高级SQL优化 | 告别 Hive 中 GROUP BY 的大 KEY 数据倾斜!PawSQL 自适应优化算法详解
数据倾斜让你的Hive查询慢如蜗牛?单个热点分组拖垮整个集群?PawSQL独家算法GroupSkewedOptimization来拯救!

🎯 痛点直击:当数据倾斜遇上分组操作
想象这样一个场景:
你的电商平台有1000万VIP用户订单和100万普通用户订单。当你用GROUP BY按客户类型分组统计时:
SELECT customer_type, COUNT(*), SUM(amount)
FROM orders
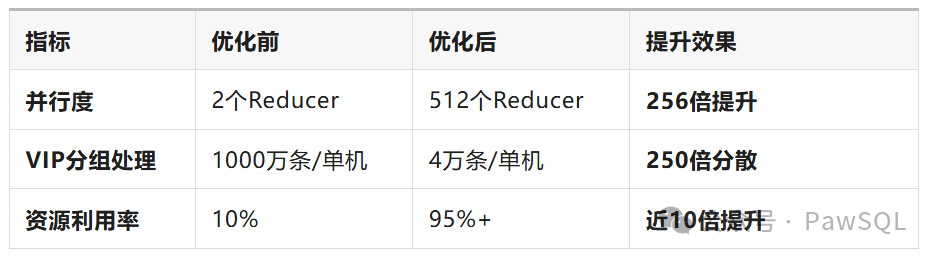
GROUP BY customer_type;VIP分组:1个Reducer苦苦支撑1000万条数据
普通分组:1个Reducer轻松处理100万条数据
其他Reducer:集体摸鱼,资源浪费
最终后果: 整个作业被最慢的那个Reducer拖垮!
💡 核心优化算法:两阶段聚合
化整为零,各个击破。
PawSQL的GroupSkewedOptimization算法采用"分而治之"的经典思想:
🔹 第一阶段:加盐打散 → 热点数据分流到256个子分组
🔹 第二阶段:合并聚合 → 还原最终结果
优化前 vs 优化后对比
🔧 GroupSkewedOptimization算法深度解析
触发条件
✅ 支持场景
GROUP BY分组查询
简单单列分组
标准聚合函数(COUNT/SUM/MAX/MIN/AVG)
❌ 限制条件
包含HAVING子句
复杂分组表达式
核心重写策略
🎲 盐值生成
CAST(RAND() * 256 AS INT) as salt这个简单表达式生成0-255随机整数,将每个分组拆分成256个子分组!
📊 聚合函数智能处理
COUNT函数:第一阶段COUNT → 第二阶段SUM
-- 重写前
SELECT region, COUNT(*)
FROM sales_data
GROUP BY region;
-- 重写后
SELECT region, SUM(count_) -- 关键转换!
FROM (SELECT region, COUNT(*) as count_,CAST(RAND() * 256 AS INT) as saltFROM sales_dataGROUP BY region, salt
) DT_xxx
GROUP BY region;AVG函数:拆解为SUM+COUNT
-- 原始AVG
SELECT region, AVG(amount)
FROM sales_data
GROUP BY region;
-- 智能重写
SELECT region, SUM(sum_) / SUM(count_) -- 重新计算平均值
FROM (SELECT region, SUM(amount) as sum_, COUNT(amount) as count_,CAST(RAND() * 256 AS INT) as saltFROM sales_dataGROUP BY region, salt
) DT_xxx
GROUP BY region;🌟 实战案例:订单统计的完美蜕变
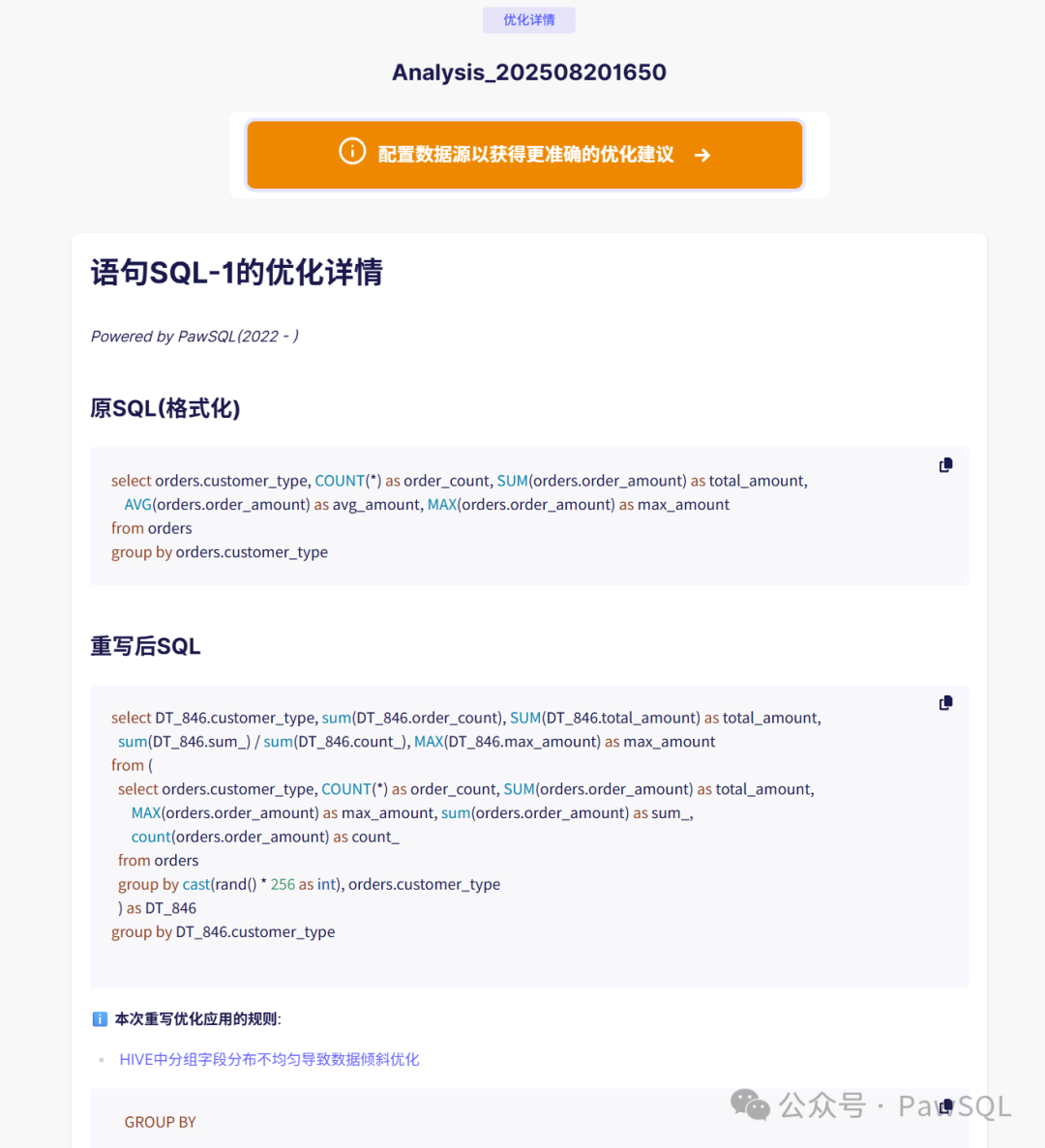
原查询:简单但低效
SELECTcustomer_type,COUNT(*) as order_count,SUM(order_amount) as total_amount,AVG(order_amount) as avg_amount,MAX(order_amount) as max_amount
FROM orders
GROUP BY customer_type;优化后:复杂但高效
SELECTcustomer_type,SUM(count_) as order_count, -- COUNT → SUMSUM(sum_) as total_amount, -- SUM保持不变SUM(sum_) / SUM(count_) as avg_amount, -- AVG重新计算MAX(max_) as max_amount -- MAX保持不变
FROM (SELECTcustomer_type,COUNT(*) as count_,SUM(order_amount) as sum_,COUNT(order_amount) as count_,MAX(order_amount) as max_,CAST(RAND() * 256 AS INT) as salt -- 🔑 关键的盐值FROM ordersGROUP BY customer_type, salt
) DT_123
GROUP BY customer_type;PawSQL自动识别并优化:
🎯 适用场景:什么时候该用这招?
✅ 最佳适用场景:严重的数据倾斜
🔹 电商平台:按商家、地区分组的订单统计
🔹 金融系统:按客户等级分组的交易分析
🔹 广告系统:按渠道分组的投放效果统计
🔹 物流系统:按配送区域分组的包裹统计
⚠️ 使用注意事项
会增加查询复杂度和中间数据量
对轻微倾斜可能效果不明显
🎉 总结:PawSQL让SQL优化变得简单高效
作为专业的SQL优化引擎,GroupSkewedOptimization算法展现了PawSQL在SQL优化领域的深厚技术积累:
✨ 自动化:无需手动调优,一键解决倾斜问题
✨ 智能化:精准识别优化时机,避免过度优化
✨ 通用化:支持多种聚合函数,适用性广
🌐关于PawSQL
PawSQL专注于数据库性能优化自动化和智能化,提供的解决方案覆盖SQL开发、测试、运维的整个流程,广泛支持多种主流商用、国产和开源数据库,为开发者和企业提供一站式的创新SQL优化解决方案。