ViT系列网络系统性分析:从架构创新到未来趋势
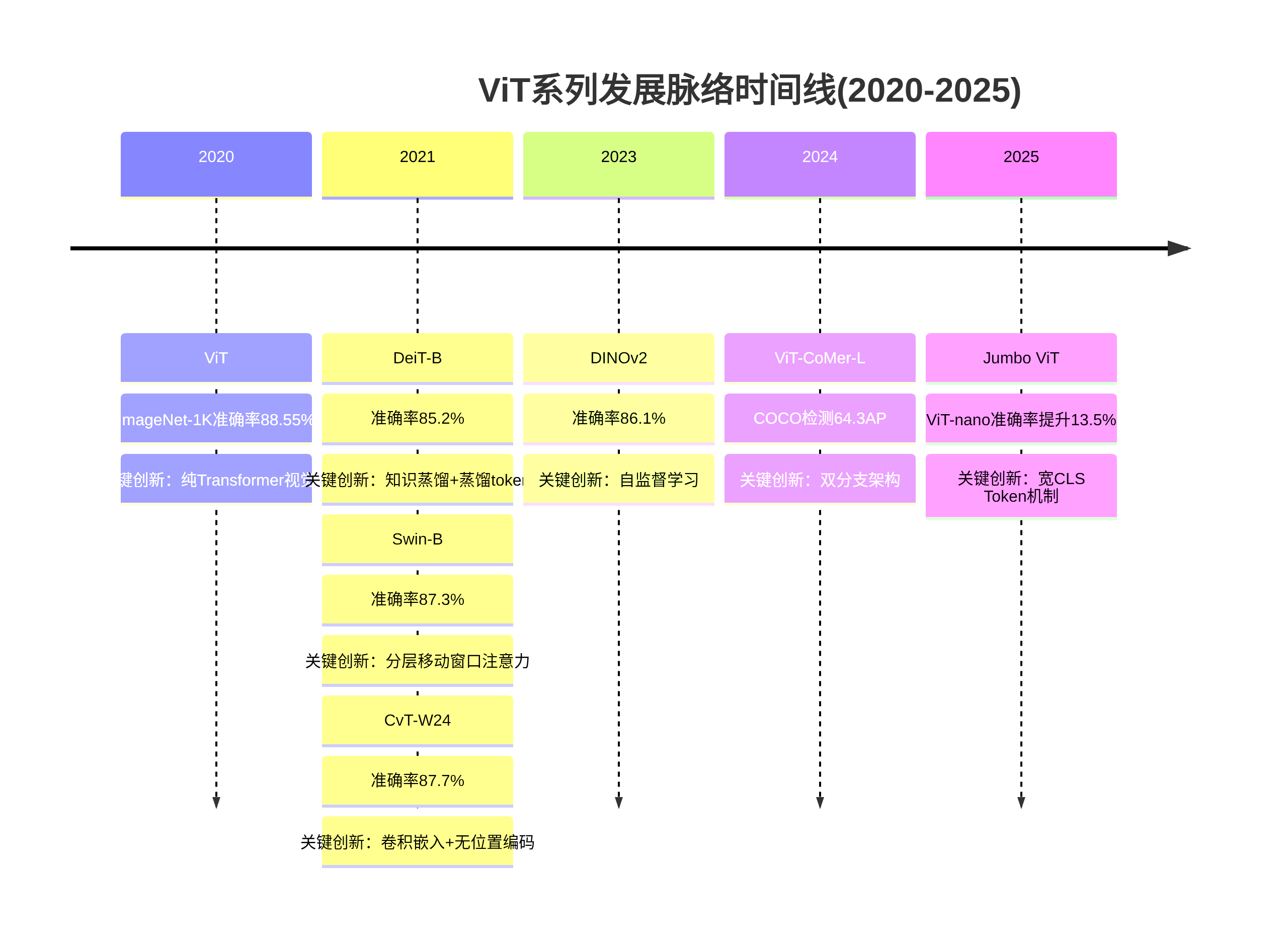
发展脉络梳理
奠基期(2020-2021)
2020-2021年是Vision Transformer(ViT)系列网络的奠基阶段,这一时期的核心使命是打破卷积神经网络(CNN)在计算机视觉领域的长期垄断,通过引入Transformer架构重构视觉任务的特征提取范式。从ViT首次验证Transformer在图像识别中的可行性,到DeiT解决数据依赖问题,再到Swin Transformer、PVT、CvT等模型针对效率、多任务适配性的优化,奠定了ViT系列作为通用视觉主干的技术基础。
ViT:Transformer视觉化的起点与性能突破
2020年,Google团队在论文《AN IMAGE IS WORTH 16 ∗ 16 16 * 16 16∗16 WORDS: TRANSFORMERS FOR IMAGE RECOGNITION AT SCALE》中首次提出ViT,彻底摒弃CNN的图像特定归纳偏差(如平移不变性、局部性),将标准Transformer直接应用于图像识别。其核心架构包括:图像分块嵌入(将图像 H ∗ W ∗ C H * W * C H∗W∗C切分为 N = H W / P 2 N = HW/P^2 N=HW/P2个 P ∗ P P * P P∗P的patch,展平后通过线性映射生成token序列)、可学习位置嵌入(弥补Transformer对序列位置不敏感缺陷)、Transformer编码器(含多头自注意力MSA、前馈神经网络FFN及残差连接)及 [CLS]分类标记(聚合全局特征用于分类)[1][2]。
ViT的性能呈现显著的数据规模依赖性:在小规模数据集(如ImageNet-1K)上性能不及同等规模ResNet,但通过JFT-300M大规模数据预训练后,ImageNet准确率达88.55%、ImageNet-ReaL达90.72%、CIFAR-100达94.55%,全面超越当时最先进CNN[1][3]。这一结果证明:当数据规模足够大时,Transformer的全局建模能力可突破CNN的局部特征学习瓶颈,为视觉领域架构革新提供了关键证据。
DeiT:知识蒸馏破解数据依赖难题
ViT对大规模数据的强依赖限制了其普及性。2021年,Facebook提出的DeiT(数据高效图像Transformer)通过知识蒸馏技术,使ViT在仅使用ImageNet-1K数据(128万张图像)的情况下即可达到与CNN竞争的性能。其核心策略包括:
- 双token设计:在[CLS]分类token基础上添加蒸馏token,分别学习真实标签与教师模型(预训练ResNet)输出,损失函数为 C E ( s i g m a ( Z c l s ) , y t r u e ) + C E ( s i g m a ( Z d i s t i l l ) , y t e a c h e r ) CE(\\sigma(Z_{cls}), y_{true}) + CE(\\sigma(Z_{distill}), y_{teacher}) CE(sigma(Zcls),ytrue)