遥感机器学习入门实战教程|Sklearn案例⑤:集成学习方法全览
在机器学习的实际应用中,单一分类器往往存在局限:比如决策树容易过拟合,kNN 对噪声敏感,逻辑回归在高维数据下收敛慢。为了提升整体效果,我们通常会采用 集成学习(Ensemble Learning)。
这篇文章将基于 sklearn 框架,系统演示 Bagging、Boosting、Voting、Stacking 四类常见的集成学习方法,并在经典的 KSC 高光谱数据集 上做实验对比。
🧩 1. 实验思路
- 数据集:KSC 高光谱影像及其地物标注
- 预处理:标准化 + PCA 降维(仅作为特征压缩,取 30 维)
- 分类器:随机森林(RF)、AdaBoost、GBDT、Bagging(kNN)、Voting、Stacking
- 评价指标:Overall Accuracy (OA) 与 Kappa 系数
⚙️ 2. 完整代码
下面给出本次实验的完整代码,可以直接运行。请注意修改 DATA_DIR 为你存放数据的路径。
# -*- coding: utf-8 -*-
"""
Sklearn案例⑤:集成学习方法全览
- 演示 Bagging / Boosting / Voting / Stacking
"""
import os, numpy as np, scipy.io as sio, matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.decomposition import PCA
from sklearn.ensemble import (RandomForestClassifier, AdaBoostClassifier,GradientBoostingClassifier, BaggingClassifier,VotingClassifier, StackingClassifier)
from sklearn.svm import SVC
from sklearn.neighbors import KNeighborsClassifier
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score, cohen_kappa_score
import matplotlib
matplotlib.rcParams['font.family'] = 'SimHei'
matplotlib.rcParams['axes.unicode_minus'] = False# ===== 参数设置 =====
DATA_DIR = "你的数据路径" # 修改为存放 KSC.mat 和 KSC_gt.mat 的文件夹
PCA_DIM, TRAIN_RATIO, SEED = 30, 0.3, 42# ===== 1. 加载数据 =====
X = sio.loadmat(os.path.join(DATA_DIR, "KSC.mat"))["KSC"].astype(np.float32)
Y = sio.loadmat(os.path.join(DATA_DIR, "KSC_gt.mat"))["KSC_gt"].astype(int)
h, w, b = X.shape
coords = np.argwhere(Y != 0)
labels = Y[coords[:,0], coords[:,1]] - 1
num_classes = labels.max() + 1# ===== 2. 划分训练/测试 =====
train_ids, test_ids = train_test_split(np.arange(len(coords)), train_size=TRAIN_RATIO,stratify=labels, random_state=SEED
)
train_pixels = X[coords[train_ids,0], coords[train_ids,1]]
test_pixels = X[coords[test_ids,0], coords[test_ids,1]]# ===== 3. 标准化 + PCA(仅预处理) =====
scaler = StandardScaler().fit(train_pixels)
pca = PCA(n_components=PCA_DIM, random_state=SEED).fit(scaler.transform(train_pixels))
X_train = pca.transform(scaler.transform(train_pixels))
X_test = pca.transform(scaler.transform(test_pixels))
y_train, y_test = labels[train_ids], labels[test_ids]# ===== 4. 定义多个集成学习模型 =====
models = {"RF": RandomForestClassifier(n_estimators=20, random_state=SEED, n_jobs=-1),"AdaBoost": AdaBoostClassifier(n_estimators=20, random_state=SEED),"GBDT": GradientBoostingClassifier(n_estimators=20, random_state=SEED),"Bagging(kNN)": BaggingClassifier(KNeighborsClassifier(5), n_estimators=30, random_state=SEED),"Voting(SVM+kNN+LR)": VotingClassifier(estimators=[("svm", SVC(probability=True)), ("knn", KNeighborsClassifier(5)),("lr", LogisticRegression(max_iter=1000))],voting="soft"),"Stacking(SVM+kNN->LR)": StackingClassifier(estimators=[("svm", SVC(probability=True)), ("knn", KNeighborsClassifier(5))],final_estimator=LogisticRegression(max_iter=200))
}# ===== 5. 训练与评估 =====
results = {}
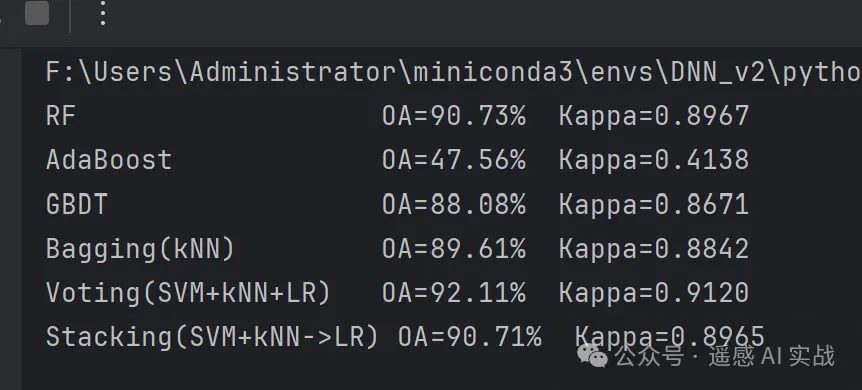
for name, clf in models.items():clf.fit(X_train, y_train)y_pred = clf.predict(X_test)oa = accuracy_score(y_test, y_pred)kappa = cohen_kappa_score(y_test, y_pred)results[name] = (oa, kappa)print(f"{name:20s} OA={oa*100:.2f}% Kappa={kappa:.4f}")# ===== 6. 可视化比较 =====
plt.figure(figsize=(8, 5), dpi=110)
names = list(results.keys())
oa_vals = [results[k][0] * 100 for k in names]
kappa_vals = [results[k][1] * 100 for k in names]
x = np.arange(len(names))
plt.plot(x, oa_vals, marker='o', linewidth=2.2, label='OA (%)')
plt.plot(x, kappa_vals, marker='s', linewidth=2.2, linestyle='--', label='Kappa × 100')
plt.xticks(x, names, rotation=20, ha='right')
plt.ylabel("Accuracy / Score (%)")
plt.title("Sklearn 集成学习方法对比")
plt.grid(alpha=0.25, linestyle='--')
for xi, yi in zip(x, oa_vals):plt.text(xi, yi + 0.6, f"{yi:.1f}", ha='center', fontsize=9)
for xi, yi in zip(x, kappa_vals):plt.text(xi, yi + 0.6, f"{yi:.1f}", ha='center', fontsize=9)
plt.legend(frameon=False, ncol=2, loc='upper left')
plt.tight_layout()
plt.show()
📊 3. 实验结果与分析
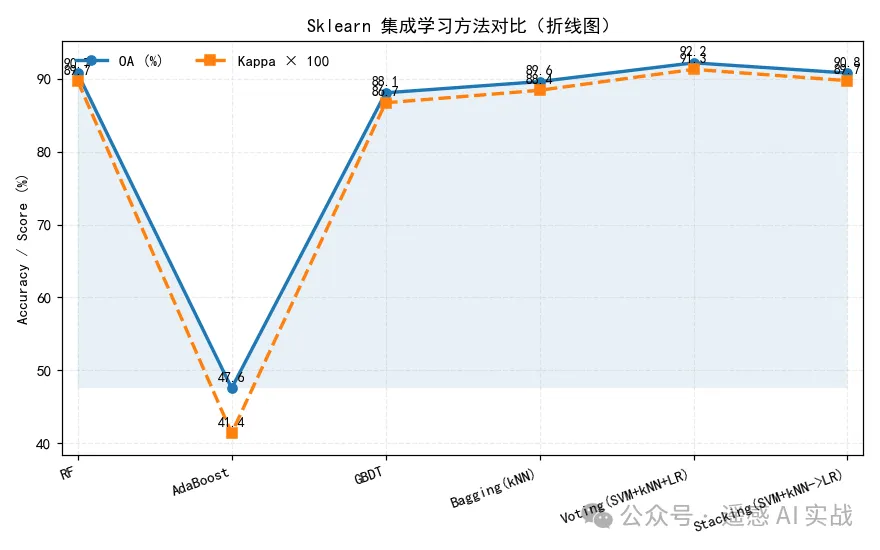
运行后会输出每个模型的分类精度(OA)和 Kappa 系数,并绘制对比折线图。实验表明:
- RF、Bagging:能有效减少过拟合,结果比较稳健;
- AdaBoost、GBDT:对复杂边界表现较好,整体精度有提升;
- Voting:结合了 SVM、kNN、逻辑回归的优势,适合多类别任务;
- Stacking:通过“元学习器”进一步优化,往往能获得更平衡的结果。
💡 4. 总结
通过本实验我们可以看到:
- sklearn 提供了 完整的集成学习工具箱,不同方法调用方式统一,便于快速切换和比较。
- 集成学习能够显著提升模型的鲁棒性,尤其适合高维、类别不平衡的数据集。
- Voting 和 Stacking 等方法,能够发挥多模型的互补性,往往比单一模型更可靠。
未来,我们还可以在此基础上:
- 尝试更多基学习器(如深度学习特征)
- 结合网格搜索进行超参数优化
- 将集成学习与迁移学习结合,应用到更大规模的遥感分类任务
欢迎大家关注下方我的公众获取更多内容!