whisper-large-v3 模型
模型介绍
Whisper 是由 OpenAI 的 Alec Radford 等人提出的顶尖自动语音识别(ASR)与语音翻译模型,相关成果发表于论文《Robust Speech Recognition via Large-Scale Weak Supervision》。作为依托大规模弱监督训练的代表性模型,Whisper 凭借超过 500 万小时标注数据的训练基础,在零样本场景下展现出极强的泛化能力,能够适配多种数据集与应用领域,为语音处理任务提供高效解决方案。
在 Whisper 系列模型中,large-v3 版本是重要升级迭代产物,其核心架构与此前的 large、large-v2 版本保持一致,仅在细节上进行优化调整,具体包括两点:一是将 spectrogram(频谱图)输入的 Mel 频率 bin 数量从 80 提升至 128,优化对音频频率特征的捕捉;二是新增粤语语言令牌,进一步扩展对特定语言的支持能力。
训练数据与流程上,Whisper large-v3 采用混合数据集训练,包含 100 万小时弱标注音频,以及 400 万小时通过 Whisper large-v2 生成伪标签的音频,整体训练覆盖 2.0 个epoch。凭借更优质的训练数据与优化设计,large-v3 版本在多语言场景下性能显著提升,相较于 Whisper large-v2,其错误率降低 10% - 20%,成为当前语音识别与翻译领域的主流选择之一。
模型加载
import torch
from modelscope import AutoModelForSpeechSeq2Seq, AutoProcessor, pipeline
from datasets import load_datasetdevice = "cuda:0" if torch.cuda.is_available() else "cpu"
torch_dtype = torch.float16 if torch.cuda.is_available() else torch.float32model_id = "openai-mirror/whisper-large-v3"model = AutoModelForSpeechSeq2Seq.from_pretrained(model_id, torch_dtype=torch_dtype, low_cpu_mem_usage=True, use_safetensors=True
)
model.to(device)
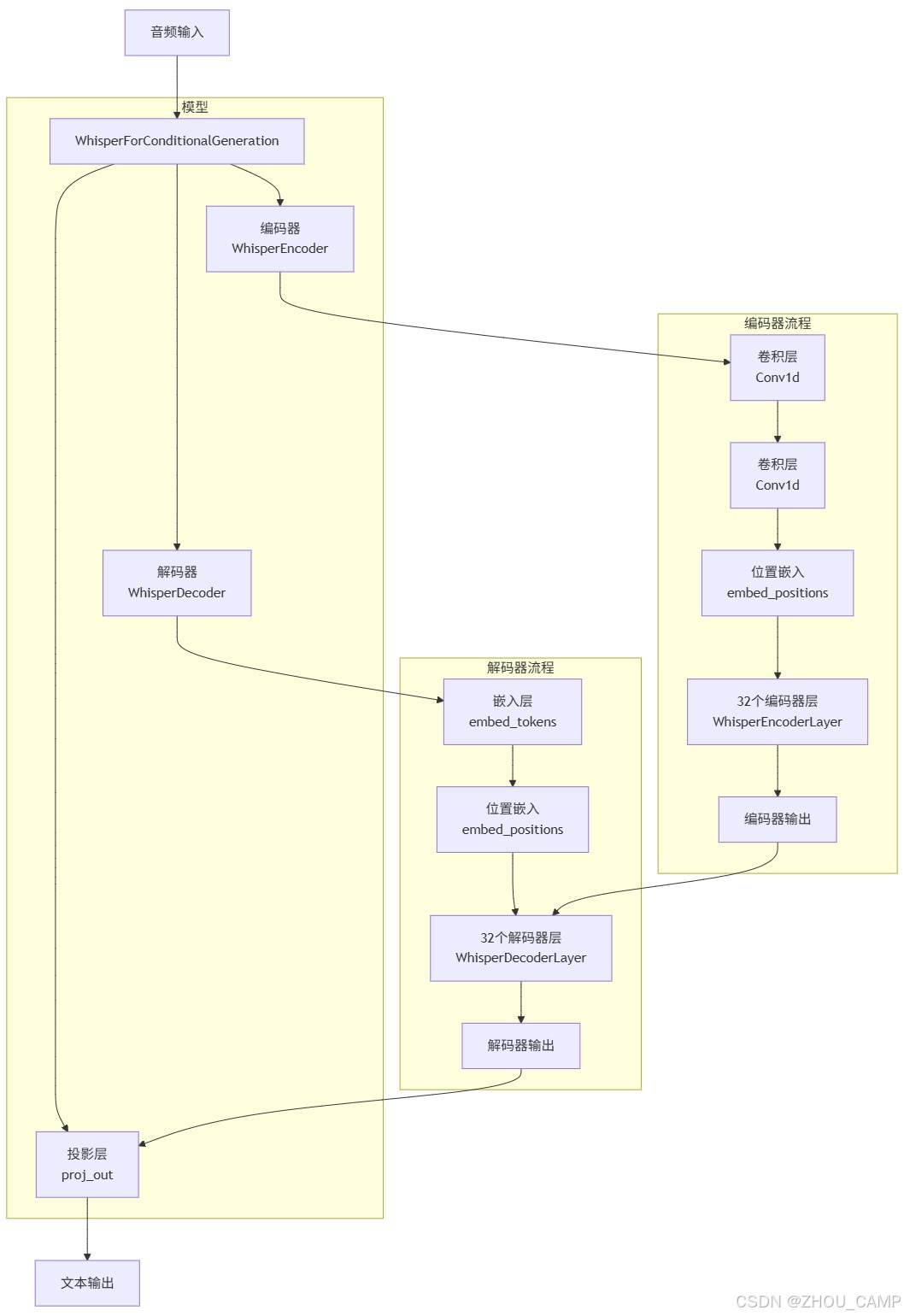
模型结构
Downloading Model from https://www.modelscope.cn to directory: /home/six/.cache/modelscope/hub/models/openai-mirror/whisper-large-v3
WhisperForConditionalGeneration((model): WhisperModel((encoder): WhisperEncoder((conv1): Conv1d(128, 1280, kernel_size=(3,), stride=(1,), padding=(1,))(conv2): Conv1d(1280, 1280, kernel_size=(3,), stride=(2,), padding=(1,))(embed_positions): Embedding(1500, 1280)(layers): ModuleList((0-31): 32 x WhisperEncoderLayer((self_attn): WhisperAttention((k_proj): Linear(in_features=1280, out_features=1280, bias=False)(v_proj): Linear(in_features=1280, out_features=1280, bias=True)(q_proj): Linear(in_features=1280, out_features=1280, bias=True)(out_proj): Linear(in_features=1280, out_features=1280, bias=True))(self_attn_layer_norm): LayerNorm((1280,), eps=1e-05, elementwise_affine=True)(activation_fn): GELUActivation()(fc1): Linear(in_features=1280, out_features=5120, bias=True)(fc2): Linear(in_features=5120, out_features=1280, bias=True)(final_layer_norm): LayerNorm((1280,), eps=1e-05, elementwise_affine=True)))(layer_norm): LayerNorm((1280,), eps=1e-05, elementwise_affine=True))(decoder): WhisperDecoder((embed_tokens): Embedding(51866, 1280, padding_idx=50256)(embed_positions): WhisperPositionalEmbedding(448, 1280)(layers): ModuleList((0-31): 32 x WhisperDecoderLayer((self_attn): WhisperAttention((k_proj): Linear(in_features=1280, out_features=1280, bias=False)(v_proj): Linear(in_features=1280, out_features=1280, bias=True)(q_proj): Linear(in_features=1280, out_features=1280, bias=True)(out_proj): Linear(in_features=1280, out_features=1280, bias=True))(activation_fn): GELUActivation()(self_attn_layer_norm): LayerNorm((1280,), eps=1e-05, elementwise_affine=True)(encoder_attn): WhisperAttention((k_proj): Linear(in_features=1280, out_features=1280, bias=False)(v_proj): Linear(in_features=1280, out_features=1280, bias=True)(q_proj): Linear(in_features=1280, out_features=1280, bias=True)(out_proj): Linear(in_features=1280, out_features=1280, bias=True))(encoder_attn_layer_norm): LayerNorm((1280,), eps=1e-05, elementwise_affine=True)(fc1): Linear(in_features=1280, out_features=5120, bias=True)(fc2): Linear(in_features=5120, out_features=1280, bias=True)(final_layer_norm): LayerNorm((1280,), eps=1e-05, elementwise_affine=True)))(layer_norm): LayerNorm((1280,), eps=1e-05, elementwise_affine=True)))(proj_out): Linear(in_features=1280, out_features=51866, bias=False)
)