机器学习回归(GeoMLR)与GeoShapley的联合框架,被用于探索这种复杂的关系之中。
一、Shapley类方法基本知识
想必大家对Shapley类方法(例如SHAP)有一定的兴趣。在地学/空间领域,基于SHAP的研究从2022年开始暴增。
*然而,绝大多数研究仍然把它作为一个普通的全局解释方法用于特征重要性排序和分析非线性的关系。其实,这些技术在SHAP之前就已经存在了。*
本Workshop将补充更多的Shapley相关的知识,并阐述这种局部解释方法在地学/空间研究上的潜力。
Shapley值(Shapley Value)是合作博弈论中的核心概念,由诺贝尔经济学奖得主Lloyd Shapley于1953年提出,用于解决多人合作博弈中公平分配联盟总收益的问题。其核心思想是根据每个参与者对联盟的边际贡献(Marginal Contribution)加权平均来确定分配方案,满足公平性、对称性和效率性等公理化性质。
一直以来,机器学习的可解释性都受到广泛关注。 现在的解释方法分为两类:全局解释和局部解释。特征重要性和偏依赖图是一种传统的全局解释方法,但它并不完全利于决策支持,因为特征的影响并非是处处同质的。Shapley值的引入使得特征在*局部样本个体和全局上的影响*都可以被量化,从而可以提供更深层次的见解。
这种局部解释方法与地学/空间研究更加契合。
本项目来源于和鲸社区,使用转载需要标注来源
作者: 和鲸社区
来源: 和鲸社区
0.机器学习中的Shapley值
在机器学习中,预测值 ![]() 可以被以下公式描述:
可以被以下公式描述:

众所周知,Shapley值还包含了交互值,Shapley交互值又是什么呢?

特征m全局的影响就是所有样本个体上Shapley值的平均值。
1.不同机器模型的Shapley值的计算方法
也许你已经发现,用Python中的SHAP库解释XGBoost、随机森林很快,但是解释SVM却很慢,这是为什么呢?
事实上,Shapley类方法分了很多种,这些不同的解释器都被集成进了SHAP库中。你在调用SHAP库解释模型时,它使用的是不同解释器。
Kernel SHAP (解释一切模型)
Kernel SHAP方法由Lundberg和Lee(2017)引入进机器学习的解释,它本质上是一种模型无关的解释方法,也就是说,它可以解释任何模型。但是,它的时间复杂度极大,运行时间非常缓慢,这与特征数量有关。
前面提及的解释SVM非常慢,就是因为SVM是用Kernel SHAP进行解释的。
Lundberg S, Lee S. A unified approach to interpreting model predictions[J]. arXiv preprint arXiv:1705.07874, 2017.
Tree SHAP (解释基于树的模型)
基于树的模型(如随机森林、XGBoost)具有的特殊结构,因此,Lundberg(2020)等提出Tree SHAP,用于近似估测基于树的模型中特征的Shapley值。
与Kernel SHAP相比,Tree SHAP是一种模型有关的解释方法,它只能用于基于树的模型。但Tree SHAP的时间复杂度被大大优化,因此“基于树的模型 + Tree SHAP”的联合方法得到了广泛的应用。
Lundberg S, Erion G, Chen H, et al. From local explanations to global understanding with explainable AI for trees[J]. Nature machine intelligence, 2020, 2(1): 56-67.
此外,SHAP库中还针对其他不同的模型结构集成了DeepExplainer、GradientExplainer等解释器
2.局部解释方法在地学/空间研究的潜力
尽管目前许多地学/空间研究应用了机器学习+Shapley类的方法,但这些研究仍然停留在特征全局重要性和非线性偏依赖图的全局解释阶段。事实上,这种结果不依赖Shapley值和博弈论也可以实现,这些方法在Python的SHAP库出现之前就存在。
Shapley类方法的重点在于它的局部解释能力,偏偏这样的能力能很好的与地学/空间研究结合起来。
Shapley类方法可以解释某个个体样本中,该个体的特征是如何对该个体的预测值产生影响的。在地学/空间研究中,“个体”就是一个个“地理单元”,因此,每一个地理单元中的每一个特征发挥的作用,都可以被绘制于地图之上,发现特征影响的空间异质性,从而为决策支持提供因地制宜的见解。 再结合非线性的偏依赖图,就可以发现特征“非线性”且“空间非平稳性”的影响,从而提供“定量化”且“因地制宜”的决策支持。
这种局部解释的能力使Shapley类方法在地学/空间的分析研究中产生更有意义的研究结果。
目前,已经有少部分研究已在行业顶刊上应用了这种Shapley类方法的局部解释能力:
Ke E, Zhao J, Zhao Y. Investigating the influence of nonlinear spatial heterogeneity in urban flooding factors using geographic explainable artificial intelligence[J]. Journal of Hydrology, 2025, 648: 132398.
Luo P, Chen C, Gao S, et al. Understanding of the predictability and uncertainty in population distributions empowered by visual analytics[J]. International Journal of Geographical Information Science, 2024: 1-31.
An R, Tong Z, Tan B, et al. Revealing the relationship between 2D/3D built environment and jobs-housing separation coupling nonlinearity and spatial nonstationarity[J]. Journal of Transport Geography, 2025, 123: 104112.
3.GeoShapley方法
顾及地理空间的机器学习回归(GeoMLR)+ GeoShapley更适用于专门的空间研究。前文提到,机器学习中的“个体”就是一个个“地理单元”,在生物或是医学的研究中,样本个体通常是独立的,然而在空间研究中,地理单元间却是存在空间关系的。
Li(2022)使用GeoMLR(在传统特征中加入了表征空间的坐标X和Y)探索了机器学习捕捉空间关系的能力,随后他于2024年提出了GeoShapley方法。GeoShapley方法源自Joint Shapley方法,它可以发现两种特征的联合贡献。因此,GeoShapley方法用其量化特征X和Y的联合贡献,用于表征空间位置特征的影响。
GeoShapley方法可以量化空间位置的影响,并量化出自变量中的空间效应,这也是传统的地理加权机器学习(GWML)+SHAP所做不到的。
另外,GeoMLR可以作为一种新方法被纳入空间建模,它克服了传统空间模型线性的假设 实现了非线性的建模,也超越了传统的机器学习建模 顾及了地理空间在其中发挥的作用。GeoShapley的解释也提升了其实用性。
因此,在空间自相关性较高的地学/空间研究中,可以尝试使用GeoMLR+GeoShapley方法进行分析,它可以比传统的ML+Shapley方法提供更多在空间上的见解。
诚然,GeoShapley方法也存在缺陷。GeoShapley方法是一种模型无关的方法,它是基于Kernel SHAP开发的,因此它的时间复杂度极高,运行时间非常久。
Li Z. Extracting spatial effects from machine learning model using local interpretation method: An example of SHAP and XGBoost[J]. Computers, Environment and Urban Systems, 2022, 96: 101845.
Li Z. GeoShapley: A Game Theory Approach to Measuring Spatial Effects in Machine Learning Models[J]. Annals of the American Association of Geographers, 2024: 1-21.
二、Workshop实验框架与数据
本次Workshop的内容分为三部分(计算UFS-用因素拟合UFS-解释拟合结果):
基于机器学习分类器计算城市内涝易发性(UFS)。使用内涝相关的变量道路密度(RD)、人口数量(POP)、兴趣点(POI)、不透水面密度(ISD)与内涝点训练XGBoost分类器,从而预测所有地理单元内涝发生的概率(即城市内涝易发性UFS)。
使用内涝因素和GeoMLR拟合UFS。使用内涝因素高程(DEM)、ISD、RD、到达水体距离(Dis2water)、地理坐标特征X、Y,和分类器输出的UFS,基于XGBoost进行回归。
使用GeoShapley解释分析。使用Shapley值解释内涝因素、地理空间变量的影响,绘制内涝因素全局影响图、内涝因素空间异质的影响图、非线性依赖图、内涝因素的空间交互图、栅格尺度上内涝的主导因素图。
广州市主城区的渔网数据,Shp格式。网格为500*500m。数据包含了['Shape_Leng', 'Shape_Area', 'DEM', 'Dis2water', 'ISD', 'POI', 'RD', 'POP', 'X', 'Y']字段。数据时间为2020年,数据全部提取自公开的数据。其中,'Shape_Leng'代表网格的周长;'Shape_Area'代表网格的面积;'X'和'Y'分别代表WGS 1984 UTM Zone 49N下每个网格的横纵坐标。
内涝数据集,csv格式。里面包含75个正样本和75个负样本。数据集包含['ID','Flood','POI','POP','RD','ISD']字段。数据时间为2020年,数据全部提取自公开的数据。其中,'ID'代表样本ID;'Flood'代表是否发生过内涝,1为是,0为否。
为什么不在训练分类器的时候就把坐标X和Y作为特征输入进去呢?
把X和Y作为特征输入进去,那么训练得到的模型泛化能力岂不是很弱?
内涝相关变量和内涝因素有什么区别?
这个UFS到底是什么?为什么用了两个机器学习模型?
在计算UFS的机器学习分类器和回归分析的GeoMLR中,都使用了不透水面密度(ISD)和道路密度(RD)这两个变量,这没有问题吗?
为什么Workshop中的内涝因素那么少?
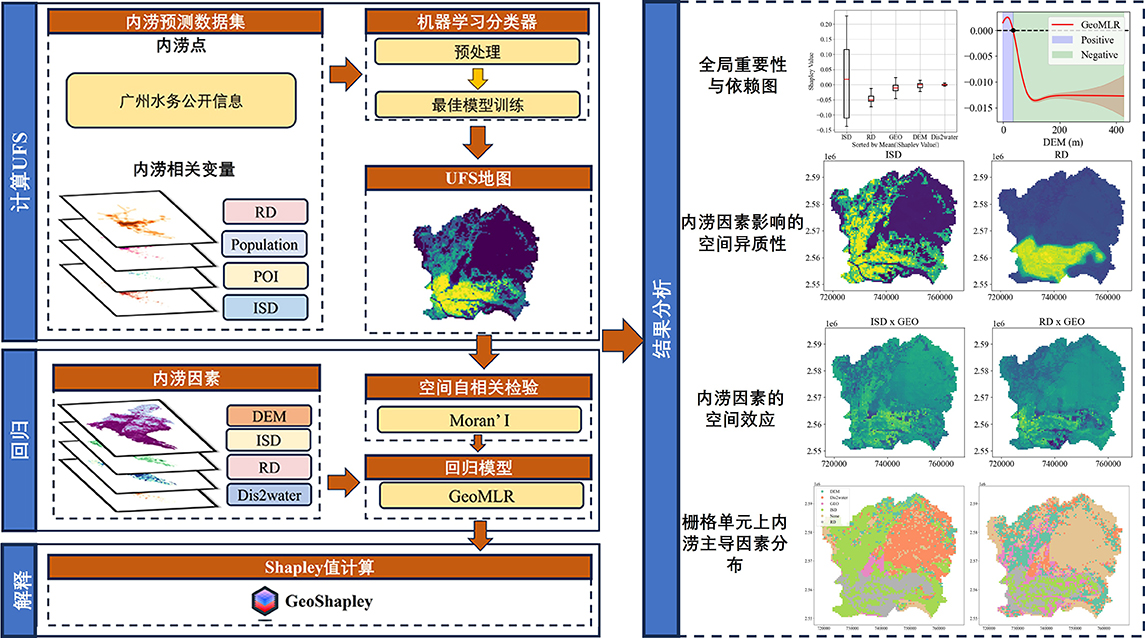
其中,GEO代表着地理位置特征X和Y共同做出的影响,即空间位置对UFS的影响。
内涝因素xGEO则代表了内涝因素的空间效应
geomlr_rslt.partial_dependence_plots(figsize=(10,6),max_cols=2,gam_curve=True)
解释分为全局解释和局部解释两种。
接下来,我们首先从全局的视角对解释结果进行分析
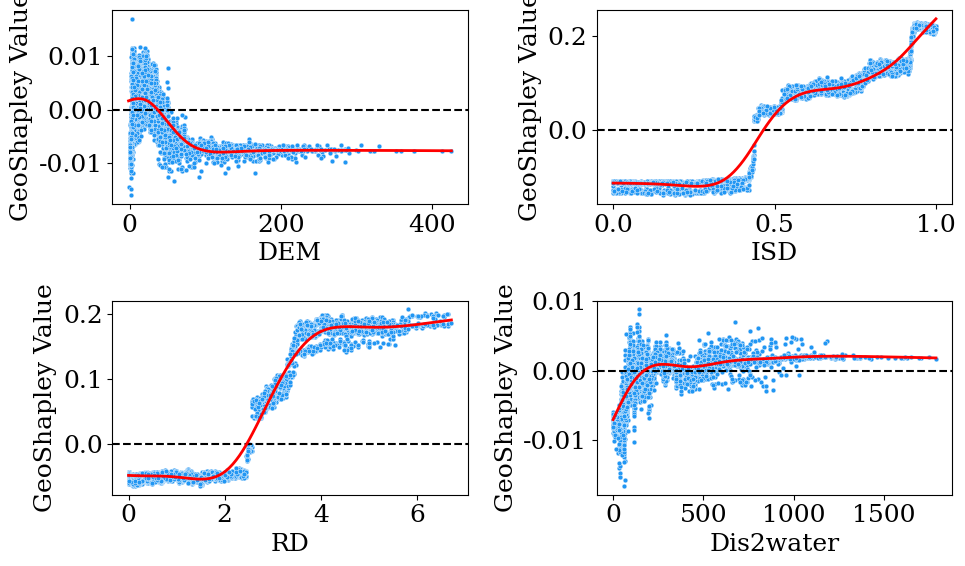
3.全局重要性
绘制全局重要性的箱线图。
某一特征的 所有shapley值的绝对值的平均值(Mean(|Shapley Value|)) 就是该特征的全局重要性。
在横轴上,从左到右排列全局重要性从高到低的特征。
箱线图则展现了Shapley值的数据分布。也可以看出对UFS影响最大的因素是ISD和RD。
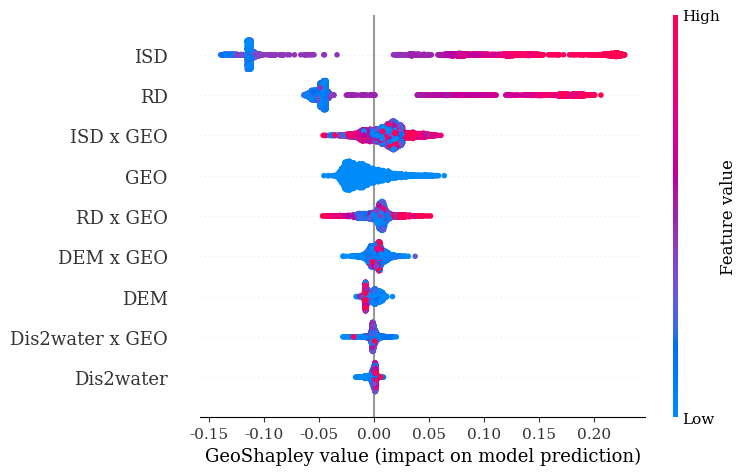
4.非线性偏依赖图
这一步的目的是绘制偏依赖图,发现内涝因素与UFS之间的非线性关系。
本质上,偏依赖图也还是是一种全局解释方法。
fig, axes = plt.subplots(2, 2, figsize=(10, 8), dpi=100)
plt.subplots_adjust(wspace=0.4, hspace=0.3) # 调整子图间隙units_list = [' (m)', '', ' (m/m²)', ' (m)']for i, name in enumerate(['DEM', 'ISD', 'RD', 'Dis2water']):row = i // 2col = i % 2# 基础设置axes[row, col].set_xlabel(name + units_list[i])axes[row, col].set_ylabel(f'Shapley value for {name}')axes[row, col].axhline(y=0, color='black', linestyle='--', linewidth=2)# 拟合GAM模型lam = np.logspace(2, 7, 5).reshape(-1, 1)gam = pygam.LinearGAM(pygam.s(0), fit_intercept=False).gridsearch(var.loc[:, name].values.reshape(-1, 1), shapley.loc[:, name].values.reshape(-1, 1), lam=lam)# 绘制偏依赖图for term in gam.terms:XX = gam.generate_X_grid(term=0)pdep, confi = gam.partial_dependence(term=0, X=XX, width=0.95) #95%的置信区间# 绘制曲线和置信区间axes[row, col].plot(XX, pdep, color="red", lw=2)axes[row, col].fill_between(XX[:, 0], confi[:, 0], confi[:, 1], color="red", alpha=0.2)# 找交点逻辑# 1. 找到与y=0的交点sign_changes = np.where(np.diff(np.sign(pdep).flatten()))[0]x0_list = []# 遍历所有符号变化点for idx in sign_changes:# 跳过区间端点if idx == 0 or idx == len(XX)-1:continue# 线性插值求精确交点x1, x2 = XX[idx][0], XX[idx+1][0]y1, y2 = pdep[idx], pdep[idx+1]x0 = x1 - y1*(x2-x1)/(y2-y1)x0_list.append(x0)# 判断填充颜色if y1 > 0: # 左侧高于0left_color = "blue"right_color = "green"else: # 左侧低于0left_color = "green"right_color = "blue"xmin, xmax = XX[:,0].min(), XX[:,0].max()axes[row, col].axvspan(xmin, x0, alpha=0.2, color=left_color)axes[row, col].axvspan(x0, xmax, alpha=0.2, color=right_color)axes[row, col].scatter(x0, 0, s=50, color='black', zorder=5)# 图例设置(只在第一个子图添加)if i == 0:legend_elements = [Line2D([0], [0], color='red', lw=2, label='GeoMLR'),Patch(facecolor='blue', alpha=0.2, label='Positive'),Patch(facecolor='green', alpha=0.2, label='Negative'),]axes[row, col].legend(handles=legend_elements, loc='upper right')plt.show()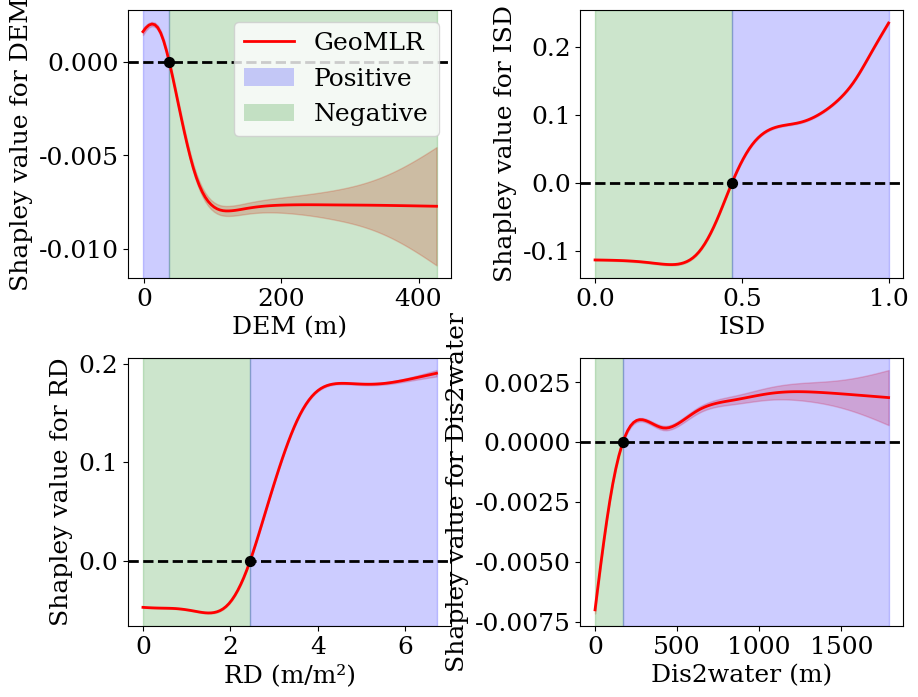
从依赖图中可以看出,将ISD控制在0.5以下,将RD控制在2.5m/m²以下有助于控制广州主城区的UFS。
关于Shapley类方法
Shapley类方法的局部解释能力,有助于理解自变量x对因变量y的影响,尤其是理解影响的空间异质性;
GeoMLR+GeoShapley不仅仍然有这种局部解释能力,它还考虑了空间的贡献,并且能揭示出空间效应。这是现今的地理加权机器学习(GWML)+SHAP方法做不到的。它更适用于空间建模,更适用于研究空间效应;
GeoShapley也存在缺陷,它是基于Kernel SHAP开发的,它的时间复杂度高,运行时间久。