[MH22D3开发笔记]2. SPI,QSPI速度究竟能跑多快,双屏系统的理想选择
MH22D3xx系列,是兆讯公司推出的第二代芯片,主频和第一代MH2103一样,保持216Mhz的高主频,RAM 64KB,FLASH可以到512KB。依然和stm32F103保持pin to pin的高度兼容,但是在局部功能和接口上已经是青出于蓝而胜于蓝,其应用场景远远超过stm32F103能支持的场景,更重要的是价格还更香,非常适合用来开发显示控制类中小尺寸屏幕产品。
我们以一个双屏异显项目的需求为例,来深度剖析一下这款芯片的新的亮点,并对比stm32f103进行硬件需求分析:

这一款产品是现在比较流行的双屏异显应用,对mcu的数据读取能力,接口速度都有极高要求,我们逐步推导一下需求就会有一个理论的上的直观感受和性能需求,以正确评估芯片的选型需求。
屏幕的配置:分辨率为240x240,接口为常见的四线spi,驱动芯片采用ST77916.
显示接口的速度需求:显示像素格式采用RGB565,那么一屏数据的大小就是240x240x2=115200byte.如果我们要达到30帧的速度,那么总的数据吞吐量就需要115200x30=3456000KB=3.456Mbytes。spi接口采用8bit串行输出,那么spi的速度需求:3.4568=27.648M。这在一般的mcu上都可以达到或者满足。
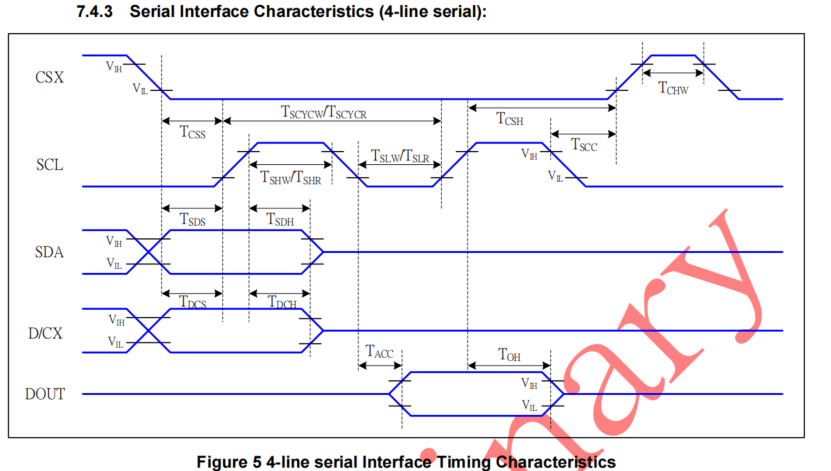
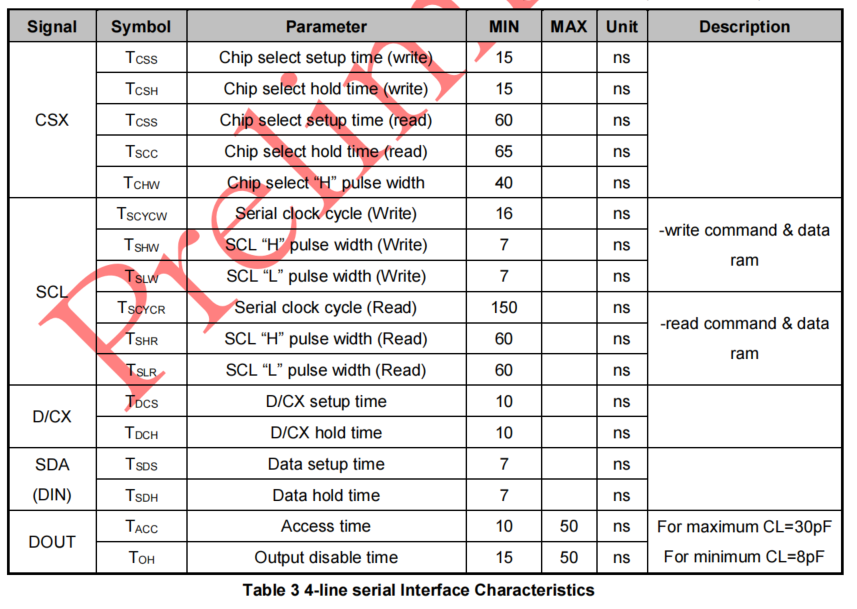
看一下驱动芯片ST77916的spi接口电气特性,如下图和表格所示,SCL最大可以达到16ns,也就是说大约60M的速度,所以我们完全可以提高前面计算的spi速度,来达到更低的mcu传输数据的时间,提高系统帧率。60M/27.648M≈2,也就是说,基于这颗芯片的接口性能,大约可以提供60帧的最高理论刷新速度(考虑到线长和pcb布线等因素,可以保守到50帧)。
基于以上显示数据的传输需求计算,我们先看看同类型的stm32f103能否满足需求?
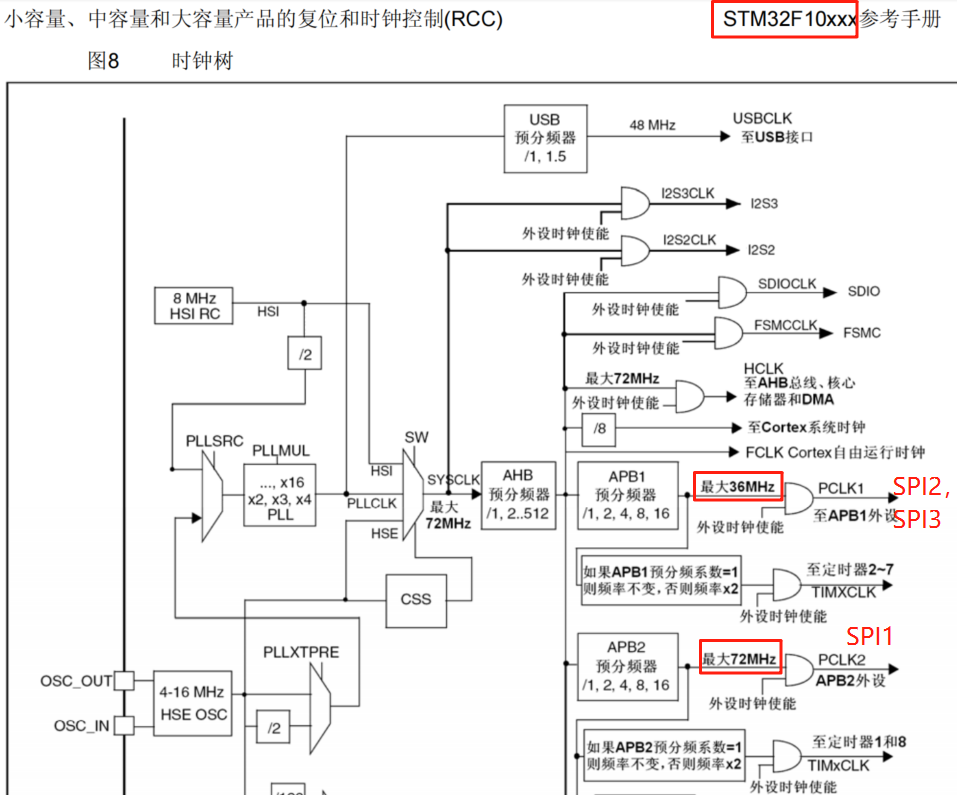
看一下如下图所示的stm32f103的时钟树,芯片的3个spi,只有spi1的速度能达超过最高帧率需求50Mhz,spi2和spi3最高只能到36M,也就是大约30帧。显然这个速度发挥不出来显示屏的最高性能。
以上是显示屏驱动接口的数据传输能力需求,那么我们来看看读取图片数据(不考虑压缩)的需求:前面计算得知,30帧的数据吞吐量是3.456Mbytes,但是我们是两块屏幕,那么就是3.456Mbytes2=6.912Mbyte,换算为spi速度6.9128=55.296Mhz,基本上已经把spi1的性能拉满了。
以上是理论计算,但是。。。实际上我们来看看代码和波形,会发现根本达不到这个要求:
这是我们常规的spi接口发送或者读取一个字节接口:
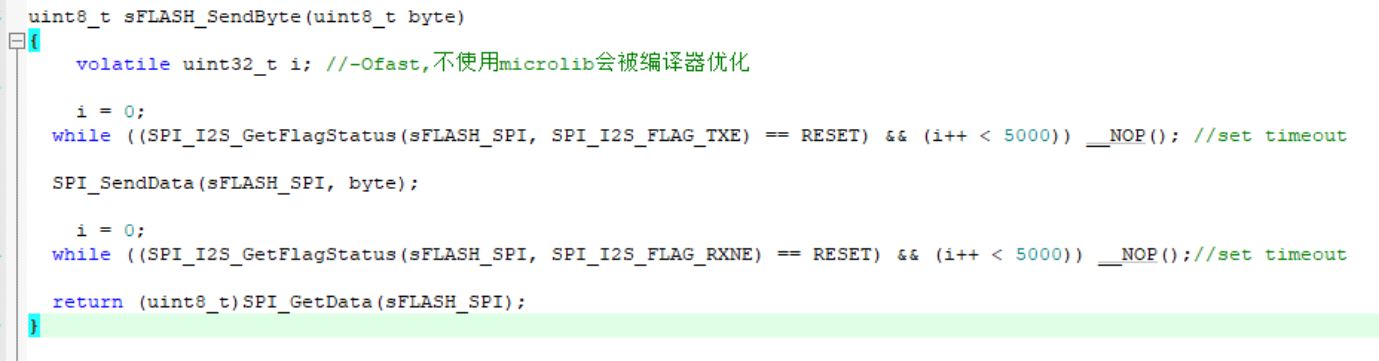
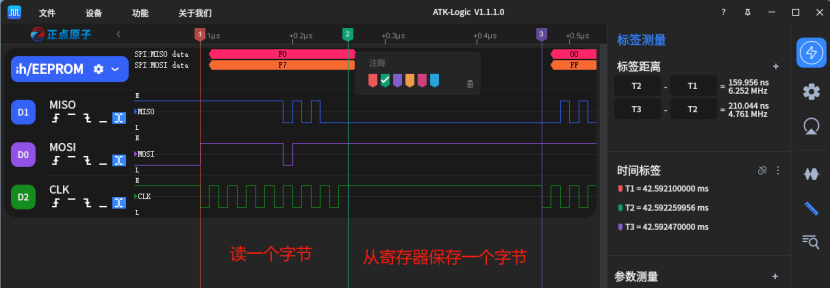
上图是spi接口抓取的数据波形,我们发现在发送两个字节之间,空出来了很长一个时间,大约是和发送一个字节相当(略长),也就是说因为如上的代码方式,发送一个字节和一个字节之间有cpu运行的等待,数据读取等周期,SPI的速度几乎腰斩了。
那么悲催的事情就来了,按照前面的计算,我们对lcd输出的spi频率要求就会翻倍,达到27.648M2≈55M,对数据读取的spi需求达到55.296Mhz*2=110Mhz,很显然,如果我们将两个显示屏接口连接到stm32f103的spi2,3,数据存储接口连接到spi1,都已经超过了物理上的最高速度36M和72Mhz,所以如果用stm32f103来实现这个方案,就行不通了。
兆讯第一代芯片MH2103和stm32f103的spi速度完全一样,所以也不适合用来做这个项目应用。我们选择了第二代芯片MH22D3来实现,那么MH22D3的spi有那些改进呢?
我们先看看MH22D3的框图:
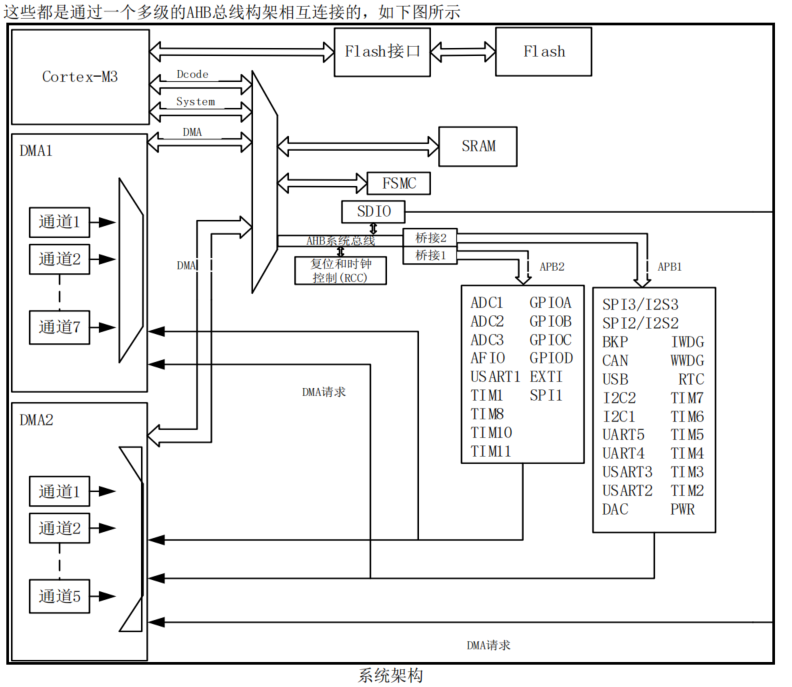
你没有看错,他和你熟悉的stm32f103依然一样,只是spi3的接口也可以配置为QSPI。但是,一个重中之重的改进来了,APB2的最大时钟已经突破了72Mhz的限制,可以达到216Mhz(系统主频216Mhz),APB1可以达到108Mhz,仅仅以这个硬件能力,采用前面同样的方式,就可以轻松达到30帧的数据传输能力。
如果我们仅仅这样使用,那就太浪费这款芯片的硬件能力了,通过如下改进,我们可以进一步大大提升系统性能:
系统硬件连接:spi1和spi2驱动双屏,spi3切换为QSPI模式,连接Norflash。
第一步:启用DMA
MH22D3有两个DMA控制器,一共12个通道,如下表:
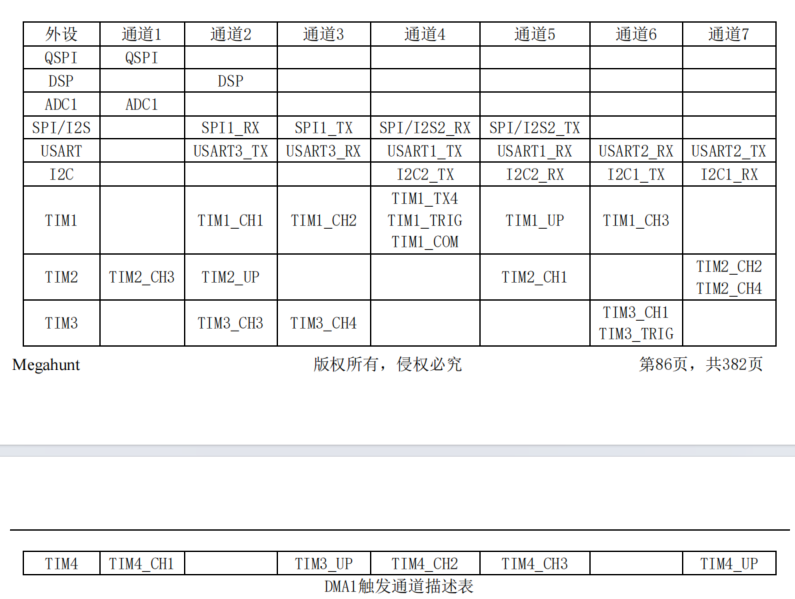
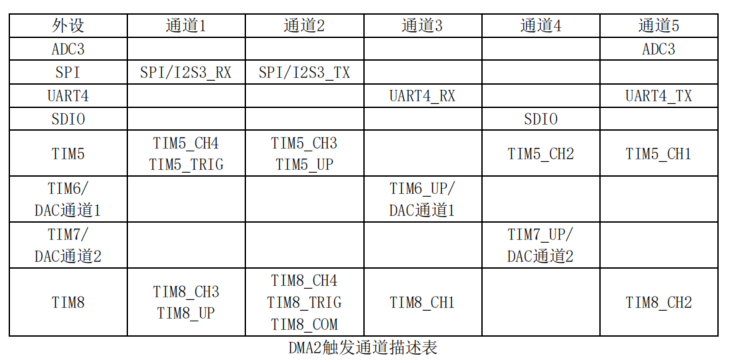
SPI1和SPI2的接口,我们可以采用DMA方式向屏幕传输数据,以消除前面我们看到的每一个字节后面的等待和仲裁时间(因为DMA方式,只需要在给定的数据传输完成后才做一次判断),使spi的传输速度提约1倍,同时SPI硬件的时钟我们也可以提高到54M(216Mhz四分频),使其接近显示驱动芯片的最高频率60M,在硬件上将性能逼近到稳定的上限。
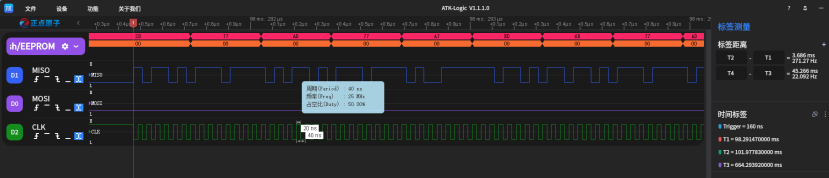
如下图所示,采用DMA后,我们看到CLK源源不断,再也没有字节过后的“休眠期”了,速度几乎翻倍。
第二步:启用QSPI
我们使用QSPI接口来从flash读取数据,实测数据如下(Norflash的接口最大速度一般为133Mhz,所以我们在该接口上最高可以跑108Mhz,通常兼顾mcu最高运行速度和接口的稳定性已经对批量芯片一致性的考虑,以及考虑到环境温度变化的影响,我们把QSPI接口跑72Mhz是比较好的配置):
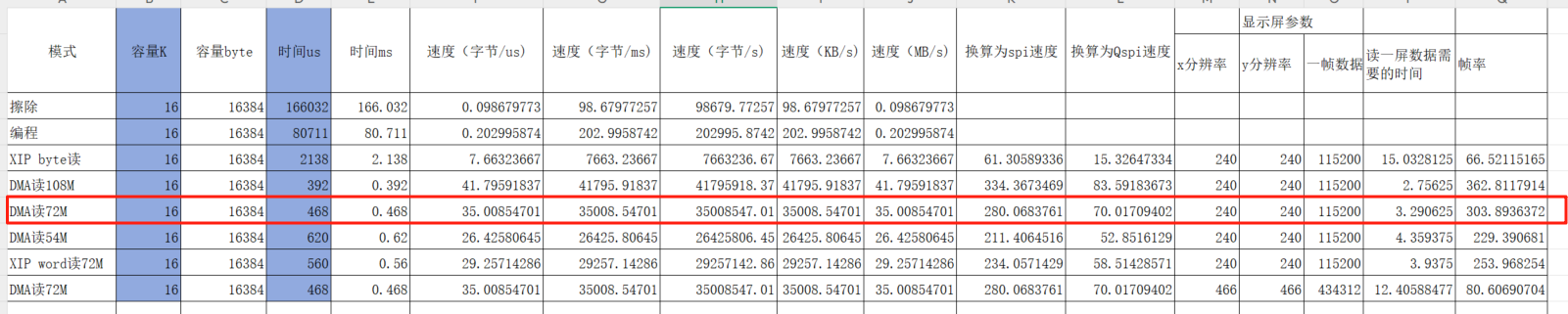
表中的实测数据表明,我们以72M的dma方式运行,读数据的速度已经相当于280M的spi速度了,是以前spi读取的5-6倍了。
读取前述显示屏一屏需要的数据只需要大约3.3ms,大约330帧,也就是说读取数据已经没有任何瓶颈了,最后传输的速度完全取决于显示屏能接受的最高速度了。
第三步:启用异步传输
根据前面DMA的配置,我们可以计算出来传输一屏显示数据的时间大约是18ms(每秒可以到50帧),读一屏数据大约需要3ms。
如果我们按照常规逻辑来显示:读显示屏1数据->写显示屏1数据->读显示屏2数据->写显示屏2数据,那么大约需要耗时3+18+3+18=42ms,帧率约25帧,而且这样来的话,mcu几乎被占满了。速度还是不是很高,如何解决?
解决的方案就是采用异步DMA方式(数据准备好,启动传输后就不需要再耗费mcu时间,传输完成后会产生中断通知)。
我们可以读取完第一个显示屏需要的数据后(不一定是一整屏,因为RAM不够),立即启动第一个显示屏的DMA的传输。然后MCU可以立即读取第二个显示屏的数据,然后启动第二个显示屏的DMA传输,使两个显示屏的传输同时进行。如此一来,虽然是两个显示屏的数据,但是几乎和一个显示屏的数据差别不大。

我们用图示来看看上述过程:
只有第一次启动显示需要一个额外的3ms读取数据时间,以后的读取数据时间,完全“掩盖”在lcd的传输时间里面了,而且双屏的刷新几乎是同步的(差大约3ms),这样的好处是非常明显的:一来是提高了显示刷新的帧率到50帧(接近显示屏的上限),二来由于双屏的同步时间很接近(3ms,约300帧),左右眼的数据几乎在人眼看起来是同步显示的,不会出现一前一后的现象,显示效果相当nice!
通过以上的硬件改进和软件优化,我们最大化的利用了MH22D3提供的硬件能力,将双眼显示的效果完美的逼近到理论的极限,提供了非常好的显示效果,从而发挥出来这颗芯片的最佳性能,提供给客户最高的性价比。
文章原创,欢迎转载,请注明出处,未经书面允许,不得用于商业用途。