NLP学习之Transformer(2)
1. Encoder-Decoder框架
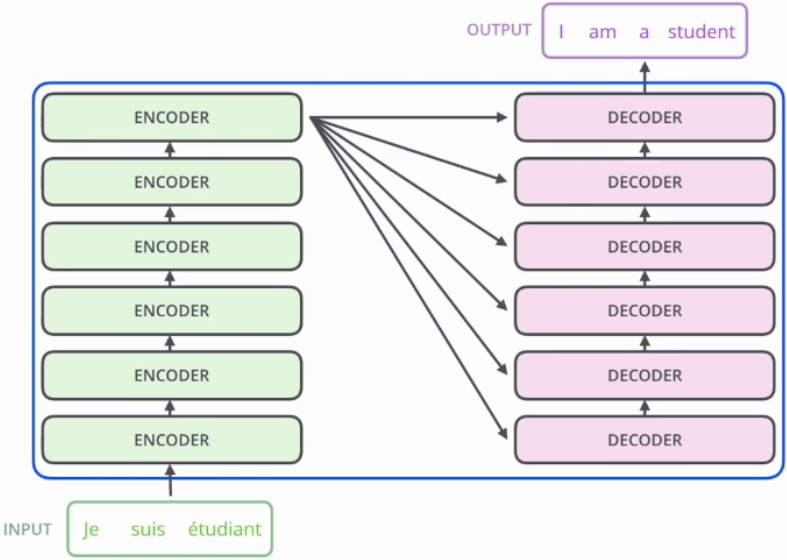 |
|
|---|---|
| 6个结构完全相同的编码器 | 6个结构完全相同的解码器 |
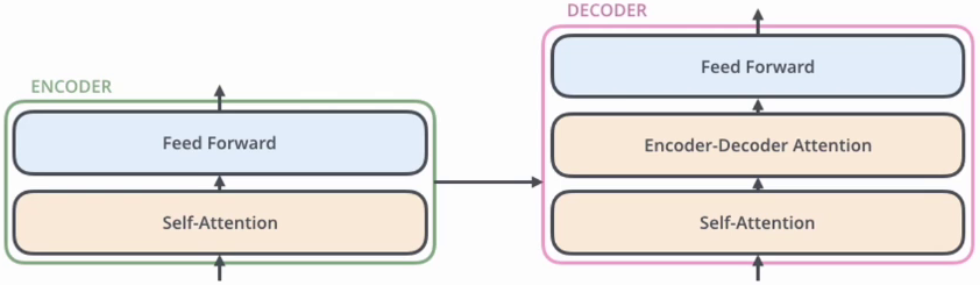
1.1 编码器Encoder
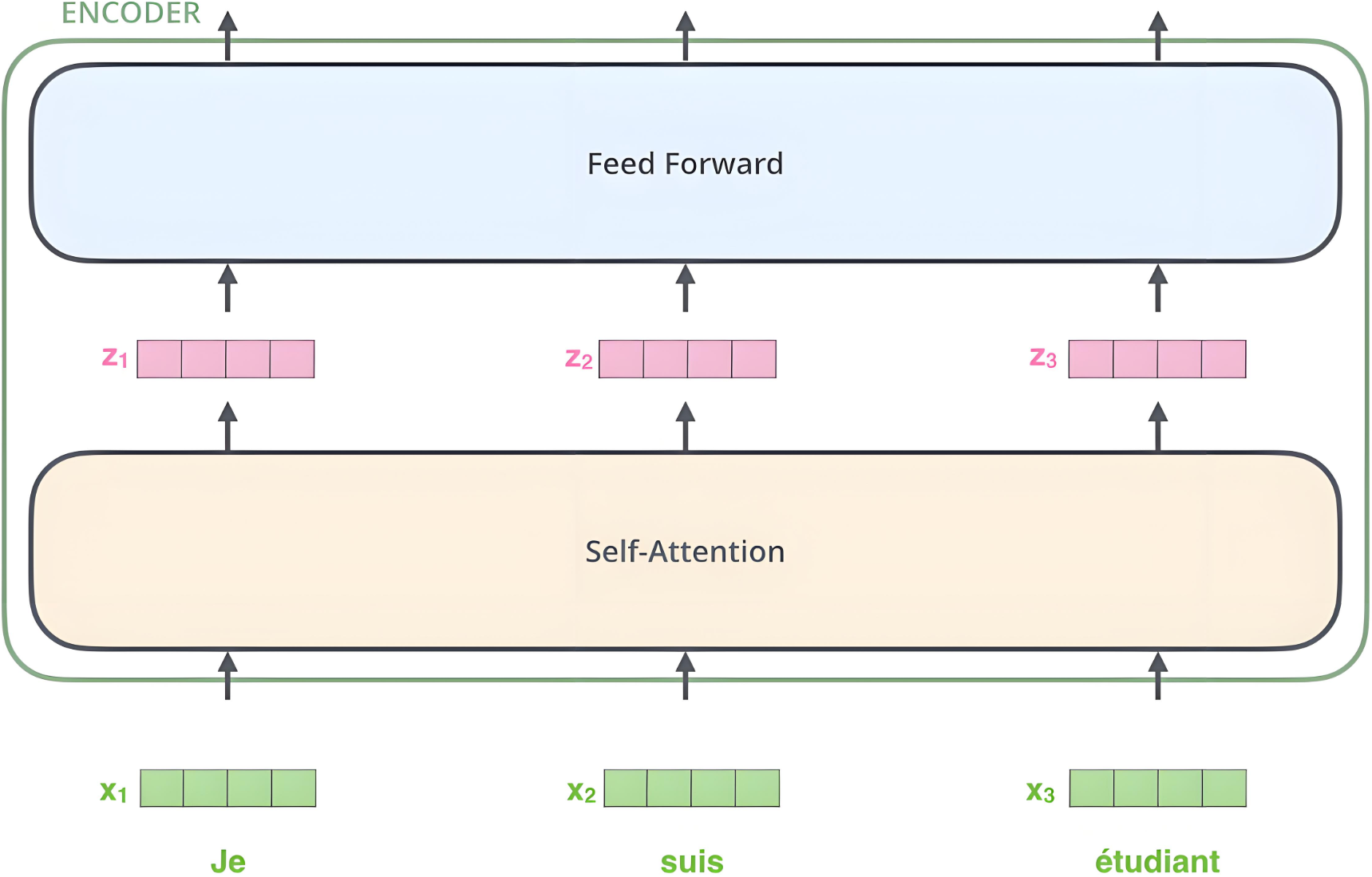
Encoder由N个相同结构的编码模块堆积而成,原始的Transformer是6个。
模块组成部分:Multi-Head Attention、Feed Forward、Add&Norm。
1.1.1 Multi-Head Attention
就是你认为的多头注意力机制
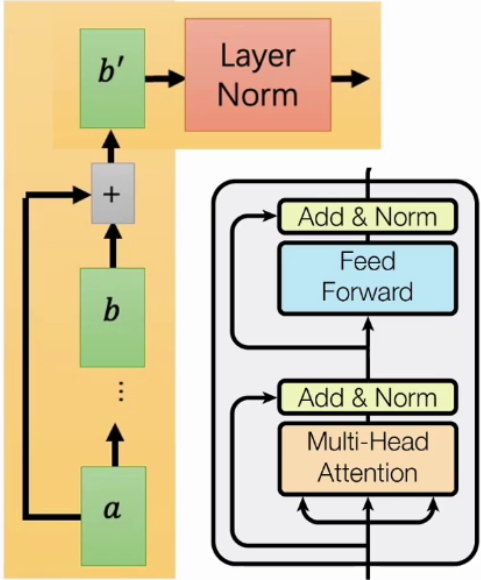
1.1.2 Add&Norm
经过残差连接和层归一化处理,让训练过程更稳定。残差就是你以为的残差思想。
 |
|---|
| Layer Normalization会将每一层神经元的输入都调整成相同均值方差,可以加快收敛。 |
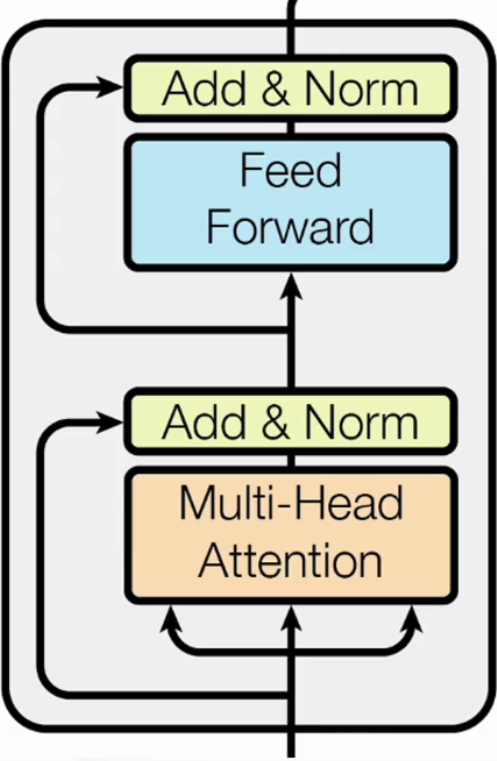
1.1.3 Feed Forward
就是一个全连接层,用于对每个位置的输出进行非线性变换。
 |  |
|---|
Feed Forward 层由两个全连接层组成
FFN(x) = max(0,xW1 +b1)W2 +b2
第一层激活函数为 ReLU,第二层不使用激活函数。
x是输入,全连接层的输入和输出都是512维,中间隐层维度为 2048。
1.2 解码器Decoder
与编码器相似,由N个相同结构的解码模块堆积而成。它还引入了“掩蔽多头自注意力(Masked Multi-Head Attention)”层。
组成部分:Masked Multi-Head Attention、Add & Norm、Multi-Head Attention、Feed Forward
1.2.0 自回归特性
Autoregressive Property,是指模型在生成序列时,每生成一个新的元素,只能依赖前面已经生成的元素,不能依赖未来的信息,而不是一次性生成整个序列。
逐步生成:
模型一次生成一个元素,并将它作为下一次生成的输入。
因果性:
自回归模型是因果的(causal),即当前时刻的输出只依赖于过去时刻的输入,而不依赖于未来的输入。
这种因果性确保了模型在生成序列时不会“偷看”未来的信息。
数学表示:
假设序列 x = (x_1, x_2, \dots, x_T),自回归模型的目标是建模序列的联合概率分布 P(x)。
根据概率链式法则,联合概率可以分解为条件概率的乘积:
自回归模型通过逐步预测每个条件概率 P(x_t | x_1, x_2, \dots, x_{t-1}) 来生成序列。
简单来说,自回归特性让模型在生成序列时能够遵循时间顺序和因果关系,避免了在训练过程中“泄漏”未来信息。
1.2.1 Masked Multi-Head
Masked Multi-Head Attention,用于解决序列任务的并行计算与自回归特性冲突问题。
1.2.1.1 产生背景
解码采用矩阵并行计算,一步就把所有目标单词预测出来。所以我们要做到:
当解码第1个字时,只能与第1个字的特征计算相关性;
当解码第2个字时,只能与第1、2个字的特征计算相关性,依此类推。
在翻译的过程中是顺序翻译的,即翻译完第 i 个单词,才可以翻译第 i+1 个单词。
通过 Masked 操作可以防止第 i 个单词知道 i+1 个单词及其之后的信息。
于是,引入了Masked设计。
1.2.1.2 内部结构
第一个Multi-Head Attention采用了Masked操作。
内部结构: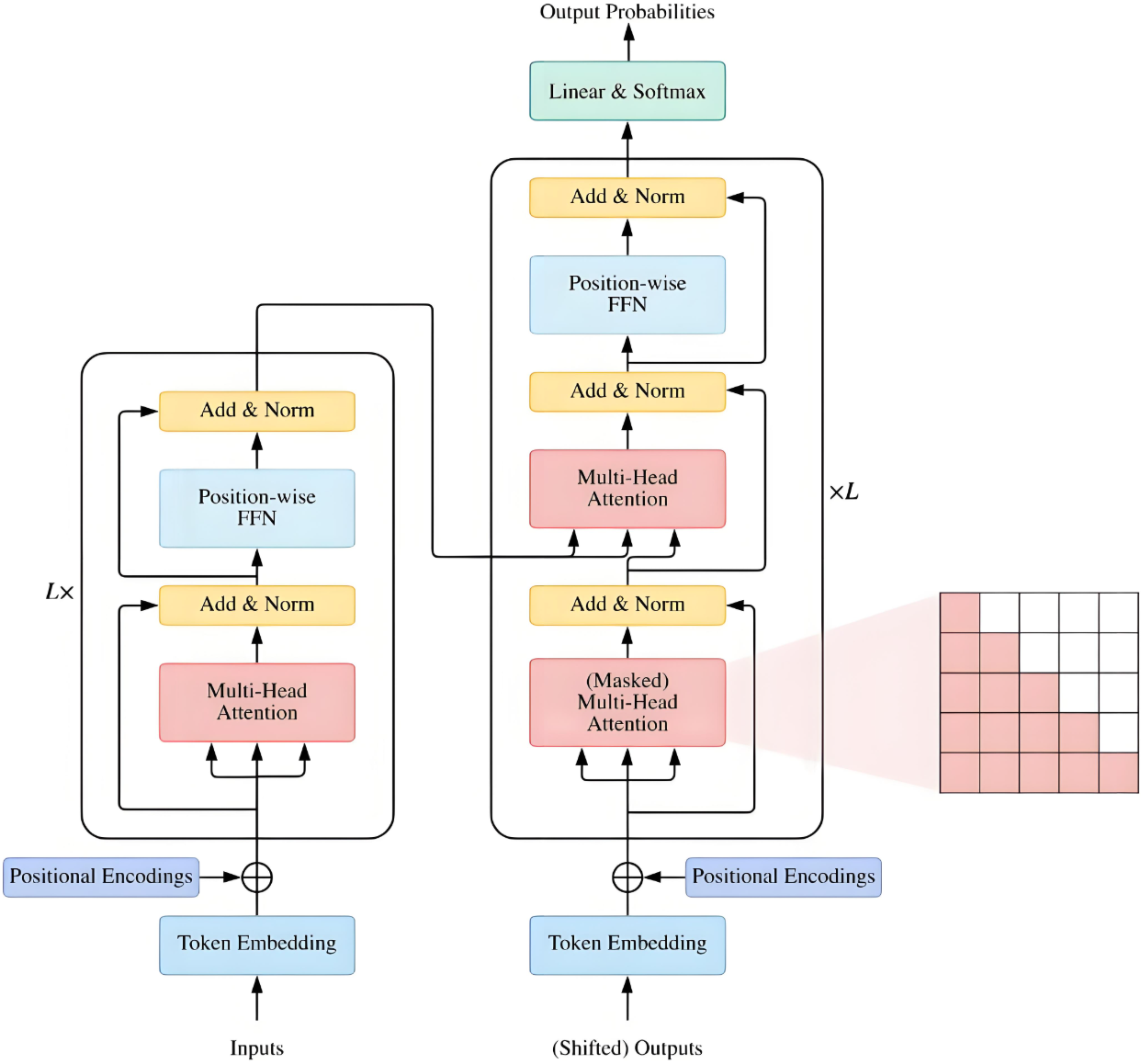
新增了Mask:先Mask,后通过 softmax 得到归一化的注意力权重。
1.2.1.3 实现步骤
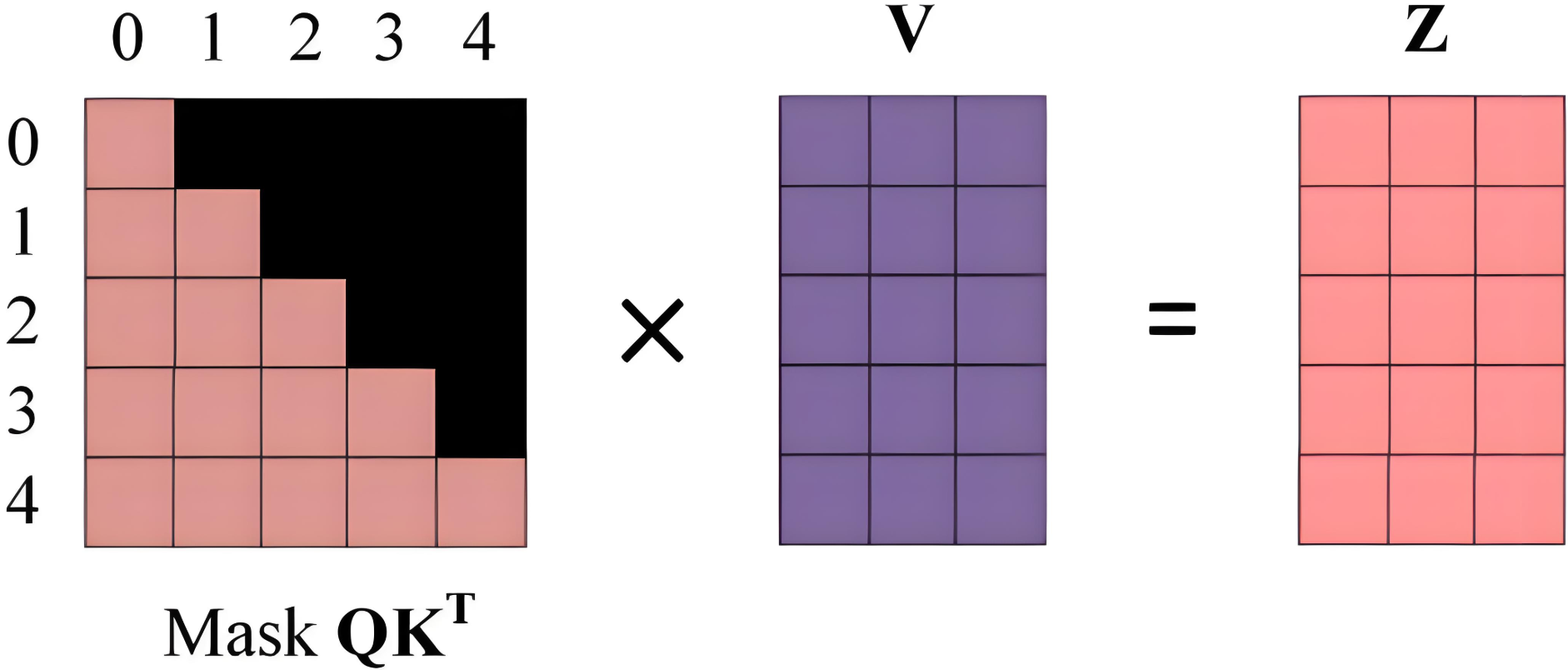
例子:以 0\:1\:2\:3\:4\:5 分别表示 <Begin> I have a cat <end>,实现步骤如下:
第一步:
Decoder输入矩阵X:包含 <Begin>l have a cat (0,1,2,3,4) 五个单词的表示向量。
Mask矩阵:是一个 5\times5 的上三角矩阵。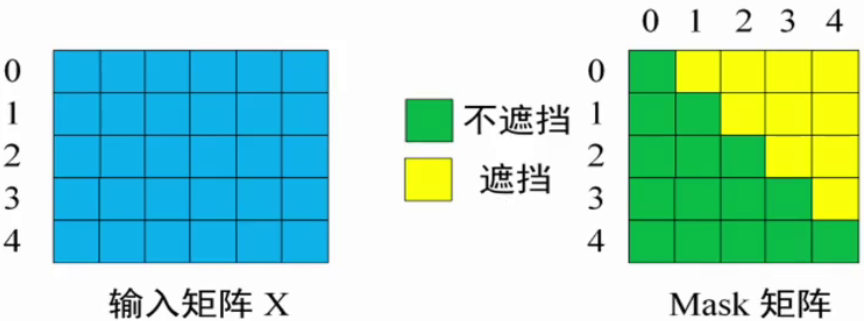
第二步:标准的自注意力计算中间特征,和masked无关
通过输入矩阵 X 计算得到 Q,K,V 矩阵,然后计算 Q 和 K^T的乘积 QK^T
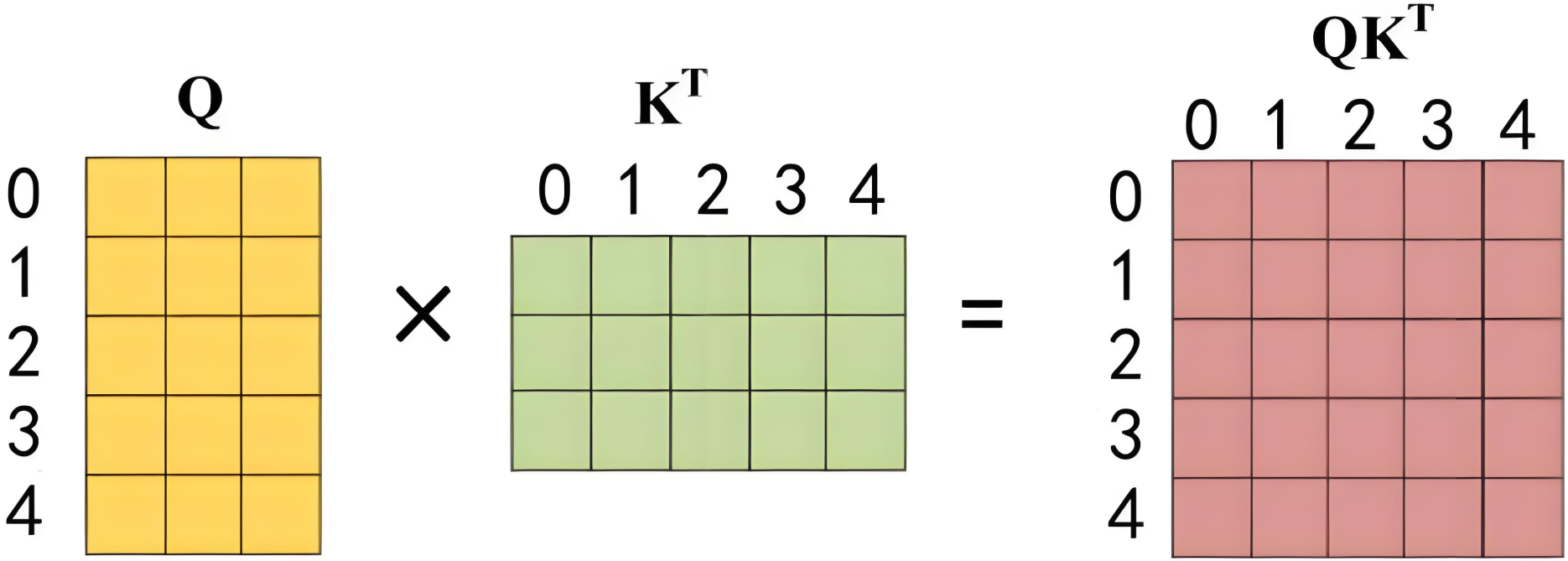
第三步: 计算中间特征
计算注意力分数,在 Softmax 之前需要使用Mask矩阵遮挡住每个单词之后的信息。
其中,黑色部分表示注意力值为 0。
Mask QK^T 每一行的和为 1,词 0 在词 1,2,3,4 上注意力值为 0,词 1 在词 2,3,4 上注意力值为 0,以此类推。
Mask矩阵数学表示如下: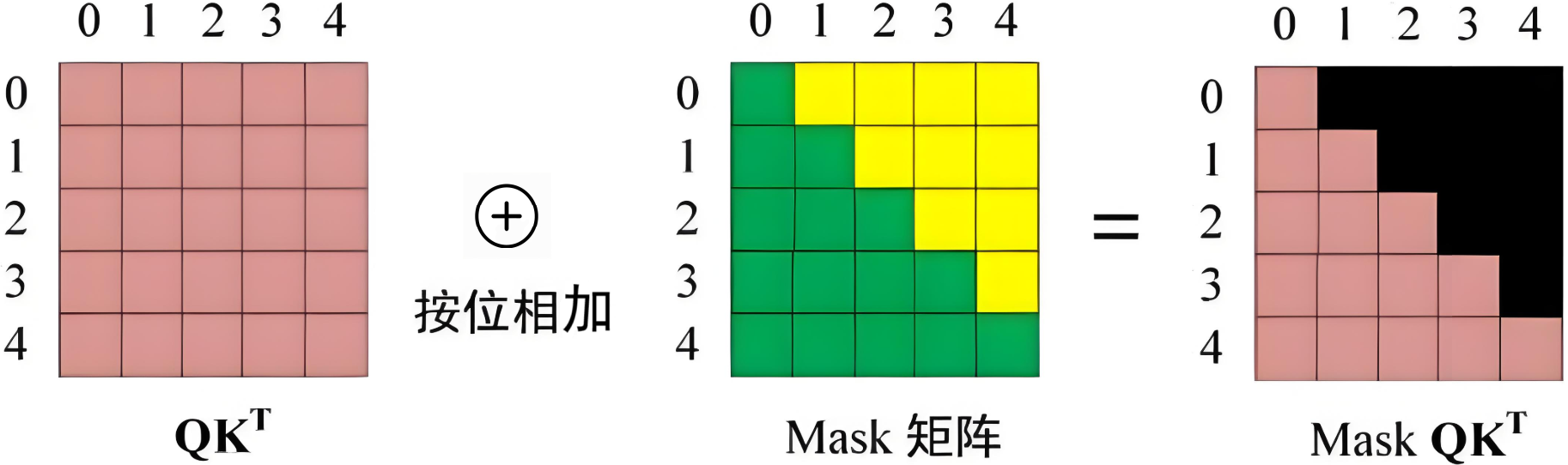
其中:
M_{ij} = 0 \quad 当 i \geq j,即当前位置 i 可以看到自己及之前的所有位置。
M_{ij} = -\infty \quad 当i < j,即当前位置 i 不允许看到未来的任何位置。
针对当前例子Masked矩阵如下:
第四步: 计算输出特征
使用注意力矩阵Mask QK^T 与矩阵 V 相乘,得到输出 Z,单词 1 的输出向量 Z_1,只包含单词 1 信息,单词 2 的输出向量 Z_2,只包含单词 1、2 信息,以此类推。
1.2.2 Add&Norm
同上:代码实现的时候,先Norm后Add
1.2.3 Multi-Head Attention
这是解码模块第二个Multi-Head Attention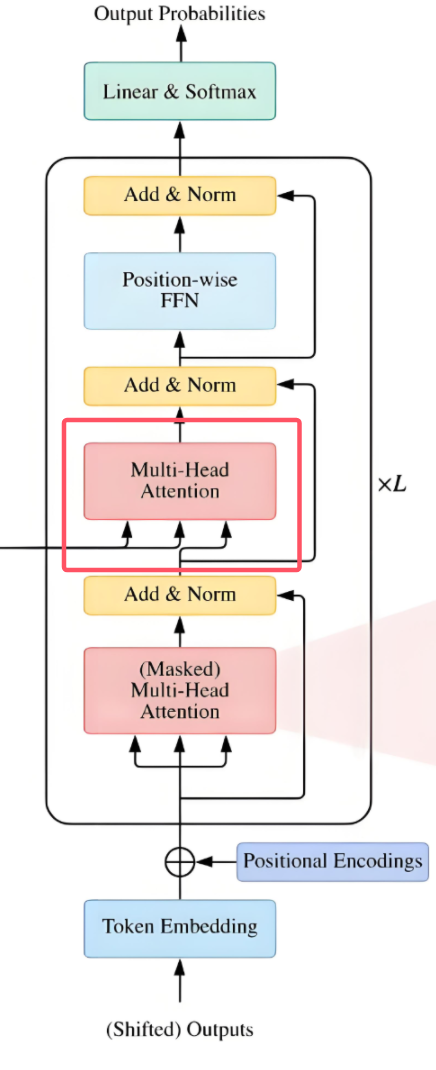
说明:
根据Encoder的输出 C 计算得到 K,V;
根据上一个 Decoder block 的输出 Z 计算 Q;
如果是第一个Decoder block则使用输入矩阵 X 进行计算;
1.2.4 Feed Forward
就是以前的知识点
2. 输入模块
输入模块是将原始输入数据转换为适合网络处理的向量表示:单词嵌入向量 + 位置编码向量。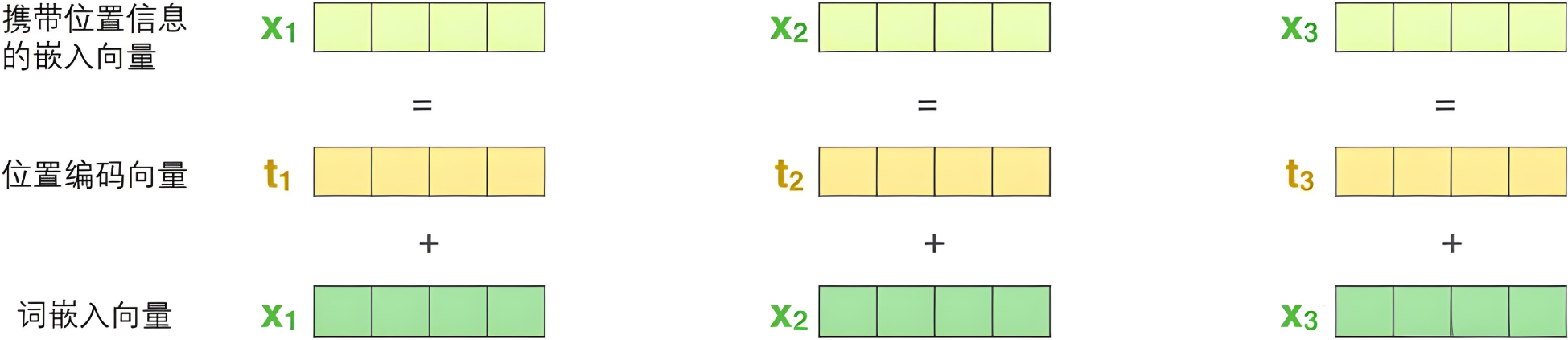
词嵌入向量:
可以采用 Word2Vec、Fasttext、Glove等算法预训练得到,也可以在 Transformer 中训练得到。
位置编码向量:
Transformer模型没有像RNN或CNN那样的顺序信息;
需要显式地将位置信息加入到输入中,以让模型知道各个元素在序列中的位置;
位置编码通过添加一个与词嵌入同维度的向量来实现,它为每个位置提供一个唯一的表示;
位置编码可以是固定函数或可学习的。
2.1 单词输入
单词输入采用词嵌入就可以了,比较直接。
 |  |
|---|---|
| 每个单词嵌入为 512 维的向量,此时输入即为 3\times512 | 上一层的输出作为下一层的输入 |
2.1.1 向量填充
不同训练句子单词个数通常是不一样,为了确保同一batch中的序列长度一致,便于批量处理,我们需要做向量填充操作。
可以简单统计所有训练句子的单词个数,取最大值,如 10;
编码器输入是 10\times512,额外填充的512维向量可以采用固定的标志编码得到,例如$$、0。
如果遇到极端的特别长的,可以丢掉一部分特殊字符。
需要PaddingMask进行掩盖。
2.2 位置编码
自注意力机制无法捕捉输入元素序列的顺序,所以需要一种方法将单词的顺序合并到Transformer架构中,于是位置编码应运而生。
位置编码可以通过正弦和余弦函数生成,也可以通过学习得到。
2.2.1 固定函数
给定输入序列的长度 N 和词向量的维度 d,对于第 i 个位置和第 j 个维度的编码,位置编码的计算公式如下:
sentence = "<BOS> 我 喜欢 自然语言 处理" N = 5 d = 512
说明:
i 是序列中位置的索引(从 0 开始)。
j 是词向量的维度索引(从 0 到 d/2 - 1)。
10000 是一个超参数,用于控制频率的衰减。

句子长度为 5,编码向量维数 D=4 计算得到的位置编码会直接加到词嵌入中。
所有句子共享这个位置编码矩阵。
2.2.1.1 函数特点
连续性:通过正弦和余弦的方式,位置编码具有平滑的特性,便于捕捉位置间的连续性。
可区分性:每个位置编码的值都是唯一的,可以帮助模型区分不同位置。
2.2.1.2 位置可控性
正弦余弦函数特征:
基于此特性,对于固定长度的间距 k,PE(pos+k) 可以用 PE(pos) 计算得到。
那这个有啥玩意用处呢?假设k=1,那么:
下一个词语的位置编码向量可由前面的编码向量线性表示;
使模型能适应比训练集里面最长的句子更长的句子。
假设训练集最长的句子是 20 个单词,输入长度为 21 个单词的句子,则可以计算出第 21 位的位置向量
2.2.1.3 位置编码可视化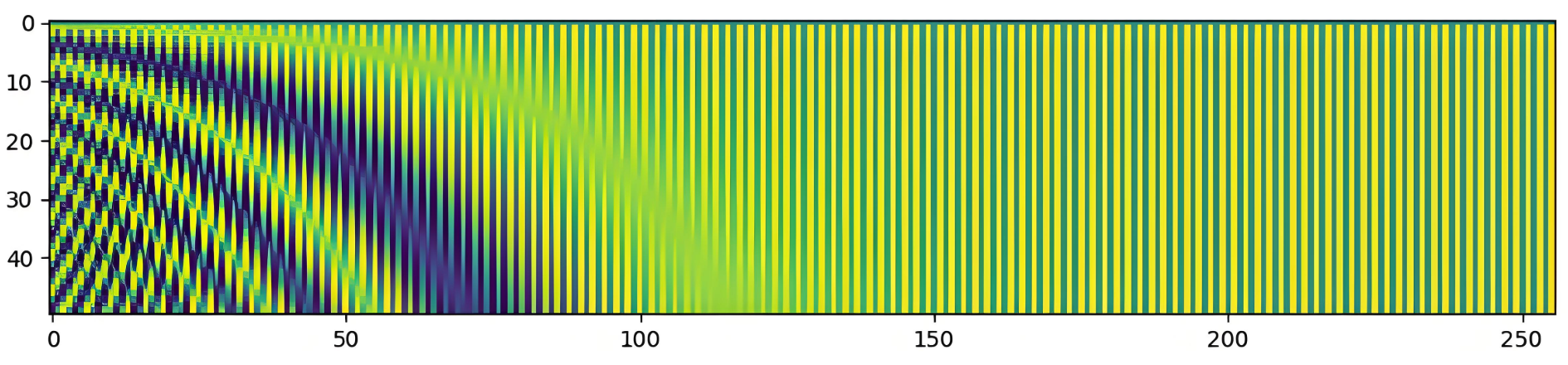
| 50 个词嵌入,维度 512 的位置编码热力图 |
2.2.2 可学习位置编码
也有研究者提出了可学习的位置编码。可学习的位置编码通过训练优化得到位置向量。相比之下,固定函数位置编码不需要训练,但表现有时不如学习到的位置编码。
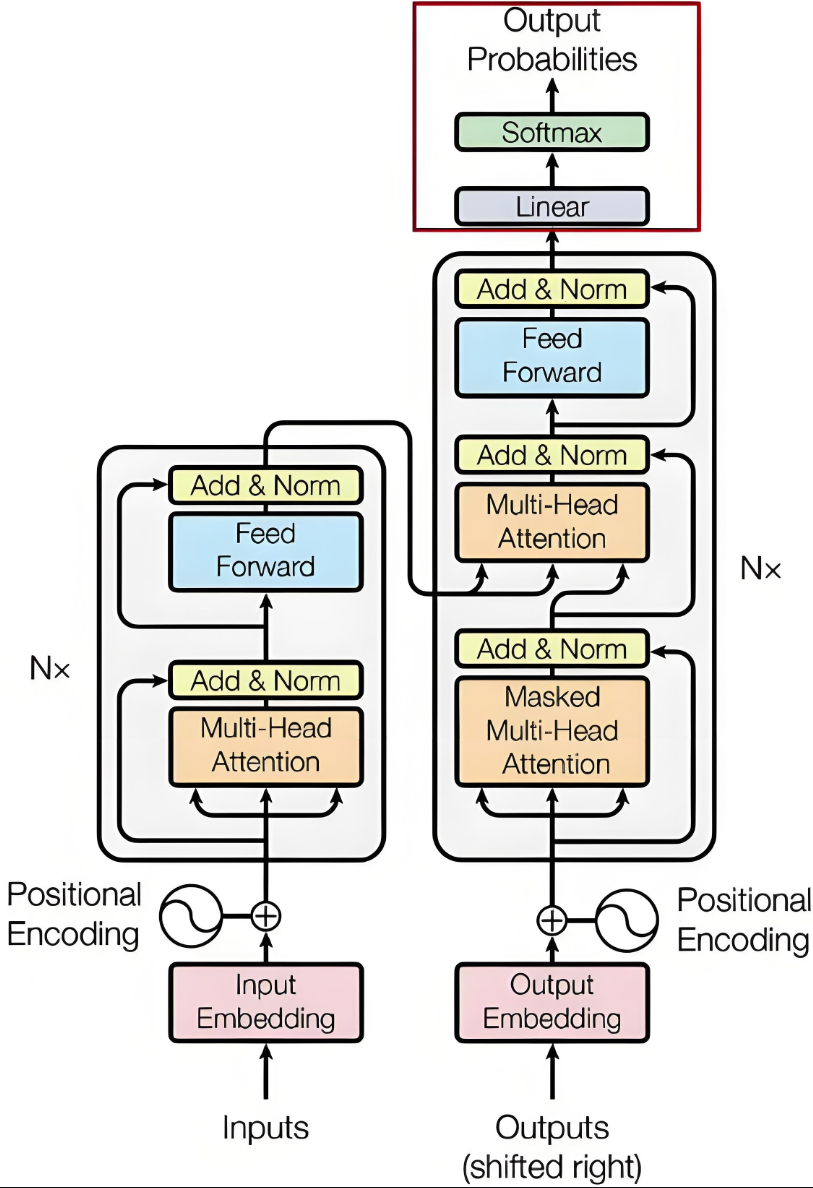
3. 解码输出
解码器的最终输出通过线性变换和 Softmax 函数,生成每个时间步的概率分布。
3.1 基本流程
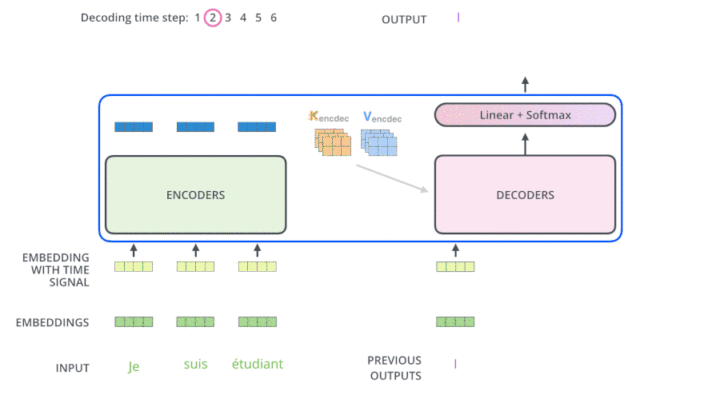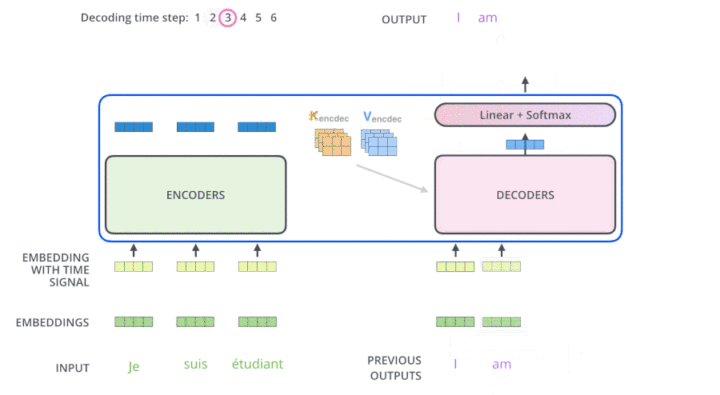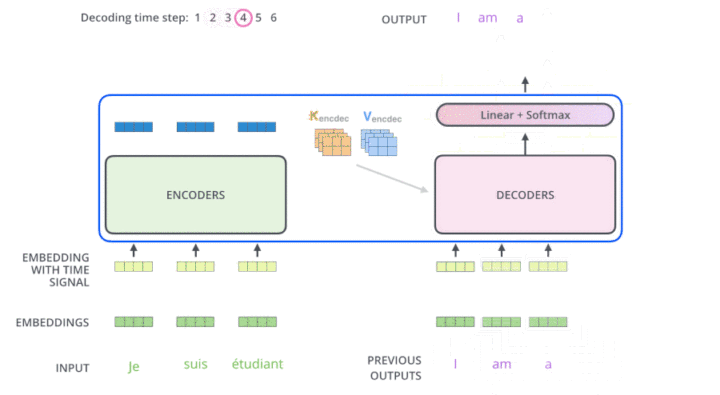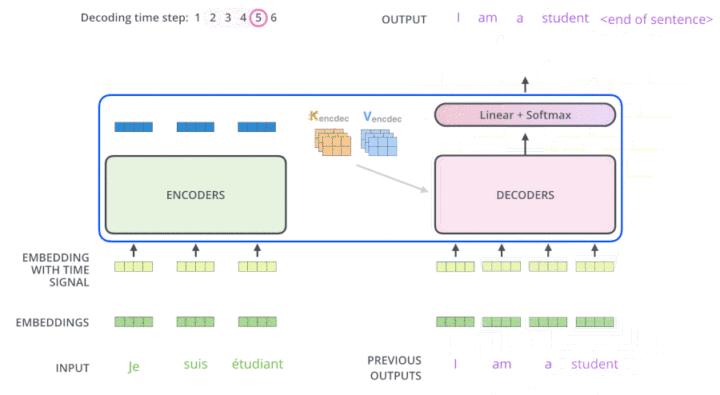
说明:
编码器输出:K 和 V;
通过线性变换映射出 K 和 V
输入到解码器的第二个注意力模块,这就是Cross-Attention
解码器输入:
第一个编码器:<BOS> + K 和 V
后续的解码器:已有解码器输出 + K 和 V
针对案例:
输入开始解码==[<BOS>]== ,预测 i
输入已解码的==[<BOS>, i]==,预测 am
输入已解码的==[<BOS>, i, am]==,预测 a,以此类推
输入已解码的==[<BOS> , i ,am,a,student]==,预测 <EOS>
预测结束
3.2 预测输出
 解码器经线性变换后,基于 Softmax 输出概率值,它表示对词汇表中每个词的概率。
解码器经线性变换后,基于 Softmax 输出概率值,它表示对词汇表中每个词的概率。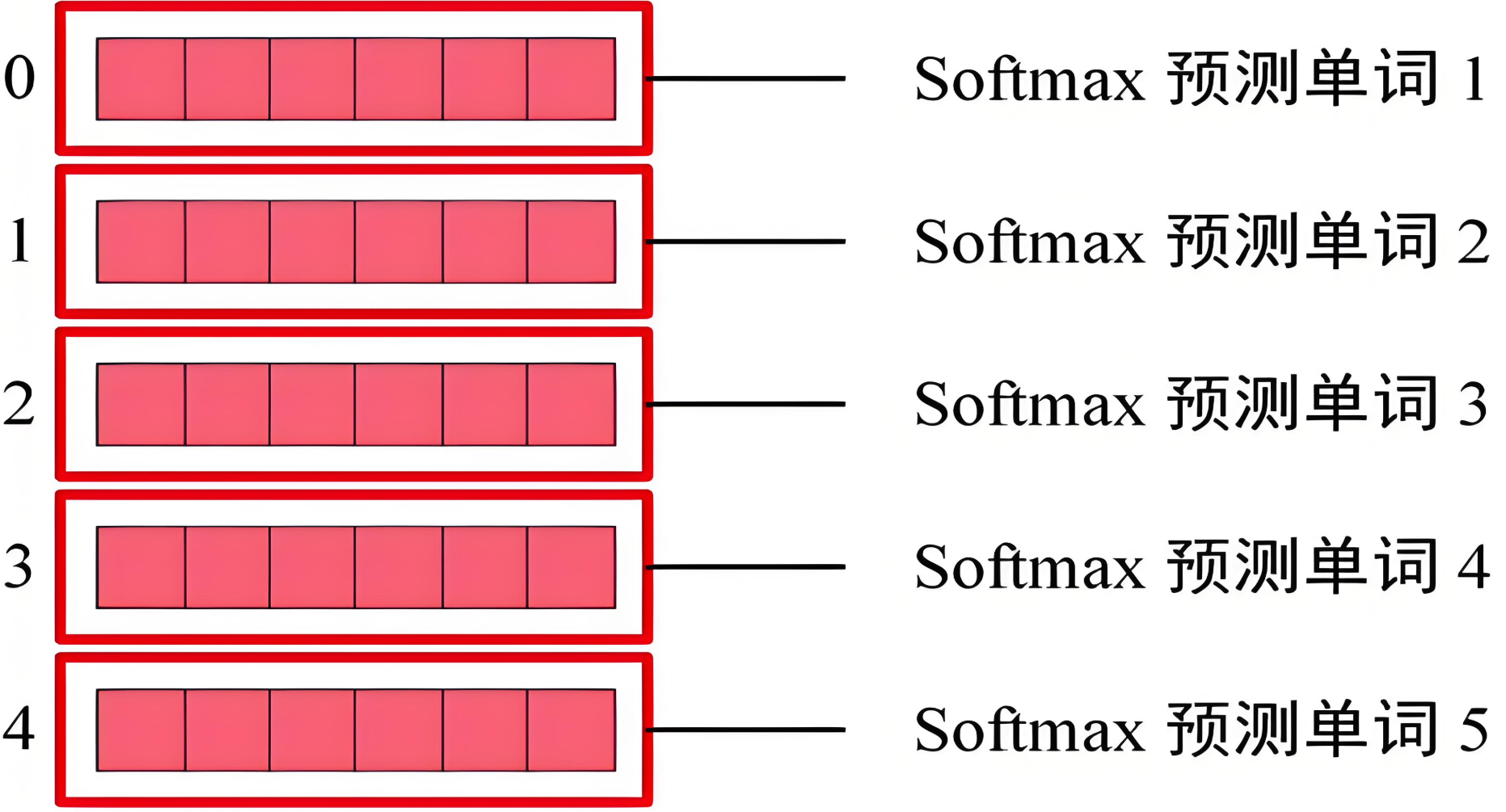
具体过程:
解码器输出:每个时间步输出一个隐藏状态。
线性层:解码器的输出经线性变换层映射到目标词汇表,得到一个原始分数。
Softmax: 经 Softmax后,得到一个概率分布,最大概率值对应的词就是预测结果。
3.3 训练与推理
在训练与推理过程中,解码器的工作机制是有差异的。
3.3.1 训练阶段
在训练时,解码器的当前输入是真实目标序列,叫做teacher forcing。
直接使用真实标签输入,避免了错误传播,模型能更快收敛。
| 输入给解码器 | 目标标签(预测目标) |
|---|---|
<BOS> | I |
<BOS>, I | am |
<BOS>, I, am | a |
| … | … |
3.3.2 推理阶段
没有真实答案提供,模型只能自己一步步预测出来!
每一步的输出会被作为下一步的输入
当前输入给解码器 模型预测输出 <BOS>I(模型预测的)<BOS>, Iam(模型预测)<BOS>, I, ama<BOS>, I, am, astudent<BOS>, I, am, a, student<EOS>如前面预测错了,后面会受到影响,这就是所谓的 暴露偏差 问题。
4. 认知掩码
Padding Mask和Sequence Mask是两种常见的掩码机制。
4.1 PaddingMask
填充掩码。
输入的序列长度通常不同,为了进行批处理,需要对短序列进行填充,使得所有输入序列长度一致。填充符号(如 <PAD>)并不代表实际信息,因此需要被掩盖,以确保不会影响模型计算。
['我', '喜欢', <PAD>, <PAD>]
4.1.1 使用场景
填充掩码用于自注意力计算中,避免填充部分对模型产生影响。
填充掩码一般用于编码器部分,也会传递到解码器部分,确保解码器不会基于填充符号做决策。
4.1.2 具体实现
实现:填充掩码通常是一个与输入序列长度相同的向量,把填充位置标记为 1,其他标记为 0。
掩膜过程:在计算注意力权重时,把填充位置的注意力值设为 -∞,Softmax 后为 0,从而忽略这些位置。
4.2 SequenceMask
序列掩码主要用于解码阶段,尤其在生成任务中,确保模型在生成每个词时只依赖已生成部分,而不会看到未来的词。
4.2.1 使用场景
在生成任务中,解码器的自注意力机制需要被限制,以确保只使用已生成的词进行生成。
Sequence Mask主要用于解码器的自注意力层中,防止模型在生成当前词时,看到后续词汇。
4.2.2 具体实现
实现:序列掩码通常是一个上三角矩阵,掩码位置标记为 -∞,表示这些位置的词在当前步骤不可见。
掩膜过程:在计算解码器自注意力时,序列掩码将未来的词的注意力设为 -∞,确保模型只能“看到”已生成的词。
4.3 掩码对比
| 掩码类型 | 使用场景 | 描述 |
|---|---|---|
| Padding Mask | 输入序列存在填充符号时 | 避免填充符号对自注意力计算产生影响,确保模型只关注有效单词。 |
| Sequence Mask | 解码阶段,生成任务中的自回归生成 | 防止模型看到当前时间步之后的词,确保生成顺序的正确性。 |
Padding Mask主要用于编码器和解码器中处理输入填充符号的问题。
Sequence Mask主要应用于解码器,确保生成过程中模型只依赖于已经生成的部分,而不能访问未来的词。
掩码机制确保了自注意力机制能够在不同任务中正确处理输入和生成序列,保障模型的有效性和稳定性。