如何使用Prometheus + Grafana + Loki构建一个现代化的云原生监控系统
如何使用 Prometheus + Grafana + Loki 构建一个现代化的云原生监控系统。这套组合被誉为监控领域的“瑞士军刀”,功能强大且生态极佳。
一、核心组件概念介绍
在搭建之前,深刻理解每个组件的角色和职责至关重要。
1. Prometheus(指标监控与时序数据库)
- 角色:系统的“核心计量器”和“数据收集器”。
- 核心概念:
- 拉取模型(Pull):Prometheus 主动从配置好的目标(
targets,如应用、节点)上拉取(HTTPGET)监控指标数据。这与传统的 Agent 推送(Push)模型不同。 - 时序数据(Time-Series Data):收集的数据是带时间戳的指标序列,例如:
shenyu_request_count{path="/api/test", status="200"}在 t1=1625000000 时刻的值是 10,在 t2=1625000005 时刻的值是 15。 - 多维数据模型:通过 指标名称(Metric Name) 和 标签(Key-Value Labels) 来唯一标识一条时间序列,这使得数据可以高度灵活地切片、聚合和查询。
- 服务发现:可以自动从 Kubernetes、Consul 等平台发现需要监控的目标,动态适应云环境。
- PromQL:强大的专有查询语言,可以对收集到的指标进行各种运算、聚合和预测。
- 拉取模型(Pull):Prometheus 主动从配置好的目标(
- 职责:定期抓取、存储指标数据,并提供查询接口。
2. Grafana(数据可视化与分析平台)
- 角色:系统的“仪表盘”和“可视化UI”。
- 核心概念:
- 数据源(Data Source):Grafana 本身不存储数据,它专注于展示。它支持从 Prometheus、Loki、MySQL、Elasticsearch 等数十种数据源中查询数据。
- 仪表盘(Dashboard):由多个面板(Panel)组成的视图,每个面板可以配置一个独立的查询和可视化方式(如图表、表格、状态值、热图等)。
- 面板(Panel):可视化基本单元,通过编写查询语句(如 PromQL)从数据源获取数据,并以图形化方式展示。
- 告警(Alerting):Grafana 可以根据面板的查询结果配置告警规则,并通过钉钉、Slack、Webhook 等多种渠道发送通知。
- 职责:从各种数据源(主要是 Prometheus)查询数据,并绘制成美观、直观的仪表盘,用于监控和告警。
3. Loki(日志聚合系统)
- 角色:系统的“日志收集器”,但更轻量、更经济。
- 核心概念:
- 索引与数据分离:Loki 的核心设计理念。它只对日志的元数据(标签,如
filename,job,level) 进行索引,而对日志内容本身不索引。这使其存储效率极高,成本远低于 Elasticsearch。 - LogQL:类似于 PromQL 的查询语言,用于通过标签和内容关键词来查询日志。
- 与 Prometheus 生态协同:鼓励使用与 Prometheus 相同的标签(如
job,instance),从而可以无缝地在指标(Prometheus)和日志(Loki)之间切换上下文。例如,看到某个应用实例 CPU 异常,可以直接用相同的标签查询它当时的日志。 - 客户端(Promtail):负责收集日志、添加标签,并将日志推送给 Loki。它通常以 DaemonSet 形式运行在每个节点上,采集节点上的容器日志。
- 索引与数据分离:Loki 的核心设计理念。它只对日志的元数据(标签,如
- 职责:高效、低成本地收集、存储和查询日志,并与指标监控联动。
二、构建思路与架构设计
构建这套系统的核心思路是:“通过指标发现问题,通过日志定位问题”。
1. 整体数据流与架构
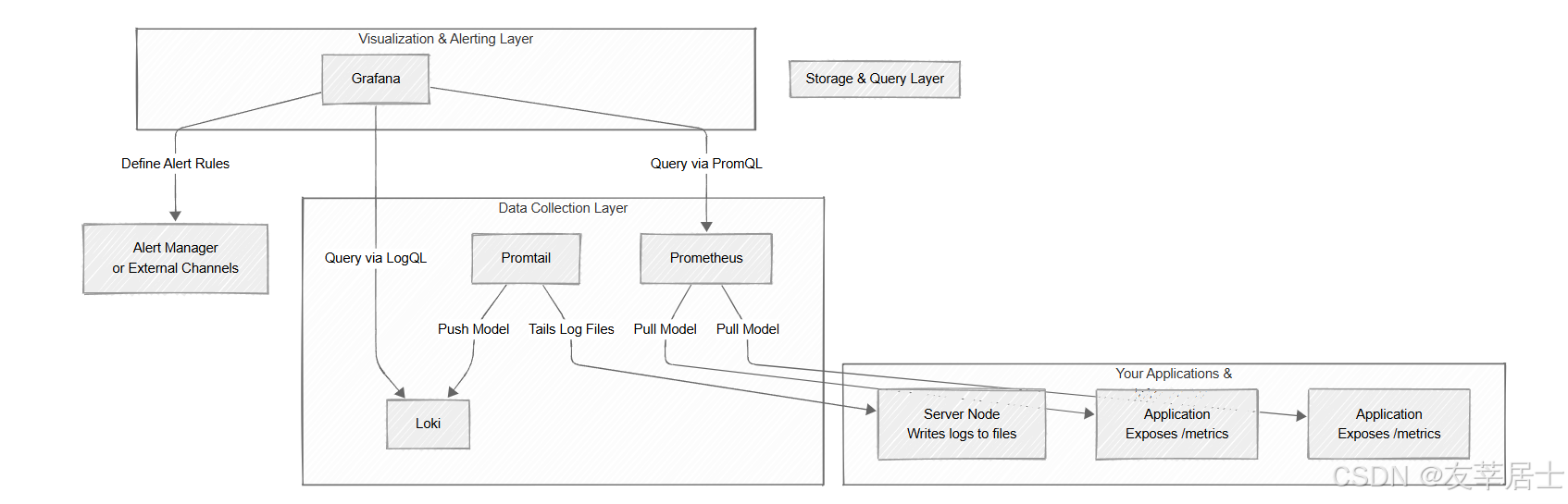
工作流程解读:
- 数据采集:
- 指标:所有需要监控的应用、服务、节点(如 ShenYu、Redis、MySQL、Node Exporter)都暴露一个
/metrics接口。Prometheus 根据配置,定期(如 15s)主动去这些目标拉取数据。 - 日志:每个节点上部署的
Promtail代理会实时监控(tail)指定的日志文件(如/var/log/*.log或容器日志目录),它为日志流添加标签(如job="shenyu-gateway",instance="host1"),然后批量压缩并推送给 Loki。
- 指标:所有需要监控的应用、服务、节点(如 ShenYu、Redis、MySQL、Node Exporter)都暴露一个
- 数据存储与查询:
- 采集到的指标数据被存储在 Prometheus 的时序数据库中,可以通过 PromQL 查询。
- 采集到的日志数据被存储在 Loki 中,可以通过 LogQL 查询。
- 可视化与告警:
- Grafana 配置两个数据源:一个是 Prometheus 的地址,另一个是 Loki 的地址。
- 运维和开发人员通过在 Grafana 中创建仪表盘,编写 PromQL/LogQL 来查询和展示他们关心的指标和日志。
- 在 Grafana 中配置告警规则(例如,PromQL 查询结果持续 5 分钟 > 阈值),并设置通知渠道。
2. 关键设计原则
- 统一标签(Labels):这是打通指标和日志的关键。确保 Prometheus 抓取目标时设置的标签(
job,instance,env等)与 Promtail 向 Loki 推送日志时使用的标签保持一致。这样,在 Grafana 中从一个有异常指标的面板,可以直接跳转到对应标签的日志查询结果。 - 选择合适的部署模式:
- 学习/测试环境:可以使用 Docker Compose 快速在单机部署所有组件。
- 生产环境:推荐使用 Kubernetes 部署,充分利用其高可用、弹性扩展和服务发现的能力。
- Prometheus 可以配置
serviceMonitor或podMonitor来自动发现 Kubernetes 中的服务。 - Promtail 以
DaemonSet形式部署,确保每个节点都有日志收集器。
- Prometheus 可以配置
- 资源规划与持久化:
- Prometheus:数据默认保留 15 天。对于大规模环境,需要考虑磁盘空间和 IOPS。可以通过设置远程写入(Remote Write)到更专业的时序数据库(如 Thanos、Cortex、VictoriaMetrics)来实现长期存储和水平扩展。
- Loki:配置不同的存储后端(如 AWS S3、MinIO、本地盘),并根据日志重要性设置不同的保留策略(如核心应用日志保留 30 天,调试日志保留 7 天)。
三、总结:为什么是这套组合?
构建这套监控系统的思路可以总结为:“用 Prometheus 收集并存储指标,用 Loki 收集并存储日志,最后用 Grafana 作为统一的 UI 进行查询、展示和告警,并通过统一的标签体系将三者无缝打通。”
其优势在于:
- 生态强大:CNCF 毕业项目,云原生事实标准。
- 成本低廉:特别是 Loki 的日志方案,相比 ELK 节省大量存储和索引成本。
- 高度协同:指标和日志的联动排查效率极高,避免了在多套系统间来回切换的麻烦。
- 灵活扩展:每个组件都可以独立扩展和优化。