布隆过滤器:用微小的空间代价换取高效的“可能存在”判定

01 引言
在现代软件架构中,我们经常面临一个经典问题:如何快速且节省空间地判断一个元素是否存在于一个超大规模的数据集合中? 例如,用户注册时检查用户名是否已被占用,或是网络爬虫判断一个URL是否已被抓取。
最直观的解决方案是使用哈希表(如 HashSet)或将所有元素存入数据库。然而,当数据量达到亿级甚至更高时,这两种方案都会面临巨大挑战:哈希表消耗大量内存,数据库查询则可能成为性能瓶颈。
而布隆过滤器(Bloom Filter) 正是为了解决此类问题而生的概率型数据结构。它并非给出一个绝对精确的答案,而是以极小的空间代价,提供“某元素一定不存在”或“某元素可能存在”的答案。
02 核心原理
布隆过滤器到底有什么魔力?
2.1 位数组
假如我们将数据放在集合中以及布隆过滤器中,同样是占用内存。为什么会布隆过滤器会节省内存?
布隆过滤器没有直接存储数据,而是将目标数据N次哈希,在不同的位置标记为1,无论什么数据,对于布隆过滤器来说存起来就是1,这就是为数组。所以影响布隆过滤器的内存大小的数据数据的数量和数据额理性没有关系,而内存和数据类型与直接的关系。
在计算机种,一个int会占用4个字节,而1字节占8位。假设我们有100W个int数,分别直接放在内存中和布隆过滤器中占用的内存:
- 直接内存:100W*4byte/1024/1024 = 3.8M
- 布隆过滤器:100W/8/1024/1024 * N = 0.12M * N
其中N位哈希函数的个数,假设有5个,那么0.12M * 5 = 0.6M
我们大致可算出相差的倍数:3.8 / 0.6 = 6 倍
这只是简单的int类型,如果是其他类型,可能相差的更多。
2.2 哈希函数
布隆过滤器通常使用多个不同的哈希函数。这些哈希函数应具有良好的随机性和均匀性,能够将不同的元素尽可能均匀地映射到不同的位置。
哈希函数计算速度快,时间复杂度通常为O(1)。相同输入必然产生相同哈希值,确保结果可重复验证。
2.3 核心流程
布隆过滤器的核心是一个巨大的位数组(Bit Array) 和一系列无偏的哈希函数。其工作流程分为两步:
添加元素
- 将新元素通过 K 个不同的哈希函数计算,得到 K 个哈希值。
- 将这些哈希值映射到位数组的对应位置上,并将该位置标记为 1
查询元素
- 将待查询元素同样通过那 K 个哈希函数计算,得到 K 个哈希值。
- 检查位数组中这些对应的位置是否全部为 1。只要有任何一个位置为0,则该元素已经不存在于布隆过滤器中,如果都为1,则可能存在布隆过滤器中(存在误判可能)。
为什么是“可能存在”?—— 理解误判率(False Positive)
因为哈希冲突的存在,不同的元素通过哈希函数计算后,可能会映射到位数组的相同位置。当查询一个不存在的元素时,如果它的 K 个哈希值对应的位恰好都被其他元素设置为 1 了,布隆过滤器就会误判它为“存在”。
布隆过滤器的巧妙之处在于,它永远不会产生假阴性(False Negative)。如果元素确实存在,它对应的位肯定都是 1,所以绝不会误报“不存在”。这一特性使其非常适合做“前置过滤器”。
03 最佳实践
3.1 谷歌Guava的布隆
布隆过滤器的使用非常简单:
@Test
void test02() {BloomFilter<CharSequence> bloomFilter = BloomFilter.create(Funnels.stringFunnel(StandardCharsets.UTF_8), 3);bloomFilter.put("a");bloomFilter.put("b");bloomFilter.put("c");System.out.println(bloomFilter.mightContain("1"));// false
}
使用就像操作集合一样,加入到布隆过滤器里面,校验的时候判断是否存在即可。
如果用于生产,布隆过滤器应设计成单例,随着项目启动加载热点数据。
3.2 Hutool的布隆
@Test
void test02() {BitMapBloomFilter bitMap = BloomFilterUtil.createBitMap(3);bitMap.add("1");bitMap.add("2");bitMap.add("3");System.out.println(bitMap.contains("1"));
}
这个使用起来更简单,完全和集合一致。
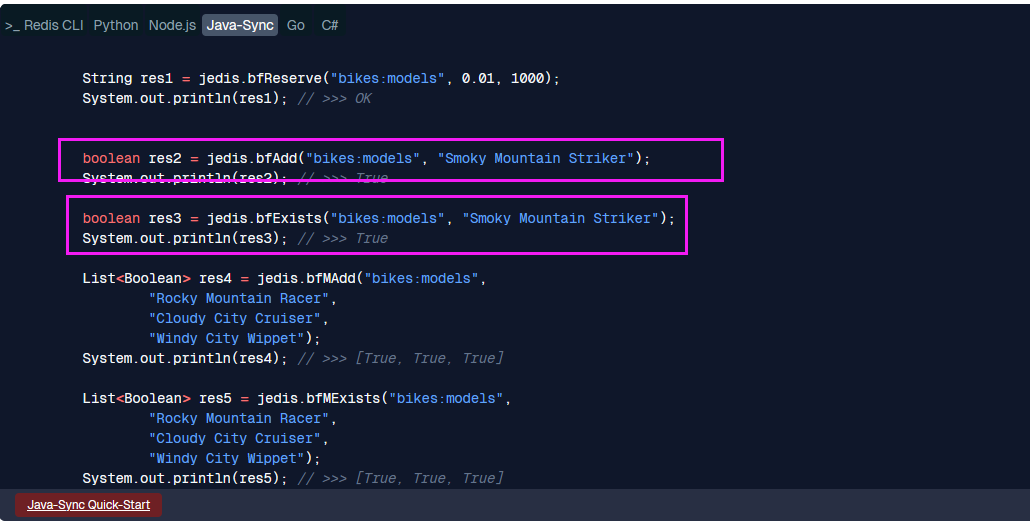
3.3 Redis的布隆过滤器
在微服务和分布式环境中,我们需要一个所有服务实例都能访问的、持久化的布隆过滤器。
Redis 8.0 不在区分插件,全部集成在Redis中。曾经有一度时间,要使用布隆过滤器还需要单独加载插件才可以。

04 小结
布隆过滤器是一种“空间换时间和确定性”的经典数据结构。它通过接受一个可控的、微小的误判率,换来了海量数据去重场景下无与伦比的空间效率和查询性能。
理解其原理和“可能存在”的特性,是正确使用它的关键。它通常不作为最终的决策依据,而是作为一个高效的前置屏障,拦截掉绝大部分不必要的昂贵操作(如数据库查询),从而为整个系统带来巨大的性能提升。
率和查询性能。
理解其原理和“可能存在”的特性,是正确使用它的关键。它通常不作为最终的决策依据,而是作为一个高效的前置屏障,拦截掉绝大部分不必要的昂贵操作(如数据库查询),从而为整个系统带来巨大的性能提升。