Llama-index学习文档
Llama-index学习文档
- 一、环境准备
- 二、llamaindex构建RAG的示例代码
- 三、Data connectors
- 四、Data Indexes
- 4.1、Chunking
- 4.2、Indexing
- 五、Query Engines
- 六、Data agents
- 6.1、代码解释
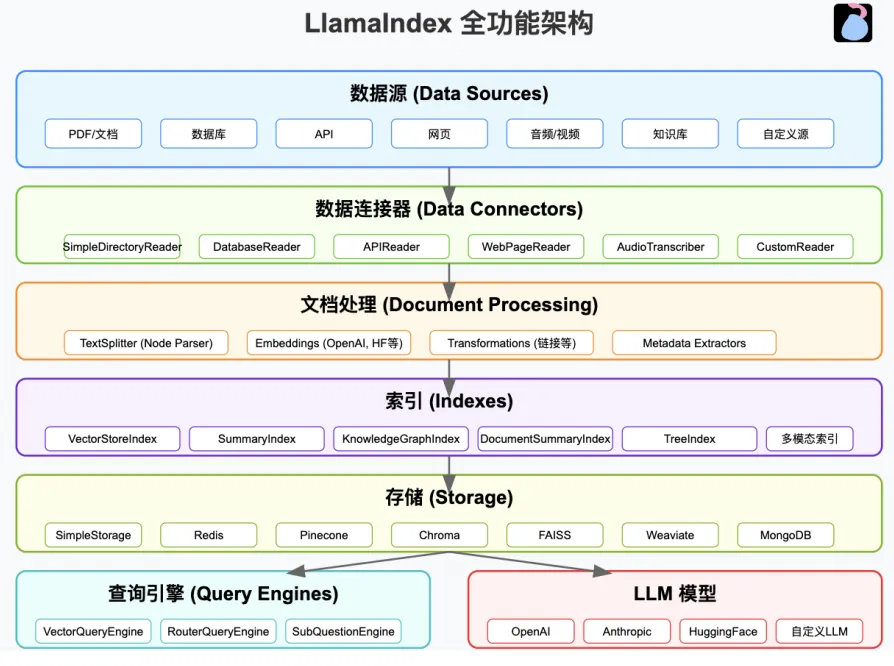
LlamaIndex 是一个用于 LLM 应用程序的数据框架,用于注入,结构化,并访问私有或特定领域数据。
llamaindex是目前最适合做RAG的框架。在本质上,LLM(如GPT)为人类和推断出的数据提供了基于自然语言的交互接口。广泛可用的大模型通常在大量公开可用的数据上进行的预训练,包括来自维基百科、邮件列表、书籍和源代码等。
构建在LLM模型之上的应用程序通常需要使用私有或特定领域数据来增强这些模型。不幸的是,这些数据可能分布在不同的应用程序和数据存储中。它们可能存在于API之后、SQL数据库中,或者存在在PDF文件以及幻灯片中。
LlamaIndex应运而生。
主要包含以下模块:
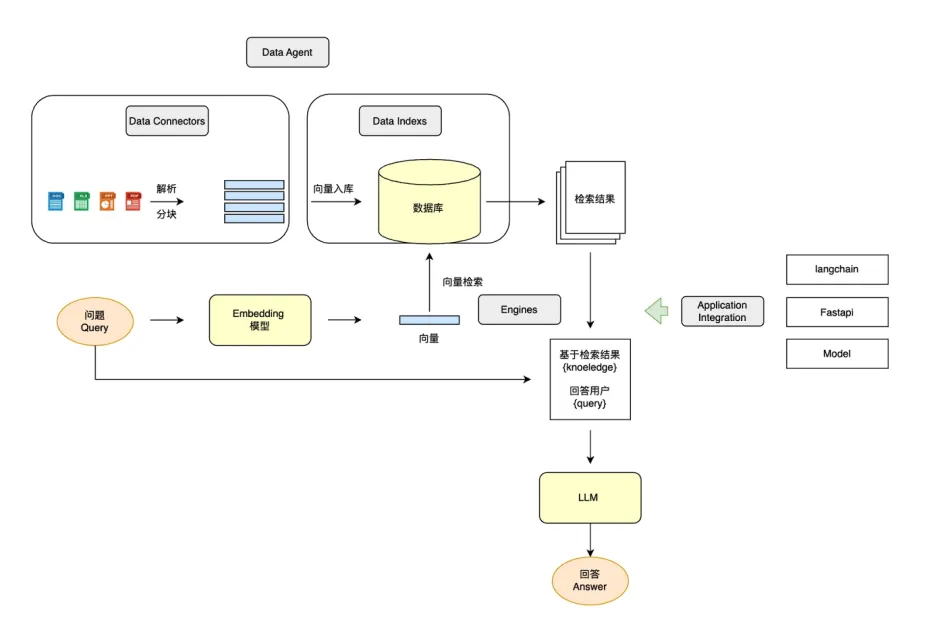
● Data connectors(数据连接器):用于从各种数据源(如数据库、API、文件系统等)提取和加载数据,以便进行索引和查询。
● Data indexes(数据索引):负责对文档分chunk,向量化表示,为每个chunk提取元信息(关键词)等,存储已提取的数据并建立索引,以支持高效的信息检索和查询优化。
● Query Engines(引擎):执行查询处理、语义搜索、RAG(检索增强生成)等任务,确保数据的高效利用和交互。
● Data agents(数据代理):智能化的数据处理组件,可自动执行任务,如数据转换、合并、增强或基于上下文进行推理。
● Application integrations(应用集成):提供与外部应用(如LLMs、BI工具、SaaS平台等)的接口,确保数据与现有系统无缝交互。
一、环境准备
pip install llama-index-core \llama-index-llms-openai \llama-index-readers-file \llama-index-readers-webpip install unstructured[pdf,docx,pptx] \paddleocr \pillow pip install trafilatura \cohere \pypdf \python-pptxpip install sentence-transformers \rank_bm25
pip install llama-index-embeddings-openai
pip install llama-index-vector-stores-faiss
pip install llama-index
pip install faiss-cpu
pip install fitz
pip install frontend
二、llamaindex构建RAG的示例代码
import os
os.environ['OPENAI_API_KEY'] = ''
# llamaindex 内嵌的默认模型是gpt-3.5
from llama_index.core import VectorStoreIndex, SimpleDirectoryReader
#文档解析
documents = SimpleDirectoryReader('data').load_data()
#构建索引
index = VectorStoreIndex.from_documents(documents)
#构建引擎
query_engine = index.as_query_engine()
#得到结果
response = query_engine.query("收盘价多少")
三、Data connectors
# 本地文件加载器(扩展支持)
local_loader = SimpleDirectoryReader(input_dir="./data",required_exts=[".pdf", ".docx", ".pptx", ".epub", ".md"],file_extractor={".pdf": PyMuPDFReader(), # 带文本坐标信息}
)
你这段代码是基于 llama_index(或类似文档加载库)的本地文件加载器配置,功能是从 ./data 文件夹中批量读取文档,并按文件后缀决定如何解析。
● SimpleDirectoryReader
一个目录读取器,会扫描input_dir中的所有文件,并根据扩展名来选择合适的解析器。
● input_dir=“./data”
指定要读取的目录路径。
● required_exts=[“.pdf”, “.docx”, “.pptx”, “.epub”, “.md”]
限定只读取这些扩展名的文件,其他文件会被忽略。
● recursive=True
递归遍历子目录
● file_extractor={…}
指定不同文件类型的解析器。例如:.pdf用PyMuPDFReader()解析,能够获取文本及其在页面上的位置信息(坐标)。
多种解析器组合
from llama_index.readers.file import (PyMuPDFReader,DocxReader,PptxReader,EpubReader,MarkdownReader,
)local_loader = SimpleDirectoryReader(input_dir="./data",required_exts=[".pdf", ".docx", ".pptx", ".epub", ".md"],file_extractor={".pdf": PyMuPDFReader(),".docx": DocxReader(),".pptx": PptxReader(),".epub": EpubReader(),".md": MarkdownReader(),}
)
自定义解析器
你可以自己写一个继承 BaseReader 的类,例如 YAML/CSV 解析,然后加入:
from llama_index.readers.base import BaseReaderclass MyYAMLReader(BaseReader):def load_data(self, file):import yamlwith open(file, "r") as f:content = yaml.safe_load(f)return [{"text": str(content)}]local_loader = SimpleDirectoryReader(input_dir="./data",required_exts=[".yaml"],file_extractor={".yaml": MyYAMLReader()}
)
完整代码示例
from llama_index.core import SimpleDirectoryReader
from llama_index.readers.file import PyMuPDFReader
from llama_index.readers.web import BeautifulSoupWebReader# 本地文件加载器(扩展支持)
local_loader = SimpleDirectoryReader(input_dir="./data",required_exts=[".pdf", ".docx", ".pptx", ".epub", ".md"],file_extractor={".pdf": PyMuPDFReader(), # 带文本坐标信息}
)# 网页加载器
web_loader = BeautifulSoupWebReader()# 示例混合加载
local_docs = local_loader.load_data()
web_docs = web_loader.load_data(urls=["https://cloud.tencent.com/developer/article/2499999?fromSource=gwzcw.9358214.9358214.9358214&utm_medium=cpc&utm_id=gwzcw.9358214.9358214.9358214" ])
documents = local_docs + web_docs
除了PyMuPDFReader,DocxReader,PptxReader,EpubReader,MarkdownReader还可以使用 Llama Cloud 提供的文档解析接口 LlamaParse
● api_key:你在 Llama Cloud 上申请的 API key,用于认证。
● result_type=“markdown”:输出结果类型为 Markdown 格式。支持的可能有 “markdown”, “txt”, “json” 等。
● num_workers=3:允许并行解析多个文档,提高效率。
● verbose=True:打印详细日志,方便调试。
● language=“ch_sim”:指定语言为简体中文,解析器会针对中文进行优化。
# 异步解析
import nest_asyncio
nest_asyncio.apply()
from llama_cloud_services import LlamaParse
parser = LlamaParse(api_key="your LLAMA_CLOUD_API_KEY", result_type="markdown", num_workers=3, # 多文档并行解析verbose=True,language="ch_sim",
)file_extractor = {".pdf": parser}
documents_cloud = SimpleDirectoryReader("./data", file_extractor=file_extractor
).load_data()
四、Data Indexes
4.1、Chunking
下面给出了llamaindex实现的chunking代码。
你这段代码使用了 LlamaIndex 的 SentenceSplitter 来对长文本进行切分,以便后续存入索引或向量数据库中。它的主要目标是:将原始文档拆分成合适大小的“节点”(Node),保证模型在上下文窗口限制内能高效检索。
● chunk_size=1024
○ 表示每个切分后的文本块最大长度(以字符为单位,除非提供 tokenizer)。
○ 设置为 1024 字符,可以保证每个块不会过长。
● chunk_overlap=100
○ 设置切分时相邻块之间的重叠部分。
○ 例如块 A 的结尾 100 字符会同时出现在块 B 的开头。
○ 作用是减少上下文割裂,提高语义连续性。
● paragraph_separator=“\n\n”
○ 指定切分时的“自然段”边界。
○ 在你的例子里,一个段落之间用两个换行符 \n\n 分隔。
○ 如果文档里有表格(例如 Markdown/HTML 表格),这样设置能避免表格被切断。
● secondary_chunking_regex=<table>(.+?)</table>
○ 二级切分规则,优先识别 <table>...</table> 的区域。
○ 表示:如果文本中出现表格(HTML 格式),则整个 <table>标签包裹的内容会作为一个整体节点,不会被切碎。
○ 这对结构化信息(如表格)非常重要。
● tokenizer=None
○ 如果提供了自定义 tokenizer,则 chunk_size 和 chunk_overlap 会以 token 数量 而非字符数计算。
○ 这里是 None,所以按字符长度切分。
get_nodes_from_documents(documents)
● 输入:一个或多个 Document 对象(通常是 LlamaIndex 的 Document,包含 text 和 metadata)。
● 输出:切分后的 Node 列表。
● 每个 Node 是一个文本块,带有:
a. text:切分后的文本片段
b. metadata:来源信息(例如文档 ID、段落位置)
c. 可用于检索和问答的 embedding
from llama_index.core.node_parser import SentenceSplitter# 设置 overlap 参数(例如 100 个字符的重叠)
splitter = SentenceSplitter(chunk_size=1024,chunk_overlap=100,paragraph_separator="\n\n", # 确保段落分隔符不会切分表格secondary_chunking_regex="<table>(.+?)</table>", # 识别表格标签(如果使用HTML格式)tokenizer=None # 可选,使用自定义分词器
)nodes = splitter.get_nodes_from_documents(documents)
4.2、Indexing
llamaindex内置的数据库检索效率比较低,使用向量数据库能提供更精确的检索结果。下面给出了使用Faiss向量数据库的例子
from llama_index.core import Settings
from llama_index.llms.openai import OpenAI
from llama_index.embeddings.openai import OpenAIEmbedding
# 修改大模型和embedding模型设置
Settings.llm = OpenAI(model="gpt-4o")
Settings.embed_model = OpenAIEmbedding(model="text-embedding-3-small")import faiss
from llama_index.core import StorageContext, VectorStoreIndex
from llama_index.core.retrievers import VectorIndexRetriever
from llama_index.retrievers.bm25 import BM25Retriever
from llama_index.core.query_engine import RetrieverQueryEngine
from llama_index.vector_stores.faiss import FaissVectorStore# 假设nodes是你已经准备好的节点列表# 1. 创建FAISS索引
d = 1536 # 对应于text-embedding-3-small的维度
faiss_index = faiss.IndexFlatL2(d)
vector_store = FaissVectorStore(faiss_index=faiss_index)# 2. 创建存储上下文
storage_context = StorageContext.from_defaults(vector_store=vector_store)# 3. 使用FAISS向量存储创建向量索引
vector_index = VectorStoreIndex(nodes,storage_context=storage_context
)# 4. 创建向量检索器
vector_retriever = VectorIndexRetriever(index=vector_index,similarity_top_k=5 # 设置为你想要的召回数量
)# 5. 创建查询引擎
query_engine = RetrieverQueryEngine.from_args(retriever=vector_retriever
)# 6. 执行查询
response = query_engine.query("同仁堂安宫牛黄丸的市场价格,中文回答")
如果检索效果不好,还可以查看检索到的内容做debug
#查看检索的结果
retrieved_nodes = vector_retriever.retrieve("同仁堂安宫牛黄丸的市场价格,中文回答")# 7. 查看检索到的节点
print(f"共检索到 {len(retrieved_nodes)} 个节点")
for i, node in enumerate(retrieved_nodes):print(f"\n节点 {i+1}:")print(f"相似度得分: {node.score}")print(f"内容: {node.node.text}")print("-" * 50)
五、Query Engines
主要功能是处理用户查询,并通过索引和检索机制返回最佳匹配结果
● Query Routing:将query引导到最相关的知识库检索
● Query Rewriting:对query进行多角度重写,去除问题中可能的违法信息
● Query Planning:拆分复杂的问题,规划处解决问题的思路,逐步进行检索
下面代码实现了自定义回答的格式,并实现了带有记忆的聊天
from llama_index.core.memory import ChatMemoryBuffermemory = ChatMemoryBuffer.from_defaults(token_limit=5000)chat_engine = index.as_chat_engine(chat_mode="context",memory=memory,system_prompt=("你是一个聊天机器人"" 要基于检索回来的信息回答问题,如果没有检索回来信息,根据你自身的能力回答,不要不回答问题"),
)response = chat_engine.chat("詹姆斯是谁")
response1 = chat_engine.chat("世运电路2023年上半年实现营业收入多少")
print(response)
print('-'*130)
print(response1)
response1 = chat_engine.chat("你可以告诉我更多吗")
print(response1)
六、Data agents
结合大模型(LLM)和工具(工具链、API)来执行复杂任务,如自动化推理、代码执行、任务分解等。下面的代码实现了全局总结工具和具体问题回复的工具。
这段代码主要是把 向量检索(vector search) 和 摘要索引(summary index) 封装成工具(Tool),方便在 LLM Agent 或多工具系统中调用
import nest_asyncio
nest_asyncio.apply()
from typing import List
from llama_index.core.vector_stores import FilterCondition
from llama_index.core.tools import FunctionTool
from llama_index.core.vector_stores import MetadataFiltersdef vector_query(query: str, page_numbers: List[str]
) -> str:"""Perform a vector search over an index.query (str): the string query to be embedded.page_numbers (List[str]): Filter by set of pages. Leave BLANK if we want to perform a vector searchover all pages. Otherwise, filter by the set of specified pages."""metadata_dicts = [{"key": "page_label", "value": p} for p in page_numbers]query_engine = vector_index.as_query_engine(similarity_top_k=5,# filters=MetadataFilters.from_dicts(# metadata_dicts,# condition=FilterCondition.OR# ))response = query_engine.query(query)return responsevector_query_tool = FunctionTool.from_defaults(name="vector_tool",fn=vector_query
)
from llama_index.core import SummaryIndex
from llama_index.core.tools import QueryEngineToolsummary_index = SummaryIndex(nodes)
summary_query_engine = summary_index.as_query_engine(response_mode="tree_summarize",use_async=True,
)
summary_tool = QueryEngineTool.from_defaults(name="summary_tool",query_engine=summary_query_engine,description=("Useful if you want to get a summary of this article"),
)
6.1、代码解释
- vector_query 函数
参数说明
● query (str):用户输入的查询语句,会被转成 embedding 去做向量相似度检索。
● page_numbers (List[str]):可选的过滤条件。如果给定页码,就只在这些页里搜索。
逻辑说明
● 构建 metadata_dicts:用于存储过滤条件(按页码筛选)。
● vector_index.as_query_engine(…):把向量索引(vector_index)封装成一个查询引擎。
○ similarity_top_k=5:返回与 query 最相似的前 5 个节点。
○ filters=… 被注释掉了,如果启用,就能限制只搜索特定页码。
● 执行查询:query_engine.query(query),返回结果。
def vector_query(query: str, page_numbers: List[str]) -> str:"""Perform a vector search over an index."""metadata_dicts = [{"key": "page_label", "value": p} for p in page_numbers]query_engine = vector_index.as_query_engine(similarity_top_k=5,# filters=MetadataFilters.from_dicts(# metadata_dicts,# condition=FilterCondition.OR# ))response = query_engine.query(query)return response
- vector_query_tool
功能:把 vector_query 函数包装成一个 工具 (FunctionTool),方便 LLM 通过工具调用方式来执行。
name:工具名称是 “vector_tool”。
fn:绑定的具体函数是 vector_query。
vector_query_tool = FunctionTool.from_defaults(name="vector_tool",fn=vector_query
)
- SummaryIndex 与 summary_query_engine
SummaryIndex(nodes)
● nodes 是文本切片后的数据节点。
● SummaryIndex 是一种特殊索引,擅长做内容总结,而不是逐节点搜索。
as_query_engine
● response_mode=“tree_summarize”:回答方式是 树状总结(Tree Summarization),即先对节点进行局部总结,再合并成全局总结。
● use_async=True:异步执行,提高性能。
from llama_index.core import SummaryIndex
from llama_index.core.tools import QueryEngineToolsummary_index = SummaryIndex(nodes)
summary_query_engine = summary_index.as_query_engine(response_mode="tree_summarize",use_async=True,
)
- summary_tool
● 功能:把 summary_query_engine 封装成一个 查询工具。
● name:工具名 “summary_tool”。
● description:告诉 LLM 什么时候调用这个工具(当需要文章总结时)。
summary_tool = QueryEngineTool.from_defaults(name="summary_tool",query_engine=summary_query_engine,description=("Useful if you want to get a summary of this article"),
)