自然语言处理——04 注意力机制
1 注意力机制介绍
1.1 人类视觉的注意力机制
-
人类视觉注意力机制的本质,是大脑在长期进化里形成的信号处理模式,能让我们高效处理视觉信息,不用逐像素分析,而是先整体扫描、再聚焦关键,像你看一幅画,会先快速扫一眼大概场景,再聚焦人物、特别色彩这些重点;
-
注意力分配的过程与特点
-
快速筛选:面对海量视觉信息(比如复杂画面),人类注意力资源有限,所以会“偷懒”——先快速扫描全局,定位关键目标(比如看人群先找熟悉面孔),优先处理高价值信息,避免被无关内容干扰;
-
聚焦规律:有默认的“关注偏好”,比如看人物优先看脸部(人脸包含情绪、身份等关键信息);看文字优先看标题、首句(快速抓核心内容),这些位置天然更易被注意力“盯上”;
-
-
那么能不能把这种注意力机制引入到深度神经网络中?
1.2 概念
-
注意力机制(Attention Mechanism)概念
- 观察事物时,能够快速判断一种事物,是因为大脑能把注意力放在事物最具有辨识度的地方,从而达到可快速判断的目的;
- 并非是从头到尾的观察一遍事物后,才能有判断结果。正是基于这样的理论,就产生了注意力机制;
-
注意力机制是一个非常重要、强大的工具
- 是一种在深度学习中常用的技术,它允许模型在处理序列数据时能够集中关注输入数据的不同部分
- 自然语言处理中,注意力机制被广泛应用于机器翻译(比如Transformer模型)、文本摘要、问答系统等任务
- 图像处理中,比如在图像描述生成、图像分类等任务中,甚至扩展到了多模态任务,如图像与文本之间的关联问题
- 注意力机制是一个非常重要且强大的工具,可以帮助模型更好地理解和利用输入数据的信息
-
思考:与RNN提取事物特征对比,为什么要引入注意力机制?
-
RNN的问题:
- 效率低:像“时间步接龙”,处理序列数据(比如一句话)时,必须一个词一个词按顺序算,不能并行处理,速度慢;
- 易遗忘:处理长文本时,前面的词的特征会被遗忘,导致模型抓不住全局重点;
-
注意力机制的突破:
- 并行提取:不局限于“顺序处理”,能同时看多个位置的信息(类似人类扫一眼画面同时抓多个重点),加速计算;
- 聚焦关键:主动给重要信息“加权”,比如处理“我喜欢吃苹果,它很甜”,会重点关注“苹果”“甜”这些词,避免遗忘、精准捕捉核心关联;
-
-
既然注意力机制这么有用,那么:
- 如何把我们的数据,也就是特征张量数据输入到注意力机制中?
- 注意力机制又是如何提取事物特征的?
1.3 注意力机制的输入QKV
-
注意力机制中信息检索的三角协作——QKV
-
Query(查询):是模型当前要解决的“问题”,代表主动要找的信息方向;
-
Key(键):是数据里用来“匹配问题”的标签,代表信息的索引标识,用来判断哪些数据和Query相关;
-
Value(值):是真正要提取的内容,代表和Key关联的具体信息;
-
-
三者协作逻辑:
-
用Query(问题)去匹配Key(索引),找到最相关的Key后,从对应的Value(内容)里提取答案;
-
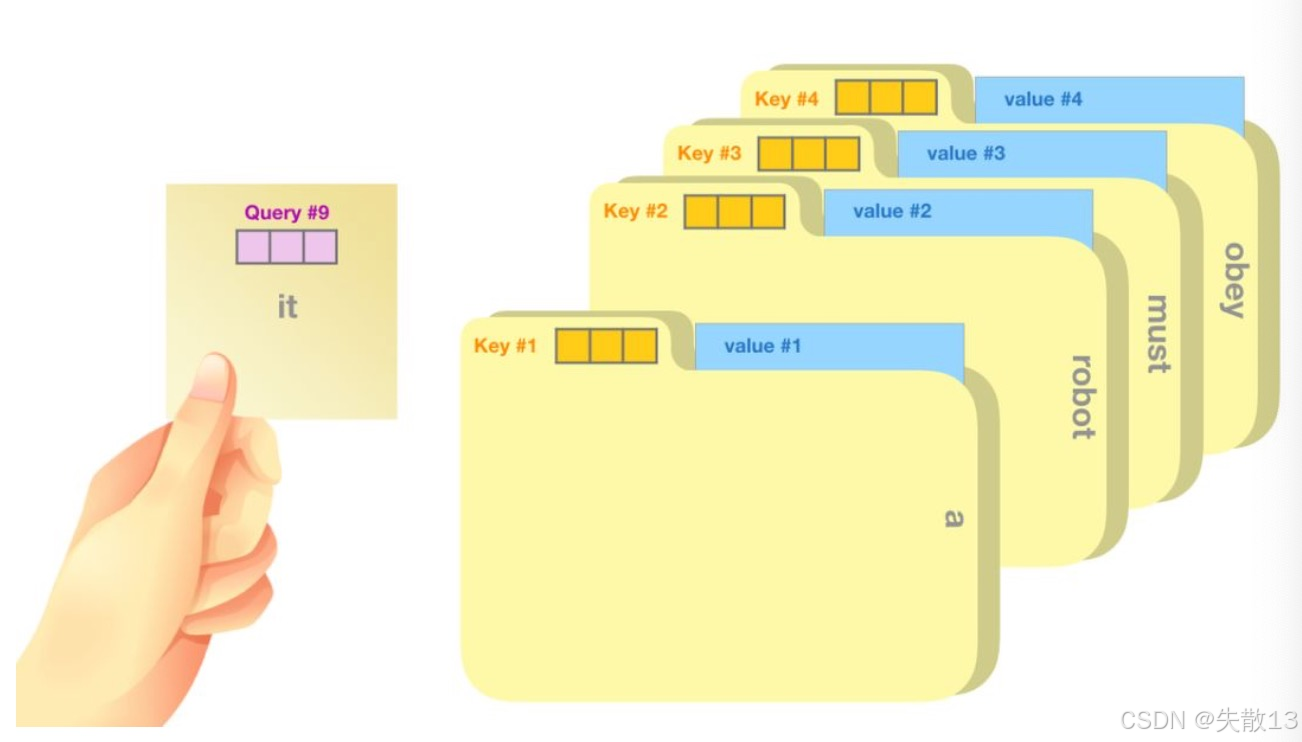
模拟人类“先找标签、再取内容”的高效信息筛选。例:
- Q查询张量,相当于正在研究的课题。比如:写在便利贴上
- K索引张量,相当于文件夹上贴的标签。比如:key#1、key#2
- V内容张量,相当于正在查找的内容。比如:文档、书籍资料
-
-
在自然语言处理中应用注意力机制的例子:
- 问答任务:Query 是问题(如新闻主题是什么),Key 是文本里的主题标签(如政府新政策),Value 是政策具体内容,模型用 Q 匹配 K 找到关联,再从 V 拿答案;
- 文本生成:Query 是生成需求(如环保短文),Key 是环保这类主题标签,Value 是环保措施等素材,让生成内容紧扣主题;
- 文本摘要:Query 是提取核心(如文章主要内容),Key 是文本里的关键主题(如科学发现),Value 是发现细节,帮模型快速抓重点。
1.4 实现步骤
-
核心逻辑:加权求和模拟人类注意力
- 用数学方法模仿人类“聚焦关键信息”——先算“哪些信息重要”(权重),再给重要信息“多分配资源”(加权求和);
- 比如看句子找代词指代,人类会自动聚焦名词,注意力机制就用**q(查询,找指代)匹配k(键,单词标签)算权重,再从v(值,单词语义)**里加权提取,把模糊的关注变成可计算的数学过程;
-
以“阅读理解下面句子中
it指代的是谁?”这个问题为例,分布拆解注意力机制的实现步骤:在机器人第2定律中有这样一句话:A robot must obey the orders given it by human beings except where such orders would conflict with the First Law. (机器人必须服从人类给它的命令,除非这些命令与第一定律相冲突。);机器人第一定律:机器人不能伤害人类。- 算权重(注意力分配)
- 用
q(要解决的问题,如“it 指代谁”)和k(每个单词的标签,如 “robot”“a”)做相似度计算(比如点积),得到attention_weight(权重分布); - 结果像
[0.001, 0.3, 0.5 ...],数值越大代表越 “值得关注”,比如例子里 “robot” 权重高,说明模型认为它和q最相关; - 这一步解决:怎么量化信息的重要性,把人类“觉得谁重要”的模糊判断,变成AI能理解的数字权重;
- 用
- 加权求和(提取关键信息)
- 用第一步算的权重,对
v(单词的语义向量)做加权求和,得到attention_q(聚焦后的结果); - 比如例子里“robot”权重高,它的语义向量就被多“放大”,最终结果里 “robot” 的影响更大,让模型输出更聚焦关键信息;
- 这一步解决:怎么把“关注谁”落地成具体计算,让 AI 真的 “学到” 关键信息,而不是泛泛处理所有内容;
- 用第一步算的权重,对
- 总结:
attention(Q, K, V)->attention_weight, attention_q;
- 算权重(注意力分配)
-
计算过程:
-
算权重
-
输入:
q是要查询的问题(找 it 指代 ),k是句子中每个单词的标签(比如 robot、a); -
计算:用相似度算法(比如点积),让
q和每个k比较,得到attention_weight(权重分布),即[0.001, 0.3, 0.5 ...];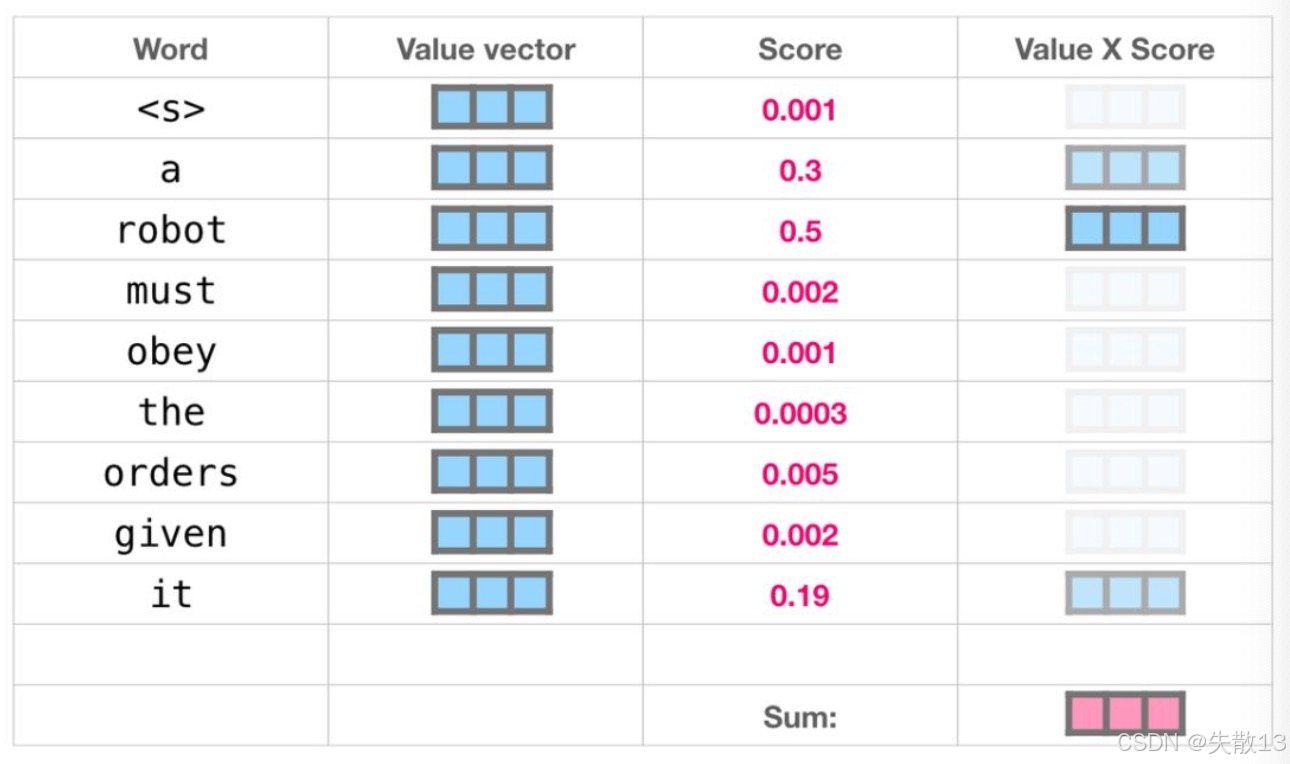
-
-
加权求和
- 输入:第一步得到的
attention_weight(权重),和每个单词的v(语义向量,比如 robot 的语义是“机器人”); - 计算:用权重对
v做加权求和,比如0.001*<s>向量 + 0.3*a 向量 + 0.5*robot 向量 + ...,得到attention_q(聚焦后的结果);
- 输入:第一步得到的
-
值向量加权求和后得到的结果也是一个向量,表示它将其50%的注意力放在了单词"robot"上,30%的注意力放在了"a"上,还有19%的注意力放在了"it"上。
-
2 Seq2Seq 架构中的注意力机制
2.1 Seq2Seq 架构
-
Sequence-to-Sequence架构
- 是一种在自然语言处理领域中非常重要的模型结构,广泛应用于诸如机器翻译、文本摘要、对话系统等任务;
- 该架构的核心思想是将输入序列映射为一个中间表示,然后再从这个中间表示生成目标序列;
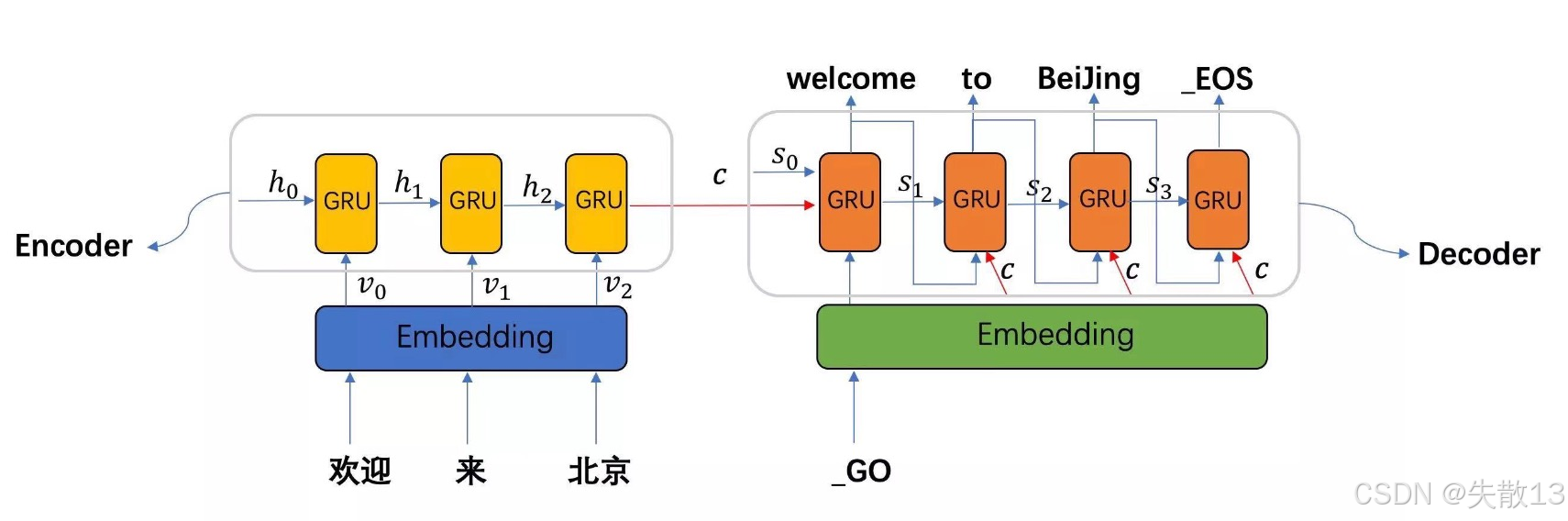
-
Seq2Seq模型架构包括三部分,分别是Encoder(编码器)、Decoder(解码器)、语义向量c
-
Encoder(编码器):理解输入序列
-
输入:句子的每个单词(比如“欢迎”“来”“北京”),先转成词向量(Embedding),让模型能“读懂”语义;
-
过程:用循环神经网络(比如GRU),一步一步处理输入,把每个单词的信息“揉”进隐藏层(h₀→h₁→h₂),最终压缩成一个 语义向量c(相当于把整句话的意思“浓缩”成一个向量);
-
作用:解决模型怎么理解输入的问题,比如把“欢迎来北京”的语义存到c里,让模型知道“要表达的是欢迎到北京这件事”;
-
-
Decoder(解码器):生成输出序列
-
输入:语义向量c + 生成过程的“状态”(比如前一个生成的单词);
-
过程:同样用循环神经网络(GRU),基于c和历史状态,一步一步生成输出(比如先出“welcome”,再出“to”,最后出“Beijing”);
-
细节:
_GO表示开始生成,_EOS表示生成结束;- 每一步生成单词后,用Softmax选概率最高的词,直到生成
_EOS就停止; - s₀ 是解码器的初始隐藏状态,负责启动生成过程;
-
-
语义向量c:桥梁作用
-
是Encoder压缩后的“精华”,把输入序列的语义“打包”传给Decoder,让Decoder知道“要生成什么内容”;
-
比如c里存了“欢迎来北京”的语义,Decoder就基于c生成对应的英文翻译。
-
-
2.2 编码器、解码器与语义向量c
-
编码器(Encoder):理解输入
-
作用
- 把输入序列(比如一句话、一段文本)压缩成固定长度的语义向量 c,让模型能抓住输入的核心意思;
- 比如输入“欢迎来北京”,编码器会把这句话的语义浓缩到 c 里,不管输入多长,c 是一个固定长度的向量(方便后续处理);
-
常用结构
-
早期用 RNN/LSTM(循环神经网络):适合处理序列数据,一步一步“读”输入,把信息存到隐藏状态里;
-
现在常用 Transformer:用注意力机制代替循环,能更高效捕捉长距离依赖(比如处理长文本时,更快找到单词间的关联);
-
-
工作流程
-
对输入序列逐词处理(每个时间步处理一个单词),每个单词会生成一个隐藏状态(记录当前单词的信息 + 之前单词的信息);
-
处理完整个输入后,最后一个时间步的隐藏状态会被用来初始化解码器(Decoder),相当于把输入的理解结果传递给解码器;
-
-
-
解码器(Decoder):生成输出
-
作用:基于编码器给的语义向量 c 和初始隐藏状态,逐词生成输出序列;
-
常用结构
-
早期也是 RNN/LSTM:和编码器呼应,一步一步生成输出,每个步骤依赖“前一个单词的信息 + 语义向量 c”;
-
现在会加注意力机制(Attention ):让解码器生成时,能动态关注输入序列的不同部分(比如翻译“北京”时,更聚焦输入里的“北京”),解决“长文本生成时信息丢失”的问题;
-
-
工作流程
-
自回归生成:从特殊符号
_GO开始(表示开始生成),每一步用前一个生成的单词 + 语义向量 c + 当前隐藏状态,生成下一个单词; -
直到生成特殊符号
_EOS(表示生成结束),输出完整序列;
-
-
-
语义向量 c:连接编码和解码的桥梁
-
c 是编码器处理完输入后,最后一个隐藏状态(或所有隐藏状态的汇总),代表输入序列的核心语义;
-
解码器每一步生成输出时,都会用到 c,相当于:拿着输入的核心意思,指导输出生成;
-
比如翻译时,c 里存了“欢迎来北京”的语义,解码器就知道要生成和“欢迎、北京”相关的英文单词;
-
-
总结:“理解→生成”的全过程
- 编码阶段:编码器用 RNN/Transformer 逐词处理输入,把语义压缩到 c 里,完成理解输入;
- 解码阶段:解码器用 RNN(+注意力),基于 c 和前一个生成的单词,逐词生成输出,完成生成输出。
2.3 解码部分引入注意力机制
-
为什么要在 Seq2Seq 里加注意力?
- 传统 Seq2Seq 用语义向量 c 压缩输入,但 c 是固定长度的,长文本输入时会导致信息丢失;
- 注意力机制让解码器生成时,能动态关注输入序列的不同部分,解决生成时抓不住重点的问题;
-
引入注意力的核心变化:QKV 参与解码
-
传统解码 vs 加注意力的解码
-
传统解码:解码器只用语义向量 c + 前一个生成的单词,生成下一个单词,对长文本记忆力差;
-
加注意力的解码:解码器每一步生成时,新增 Q(查询)、K(键)、V(值) 计算,让模型主动找输入里的关键信息;
-
-
QKV 在解码中的作用
-
Q(查询):解码器当前要生成的问题,比如生成“welcome”时,Q 是“怎么翻译‘欢迎’”的语义表示;
-
K(键):输入序列的索引,上一个时间步的隐藏层输出,比如输入“欢迎、来、北京”的隐藏状态(h₀、h₁、h₂),用来和 Q 匹配;
-
V(值):输入序列的内容,通常是中间语义向量 c(或输入的隐藏状态),包含输入的详细信息;
-
-
-
**解码时怎么用注意力?**以生成“welcome”为例:
- 生成 q:解码器处理到当前步骤,把“要生成 welcome”的语义转成查询向量 q;
- 匹配 k,算权重:用 q 和输入序列的 k(h₀、h₁、h₂)做相似度计算,得到注意力权重(比如“欢迎”权重高,“来”“北京”权重低);
- 加权求和 v,得到 q’:用权重对 v(中间语义向量 c)做加权求和,得到更聚焦的 q’(融合了输入关键信息的新查询);
- 用 q’ 生成单词:q’ 代替原来的 q,参与解码计算,让生成的“welcome”更贴合输入“欢迎”的语义。
3 注意力机制计算规则、代码实现、分类及作用
3.1 计算规则
-
注意力机制计算规则的目标说明
-
用查询张量 Q\boldsymbol{Q}Q 与键 K\boldsymbol{K}K 进行运算(相似度运算)得到注意力机制的权重分布(权重系数),可表示为:
权重分布=相似度运算(Q,K)\text{权重分布} = \text{相似度运算}(\boldsymbol{Q}, \boldsymbol{K})权重分布=相似度运算(Q,K)- 注:常见相似度运算有内积、点积等,不同规则里具体形式有差异;
-
用权重分布乘以值 V\boldsymbol{V}V 得到注意力机制的结果表示:
attention_result=权重分布⊙V\text{attention\_result} = \text{权重分布} \odot \boldsymbol{V}attention_result=权重分布⊙V- ⊙\odot⊙ 表示按元素相乘,最终让普通的 q\boldsymbol{q}q 升级成更强大的表示,即 attention_q\text{attention\_q}attention_q;
-
-
常见规则公式
-
规则一:
Attention(Q,K,V)=Softmax(Linear([Q,K]))⋅V \text{Attention}(\boldsymbol{Q}, \boldsymbol{K}, \boldsymbol{V}) = \text{Softmax}\big( \text{Linear}([\boldsymbol{Q}, \boldsymbol{K}]) \big) \cdot \boldsymbol{V} Attention(Q,K,V)=Softmax(Linear([Q,K]))⋅V- 先将 Q\boldsymbol{Q}Q、K\boldsymbol{K}K 最后一个维度的特征层拼接([Q,K][\boldsymbol{Q}, \boldsymbol{K}][Q,K] 表示拼接操作),经线性变换(Linear\text{Linear}Linear )后,用 Softmax\text{Softmax}Softmax 处理得到权重,再与 V\boldsymbol{V}V 做矩阵乘法(⋅\cdot⋅ 表示矩阵乘);
-
规则二:
Attention(Q,K,V)=Softmax(sum(tanh(Linear([Q,K]))))⋅V\text{Attention}(\boldsymbol{Q}, \boldsymbol{K}, \boldsymbol{V}) = \text{Softmax}\big( \text{sum}\big( \tanh\big( \text{Linear}([\boldsymbol{Q}, \boldsymbol{K}]) \big) \big) \big) \cdot \boldsymbol{V}Attention(Q,K,V)=Softmax(sum(tanh(Linear([Q,K]))))⋅V- 拼接 Q\boldsymbol{Q}Q、K\boldsymbol{K}K 并线性变换后,用 tanh\tanhtanh 激活函数处理,再对结果求和(sum\text{sum}sum),接着 Softmax\text{Softmax}Softmax 算权重,最后与 V\boldsymbol{V}V 相乘;
-
规则三(常用的缩放点积注意力):
Attention(Q,K,V)=Softmax(QK⊤dk)⋅V\text{Attention}(\boldsymbol{Q}, \boldsymbol{K}, \boldsymbol{V}) = \text{Softmax}\bigg( \frac{\boldsymbol{Q}\boldsymbol{K}^\top}{\sqrt{d_k}} \bigg) \cdot \boldsymbol{V}Attention(Q,K,V)=Softmax(dkQK⊤)⋅V- 先计算 Q\boldsymbol{Q}Q 与 K⊤\boldsymbol{K}^\topK⊤(K\boldsymbol{K}K 的转置 )的点积(内积运算,衡量相似度),除以 dk\sqrt{d_k}dk(dkd_kdk 是 K\boldsymbol{K}K 最后一维的维度,缩放避免 Softmax 后梯度消失),经 Softmax\text{Softmax}Softmax 得到权重,再与 V\boldsymbol{V}V 相乘;
- Transformer 里的多头注意力,基础就是这个规则;
-
-
假设在 Seq2Seq 翻译任务中,V\boldsymbol{V}V 是输入序列的特征(比如 10 个单词,每个单词 32 维特征 ),K\boldsymbol{K}K 是这 10 个单词的索引表示,Q\boldsymbol{Q}Q 是查询向量(比如要生成单词的查询),按上述公式就能算出:
- 相似度(权重分布):衡量 Q\boldsymbol{Q}Q 和每个 K\boldsymbol{K}K 的关联程度;
- 加权求和(结果表示):用权重给 V\boldsymbol{V}V 加权,得到升级后的 attention_q\text{attention\_q}attention_q ,辅助生成更贴合的输出。
3.2 代码实现
import torch
import torch.nn as nn
import torch.nn.functional as F # 导入PyTorch的函数式接口,包含各种激活函数等
class MyAtt(nn.Module):def __init__(self, query_size, key_size, value_size1, value_size2, output_size):super(MyAtt, self).__init__()# 保存各输入输出的维度信息self.query_size = query_size # 查询向量的维度self.key_size = key_size # 键向量的维度self.value_size1 = value_size1 # 值向量的第一个维度(可以理解为序列长度)self.value_size2 = value_size2 # 值向量的第二个维度(特征维度)self.output_size = output_size # 输出向量的维度# 定义注意力权重计算的线性层:输入为query+key的拼接,输出维度为value_size1self.attn = nn.Linear(self.query_size + self.key_size, self.value_size1)# 定义注意力输出与query拼接后的线性层:输入为query+加权后的value,输出为指定维度self.attn_combine = nn.Linear(self.query_size + self.value_size2, self.output_size)# 前向传播方法,定义注意力机制的计算过程def forward(self, Q, K, V):# 将query和key的第一个元素拼接tmp1 = torch.cat((Q[0], K[0]), dim=-1) # 在最后一个维度拼接# 通过线性层计算注意力得分tmp2 = self.attn(tmp1)# 对得分应用softmax,得到注意力权重(仅用于打印查看)tmp3 = F.softmax(tmp2, dim=-1)print('tmp3-->', '\n', tmp3) # 打印临时计算的注意力权重# 重新计算注意力权重(与tmp3计算过程相同,正式用于后续计算)attn_weights = F.softmax(self.attn(torch.cat((Q[0], K[0]), dim=-1)), dim=-1)# 将注意力权重与值向量V进行批量矩阵乘法(bmm),得到加权后的V# unsqueeze(0)是为了增加一个批次维度以满足bmm的输入要求attn_applied = torch.bmm(attn_weights.unsqueeze(0), V)# 将原始query与加权后的V拼接output = torch.cat((Q[0], attn_applied[0]), dim=-1)# 通过线性层得到最终输出,并增加一个维度保持一致性output = self.attn_combine(output).unsqueeze(0)return output, attn_weights # 返回最终输出和注意力权重
# 定义各向量的维度参数
query_size = 32 # 查询向量维度
key_size = 32 # 键向量维度
value_size1 = 10 # 值向量的序列长度维度
value_size2 = 32 # 值向量的特征维度
output_size = 32 # 输出向量维度# 生成随机张量作为输入(模拟实际数据)
Q = torch.randn(1, 1, query_size) # 查询向量,形状为[1, 1, 32]
K = torch.randn(1, 1, key_size) # 键向量,形状为[1, 1, 32]
V = torch.randn(1, value_size1, value_size2) # 值向量,形状为[1, 10, 32]# 创建自定义注意力机制的实例
myattobj = MyAtt(query_size, key_size , value_size1, value_size2, output_size)# 前向传播,得到输出和注意力权重
output, attn_weights = myattobj(Q, K, V)# 打印输出结果的形状和值
print('查询张量q的注意力结果表示(更加强大的q):output-->', '\n', output.shape, output)
# 打印注意力权重的形状和值
print('查询张量q的注意力权重分布attn_weights-->', '\n', attn_weights.shape, attn_weights)
tmp3--> tensor([[0.1043, 0.0886, 0.0483, 0.0805, 0.0865, 0.1218, 0.0713, 0.1008, 0.1329,0.1650]], grad_fn=<SoftmaxBackward0>)
查询张量q的注意力结果表示(更加强大的q):output--> torch.Size([1, 1, 32]) tensor([[[ 0.6641, 0.6755, 0.6782, -0.2611, 0.6339, 0.2664, 0.1460,-0.3656, 0.2752, 0.7221, 0.5109, -0.6861, -0.2070, 0.2194,0.4128, 0.6387, 0.4653, 0.1066, -0.3968, 0.0033, -0.6615,0.4693, -0.5146, 0.5735, -0.5763, -0.1813, -0.5509, -0.5316,0.6087, 0.0557, -0.5242, -0.1305]]], grad_fn=<UnsqueezeBackward0>)
查询张量q的注意力权重分布attn_weights--> torch.Size([1, 10]) tensor([[0.1043, 0.0886, 0.0483, 0.0805, 0.0865, 0.1218, 0.0713, 0.1008, 0.1329,0.1650]], grad_fn=<SoftmaxBackward0>)
3.3 分类及作用
-
注意力机制的核心是通过**Query(查询)、Key(键)、Value(值)**三个向量计算注意力权重,再加权得到输出。根据这三个向量是否相同,分为两类:
-
一般注意力机制
-
Q != K != V:三个向量都不同; -
Q != (K = V):Key 和 Value 相同,但和 Query 不同; -
常见于解码器中,用 Query(当前解码状态)去匹配编码器输出的 Key/Value,聚焦相关信息;
-
-
自注意力机制(Self-Attention)
-
Q = K = V:即 Query、Key、Value 是同一组向量; -
核心逻辑:让序列中的每个元素(如文本中的词),同时作为“查询者”和“被查询者”,计算自身与序列内其他元素的关联权重;
-
常见于编码器中(比如 BERT、Transformer 的 encoder 阶段),用于挖掘序列内部的依赖关系(如文本中词与词的语义关联);
-
-
-
注意力机制的作用
-
解码器端的注意力机制:
- 能够根据模型目标有效地聚焦编码器的输出结果(比如更加聚焦中间语义张量 c);
- 提升解码器的解码提升效果;
-
编码器端的注意力机制;
-
可以并行提取文本序列特征,支持长文本特征提取,增强了特征提取能力;
-
一般使用自注意力机制(Self-Attention)
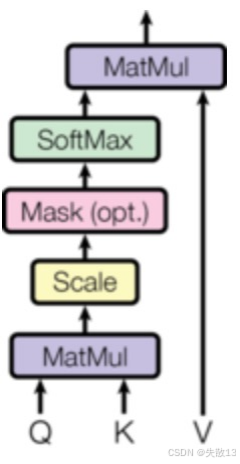
Attention(Q,K,V)=Softmax(Q⋅KTdk)⋅V \text{Attention}(Q, K, V) = \text{Softmax}\left( \frac{Q \cdot K^T}{\sqrt{d_k}} \right) \cdot V Attention(Q,K,V)=Softmax(dkQ⋅KT)⋅V-
Q⋅KTQ \cdot K^TQ⋅KT:计算 Query 与 Key 的相似度
-
dk\sqrt{d_k}dk:缩放因子,避免相似度计算值过大(对应下图的 Scale)
-
Softmax\text{Softmax}Softmax:将相似度转为注意力权重
-
最终输出:用权重加权 Value,得到聚焦后的特征
-
-
-