数据库服务-主从同步-高可用架构MHA
文章目录
- 🌟主从故障排查思路
- 🔍查看主从同步状态
- 🔍查看主从同步错误提示信息
- 🔍查看dump线程发送的binlog日志文件和位置点信息
- 🔍查看relay log日志中回放数据信息binlog文件和位置点
- 🔍从库是否开启了延迟同步功能
- ⚠️IO线程出现故障Slave_IO_Running: connecting
- 模拟用户密码故障
- 模拟防火墙阻止连接建立
- 模拟数据库服务连接数到达上限故障
- ⚠️IO线程出现故障Slave_IO_Running: no
- binlog日志信息被无意清理
- 无法读取binlog日志文件故障解决办法
- 标识信息server_uuid冲突了
- 主从配置的标识信息重复冲突解决方法
- ⚠️SQL线程出现故障Slave_SQL_Running: no
- SQL线程执行事务时失败了
- 避免主从冲突方案
- 产生主从冲突如何处理
- 🌟基于GTID实现主从同步
- 📌实现原理机制
- 🛠️GTID实战
- 准备主从实例主机
- 需要在主从主机配置GTID功能
- 在主库上进行数据备份
- 在从库恢复备份数据
- 在从库上做主从配置
- 启动主从同步
- 测试
- 🌟实现主从延迟同步数据
- 🧩主从延迟同步原理
- 🛠️主从延迟同步实践
- 准备主从实例主机
- 在主库做好数据备份
- 在从库进行数据恢复
- 确认正常主从是否可以建立
- 需要停止主从SQL线程,进行延迟功能配置
- 测试
- 🌟如何利用延迟从库修复数据
- 🔍模拟创建测试数据
- 🖥️模拟管理数据库人员做了错误操作
- 📁利用延迟从库备份数据
- 停止SQL线程
- 找到正确事务
- 找到错误事务
- 将错误事务之前的事务恢复
- 备份误删除数据的表
- 🌏在主库中恢复数据信息
- 🌟数据库主从同步传输数据方式
- 📌异步复制
- 📐半同步复制
- 🍀同步复制
- 🌟数据库半同步复制实践过程
- 🖥️准备主从实例主机
- 📁在主库上做数据备份
- 🛠️在从库进行数据恢复
- 📌确认正常主从是否可以建立
- 🧩主库和从库中安装半同步插件
- 💡激活半同步功能
- ⚠️模拟IO线程异常
- 🌟数据库服务高可用架构(MHA)
- 🖥️准备主从同步环境
- 编辑主库配置文件(db03)
- 编写从库配置文件(db04)
- 编写从库配置文件(db05)
- 初始化数据库(db03/db04/db05)
- 在主库创建主从同步用户(db03)
- 在从库做主从配置(db04/db05)
- 🛠️安装部署高可用服务软件
- MHA管理节点(db06)
- MHA数据节点(db03/db04/db05)
- 📝编写MHA服务配置文件(db06管理节点)
- 🌈主库创建mha管理用户
- 🔍MHA服务环境测试
- 测试主从节点之间互信功能
- 测试主从同步状态
- 🚀启动mha服务程序
- MHA功能配置
- 高可用主库的监控
- 主库选举机制
- 数据补偿过程
- 进行主从重构
- 实现主从切换应用透明(需要做配置)
- 实现MHA故障转移报警功能
- 测试MHA切换功能
- 编写VIP切换脚本
- 实现故障报警功能
- 实现数据额外补偿功能
- 测试高可用自动切换功能
- 恢复MHA运行启动
- 将db03重新加入到主从节点中
- 实现手动切换
- 编写手动切换脚本
- 编写MHA配置文件
- 加载MHA配置
- 利用命令实现手动切换
- ✅总结
🌟主从故障排查思路
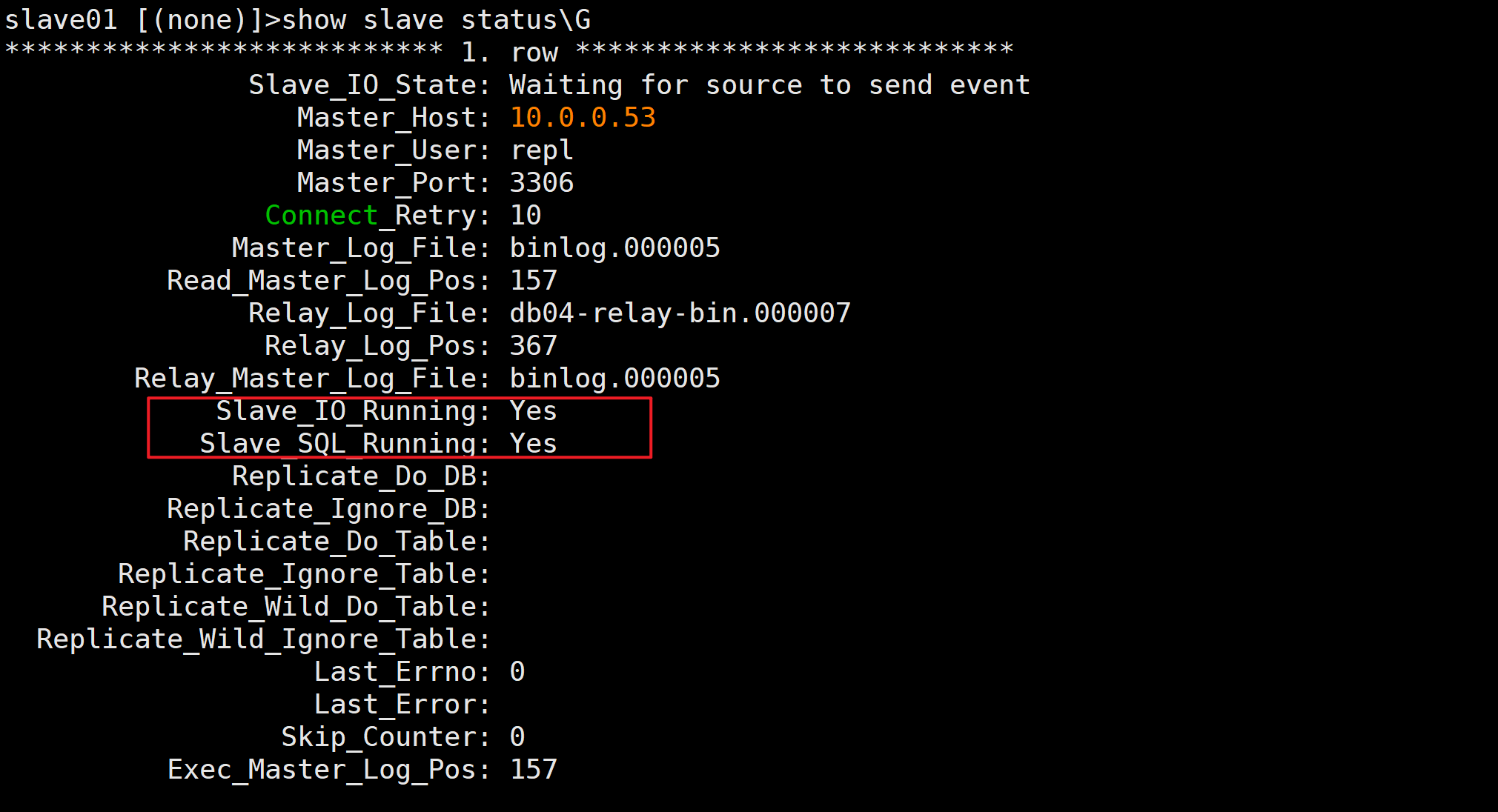
🔍查看主从同步状态
show slave status\G
Slave_IO_Running: Yes
Slave_SQL_Runnint: Yes
从库上两个关键线程,状态为Yes,表示主从同步正常
✅zabbix自定义监控项的时候可以监控这两个指标,过滤出来2个Yes说明主从正常,少于2个说明不正常
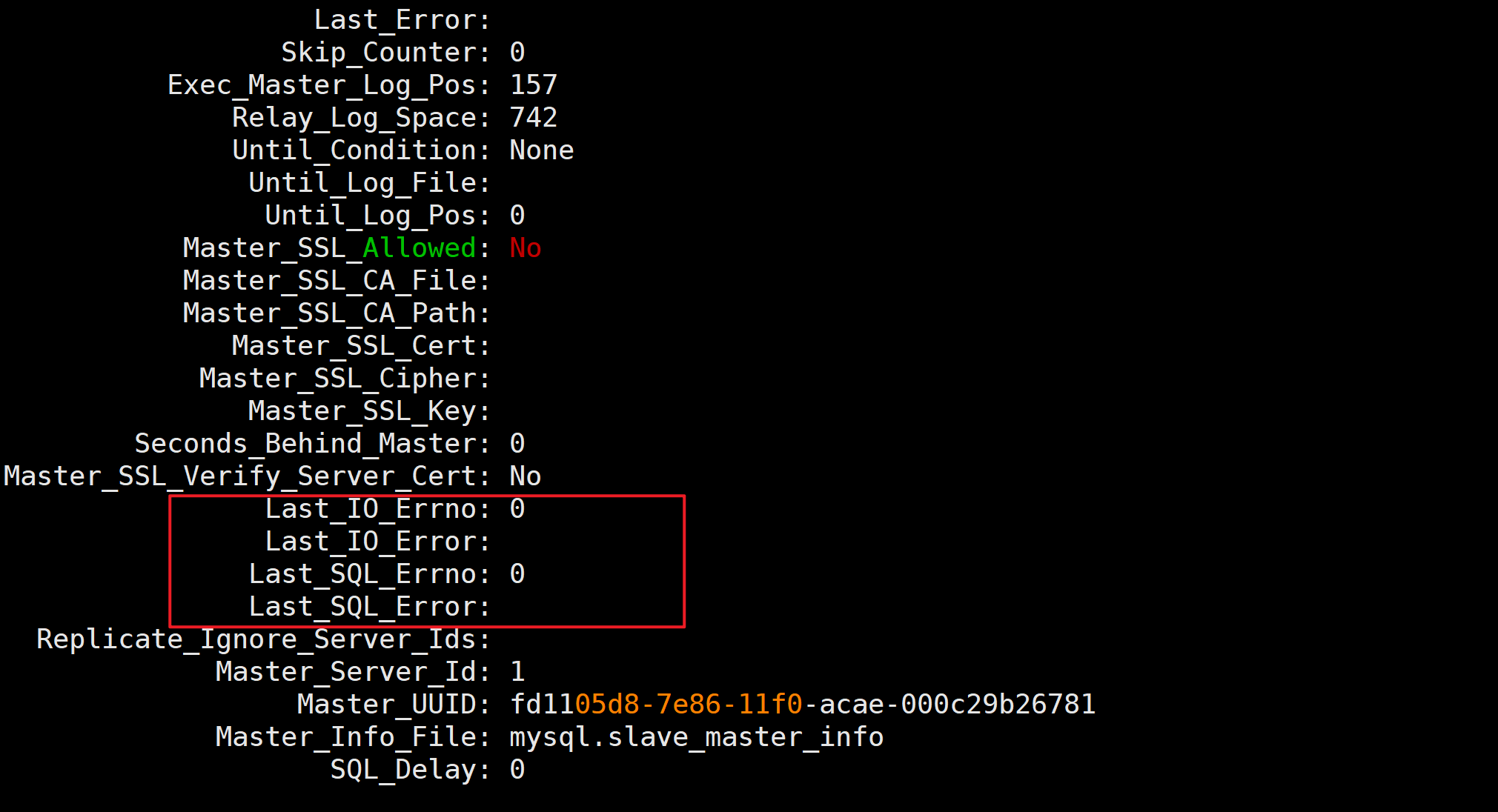
🔍查看主从同步错误提示信息
Last_IO_Errno: 0
Last_IO_Error:
Last_SQL_Errno: 0
Last_SQL_Error:
📌通过错误信息,定位故障问题
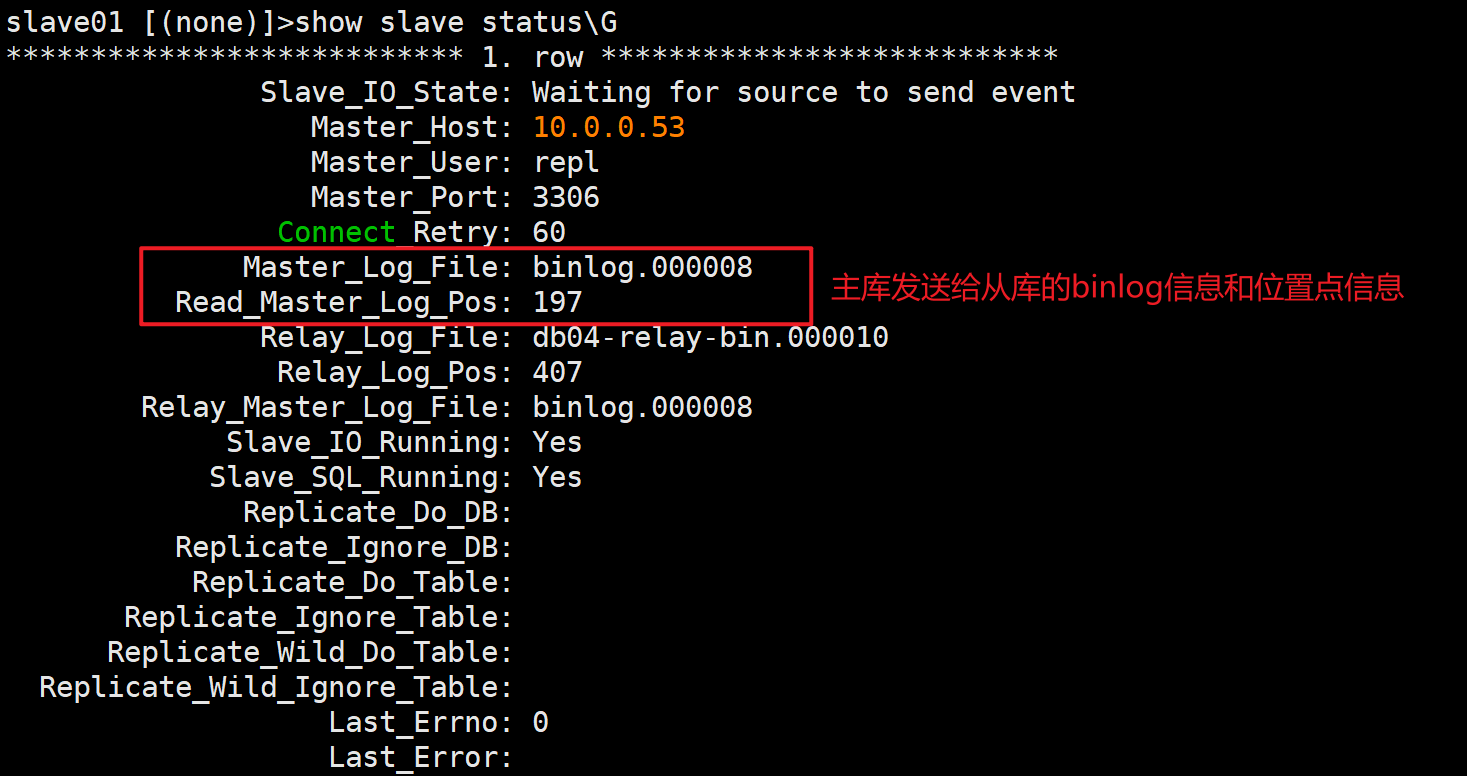
🔍查看dump线程发送的binlog日志文件和位置点信息
Master_Log_File: binlog.000005
Read_Master_Log_Pos: 157
✅查看Master_Log_File和Relay_Master_Log_File是否一致
✅查看Read_Master_Log_Pos和Exec_Master_Log_Pos是否一致
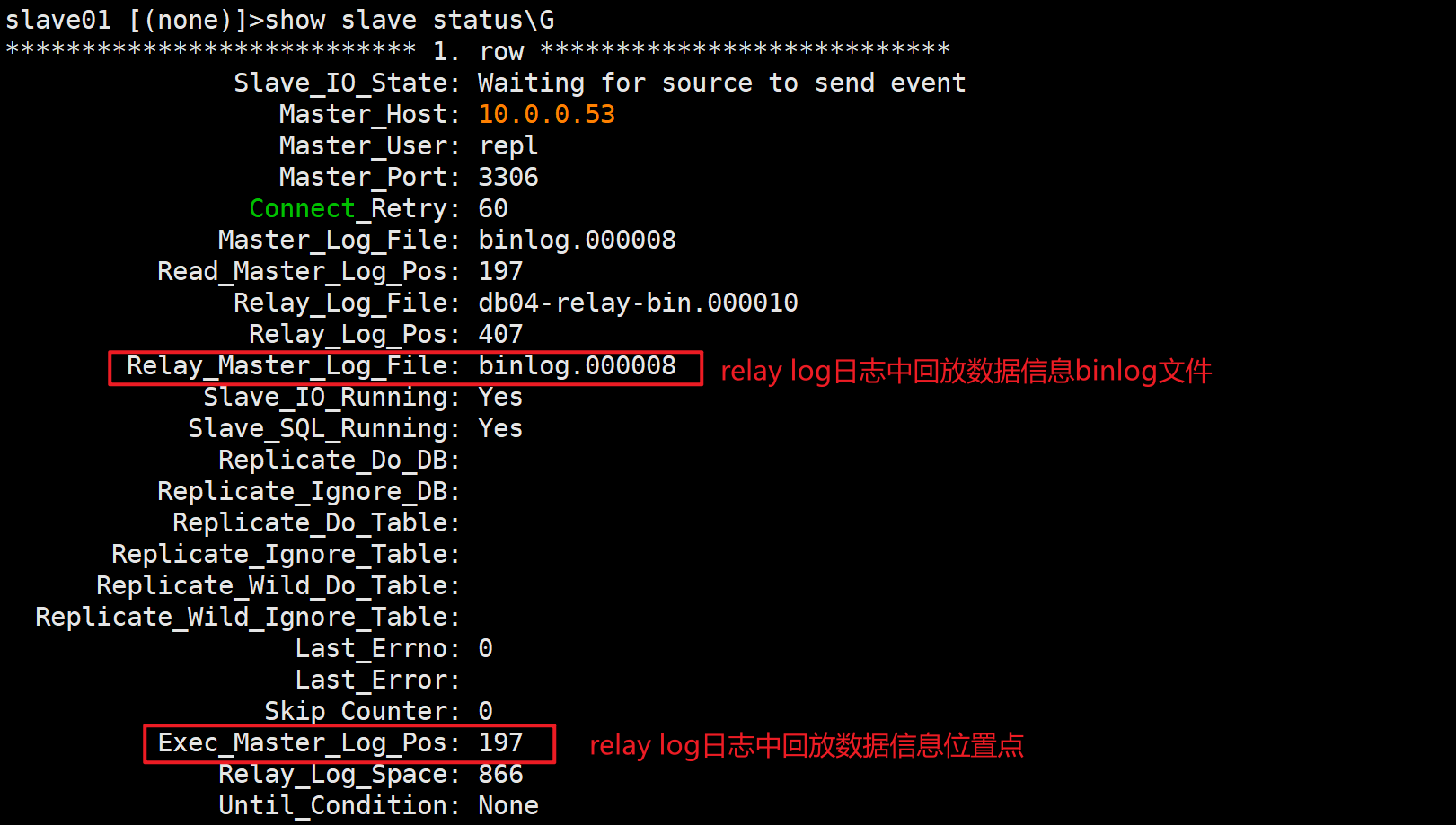
🔍查看relay log日志中回放数据信息binlog文件和位置点
Relay_Master_Log_File: binlog.000005
Exec_Master_Log_Pos: 157
✅查看Relay_Master_Log_File和Master_Log_File是否一致
✅查看Exec_Master_Log_Pos和Read_Master_Log_Pos是否一致
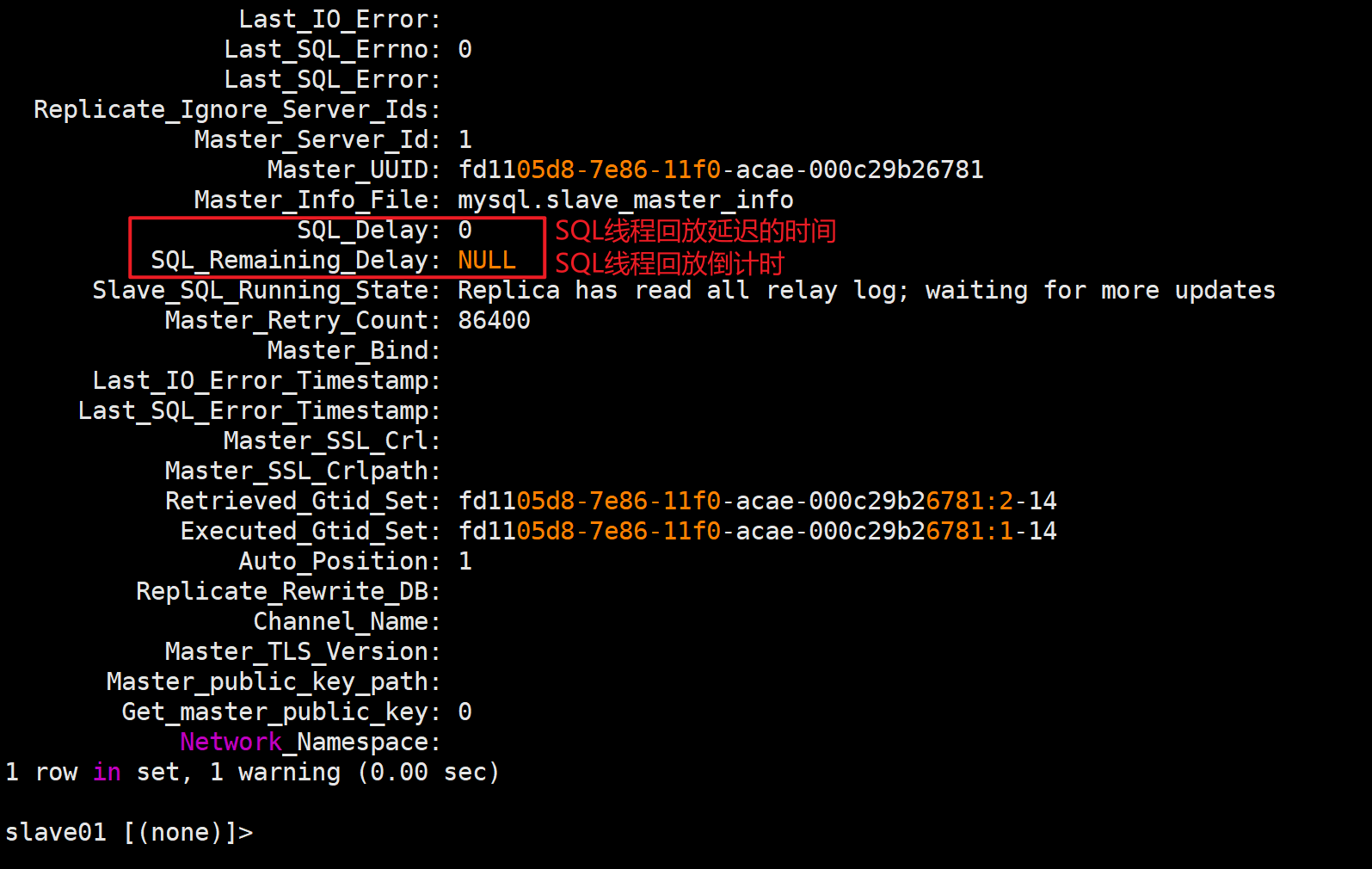
🔍从库是否开启了延迟同步功能
SQL_Delay: 0
SQL_Remaining_Delay: NULL
⚠️IO线程出现故障Slave_IO_Running: connecting
- 1️⃣连接地址、端口、用户、密码信息不对可能导致连接异常
- 2️⃣防火墙安全策略阻止连接建立、网络通讯配置异常影响连接
- 3️⃣数据库服务连接数到达上限,造成主从连接产生异常
模拟用户密码故障
1.停止
stop slave;2.清空从库配置信息
reset slave all;
select * from mysql.slave_master_info\G3.修改从库配置(密码修改为12345)
CHANGE MASTER TO
MASTER_HOST='10.0.0.53',
MASTER_PORT=3306,
MASTER_USER='repl',
MASTER_PASSWORD='12345',
MASTER_LOG_FILE='binlog.000005',
MASTER_LOG_POS=157,
MASTER_CONNECT_RETRY=10;4.激活主从同步
start slave;5.查看主从状态
show slave status\G
⚠️数据库正确密码为123456
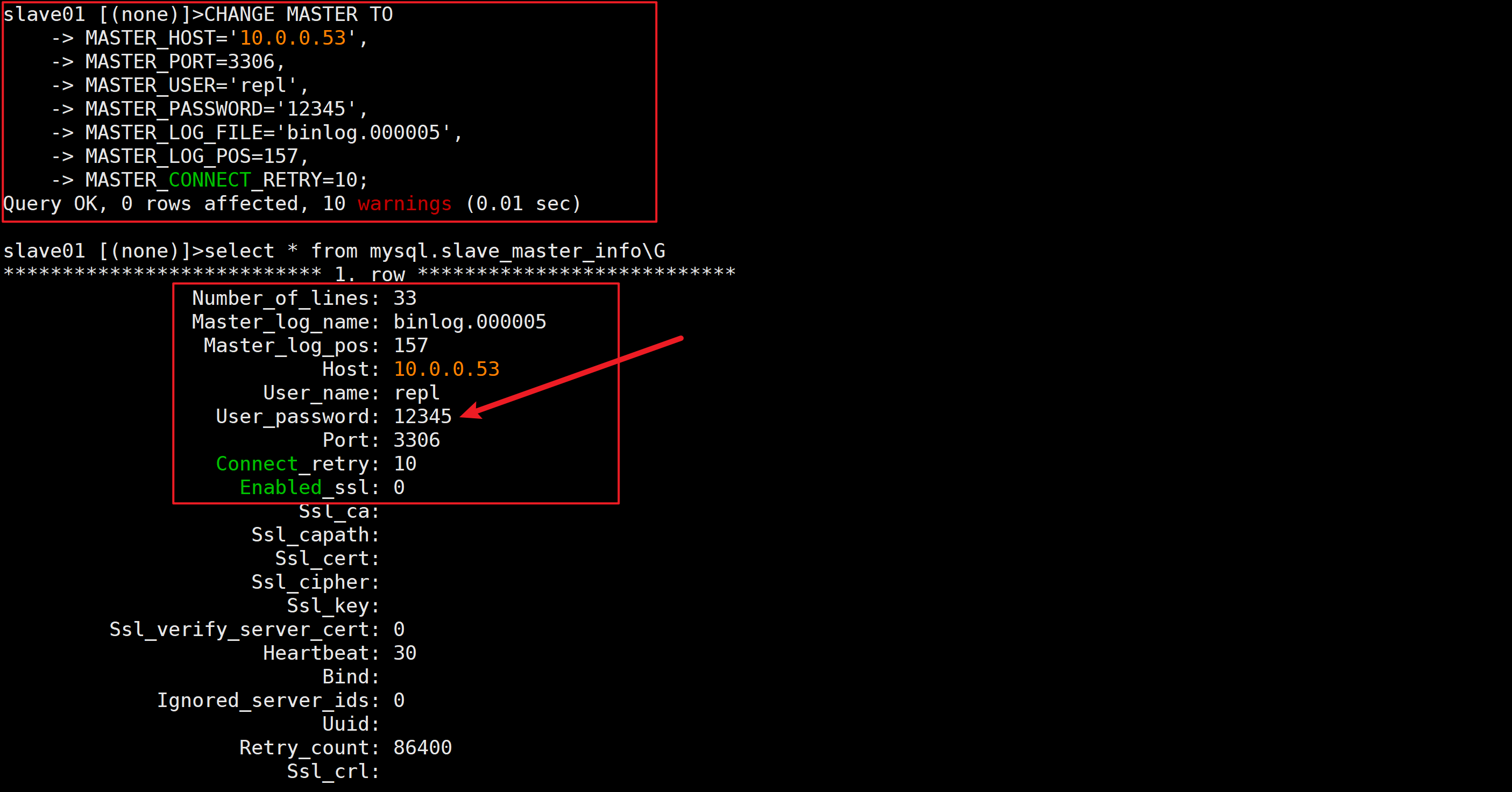
✅激活主从同步后查看主从状态
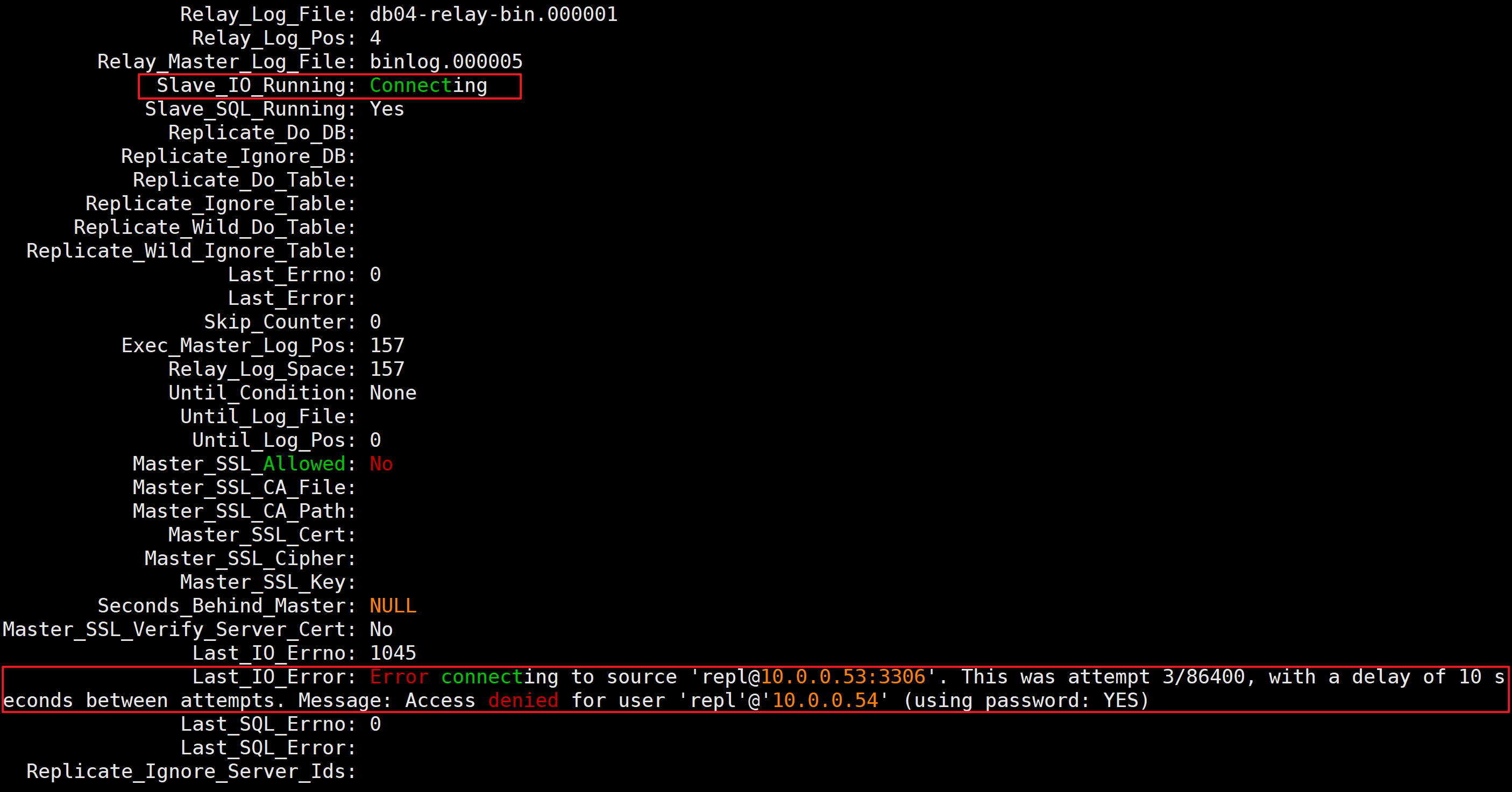
模拟防火墙阻止连接建立
- 开启防火墙
systemctl start firewalld
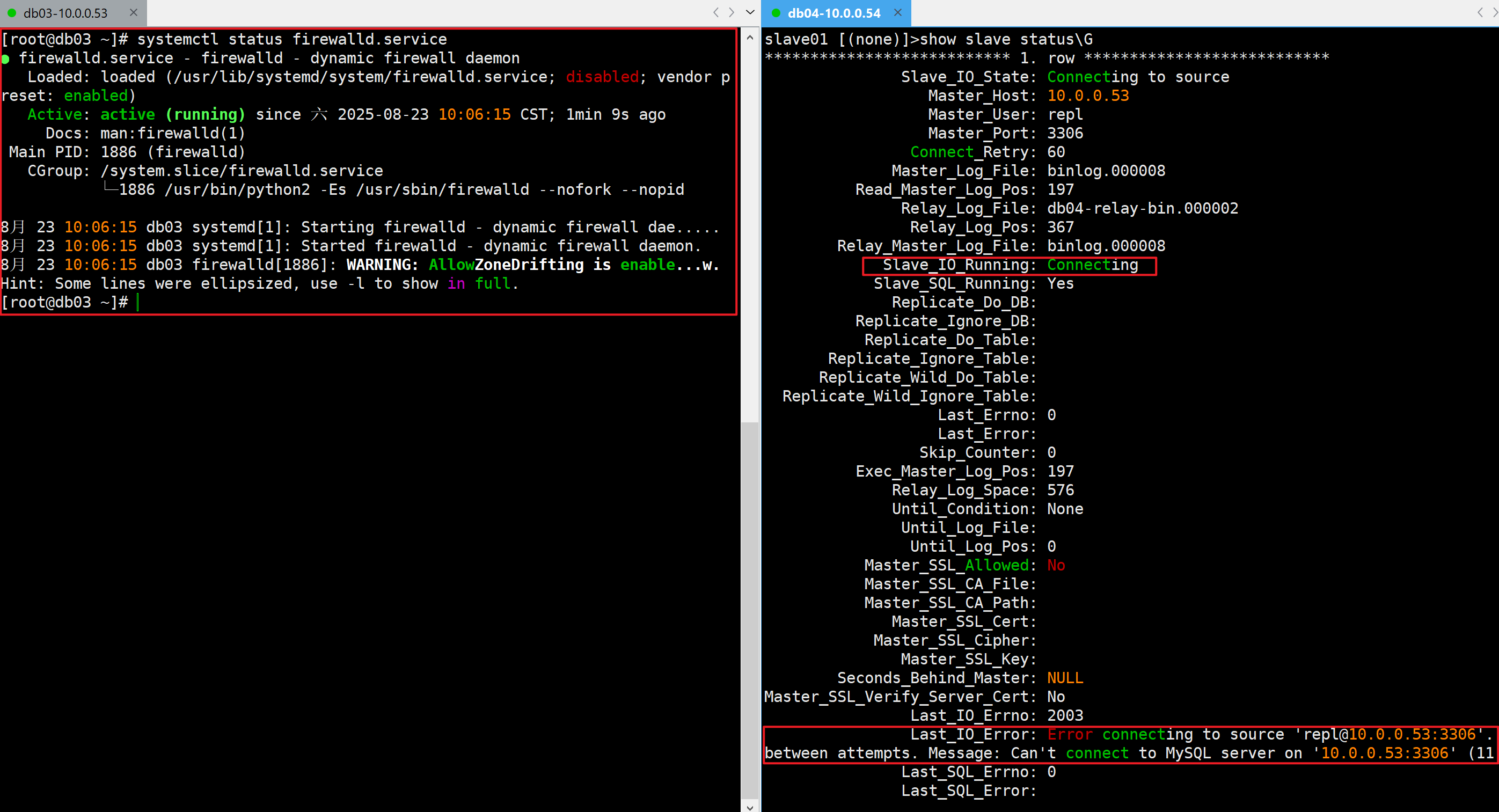
Last_IO_Errno: 2003
Last_IO_Error: Error connecting to source ‘repl@10.0.0.53:3306’. This was attempt 1/86400, with a delay of 60 seconds between attempts. Message: Can’t connect to MySQL server on ‘10.0.0.53:3306’ (113)
无法连接到源“repl@10.0.0.53:3306”。这是第 1 次尝试,总共有 86400 次尝试,每次尝试之间间隔 60 秒。错误信息:无法连接到“10.0.0.53:3306”上的 MySQL 服务器(113)
- 关闭防火墙
systemctl stop firewalld.service
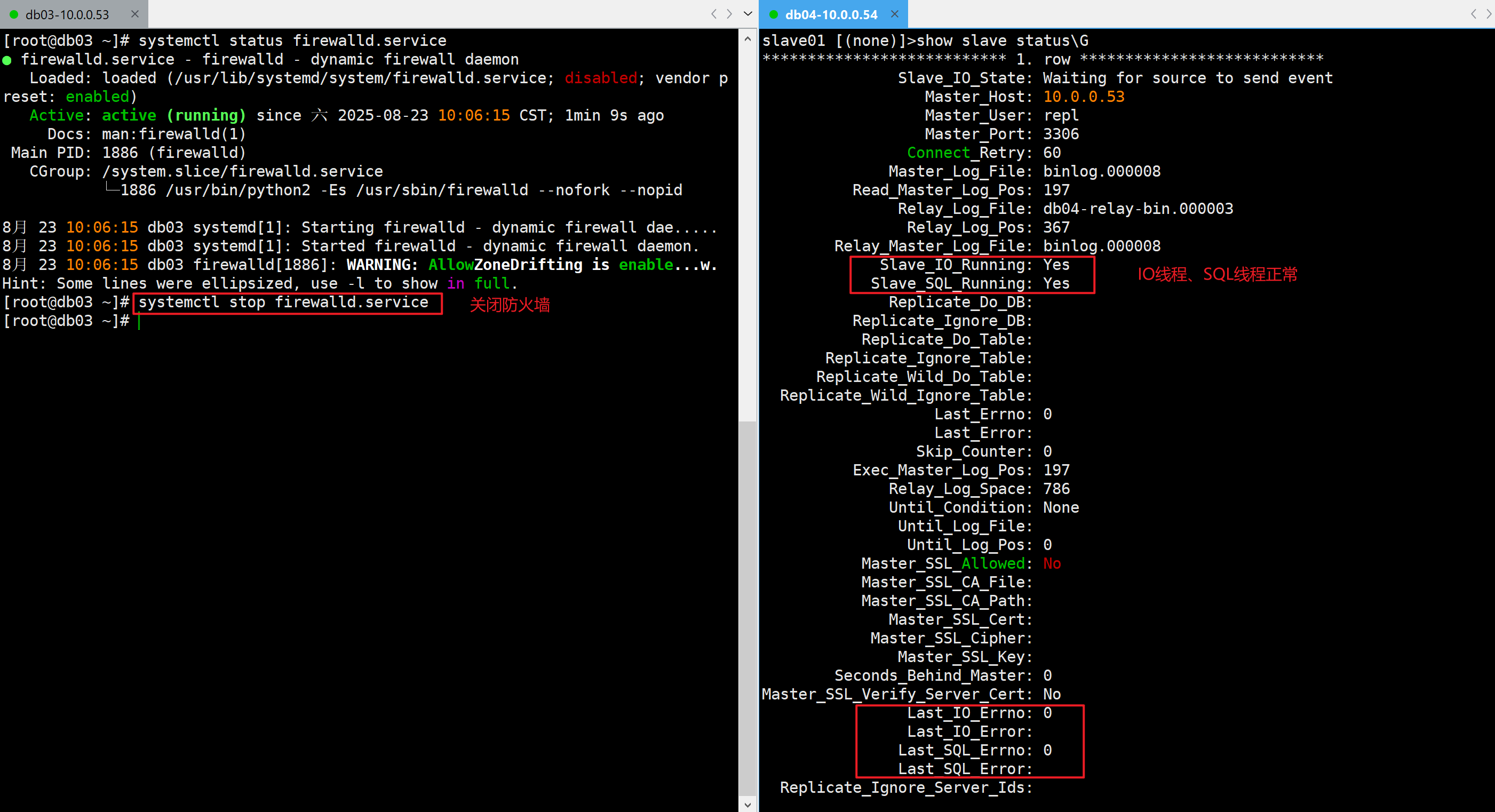
✅关闭防火墙后恢复正常
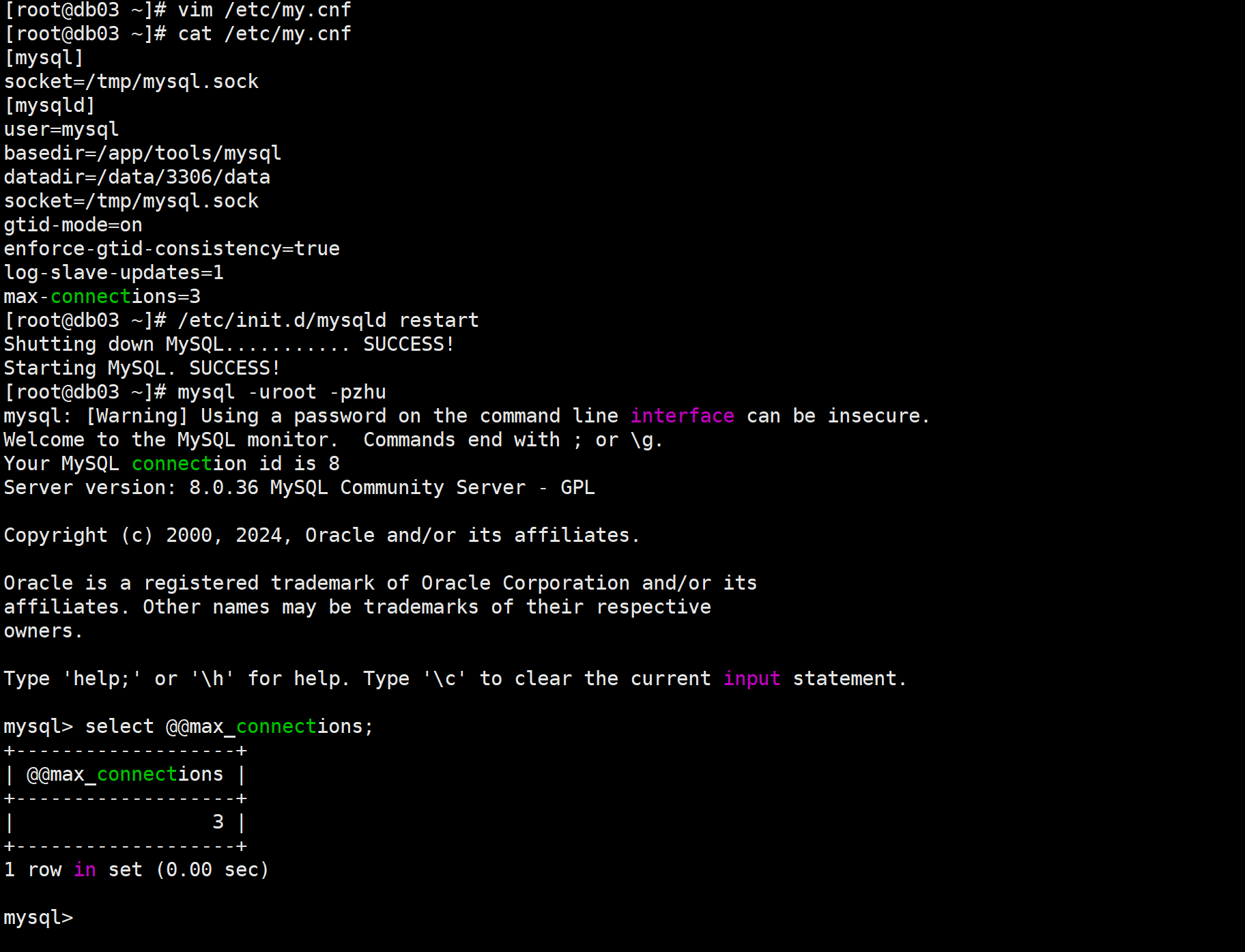
模拟数据库服务连接数到达上限故障
1.查看数据库最大连接数
mysql> select @@max_connections;2.修改最大连接数
vim /etc/my.cnf
max-connections=33.重启服务
/etc/init.d/mysqld restart
✅数据库默认最大连接数为151
- 报错信息
Last_IO_Errno: 1040
Last_IO_Error: Error connecting to source 'repl@10.0.0.53:3306'. This was attempt 1/86400, with a delay of 60 seconds between attempts. Message: Too many connections无法连接到源“repl@10.0.0.53:3306”。这是第 1 次尝试,共进行了 86400 次尝试,每次尝试之间间隔 60 秒。错误信息:连接过多
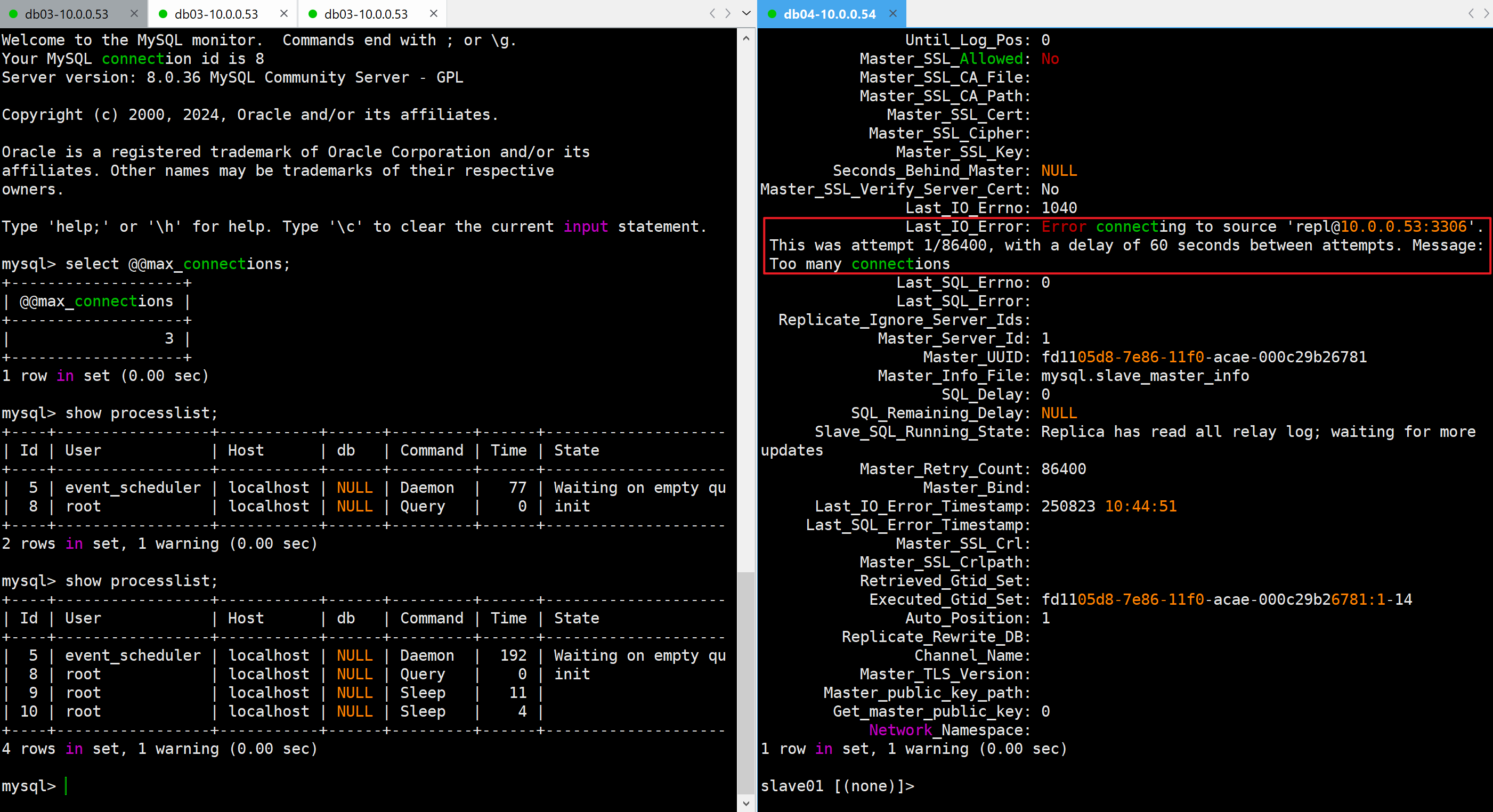
- 手动结束mysql会话连接
kill 9;
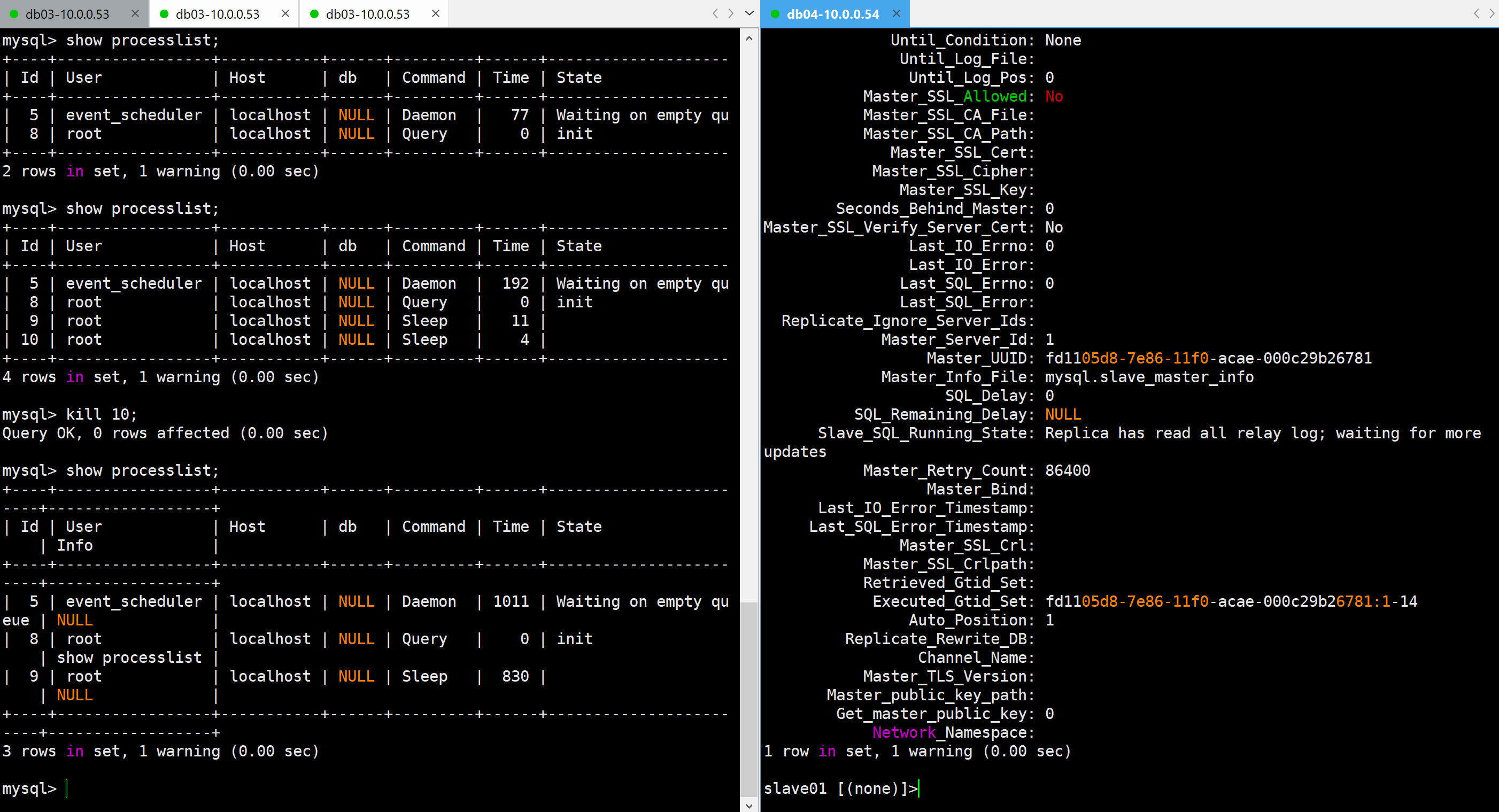
⚠️IO线程出现故障Slave_IO_Running: no
- IO线程在请求日志信息失败,有可能日志信息被无意清理了
- IO线程在请求日志信息失败,有可能主从配置的标识信息重复冲突了
binlog日志信息被无意清理
⚠️当磁盘空间满时,运维人员在清理大文件,不小心把binlog文件也给清理了,导致从库无法读取binlog文件
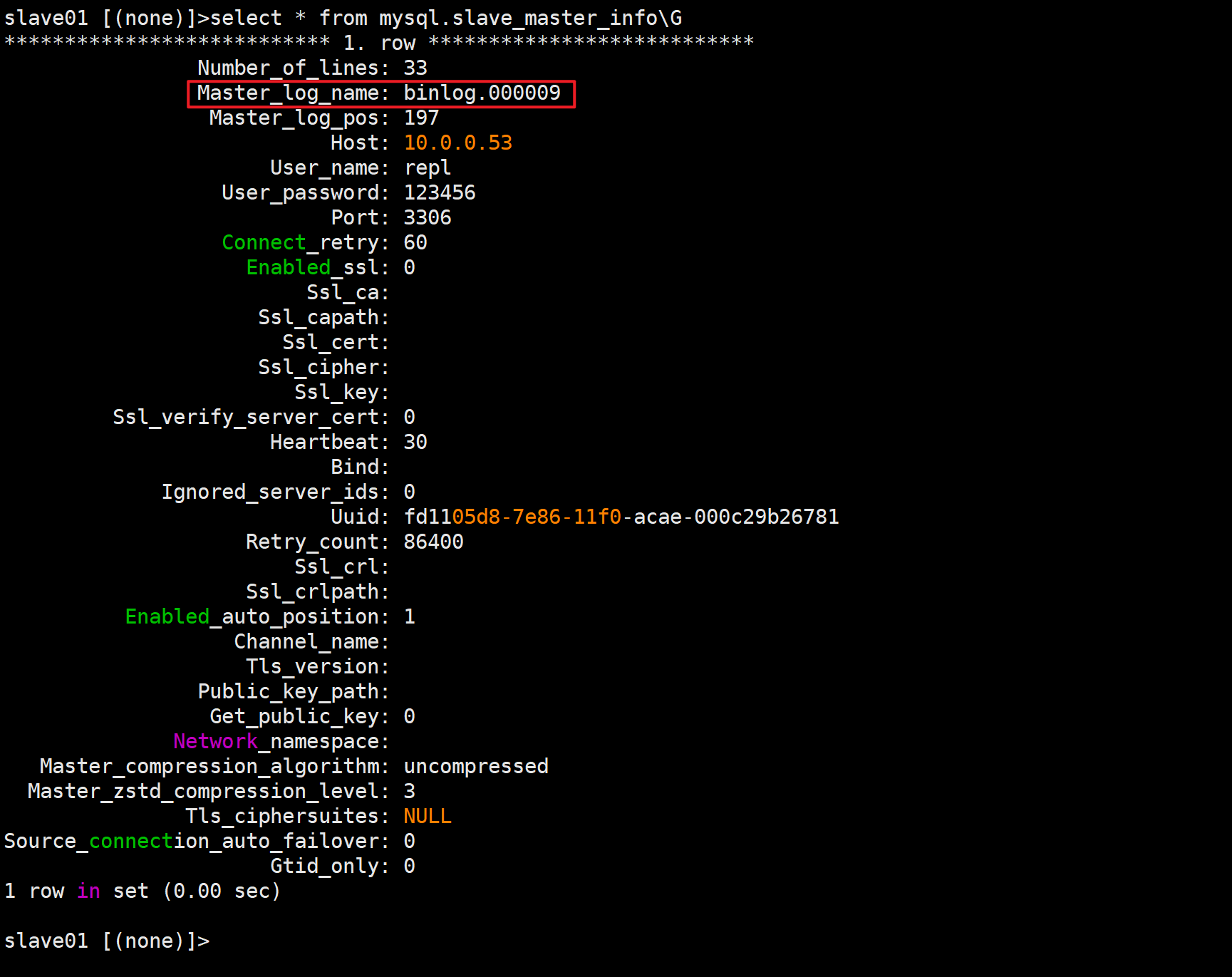
1.查看从库加载的是主库上哪个binlog文件
select * from mysql.slave_master_info\G2.将主库上的binlog文件删除
mv binlog.000009 binlog.000009.bak
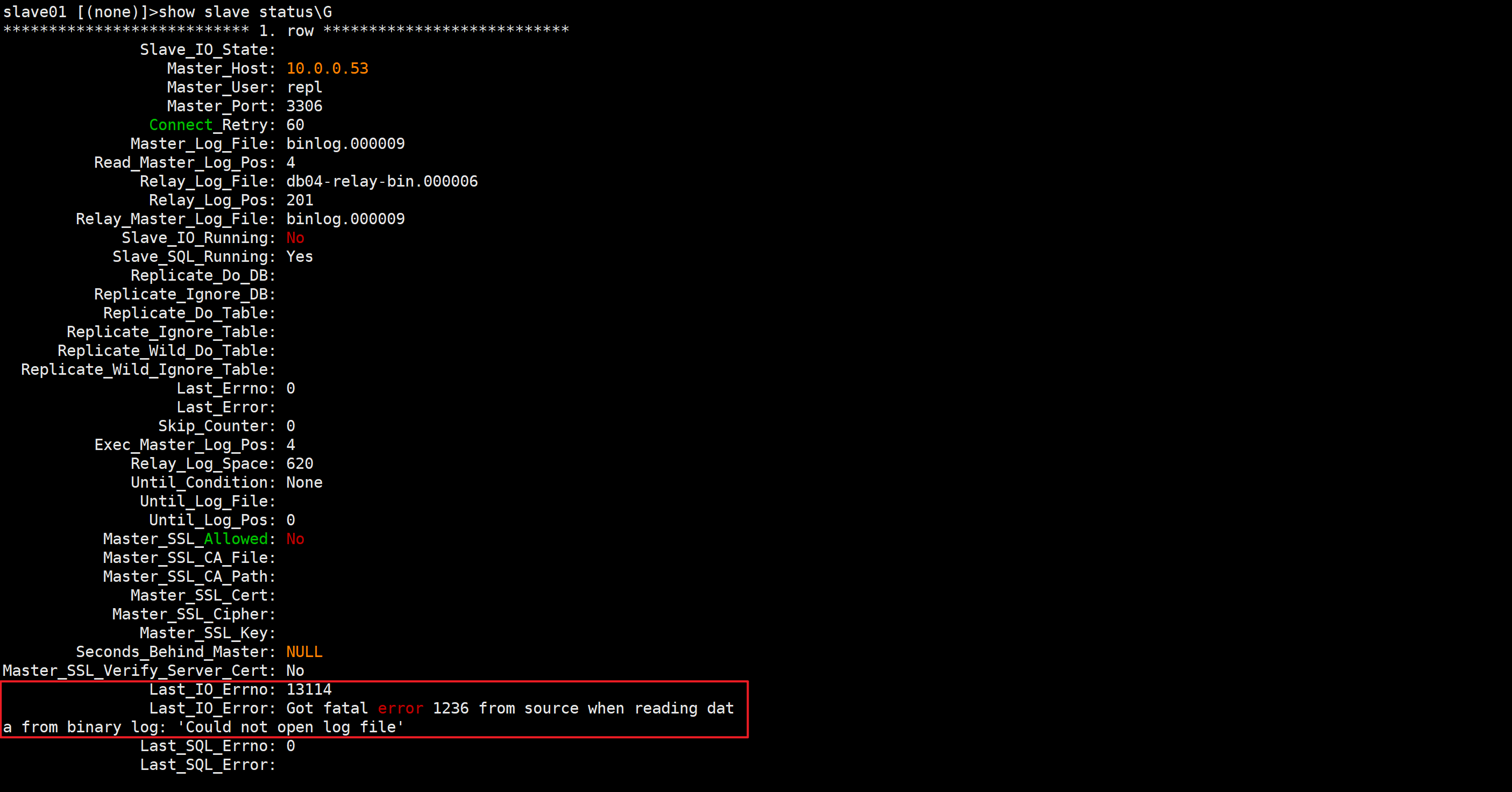
Last_IO_Errno: 13114
Last_IO_Error: Got fatal error 1236 from source when reading data from binary log: ‘Could not open log file’
在从二进制日志读取数据时,从源端获取到了错误代码 1236:“无法打开日志文件”
无法读取binlog日志文件故障解决办法
- 1️⃣在从库上需要停止主从,并清理从库相关主从配置
- 2️⃣在主库上需要切割日志信息,生成新的日志
- 3️⃣在主库上重新进行数据备份,并将备份信息迁移到从库
- 4️⃣在从库上恢复数据信息,根据备份文件binlog信息和位置点信息,重新配置主从功能
⚠️PS: 在使用GTID功能实现主从同步时,可以从库自动识别主库的binlog位置点信息
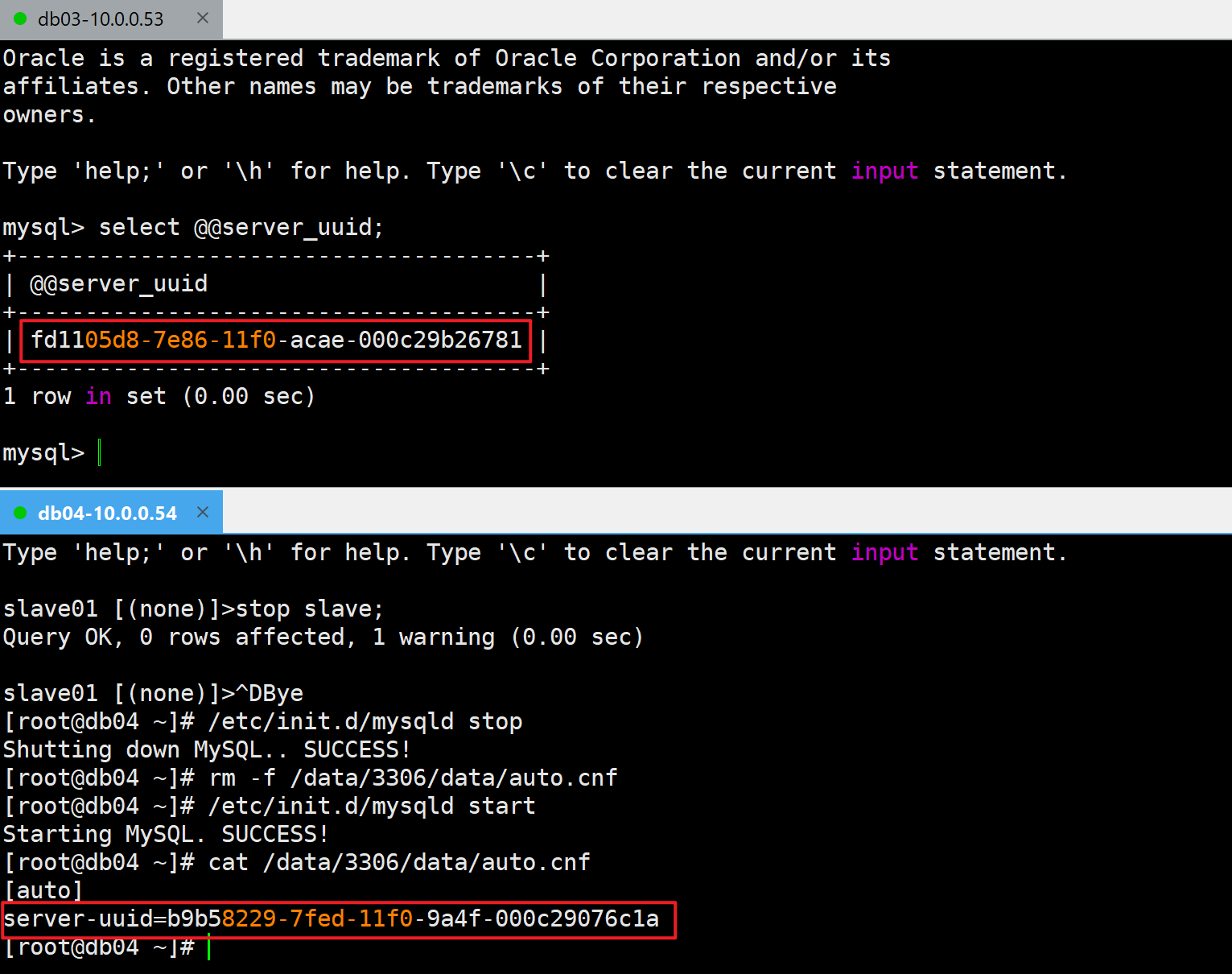
标识信息server_uuid冲突了
IO线程在请求日志信息失败,有可能主从配置的标识信息冲突了
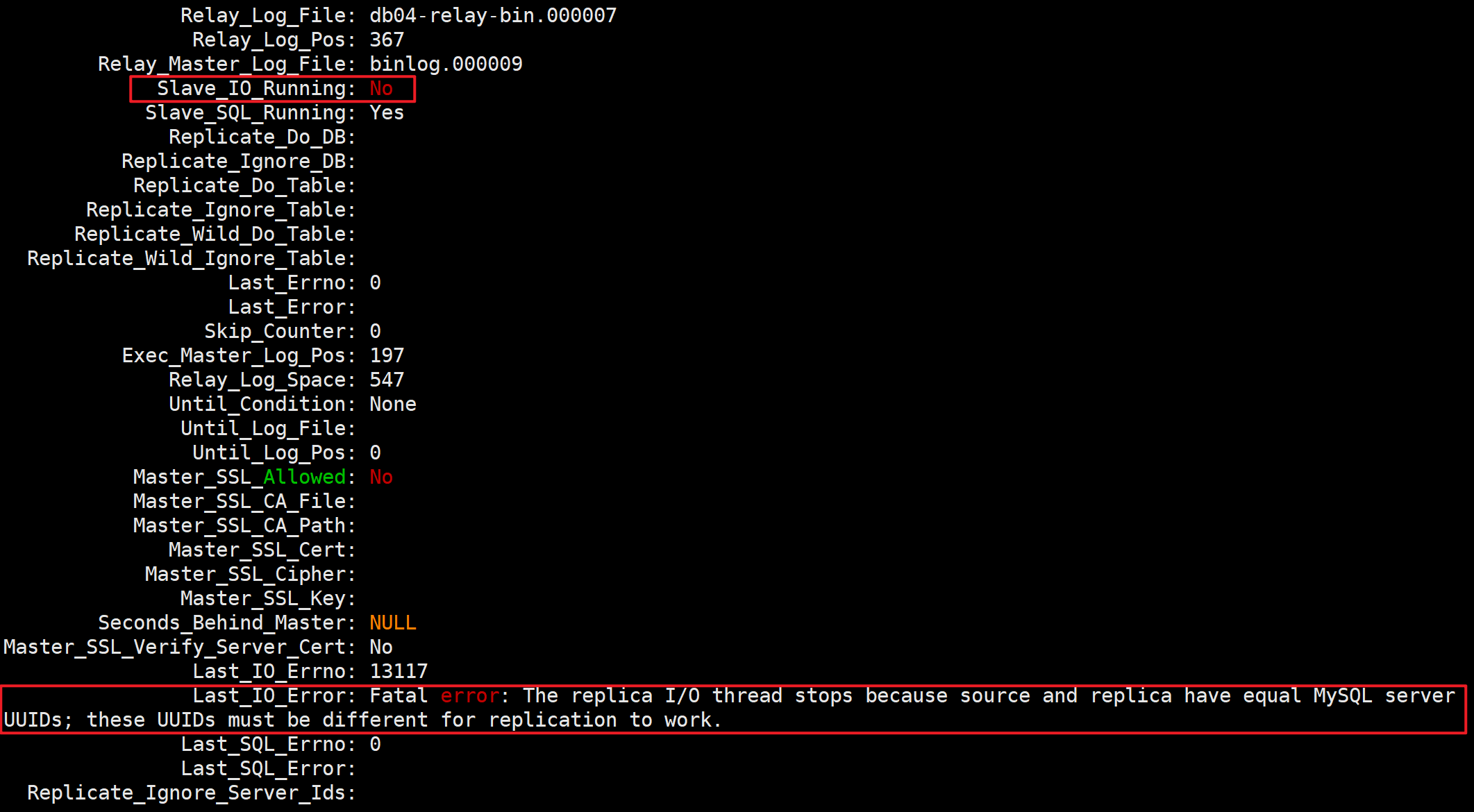
- 报错信息
Last_IO_Errno: 13117
Last_IO_Error: Fatal error: The replica I/O thread stops because source and replica have equal MySQL server UUIDs; these UUIDs must be different for replication to work.
- 查看主从uuid信息
slave01 [(none)]>select @@server_uuid;
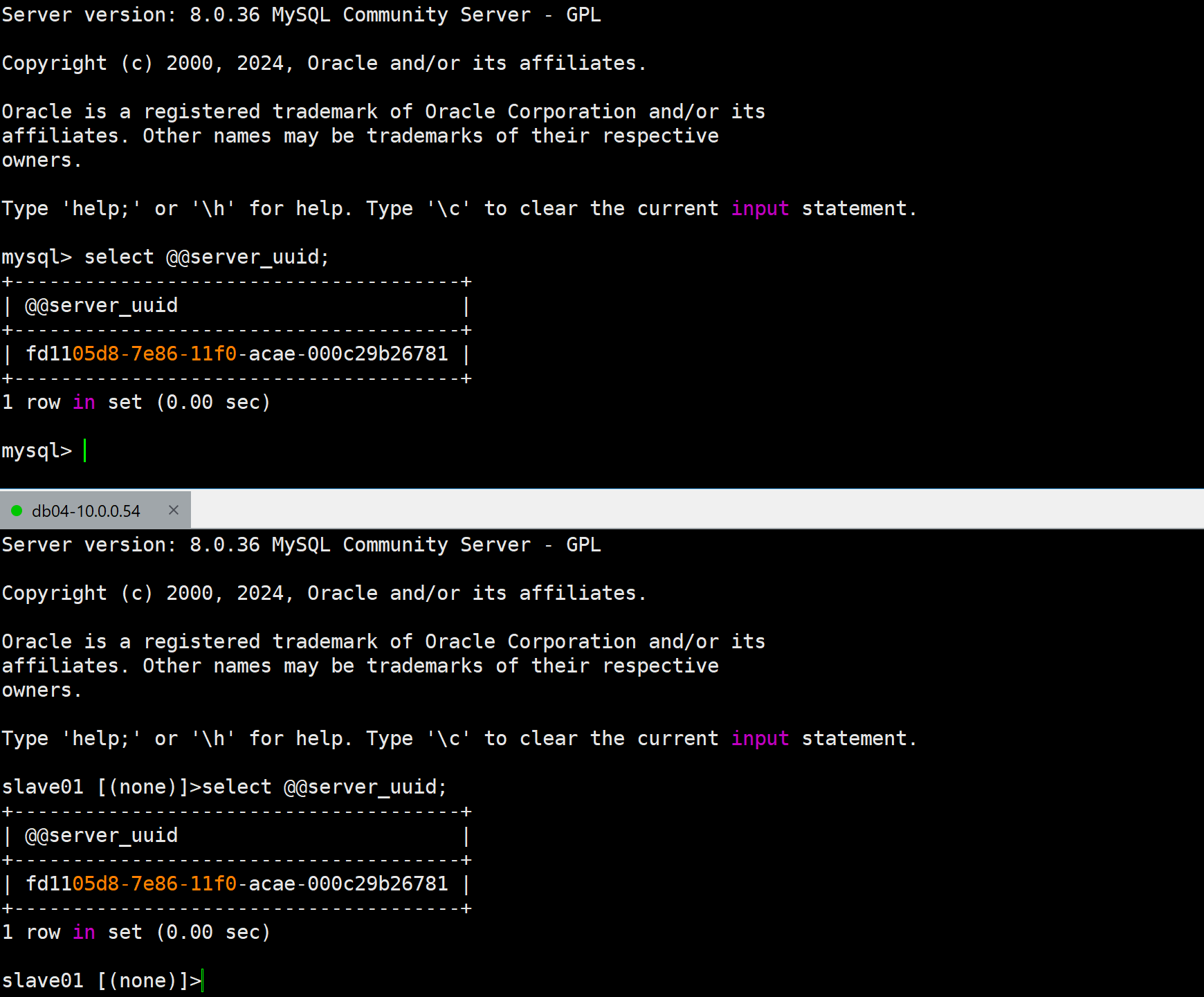
⚠️主库和从库server_uuid冲突了
主从配置的标识信息重复冲突解决方法
1.在从库上停止mysql服务
/etc/init.d/mysqld stop2.在从库上删除auto.cnf文件
rm -f /data/3306/data/auto.cnf3.在从库上启动mysql服务
/etc/init.d/mysqld start4.登录从库
mysql -uroot -pzhu5.查看从库的uuid
slave01 [(none)]>select @@server_uuid;
⚠️SQL线程出现故障Slave_SQL_Running: no
- 1️⃣SQL线程无法加载relaylog文件,可能relaylog文件被清理删除
- 2️⃣SQL线程可以加载relaylog文件,加载relaylog文件事务信息后,做执行时产生了异常问题
SQL线程主要用于回放执行relay log日志信息,即执行相关数据同步SQL语句信息;
可能导致异常原因:(从库数据或设置异常导致)
- 创建的对象已经存在,涉及到的对象可能有库、表、用户、索引…;
- 插入(insert)的操作对象有异常、修改(update alter)的操作对象有异常、删除(delete drop)的操作对象有异常;
- 由于数据库设置的约束信息,与执行的SQL语句产生冲突问题;
- 在数据库不同版本之间进行数据同步时,可能出现配置冲突问题(比如:5.6可以识别时间为0字段,5.7不能识别时间为0字段)
可能造成异常情况:
- 在进行主从配置时,指定的位置点出现错误(change master to);
- 在进行主从配置前,从库被写入相应的数据信息了,与主库同步数据产生冲突(误连接从库进行操作了);
- 在从库工作繁忙状态时,从库宕机了,业务恢复后可能出现异步同步数据错乱(主库操作创建表操作没同步,同步了插入表操作);
- 在进行主从切换时(假设进行的是手工切换),没有正确操作锁定源主库和binlog日志信息;导致切换前主库数据没有完全同步,切换后从库数据(原主库)比主库数据(原从库)信息更全;
- 在应用数据库双主结构时,没有正确使用(经常导致相互同步数据,主键或唯一键冲突)若企业创建必须使用双主架构,实现双写机制,可以使用全局序列机制,实现主键或唯一键的统一分配;不要使用行格式,建议使用语句格式进行同步;根据业务来划分双主,不同业务写入不同的主库不同数据库;
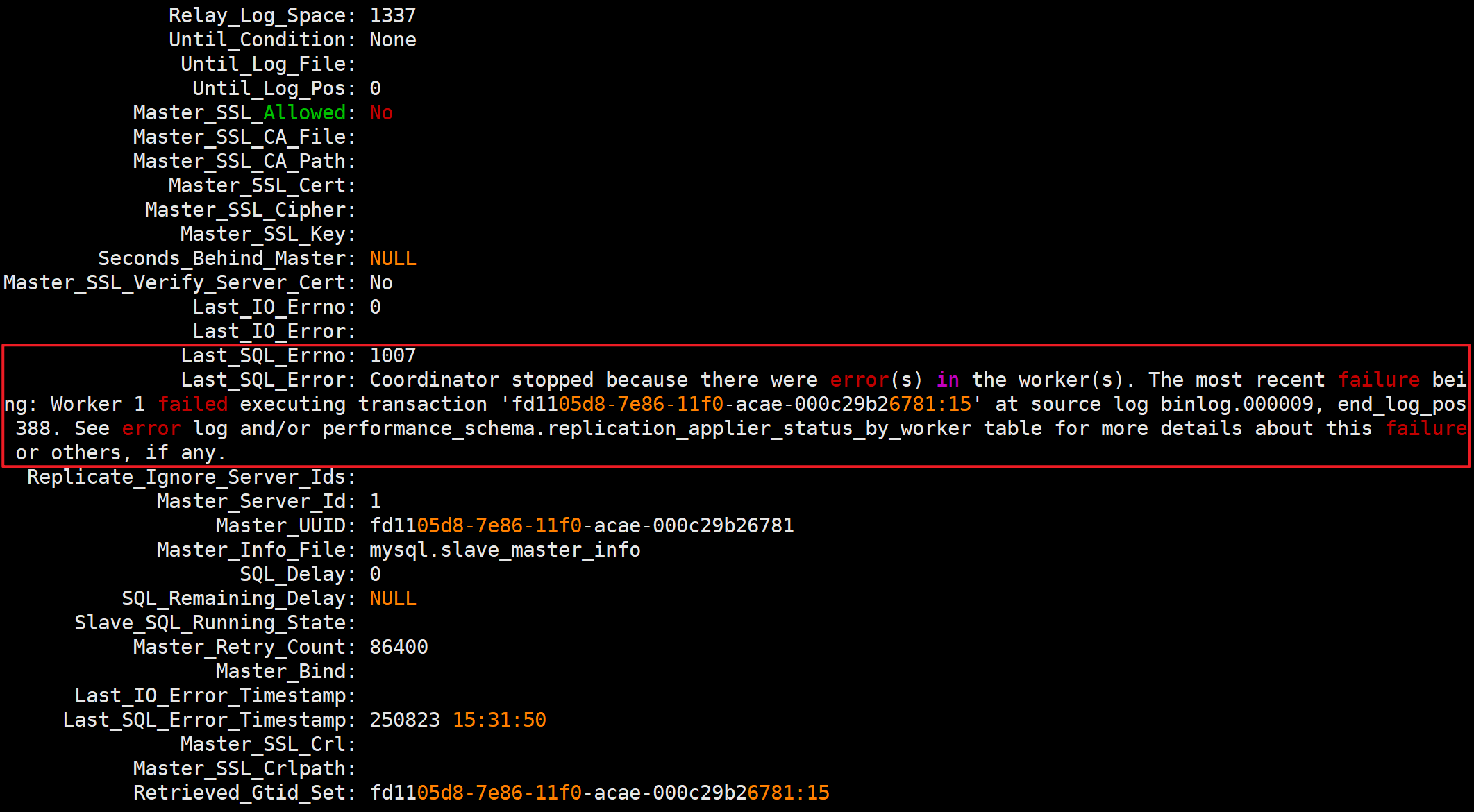
SQL线程执行事务时失败了
- 报错信息
Last_SQL_Errno: 1007
Last_SQL_Error: Coordinator stopped because there were error(s) in the worker(s). The most recent failure being: Worker 1 failed executing transaction 'fd1105d8-7e86-11f0-acae-000c29b26781:15' at source log binlog.000009, end_log_pos 388. See error log and/or performance_schema.replication_applier_status_by_worker table for more details about this failure or others, if any.协调器停止了,因为工作进程出现了错误。最近一次失败的情况是:工作进程 1 在源日志 binlog.000009 中执行事务 'fd1105d8-7e86-11f0-acae-000c29b26781:15' 时失败,结束日志位置为 388。有关此次失败或其他失败的更多详细信息,请查看错误日志和/或 performance_schema.replication_applier_status_by_worker 表。
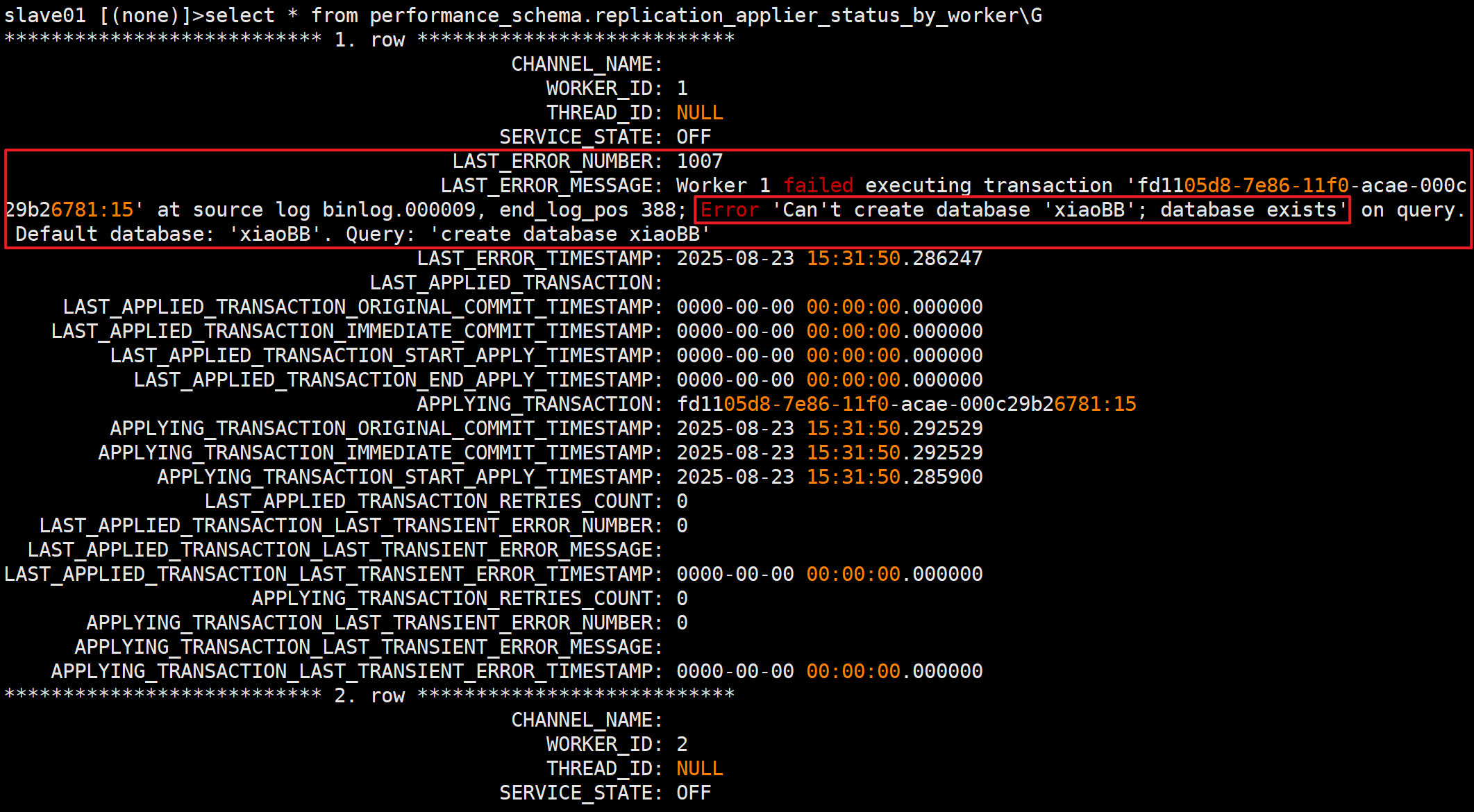
- 查看详细报错信息
select * from performance_schema.replication_applier_status_by_worker\G
显示每个复制工作线程的详细状态信息,帮助监控和诊断主从复制的运行情况。LAST_ERROR_NUMBER: 1007
LAST_ERROR_MESSAGE: Worker 1 failed executing transaction 'fd1105d8-7e86-11f0-acae-000c29b26781:15' at source log binlog.000009, end_log_pos 388; Error 'Can't create database 'xiaoBB'; database exists' on query. Default database: 'xiaoBB'. Query: 'create database xiaoBB'在源日志 binlog.000009 中执行事务 'fd1105d8-7e86-11f0-acae-000c29b26781:15' 时失败,结束位置为 388;在查询时出错 '无法创建数据库 'xiaoBB';数据库已存在';
避免主从冲突方案
1.修改/etc/my.cnf配置文件
#限制普通用户修改数据库
read-only=1
#限制管理员root用户修改数据库
super-read-only=12.重启数据库服务
/etc/init.d/mysqld restart
产生主从冲突如何处理
- 将从库冲突的数据信息删除
slave01 [(none)]>drop database xiaoBB;
- 在从库上做忽略冲突错误
1.在从库上获取错误编码
Last_SQL_Errno: 10072.修改配置文件
vim /etc/my.cnf
slave-skip-errors=10073.重启数据库服务
/etc/init.d/mysqld restart
🌟基于GTID实现主从同步
GTID(global transaction id)是对于一个已提交事务的唯一编号,并且是一个全局唯一编号(主从复制过程)是数据库5.6版本开始的一个功能新特性
- 解决了主从同步需要获取位置点的问题
- 解决了主从同步位置点更新异常的问题
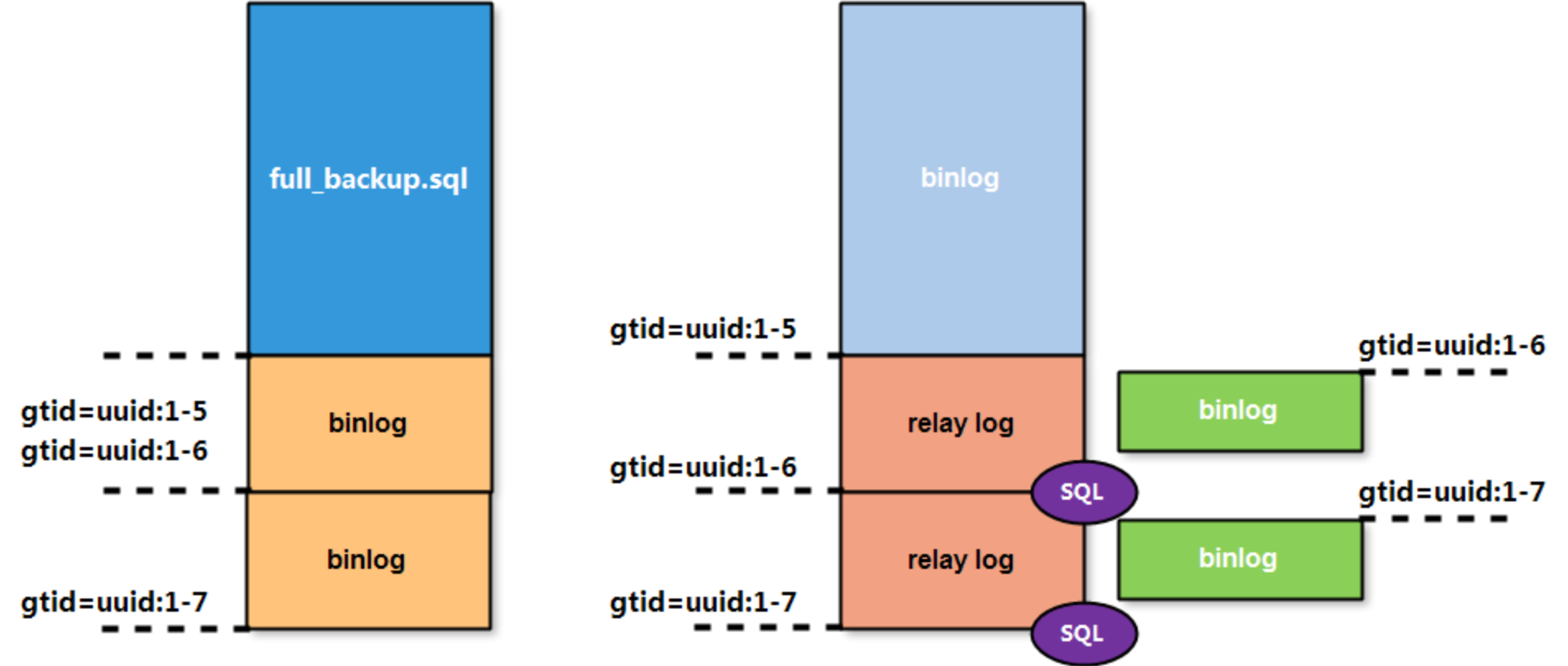
📌实现原理机制
- 1️⃣master节点在更新数据的时候,会在事务前产生GTID信息,一同记录到binlog日志中;
- 2️⃣slave节点的io线程将主库推送的binlog写入到本地relay log中;
- 3️⃣SQL线程从relay log中读取GTID,设置gtid_next的值为该gtid,对比slave端的binlog是否有记录;
- 4️⃣如果有记录的话,说明该GTID的事务已经运行,slave会忽略;
- 5️⃣如果没有记录的话,slave就会执行该GTID对应的事务,并记录到binlog中。
🛠️GTID实战
准备主从实例主机
| 主机 | ip |
|---|---|
| db03(主) | 10.0.0.53 |
| db04(从) | 10.0.0.54 |
需要在主从主机配置GTID功能
1.修改/etc/配置文件(主和从都要配置)
vim /etc/my.cnf
#开启GTID功能
gtid-mode=on
enforce-gtid-consistency=true# 让从库也需要记录binlog日志功能
log-slave-updates=12.重启数据库服务
/etc/init.d/mysqld restart
在主库上进行数据备份
1.备份数据库
mysqldump -uroot -pzhu -A --single-transaction --set-gtid-purged=ON --source-data >/backup/all.sql
--single-transaction: 在备份期间可以不影响数据库业务,不加参数会锁库
--source-data: 在备份文件中记录备份后的binlog日志和位置点信息,便于主从同步
--set-gtid-purged=OFF ,可以将备份的数据信息用于修复数据
--set-gtid-purged=ON 只能将备份的数据信息用于主从同步(默认)2.将备份的sql文件拷贝到从节点
scp -rp /backup/all.sql 10.0.0.54:/tmp/all.sql

⚠️当主从数据库服务开启GTID功能后,进行主库数据备份时会有警告提示,可以忽略
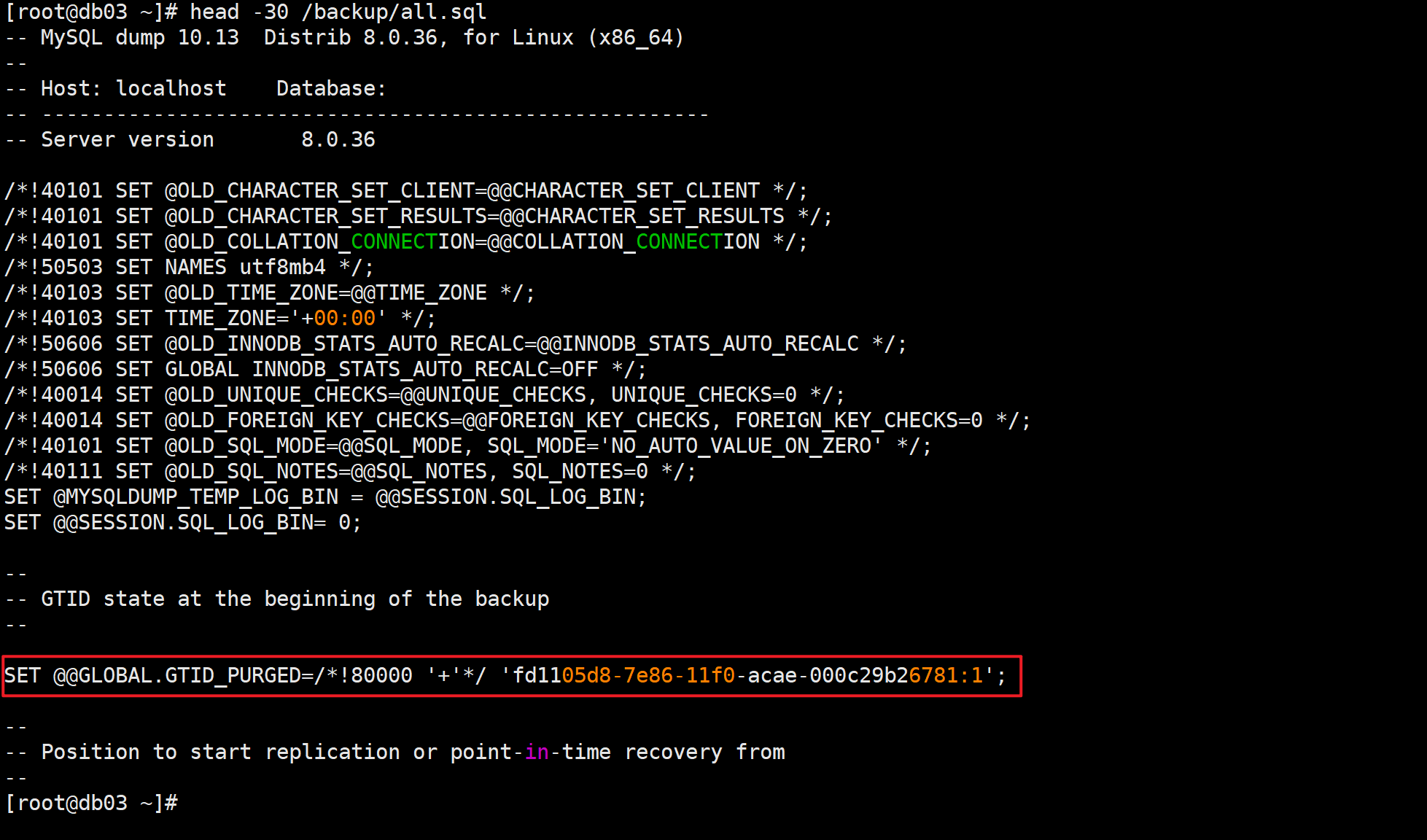
📌备份数据库文件中存放了gtid全局事务标识符
表示备份文件中,或数据库服务中已经做过了什么事务操作
一旦GTID功能开启,完成事务操作时,会具有幂等特性(做过的事情不会重复操作)
在从库恢复备份数据
1.登录数据库
mysql -uroot -pzhu2.恢复备份数据
source /tmp/all.sql
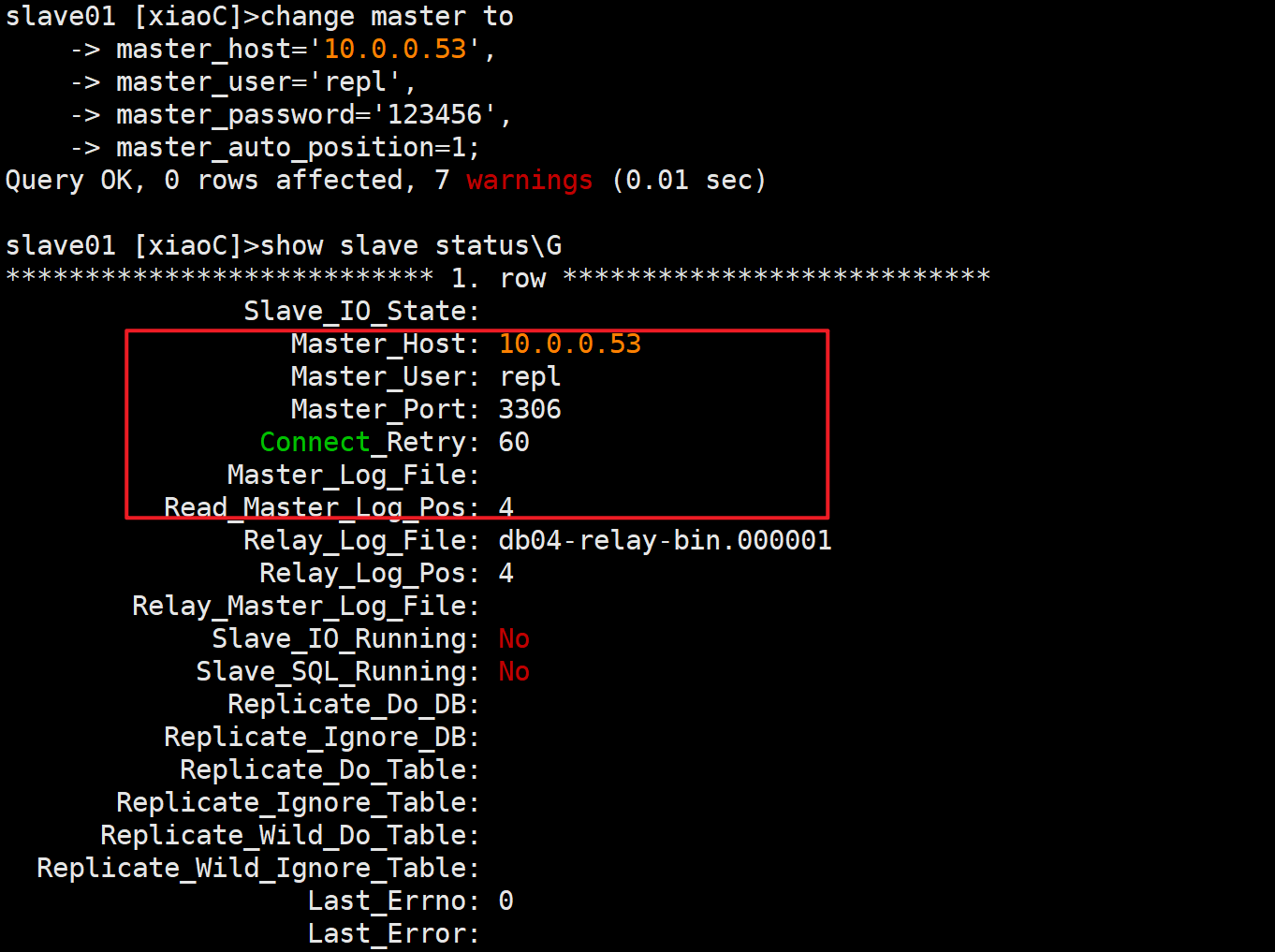
在从库上做主从配置
change master to
master_host='10.0.0.53',
master_user='repl',
master_password='123456',
master_auto_position=1;
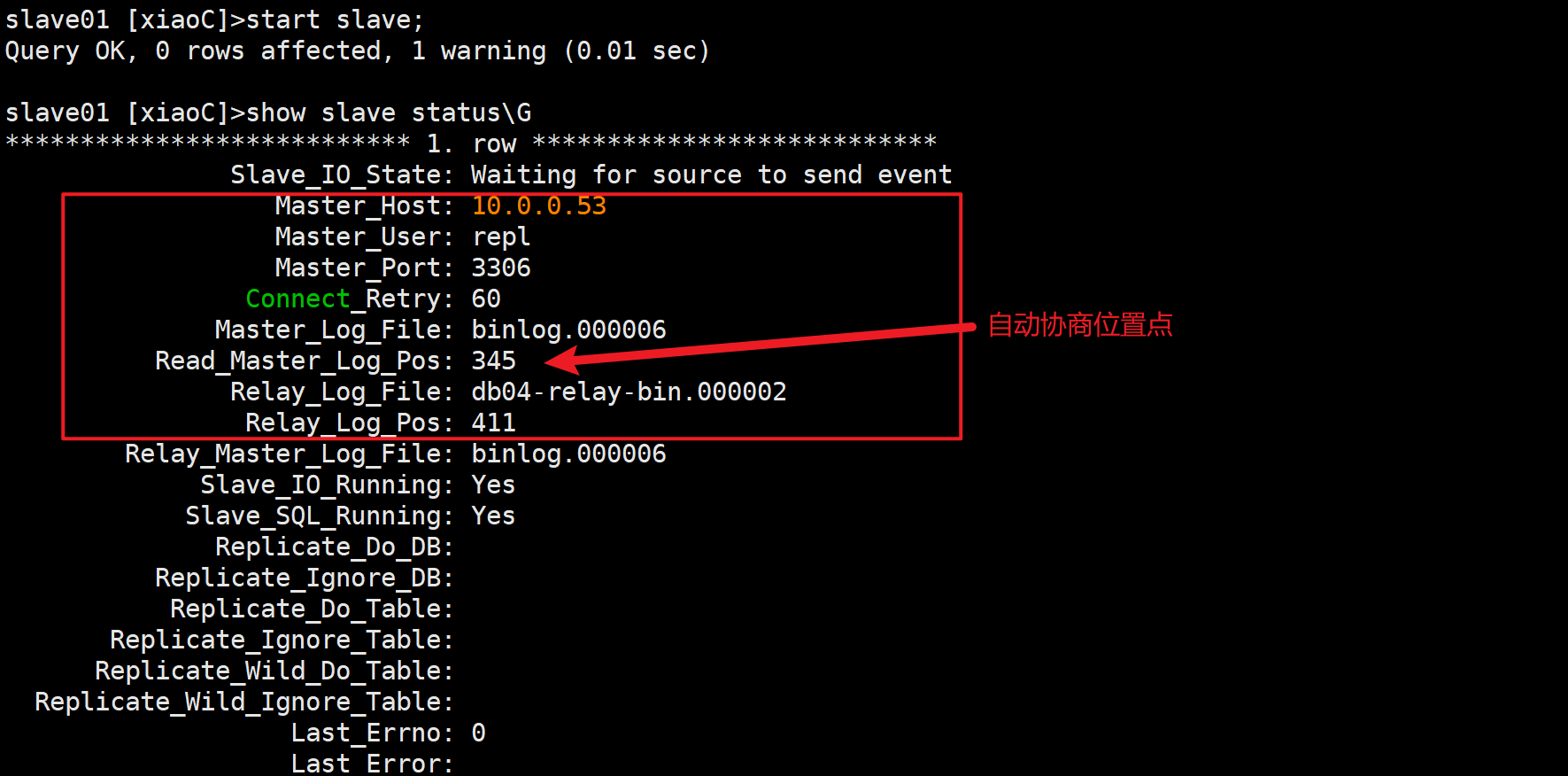
启动主从同步
start slave;
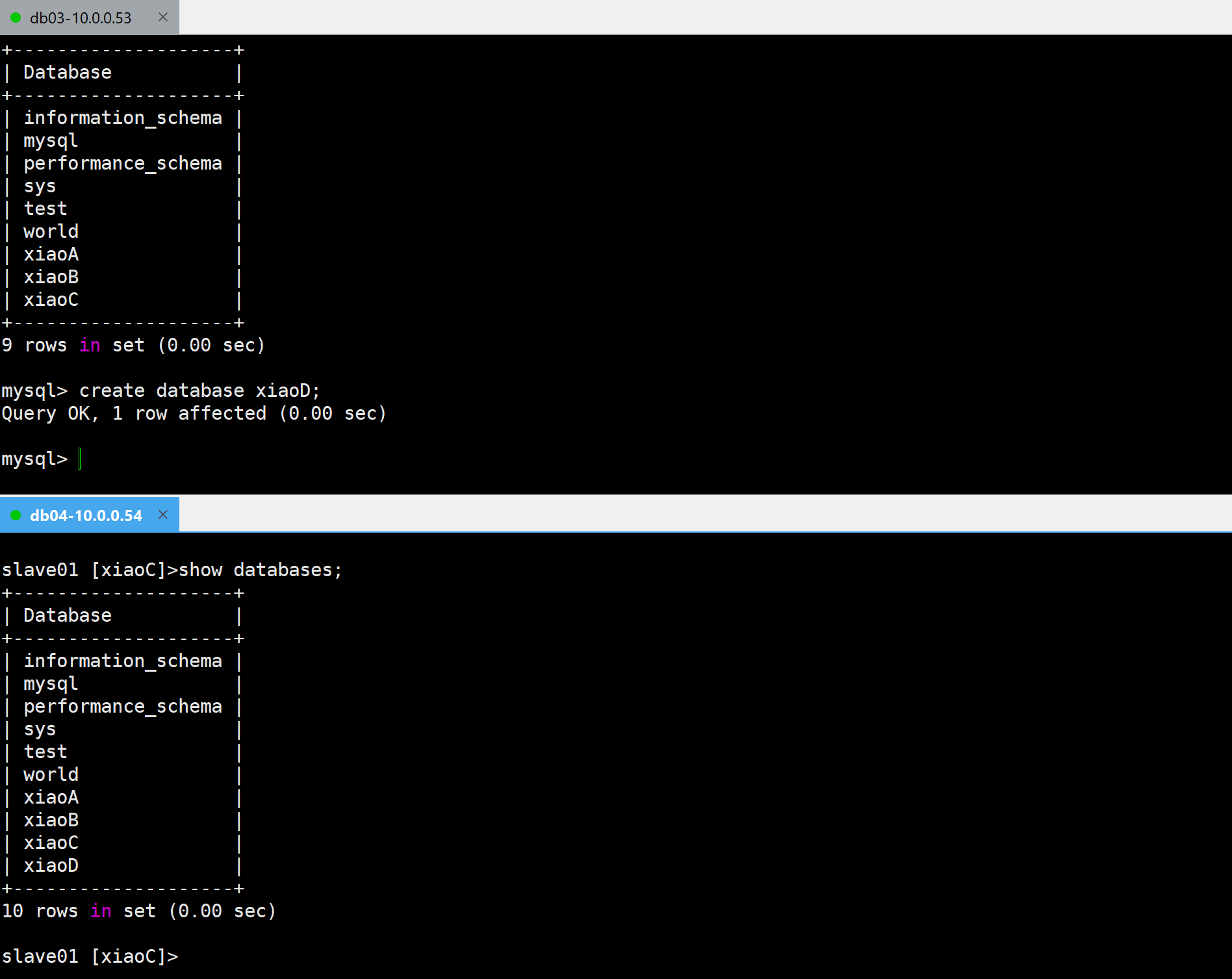
测试
✅在主数据库上创建xiaoD数据库,在从数据库上查看数据库信息
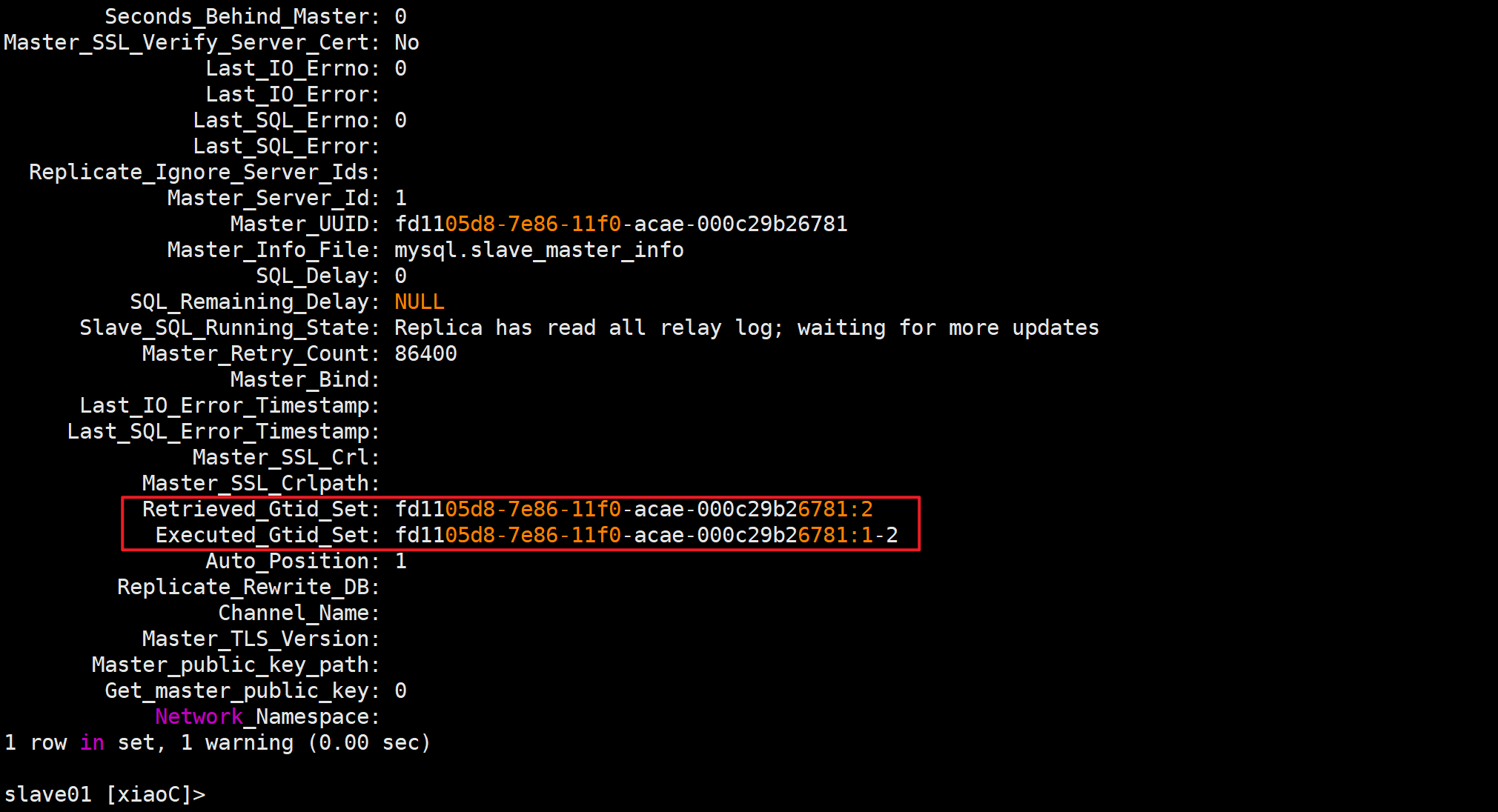
🌟实现主从延迟同步数据
🧩主从延迟同步原理
利用控制SQL线程,让SQL线程在指定时间后,进行relay log文件事务信息的回放
🛠️主从延迟同步实践
准备主从实例主机
| 主机 | ip |
|---|---|
| db03(主) | 10.0.0.53 |
| db04(从) | 10.0.0.54 |
在主库做好数据备份
1.备份数据库
mysqldump -uroot -pzhu -A --single-transaction --set-gtid-purged=ON --source-data >/backup/all.sql
--single-transaction: 在备份期间可以不影响数据库业务,不加参数会锁库
--source-data: 在备份文件中记录备份后的binlog日志和位置点信息,便于主从同步
--set-gtid-purged=ON 只能将备份的数据信息用于主从同步2.将备份的sql文件拷贝到从节点
scp -rp /backup/all.sql 10.0.0.54:/tmp/all.sql
在从库进行数据恢复
1.登录数据库
mysql -uroot -pzhu2.恢复备份数据
source /tmp/all.sql
确认正常主从是否可以建立
change master to
master_host='10.0.0.53',
master_user='repl',
master_password='123456',
master_auto_position=1;
需要停止主从SQL线程,进行延迟功能配置
1.停止SQL线程
stop slave sql_thread;2.配置延迟同步300s
change master to master_delay=300;3.启动SQL线程
start slave sql_thread;
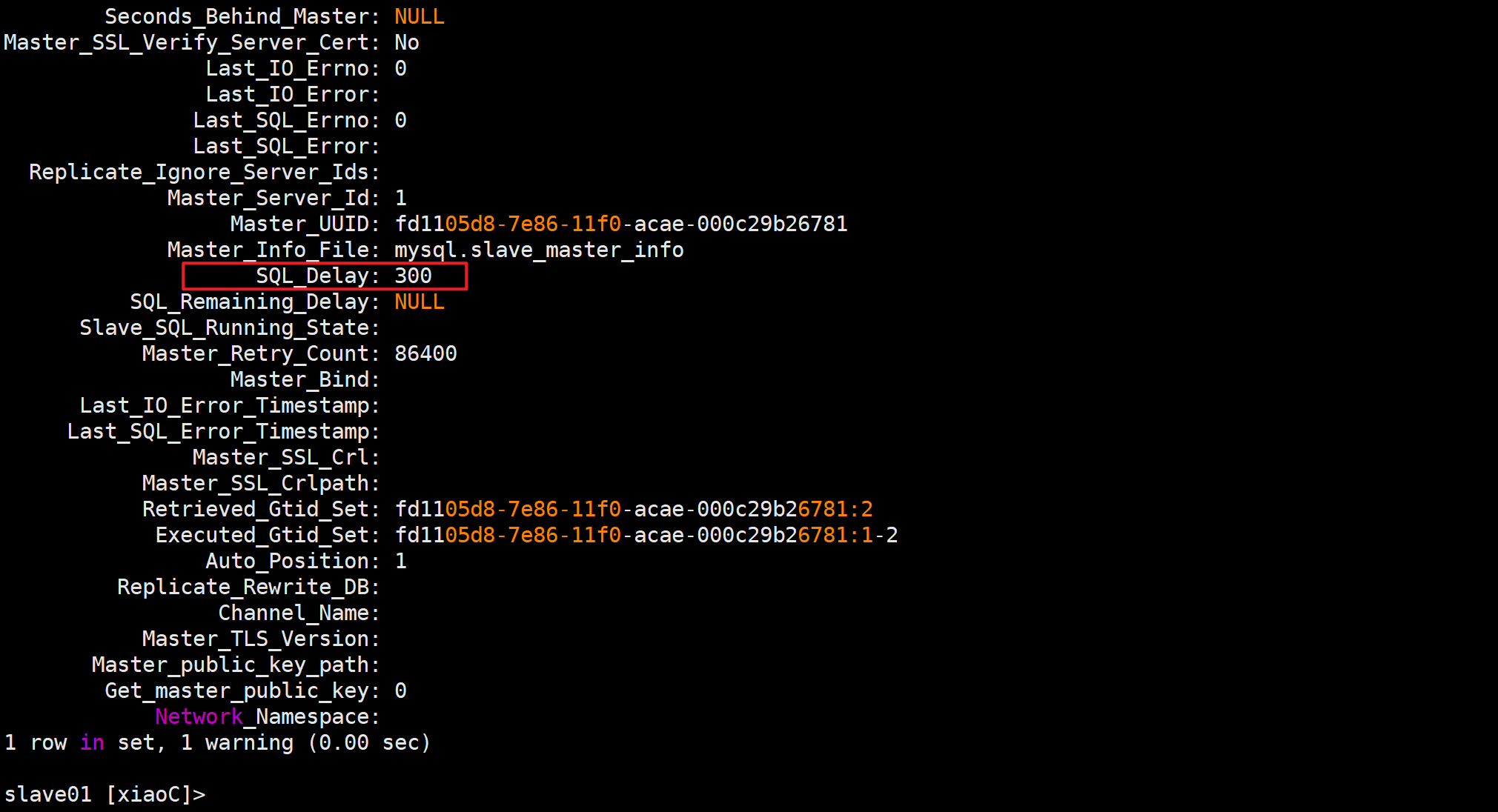
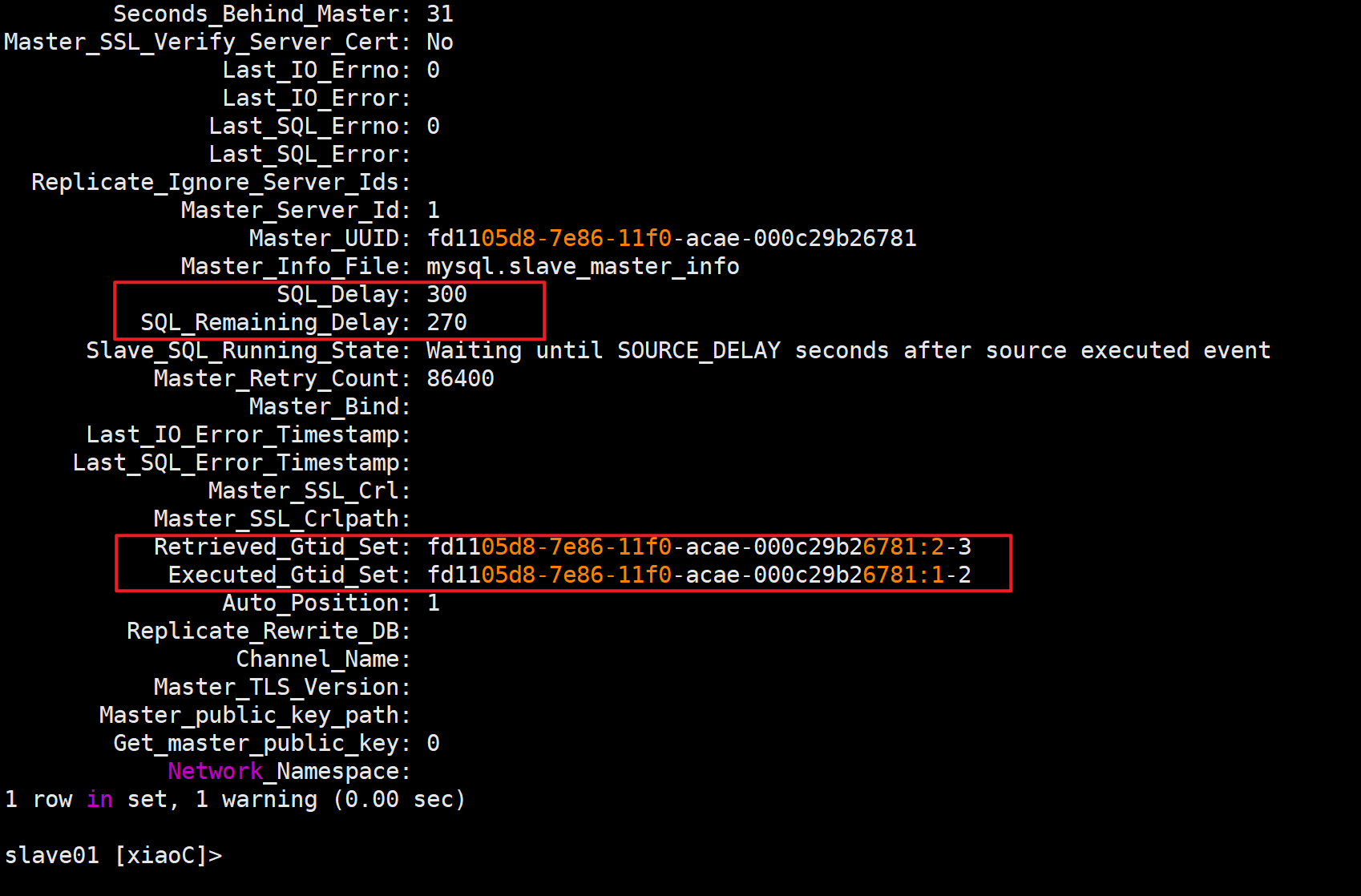
测试
SQL_Delay: 300(延迟时间)
SQL_Remaining_Delay: 270(同步倒计时)
🌟如何利用延迟从库修复数据
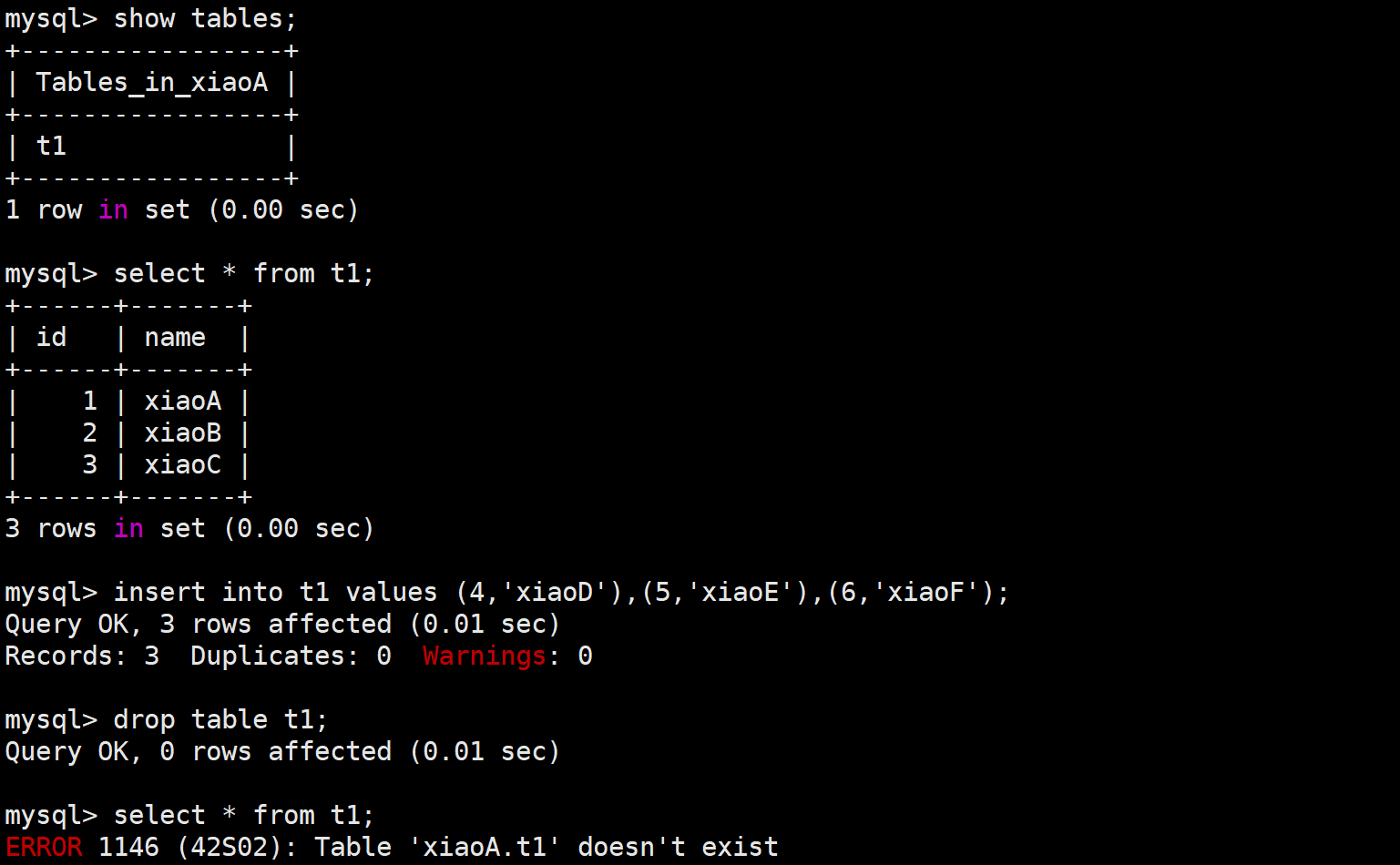
🔍模拟创建测试数据
mysql> use xiaoA;
mysql> insert into t1 values (1,'xiaoA'),(2,'xiaoB'),(3,'xiaoC');
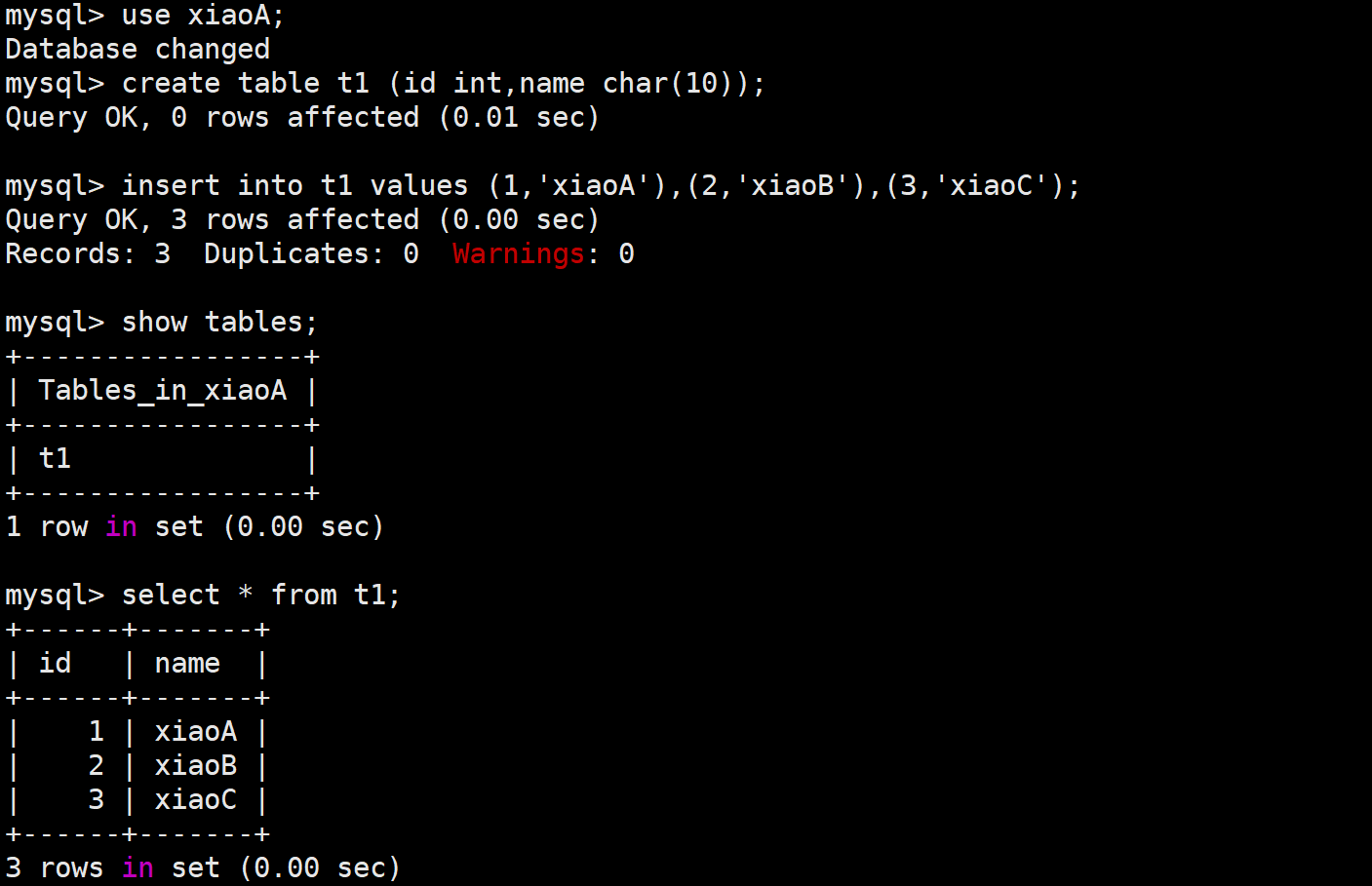
🖥️模拟管理数据库人员做了错误操作
1.正确操作insert
insert into t1 values (4,'xiaoD'),(5,'xiaoE'),(6,'xiaoF');2.错误操作删除了t1表,数据丢失
drop table t1;
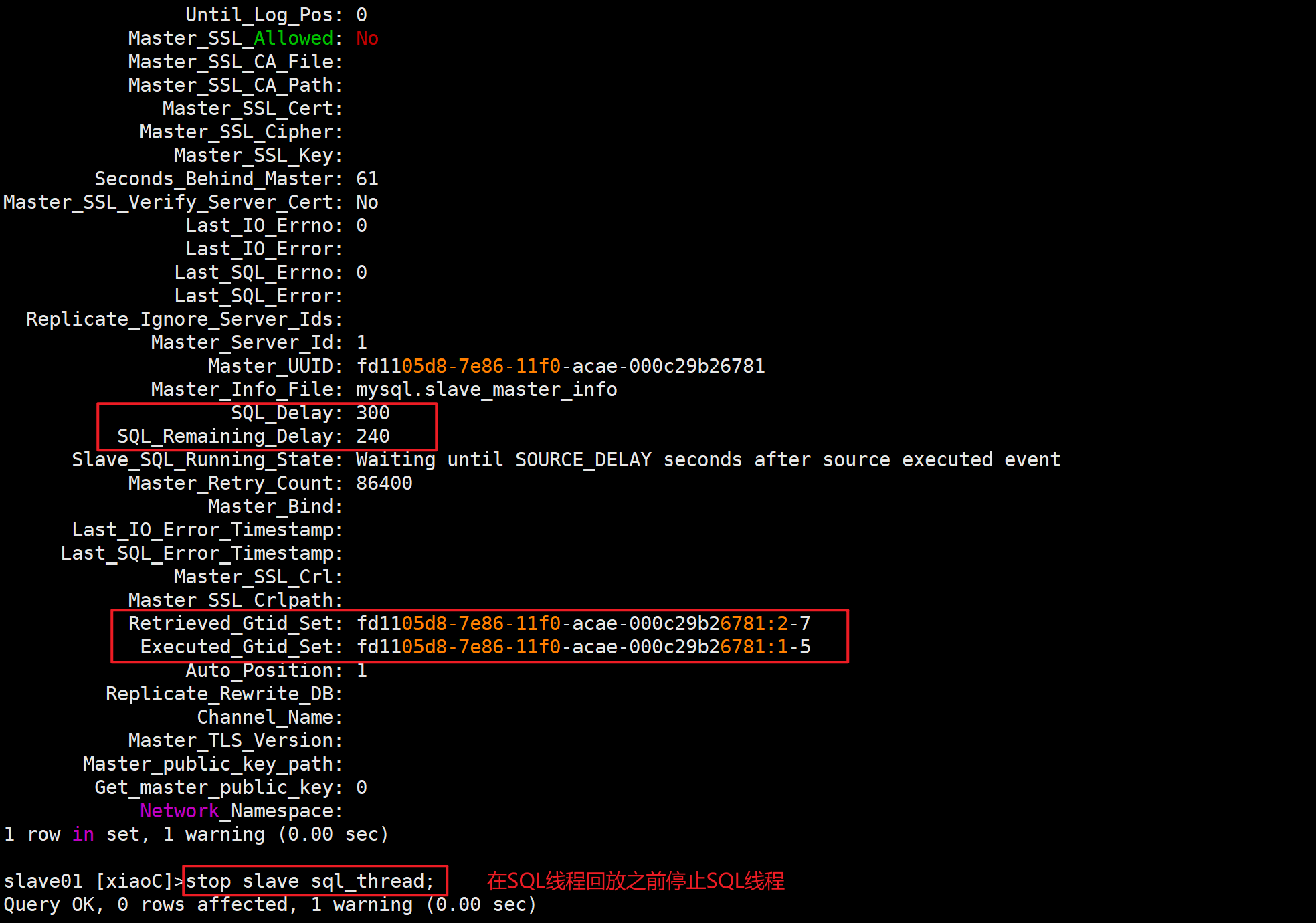
📁利用延迟从库备份数据
停止SQL线程
stop slave sql_thread;
或
stop slave;
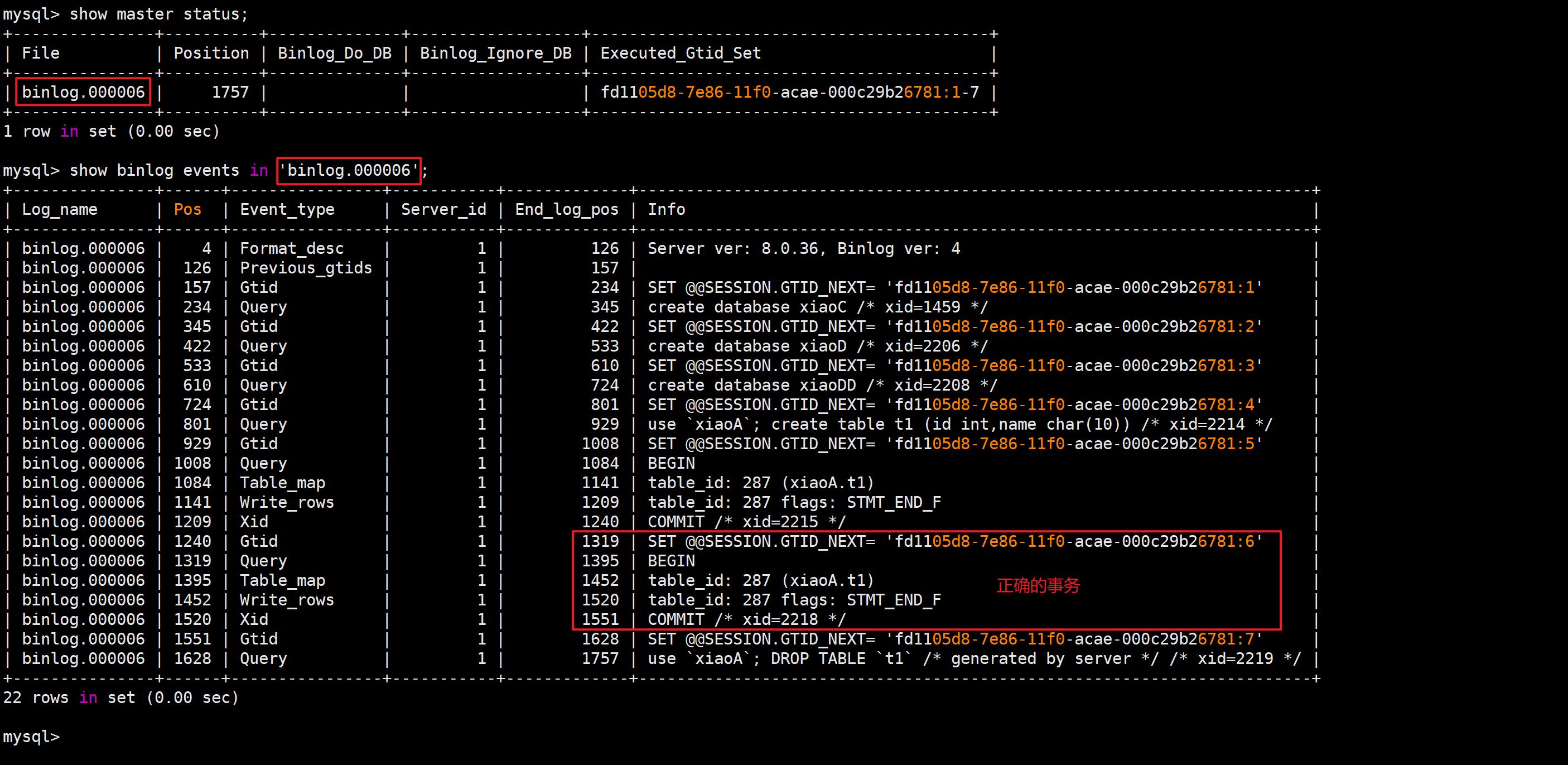
找到正确事务
mysql> show master status;
mysql> show binlog events in 'binlog.000006';
找到错误事务
mysql> show master status;
mysql> show binlog events in 'binlog.000006';
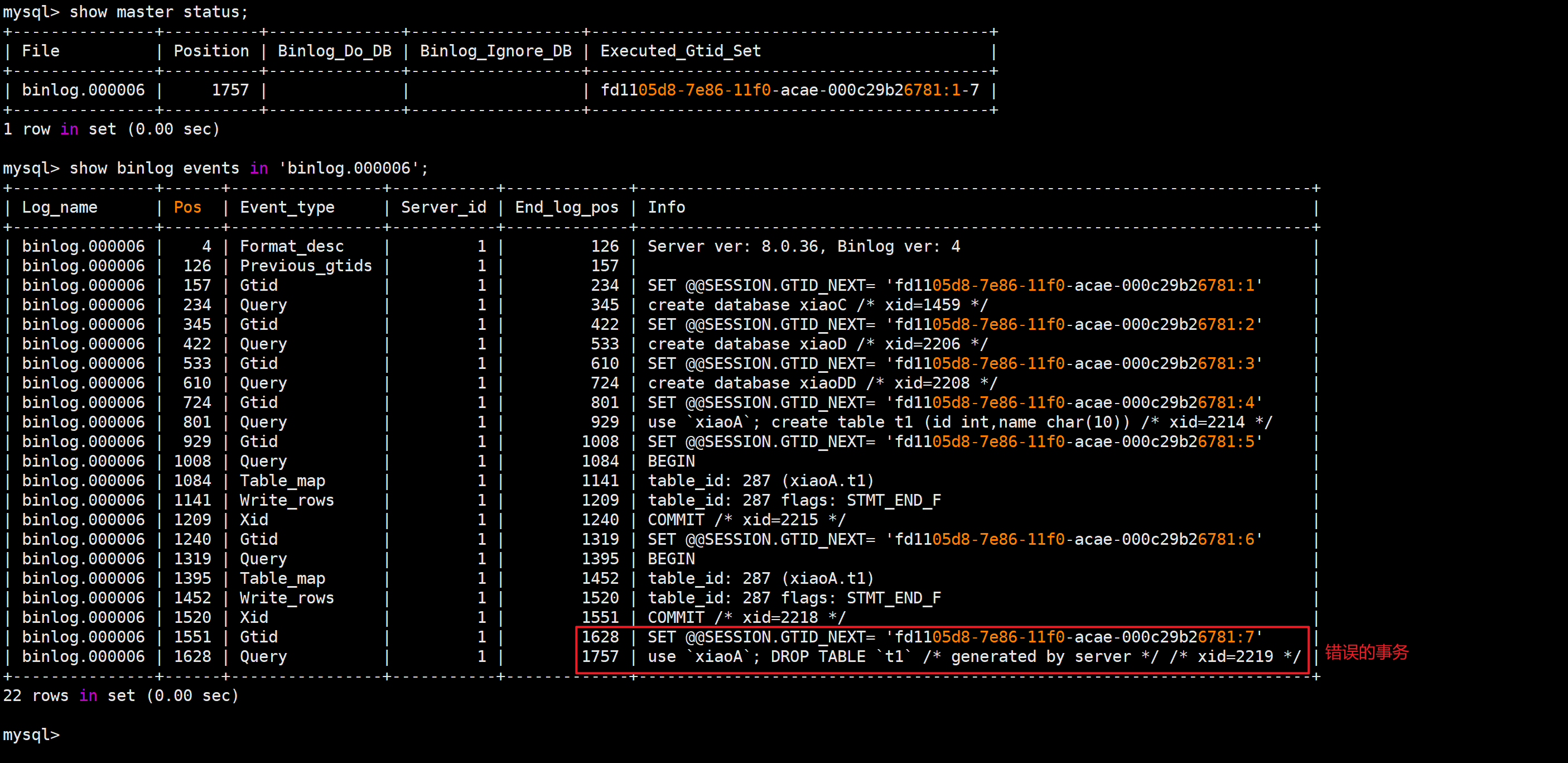
将错误事务之前的事务恢复
slave01 [(none)]>change master to master_delay=0;
slave01 [(none)]>start slave until sql_before_gtids="fd1105d8-7e86-11f0-acae-000c29b26781:7";
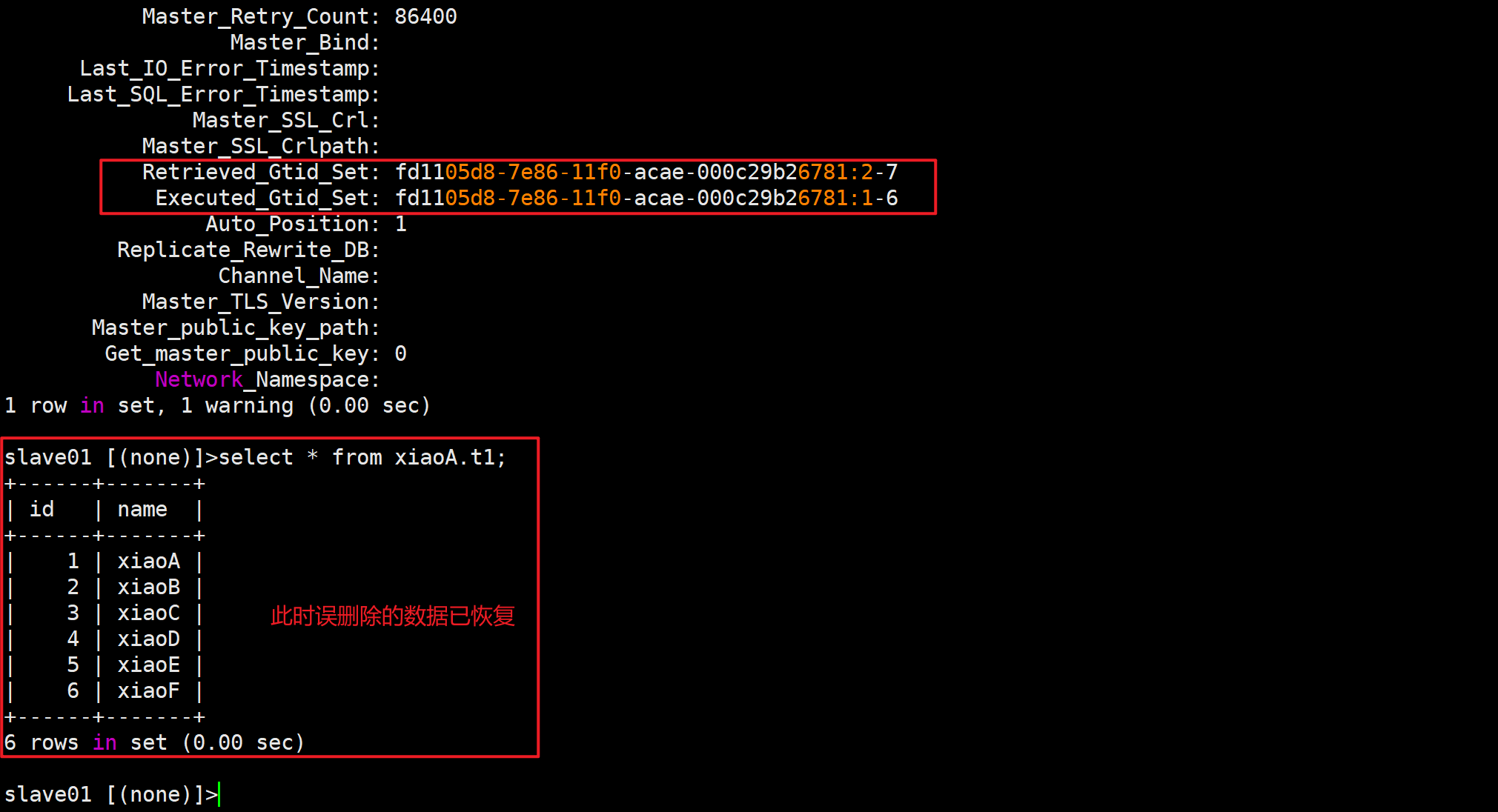
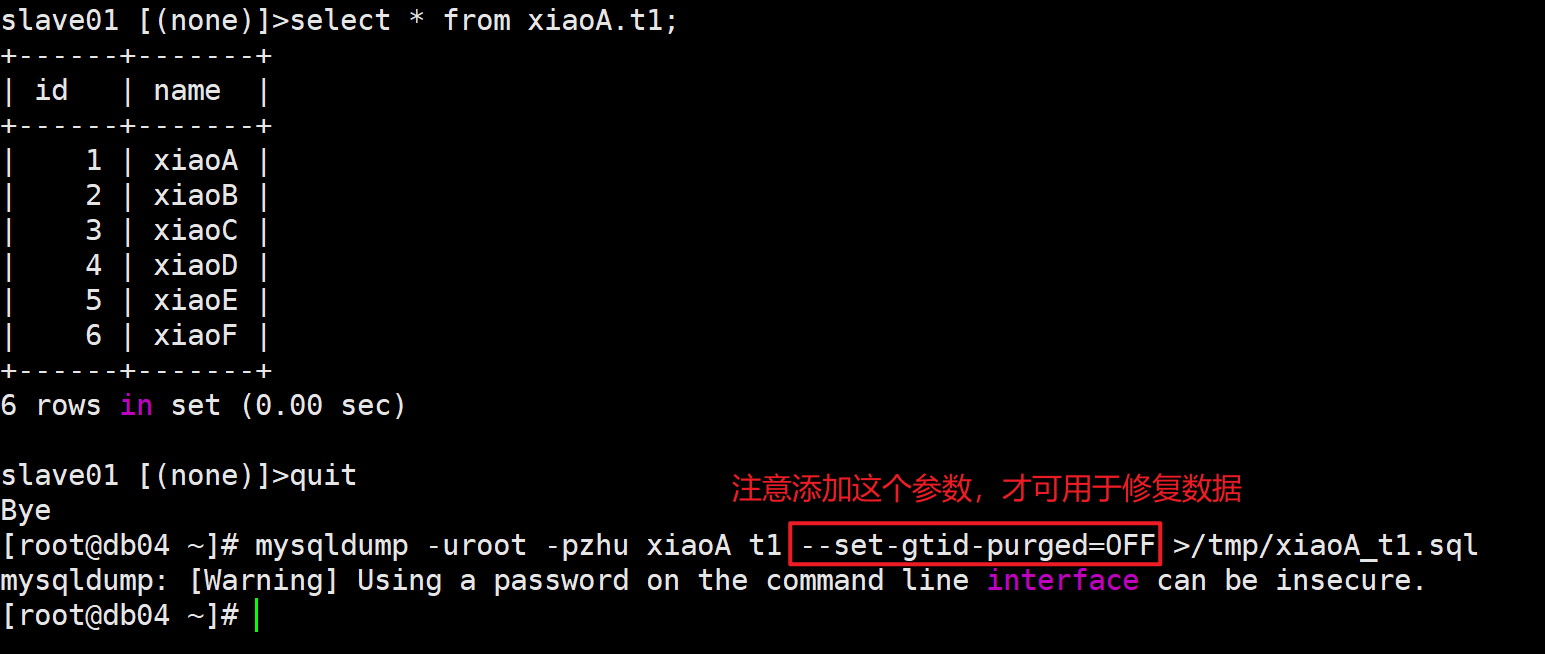
备份误删除数据的表
1.备份t1表
mysqldump -uroot -pzhu xiaoA t1 --set-gtid-purged=OFF >/tmp/xiaoA_t1.sql
--single-transaction: 在备份期间可以不影响数据库业务,不加参数会锁库
--source-data: 在备份文件中记录备份后的binlog日志和位置点信息,便于主从同步
--set-gtid-purged=ON 只能将备份的数据信息用于主从同步2.将从库备份的数据库文件发送到主库
scp -rp /tmp/xiaoA_t1.sql 10.0.0.53:/tmp/
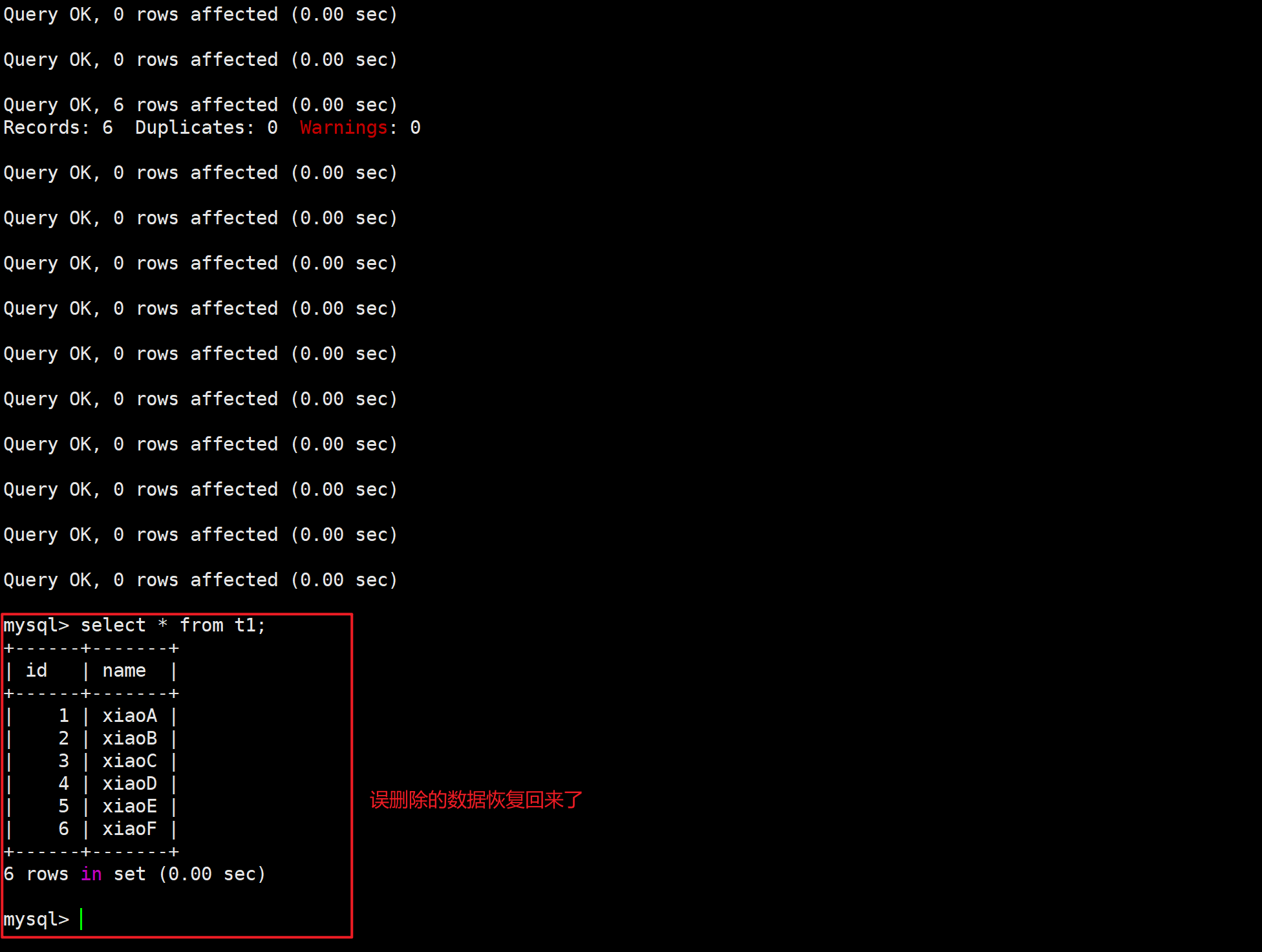
🌏在主库中恢复数据信息
1.登录数据库
mysql -uroot -pzhu2.恢复t1表的数据
source /tmp/xiaoA_t1.sql
🌟数据库主从同步传输数据方式
📌异步复制
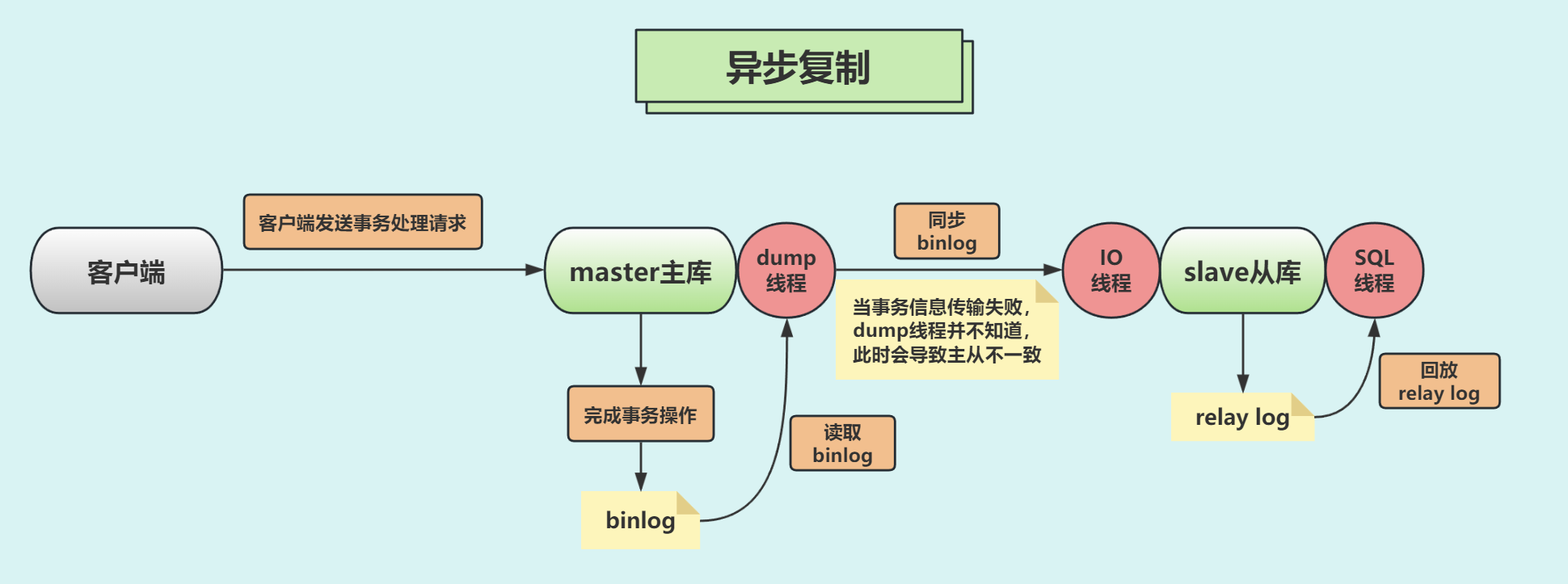
MySQL主从同步数据时,默认使用的复制数据机制就是异步的;
客户端发起数据更新操作请求,主库执行更新操作完成后立即向客户端发起响应,然后再向从库发起数据同步;
主库执行更新操作不需要等待从库的响应,因此主库对于客户端的响应较快,但是数据同步到从库并不是实时同步的;
所以主从延迟情况下,主库发生故障可能会导致主从数据不一致;
简单理解:主库在执行完客户端提交的事务后会立即将结果返给客户端,并不关心从库是否已经接收并处理;
同步痛点:若主库宕机了,此时主上已经提交的事务可能并没有传到从上,此时若从被提升为主,可能导致新主上的数据不完整;
📐半同步复制
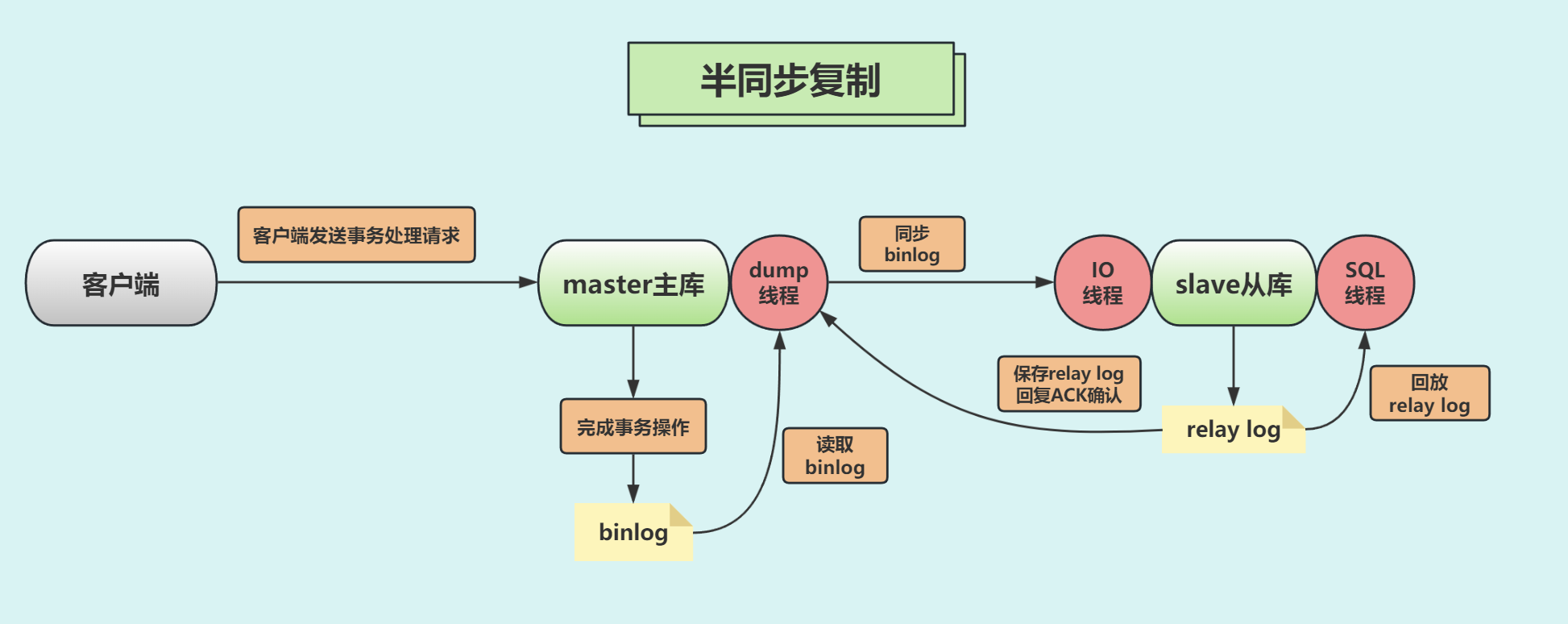
主库提交更新写入二进制日志文件后,等待数据更新写入了从服务器中继日志中,然后才能再继续处理其它请求。
该功能确保至少有1个从库接收完主库传递过来的binlog内容已经写入到自己的relay log里面了,才会通知主库上面的等待线程,该操作完毕。
半同步复制,是最佳安全性与最佳性能之间的一个折中。
MySQL 5.5版本之后引入了半同步复制功能,主从服务器必须安装半同步复制插件,才能开启该复制功能。
如果等待超时,超过rpl_semi_sync_master_timeout参数设置时间(默认值为10000,表示10秒),则关闭半同步复制,并自动转换为异步复制模式。
当master dump线程发送完一个事务的所有事件之后,如果在rpl_semi_sync_master_timeout内,收到了从库的响应,则主从又重新恢复为增强半同步复制。
🍀同步复制
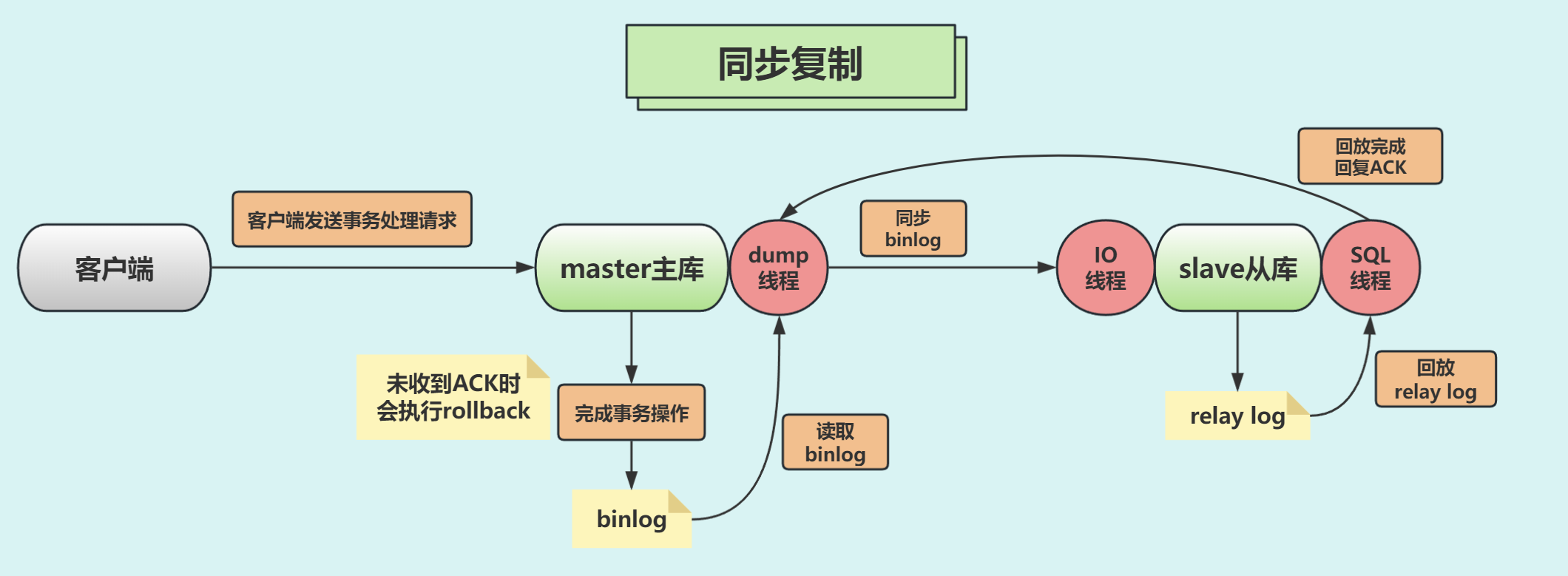
主库将更新写入Binlog日志文件后,需要等待数据更新已经复制到从库中,并且已经在从库执行成功,然后才能返回继续处理其它的请求。同步复制提供了最佳安全性,保证数据安全,数据不会丢失,但对性能有一定的影响。
🌟数据库半同步复制实践过程
🖥️准备主从实例主机
| 主机 | ip |
|---|---|
| db03(主) | 10.0.0.53 |
| db04(从) | 10.0.0.54 |
📁在主库上做数据备份
1.备份数据库
mysqldump -uroot -pzhu -A --single-transaction --set-gtid-purged=ON --source-data >/backup/all.sql
--single-transaction: 在备份期间可以不影响数据库业务,不加参数会锁库
--source-data: 在备份文件中记录备份后的binlog日志和位置点信息,便于主从同步
--set-gtid-purged=ON 只能将备份的数据信息用于主从同步2.将备份的sql文件拷贝到从节点
scp -rp /backup/all.sql 10.0.0.54:/tmp/all.sql
🛠️在从库进行数据恢复
1.登录数据库
mysql -uroot -pzhu2.恢复备份数据
source /tmp/all.sql
📌确认正常主从是否可以建立
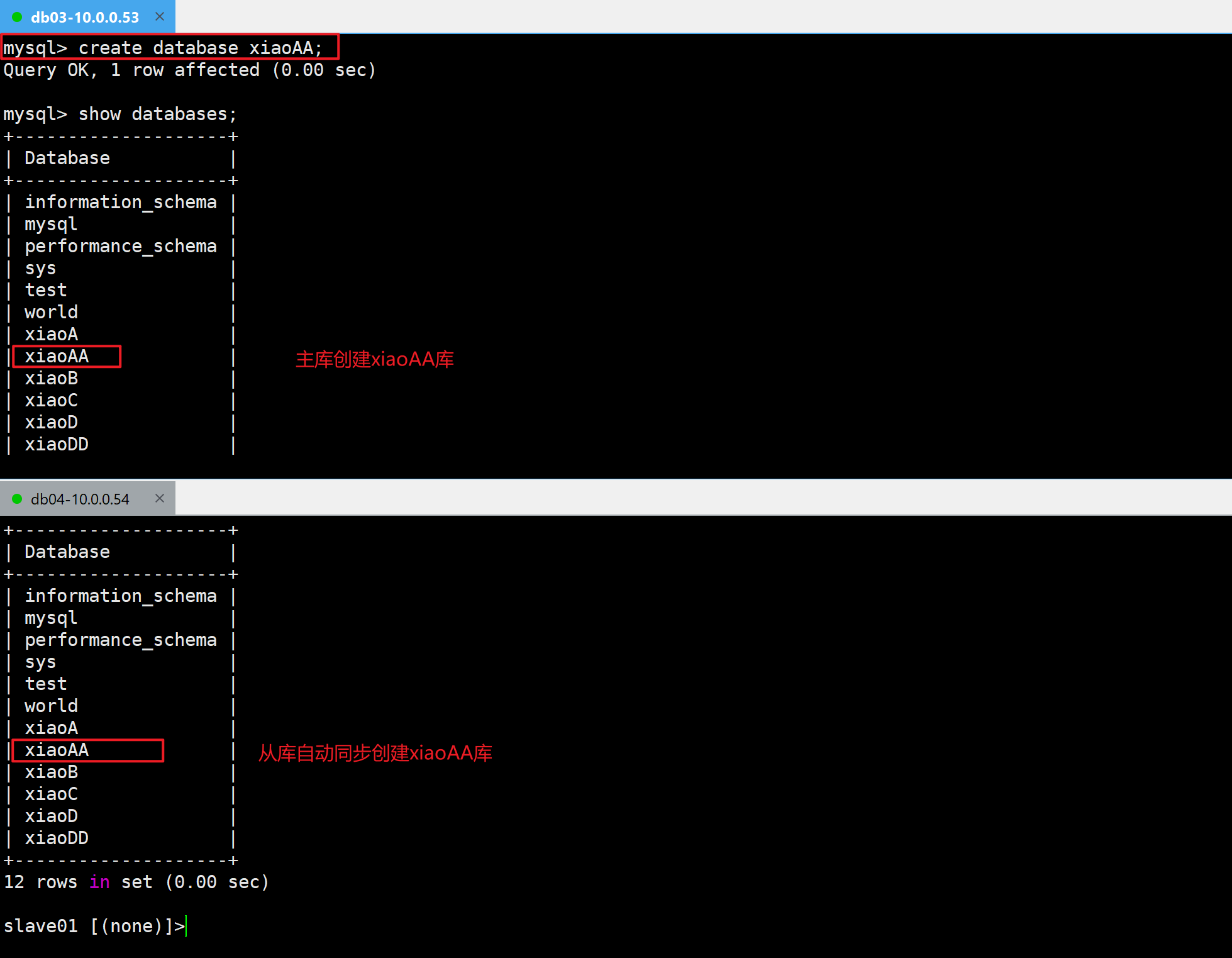
🧩主库和从库中安装半同步插件
1.主库安装半同步插件
mysql> INSTALL PLUGIN rpl_semi_sync_master SONAME 'semisync_master.so';
Query OK, 0 rows affected, 1 warning (0.00 sec)2.从库安装半同步插件
slave01 [(none)]>INSTALL PLUGIN rpl_semi_sync_slave SONAME 'semisync_slave.so';
Query OK, 0 rows affected, 1 warning (0.01 sec)3.查看已经安装的插件
show plugins;
💡激活半同步功能
1.主库激活半同步功能
set global rpl_semi_sync_master_enabled =1;2.从库激活半同步功能
set global rpl_semi_sync_slave_enabled =1;3.重启从库的IO线程
stop slave IO_THREAD;
start slave IO_THREAD;4.查看master等待ACK的超时时间
select @@rpl_semi_sync_master_timeout;
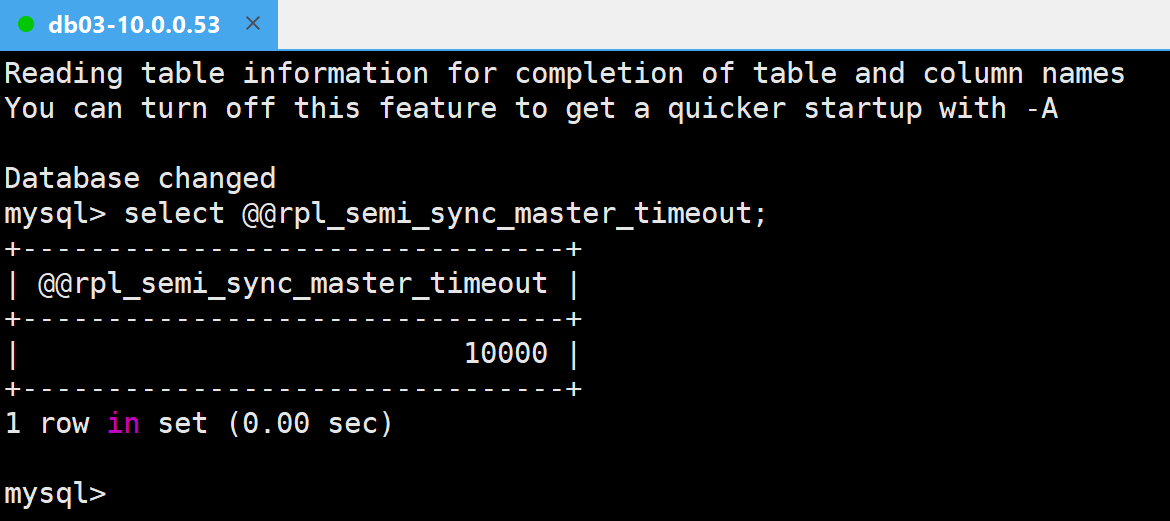
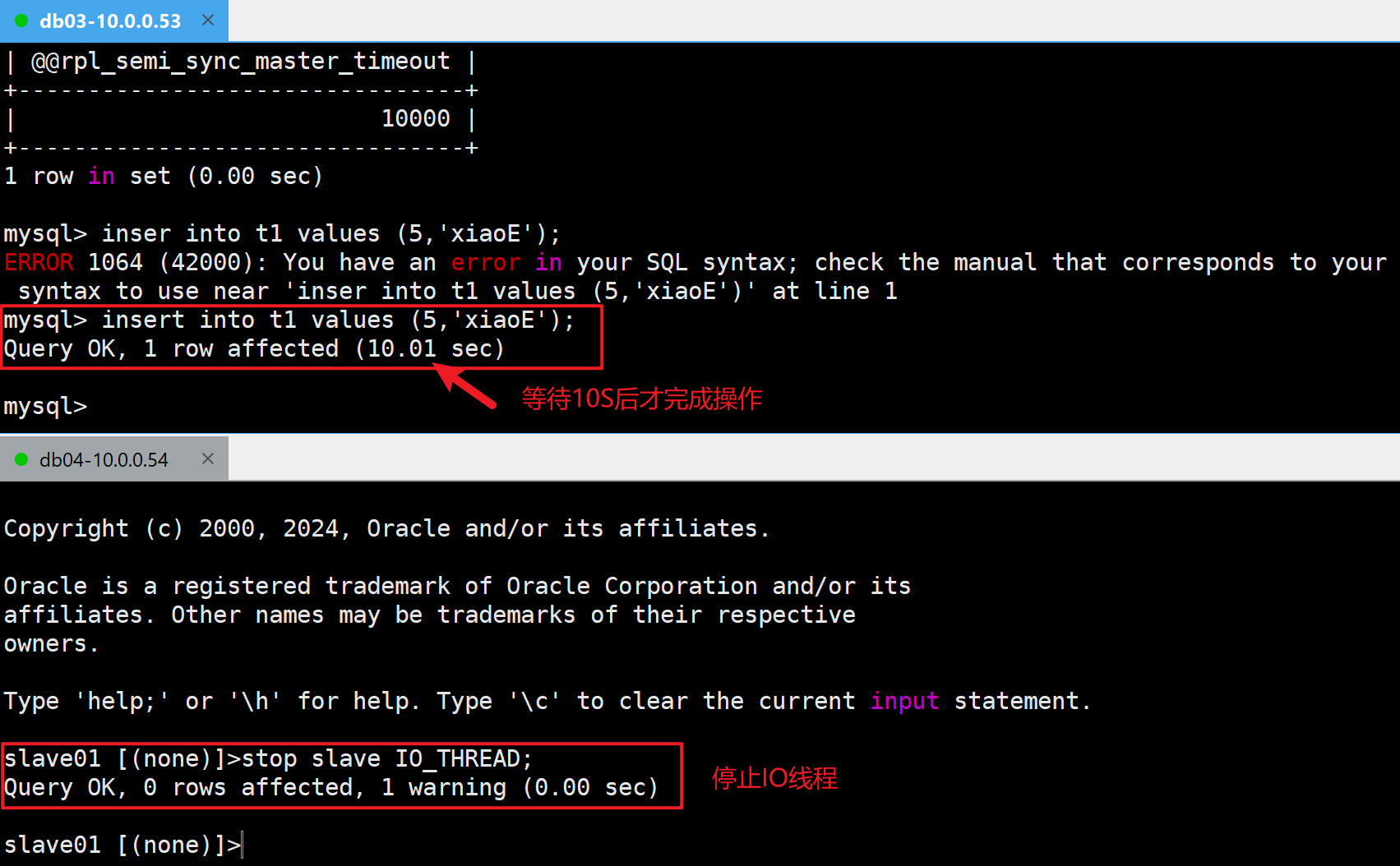
⚠️模拟IO线程异常
1.从库关闭IO线程
stop slave IO_THREAD;2.主库插入数据
insert into t1 values (5,'xiaoE');
🌟数据库服务高可用架构(MHA)
MHA(Master High Availability)目前在MySQL高可用方面是一个相对成熟的解决方案,它由日本DeNA公司youshimaton研发,此人目前就职于Facebook公司,MHA是一套优秀的作为MySQL高可用性环境下故障切换和主从提升的高可用软件。
MySQL进行故障切换过程中,MHA能做到在0~30秒之内自动完成数据库的故障切换操作,并且在进行故障切换过程中;
MHA能在最大程度上保证数据的一致性,以达到真正意义上的高可用。
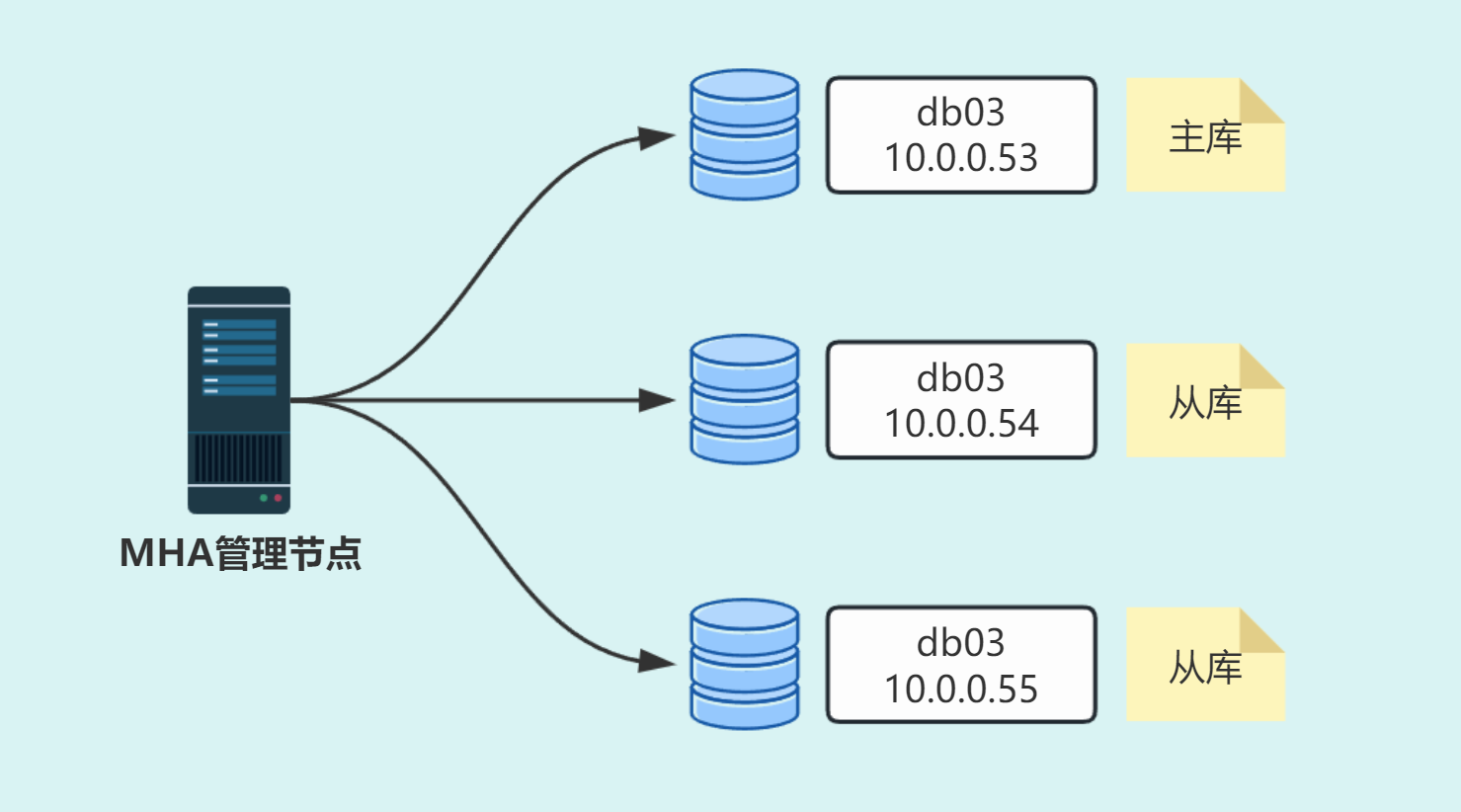
🖥️准备主从同步环境
| 主机 | ip |
|---|---|
| db03(主库) | 10.0.0.53 |
| db04(从库) | 10.0.0.54 |
| db05(从库) | 10.0.0.55 |
| db06(管理节点) | 10.0.0.56 |
编辑主库配置文件(db03)
cat >/etc/my.cnf <<EOF
[mysqld]
basedir=/app/tools/mysql
datadir=/data/3306/data
socket=/tmp/mysql.sock
server_id=53
port=3306
gtid-mode=on
enforce-gtid-consistency=true
log-slave-updates=1
[mysql]
prompt=db03 [\\d]>
EOF
编写从库配置文件(db04)
cat >/etc/my.cnf <<EOF
[mysqld]
basedir=/app/tools/mysql
datadir=/data/3306/data
socket=/tmp/mysql.sock
server_id=54
port=3306
gtid-mode=on
enforce-gtid-consistency=true
log-slave-updates=1
[mysql]
prompt=db04 [\\d]>
EOF
编写从库配置文件(db05)
cat >/etc/my.cnf <<EOF
[mysqld]
basedir=/app/tools/mysql
datadir=/data/3306/data
socket=/tmp/mysql.sock
server_id=55
port=3306
gtid-mode=on
enforce-gtid-consistency=true
log-slave-updates=1
[mysql]
prompt=db05 [\\d]>
EOF
初始化数据库(db03/db04/db05)
mysqld --initialize-insecure --user=mysql --datadir=/data/3306/data --basedir=/app/tools/mysql
在主库创建主从同步用户(db03)
create user repl@'10.0.0.%' identified with mysql_native_password by '123456';
grant Replication slave on *.* to repl@'10.0.0.%';
在从库做主从配置(db04/db05)
change master to
master_host='10.0.0.53',
master_user='repl',
master_password='123456',
master_auto_position=1;start slave;
🛠️安装部署高可用服务软件
MHA管理节点(db06)
1.创建软连接
ln -s /app/tools/mysql/bin/mysqlbinlog /usr/bin/mysqlbinlog
ln -s /app/tools/mysql/bin/mysql /usr/bin/mysql2.配置各节点互信
rm -rf /root/.ssh
cd /root/.ssh/
mv id_rsa.pub authorized_keys
scp -rp /root/.ssh 10.0.0.53:/root/
scp -rp /root/.ssh 10.0.0.54:/root/
scp -rp /root/.ssh 10.0.0.55:/root/3.下载node节点软件包传输到所有节点/app/tools/目录下
yum install perl-DBD-MySQL -y
cd /app/tools/
rpm -ivh mha4mysql-node-0.58-0.el7.centos.noarch.rpm4.安装MHA软件,下载MHA安装包到/app/tools/目录下
yum install -y perl-Config-Tiny epel-release perl-Log-Dispatch perl-Parallel-ForkManager perl-Time-HiRes
yum localinstall -y mha4mysql-manager-0.58-0.el7.centos.noarch.rpm
MHA数据节点(db03/db04/db05)
1.创建软连接
ln -s /app/tools/mysql/bin/mysqlbinlog /usr/bin/mysqlbinlog
ln -s /app/tools/mysql/bin/mysql /usr/bin/mysql2.安装node软件包
yum install perl-DBD-MySQL -y
cd /app/tools/
rpm -ivh mha4mysql-node-0.58-0.el7.centos.noarch.rpm
📝编写MHA服务配置文件(db06管理节点)
1.创建配置文件目录
mkdir -p /etc/mha2.创建日志目录
mkdir -p /var/log/mha/app013.编写配置文件
cat >/etc/mha/app01.cnf<<EOF
[server default]
manager_log=/var/log/mha/app01/manager
manager_workdir=/var/log/mha/app01
master_binlog_dir=/data/3306/data
user=mha
password=mha
ping_interval=2
repl_password=123456
repl_user=repl
ssh_user=root
[server1]
hostname=10.0.0.53
port=3306
[server2]
hostname=10.0.0.54
port=3306
[server3]
hostname=10.0.0.55
port=3306
EOF
🌈主库创建mha管理用户
db03 [(none)]>create user mha@'10.0.0.%' identified with mysql_native_password by 'mha';
db03 [(none)]>grant all privileges on *.* to mha@'10.0.0.%';
✅主库创建完后,从库会自动同步创建mha用户
🔍MHA服务环境测试
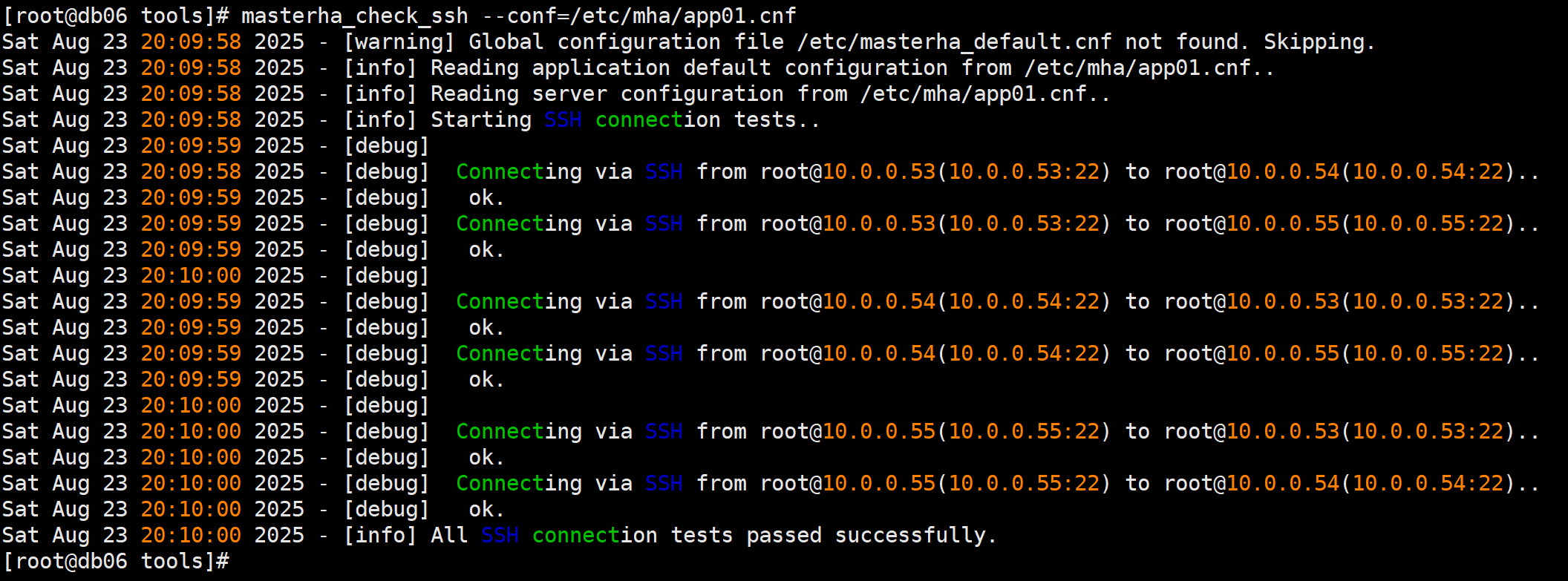
测试主从节点之间互信功能
masterha_check_ssh --conf=/etc/mha/app01.cnf
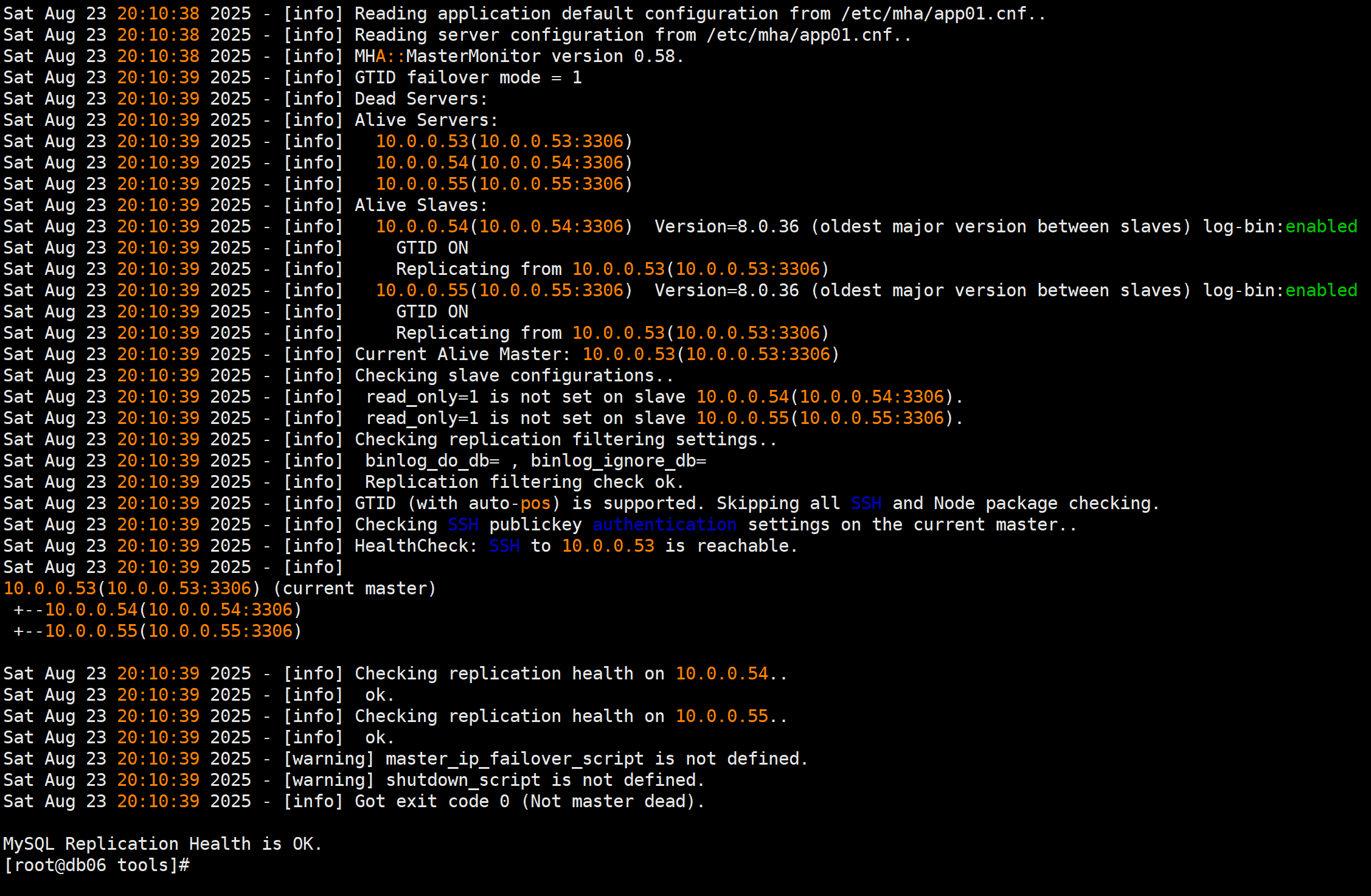
测试主从同步状态
masterha_check_repl --conf=/etc/mha/app01.cnf
🚀启动mha服务程序
1.在后台启动
nohup masterha_manager --conf=/etc/mha/app01.cnf --remove_dead_master_conf --ignore_last_failover < /dev/null > /var/log/mha/app01/manager.log 2>&1 &
--remove_dead_master_conf 将故障节点从高可用集群中移除,在配置文件中删除该节点配置信息
--ignore_last_failover 可以在出现异常时连续启动高可用服务,忽略一些错误信息
</dev/null让程序在后台运行时不等待用户输入2.检查
ps -ef | grep mhamasterha_check_status --conf=/etc/mha/app01.cnf

MHA功能配置
高可用主库的监控
利用masterha_manager启动脚本,在启动MHA服务后,会自动调用masterha_master_monitor脚本
利用监控脚本向主库发送SQL语句请求
如果可以对SQL语句做响应,表示主库正常
如果不能对SQL语句做响应,会连续发送4此测试请求,4次连续请求都不能做响应,会触发MHA故障切换
主库选举机制
1️⃣划分角色信息
| 角色数组 | 作用 |
|---|---|
| alive | 将活着的节点会划分到此数组中 |
| latest | 将数据量和主库一致的节点划分到此数组中 |
| pref | 会检查MHA配置文件节点信息,看节点信息中是否有candidate_master配置项,有就会把对应节点划分到此数组中 |
| bad | 划分到此数组中的节点,不参与选举 1️⃣在从库上做了log_bin=0配置,关闭binlog日志 2️⃣在从库上做了no_master=1配置,明确不参与选举 3️⃣从库和主库的数据差异量太多(超过100M) |
2️⃣根据机制选择新主
方案一:
活着节点 --> 数据量一致 --> 有candidate_master配置项 --> 不能出现在bad数组 -->会优先选择为新主节点
方案二:
活着节点 --> 数据量一致 --> --> 不能出现在bad数组
方案三:
活着节点 --> 有candidate_master配置项 --> --> 不能出现在bad数组
方案四:
活着节点 --> 数据量一致 --> --> 不能出现在bad数组
以上4种方案,进行选主时,出现多个主节点情况,看配置节点标签编号,标签编号越小,优先成为主节点
数据补偿过程
方案一:当原主库可以被SSH连接访问时
会利用ssh免密连接,拉取主库种的binlog日志文件,保存到新的从库种,进行数据补偿
方案二:当主库不能被SSH连接访问时
- 利用从库之间数据差异性,进行数据补偿,确保新主的数据最全
- 利用binlog日志备份服务器,实现数据补偿(需要进行配置)
进行主从重构
#在从节点上进行重新配置
stop slave
reset slave all
change master to
master_host=新主IP地址
master_post=新主port
master_user=$repl_user
master_password=$
实现主从切换应用透明(需要做配置)
应用透明表示让前端服务器感知不到后端有故障切换过程
利用VIP地址实现应用透明
实现MHA故障转移报警功能
告知管理人员,主数据库
测试MHA切换功能
编写VIP切换脚本
- 将脚本文件传输到管理节点(db06)
scp master_ip_failover root@10.0.0.56:~
- 移动到/usr/local/bin/目录下
mv master_ip_failover /usr/local/bin/
- 编辑脚本文件
vim /usr/local/bin/master_ip_failover
#定义VIP地址
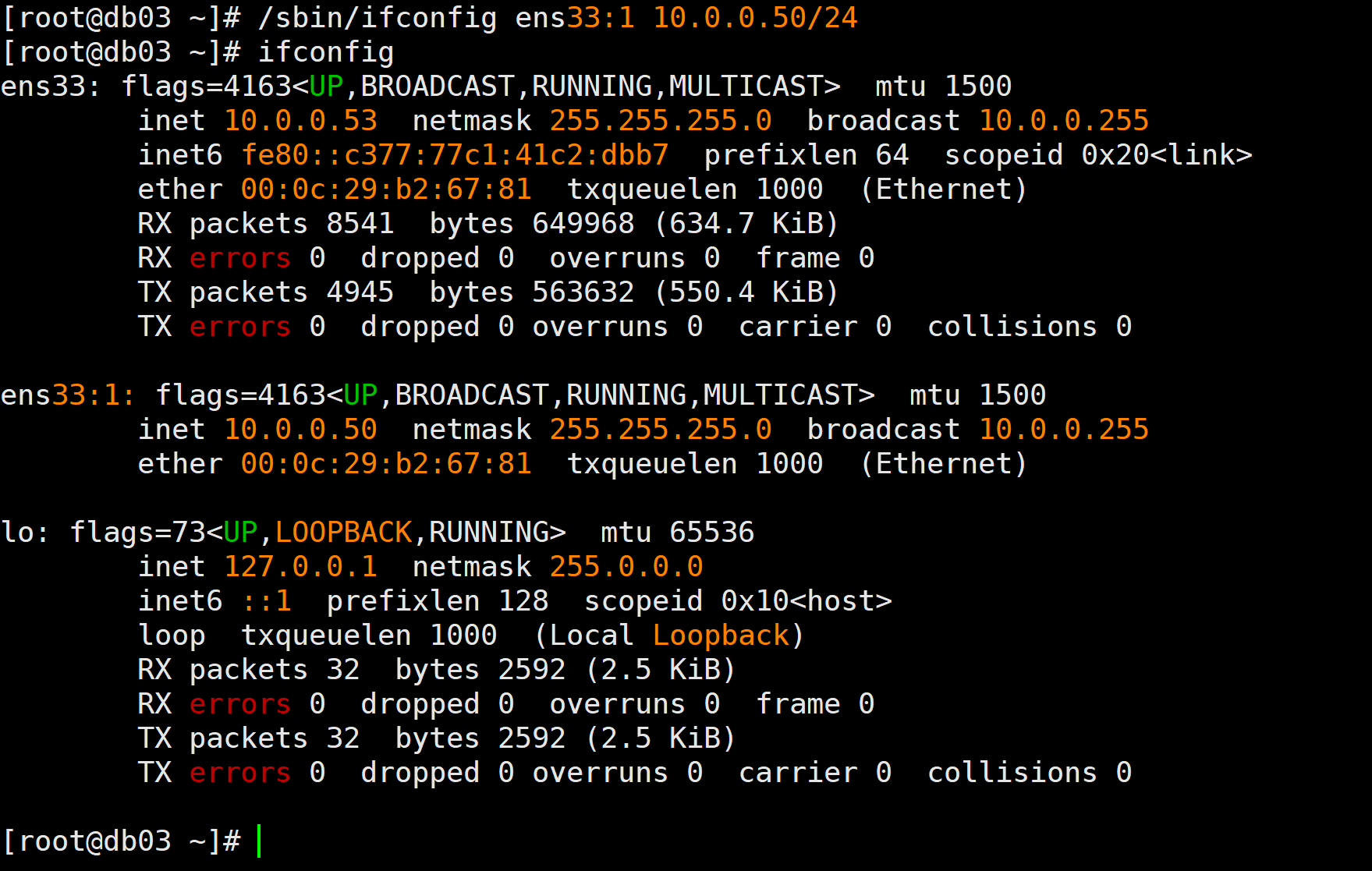
my $vip = '10.0.0.50/24';
#定义VIP地址所在网卡的别名
my $key = '1';
#在从节点(新主节点)会创建生成VIP
my $ssh_start_vip = "/sbin/ifconfig ens33:$key $vip";
#在主节点(原主节点)会删除VIP地址
my $ssh_stop_vip = "/sbin/ifconfig ens33:$key down";
#让所有数据库客户端主机,可以重新生成VIP地址的ARP记录(确保web前端可以访问新的主节点)
my $ssh_Bcast_arp= "/sbin/arping -I ens33 -c 3 -A 10.0.0.50";
- 手动生成VIP
- 编辑mha配置文件
vim /etc/mha/app01.cnf
master_ip_failover_script=/usr/local/bin/master_ip_failover
实现故障报警功能
- 将脚本文件传输到管理节点(db06)
scp send_report root@10.0.0.56:~
- 移动到/usr/local/bin/目录下
mv send_report /usr/local/bin/
- 设置邮件服务域名信息
my $smtp='smtp.163.com';
my $mail_from='15180579479@163.com';
my $mail_user='15180579479';
my $mail_pass='GYVBK9cqTR6iHrSY';
#my $mail_to=['to1@qq.com','to2@qq.com'];
my $mail_to='2501379813@qq.com';
- 编辑mha配置文件
vim /etc/mha/app01.cnf
report_script=/usr/local/bin/send_report
实现数据额外补偿功能
- 需要有binlog日志备份服务器
1.创建存放binlog文件目录
mkdir -p /binlog_backup/app01/2.执行远程同步binlog
cd /binlog_backup/app01/
mysqlbinlog -R --host=10.0.0.50 --user=mha --password=mha --raw --stop-never binlog.000010 &
- 编辑mha配置文件
vim /etc/mha/app01.cnf
[binlog1]
no_master=1
hostname=10.0.0.56
master_binlog_dir=/binlog_backup/app01/
- 加载mha配置
1.停止mha服务
masterha_stop --conf=/etc/mha/app01.cnf2.重新启动mha服务
nohup masterha_manager --conf=/etc/mha/app01.cnf --remove_dead_master_conf --ignore_last_failover < /dev/null > /var/log/mha/app01/manager.log 2>&1 &
测试高可用自动切换功能
- 模拟db03主库故障
1.停止数据库服务
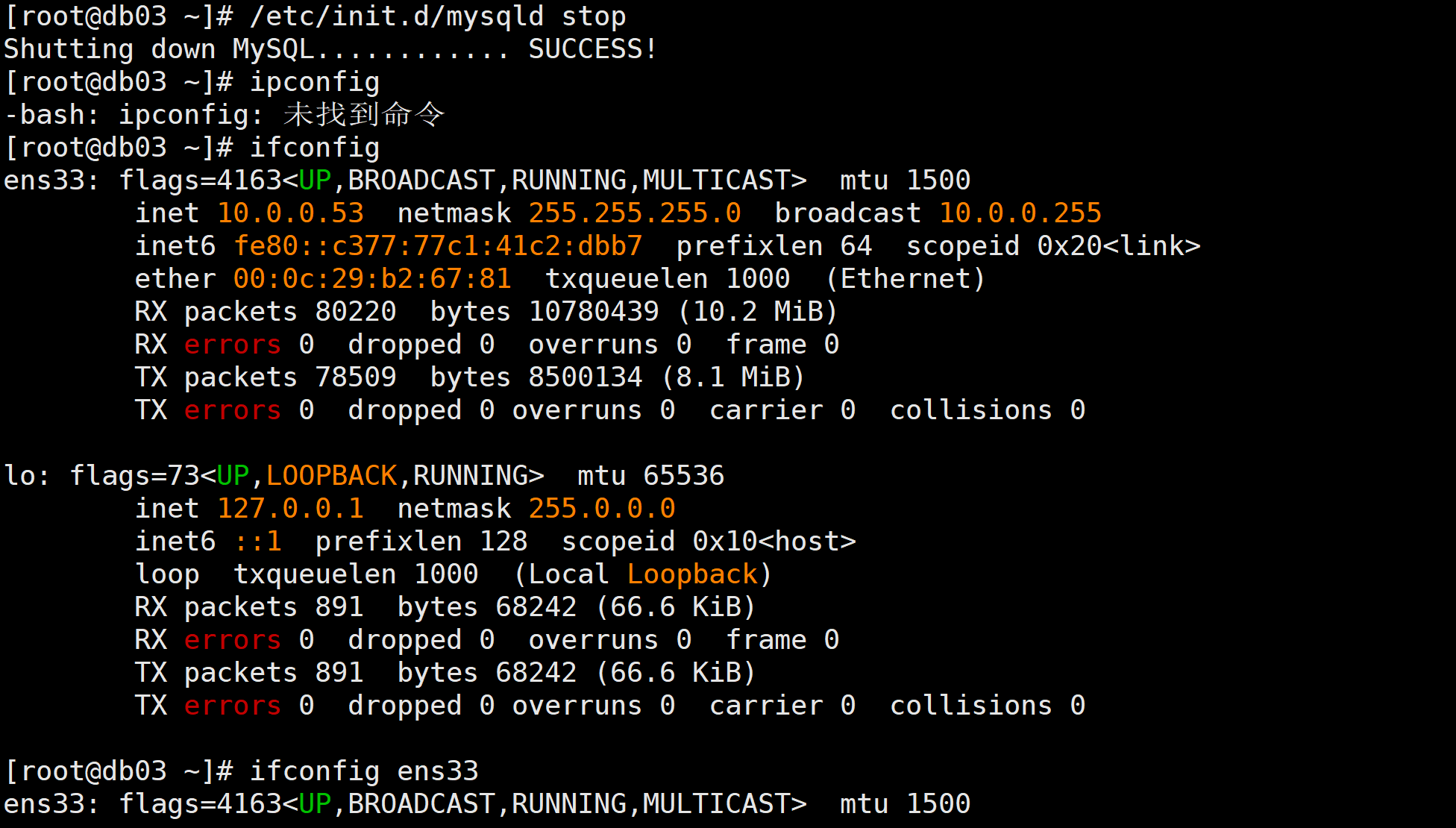
/etc/init.d/mysqld stop2.查看虚拟IP地址
ifconfig
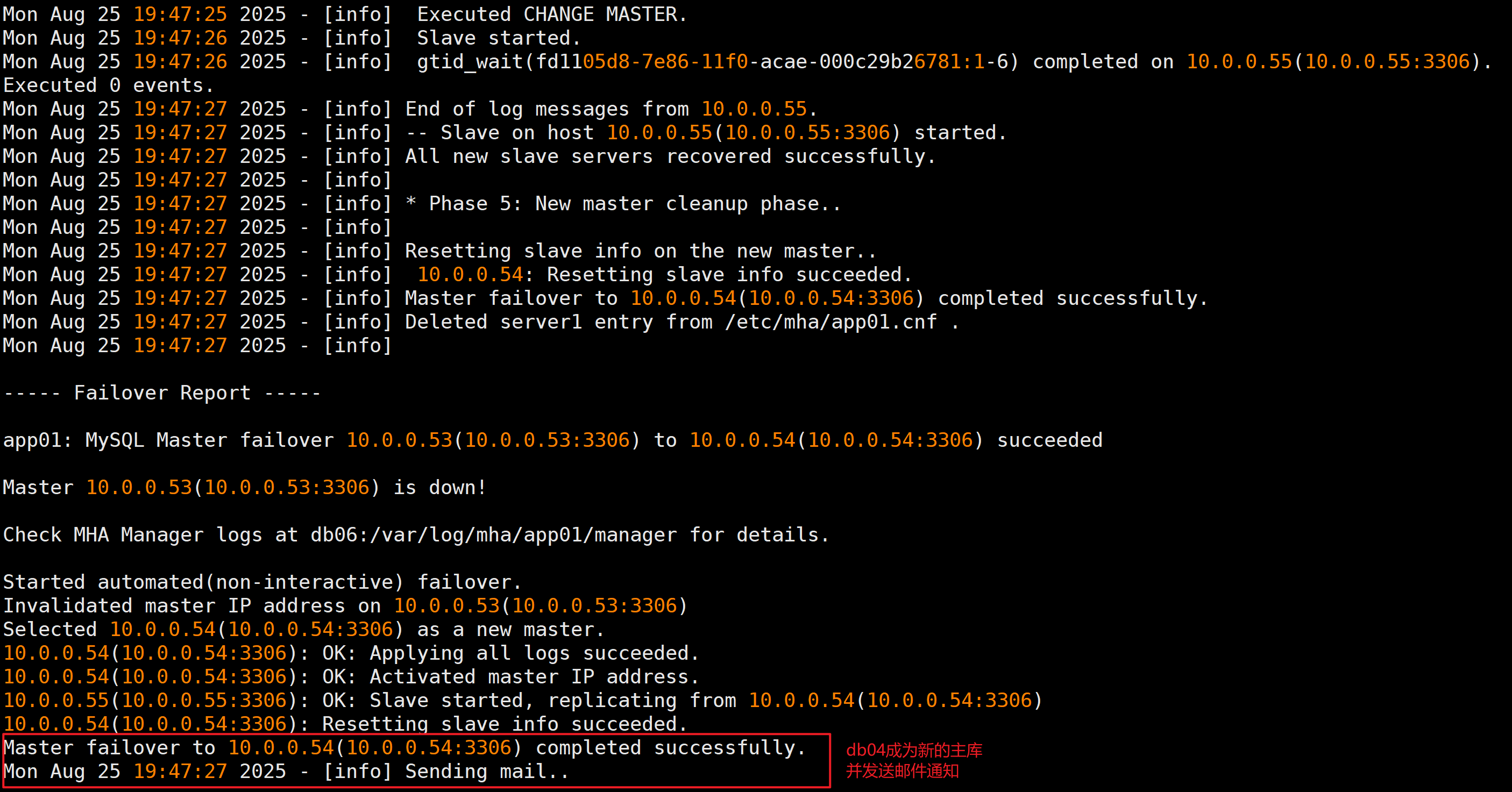
- 查看MHA日志
tail -f /var/log/mha/app01/manager
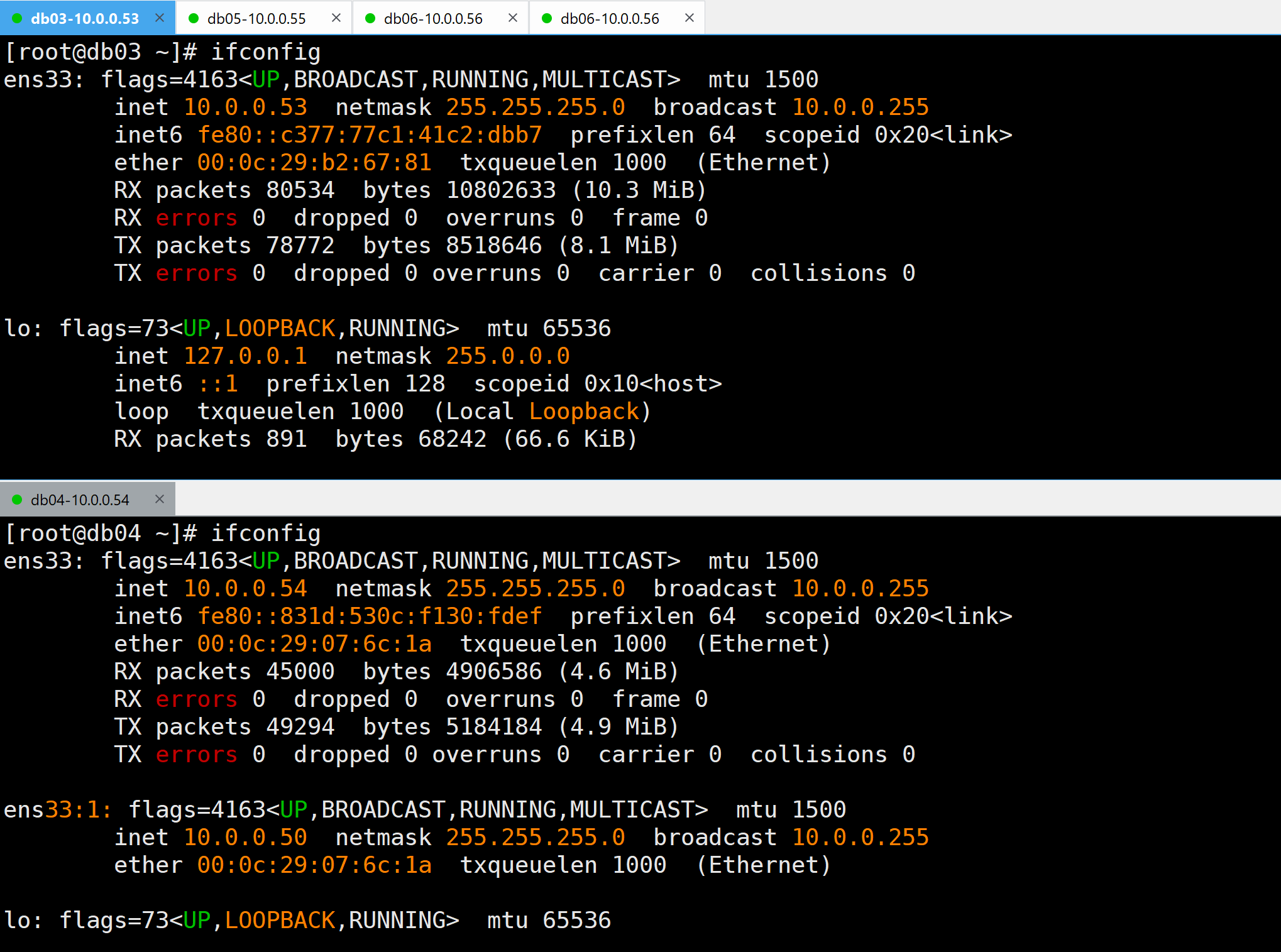
- 检查01:VIP地址是否漂移
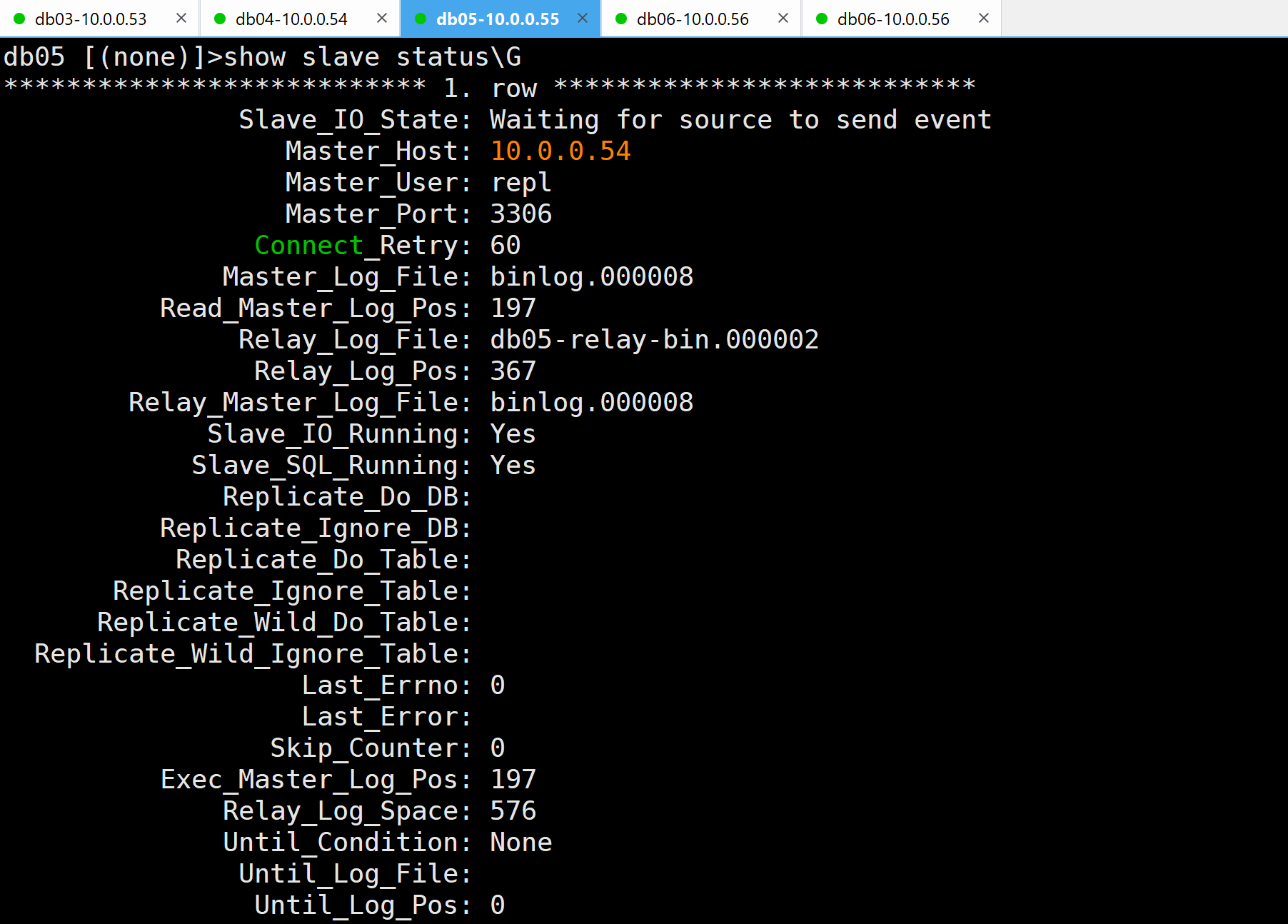
- 检查02:主从是否重新构建
- 检查03:是否收到邮件告警通知
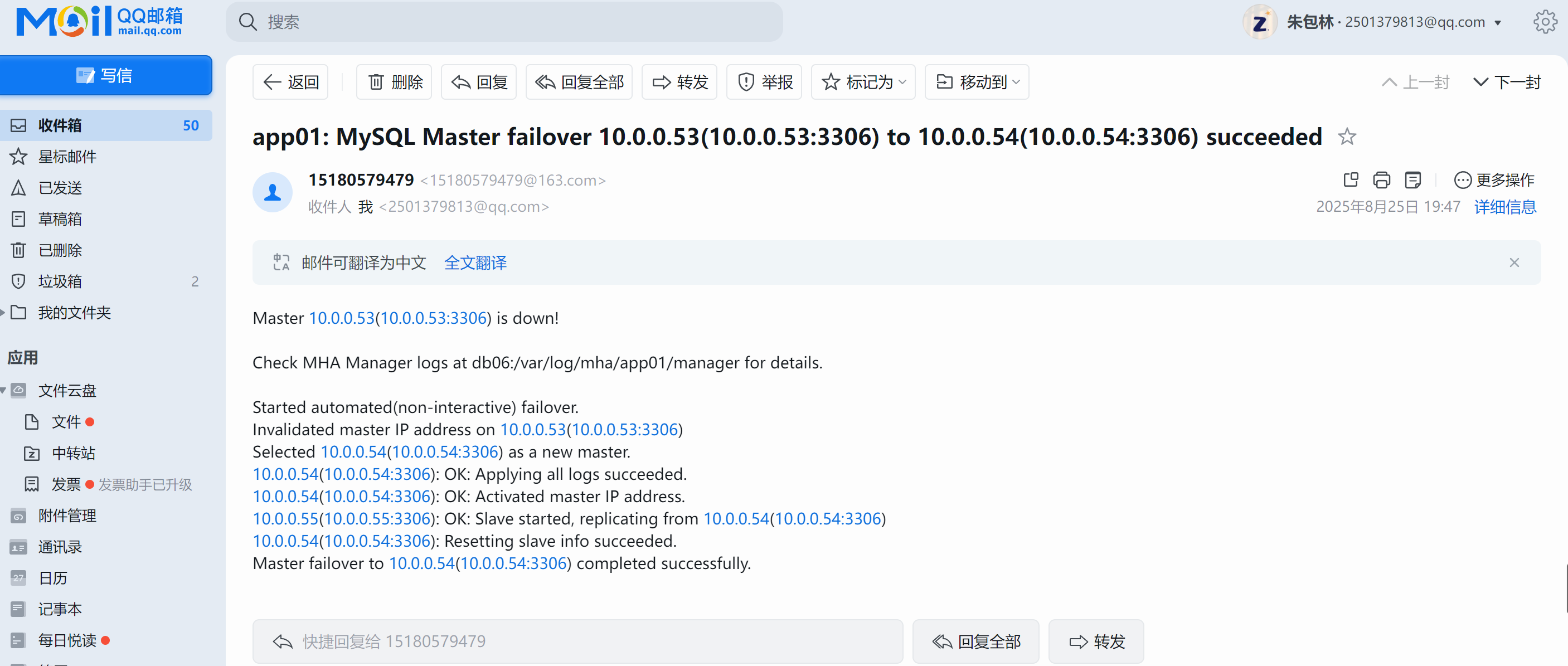
- 检查04:检查mha服务状态
masterha_check_status --conf=/etc/mha/app01.cnf
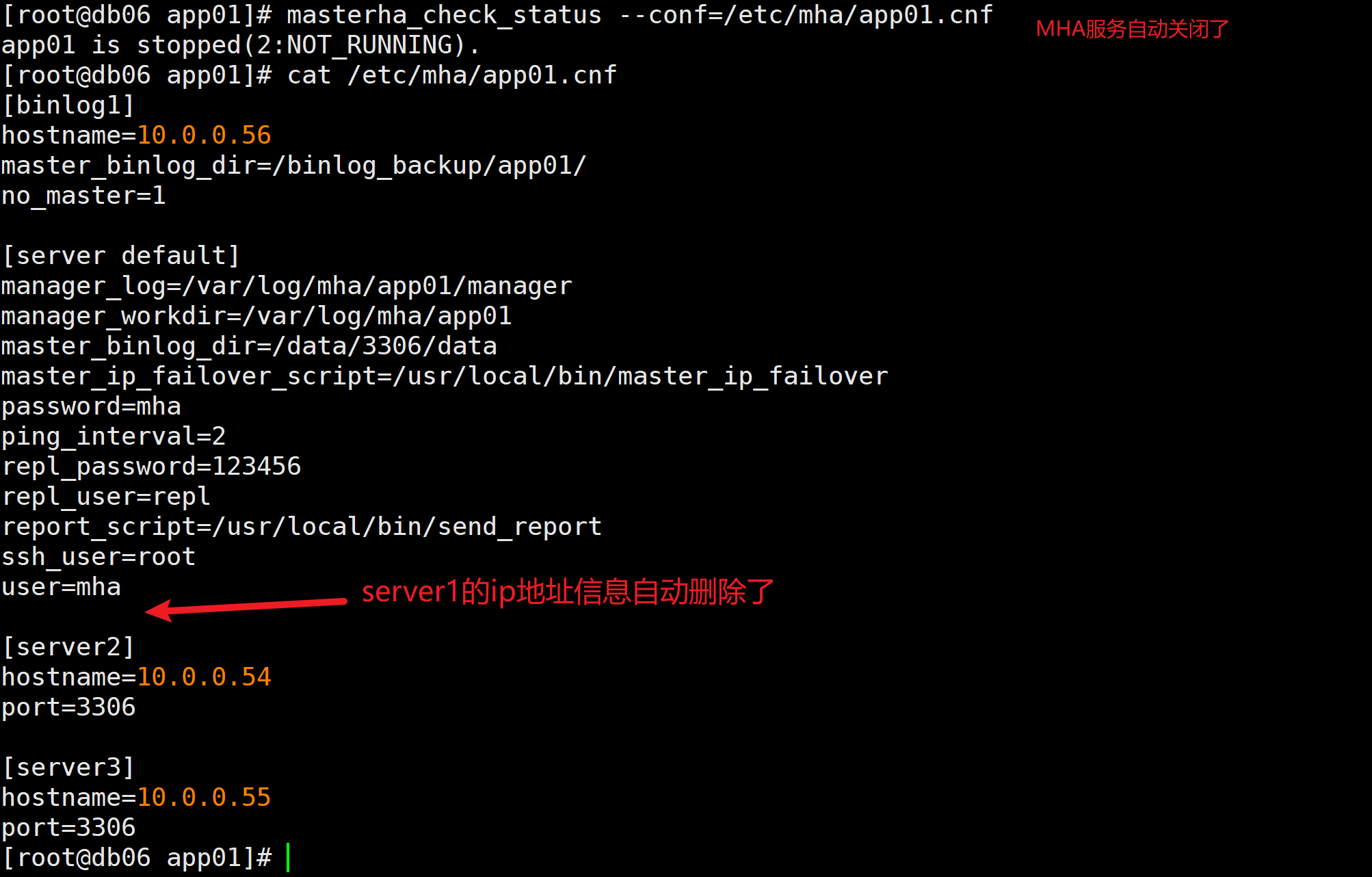
恢复MHA运行启动
- 在日志备份服务器上,恢复日志备份功能
1.切换到日志备份目录
cd /binlog_backup/app01/2.清空里面的日志信息,确保不会和新备份冲突
rm -f /binlog_backup/app01/*3.开启日志备份功能
mysqlbinlog -R --host=10.0.0.50 --user=mha --password=mha --raw --stop-never binlog.000008 &
- 恢复MHA
nohup masterha_manager --conf=/etc/mha/app01.cnf --remove_dead_master_conf --ignore_last_failover < /dev/null > /var/log/mha/app01/manager.log 2>&1 &

将db03重新加入到主从节点中
1.启动mysql服务
/etc/init.d/mysqld start2.登录数据库
mysql -uroot -pzhu3.添加主从配置
change master to
master_host='10.0.0.54',
master_user='repl',
master_password='123456',
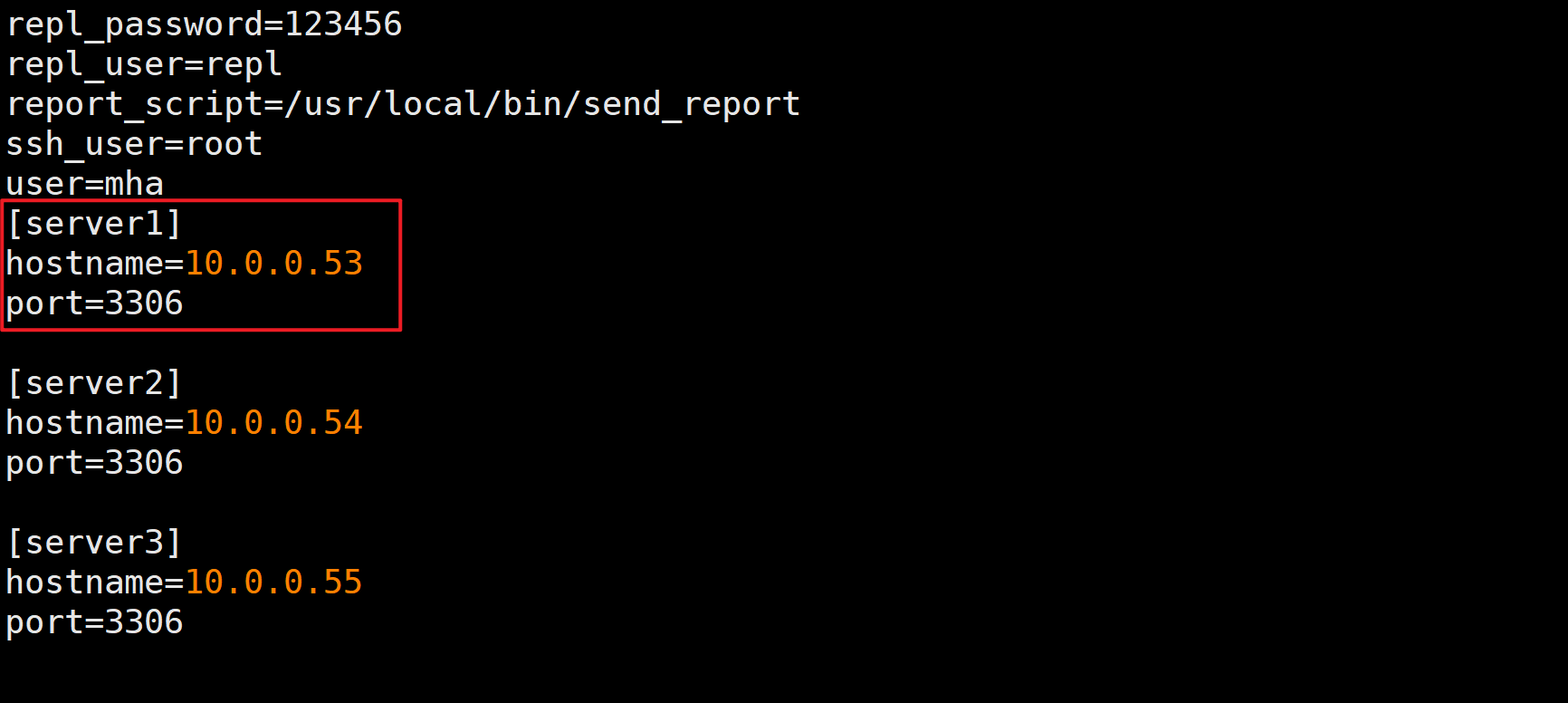
master_auto_position=1;start slave;4.修改mha配置文件,将mha删除掉的server1配置重新添加回来
vim /etc/mha/app01.cnf
[server1]
hostname=10.0.0.53
port=33065.停止mha服务
masterha_stop --conf=/etc/mha/app01.cnf6.重新启动mha服务
nohup masterha_manager --conf=/etc/mha/app01.cnf --remove_dead_master_conf --ignore_last_failover < /dev/null > /var/log/mha/app01/manager.log 2>&1 &
实现手动切换
编写手动切换脚本
1.将脚本拷贝到管理节点上
scp -r master_ip_online_change root@10.0.0.56:~2.编辑脚本文件
vim master_ip_online_change
my $vip = "10.0.0.50";
my $key = "1";
my $ssh_start_vip = "/sbin/ifconfig ens33:$key $vip";
my $ssh_stop_vip = "/sbin/ifconfig ens33:$key $vip down";
my $ssh_Bcast_arp= "/sbin/arping -I ens33 -c 3 -A 10.0.0.50";3.添加执行权限
chmod +x master_ip_online_change4.将脚本移动到/usr/local/bin/目录
mv master_ip_online_change /usr/local/bin/
编写MHA配置文件
在[server default]下方添加一行
vim /etc/mha/app01.cnf
master_ip_online_change_script=/usr/local/bin/master_ip_online_change
加载MHA配置
1.停止mha服务
masterha_stop --conf=/etc/mha/app01.cnf2.重新启动mha服务
nohup masterha_manager --conf=/etc/mha/app01.cnf --remove_dead_master_conf --ignore_last_failover < /dev/null > /var/log/mha/app01/manager.log 2>&1 &

利用命令实现手动切换
1.停止MHA服务
masterha_stop --conf=/etc/mha/app01.cnf2.执行手动切换
masterha_master_switch --conf=/etc/mha/app01.cnf --master_state=alive --new_master_host=10.0.0.53 --orig_master_is_new_slave --running_updates_limit=100003.参数详解
#确保在主节点活着的状态进行MHA高可用切换
--master_state=alive
#指定在手工切换过程中,哪个从节点成为新的主节点
--new_master_host=10.0.0.55
#实现主从重构功能
--orig_master_is_new_slave
#在指定时间内,如果没有完成手工切换,会自动终止切换过程
--running_updates_limit=10000
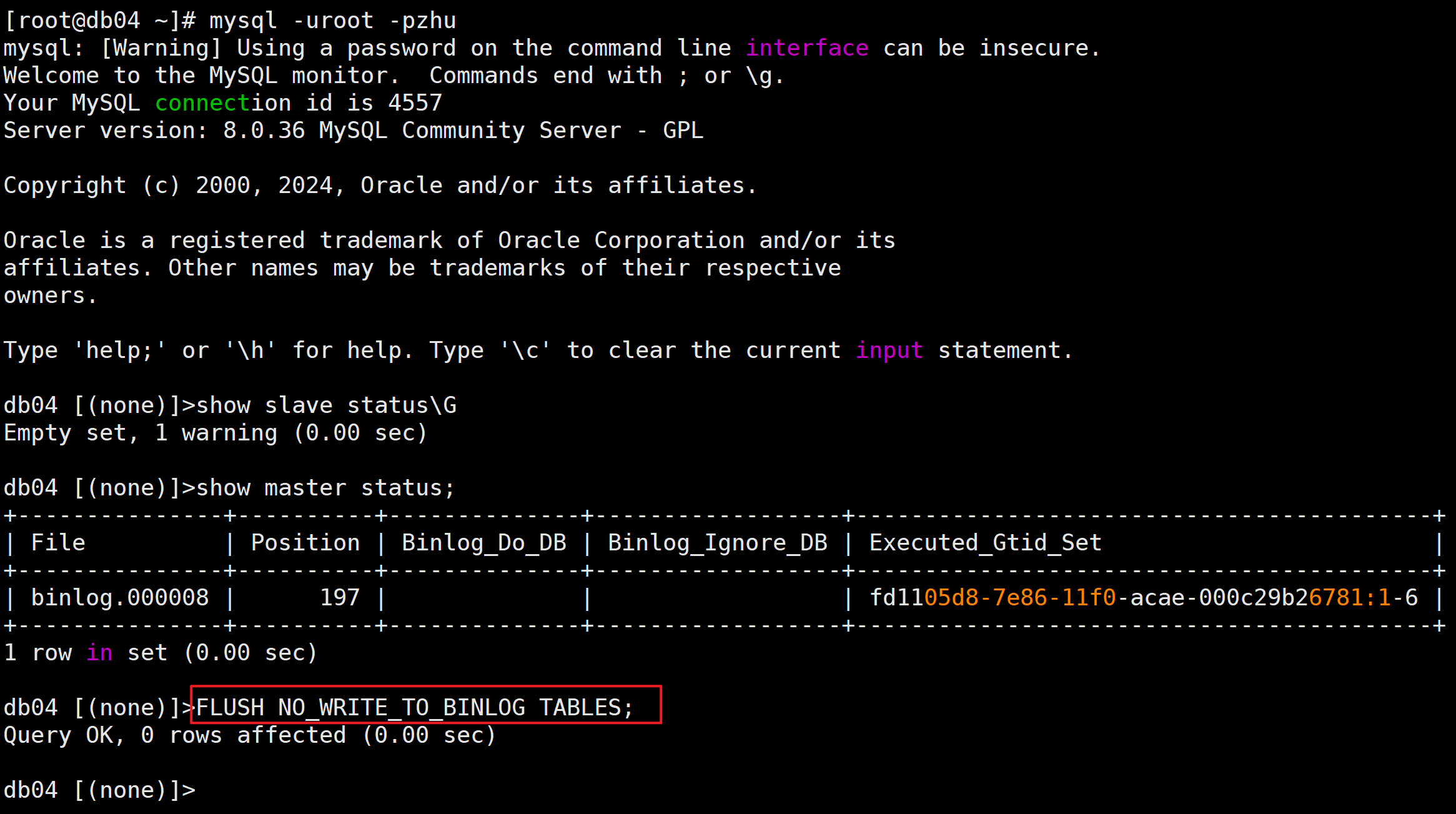
切换主节点之前在当前的主节点上执行FLUSH NO_WRITE_TO_BINLOG TABLES:不记录binlog日志
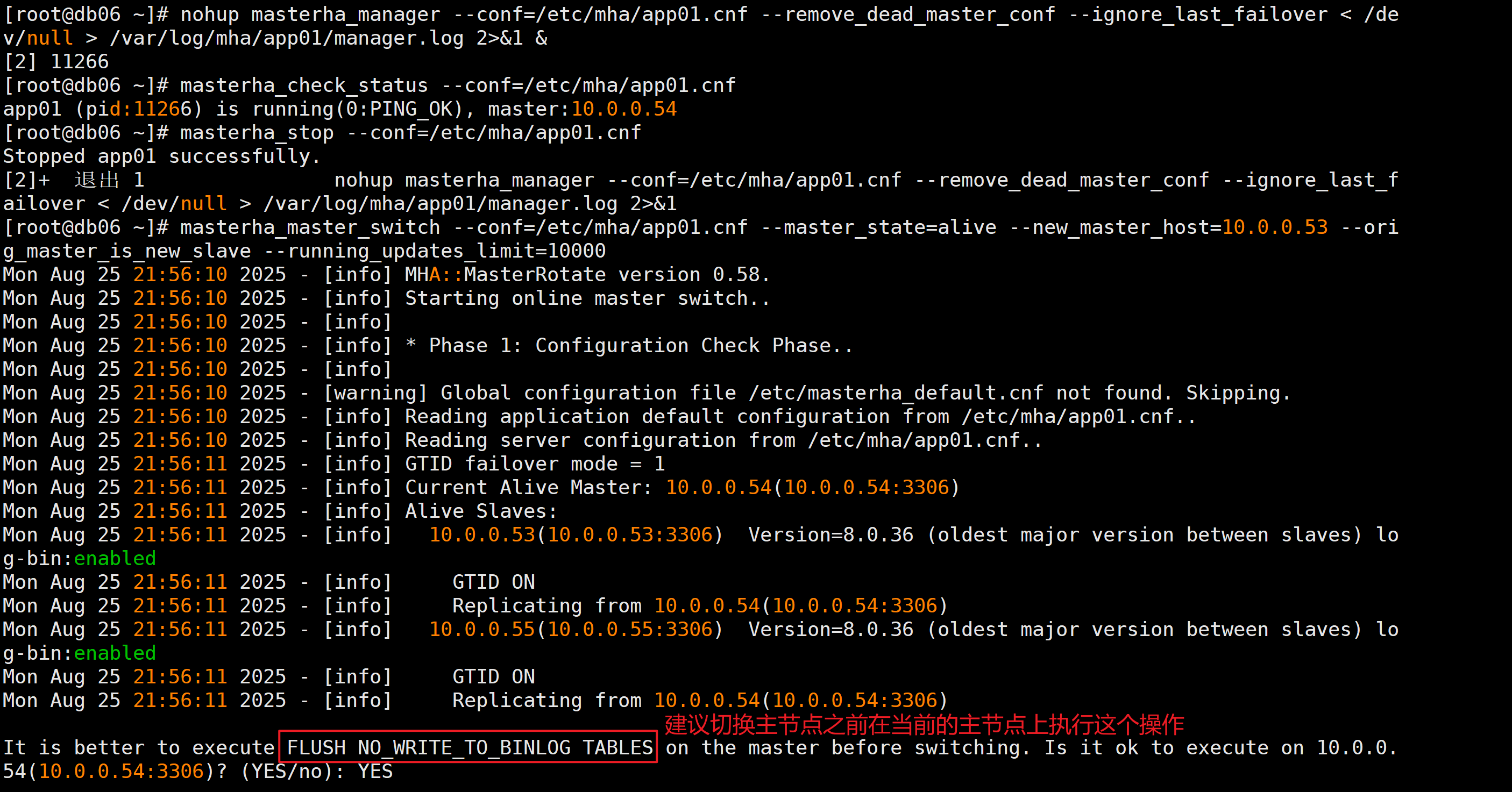
在DB04上执行FLUSH NO_WRITE_TO_BINLOG TABLES
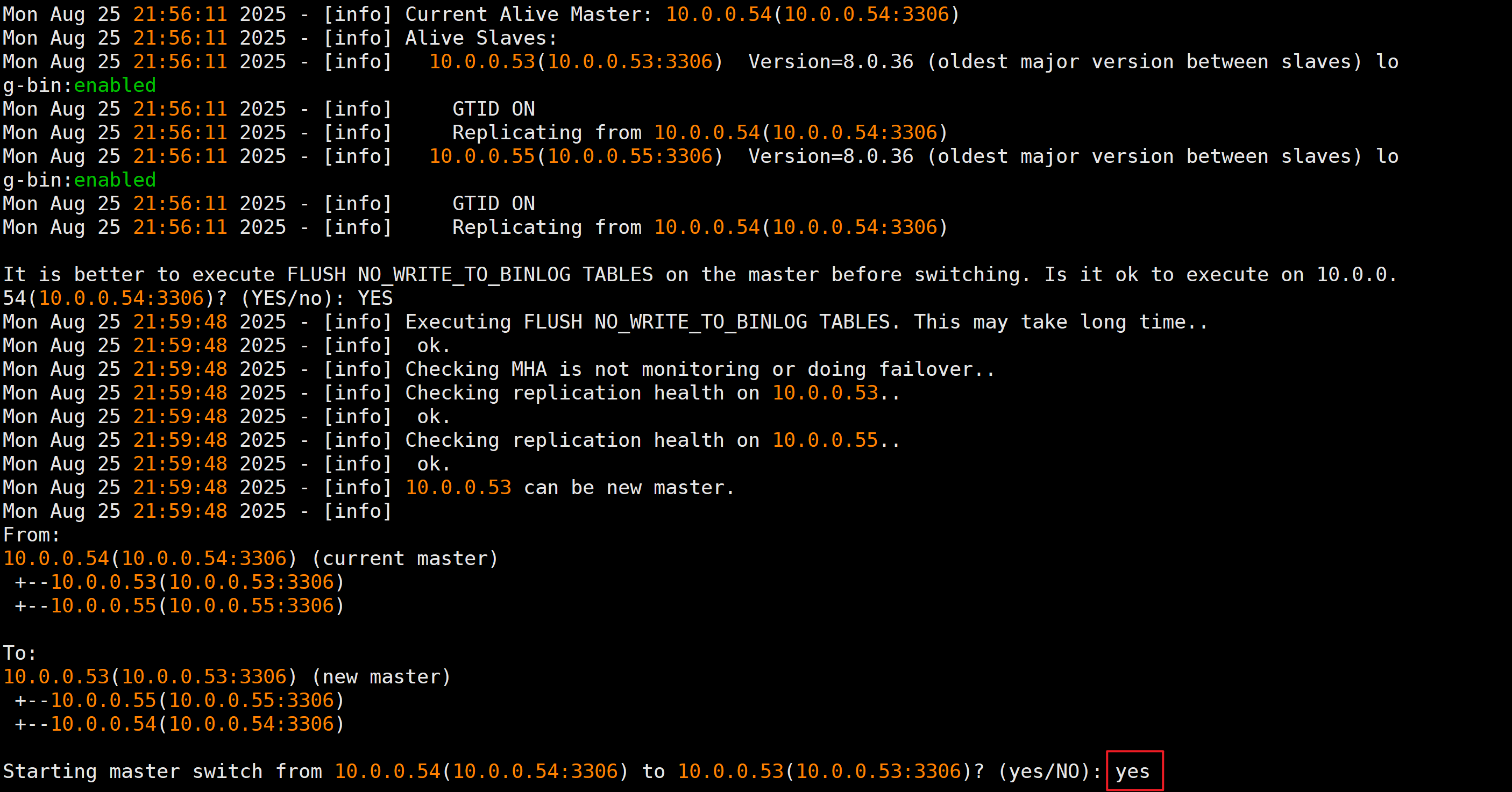
输入yes确认切换
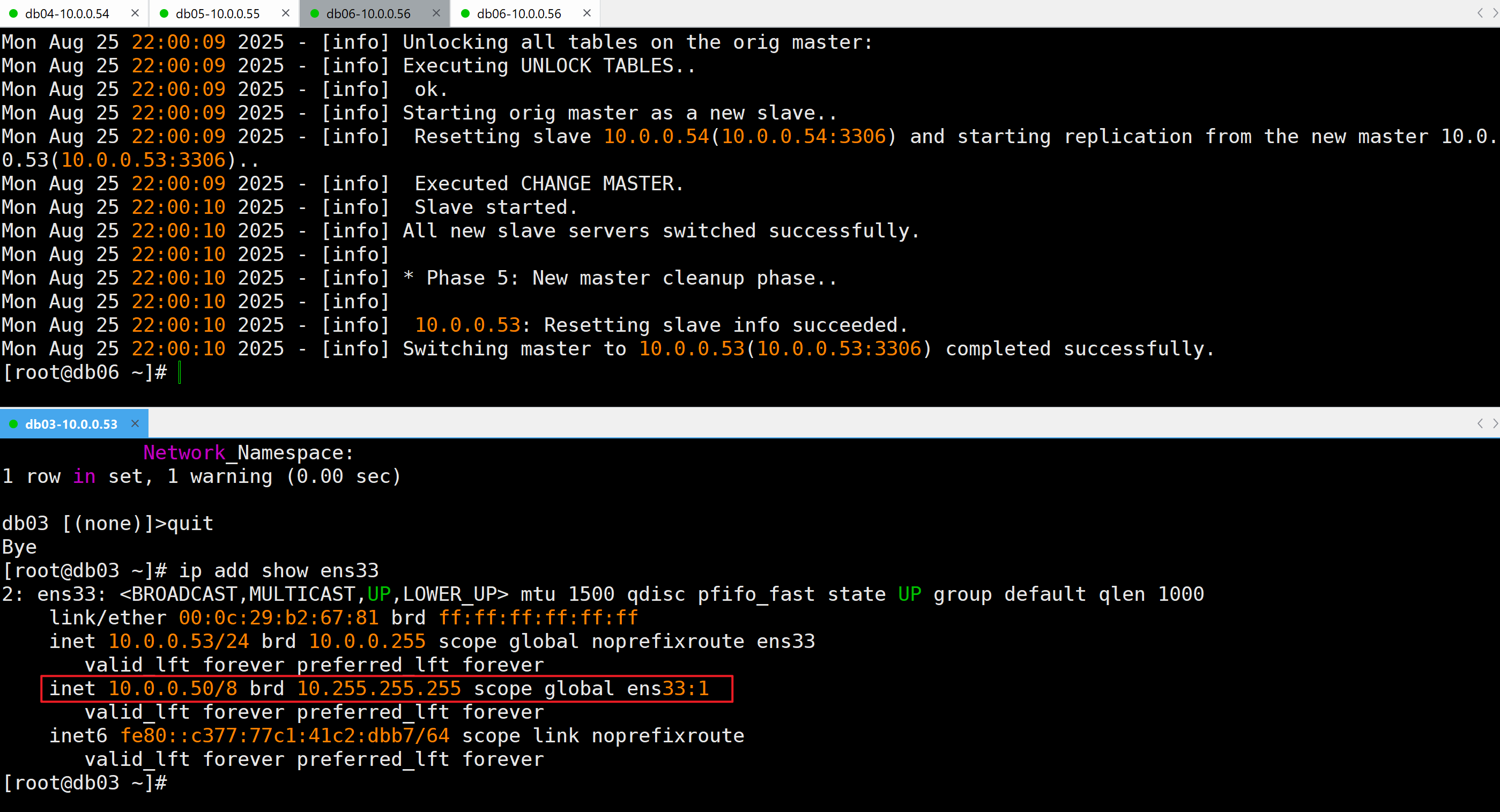
查看虚拟IP是否漂移到DB03上
✅总结
- 掌握MHA高可用搭建配置过程
- 掌握MHA高可用切换原理流程
- 掌握MHA高可用如何实现自动和手动切换
