深度学习——激活函数
一、什么是激活函数?
在深度学习中,激活函数(Activation Function) 是神经网络中每个神经元上应用的一个非线性函数,它决定了该神经元是否应该被“激活”,即是否将输入信号传递到下一层。
数学表示:
如果一个神经元的输入是 z(通常是加权求和加上偏置:z=w⋅x+b),那么经过激活函数 σ后的输出为:
二、为什么要用激活函数?
神经网络的核心能力在于学习复杂的非线性映射关系,而如果只使用线性运算(如矩阵乘法加偏置),无论多少层网络叠加,其整体依然是一个线性模型:
这本质上还是线性变换,无法表达复杂的函数关系,比如异或(XOR)、图像、语音等。
👉 激活函数的引入,打破了线性性,使神经网络具有表达非线性函数的能力,是深度学习模型能够学习复杂模式的关键。
三、激活函数的分类
激活函数大致可以分为以下几类:
1. 线性激活函数(Linear Activation)
- 特点:输出等于输入,无任何非线性。
- 缺点:整个网络仍然是线性的,无法学习复杂特征。
- 使用场景:仅在回归问题的输出层,或者特殊情况下使用。
2. 非线性激活函数(Non-linear Activation)
这是深度学习中最常用的激活函数类型,常见的有:
(1)Sigmoid 函数

✅ 优点:
- 输出在 0 到 1 之间,可用于表示概率。
- 平滑、处处可导。
❌ 缺点:
- 容易导致梯度消失(在输入很大或很小时,梯度接近0)。
- 输出不是以 0 为中心,影响优化效率。
📌 适用场景: 二分类问题的输出层(输出概率)。
(2)Tanh 函数(双曲正切)
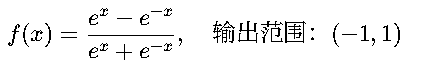
✅ 优点:
- 输出以 0 为中心,比 Sigmoid 更好。
- •平滑可导。
❌ 缺点:
- 仍然存在梯度消失问题。
📌 适用场景: 隐藏层(比 Sigmoid 效果略好)。
(3)ReLU 函数(Rectified Linear Unit,修正线性单元)
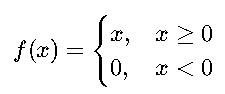
✅ 优点:
- 计算简单,速度快。
- 在正区间不会饱和,缓解了梯度消失问题。
- 实践中表现非常好,是当前最常用的激活函数之一。
❌ 缺点:
- 神经元死亡问题:某些神经元可能永远不被激活(输出恒为 0)。
📌 适用场景: 隐藏层(最常用!)
(4)Leaky ReLU

✅ 优点:
- 解决了 ReLU 的“神经元死亡”问题,负区间有小的梯度。
- 通常比 ReLU 效果更好。
📌 适用场景: 当你担心某些神经元不激活时使用。
(5)Parametric ReLU (PReLU)
- Leaky ReLU 的升级版,其中 α是一个可学习参数,不是固定的。
(6)ELU(Exponential Linear Unit)
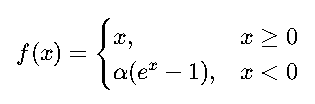
✅ 优点:
- 负值区域有非零输出,有助于让输出均值接近零,加速收敛。
- 比 ReLU 更平滑。
📌 适用场景: 深层网络,对训练稳定性要求较高的场景。
(7)Softmax 函数
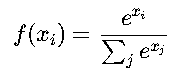
✅ 特点:
- •将一组数值转化为概率分布,所有输出之和为 1。
- •常用于多分类问题的输出层。
📌 适用场景: 多分类任务的输出层。
四、激活函数的选择指南
任务/层类型 | 推荐激活函数 | 原因说明 |
|---|---|---|
隐藏层(一般情况) | ReLU、Leaky ReLU | 训练快,效果好,不容易梯度消失 |
隐藏层(深层网络) | ReLU / ELU / Leaky ReLU | 更稳定,缓解梯度问题 |
二分类输出层 | Sigmoid | 输出概率,范围 (0,1) |
多分类输出层 | Softmax | 输出类别概率分布 |
回归问题输出层 | 线性(无激活函数) 或根据需求选择 | 输出连续值 |
避免神经元死亡 | Leaky ReLU / PReLU / ELU | 负区间有梯度 |
五、激活函数的发展趋势
随着深度学习的发展,研究者提出了许多改进的激活函数,目标是:
- 缓解梯度消失 / 梯度爆炸
- 加速网络收敛
- 提高模型泛化能力
- 避免神经元死亡
例如:
- Swish(Google 提出):f(x)=x⋅σ(βx),一个自门控的激活函数,表现有时优于 ReLU。
- GELU(高斯误差线性单元):被用于 Transformer 模型(如 BERT),结合了 ReLU 和 Dropout 的思想。
- Mish:f(x)=x⋅tanh(ln(1+ex)),近年来在一些任务中表现优异。
但这些高级激活函数一般在特定任务或模型中表现更好,ReLU 及其变种仍是最常用、最通用的选择。
六、激活函数总结表(PyTorch版)
激活函数 | PyTorch类 | PyTorch函数 | 是否常用 | 适用位置 |
|---|---|---|---|---|
ReLU |
|
| ✅✅✅ | 隐藏层 |
LeakyReLU |
|
| ✅✅ | 隐藏层(防死亡) |
Sigmoid |
|
| ✅ | 二分类输出层 |
Tanh |
|
| ✅ | 隐藏层(效果不如 ReLU) |
Softmax |
|
| ✅ | 多分类输出层 |
LogSoftmax |
|
| ✅ | 分类 + NLLLoss |
ELU |
|
| ✅ | 隐藏层(平滑负值) |
GELU |
|
| ✅(如BERT) | 隐藏层(Transformer类模型) |
SELU |
|
| ✅(自归一化网络) | 隐藏层 |
Swish | 无(可用 |
| ✅(Google提出) | 隐藏层 |
🔥 推荐默认选择:
- 隐藏层:ReLU、LeakyReLU、GELU、ELU
- 输出层:
- 二分类 → Sigmoid
- 多分类 → Softmax
- 回归 → 无激活函数(或线性)
七、总结
项目 | 说明 |
|---|---|
定义 | 激活函数给神经元引入非线性,是神经网络能够学习复杂模式的关键 |
为什么重要 | 没有激活函数,神经网络等效于线性模型,无法处理复杂任务 |
常用激活函数 | Sigmoid、Tanh、ReLU、Leaky ReLU、ELU、Softmax 等 |
如何选择 | 根据任务类型(分类/回归)、网络深度、训练效果等决定 |
当前主流 | ReLU 及其变种(Leaky ReLU、ELU等)在隐藏层最常用;Softmax 用于多分类输出;Sigmoid 用于二分类输出 |