实现自己的AI视频监控系统-第二章-AI分析模块2
文章目录
- 前言
- 一、ultralytics推理模型存在的弊端
- 二、onnx与onnxruntime简介
- 三、onnxruntime实战测试
- 3.1 onnxruntime的安装
- 3.2 ultralytics直接导出onnx
- 3.3 基于onnxruntime的yolo11n推理测试
- 3.4基于ultralytics的推理测试
- 3.5 章节小节
- 总结
- 下期预告
前言
在上一小节,我们在视频展示系统上加入了yolo11n的推理分析,实现了8路实时分析和展示,但是遇到了以下几个问题:
- 分析帧率并不高
- 基于ultralytics的yolo推理需要注意线程安全问题
- python GIL锁导致整体运行效率并不高
基于以上三点问题,python自身线程锁的问题并不在本章的讨论范围之内,我们更聚焦于多平台、多工具推理,依托硬件设备和模型优化实现AI模型的高性能推理。
一、ultralytics推理模型存在的弊端
众所周知,ultralytics库的底层实现是基于pytorch,虽然pytorch逐步实现了对多种硬件设备的兼容,但是其依旧存在一定问题。这些弊端主要源于其研究优先的设计哲学,在追求灵活性、易用性和快速迭代的同时,在某些生产环境和极端性能要求的场景下,可能会暴露出以下局限性:
-
对 PyTorch 的强依赖导致的环境臃肿与性能瓶颈
-
动态图(Dynamic Graph)推理开销:PyTorch 的 eager execution 模式在推理时存在额外的解释开销,无法像静态图框架(如 TensorRT, ONNX Runtime, OpenVINO)那样进行深度的图融合(Graph Fusion)、层合并(Layer Fusion)和常量折叠(Constant Folding)等优化。这导致了在相同硬件上,纯 PyTorch 模型的推理速度通常不是最优的。
-
依赖项庞大:部署一个完整的 ultralytics 推理环境需要安装 PyTorch、TorchVision 以及其他一系列科学计算库。这对于追求轻量级、快速启动的边缘计算容器(如 Docker)或资源受限的嵌入式设备来说,显得过于臃肿。
-
-
硬件支持广而不精,性能未达极致
-
“通用”而非“专用”:PyTorch 提供了在各种硬件(NVIDIA GPU, AMD GPU, CPU, Apple Silicon等)上运行的能力,但这是一种“通用”支持。对于特定硬件,缺乏为其深度定制的优化算子。
-
NVIDIA GPU:其原生 PyTorch 模型无法直接利用 NVIDIA TensorRT 的极致优化能力,例如使用 FP16/INT8 精度、利用特定 Tensor Core 的指令集、以及更激进的 kernel auto-tuning。虽然可以通过转换为 ONNX 再导入 TensorRT 实现,但这增加了流程的复杂性和出错的概率。
-
Intel CPU:未集成 OpenVINO 运行时,无法直接使用 OpenVINO 对 Intel CPU 和 VPU 的深度指令集优化。
-
其他AI加速卡:对于华为昇腾(Ascend)、瑞星微(rockchip)等NPU,支持非常薄弱或几乎为零,需要复杂的模型转换和移植工作。
-
-
-
部署生态的局限性
-
偏向 Python 生态:ultralytics 的核心推理 API 是 Python 版本的,这对于需要 C++, C#, Java, JavaScript 等语言进行集成的工业级应用来说非常不友好。虽然可以通过将模型导出为 ONNX 等格式后,用其他语言的推理引擎加载,但这意味着脱离了 ultralytics 便捷的后处理(NMS)、数据增强等 pipeline,需要用户自己重新实现,增加了开发成本和出错风险。
-
缺乏服务化工具:库本身没有提供现成的、高性能的模型服务化(Model Serving)工具,例如基于web API 的推理服务、批处理系统、负载均衡和监控等。构建一个高并发的推理服务需要用户基于 Web 框架(如 FastAPI)进行二次开发,并自行处理线程/进程安全、GPU 资源管理等一系列复杂问题。
-
-
高级功能支持不足
-
量化支持有限且不成熟:虽然 PyTorch 提供了量化感知训练(QAT)和训练后动态量化(PTDQ)的工具,但 ultralytics 官方对此的支持和示例相对较少。对于 INT8 量化这种对边缘部署至关重要的技术,用户往往需要自行摸索,且很容易遇到精度下降严重或转换失败的问题,远不如 TensorRT 或 OpenVINO 的量化工具链成熟和稳定。
-
模型编译与优化缺失:没有内置的模型编译(Compiler)功能,无法像 TVM、Apache MXNet 那样将模型编译为高度优化的、针对特定硬件平台的低级代码,以牺牲编译时间来换取极致的运行时性能。
-
-
分布式推理支持较弱
- 对于需要处理超高分辨率图像或极低延迟要求的场景,可能需要将单张图像切分(tile)并在多个 GPU 上并行推理,最后再合并结果。ultralytics 库虽然内置了sahi的推理示例,但是深度优化需要用户自己实现,技术门槛较高。
因此,一个常见的成熟工作流是:使用 Ultralytics 进行模型训练、验证和实验(优势领域),然后将其导出的模型(如 ONNX)交给 TensorRT 或 OpenVINO 等专门的推理引擎去部署,从而在享受开发便捷性的同时,获得生产环境所需的极致性能和部署灵活性。 意识到这些“弊端”,是为了更好地在不同阶段选用合适的工具,而非否定其价值。
二、onnx与onnxruntime简介
面对ultralytics训练完的模型,我们要转到硬件平台上做到性能极致的推理就离不开多个平台模型的转换,不同的平台有各自的定义格式,如NVIDIA的engine、Ascend的om、瑞星微的rknn,如果要多种训练框架训练后的模型转换到专业平台上,则需要一个统一的桥梁,而现阶段小模型最常见的桥梁便是onnx模型。
-
ONNX:开放的模型交换标准
ONNX 的核心价值在于它定义了一个与框架和硬件无关的、开放式的计算图模型标准。它成功地充当了深度学习领域的“通用语”。-
框架解耦:它将模型开发(在 PyTorch/TensorFlow/PaddlePaddle 中完成)与模型部署(在各种推理引擎上完成)两个阶段清晰地分离开。研究者可以永远使用最顺手的框架进行创新和实验,而工程师则可以选择最适合目标硬件的推理引擎进行部署,双方在 ONNX 这个交界点上达成一致。
-
简化转换流程:在没有 ONNX 之前,要将一个 PyTorch 模型部署到 NVIDIA TensorRT,可能需要编写复杂的插件和层定义来兼容不支持的算子。如今,这一过程被简化为:PyTorch -> ONNX -> TensorRT。对于其他硬件平台,流程也同样变为 PyTorch -> ONNX -> OpenVINO / CoreML / RKNN / …。这极大地降低了转换的复杂度和维护成本。
-
算子生态系统:ONNX 定义了一套不断扩大的标准算子集(Operators),覆盖了大多数常见的深度学习操作。这保证了主流框架的大多数模型都能找到对应的导出路径。
-
-
ONNX Runtime:高性能跨平台推理引擎
如果说 ONNX 是“通用语”,那么 ONNX Runtime (ORT) 就是第一位也是最通用的一位“翻译官”。它是一个为运行 ONNX 模型而设计的高性能推理引擎。-
统一 API,多种后端:ORT 最强大的特性是其执行提供程序(Execution Providers, EP) 机制。它提供了一个统一的 API,但允许开发者选择不同的 EP 来底层调用特定硬件的加速库。
-
CPU: CPUExecutionProvider,使用高度优化的 MLAS、Eigen 等库。
-
NVIDIA GPU: CUDAExecutionProvider (使用 CUDA/cuDNN) 和 TensorRTExecutionProvider (直接调用 TensorRT,能进行更深度的优化)。
-
Intel CPU/GPU: OpenVINOExecutionProvider,直接利用 Intel OpenVINO 工具套件的优化能力。
-
AMD GPU: DMLExecutionProvider (DirectML),适用于 Windows 平台。
-
Android NNAPI: NNAPIExecutionProvider,调用安卓设备的神经网络 API。
-
Apple Silicon: CoreMLExecutionProvider,为 Apple 设备原生加速。
这意味着,同一份 ONNX 模型文件和几乎相同的代码,只需在运行时切换 EP,就可以在从云到边的各种设备上以接近原生性能运行。
-
-
较为理想的性能优化:ORT 团队会对计算图进行大量优化,包括:
-
图优化:常量折叠、算子融合(如将 Conv-BatchNorm-ReLU 融合为一个算子)、冗余节点消除等。
-
内核优化:为每个算子和硬件目标编写了高度优化的内核实现。
-
量化支持:支持静态和动态量化,显著降低模型大小和提高 INT8 硬件上的推理速度,但是需要注意精度问题。
-
-
多语言支持:ORT 提供了丰富的 API 支持,包括 Python, C++, C#, C, Java, JavaScript 等。这使得它不仅能用于 Python 研究环境,更能无缝集成到由 C++ 编写的高性能服务器、由 C# 编写的桌面应用、由 Java 编写的安卓应用或由 JavaScript 编写的 Web 应用中,真正实现了模型的“一次转换,随处部署”。
-
三、onnxruntime实战测试
- 本次测试平台:
- os: windows 10
- cpu:i5-12490f
- gpu:rtx3080
- RAM: 16G GDDR4 3200Hz
- cudnn:11.6
我们采用如下公式计算并发的FPS数量:
FPS=1000推理时间ms×N\text{FPS} = \frac{1000}{\text{推理时间}_{\text{ms}}} \times N FPS=推理时间ms1000×N
3.1 onnxruntime的安装
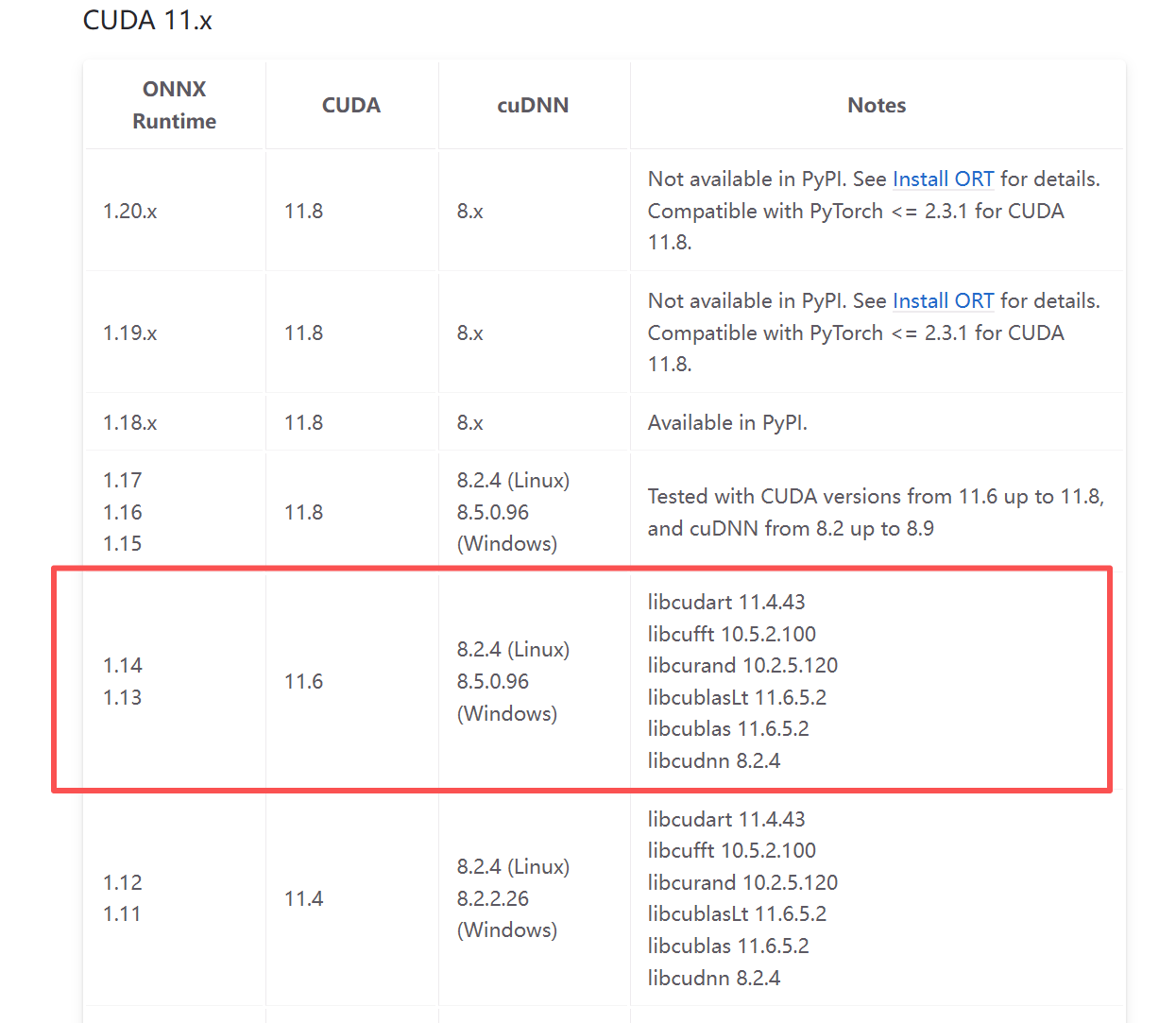
测试平台是NVIDIA显卡,CUDNN版本为11.6,基于onnx官方给出的链接,如下图所示:
- 我们直接在python环境中安装:
pip install onnxruntim-gpu==1.14.0
- 而后我们直接使用ultralytics库导出onnx
3.2 ultralytics直接导出onnx
from ultralytics import YOLO# Load a model
# model = YOLO("yolo11n.pt") # load an official model
model = YOLO(r"D:\academic\csgo_\ultralytics\weights\yolo11n.pt") # load a custom trained model# Export the model
model.export(format="onnx",opset = 14)
3.3 基于onnxruntime的yolo11n推理测试
- 我们基于以下代码进行onnxruntime的推理测试
import cv2
import numpy as np
import onnxruntime as ort
from PIL import Image
import time
import multiprocessing# 配置参数
MODEL_PATH = r"path to \yolo11n.onnx" # 替换为你的ONNX模型路径
IMAGE_PATH = r"path to \test.png" # 替换为测试图片路径
CONF_THRESH = 0.5 # 置信度阈值
IOU_THRESH = 0.45 # IOU阈值# 初始化ONNX Runtime
def init_session(model_path):# 配置CUDA执行提供器providers = [('CUDAExecutionProvider', {'device_id': 0, # 使用第一个GPU}),]# 创建会话session = ort.InferenceSession(model_path,providers=["CUDAExecutionProvider"],sess_options=ort.SessionOptions())return session# Letterbox图像预处理
def preprocess(image, target_size=640):# 获取原始图像尺寸h, w = image.shape[:2]# 计算缩放比例scale = min(target_size / h, target_size / w)nh, nw = int(h * scale), int(w * scale)# 调整图像大小resized = cv2.resize(image, (nw, nh), interpolation=cv2.INTER_LINEAR)# 创建画布并填充canvas = np.full((target_size, target_size, 3), 114, dtype=np.uint8)# 计算放置位置(居中)dx = (target_size - nw) // 2dy = (target_size - nh) // 2canvas[dy:dy + nh, dx:dx + nw] = resized# 转换颜色空间和归一化input_img = canvas.astype(np.float32) / 255.0input_img = input_img.transpose(2, 0, 1)[None] # HWC -> CHW -> 添加批次维度return input_img, (w, h), scale, (dx, dy)# 后处理(非极大值抑制)
def postprocess(outputs, orig_size, scale, padding, conf_thresh=0.25, iou_thresh=0.45):# 转换输出为NumPy数组predictions = np.squeeze(outputs[0]).T# 过滤低置信度检测scores = np.max(predictions[:, 4:], axis=1)predictions = predictions[scores > conf_thresh]scores = scores[scores > conf_thresh]if len(scores) == 0:return []# 获取类别IDclass_ids = np.argmax(predictions[:, 4:], axis=1)# 提取边界框 (xywh)boxes = predictions[:, :4]# 将边界框从中心格式转换为角点格式boxes[:, 0] = boxes[:, 0] - boxes[:, 2] / 2 # x1boxes[:, 1] = boxes[:, 1] - boxes[:, 3] / 2 # y1boxes[:, 2] = boxes[:, 0] + boxes[:, 2] # x2boxes[:, 3] = boxes[:, 1] + boxes[:, 3] # y2# 调整边界框到原始图像尺寸dx, dy = paddingboxes[:, [0, 2]] = (boxes[:, [0, 2]] - dx) / scale # xboxes[:, [1, 3]] = (boxes[:, [1, 3]] - dy) / scale # y# 裁剪边界框到原始图像尺寸boxes[:, 0] = np.clip(boxes[:, 0], 0, orig_size[0]) # x1boxes[:, 1] = np.clip(boxes[:, 1], 0, orig_size[1]) # y1boxes[:, 2] = np.clip(boxes[:, 2], 0, orig_size[0]) # x2boxes[:, 3] = np.clip(boxes[:, 3], 0, orig_size[1]) # y2# 计算边界框宽度和高度boxes[:, 2] -= boxes[:, 0] # wboxes[:, 3] -= boxes[:, 1] # h# 执行非极大值抑制indices = cv2.dnn.NMSBoxes(boxes.tolist(), scores.tolist(), conf_thresh, iou_thresh)results = []if indices is not None:for i in indices:idx = i if isinstance(i, np.int32) else i[0]box = boxes[idx]score = scores[idx]class_id = class_ids[idx]results.append([int(class_id), float(score), [float(x) for x in box]])return results# 主函数
def main(index: int):# 初始化模型session = init_session(MODEL_PATH)input_name = session.get_inputs()[0].name# 加载图像orig_img = cv2.imread(IMAGE_PATH)if orig_img is None:print(f"Error: 无法加载图像 {IMAGE_PATH}")return# 预处理和推理循环count = 0res = []while True:count += 1start = time.time()input_img, orig_size, scale, padding = preprocess(orig_img)outputs = session.run(None, {input_name: input_img})detections = postprocess(outputs, orig_size, scale, padding, CONF_THRESH, IOU_THRESH)inference_time = time.time() - startres.append(inference_time)if count % 100 == 0:print(f"进程:{index},推理时间: {sum(res) /100 * 1000:.2f} ms")res.clear()if __name__ == "__main__":t1 = multiprocessing.Process(target=main, args=(1,), daemon=True).start()while True:time.sleep(1)"""进程:1,推理时间: 12.24 ms进程:1,推理时间: 12.25 ms进程:1,推理时间: 11.83 ms进程:1,推理时间: 12.15 ms进程:1,推理时间: 11.48 ms进程:1,推理时间: 12.55 ms进程:1,推理时间: 11.89 ms进程:1,推理时间: 12.11 ms进程:1,推理时间: 11.64 ms进程:1,推理时间: 12.32 ms进程:1,推理时间: 12.09 ms进程:1,推理时间: 11.40 ms进程:1,推理时间: 12.01 ms进程:1,推理时间: 12.50 ms
"""- 可以看到本地的测试时间(预处理-推理-后处理)平均在12ms左右,帧率约为83FPS
- 为了提高并发量,我们可以同时运行多个模型进行时间分析,只需要在启动的时候多启动一些进行,便可模拟这一操作。
if __name__ == "__main__":t1 = multiprocessing.Process(target=main, args=(1,), daemon=True).start()t2 = multiprocessing.Process(target=main, args=(2,), daemon=True).start()t3 = multiprocessing.Process(target=main, args=(3,), daemon=True).start()while True:time.sleep(1)
"""
进程:1,推理时间: 22.73 ms
进程:2,推理时间: 22.03 ms
进程:3,推理时间: 22.44 ms
进程:1,推理时间: 21.67 ms
进程:3,推理时间: 22.01 ms
进程:2,推理时间: 22.45 ms
进程:1,推理时间: 22.03 ms
进程:3,推理时间: 21.96 ms
进程:2,推理时间: 22.29 ms
进程:1,推理时间: 21.33 ms
进程:3,推理时间: 22.11 ms
进程:2,推理时间: 22.25 ms
"""
- 可以看到三个进程的推理平均时间为22ms,虽然相比于单一进程的12ms有10ms的时间增长,但是并发的帧率约为:136FPS
- 同理当我们开启到5个进程时,平均推理时间为34ms,总FPS约为:147FPS
进程:1,推理时间: 33.20 ms
进程:5,推理时间: 33.40 ms
进程:4,推理时间: 34.16 ms
进程:3,推理时间: 34.32 ms
进程:2,推理时间: 35.07 ms
进程:1,推理时间: 33.61 ms
进程:5,推理时间: 34.25 ms
进程:4,推理时间: 33.95 ms
进程:3,推理时间: 34.74 ms
进程:2,推理时间: 34.59 ms
- 受限于推理资源和硬件限制,更多的线程开启时,帧率并不会线性增长,而是在某一数量后趋于稳定
3.4基于ultralytics的推理测试
- 测试代码:
from ultralytics import YOLO
import cv2
import time
import multiprocessing
load_path = "./weights/yolo11n.pt"
IMAGE_PATH = r"D:\academic\csgo_\ultralytics\data\test.png"def main(index: int):model = YOLO(load_path, verbose=False)model.eval()orig_img = cv2.imread(IMAGE_PATH)count = 0res = []while True:count += 1start = time.time()results = model(orig_img, conf=0.5,classes=0.45, verbose=False)inference_time = time.time() - startres.append(inference_time)if count % 100 == 0:print(f"进程:{index},推理时间: {sum(res) / 100 * 1000:.2f} ms")res.clear()if __name__ == "__main__":t1 = multiprocessing.Process(target=main, args=(1,), daemon=True).start()t2 = multiprocessing.Process(target=main, args=(2,), daemon=True).start()t3 = multiprocessing.Process(target=main, args=(3,), daemon=True).start()t4 = multiprocessing.Process(target=main, args=(4,), daemon=True).start()t5 = multiprocessing.Process(target=main, args=(5,), daemon=True).start()while True:time.sleep(1)
"""
单一进程约9ms,FPS约:111FPS
三进程约15ms,FPS约:200FPS
三进程以上现存分配出错,导致无法初始化资源
"""
3.5 章节小节
- onnxruntime与ultralytics推理对比
| 进程数 | onnxruntime | ultralytics |
|---|---|---|
| 1 | CPU: 15% RAM: 4822MB GPU: 2.3G FPS: 90 | CPU: 15% RAM:5904MB GPU: 2.6G FPS:111 |
| 3 | CPU: 40% RAM: 9800MB GPU: 4.8G FPS:140 | CPU: 40% RAM: 6300MB GPU: 5.8G FPS: 200 |
| 4 | … … | × |
| 6 | CPU: 75% RAM: 9840MB GPU: 8.5G FPS: 150 | × |
-
优化路径与性能差异:
-
Ultralytics (PyTorch) 的推理路径是高度定制化的。其代码和计算图是针对 YOLO 系列模型深度优化过的,算子融合充分,并且与 PyTorch 的 CUDA 内核紧密结合。因此,在 单进程 情况下,其 FPS 最高(111 vs 90),体现了“专用工具”的优势。
-
ONNX Runtime 是一个通用推理引擎。它将模型转换为标准计算图后进行优化,其优化是通用性的(如图优化、常量折叠)。虽然高效,但可能无法做到框架原生的极致优化,导致在相同硬件上单进程性能略低于原生框架。
-
-
多进程扩展性的瓶颈:
-
测试数据清晰表明,两者的多进程扩展效率都不理想。进程数从 1 增加到 6,ONNX Runtime 的 FPS 从 90 仅提升到 150(1.67倍),远未达到理想的线性增长。
-
根本原因:无论是 PyTorch 还是 ONNX Runtime 的 CUDA EP,其多进程推理的瓶颈通常在于 GPU 内核的调度竞争 和 Python GIL(全局解释器锁) 的开销。多个进程频繁地向 GPU 提交计算任务,会产生大量的调度开销,导致 GPU 利用率无法随进程数线性增长,甚至可能下降。您数据中 6 进程 FPS 反而低于 3 进程,很可能触发了某个性能拐点。
-
-
资源消耗模式的不同:
-
内存:ONNX Runtime 进程间内存隔离,导致总内存占用随进程数近乎线性增长(1进程 4822MB → 6进程 9840MB)。而 Ultralytics 在 3 进程时内存控制得更好(6300MB),这可能得益于 PyTorch 内部的一些内存管理机制。
-
GPU:Ultralytics 显存占用更高,暗示其可能为提升性能而使用了更多的显存资源(如更大的 CUDA 内核缓存)。
-
为什么必须引入 TensorRT 和 OpenVINO等专业推理工具?
上述测试中的方案,本质上是“用通用工具干专业的事”,其性能天花板很低。要突破这个天花板,就必须使用为推理而生的专业工具:TensorRT 、OpenVINO等。它们的核心价值在于:
- 极致的硬件专属优化(突破单进程性能极限)
-
通用框架为了兼容性,必须使用标准算子。而专业推理引擎则不同:
-
TensorRT (NVIDIA):它会将网络中的多个层(如 Conv + BN + ReLU)融合(Fusion) 为一个单一、高度优化的 GPU 内核。这极大地减少了数据在 GPU 显存中的搬运次数和内核启动开销,这是其性能远超 PyTorch/ORT 的根本原因。同时,它提供成熟的 INT8 量化支持,进一步压榨 Tensor Core 的算力。
-
OpenVINO (Intel):它同样会对计算图进行深度优化与层融合,并利用 Intel CPU 特有的指令集(如 AVX-512、AMX)及硬件特性,为 Intel 架构量身定制执行代码,最大化 CPU 的吞吐能力。
-
-
这意味着,仅使用单进程,TensorRT/OpenVINO 就能实现超越 ONNX Runtime 或 Ultralytics 的 FPS。
-
先进的并发模型(突破多进程扩展瓶颈)
-
“启动多个Python进程”是一种低效、资源浪费的并发方案。专业引擎提供了更底层的解决方案:
-
TensorRT 的执行上下文(ExecutionContext):可以在单个进程内创建多个执行上下文。每个上下文持有模型参数,但拥有独立的推理状态。这使得单进程内并行处理多个流成为可能,完美避免了多进程带来的 GPU 调度竞争和 Python GIL 开销,真正实现了高效的并发推理。
-
动态批处理(Dynamic Batching):专业推理服务器(如 NVIDIA Triton)可以收集多个传入的请求,并将其动态组合成一个更大的批次进行推理,大幅提升 GPU 利用率和吞吐量。这是简单多进程方案无法实现的。
-
-
-
统一的硬件抽象层
它们提供了一个统一的 API,但底层却调用着为硬件量身定制的极致优化库(如 TensorRT 调用 cuDNN、cuBLAS;OpenVINO 调用 MKL-DNN),将应用层与复杂的硬件优化细节解耦。开发者无需关心底层实现,就能获得当前硬件的最佳性能。
总结
在模型部署的生产环境中,仅仅满足于“能跑”是远远不够的。
-
Ultralytics (PyTorch) 和 ONNX Runtime 是出色的研究和原型验证工具,它们提供了无与伦比的易用性和灵活性。
-
但当进入生产部署阶段,追求的是极致的性能、最低的资源成本和最高的稳定性时,TensorRT 和 OpenVINO 这类专业的推理引擎就不再是“可选项”,而是“必选项”。它们通过底层的、颠覆性的优化策略,解决了通用框架在并发和性能上的固有缺陷,最终目的是将昂贵的硬件计算力(无论是 GPU 还是 CPU)转化为实实在在的、可线性扩展的推理吞吐量。这才是其不可替代的核心价值所在。
我们也将逐步深入专业推理工具,实现高效的模型推理。
下期预告
- 模型量化基础及实践
- 专业推理工具的尝试