Linux系统编程——进程 | 线程
进程(Process) --- 并发
---> 进程是一个程序执行的过程(正在运行的程序),会去分配内存资源,CPU的调度
ssd --- 固态硬盘
pcb(process control block)块内重要的部分:
//PID,进程标识符 --- 为每个运行的程序分配一个编号作为身份的标识
//pcb块记录当前工作路径
//umask 002(掩码) --- 控制新文件的权限,包括普通文件和目录文件
//信号处理 --- 信号相关设置 处理异步IO
//用户id,组id
//进程资源的上限 ulimit -a 显示资源上限
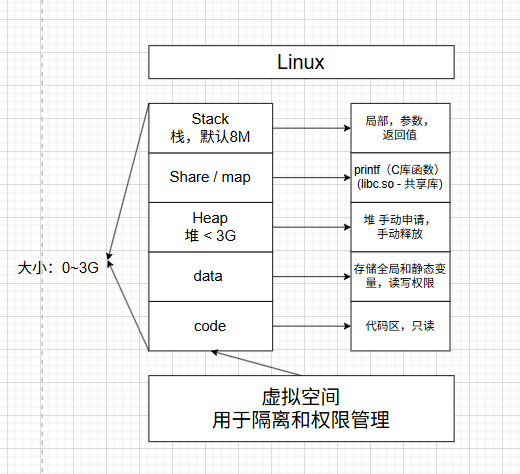
栈空间默认8M
文件描述符默认取值范围:0~1023
进程 VS 程序
| 进程 | 程序 |
| 动态(程序执行过程中,包括进程的创建,调度,消亡) | 静态(存储在硬盘中的代码,数据的集合) |
| 暂时 | 永存 |
| 有程序状态的变化 | 没有程序状态的变化 |
| 有并发(并发:所有的程序同时运行) | 没有并发 |
| 进程与进程之间存在竞争计算机的资源 | 不存在 |
| 一个程序可以运行多次,变成多个进程;一个进程可以运行一个或多个程序 | |
内存的分布:
0~3G -- 进程的空间,3G~4G -- 内核分空间,虚拟地址
虚拟地址 * 物理内存和虚拟内存的地址,映射表 1page = 4K(默认值)
进程分类:
1.交互式进程
2.批处理进程 shell脚本
3.守护进程:特定时间运行,其他时间休眠 --- (示例:Windows中杀毒软件)
进程的作用:
资源分配的载体:它是操作系统进行CPU时间、内存、文件等资源分配和调度的基本单位。
独立执行的实体:它为程序提供了一个独立运行的环境,拥有自己的资源空间,与其他进程隔离,保证了系统的稳定性和安全性。
并发执行的基础:正是因为有了进程的概念,我们才能够在单核CPU上实现宏观的“多任务同时进行”,极大地提升了计算机的利用率和用户体验。
并发:并发是关于结构的设计,是逻辑上的同时发生
//并发指的是系统有能力同时处理多个任务,但不一定这些任务在同一时刻都在执行。
核心: 处理多个未完成的任务,在任务之间快速切换。
关键手段: 上下文切换 (Context Switching)。
典型场景: 在单个CPU核心上运行多个任务。
并行:并行是关于执行的计算,是物理上的同时发生
//并行指的是系统在同一时刻同时执行多个任务。
核心: 同时执行多个任务。
关键手段: 多核处理器、分布式计算、GPU。
典型场景: 在多核CPU上,每个核心同时执行一个线程。
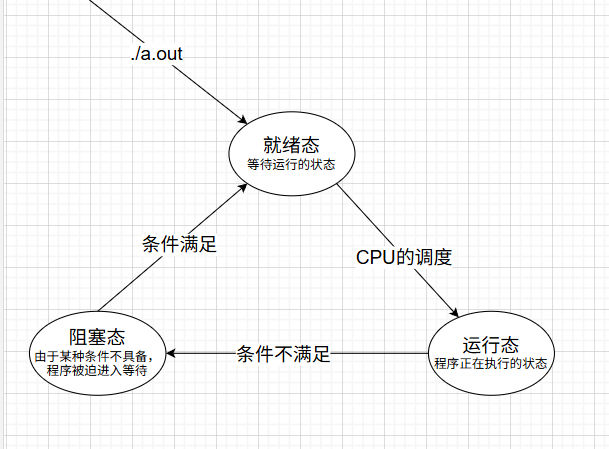
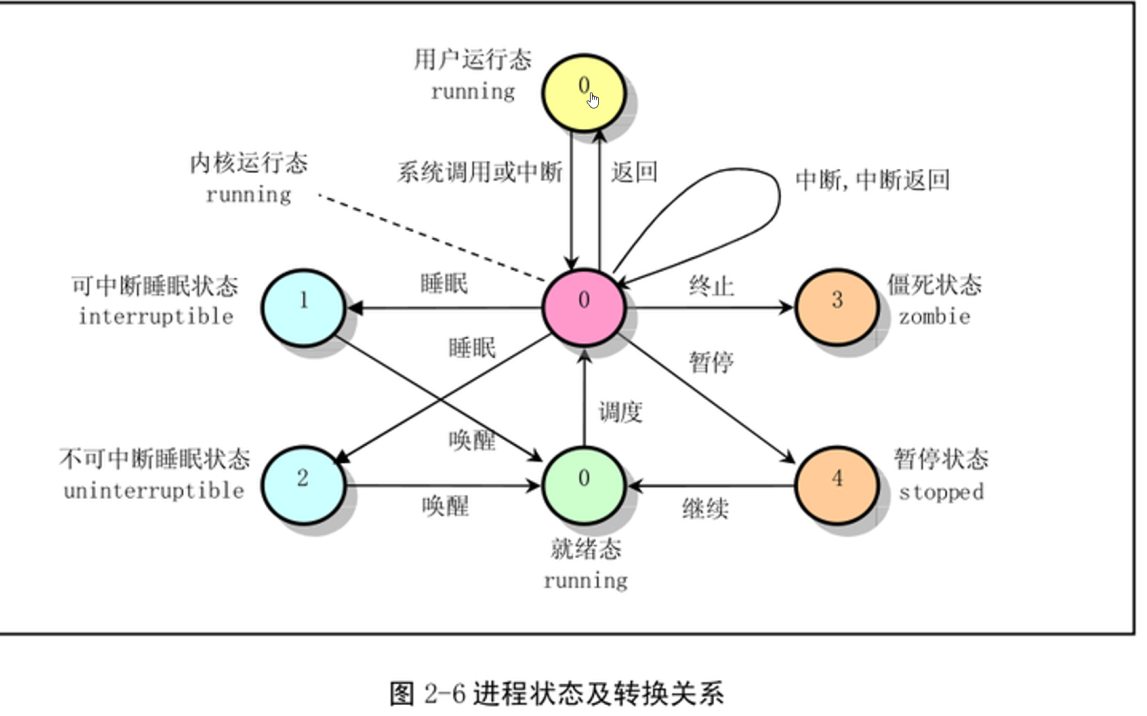
进程的状态
调度算法
1.先来先服务
2.短任务优先(时间短的先执行)
3.多级任务队列(按优先级分队,优先级高的先运行)
查询进程的相关命令:
ps aux //查看进程
top //根据CPU占用率查看进程相关信息
kill / killall //发送一个信号
kill -2 PID 15 //发送信号+PID(进程号) 对应的进程,默认接收者关闭
killall -9 进程名 //发送信号 进程名对应的所有进程
atp install //用于安装软件
原语:
1.fork();
pid_t fork();
功能:通过该函数可以从当前进程中克隆一个同名新进程。
克隆的进程称为子进程,原有的进程称为父进程。
子进程是父进程的完全拷贝。
子进程的执行过程是从fork函数之后执行。
子进程与父进程具有相同的代码逻辑。
子进程复制父进程的0到3g空间和父进程内核中的PCB,但id号不同
返回值:int 类型的数字。
在父进程中:成功返回值是子进程的pid号>0
失败返回-1;
在子进程中:成功返回值0
失败无
一次调用,会返回两次。
子进程先运行还是父进程先进程,顺序不确定。
int main() {pid_t ret = fork();if(ret > 0){while(1){printf("father, 发视频。。。。。\n");sleep(1);}}else if(ret == 0){while(1){printf("child, 接收控制。。。。\n");sleep(1);}}else{perror("fork err\n");return 1;}return 0; }<1>. fork() 的核心机制:复制进程
当调用 fork() 时,操作系统会创建一个当前进程的几乎完全相同的副本,这个副本就是子进程,子进程获得父进程的数据段,堆,栈,正文段共享。
关键点在于:子进程不是从 main() 函数开始执行的,而是从 fork() 调用之后的那一刻开始执行的。它拥有和父进程此时完全相同的状态:相同的代码执行位置、相同的变量值、相同的打开文件等。
<2>. 区分父子进程:不同的返回值
既然两个进程从同一行代码继续执行,操作系统就需要提供一种方法让程序知道自己当前是父进程还是子进程,从而执行不同的逻辑。
fork() 通过返回不同的值来解决这个问题:
• 在父进程中:fork() 返回新创建的子进程的进程号 (PID)。这是一个大于0的数字。
• 在子进程中:fork() 返回 0。
• 如果创建失败:fork() 返回 -1。//父进程结束,子进程不受影响
if(ret > 0) // 我是父进程,我拿到了孩子的PID(进程号) {// 父进程干活 } else if(ret == 0) // 我是子进程,我的返回值是0 {// 子进程干活 } else // fork失败了(只有父进程会走到这里) {// 错误处理 }
变量不共享。
//写时复制(cow):是一种延迟复制策略:它不会在 fork() 发生时立即复制父进程的整个地址空间(内存页)给子进程,而是让父子进程共享相同的物理内存页。只有当其中任何一个进程试图修改某个内存页时,操作系统才会为该进程透明地复制这个特定的内存页。
pid_t ret = fork();if(ret > 0){sleep(3);printf("father, a = %d\n",a);}else if(ret == 0){//写时复制,a+=10只在子进程开a的空间a+=10;printf("child, a = %d\n",a);sleep(1);}else{perror("fork err\n");return 1;}printf("a = %d\n",a);
获得进程和父进程的pid(进程号)
#include <sys/types.h>
#include <unistd.h><1> getpid //进程pid
原型: pid_t getpid(void);
功能: 获得调用该函数进程的pid返回值: 成功 获得进程pid
失败 返回-1;
<2> getppid //父进程pid
原型: pid_t getppid(void);
功能: 获得该函数父进程的pid
返回值: 成功 获得父进程pid
应用场合:
1)一个进程希望复制自己,使父子进程同时执行同的代码段。网络服务中会比较多见。
2)一个进程需要执行一个不同的程序。fork+exec、
进程的终止:
正常终止:1)main中return
2)exit() 作用:退进程
//属于C库函数,会执行io库的清理工作,关闭所有的流,以及所有打开的文件。
//已经清理函数(atexit)
3)_exit, _Exit 会关闭所有已经打开的文件,不执行清理函数
4)主线程退出
5)主线程调用pthread_exit
异常终止:6)abort()
7)signal kill pid(发信号)
8)线程被pthread_cancle(终止其他进程)
进程的退出 --- 僵尸进程 / 孤儿进程
僵尸进程:是指已经执行完毕但其退出状态还没有被父进程回收(reap) 的进程。它虽然已经死亡,但在进程表中仍然占有一个条目(Entry)
孤儿进程: