CVPR2025丨VL2Lite:如何将巨型VLM的“知识”精炼后灌入轻量网络?这项蒸馏技术实现了任务专用的极致压缩
关注gongzhonghao【CVPR顶会精选】
小模型(Small Models)通常指参数量较小、计算与存储成本更低的深度学习模型。近年来,它们在移动端部署、边缘计算和隐私保护等场景中快速发展,逐渐成为大模型的轻量化补充。
随着蒸馏、剪枝、量化等技术成熟,小模型在语音识别、图像分类等任务中已能接近甚至媲美大模型表现。但受限于容量和泛化能力,其在复杂推理、跨模态理解方面仍存在不足。今天小图给大家精选3篇CVPR有关小模型方向的论文,请注意查收!
论文一:A Stitch in Time Saves Nine: Small VLM is a Precise Guidance for Accelerating Large VLMs
方法:
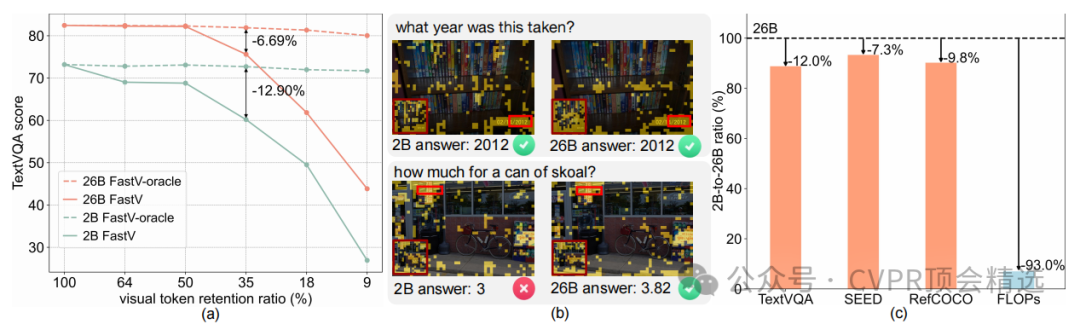
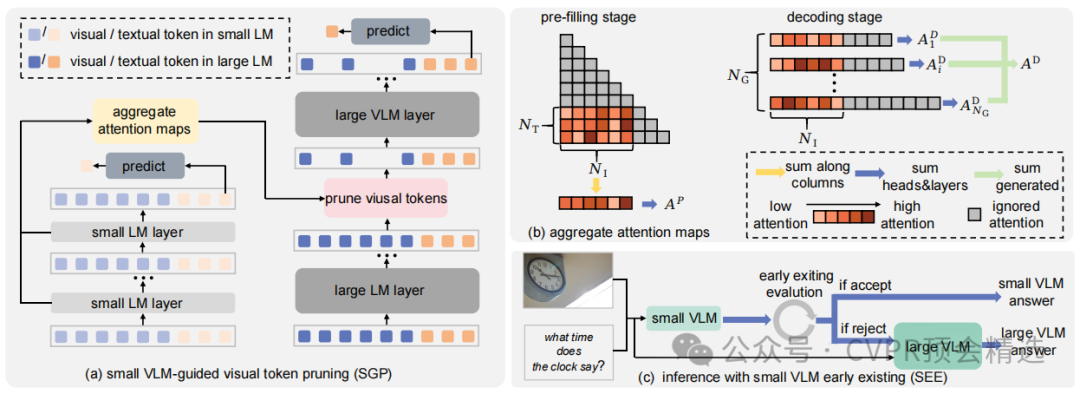
文章首先通过实验证明了小型VLM的全局注意力图与大型VLM的一致性,基于此提出了SGP方法,它先在小型VLM中聚合所有层的注意力图以计算视觉标记的重要性分数,然后利用这些分数指导大型VLM中视觉标记的修剪,有效减少了大型VLM的计算负担。同时,文章还设计了SEE机制,通过评估小型VLM的预测置信度来决定是否提前终止推理,避免了对大型VLM的无谓调用,两者结合在多个基准测试中展现了优异的效率与性能平衡。
创新点:
首次发现小型VLM的全局注意力图与大型VLM高度相似,突破了以往仅依赖大型VLM单层注意力图的局限。
提出了Small VLM-Guided视觉标记修剪技术,利用小型VLM的全局注意力图对大型VLM的视觉标记进行重要性排序并修剪不重要的标记,实现了在极低标记保留率下的性能优化。
引入了Small VLM Early Exiting机制,进一步减少了不必要的计算,提升了整体的推理效率。
论文链接:
https://cvpr.thecvf.com/virtual/2025/poster/34456
图灵学术科研辅导
论文二:VL2Lite: Task-Specific Knowledge Distillation from Large Vision-Language Models to Lightweight Networks
方法:
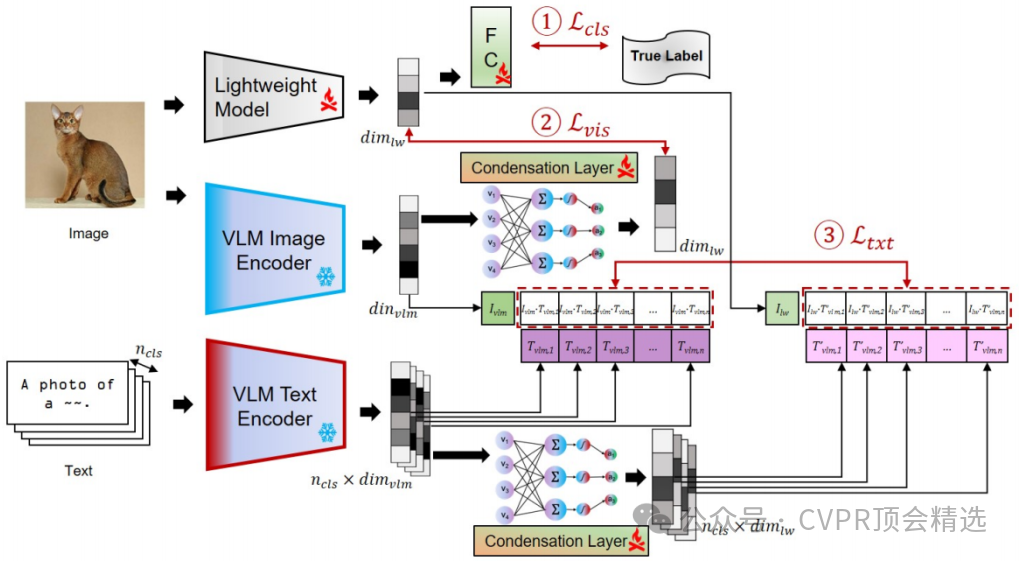
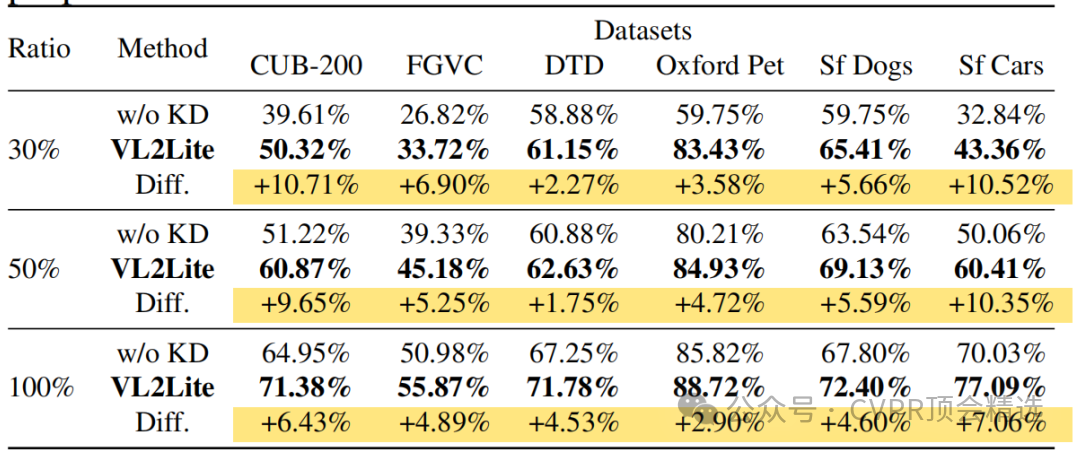
文章首先定义了一个任务特定的分类损失函数,确保轻量级模型能够准确地完成特定任务。接着,通过视觉知识蒸馏损失函数,利用知识凝聚层将VLMs的高维特征压缩到适合轻量级模型的低维空间,同时保持特征间的关系。此外,通过语言知识蒸馏损失函数,进一步将VLMs的文本编码器输出与轻量级模型的视觉特征对齐,增强其语义理解能力。最终,将这三个损失函数整合到一个复合损失函数中,并在训练过程中动态调整它们的权重,以实现同时进行分类和知识蒸馏的目标。
创新点:
提出了直接从预训练的VLMs到轻量级模型的一阶段知识蒸馏方法,避免了传统两阶段知识蒸馏的复杂性和偏见传播。
创新性地结合了视觉和语言知识蒸馏,通过专门设计的损失函数和知识凝聚层,实现了更有效的知识迁移。
引入了文本提示工程来增强轻量级模型的语义理解能力,进一步提升了其在视觉任务上的表现。
论文链接:
https://cvpr.thecvf.com/virtual/2025/poster/33217
图灵学术科研辅导
论文三:BlueLM-V-3B: Algorithm and System Co-Design for Multimodal Large Language Models on Mobile Devices
方法:
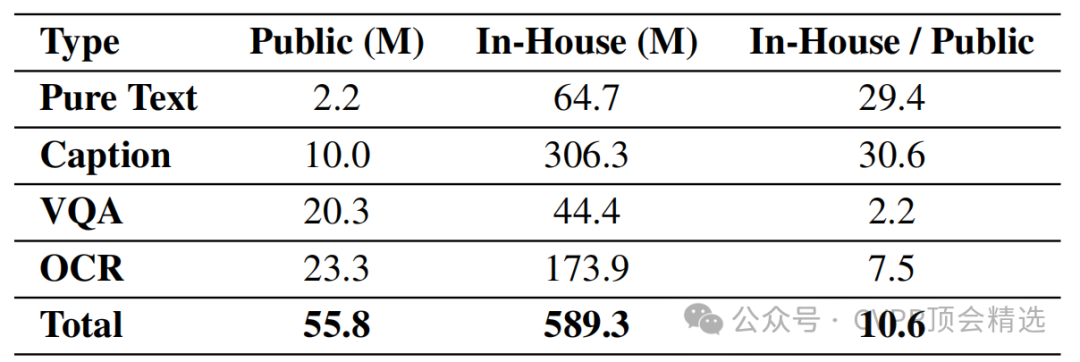
文章首先对现有的动态分辨率方案进行了改进,通过引入放松的宽高比匹配方法,减少了图像放大带来的额外计算负担。接着,针对移动设备的硬件特性,设计了批量图像编码和流水线并行处理策略,以充分利用硬件的计算能力。此外,还采用了分块计算方法来处理长输入序列,平衡了并行处理和硬件性能之间的关系。最后,通过混合精度量化和解耦图像编码与指令处理的框架,进一步优化了模型在移动设备上的部署效率。

创新点:
提出了一种改进的动态分辨率方案,通过放松宽高比匹配方法,有效减少了图像标记的数量,同时保持了模型的准确性。
设计了一系列针对移动设备硬件感知的系统优化措施,包括批量图像编码、流水线并行处理和分块计算,显著提高了模型的推理效率。
实现了混合精度量化和图像编码与指令处理的解耦,进一步降低了内存使用量,提高了模型的部署效率。
论文链接:
https://cvpr.thecvf.com/virtual/2025/poster/34136
本文选自gongzhonghao【CVPR顶会精选】