K8s Pod驱逐机制详解与实战
目录
一、Pod驱逐
1、为什么要有驱逐
2、驱逐机制
3、Pod eviction(Pod 驱逐)
3.1、resource 的 requests 和 limits
3.2、QoS 类别
3.3、PriorityClass 和 Priority
二、Pod驱逐实战案例
1、k8s pod内存驱逐问题解决
1.1、查看pod状态:
1.2、查看pod事件日志:
1.3、排查节点内存监控
1.4、思考内存驱逐的原理
一、 HPA解决的问题
二、原理架构
三、HPA的metrics的分类
四、 HPA的使用说明
五、HPA扩缩容算法具体实现
5.1 算法模型
5.2 扩缩容threshold控制
5.3 缩容冷却机制(cooldown delay)
5.4 Pod的metrics数据过滤检查机制
六、HPA的scale速度控制
不同扩缩容速率需求场景下的behavior用法举例
场景1:扩容越快越好
场景 2: 扩容越快越好但要逐步缩容
场景 3: 逐步扩容、正常的缩容
场景 4: 正常扩容、不要缩容
场景 5: 延后缩容
七、总结
一、Helm概述
1.1、Helm 组件及相关术语
1.2、Helm工作原理
二、Helm部署
2.1、安装方式
2.2、chart库配置
2.3、Helm命令
三、Helm Chart 详解
3.1、chart目录结构
3.2、Chart.yaml
三、helm部署案例
部署Nginx应用
四、升级与回滚
一、Pod驱逐
1、为什么要有驱逐
pod.spec.containers[].resources中会存在cpu或memory的request和limit。即该pod请求的最小资源和Node结点可以给的最大资源。
当一个容器的cpu使用率超过limit时会被进行流控,而当内存超过limit时则会被oom_kill。
完全依赖于oom_kill并不是一个很好的方案,一来对于cpu要求高的容器没有作用,二来单纯将pod杀死,并不能根本上解决困局,比如pod占用node绝大部分内存,假如pod被kill后再次调度到这个node上,oom的情况还会复现。所以kubelet增加了一套驱逐机制。 eviction中要设置触发驱逐的阈值Eviction Thresholds,这个阈值的配置可以是一个定值或一个百分比。如:
memory.available<10%memory.available<1Gi2、驱逐机制
Soft Eviction Thresholds(软驱逐机制)
当node的内存/磁盘空间达到一定的阈值后,我要观察一段时间,如果改善到低于阈值就不进行驱逐,若这段时间一直高于阈值就进行驱逐。
Hard Eviction Thresholds( 强制驱逐机制)
简单的多,一旦达到阈值,立刻把pod从本地kill。
3、Pod eviction(Pod 驱逐)
当资源使用情况触发了驱逐条件时,kubelet会启动一个任务去轮流停止运行中的pod,直到资源使用状况恢复到阈值以下。以硬驱逐为例,整体流程是:
-
每隔一段时间从cadvisor中获取资源使用情况,发现触发了阈值;
-
从运行中的pod里找到QoS策略最开放的一个,比如策略为bestEffort的一个pod(即便这个pod没有吃多少内存,大部分内存是另一个策略为burstable,但内存使用率也很高的pod),kubelet停止该pod对应的所有容器,然后将pod状态更新为Failed。如果该pod长时间没有被成功kill掉,kubelet会再找一个pod进行驱逐。
-
检查内存用量是否恢复到阈值以下,如果没有,则重复第二步(这里就要干掉那个罪魁祸首了)。一直到内存使用情况恢复到阈值以下为止。
在 Kubernetes 中,当资源不足需要驱逐 Pod 时,系统会根据 Pod 的优先级(由 PriorityClass 的 value 决定)和 Pod 的 Quality of Service (QoS) 类别等进行决策。而调度优先级主要由 Priority 值确定。
3.1、resource 的 requests 和 limits
Requests(请求):Requests 是指容器在运行时所需的资源的最小数量。它们用于告诉 Kubernetes 调度器在选择节点时要为 Pod 预留多少资源。如果没有足够的请求资源可用,Pod 可能无法被调度到节点上。
Limits(限制):Limits 是指容器在运行时所允许使用的资源的最大数量。它们用于限制容器的资源使用,以防止容器占用过多的资源导致其他容器或节点受到影响。如果容器尝试使用超过其限制的资源量,Kubernetes 将会限制其资源使用,并可能触发容器的重新启动。
3.2、QoS 类别
-
BestEffort:没有设置 resource requests 和 limits 的 Pod。
-
Burstable:设置了 requests 或者 limits,但不完全相同。
-
Guaranteed:requests 和 limits 都设置了,并且两者值相等。
驱逐顺序:BestEffort(lowest) -> Burstable -> Guaranteed(highest)。不影响调度的优先级。
3.3、PriorityClass 和 Priority
PriorityClass(优先级类):PriorityClass 是一种用于调度和优先级管理的对象。它允许您为 Pod 分配优先级。PriorityClass 定义了一个优先级类别,其中包含一个整数值 value 表示优先级的相对值。较高的 value 值表示较高的优先级。通过将 Pod 与特定的 PriorityClass 关联,可以影响 Pod 的调度和驱逐顺序。
Priority(优先级):Priority 是一个整数值,直接应用于 Pod 对象。它表示 Pod 的绝对优先级。较高的 Priority 值表示较高的优先级。同样可以影响 Pod 的调度和驱逐顺序。
查看 PriorityClass
kubectl get priorityclasses查看系统组件 controller-manager 使用的 PriorityClass
[root@k8s-master ~]# kubectl describe pod -n kube-system kube-controller-manager-k8s-master | grep -i priority
Priority: 2000001000
Priority Class Name: system-node-critical当集群中没有默认的 PriorityClass,也没有手动指定 Priority,那优先级的值就为 0。优先级的值越小,驱逐顺序越靠前,调度顺序越靠后。
还有一种情况是:尽管 PriorityClass 的 value 值大,但是 BestEffort 类型的 qos class 会比Burstable 或 Guaranteed 类别更容易被驱逐。当然还会有其他因素也会影响 pod 的驱逐顺序,但是影响力不如上面两种大,例如:Pod资源使用量越接近 limits,和 pod 运行时长越短等,那么这些 Pod 会被优先考虑驱逐。
当集群内有比较重要的服务时,可以把 Qos Class 设置为 Guaranteed,也就是都指定了 requests 和 limits 并且二者值相等,会有长时间运行稳定性的优势。且 Priority 的值尽可能设置大些,会有优先占用集群资源资源的优势。
在K8s 1.6之后还引入了Taint的两个新特性,TaintNodesByCondition与TaintBasedEvictions用来改善出现异常时对Pod的调度与驱逐问题
TaintNodesByCondition
特性如下(为节点添加NoSchedule的污点)
-
Node节点会不断的检查Node的状态,并且设置对应的Condition
-
不断地根据Condition的变更设置对应的Taint
-
不断地根据Taint驱逐Node上的Pod
主要污点如下:
node.kubernetes.io/not-ready 节点未就绪,节点Ready为False
node.kubernetes.io/unreachable 节点不可达
node.kubernetes.io/out-of-disk 磁盘空间已满
node.kubernetes.io/network-unavailable 网络不可用
node.kubernetes.io/unschedulable 节点不可调度
node.cloudprovider.kubernetes.io/uninitialized 如果 kubelet 从 外部 云服务商启动的,该污点用来标识某个节点当前为不可用状态,当云控制器 cloud-controller-manager 初始化这个节点后,kubelet 会将此污点移除
TaintBasedEvictions
特性添加的是NoExecute的污点,例如内存与磁盘有压力时,如果Pod没有设置容忍这些污点,则会被驱逐,以保证Node不会崩溃
主要污点如下:
node.kubernetes.io/memory-pressure 内存不足
node.kubernetes.io/disk-pressure 磁盘不足
1.13版本之后TaintNodesByCondition 与 TaintBasedEvictions 都是默认开启
二、Pod驱逐实战案例
1、k8s pod内存驱逐问题解决
背景:突然收到 web 无法访问告警,然后发现前段应用pod状态为Evicted,证明pod是被驱逐了
排查过程:
1.1、查看pod状态:
kubectl get pods
kubectl get pods -A | grep 0/1web-nginx-865674789f-c7bv4 0/1 Evicted 0 25h <none> 192.168.3.10 <none>web-nginx-865674789f-ggb27 0/1 Evicted 0 25h <none> 192.168.3.10 <none>web-nginx-865674789f-fwp94 0/1 Evicted 0 25h <none> 192.168.3.10 <none>web-nginx-865674789f-djj46 0/1 Evicted 0 25m <none> 192.168.3.10 <none>1.2、查看pod事件日志:
kubectl describe pods web-nginx-xxx从日志上可以看出来是内存不足导致了驱逐
Events:Type Reason Age From Message---- ------ ---- ---- -------Warning Evicted 2m (x1 over 2m) kubelet The node was low on resource: [MemoryPressure].1.3、排查节点内存监控
发现利用率在50%,没理由会导致内存不足
1.4、思考内存驱逐的原理
1.4.1 K8S通过kubelet来配置pod的驱逐参数,如果没有配置,则使用默认值。检查下驱逐阈值。
# 硬性驱逐条件
evictionHard:memory.available: "200Mi"nodefs.available: "10%"nodefs.inodesFree: "5%"imagefs.available: "15%"
# 软性驱逐条件
evictionSoft:memory.available: "300Mi"nodefs.available: "15%"imagefs.available: "20%"
# 软性驱逐条件的宽限期
evictionSoftGracePeriod:memory.available: "1m"nodefs.available: "1m"imagefs.available: "1m"
# 驱逐Pod前的最大宽限期
evictionMaxPodGracePeriod: 60
#驱逐开始前等待资源压力状态稳定的时间
evictionPressureTransitionPeriod: "5m"硬性驱逐和软性驱逐的区别:
-
硬性驱逐是当资源达到或超过设定的硬性驱逐阈值时,Kubelet立即执行驱逐操作。硬性驱逐的特点是直接且无延迟。
-
软性驱逐是在资源使用达到设定的软性驱逐阈值后,给Pod一个宽限期(Grace Period)。如果在宽限期结束后资源使用仍然没有降低,Kubelet才会驱逐Pod。
1.4.2 查看node可用内存
kubectl describe nodeAllocatable:cpu: 15400mephemeral-storage: 1043358208Kihugepages-1Gi: 0hugepages-2Mi: 0memory: 63242364Ki #可分配60G内存pods: 253可分配内存为60G,而服务器内存为100G,
和现场同学(一线工程师)确认,问题出现前由于内存占用很高,做过一次在线扩容。
故障复盘:故障原因为前期内存资源不足后,虚拟机采用在线扩容内存的方式,服务器没有重启,并且K8S的kubelet服务也没有重启,获取到的内存配置仍然是60G,所以当主机内存达到60G的时候出现pod由于内存不足产生驱逐。
至于监控,node-exporter可以动态获取主机物理资源,所以过于依赖监控却忽略了检查kubelet。
优化方案:对node内存和kubelet可分配内存做对比,如果相差大于1G则触发告警
一、 HPA解决的问题
HPA全称是 Horizontal Pod Autoscaler,也就是对k8s的workload的副本数进行自动水平扩缩容(scale)机制,也是k8s里使用需求最广泛的一种Autoscaler机制,在开始详细介绍HPA之前,先简单梳理下k8s autoscale的整个大背景。
k8s被誉为新一代数据中心操作系统(DCOS),说到操作系统我们自然想到其定义:管理计算机的软硬件资源的系统,k8s也一样其核心工作也是管理整个集群的计算资源,并按需合理分配给系统里的程序(以Pod为基础的各种workload)。
其本质是解决资源与业务负载之间供需平衡的问题,随着业务需求和部署规模的增大,k8s集群就要相应扩容计算资源,集群扩容的最直接的办法是新增资源,一般单机器很难垂直扩展(k8s node也不支持),所以一般都是直接增加节点。但是随着机器的不断增加成本也不断加大,而实际上大量服务大部分时间负载很低导致机器的整体使用率很低,一方面业务为了应对每日随机流量高峰会把副本数尽量扩得很高,另一方面业务方并不能准确评估服务实际需要的CPU等资源,也出现大量浪费。
为了解决业务服务负载时刻存在的巨大波动和资源实际使用与预估之间差距,就有了针对业务本身的“扩缩容”解决方案: Horizontal Pod Autoscaler(HPA)和 Vertical Pod Autoscaler(VPA)。
为了充分利用集群现有资源优化成本,当一个资源占用已经很大的业务需要扩容时,其实可以先尝试优化业务负载自身的资源需求配置(request与实际的差距),只有当集群的资源池确实已经无法满足负载的实际的资源需求时,再调整资源池的总量保证资源的可用性,这样可以将资源用到极致。
所以总的来说弹性伸缩应该包括:
-
Cluster-Autoscale: 集群容量(node数量)自动伸缩,跟自动化部署相关的,依赖iaas的弹性伸缩,主要用于虚拟机容器集群
-
Vertical Pod Autoscaler: 工作负载Pod垂直(资源配置)自动伸缩,如自动计算或调整deployment的Pod模板limit/request,依赖业务历史负载指标
-
Horizontal-Pod-Autoscaler: 工作负载Pod水平自动伸缩,如自动scale deployment的replicas,依赖业务实时负载指标
其中VPA和HPA都是从业务负载角度从发的优化,VPA是解决资源配额(Pod的CPU、内存的limit/request)评估不准的问题,HPA则要解决的是业务负载压力波动很大,需要人工根据监控报警来不断调整副本数的问题,有了HPA后,被关联上HPA的deployment,后续副本数修改就不用人工管理,HPA controller将会根据业务忙闲情况自动帮你动态调整。当然还有一种固定策略的特殊HPA: cronHPA,也就是直接按照cron的格式设定扩容和缩容时间及对应副本数,这种不需要动态识别业务繁忙度属于静态HPA,适用于业务流量变化有固定时间周期规律的情况,这种比较简单可以算做HPA的一种简单特例。
二、原理架构
既然是自动根据业务忙闲来调整业务工作负载的副本数,其实HPA的实现思路很容易想到:通过监控业务繁忙情况,在业务忙时,就要对workload扩容副本数;等到业务闲下来时,自然又要把副本数再缩下去。所以实现水平扩缩容的关键就在于:
-
如何识别业务的忙闲程度
-
使用什么样的副本调整策略
kubernetes提供了一种标准metrics接口(整个HPA及metrics架构如下图所示),HPA controller通过这个统一metrics接口可以查询到任意一个HPA对象关联的deployment业务的繁忙指标metrics数据,不同的业务的繁忙指标均可以自定义,只需要在对应的HPA里定义关联deployment对应的metrics即可。
标准的metrics查询接口有了,还需要实现metrics API的服务端,并提供各种metrics数据,我们知道k8s的所有核心组件之间都是通过apiserver进行通信,所以作为k8s API的扩展,metrics APIserver自然选择了基于API Aggregation聚合层,这样HPA controller的metrics查询请求就自动通过apiserver的聚合层转发到后端真实的metrics API的服务端(对应下图的Promesheus adapter和Metrics server)。
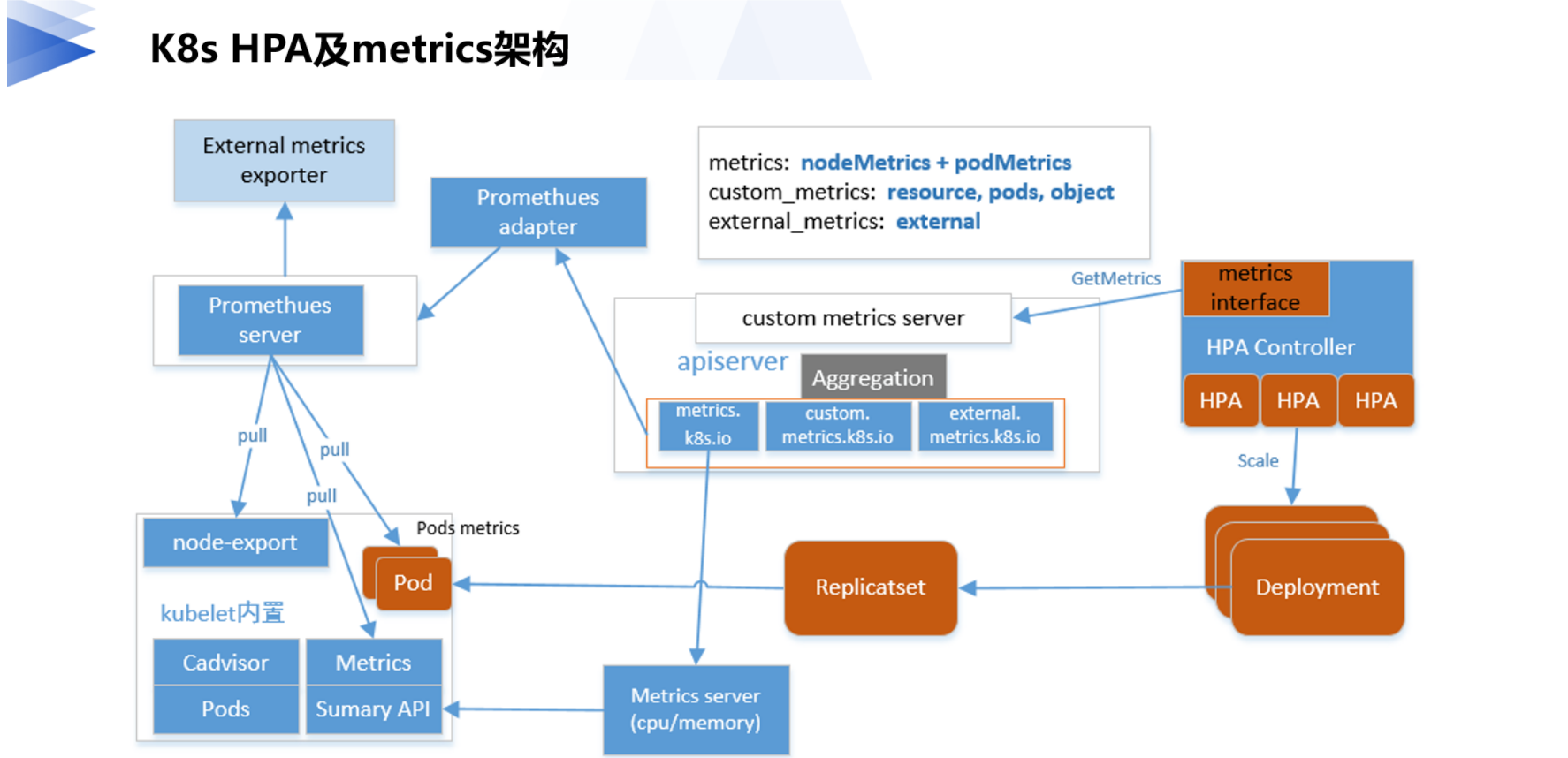
最早的metrics数据是由metrics-server提供的,只支持CPU和内存的使用指标,metrics-serve通过将各node端kubelet提供的metrics接口采集到的数据汇总到本地,因为metrics-server是没有持久模块的,数据全在内存中所以也没有保留历史数据,只提供当前最新采集的数据查询,这个版本的metrics对应HPA的版本是autoscaling/v1(HPA v1只支持CPU指标)。
后来为了适应更灵活的需求,metrics API开始扩展支持用户自定义metrics指标(custom metrics),自定义数据则需要用户自行开发custom metrics server,社区有提供专门的custom adpater框架 custom-metrics-apiserver ,该框架定义了Custom和External的MetricsProvider接口(如下所示),需要自行实现对应的接口。
type MetricsProvider interface {CustomMetricsProviderExternalMetricsProvider
}type CustomMetricsProvider interface {// GetMetricByName fetches a particular metric for a particular object.// The namespace will be empty if the metric is root-scoped.GetMetricByName(name types.NamespacedName, info CustomMetricInfo, metricSelector labels.Selector) (*custom_metrics.MetricValue, error)// GetMetricBySelector fetches a particular metric for a set of objects matching// the given label selector. The namespace will be empty if the metric is root-scoped.GetMetricBySelector(namespace string, selector labels.Selector, info CustomMetricInfo, metricSelector labels.Selector) (*custom_metrics.MetricValueList, error)// ListAllMetrics provides a list of all available metrics at// the current time. Note that this is not allowed to return// an error, so it is reccomended that implementors cache and// periodically update this list, instead of querying every time.ListAllMetrics() []CustomMetricInfo
}type ExternalMetricsProvider interface {GetExternalMetric(namespace string, metricSelector labels.Selector, info ExternalMetricInfo) (*external_metrics.ExternalMetricValueList, error)ListAllExternalMetrics() []ExternalMetricInfo
}目前社区已经有人基于promethus server的监控数据源,实现看一个promethus adapter来提供 custom metrics server服务,如果需要的自定义指标数据已经在promesheus里有了,可以直接对接使用,否则要先把自定义的指标数据注入到promesheus server里才行。因为HPA的负载一般来源于监控数据,而promesheus又是CNCF标准的监控服务,所以这个promesheus adapter基本也可以满足我们所有自定义metrics的HPA的扩展需求。
讲清楚了metrics,也就解决了识别业务的忙闲程度的问题,那么HPA Controller是怎么利用metrics数据进行扩缩容控制的呢,也就是使用什么样的副本调整机制呢?
如上图右边所示,用户需要在HPA里设置的metrics类型和期望的目标metrics数值,HPA Controller会定期(horizontal-pod-autoscaler-sync-period配置,默认15s)reconcile每个HPA对像,reconcile里面又通过metrics的API获取该HPA的metrics实时最新数值(在当前副本数服务情况下),并将它与目标期望值比较,首先根据比较的大小结果确定是要扩缩容方向:扩容、缩容还是不变,若不需要要进行扩缩容调整就直接返回当前副本数,否则才使用HPA metrics 目标类型对应的算法来计算出deployment的目标副本数,最后调用deployment的scale接口调整当前副本数,最终实现尽可能将deployment下的每个pod的最终metrics指标(平均值)基本维持到用户期望的水平。注意HPA的目标metrics是一个确定值,而不是一个范围。
三、HPA的metrics的分类
要支持最新的custom(包括external)的metrics,也需要使用新版本的HPA:autoscaling/v2beta1,里面增加四种类型的Metrics:Resource、Pods、Object、External,每种资源对应不同的场景,下面分别说明:
-
Resource支持k8s里Pod的所有系统资源(包括cpu、memory等),但是一般只会用cpu,memory因为不太敏感而且跟语言相关:大多数语言都有内存池及内置GC机制导致进程内存监控不准确。
-
Pods类型的metrics表示cpu,memory等系统资源之外且是由Pod自身提供的自定义metrics数据,比如用户可以在web服务的pod里提供一个promesheus metrics的自定义接口,里面暴露了本pod的实时QPS监控指标,这种情况下就应该在HPA里直接使用Pods类型的metrics。
-
Object类型的metrics表示监控指标不是由Pod本身的服务提供,但是可以通过k8s的其他资源Object提供metrics查询,比如ingress等,一般Object是需要汇聚关联的Deployment下的所有的pods总的指标。
-
External类型的metrics也属于自定义指标,与Pods和Object不同的是,其监控指标的来源跟k8s本身无关,metrics的数据完全取自外部的系统。
在HPA最新的版本 autoscaling/v2beta2 中又对metrics的配置和HPA扩缩容的策略做了完善,特别是对 metrics 数据的目标指标值的类型定义更通用灵活:包括AverageUtilization(平均利用率)、AverageValue(平均值)和Value,但是不是所有的类型的Metrics都支持三种目标值的,具体对应关系如下表。
HPA里的各种类型的Metrics和Metrics Target Type的对应支持关系表
| Metrics Type I Target Type | AverageUtilization | AverageValue | Value | 备注(query metrics) |
|---|---|---|---|---|
| Resource(pod's cpu/memory etc. | Yes | Yes | No | pods metrics list |
| Pods(pod's other metrics) | No | Yes | No | pods metrics list |
| Object(k8s object) | No | Yes | Yes | object metrics |
| External(not k8s object) | No | Yes | Yes | external metrics list |
四、 HPA的使用说明
先看个最简单的HPA的定义的例子
apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
metadata:name: php-apache
spec:scaleTargetRef:apiVersion: apps/v1kind: Deploymentname: nginxminReplicas: 1maxReplicas: 10metrics:- type: Resourceresource:name: cputarget:type: UtilizationaverageUtilization: 50解析
# API版本,表示这是autoscaling API的v2beta2版本
apiVersion: autoscaling/v2beta2
# 资源类型,表示这是一个HorizontalPodAutoscaler资源
kind: HorizontalPodAutoscaler
# Metadata信息,定义了HPA的
metadata:# HPA的名称name: php-apache
# Spec配置,定义了HPA的具体配置参数
spec:# 缩放目标引用,指定了要自动扩展的Deployment资源scaleTargetRef:# API版本,这是apps API的v1版本apiVersion: apps/v1# 资源类型,表示这是一个Deployment资源kind: Deployment# 要扩展的Deployment资源的名称name: php-apache# 最小副本数,HPA将确保Pod的副本数不会低于这个值minReplicas: 1# 最大副本数,HPA将确保Pod的副本数不会超过这个值maxReplicas: 10# 监控指标,用于触发Pod副本数的扩展metrics:# 类型,表示这是资源类型的监控指标type: Resource# 资源名称,这里是指CPU资源resource:# 资源名称,这里是CPUname: cpu#目标类型,表示监控的是资源的使用率target:# 目标类型,表示监控的是平均使用率type: Utilization# 期望的平均CPU使用率,当实际使用率高于这个值时,HPA会扩展Pod的副本数averageUtilization: 50从上面的例子可以看出,HPA的spec定义由三个必填部分组成:
-
HPA控制的目标workload,即scaleTargetRef,理论上HPA可以对任意支持scale子接口( sub-resource )的workload做弹性伸缩,不过statefulset一般代表有状态服务,副本不可随便修改,而Job一般代表短生命周期的,所以基本可以认为HPA目前是专门控制deployment的扩缩容的(不建议直接控制RS,否则将无法滚动升级)。
-
弹性扩缩容的上下边界,minReplicas和maxReplicas,也就是说HPA的扩缩容也不能是漫无边际,如果计算出的副本数超过max则统一取maxReplicas,maxReplicas是为了保护k8s集群的资源被耗尽,minReplicas则相反,而且minReplicas必须不大于maxReplicas,但是也要大于0(k8s v1.16之后才放开允许Objetct和External类型的metrics的minReplicas为0,需要apiserver开启–feature-gates mapStringBool HPAScaleToZero=true),两者相等就相当于关闭了自动伸缩功能了,总的来说minReplicas和maxReplicas边界机制避免metrics数据异常导致的副本数不受控,特别是HPA在k8s最新的v1.18版本也依然是alpha特性,强烈建议大家谨慎设置这两个边界。
-
metrics指标类型和目标值,在autoscaling/v1里只有targetCPUUtilizationPercentage,autoscaling/v2beta1开始就扩展为metrics数组了,也就是说一个HPA可以同时设置多个类型维度的metrics目标指标,如果有多个HPA 将会依次考量各个指标,然后最终HPA Controller选择一个会选择扩缩幅度最大的那个为最终扩容副本数。在最新的autoscaling/v2beta2版本的HPA中,metrics type共有4种类型:Resource、Pods、Object、External,target里则定义了metrics的目标期望值,这里target的type也有三种类型Utilization,AverageValue和 Value,不同的metrics type都只能支持部分target type(详见上面表格)
此外,在autoscaling/v2beta2的HPA的spec里还新增了一个Behavior可选结构,它是用来精确控制HPA的扩容和缩容的速度。
完整的HPA的定义可参考k8s的官方API文档。
默认HPA spec里不配置任何metrics的话k8s会默认设置cpu的Resouce,且目标类型是AverageUtilization value为80%。
五、HPA扩缩容算法具体实现
5.1 算法模型
在HPA控制器里,针对不同类型的metrics和不同metrics下的target 类型,都有独立的计算算法,虽然有很多细节差异,但是总的来说,计算公式可以抽象为:
desiredReplicas = ceil[currentReplicas * ( currentMetricValue / desiredMetricValue )]
例如如果配置 target value 是100m,当前从metrics接口读取到的 metrics value 是 200m,说明最新的副本数应该是当前的 200m/100m=2.0倍, 如果当前副本数为 2,则HPA计算后的期望副本数是2*2.0=4;
而如果当前从metrics接口读取到的 metrics value是 50m,说明最新的副本数应该是 当前的 50m/100m=0.5倍,也就是最终scale的副本数将为1。
当然实际上当前的metrics value并不一定就只有一个值,如果是 Resource或者Pods类型的metrics,实际上 GetMetrics 会返回一批关联的Pods对应的metrics数据,一般需要做一个平均后再与target的metrics的做比较。
此外,为了保证结果尽量精确,metrics的计算都是浮点数计算,但是最终的副本数肯定要是整数,为了统一HPA控制器在最后,都会对计算出的浮点数副本数向上取整,也就是上面公式里最外层的ceil函数。
5.2 扩缩容threshold控制
当然上面的公式也只是纯数学模型,实际工程实现还要考虑很多现实细节问题:比如监控数据可能会有一定的误差,如果GetMetrics里读到数据不稳定就会造成算出的期望副本数不稳定,导致deployment一会扩缩1个副本,一会又扩容1副本。所以为了避免这种问题kube-controller-manager里有个HPA的专属参数 horizontal-pod-autoscaler-tolerance 表示HPA可容忍的最小副本数变化比例,默认是0.1,如果期望变化的副本倍数在[0.9, 1.1] 之间就直接停止计算返回。那么如果相反,某个时间点开始metrics数据大幅增长,导致最后计算的副本数变化倍数很大,是否HPA控制器会一步扩容到位呢? 事实上HPA控制器为了避免副本倍增过快还加了个约束:单次倍增的倍数不能超过2倍,而如果原副本数小于2,则可以一次性扩容到4副本,注意这里的速率是代码写死不可用配置的。(这个也是HPA controller默认的扩缩容速率控制,autoscaling/v2beta2的HPA Behavior属性可以覆盖这里的全局默认速率)
5.3 缩容冷却机制(cooldown delay)
虽然HPA同时支持扩容和缩容,但是在生产环境上扩容一般来说重要性更高,特别是流量突增的时候,能否快速扩容决定了系统的稳定性,所以HPA的算法里对扩容的时机是没有额外限制的,只要达到扩容条件就会在reconcile里执行扩容(当前一次至少扩容到原来的1.1倍)。但是为了避免过早缩导致来回波动(thrashing ),而容影响服务稳定性甚,HPA的算法对缩容的要求比较严格,通过设置一个默认5min(可配置horizontal-pod-autoscaler-downscale-stabilization)的滑动窗口,来记录过去5分钟的期望副本数,只有连续5分钟计算出的期望副本数都比当前副本数小,才执行scale缩容操作,缩容的目标副本数取5分钟窗口的最大值。
总的来说k8s HPA算法的默认扩缩容原则是:快速扩容,谨慎缩容。
5.4 Pod的metrics数据过滤检查机制
一般情况下HPA的数据指标都来自k8s的Pod里,但是实际上每次创建deployment、对deployment做扩缩容,Pod的副本数和状态都会不断变化,这就导致HPA controller在reconcile里获取到的metrics的指标肯定会有一定的异常,比如Pod还没有Running、Pod刚刚启动还在预热期、或者Pod中间临时OOM恰逢采集时刻、或者Pod正处在删除中,这些都可能导致metrics指标缺失。如果有任何 pod 的指标缺失,HPA控制器会采取最保守的方式重新计算平均值, 在需要缩小时假设这些 pod 消耗了目标值的 100%, 在需要放大时假设这些 pod 消耗了0%目标值, 这可以在一定程度上抑制伸缩的幅度。
具体来说,HPA算法里把deployment下的所有Pod的metrics的指标数据分为三类:
-
ready pods list, deployment下处于Running状态的Pod且HPA controller成功通过GetMetrics获取的pod metrics的列表
-
ignore pods list, deployment下处于pending状态的Pods或者(仅对Resouce类似的cpu metrics有效)虽然pod running了但controller成功通过GetMetrics获取的pod metrics,但是pod的启动时间在配置的initial-readiness-delay和cpu-initialization-period 保护期内。
-
missing pods list,deployment下处于running状态的pod(非pending、非failed、非deleted状态)但是HPA controller通过GetMetrics无法获取的pod metrics的列表
在计算pod的平均metrics值的时候,统一把 ignore pods的metrics设置为最小值0,如果HPA扩缩容的方向是扩容,把missing pods的metrics也设置为最小值0,如果是缩容方向则把missing pods的metrics也设置为最大值(如果是Resouce类型,最大值是Pod的request值,否则最大值就是target value)。
六、HPA的scale速度控制
讲解完HPA的原理及具体算法后,最后再重点介绍HPA在扩缩容的速率控制机制。在前面讲过HPA controller里默认扩缩容总原则是:快速扩容,谨慎缩容,扩容上虽然强调快,但是速度却是固定的最大于当前副本数的2倍速度,对于想设置其他倍数或者说想精确控制副本数增量的方式的需求都是不行的;缩容上则仅仅只是靠设置一个集群全局的窗口时间,窗口期过后也就失去控制能力。
为了能更精准灵活地控制HPA的autoscale速度,从k8s v1.18(依赖HPA autoscaling/v2beta2)开始HPA的spec里新增了behavior结构(如下定义)扩展了HPA的scale速度控制策略,该结构支持每个HPA实例独立配置扩缩容的速度,而且还可以单独配置扩容scaleUp和缩容scaleDown使用不同的策略。
在扩容策略ScalingRules里,有个StabilizationWindowSeconds用来记录最近计算的期望副本数,效果跟上面缩容的cooldown delay机制一样,每次都会选择窗口里所有推荐值的最大值,保证结果的稳定性。
Policies是一个HPAScalingPolicy数组,每个HPAScalingPolicy才是真正控制速度的部分:扩缩容计算周期和周期内扩缩容变化的最大幅度,PeriodSeconds周期单位是秒,Percent是设置副本数每次变化的百分比,扩容后副本数是:(1+PercentValue%)* currentReplicas,缩容后副本数是:(1-PercentValue%)* currentReplicas; Pods则是设置每次副本数变化的绝对值。
次外,每个方向还可以设置多个策略,多个策略会同时计算最终副本数,最后结果则是通过SelectPolicy:Max/Min/Disabled做聚合,注意在缩容时Max会选择计算副本数最小的那个,Min会选择计算的副本数最大的那个,Disabled表示禁止这个方向的扩缩容。
type HorizontalPodAutoscalerBehavior struct {// scaleUp is scaling policy for scaling Up.// If not set, the default value is the higher of:// * increase no more than 4 pods per 60 seconds// * double the number of pods per 60 secondsScaleUp *HPAScalingRules// scaleDown is scaling policy for scaling Down.// If not set, the default value is to allow to scale down to minReplicas pods, with a// 300 second stabilization window (i.e., the highest recommendation for// the last 300sec is used).ScaleDown *HPAScalingRules
}type HPAScalingRules struct {// StabilizationWindowSeconds is the number of seconds for which past recommendations should be// considered while scaling up or scaling down.StabilizationWindowSeconds *int32// selectPolicy is used to specify which policy should be used.// If not set, the default value MaxPolicySelect is used.SelectPolicy *ScalingPolicySelect// policies is a list of potential scaling polices which can used during scaling.// At least one policy must be specified, otherwise the HPAScalingRules will be discarded as invalidPolicies []HPAScalingPolicy
}// HPAScalingPolicyType is the type of the policy which could be used while making scaling decisions.
type HPAScalingPolicyType string
const (// PodsScalingPolicy is a policy used to specify a change in absolute number of pods.PodsScalingPolicy HPAScalingPolicyType = "Pods"// PercentScalingPolicy is a policy used to specify a relative amount of change with respect to// the current number of pods.PercentScalingPolicy HPAScalingPolicyType = "Percent"
)// HPAScalingPolicy is a single policy which must hold true for a specified past interval.
type HPAScalingPolicy struct {// Type is used to specify the scaling policy.Type HPAScalingPolicyType// Value contains the amount of change which is permitted by the policy.Value int32// PeriodSeconds specifies the window of time for which the policy should hold true.// PeriodSeconds must be greater than zero and less than or equal to 1800 (30 min).PeriodSeconds int32
}HPA的Behavior如果不设置,k8s会自动设置扩缩容的默认配置, 具体内容如下:
behavior:scaleDown:stabilizationWindowSeconds: 300policies:- type: Percentvalue: 100periodSeconds: 15scaleUp:stabilizationWindowSeconds: 0policies:- type: Percentvalue: 100periodSeconds: 15- type: Podsvalue: 4periodSeconds: 15selectPolicy: Max
默认配置里分别定义了扩容和缩容的速率策略,缩容按照百分比,每15秒最多减少currentReplicas100%个副本(但最终不可小于minReplicas),且缩容后的最终副本不得低于过去300s内计算的历史副本数的最大值;扩容则采用快速扩容,不考虑历史计算值(窗口时间为0),每15秒副本翻倍或者每15秒新增4个副本(取最大值),即:max(2currentReplicas,4)。这个默认Behavior的默认配置是否有点似曾相似的感觉,没错它跟HPA没有Behavior时的默认快速扩容,缩容的策略是完全一致的。
不同扩缩容速率需求场景下的behavior用法举例
场景1:扩容越快越好
如果业务希望能尽快的扩容,可以配置大的 percent值,可以按照如下配置:
behavior:scaleUp:policies:- type: Percentvalue: 900periodSeconds: 60假如 deployment的副本数最开始是1,那么每隔60s的的极限扩容副本数的变化如下:
1 -> 10 -> 100 -> 1000
也就是每个扩容period都是(1+900%)=10倍的速度,不过最大副本数依然不可用超过HPA 的 maxReplicas上界,缩容则使用默认行为。当然Percent类型可能对资源消耗波动特别大,如果希望资源消耗可控,可以按绝对副本数来Pods类型来配置。
场景 2: 扩容越快越好但要逐步缩容
当业务希望能尽快的扩容,但是缩容需要缓慢一些时,可以使用如下配置:
behavior:scaleUp:policies:- type: Percentvalue: 900periodSeconds: 60scaleDown:policies:- type: Podsvalue: 1periodSeconds: 600假如 pod 最开始数量为 1,那么扩容路径如下:
1 -> 10 -> 100 -> 1000
同时,缩容路径如下 (每 10 分钟缩容一次,每次减少一个 pod):
1000 -> 1000 -> 1000 -> … (another 7 min) -> 999 (最小不低于minReplicas)
场景 3: 逐步扩容、正常的缩容
当希望缓慢的扩容、正常的缩容,可以使用如下配置
behavior:scaleUp:policies:- type: Podsvalue: 1periodSeconds: 600把缩容的百分比或者pod 都置为 0,那么就永远不会缩容。或者直接设置 selectPolicy: Disabled。
behavior:scaleDown:policies:- type: Podsvalue: 1periodSeconds: 600场景 4: 正常扩容、不要缩容
如果希望能正常的扩容,但是不要自动缩容,可以使用如下配置:
behavior:scaleDown:policies:- type: Percent #或 Podsvalue: 0periodSeconds: 600都置为 0,那么就永远不会缩容。或者直接设置 selectPolicy: Disabled。
behavior:scaleDown:selectPolicy: Disabled场景 5: 延后缩容
一般在流量激增时,都希望快速扩容应对,那么发现流量降低是否应该立马缩容呢,加入只是临时的流量降低呢,这样就可能导致短时间反复的扩缩容,为了避免这种情况,缩容时应该更谨慎些,可以使用延迟缩容机制:delaySeconds(这个跟 kube-controller-manager 的 horizontal-pod-autoscaler-downscale-stabilization 非常类似,但是这个参数是全局的,如果HPA有配置优先使用delaySeconds),配置如下:
behavior:scaleDown:policies:- type: Podsvalue: 5periodSeconds: 600那么,每次缩容最多减少 5 个 pod,同时每次缩容,至少要往前看 600s 窗口期的所有推荐值,每次都从窗口期中选择最大的值。这样,除非连续600s的推荐值都比之前的最大副本数小,才开始缩容。
七、总结
总的来说,从k8s v1.18开始HPA的机制已经算比较灵活了,在扩缩容识别指标上可以使用Pod的系统cpu、内存指标,也可以Pods自身暴露的自定义metrics指标,还可以支持外部的业务指标;在具体自定义实现上也提供了标准的扩展框架,还有社区其他人贡献的promesheus adapter。在扩缩容速度上也通过相对百分比和绝对 Pods数变化,可以独立控制单位时间内最大的扩容和缩容,此外还通过自定义窗口时间机制保证副本变化的稳定性。
需要说明下,HPA特性还依然处于非正式GA版本,社区相关的issue有些没有解决,包括HPA缩容的最小副本不允许为0(Resouce和Pods类型的metrics如果在pod副本为0时,将采集不到metrics,需要依赖额外的流量激活机制,Knative集成了service mesh有对流量的劫持所以可以直接实现0副本),参数控制粒度还不够灵活,而且HPA controller的reconcile循环不支持多线程并发,所以也一定程度上影响了一个k8s集群内HPA的对象数过多的时效性,随着k8s HPA关注和使用人数的增多,相信这些问题也都会逐步优化掉。
一、Helm概述
helm通过打包的方式,支持发布的版本管理和控制,很大程度上简化了Kubernetes应用的部署和管理。
Helm本质就是让k8s的应用管理(Deployment、Service等)可配置,能动态生成。通过动态生成K8S资源清单文(deployment.yaml、service.yaml)。然后kubectl自动调用K8S资源部署。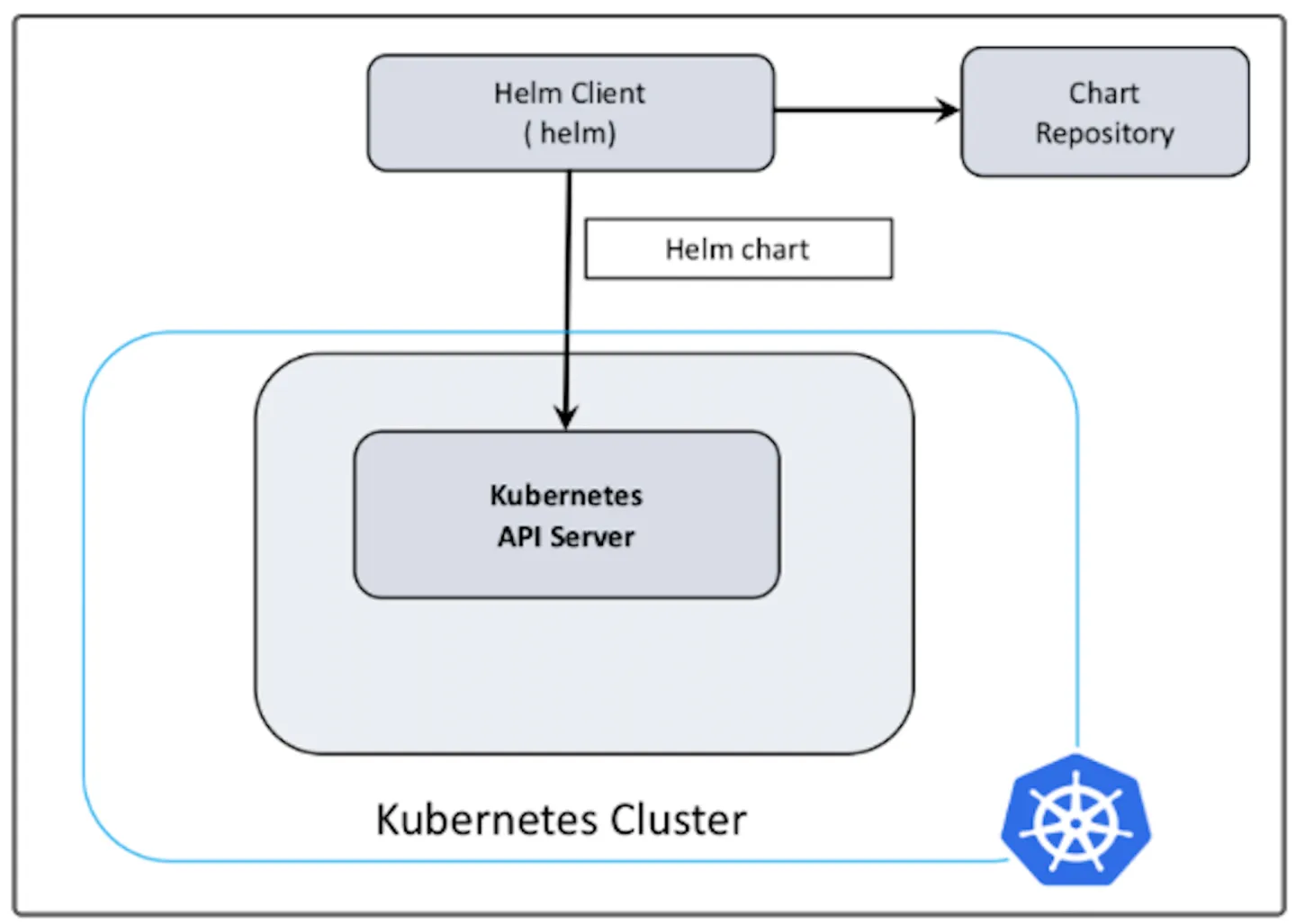
对于K8s来说,应用资源配置可以定义为K8s API对象,包括Deployment,Namespace,Service, PV(Persistent Volumes)和PVC(PersistentVolumeClaims)等等。通常一个应用的部署会涉及很多资源的共同协作,用户会定义这些API对象到一系列Yaml文件中,然后通过kubectl来逐一进行部署。
那么问题来了,假如我没接触过K8s, 只想部署个应用了解下,不会写Yaml一个个配这些资源对象怎么破?需要去结合K8s文档学习Yaml语法。过了几天我终于学会了,一个个配好了这些资源对象的Yaml文件,并逐一部署在这台机器上。后面想在这台机器上再重复部署几套,另外还有十台环境要配成和这台一样,怎么办?拷贝过去再一一部署出来?这配置管理也太麻烦了,不好用,直接劝退!
先别急!幸好已经有Helm,避免了我们去完成这些繁琐配置和维护过程。它能够把这些零零散散的应用资源文件放在一起进行统一配置,极大方便了开发人员对K8s集群应用的管理。

1.1、Helm 组件及相关术语
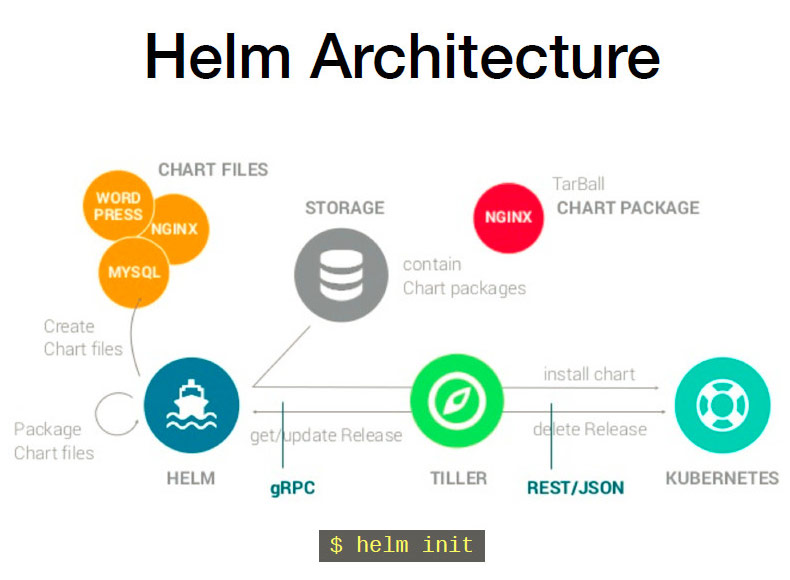
Helm是官方提供类似于YUM的包管理,是部署环境的流程封装,Helm有三个重要的概念:chart、release和Repository
-
Helm:Helm 是一个命令行下的客户端工具。主要用于 Kubernetes 应用程序 Chart 的创建、打包、发布以及创建和管理本地和远程的 Chart 仓库。
-
Tiller:Tiller 是 Helm 的服务端,部署在 Kubernetes 集群中。Tiller 用于接收 Helm 的请求,并根据 Chart 生成 Kubernetes 的部署文件( Helm 称为 Release ),然后提交给 Kubernetes 创建应用。Tiller 还提供了 Release 的升级、删除、回滚等一系列功能。
-
Chart:Helm 的软件包,采用 TAR 格式。类似于 APT 的 DEB 包或者 YUM 的 RPM 包,其包含了一组定义 Kubernetes 资源相关的 YAML 文件。Chart有特定的文件目录结构,如果开发者想自定义一个新的 Chart,只需要使用Helm create命令生成一个目录结构即可进行开发。
-
Repoistory:Helm 的软件仓库,Repository 本质上是一个 Web 服务器,该服务器保存了一系列的 Chart 软件包以供用户下载,并且提供了一个该 Repository 的 Chart 包的清单文件以供查询。Helm 可以同时管理多个不同的 Repository, 官方仓库的地址是Artifact Hub。
-
Release:使用 helm install 命令在 Kubernetes 集群中部署的 Chart 称为 Release。
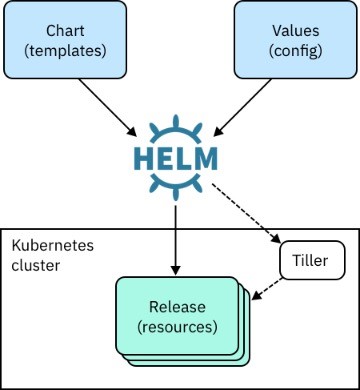
1.2、Helm工作原理
1、Chart Install 过程:
-
Helm从指定的目录或者tgz文件中解析出Chart结构信息
-
Helm将指定的Chart结构和Values信息通过gRPC传递给Tiller
-
Tiller根据Chart和Values生成一个Release
-
Tiller将Release发送给Kubernetes用于生成Release
2、Chart Update过程:
-
Helm从指定的目录或者tgz文件中解析出Chart结构信息
-
Helm将要更新的Release的名称和Chart结构,Values信息传递给Tiller
-
Tiller生成Release并更新指定名称的Release的History
-
Tiller将Release发送给Kubernetes用于更新Release
3、Chart Rollback过程:
-
Helm将要回滚的Release的名称传递给Tiller
-
Tiller根据Release的名称查找History
-
Tiller从History中获取上一个Release
-
Tiller将上一个Release发送给Kubernetes用于替换当前Release
二、Helm部署
现在越来越多的公司和团队开始使用Helm这个Kubernetes的包管理器,我们也会使用Helm安装Kubernetes的常用组件。Helm由客户端命令helm工具和服务端tiller组成。
helm的GitHub地址:https://github.com/helm/helm
2.1、安装方式
[root@k8s-master01 ~]# mkdir helm
[root@k8s-master01 helm]# wget https://get.helm.sh/helm-v3.14.0-linux-amd64.tar.gz
[root@k8s-master01 helm]# tar -zxvf helm-v3.14.0-linux-amd64.tar.gz
[root@k8s-master01 helm]# cd linux-amd64/
[root@k8s-master01 linux-amd64]# cp helm /usr/local/bin/
[root@k8s-master01 linux-amd64]# echo "source <(helm completion bash)" >> ~/.bashrc
[root@k8s-master01 linux-amd64]# source ~/.bashrc2.2、chart库配置
做完上述设置后即可使用helm search搜索官方helm hub chart库
helm search hub nginx添加第三方Chart库
helm repo add aliyun https://kubernetes.oss-cn-hangzhou.aliyuncs.com/charts
helm repo add bitnami https://charts.bitnami.com/bitnami查看Chart库
helm repo list从仓库中查找指定chart的名字
helm search repo nginx2.3、Helm命令
| 命令字 | 中文释义 | 作用 |
|---|---|---|
| completion | 完成 | 生成特定Shell的自动补全脚本 |
| create | 创建 | 使用给定的名称创建新图表 |
| dependency | 依赖 | 管理图表的依赖关系 |
| env | 环境 | Helm客户端环境信息 |
| get | 获取 | 下载已命名发布的扩展信息 |
| help | 帮助 | 关于任何命令的帮助 |
| history | 历史 | 获取发布历史记录 |
| install | 安装 | 安装图表 |
| lint | 检查 | 检查图表可能存在的问题 |
| list | 列表 | 列出发布 |
| package | 打包 | 将图表目录打包成图表存档 |
| plugin | 插件 | 安装、列出或卸载Helm插件 |
| pull | 拉取 | 从存储库下载图表,并可选在本地目录中解包 |
| push | 推送 | 将图表推送到远程存储库 |
| registry | 注册表 | 登录或注销注册表 |
| repo | 仓库 | 添加、列出、删除、更新和索引图表存储库 |
| rollback | 回滚 | 将发布回滚到先前版本 |
| search | 搜索 | 在图表中搜索关键字 |
| show | 显示 | 显示图表的信息 |
| status | 状态 | 显示指定发布的状态 |
| template | 模板 | 本地渲染模板 |
| test | 测试 | 运行发布的测试 |
| uninstall | 卸载 | 卸载发布 |
| upgrade | 升级 | 升级发布 |
| verify | 验证 | 验证给定路径的图表已签名并且有效 |
| version | 版本 | 打印客户端版本信息 |
三、Helm Chart 详解
3.1、chart目录结构
# 通过helm create命令创建一个新的chart包
[root@k8s-master01 helm]# helm create nginx
Creating nginx
[root@k8s-master01 nginx]# tree
.
├── charts
├── Chart.yaml
├── templates
│ ├── deployment.yaml
│ ├── _helpers.tpl
│ ├── hpa.yaml
│ ├── ingress.yaml
│ ├── NOTES.txt
│ ├── serviceaccount.yaml
│ ├── service.yaml
│ └── tests
│ └── test-connection.yaml
└── values.yaml
3 directories, 10 files
####目录结构解析####
nginx/
├── charts #依赖其他包的charts文件
├── Chart.yaml # 该chart的描述文件,包括ico地址,版本信息等
├── templates # #存放k8s模板文件目录
│ ├── deployment.yaml # 创建k8s资源的yaml 模板
│ ├── _helpers.tpl # 下划线开头的文件,可以被其他模板引用
│ ├── hpa.yaml # 弹性扩缩容,配置服务资源CPU 内存
│ ├── ingress.yaml # ingress 配合service域名访问的配置
│ ├── NOTES.txt # 说明文件,helm install之后展示给用户看的内容
│ ├── serviceaccount.yaml # 服务账号配置
│ ├── service.yaml # kubernetes Serivce yaml 模板
│ └── tests # 测试模块
│ └── test-connection.yaml
└── values.yaml # 给模板文件使用的变量3.2、Chart.yaml
apiVersion: # chart API 版本信息, 通常是 "v1" (必须)
name: # chart 的名称 (必须)
version: # chart 包的版本 (必须)
kubeVersion: # 指定 Kubernetes 版本 (可选)
type: # chart类型 (可选)
description: # 对项目的描述 (可选)
keywords:- # 有关于项目的一些关键字 (可选)
home: # 项目 HOME 页面的 URL 地址 (可选)
sources:- # 项目源码的 URL 地址 (可选)
dependencies: # chart 必要条件列表 (可选)- name: # chart名称 (nginx)version: # chart版本 ("1.2.3")repository: # (可选)仓库URL ("https://example.com/charts") 或别名 ("@repo-name")condition: # (可选) 解析为布尔值的yaml路径,用于启用/禁用chart (e.g. subchart1.enabled )tags: # (可选)- # 用于一次启用/禁用 一组chart的tagimport-values: # (可选)- # ImportValue 保存源值到导入父键的映射。每项可以是字符串或者一对子/父列表项alias: # (可选) chart中使用的别名。当你要多次添加相同的chart时会很有用
maintainers: # (可选)维护者信息- name: # 维护者的名称email: # 维护者的邮件地址url: # 维护者的个人主页
engine: gotpl # 模板引擎的名称(可选,默认为 gotpl)
icon: # (可选)指定 chart 图标的 SVG 或 PNG 图像的 URL
appVersion: # 应用程序包含的版本
deprecated: # (可选,使用布尔值)该 chart 是否被废弃
annotations:example: # 按名称输入的批注列表 (可选).-
从 v3.3.2,不再允许额外的字段。推荐的方法是在
annotations中添加自定义元数据。 -
每个 chart 都必须有个版本号(
version)。版本必须遵循 语义化版本 2 标准。不像经典 Helm, Helm v2 以及后续版本会使用版本号作为发布标记。仓库中的包通过名称加版本号标识。
比如 nginx chart 的版本字段 version: 1.2.3 按照名称被设置为:
nginx-1.2.3.tgz三、helm部署案例
部署Nginx应用
[root@k8s-master01 nginx-helm]# helm pull bitnami/nginx --version 15.3.5
[root@k8s-master01 nginx-helm]# ls
nginx-15.3.5.tgz
[root@k8s-master01 nginx-helm]# tar xf nginx-15.3.5.tgz
[root@k8s-master01 nginx-helm]# ls
nginx nginx-15.3.5.tgz
[root@k8s-master01 nginx-helm]# cd nginx
[root@k8s-master01 nginx]# vim values.yaml
532 service:
533 ## @param service.type Service type
534 ##
535 type: ClusterIP
536 ## @param service.ports.http Service HTTP port
537 ## @param service.ports.https Service HTTPS port
538 ##
539 ports:
540 http: 80
541 https: 443
###安装chart###
[root@k8s-master01 nginx]# helm install nginx-server .
NAME: nginx-server
LAST DEPLOYED: Sat Feb 3 15:57:33 2024
NAMESPACE: default
STATUS: deployed
REVISION: 1
TEST SUITE: None
NOTES:
CHART NAME: nginx
CHART VERSION: 15.3.5
APP VERSION: 1.25.3
** Please be patient while the chart is being deployed **
NGINX can be accessed through the following DNS name from within your cluster:
nginx-server.default.svc.cluster.local (port 80)
To access NGINX from outside the cluster, follow the steps below:
1. Get the NGINX URL by running these commands:
export SERVICE_PORT=$(kubectl get --namespace default -o jsonpath="{.spec.ports[0].port}" services nginx-server)kubectl port-forward --namespace default svc/nginx-server ${SERVICE_PORT}:${SERVICE_PORT} &echo "http://127.0.0.1:${SERVICE_PORT}"
####查看pod和service###
[root@k8s-master01 nginx]# kubectl get deployments.apps
NAME READY UP-TO-DATE AVAILABLE AGE
nginx-deploy 3/3 3 3 23h
nginx-deploy1 3/3 3 3 22h
nginx-deploy2 3/3 3 3 22h
nginx-server 1/1 1 1 56s
[root@k8s-master01 nginx]# kubectl get pod
NAME READY STATUS RESTARTS AGE
nginx-deploy-5f87d95c-7ph78 1/1 Running 1 (151m ago) 23h
nginx-deploy-5f87d95c-dswvq 1/1 Running 1 (151m ago) 23h
nginx-deploy-5f87d95c-vk9vg 1/1 Running 1 (151m ago) 23h
nginx-deploy1-c8d58b5c7-7dfrd 1/1 Running 1 (151m ago) 22h
nginx-deploy1-c8d58b5c7-d2hd7 1/1 Running 1 (151m ago) 22h
nginx-deploy1-c8d58b5c7-pfvhn 1/1 Running 1 (151m ago) 22h
nginx-deploy2-db98bd9d9-2jl74 1/1 Running 1 (151m ago) 22h
nginx-deploy2-db98bd9d9-h67n6 1/1 Running 1 (151m ago) 22h
nginx-deploy2-db98bd9d9-wfcmw 1/1 Running 1 (151m ago) 22h
nginx-server-ff5765f8-4wbms 1/1 Running 0 2m5s
pod-controller-qk5jl 1/1 Running 1 (151m ago) 19h
pod-controller-scsxt 1/1 Running 1 (151m ago) 19h
[root@k8s-master01 nginx]# kubectl get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes ClusterIP 10.10.0.1 <none> 443/TCP 14d
nginx-server ClusterIP 10.10.127.16 <none> 80/TCP 2m32s
nginx-svc ClusterIP 10.10.83.76 <none> 80/TCP 23h
nginx-svc1 LoadBalancer 10.10.168.131 192.168.115.167 80:31261/TCP 22h
nginx-svc2 NodePort 10.10.14.245 <none> 80:31110/TCP 22h
####测试访问###
[root@k8s-master01 nginx]# curl 10.10.127.16
<!DOCTYPE html>
<html>
<head>
<title>Welcome to nginx!</title>
<style>
html { color-scheme: light dark; }
body { width: 35em; margin: 0 auto;
font-family: Tahoma, Verdana, Arial, sans-serif; }
</style>
</head>
<body>
<h1>Welcome to nginx!</h1>
<p>If you see this page, the nginx web server is successfully installed and
working. Further configuration is required.</p>
<p>For online documentation and support please refer to
<a href="http://nginx.org/">nginx.org</a>.<br/>
Commercial support is available at
<a href="http://nginx.com/">nginx.com</a>.</p>
<p><em>Thank you for using nginx.</em></p>
</body>
</html>四、升级与回滚
修改配置文件
[root@k8s-master01 nginx]# vim values.yaml
123 replicaCount: 3
124 ## @param revisionHistoryLimit The number of old history to retain to allow rollback
125 ##升级
[root@k8s-master01 nginx]# helm upgrade nginx-server .查看升级结果
[root@k8s-master01 nginx]# kubectl get pod
[root@k8s-master01 nginx]# kubectl get pod
NAME READY STATUS RESTARTS AGE
nginx-deploy-5f87d95c-7ph78 1/1 Running 1 (166m ago) 23h
nginx-deploy-5f87d95c-dswvq 1/1 Running 1 (166m ago) 23h
nginx-deploy-5f87d95c-vk9vg 1/1 Running 1 (166m ago) 23h
nginx-deploy1-c8d58b5c7-7dfrd 1/1 Running 1 (166m ago) 23h
nginx-deploy1-c8d58b5c7-d2hd7 1/1 Running 1 (166m ago) 23h
nginx-deploy1-c8d58b5c7-pfvhn 1/1 Running 1 (166m ago) 23h
nginx-deploy2-db98bd9d9-2jl74 1/1 Running 1 (166m ago) 22h
nginx-deploy2-db98bd9d9-h67n6 1/1 Running 1 (166m ago) 22h
nginx-deploy2-db98bd9d9-wfcmw 1/1 Running 1 (166m ago) 22h
nginx-server-ff5765f8-4p6sh 1/1 Running 0 31s
nginx-server-ff5765f8-4wbms 1/1 Running 0 16m
nginx-server-ff5765f8-lnkkg 1/1 Running 0 31s查看记录
[root@k8s-master01 nginx]# helm history nginx-server
REVISION UPDATED STATUS CHART APP VERSION DESCRIPTION
1 Sat Feb 3 15:57:33 2024 superseded nginx-15.3.5 1.25.3 Install complete
2 Sat Feb 3 16:13:44 2024 deployed nginx-15.3.5 1.25.3 Upgrade complete回滚
[root@k8s-master01 nginx]# helm rollback nginx-server 1验证回滚
[root@k8s-master01 nginx]# kubectl get pod
NAME READY STATUS RESTARTS AGE
nginx-deploy-5f87d95c-7ph78 1/1 Running 1 (170m ago) 23h
nginx-deploy-5f87d95c-dswvq 1/1 Running 1 (170m ago) 23h
nginx-deploy-5f87d95c-vk9vg 1/1 Running 1 (170m ago) 23h
nginx-deploy1-c8d58b5c7-7dfrd 1/1 Running 1 (170m ago) 23h
nginx-deploy1-c8d58b5c7-d2hd7 1/1 Running 1 (170m ago) 23h
nginx-deploy1-c8d58b5c7-pfvhn 1/1 Running 1 (170m ago) 23h
nginx-deploy2-db98bd9d9-2jl74 1/1 Running 1 (170m ago) 22h
nginx-deploy2-db98bd9d9-h67n6 1/1 Running 1 (170m ago) 22h
nginx-deploy2-db98bd9d9-wfcmw 1/1 Running 1 (170m ago) 22h
nginx-server-ff5765f8-lnkkg 1/1 Running 0 4m44s御载
[root@k8s-master01 nginx]# helm uninstall nginx-server