CVPR 强化学习模块深度分析:连多项式不等式+自驾规划
关注gongzhonghao【CVPR顶会精选】
今天想和大家聊聊极具潜力的强化学习。它正处于技术突破爆发期,无论是理论创新还是工程落地,都有巨大探索空间。同时,作为跨领域的 “技术桥梁”,强化学习在自动驾驶、机器人、金融、游戏等需要动态决策的场景广泛应用,既能满足产业需求,又备受多领域关注。
那么小图给大家精选3篇CVPR有关强化学习方向的论文,供大家借鉴和参考,同时也欢迎大家向小图投稿或推荐优秀的论文。
论文一: CAutomated Proof of Polynomial Inequalities via Reinforcement Learning
方法:
作者首先将多项式不等式证明建模为马尔可夫决策过程,通过深度强化学习智能选择变换和推理路径,有效探索解空间。系统采用非负Krivine基表示,保证证明过程的表达能力和严格性,并结合定制化奖励函数引导学习。最后,通过大规模实验验证,该方法在多个公开基准上表现出优异的效率和自动化程度。
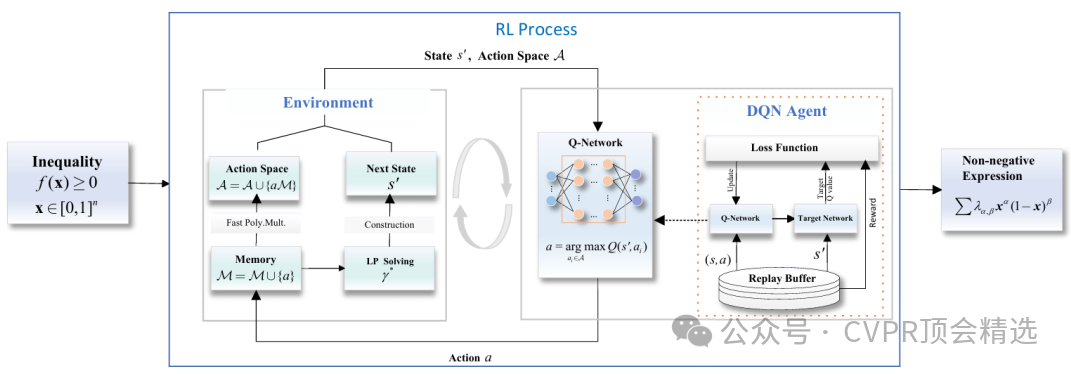
创新点:
首次将深度强化学习引入多项式不等式证明流程,实现了端到端的自动化决策。
构建了基于非负Krivine基的表示框架,有效扩展了现有方法的适用范围。
设计了高效的奖励机制和训练策略,极大提升了证明过程的收敛速度和成功率。
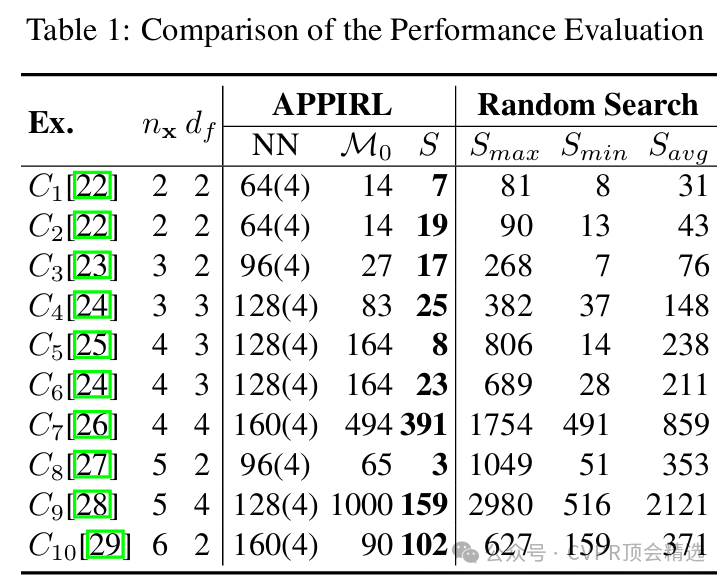
论文链接:
https://arxiv.org/abs/2503.06592
图灵学术科研辅导
论文二:CarPlanner: Consistent Auto-regressive Trajectory Planning for Large-Scale Reinforcement Learning in Autonomous Driving
方法:
作者将轨迹规划问题转化为自回归序列决策任务,结合强化学习算法动态生成最优路径,确保每一步决策与整体轨迹高度一致。采用分布式训练和高效样本利用机制,大幅提升模型在大规模数据集上的收敛速度和泛化表现。最终,通过与主流方法对比实验,证明CarPlanner在自动驾驶轨迹规划中的性能优势和实际应用价值。
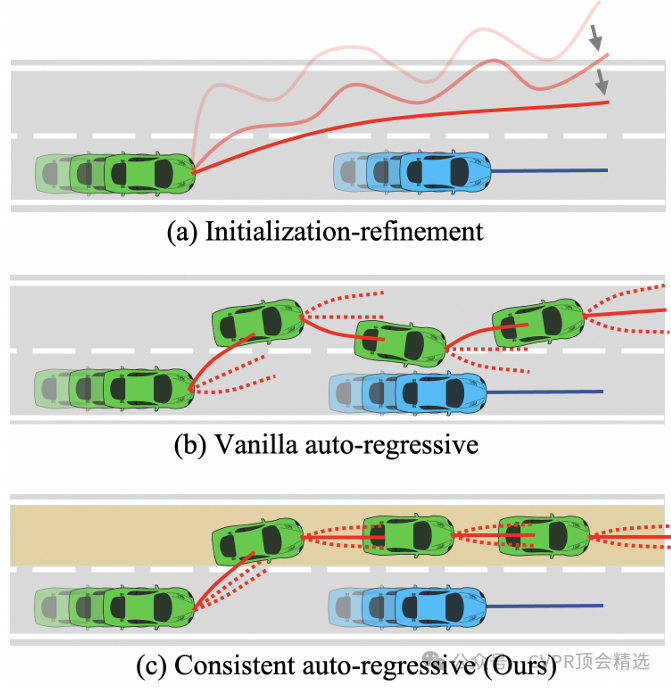
创新点:
提出了首个一致性自回归轨迹规划策略,有效提升了轨迹生成的连贯性和准确性。
设计了大规模强化学习训练架构,专为自动驾驶场景优化,显著提高了训练速度与泛化能力。
在真实大规模数据集上实现了对现有方法的超越,验证了框架的高实用性和鲁棒性。
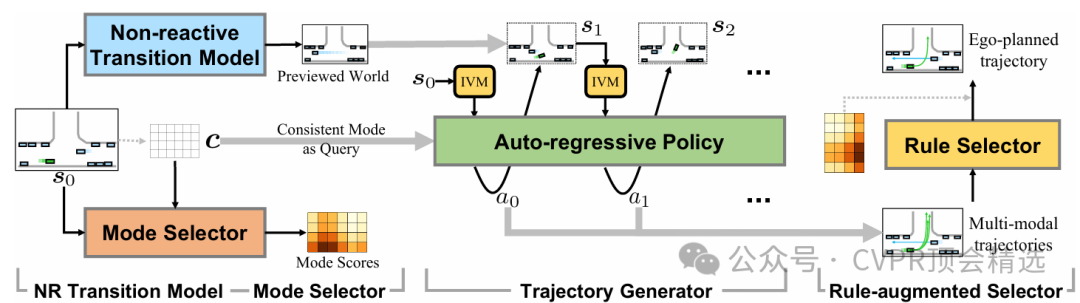
论文链接:
https://arxiv.org/abs/2502.19908
图灵学术科研辅导
论文三:VLMs-Guided Representation Distillation for Efficient Vision-Based Reinforcement Learning
方法:
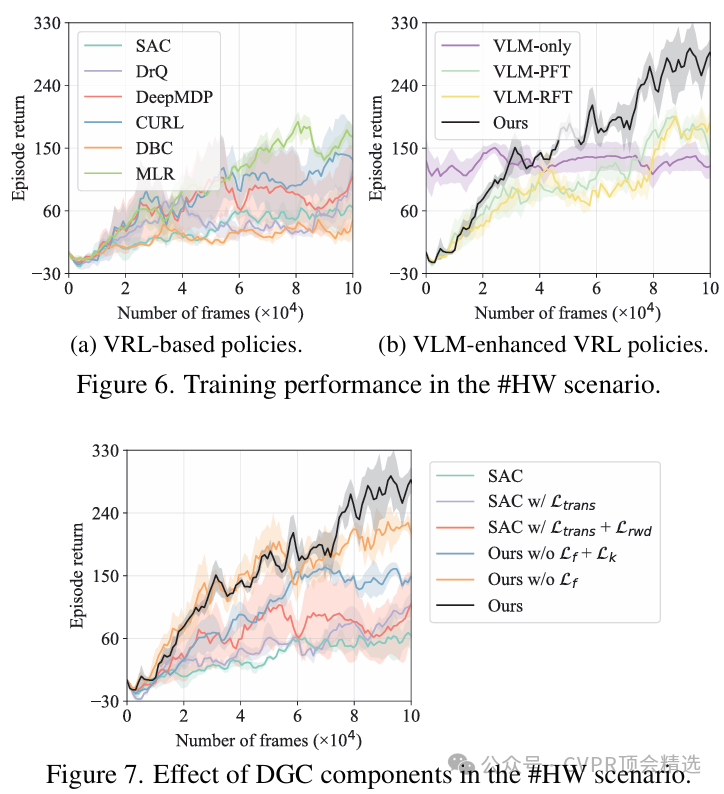
作者首先利用视觉语言模型对环境视觉信息进行深度编码,并通过自监督蒸馏将其知识迁移到强化学习智能体,提升特征提取的通用性和表达力。接着,结合跨模态信息融合,使语言和视觉的互补信息共同优化状态表征,增强策略泛化能力。最终,通过在多个视觉强化学习任务上的实验,验证了DGC方法在样本利用率和最终性能上的显著提升。
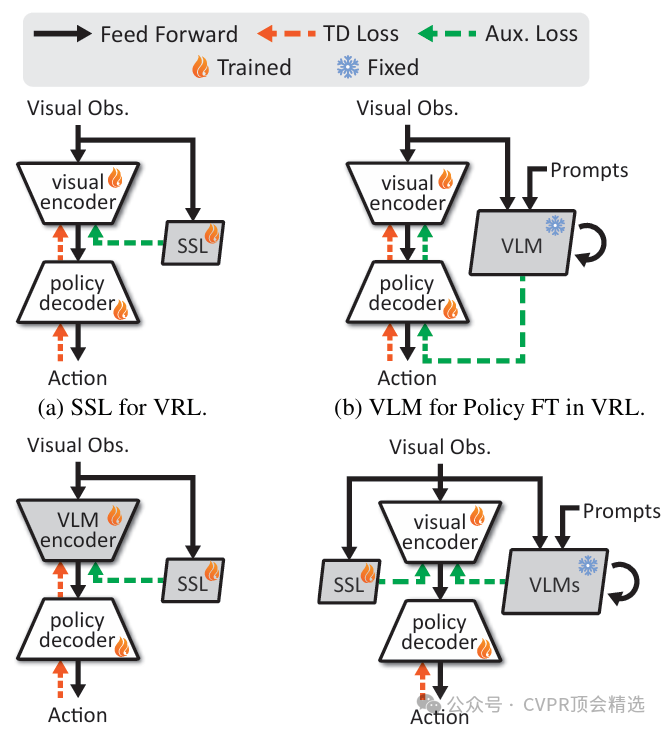
创新点:
创新性地将视觉语言模型引入视觉强化学习,指导特征表征的自监督蒸馏。
设计了跨模态信息融合机制,使视觉和语言知识共同提升状态表征的表达能力。
显著提升了视觉强化学习的样本效率,实验中在多种基准环境下实现了优异表现。
论文链接:
https://openaccess.thecvf.com/content/CVPR2025/papers/Xu_VLMs-Guided_Representation_Distillation_for_Efficient_Vision-Based_Reinforcement_Learning_CVPR_2025_paper.pdf
本文选自gongzhonghao【CVPR顶会精选】