Multi Agents Collaboration OS:Browser Automation System
0背景
在企业日常运营中,大量业务系统(如项目管理、OA、财务报销、工单系统等)依赖浏览器界面交互完成任务。然而,传统的人机交互方式存在显著痛点:首先,操作路径复杂,用户需要在不同菜单和页面之间频繁切换,尤其是需要跨页面查找信息或填写表单时,容易出现遗漏与错误;其次,流程高度重复,诸如日报填报、任务查询、文件下载等操作耗费大量时间,难以释放员工的创造性价值;再次,不同业务系统界面差异大,用户必须反复学习各类交互逻辑,造成使用门槛与沟通成本。基于此,我们提出 Multi Agents Collaboration OS:Browser Automation System 的建设思路。该系统借助大模型与多智能体协作,将原本需要人工逐步操作的流程转化为自然语言驱动的自动化闭环:用户只需提出需求,如“查询某人本周的工作日志”,系统即可自动调用网页导航、信息提取、表单填写、文件下载等多个智能体,完成跨页跳转、数据抓取与结果输出,用户直接获取最终答案。通过这种方式,系统有效解决了业务操作的繁琐性和低效性,提升了信息获取的及时性与准确性,同时降低了使用成本,显著改善了人与业务系统的交互模式。更重要的是,这一模式具备高度扩展性,可以适配更多智能体能力(如验证码识别、文件上传、跨系统跳转等),最终形成一个智能化、统一化的业务操作入口,为企业的数字化转型提供了全新路径与价值。
Multi Agents Collaboration OS的设计愿景是改变** “人——机器——业务系统” **的交互方式,通过对话解决大部分工作内容,包括数据分析、信息检索、业务系统操作(OA审批流、数据上传、内容填写等)。
1 整体架构设计
Multi Agents Collaboration OS:Browser Automation System 的整体架构基于 大模型推理能力 与 多智能体协作机制,结合 浏览器操作逻辑 和 业务知识检索,构建出一个从自然语言到自动执行的闭环系统。
架构分为四个核心层次:
- 前端交互层:提供类似 ChatGPT 的对话界面,用户以自然语言输入需求,系统以多轮对话形式反馈执行计划、任务进度与最终结果。
- 多智能体协作层:由导航、信息提取、表单填写、文件下载等智能体组成,系统通过 大模型规划器将用户请求拆解为多步骤任务,自动分配给对应智能体执行。
- 浏览器操作层:基于 Playwright/Chrome 插件 API 实现底层 DOM操作,包括页面跳转、元素点击、数据提取、文件交互等,确保任务在真实业务系统中自动化运行。
- 知识检索与参数共享层:通过 业务系统知识库获取页面结构、账号信息、操作逻辑等背景数据,并结合大模型生成参数输入,确保智能体间的信息流畅共享。
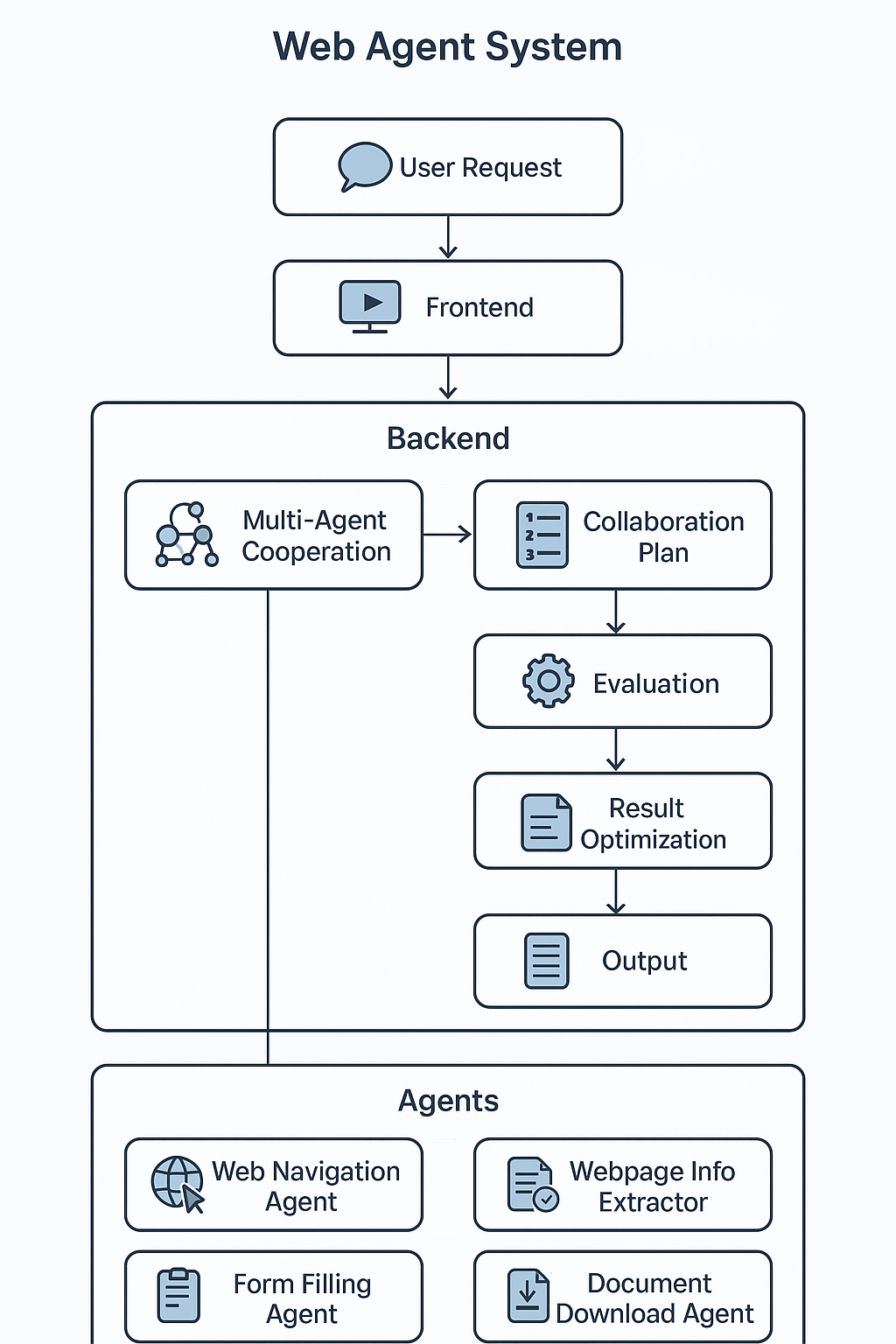
该架构实现了 自然语言驱动 → 任务分解 → 智能体协作 → 浏览器自动化 → 结果优化 的完整流程,既提升了业务系统交互效率,又为后续扩展更多智能体提供了开放的架构基础。
关键代码设计
(1)多智能体协作体系设计
网页浏览器自动化智能体设计:网页浏览器自动化智能体的设计核心在于通过大模型推理能力与多智能体协作机制,将原本复杂的人工浏览器操作转化为自然语言驱动的自动化流程。整体思路是用户只需以口语化的方式提出需求,如“帮我查询某个项目的任务详情”或“提交一份日报”,系统即可调用内部的协作规划器,将请求分解为可执行的多步骤任务,并根据任务属性分配给不同的智能体模块,如导航智能体负责页面跳转和元素定位,信息提取智能体抓取目标数据,表单填写智能体完成输入与提交,文件下载或上传智能体处理资料交互。底层操作由浏览器控制引擎(如 Playwright 或 Chrome 插件 API)实现,确保能在实际业务系统中执行真实的 DOM 操作。同时,通过业务知识库检索与参数共享机制,系统能自动获取账号信息、页面结构和数据逻辑,提升操作的准确性与鲁棒性。整体设计不仅降低了用户的学习成本,还极大提升了业务系统的交互效率和自动化程度,为企业构建统一的智能化入口提供了可扩展的技术框架。
def extract_interactive_dom(url: str, page: Page) -> str:"""使用Playwright获取当前页面的完整DOM源码(包含JavaScript动态内容)参数:page: Playwright页面实例返回:str: 包含完整动态内容的HTML源码"""try:# 等待页面完全加载(包括异步JS)page.wait_for_load_state("networkidle", timeout=120000)except TimeoutError:print("警告:页面加载超时,但将继续获取当前DOM状态")# 返回渲染后的完整DOM源码return page.content()##网页结构解析智能体
def parse_web_structure(url: str, page: Page, agents_info: str) -> Dict[str, str]:llm = ChatOpenAI(model=model_use, temperature=0.2)dom_structure = extract_interactive_dom(url, page)messages = [("system", f"""你是一个网页结构解析智能体,需要分析当前页面的DOM结构。当前URL: {url}当前页面的DOM结构: {dom_structure}需求: {agents_info}根据需求解析网页结构并预测页面的主要元素和结构信息。请提取页面的主要元素和结构信息,并返回一个JSON对象,包含以下:- 页面标题- 主要导航链接- 重要按钮或表单- 主要内容区域- 其他关键元素"""),("human", "请提取页面的主要元素和结构信息,并返回一个JSON对象,包含以下内容:\n""- 页面标题\n""- 主要导航链接\n""- 重要按钮或表单\n""- 主要内容区域\n""- 其他关键元素")]response = llm.invoke(messages)return response.content#多智能体协作机制
def multi_agents_cooperation(query: str, model_use: str = 'deepseek-chat',web_page_info=None,agents_info: List[Dict[str, str]] = []):llm = ChatOpenAI(model=model_use, temperature=0.2)messages = [("system", f"""你是一个多智能体协作助手,根据用户的诉求选择合适的智能体进行任务处理。用户问题为: "{query}"智能体信息为: {agents_info}业务系统知识库为: {web_page_info}请根据用户问题,选择合适的智能体进行任务处理。请根据如下常见场景提示,增强你对任务的理解和分解能力:常见任务场景提示:需要登录的业务系统登录页填写用户名和密码跳转至主页面,验证登录成功系统内搜索任务在搜索栏输入关键词筛选搜索结果列表点击进入详细页面信息提取任务确定页面是否包含目标信息(如任务名称、状态、人员等)提取具体字段(可通过 DOM/XPath/CSS Selector)表单填写任务输入表单数据提交并验证是否成功文件下载任务点击“下载”按钮或链接等待下载完成并返回文件信息多轮跳转/页面深度遍历可能需要多层跳转寻找目标页面每一层都需判断是否相关,决定是否深入或回退其他场景需要根据具体业务逻辑进行判断和处理主要工作:1、理解用户的问题,规划多智能体协作的方案。2、拆解成多个子任务,每个子任务由一个智能体完成。3、输出多智能体协作的方案,包括步骤信息,各步骤选择的智能体及其任务,各个步骤的预期输出。你应该输出一个JSON对象,不要输出任何非Json格式的其他信息,包含多智能体协作的方案,包括步骤信息,各步骤选择的智能体及其任务,各个步骤的预期输出。输出的信息格式如下:```json{{"initial_url": "url,<从知识库内自动判断与用户问题相关的业务系统地址>","steps": [{{"step": "step1","agent": "agent1","task": "task1","output": "output1"}},{{"step": "step2","agent": "agent2","task": "task2","output": "output2"}}]}}'''"""),("human","你的主要工作是:理解用户的问题,规划多智能体协作的方案。")]response = llm.invoke(messages)res = response.content.replace('```json', '').replace('```', '').strip()strategy = json.loads(res)return strategy#参数共享
@retry(wait=wait_fixed(3), stop=stop_after_attempt(3))
def get_parameters_multiple_agents(query: str, model_use: str = 'deepseek-chat',agents_info: List[Dict[str, str]] = [],last_agent_response: str = ""):llm = ChatOpenAI(model=model_use, temperature=0)messages = [("system", f"""你是一个智能体信息共享助手。根据用户的问题,获取智能体的输入参数。用户问题为: "{query}"智能体信息为: {agents_info}前一个智能体的输出为: {last_agent_response}请根据用户问题,获取智能体的输入参数。[警告]请不要杜撰智能体参数信息,根据各个智能体的输出,准确的完整的输出各个智能体的输入参数。【建议】涉及到网址搜索的,最大搜索结果数至少为10个。[注意] 不要遗漏智能体的输入参数,完整的输出各个智能体的所有输入参数。【提示】如果用户的问题中无明确的日期,默认是最新的日期。【提示】给出的参数需要尽可能精准,如果输出的文字参数,请不要过于精简,尽可能与用户的诉求、任务描述等一致,适当扩展你应该输出一个JSON对象,包含智能体的名称和输入参数。不要输出任何其他信息。输出的信息格式如下:```json{{"<agent_name>": {{"target_url": "https://example.com"}},.....}}'''"""),("human", "你的主要工作是:获取智能体的输入参数。")]response = llm.invoke(messages)res = response.content.replace('```json', '').replace('```', '').strip()strategy = json.loads(res)return strategy# 网页导航智能体
def web_navigation_agent(target_url: str,user_request: str,model_use: str = 'deepseek-chat',max_iterations: int = 5,page: Page = None,feedback: Optional[str] = None,account_info: Optional[Dict] = None
) -> Dict[str, str]:"""Playwright-based navigation agent."""dom_structure = extract_interactive_dom(target_url, page)llm = ChatOpenAI(model=model_use, temperature=0.2)account_prompt = f"\nAccount info: {account_info}" if account_info else ""messages = [("system", f"""你是一个网页导航智能体,需要根据用户请求生成导航策略。初始URL: {target_url}当前页面的DOM结构: {dom_structure}用户请求: "{user_request}"{account_prompt}请生成Playwright导航代码,帮助找到与用户请求相关的页面。上一轮反馈: {feedback if feedback else '无'}导航策略应考虑:1. 使用page.goto(url)导航2. 使用page.click(selector)点击元素3. 使用page.wait_for_selector()等待元素4. 最多进行{max_iterations}次迭代5. 最终输出新发现的URL请返回包含导航代码的Python对象。你只能输出python代码,不要输出任何其他信息。示例:```pythonpage.goto('https://example.com')page.click('a.some-link')page.wait_for_selector('div.content')result = page.url```"""),("human", "生成网页导航代码")]response = llm.invoke(messages)res = response.content.replace('```python', '').replace('```', '').strip()#print(res)try:# Execute the generated codeexec(res, globals(), locals())return {'status': 'success','current_url': page.url,'message': 'Navigation completed',}except Exception as e:return {'status': 'error','current_url': page.url,'message': str(e),}# 网页信息提取智能体
def webpage_info_extractor(target_url: str,user_request: str,model_use: str = 'deepseek-chat',page: Page = None,feedback: Optional[str] = None,account_info: Optional[Dict] = None
) -> Dict[str, str]:"""Extract information using Playwright."""dom_structure = extract_interactive_dom(target_url, page)llm = ChatOpenAI(model=model_use, temperature=0.2)messages = [("system", f"""你是一个网页信息提取智能体,需要根据用户请求从页面中提取数据或者信息。当前URL: {target_url}业务系统的账户信息: {account_info if account_info else '无'}当前页面的DOM结构: {dom_structure}用户请求: "{user_request}"{"上一轮反馈: " + feedback if feedback else ""}请生成Playwright提取代码,使用:1. page.inner_text(selector)获取文本2. page.query_selector_all(selector)获取多个元素3. BeautifulSoup解析DOM【注意】你编写的代码需要能够返回输出提取到的信息或者数据。返回提取的数据或者信息。你只能输出python代码,不要输出任何其他信息。示例:```pythonresult = page.inner_text('selector')....```"""),("human", "生成信息提取代码")]response = llm.invoke(messages)res = response.content.replace('```python', '').replace('```', '').strip()#print(res)try:exec(res, globals(), locals())return {'status': 'success','data': locals().get('result', {}),}except Exception as e:return {'status': 'error','message': str(e),}# 表单填写智能体
def form_filling_agent(target_url: str,user_request: str,model_use: str = 'deepseek-chat',page: Page = None,feedback: Optional[str] = None,account_info: Optional[Dict] = None
) -> Dict[str, str]:"""Fill forms using Playwright."""dom_structure = extract_interactive_dom(target_url, page)llm = ChatOpenAI(model=model_use, temperature=0.2)web_structure_request_info = f"当前的任务是填写内容,你需要帮助该智能体完成用户的需求,所以请解析当前网页的结构,用户的诉求是{user_request}。"#网页内容解析web_structure = parse_web_structure(target_url, page, web_structure_request_info)messages = [("system", f"""你是一个表单填写智能体,需要根据用户请求填写网页表单。首先分析当前页面的字段情况,精准填写相关内容,并确认提交。1. 区分必填/选填字段:- 优先处理用户明确要求的字段- 忽略非必要字段(除非用户指定)- 对不确定的字段保持空白2. 智能填充策略:- 日期字段: 自动格式化为YYYY-MM-DD- 数字字段: 验证数值范围- 选项字段: 匹配最接近的选项[新增iframe处理规则]3. 检测iframe存在时:- 使用page.frame_locator(selector)定位iframe- 添加等待iframe加载的代码:frame = page.wait_for_selector('iframe')当前URL: {target_url}业务系统的账户信息: {account_info if account_info else '无'}当前页面的html结构: {dom_structure}当前页面的网页元素信息: {web_structure}用户请求: "{user_request}"上一轮反馈: {feedback if feedback else '无'}请生成Playwright表单填写代码,使用:1. page.fill(selector, value)填写字段2. page.click(selector)提交表单【模态框iframe表单填写策略】填写表单前请严格按照以下步骤生成Playwright代码:1. 先等待并确认「新增日志」按钮可点击:- 等待元素出现:page.wait_for_selector('button#新增日志按钮选择器', timeout=10000)- 滚动到可见:page.evaluate("() => document.querySelector('button#新增日志按钮选择器').scrollIntoView()")- 如果常规click失败,可用evaluate或JS点击:page.evaluate("() => document.querySelector('button#新增日志按钮选择器').click()")2. 点击后等待模态框容器出现(如#triggerModal),并确保可见:- page.wait_for_selector('#triggerModal', timeout=10000)3. 等待iframe标签本身出现:- 等待iframe加载到DOM:frame = page.wait_for_selector('iframe', timeout=15000)4. 获取iframe的 content_frame() 对象:- frame = page.frame_locator('iframe').first.content_frame()- 确认iframe是否返回None,如果获取失败,抛出异常:if not frame:raise Exception("无法获取iframe内容")5. 在获取到的iframe frame对象里:- 分别等待内部表单输入框和按钮:frame.wait_for_selector('input[name="字段名"]', timeout=10000)frame.wait_for_selector('button[type="submit"]', timeout=10000)- 分别调用 fill() 和 click():frame.fill('input[name="字段名"]', '字段值')frame.click('button[type="submit"]')- 所有wait_for_selector必须带超时参数6. 如果在任何步骤中发生超时错误,尝试重新执行该步骤,最多重试3次。返回操作结果。你只能输出python代码,不要输出任何其他信息。示例:page.fill('input[name="username"]', 'your_username')page.click('button[type="submit"]')"""),("human", "生成表单填写代码")]response = llm.invoke(messages)res = response.content.replace('```python', '').replace('```', '').strip()#print(res)try:exec(res, globals(), locals())return {'status': 'success','message': 'Form filled successfully',}except Exception as e:return {'status': 'error','message': str(e),}# 文件下载智能体
def document_download_agent(target_url: str,user_request: str,model_use: str = 'deepseek-chat',page: Page = None,feedback: Optional[str] = None,download_dir: str = './downloads',account_info: Optional[Dict] = None
) -> Dict[str, str]:"""Download files using Playwright."""dom_structure = extract_interactive_dom(target_url, page)llm = ChatOpenAI(model=model_use, temperature=0.2)messages = [("system", f"""你是一个文件下载智能体,需要根据用户请求下载网页上的文件。当前URL: {target_url}网页系统的账户信息: {account_info if account_info else '无'}当前页面的DOM结构: {dom_structure}用户请求: "{user_request}"下载文件保存到目录: {download_dir}{"上一轮反馈: " + feedback if feedback else ""}请生成Playwright下载代码,使用:1. page.click(selector)触发下载2. page.wait_for_event('download')等待下载完成返回下载结果。你只能输出python代码,不要输出任何其他信息。示例:```pythondownload = page.wait_for_event('download')result = download.path()```"""),("human", "生成文件下载代码")]response = llm.invoke(messages)res = response.content.replace('```python', '').replace('```', '').strip()#print(res)try:exec(res, globals(), locals())return {'status': 'success','downloaded_files': locals().get('result', []),}except Exception as e:return {'status': 'error','message': str(e),}
评估体系设计:引入结果评估智能体与页面结果优化智能体,确保多智能体协作过程中每一步的输出都能被验证与优化。结果评估智能体通过对比用户请求、智能体输出、当前页面URL与DOM结构,判断任务是否真正满足需求,重点关注登录是否成功、页面内容是否完整、表单是否正确提交、文件是否完整下载等关键场景,并以统一的 JSON 格式(status=YES/NO + 反馈信息) 返回结果,用于驱动任务的重试或迭代。与此同时,页面结果优化智能体在评估结果的基础上,将复杂的执行过程转化为用户友好的 Markdown 说明,包括任务进程、目标、页面信息与执行结果,使得用户能够清晰理解当前自动化操作的状态与价值。该评估体系既保证了系统执行的可靠性与闭环性,又提升了交互的可解释性和易用性,是实现浏览器自动化智能体可信运行的关键环节。
#结果评估智能体
def evaluate_and_feedback(agent_output, user_request,target_url,page):##获取当前页面的文本内容dom_structure = extract_interactive_dom(target_url, page)# 根据agent的输出和用户请求进行评估和反馈llm = ChatOpenAI(model=model_use, temperature=0.2)messages = [("system", f"""你是一个网页操作智能体结果评估助手,需要根据用户请求和智能体输出以及当前页面信息进行评估,各子任务智能体执行返回的信息进行深度评估。主要评估场景包括:1. 用户请求是否被满足,用户请求的内容是否在当前页面中。2. 当前页面的DOM结构是否符合预期。3. 当前页面的URL是否符合预期。4. 当前页面的内容是否符合用户请求。5. 如果有反馈内容,是否需要重新执行智能体任务。6. 重点关注的是登录是否报错、页面内容提取是否符合用户的诉求及是否完整、用户需要填入的信息是否精准填入相应的模块、用户需要下载的文件是否完整下载。【提示】登录成功的标准是不在登录页,页面内容提取的标准是提取到用户请求的内容,表单填写的标准是表单提交成功且数据正确,文件下载的标准是文件完整下载。[Login Success Conditions]1. Current URL is NOT the login page URL (check if URL contains 'login' or matches known login patterns)2. DOM contains elements indicating authenticated state (e.g. user profile, logout button)3. No error messages related to authentication in the page content【注意】你只能输出JSON格式的结果,不要输出任何其他信息。Current State:- User request: {user_request}- Agent output: {agent_output}- Current URL: {target_url}- Current Page DOM structure: {dom_structure}Output JSON format:```json{{"feedback": "反馈内容""status": "YES" 或 "NO"}}'''"""),("human", "生成反馈,status为YES或NO")]response = llm.invoke(messages)res = response.content.replace('```json', '').replace('```', '').strip()return json.loads(res)
from playwright.sync_api import sync_playwright
import sys##页面结果优化智能体
def get_page_text_agent(agent_output, user_request,target_url=None,page=None):if page is not None:##获取当前页面的文本内容dom_structure = extract_interactive_dom(target_url, page)else:dom_structure = "无页面内容"# 根据agent的输出和用户请求进行评估和反馈llm = ChatOpenAI(model=model_use, temperature=0.2)messages = [("system", f"""你是一个网页操作智能体结果优化助手,需要根据用户请求和智能体输出以及当前页面信息进行优化,输出用户能理解的信息,使得用户能够了解当前任务进程及结果。当前页面信息: {dom_structure if page is not None else '不需要'}用户请求: {user_request}智能体输出: {agent_output}"""),("human", "优化输出结果,使其更易于用户理解,输出形式为markdown格式。包括以下内容:当前任务进程、当前任务目标、当前页面信息、智能体输出结果等。注意,输出的内容可能需要再系统后续中使用,并可能作为内容嵌入json格式内容中,请保证输出结果没有特殊字符")]response = llm.invoke(messages)res = response.contentreturn res
任务拆解、规划及参数协作设计:系统通过 大模型驱动的任务规划器 对用户输入进行语义解析和意图识别,将复杂的业务需求拆解为若干有序子任务。例如,“查询某人本周的工作日志”会被拆解为 登录 → 导航到日志页面 → 输入查询条件 → 提取结果数据 等步骤。规划器会以 JSON 结构化计划 的形式输出协作流程,明确每一步的任务目标、负责执行的智能体及预期输出。
随后,进入 参数协作阶段。在每个子任务执行前,系统会调用 参数生成助手,根据用户的原始请求、业务知识库、前序智能体的输出结果,自动补齐下一个智能体所需的参数。例如,导航智能体输出的页面 URL 会作为信息提取智能体的输入参数,表单智能体的字段信息则可能依赖前一阶段的解析结果。通过这种方式,智能体之间建立了高效的信息传递链路,避免重复推理和上下文丢失。
#多智能体协作机制
def multi_agents_cooperation(query: str, model_use: str = 'deepseek-chat',web_page_info=None,agents_info: List[Dict[str, str]] = []):llm = ChatOpenAI(model=model_use, temperature=0.2)messages = [("system", f"""你是一个多智能体协作助手,根据用户的诉求选择合适的智能体进行任务处理。用户问题为: "{query}"智能体信息为: {agents_info}业务系统知识库为: {web_page_info}请根据用户问题,选择合适的智能体进行任务处理。请根据如下常见场景提示,增强你对任务的理解和分解能力:常见任务场景提示:需要登录的业务系统登录页填写用户名和密码跳转至主页面,验证登录成功系统内搜索任务在搜索栏输入关键词筛选搜索结果列表点击进入详细页面信息提取任务确定页面是否包含目标信息(如任务名称、状态、人员等)提取具体字段(可通过 DOM/XPath/CSS Selector)表单填写任务输入表单数据提交并验证是否成功文件下载任务点击“下载”按钮或链接等待下载完成并返回文件信息多轮跳转/页面深度遍历可能需要多层跳转寻找目标页面每一层都需判断是否相关,决定是否深入或回退其他场景需要根据具体业务逻辑进行判断和处理主要工作:1、理解用户的问题,规划多智能体协作的方案。2、拆解成多个子任务,每个子任务由一个智能体完成。3、输出多智能体协作的方案,包括步骤信息,各步骤选择的智能体及其任务,各个步骤的预期输出。你应该输出一个JSON对象,不要输出任何非Json格式的其他信息,包含多智能体协作的方案,包括步骤信息,各步骤选择的智能体及其任务,各个步骤的预期输出。输出的信息格式如下:```json{{"initial_url": "url,<从知识库内自动判断与用户问题相关的业务系统地址>","steps": [{{"step": "step1","agent": "agent1","task": "task1","output": "output1"}},{{"step": "step2","agent": "agent2","task": "task2","output": "output2"}}]}}'''"""),("human","你的主要工作是:理解用户的问题,规划多智能体协作的方案。")]response = llm.invoke(messages)res = response.content.replace('```json', '').replace('```', '').strip()strategy = json.loads(res)return strategy#参数共享
@retry(wait=wait_fixed(3), stop=stop_after_attempt(3))
def get_parameters_multiple_agents(query: str, model_use: str = 'deepseek-chat',agents_info: List[Dict[str, str]] = [],last_agent_response: str = ""):llm = ChatOpenAI(model=model_use, temperature=0)messages = [("system", f"""你是一个智能体信息共享助手。根据用户的问题,获取智能体的输入参数。用户问题为: "{query}"智能体信息为: {agents_info}前一个智能体的输出为: {last_agent_response}请根据用户问题,获取智能体的输入参数。[警告]请不要杜撰智能体参数信息,根据各个智能体的输出,准确的完整的输出各个智能体的输入参数。【建议】涉及到网址搜索的,最大搜索结果数至少为10个。[注意] 不要遗漏智能体的输入参数,完整的输出各个智能体的所有输入参数。【提示】如果用户的问题中无明确的日期,默认是最新的日期。【提示】给出的参数需要尽可能精准,如果输出的文字参数,请不要过于精简,尽可能与用户的诉求、任务描述等一致,适当扩展你应该输出一个JSON对象,包含智能体的名称和输入参数。不要输出任何其他信息。输出的信息格式如下:```json{{"<agent_name>": {{"target_url": "https://example.com"}},.....}}'''"""),("human", "你的主要工作是:获取智能体的输入参数。")]response = llm.invoke(messages)res = response.content.replace('```json', '').replace('```', '').strip()strategy = json.loads(res)return strategy
(2)知识检索模块设计
在浏览器自动化的多智能体协作体系中,单纯依靠 DOM 解析与任务规划往往难以完整支撑复杂的业务逻辑执行,因为实际的企业系统往往伴随着复杂的操作手册、技术说明书及制度文档。因此,本系统设计了一个 知识检索模块,作为智能体执行的“背景知识支撑层”,用于补充和解释业务系统的操作逻辑。
该模块的设计思想是:通过 大模型驱动的知识检索助手,将用户的自然语言请求与本地 业务系统知识库(包含系统摘要、账号信息、系统网址、操作文档路径等)进行语义关联,筛选出最相关的业务系统,并输出系统名称、网址、账号信息及对应操作手册文件地址。随后,系统进一步解析这些文件(支持 txt、pdf、docx 等格式),抽取文档中与用户诉求强相关的内容,包括 数据结构、字段含义、取值范围、依赖关系、页面操作逻辑 等,从而将操作指南与任务规划进行深度融合。
最终,模块会输出统一的 JSON 格式知识描述,其中不仅包含账号密码、数据结构、页面信息,还附带详细的系统上下文逻辑。这样,智能体在执行过程中能够调用知识检索结果作为辅助信息,提升页面导航、参数填写、信息提取等操作的准确性与稳定性。通过这种方式,系统实现了 “任务推理 + 知识补充” 的闭环设计,使得自动化执行不仅依赖网页结构,还具备业务知识背景,显著增强了在复杂业务系统中的适应性与鲁棒性。
##业务系统知识检索:输出业务系统知识、账号密码
def system_knowledge_RGA(uer_request,model_use):##读取业务系统知识摘要文件:"C:/Users/liuli/Desktop/multi_agents_system/multi_agents/system_kg/system_kg.json"with open("C:/Users/liuli/Desktop/multi_agents_system/multi_agents/system_kg/system_kg.json", 'r', encoding='utf-8') as f:system_info = json.load(f)#print(system_info)llm = ChatOpenAI(model=model_use, temperature=0.2)#检索业务系统文件,输出业务系统操作指南文件地址messages_system_knowledge_summary = [("system", f"""你是一个**业务系统知识检索助手**。你的任务是:1. 根据用户请求,检索本地业务系统知识库(包含多个业务系统的摘要信息、账号信息、系统网址、文件路径等)。2. 从知识库中找到与用户请求**最相关**的业务系统。3. 提取并返回该系统的关键信息,包括:系统名称、账号信息(如需要)、系统网址、业务系统知识文件路径。用户请求: "{uer_request}"业务系统知识库为: {system_info}输出格式为json格式,必须严格按照以下格式输出,不要包含任何额外的文本或解释:```json{{"status": "success","system_name": "业务系统名称","account_info": {{"account": "账号","password": "密码"}},"system_url": "业务系统网址","original_file_path": "业务系统知识文件地址(文件可能是多种格式,如如txt、pdf、docx等),完整地址,如C:/Users/liuli/Desktop/multi_agents_system/multi_agents/system_kg/xxx...",}}```请确保输出是有效的JSON格式,不要包含任何其他文字。"""),("human", "请根据要求生成 JSON 输出")]response = llm.invoke(messages_system_knowledge_summary)res = response.content.replace('```json', '').replace('```', '').strip()system_knowledge = json.loads(res)#print(system_knowledge)#time.sleep(10)llm = ChatOpenAI(model=model_use, temperature=0.2)##读取original_file_path内容:txt、pdf、docx 格式original_file_path = system_knowledge.get("original_file_path", "")if original_file_path and os.path.exists(original_file_path):if original_file_path.endswith('.txt'):with open(original_file_path, 'r', encoding='utf-8') as f:system_do_info = f.read()elif original_file_path.endswith('.pdf'):from PyPDF2 import PdfReaderreader = PdfReader(original_file_path)system_do_info = "\n".join(page.extract_text() for page in reader.pages)elif original_file_path.endswith('.docx'):from docx import Documentdoc = Document(original_file_path)system_do_info = "\n".join(paragraph.text for paragraph in doc.paragraphs)system_relate_info = f"""业务系统基础信息:{system_knowledge},业务系统操作手册内容:{system_do_info if 'system_do_info' in locals() else '无'}"""messages_system_knowledge = [("system", f"""你是一个**业务系统知识深度解析助手**。你的任务是:1. 根据用户请求和业务系统操作手册,提取与用户诉求**强相关**的信息。2. 输出内容必须涵盖:- 业务系统名称、网址- 账号信息(如需要登录)- 数据结构(字段、含义、取值范围、依赖关系)- 与用户诉求相关的页面信息与操作逻辑(越详细越好)输入信息:- 用户请求: "{uer_request}"- 业务系统基础信息与操作手册内容: {system_relate_info}**输出要求:**- 必须返回 JSON 格式- 字段缺失时填入 `null`- 严格按照以下模板输出- 不得包含任何额外的文字、解释或代码标记```json{{"status": "success","system_name": "业务系统名称","system_url": "业务系统网址","account_info": {{"username": "用户名","password": "密码"}},"data_structure": {{"字段1": "字段1含义","字段2": "字段2含义"}},"web_page_info":"与用户诉求关联的页面信息、页面操作逻辑等,尽可能详细","system_context": "与用户诉求关联的系统信息、系统操作逻辑等,尽可能详细,markdown格式,请勿省略任何信息",}}```"""),("human", "请根据要求生成 JSON 输出")]response = llm.invoke(messages_system_knowledge)res = response.content.replace('```json', '').replace('```', '').strip()system_page_knowledge = json.loads(res)#account_info = system_knowledge.get("account_info", {})return system_page_knowledge
(3)协作体系设计
整个浏览器自动化体系的 核心调度入口,其设计思想是通过 多智能体协作机制 实现从自然语言需求到可执行自动化操作的完整闭环。
用户请求解析
- 入口接收用户的自然语言需求,例如“查询某项目的任务详情”。
- 系统首先调用 任务规划器,利用大模型将复杂请求拆解为多个有序的子任务(如登录、导航、提取、表单填写、下载等)。
智能体分配与调度:根据任务规划结果,系统动态选择对应的 功能性智能体:
- 导航智能体:跳转目标页面
- 信息提取智能体:解析页面数据
- 表单智能体:完成表单输入与提交
- 文件处理智能体:上传/下载文件
各个智能体执行时通过 参数协作机制 共享上下文信息,避免重复计算和信息丢失。
浏览器执行与反馈
底层通过 Playwright/浏览器驱动 完成真实 DOM 操作,保证可在业务系统中真实运行。
每个子任务执行后,结果被反馈到 结果评估智能体,判断是否满足用户请求,必要时触发重试或优化。
知识检索辅助
在执行过程中,如果任务涉及复杂的操作逻辑,系统会调用 知识检索模块,从操作手册或系统说明中补充上下文知识,提升任务执行的准确性。
最终结果输出
协作完成后,系统将所有步骤的执行结果整合,并通过 结果优化智能体 转换为用户可读的说明(Markdown 或可视化结果),并支持 JSON 输出,保证可追溯与复用。
# 多智能体协作模块
def web_system_auto_agent(user_request: str):#account_info = {"日志系统":{"url": "https://51opoc.zentaopm.com/", "username": "liulin", "password": "GloryView@2024"}}agents_info = [{"name": "web_navigation_agent", "description": "网页导航智能体,"},{"name": "webpage_info_extractor", "description": "网页信息提取智能体"},{"name": "form_filling_agent", "description": "表单填写智能体"},{"name": "document_download_agent", "description": "文件下载智能体"},]agents_param_info = [{"name": "web_navigation_agent","params": {"target_url": "str - The URL to navigate to","user_request": "str - User's navigation request","model_use": "str - Model to use (default: 'deepseek-chat')","max_iterations": "int - Maximum navigation iterations (default: 5)","page": "Page - Playwright page instance for navigation","feedback": "Optional[str] - Feedback from previous steps","account_info": "Optional[Dict] - Account credentials if needed"}},{"name": "webpage_info_extractor","params": {"target_url": "str - URL to extract information from","user_request": "str - User's extraction request","model_use": "str - Model to use (default: 'deepseek-chat')","page": "Page - Playwright page instance for DOM interaction","feedback": "Optional[str] - Feedback from previous steps","account_info": "Optional[Dict] - Account credentials if needed"}},{"name": "form_filling_agent","params": {"target_url": "str - URL with form to fill","user_request": "str - User's form filling request","model_use": "str - Model to use (default: 'deepseek-chat')","page": "Page - Playwright page instance for form interaction","feedback": "Optional[str] - Feedback from previous steps","account_info": "Optional[Dict] - Account credentials (required for login forms)"}},{"name": "document_download_agent","params": {"target_url": "str - URL to download files from","user_request": "str - User's download request","model_use": "str - Model to use (default: 'deepseek-chat')","page": "Page - Playwright page instance for download interaction","feedback": "Optional[str] - Feedback from previous steps","download_dir": "str - Directory to save downloads (default: './downloads')","account_info": "Optional[Dict] - Account credentials if needed"}}]web_page_info= system_knowledge_RGA(user_request,model_use=model_use)account_info = web_page_info.get("account_info", None)##使用智能体优化知识检索的结果RAG_optimized_output = web_page_info.get("system_context", None)yield {"type": "RAG_knowledge_retrieval","data": str(RAG_optimized_output),}sys.stdout.flush()print(json.dumps({"type": "RAG_knowledge_retrieval","data": RAG_optimized_output,}, ensure_ascii=False), flush=True)#多智能体协作方案设计collaboration_plan= multi_agents_cooperation(query=user_request,model_use=model_use,agents_info=agents_info,web_page_info=web_page_info,)yield {"type": "collaboration_plan","data": collaboration_plan}print(json.dumps({"type": "collaboration_plan","data": collaboration_plan}, ensure_ascii=False), flush=True)sys.stdout.flush()initial_url = collaboration_plan.get("initial_url","")"""Main function to coordinate multiple agents using Playwright."""with sync_playwright() as p:browser = p.chromium.launch(headless=False)context = browser.new_context()page = context.new_page()page.goto(initial_url)results = {}current_url = initial_urlstep_result =[]max_retries = 5feedback = Nonefor step in collaboration_plan.get("steps", []):step_name = step["step"]agent_name = step["agent"]step_task = step["task"]agent_functions = {"web_navigation_agent": web_navigation_agent,"webpage_info_extractor": webpage_info_extractor,"form_filling_agent": form_filling_agent,"document_download_agent": document_download_agent,}retry_count = 0step_success = Falsewhile not step_success and retry_count < max_retries:step_params = get_parameters_multiple_agents(query=step_task,model_use=model_use,agents_info=agents_param_info,last_agent_response=json.dumps(step_result)).get(agent_name, {})step_params["user_request"] = step_taskstep_params["model_use"] = model_usestep_params["feedback"] = feedbackstep_params["page"] = page # 确保传递Page对象step_params["account_info"] = account_info # 确保传递账户step_params['target_url'] = current_url # 使用当前URLif agent_name in agent_functions:try:# 调用对应的智能体函数result = agent_functions[agent_name](**step_params)step_result.append(result)results[step_name] = resultcurrent_url = page.url # 更新当前URL#print(f"当前页面URL: {current_url}")evaluation = evaluate_and_feedback(agent_output=step_result,user_request=step_task,target_url=current_url,page=page)#yield {# "type": "evaluation",# "step": step_name,# "data": evaluation# }#sys.stdout.flush()if evaluation.get("status") == "YES":step_success = Truecurrent_url = page.url#print(f" Step '{step_name}' passed evaluation")#判断成功之后,对当前的页面进行截图保存screenshot_path = f"./screenshots/step_{step_name}_{int(time.time())}.png"os.makedirs(os.path.dirname(screenshot_path), exist_ok=True)page.screenshot(path=screenshot_path, full_page=True,timeout=30000)#优化输出结果optimized_output = get_page_text_agent(agent_output=step_result,user_request=step_task,target_url=current_url,page=page)yield {"type": "step_execution","step": step_name,"agent": agent_name,"data": str(optimized_output),"screenshot_path":screenshot_path}sys.stdout.flush()print(json.dumps({"type": "step_execution","step": step_name,"agent": agent_name,"data": str(optimized_output),"screenshot_path":screenshot_path}, ensure_ascii=False), flush=True)yield {"type": "evaluation","step": step_name,"data": evaluation}print(json.dumps({"type": "evaluation","step": step_name,"data": evaluation}, ensure_ascii=False), flush=True)sys.stdout.flush()else:retry_count += 1feedback = evaluation.get("feedback", "No specific feedback")#print(f" Step '{step_name}' failed evaluation (attempt {retry_count}/{max_retries})")#print(f"Feedback: {feedback}")if retry_count >= max_retries:results[step_name] = {"status": "failed","message": f"Step failed after {max_retries} retries","evaluation_feedback": feedback}yield {"type": "step_execution","step": step_name,"agent": agent_name,"data": "failed","screenshot_path":screenshot_path}sys.stdout.flush()break#更新page状态except Exception as e:logging.error(f"Error in step {step_name}: {e}")context.close()browser.close()
(4)网页操作自动化过程前端设计
基于Streamlit的网页浏览器自动化操作设计
from playwright.sync_api import sync_playwright, Page, BrowserContext
from typing import Dict, Optional, List
import json
import time
import logging
from bs4 import BeautifulSoup
from langchain_openai import ChatOpenAI
from langchain.schema import HumanMessage
from tenacity import retry, stop_after_attempt, wait_fixed
import os
import streamlit as st # Add Streamlit import
import glob
from crawler import web_system_auto_agentimport subprocess
import json
import sys
from typing import Generatordef run_playwright_agent(user_request: str) -> Generator[dict, None, None]:"""Run the Playwright agent in a separate process and stream results in real-time"""# Prepare the input datainput_data = {"user_request": user_request}# Start the subprocessprocess = subprocess.Popen([sys.executable, r'C:\Users\liuli\Desktop\multi_agents_system\multi_agents\run_browser_auto_agent.py'],stdin=subprocess.PIPE,stdout=subprocess.PIPE,stderr=subprocess.PIPE,text=True,bufsize=1,universal_newlines=True # Line buffered)# Send input data to the subprocesstry:process.stdin.write(json.dumps(input_data) + '\n')process.stdin.flush()process.stdin.close()except Exception as e:yield {"type": "error", "data": f"Failed to send input to subprocess: {str(e)}"}return# Read output line by line in real-timewhile True:output_line = process.stdout.readline()if output_line == '' and process.poll() is not None:breakif output_line:try:result = json.loads(output_line.strip())yield resultexcept json.JSONDecodeError:# Log non-JSON output for debugginglogging.warning(f"Non-JSON output: {output_line.strip()}")yield {"type": "final_result", "data": f"Final output: {output_line.strip()}"}continue# Check for any errorsstderr_output = process.stderr.read()if stderr_output:yield {"type": "error", "data": f"Subprocess error: {stderr_output.strip()}"}process.wait()# 读取模型配置
with open(r'C:\Users\liuli\Desktop\multi_agents_system\multi_agents\agents_info\model config.json', 'r') as f:config = json.load(f)
model_use = 'gemini-2.0-flash'
model_config = config[model_use]
os.environ.update({"OPENAI_API_KEY": model_config['openai_api_key'],"OPENAI_MODEL_NAME": model_config.get('model_name', ''),"OPENAI_API_BASE": model_config.get('openai_api_base', '')
})web_page_info = [{"禅道工作日志记录系统": {"系统网址": "https://51opoc.zentaopm.com/","任务查询页面": "https://51opoc.zentaopm.com/my-task-assignedTo.html","日志填报页面": "https://51opoc.zentaopm.com/effort-calendar.html","项目首页": "https://51opoc.zentaopm.com/project-index-no.html",}}
]def web_Browser_auto_page():st.title("🤖 Web Agent System")# Initialize session stateif 'agent_results' not in st.session_state:st.session_state.agent_results = Noneif 'messages' not in st.session_state:st.session_state.messages = []if 'execution_results' not in st.session_state:st.session_state.execution_results = []if 'is_running' not in st.session_state:st.session_state.is_running = False# Display chat historyfor message in st.session_state.messages:with st.chat_message(message["role"]):st.markdown(message["content"])# 增加初始提醒信息,提醒用户如何使用该系统 st.markdown("""**使用说明:**- 输入您的任务请求,例如"请帮我查询禅道工作日志记录系统2025年7月17日工作日志的数据"。- 系统将自动规划多智能体协作方案,并执行任务。- 任务执行过程中,您可以查看每个步骤的执行情况和结果。""")# User inputif prompt := st.chat_input("🔍 Enter your web task request", key="user_input"):# Display user messagest.session_state.messages.append({"role": "user", "content": prompt})with st.chat_message("user"):st.markdown(prompt)# Process request with agentwith st.chat_message("assistant"):st.session_state.is_running = Truest.session_state.execution_results = []# Create containers for different sectionsplan_container = st.container(border=True)steps_container = st.container(border=True)eval_container = st.container(border=True)final_container = st.container(border=True)# Initialize placeholdersplan_placeholder = Nonestep_placeholders = {}eval_placeholders = {}with st.spinner('🤖 Planning collaboration strategy...'):# Process the request step by stepfor update in run_playwright_agent(prompt):if update["type"] == "RAG_knowledge_retrieval":if 'rag_container' not in locals():rag_container = st.container(border=True)with rag_container:st.subheader("📚 RAG Knowledge Retrieval")rag_placeholder = st.empty()with rag_placeholder.container():st.markdown("**Retrieved Knowledge:**")# Format the knowledge retrieval result nicelyif isinstance(update['data'], str):st.info(update['data'])elif isinstance(update['data'], dict):st.json(update['data'])else:st.write(update['data'])elif update["type"] == "collaboration_plan":if plan_placeholder is None:with plan_container:st.subheader("📋 Collaboration Plan")plan_placeholder = st.empty()tab_json, tab_flow = st.tabs(["collaboration_plan", "collaboration_plan Flowchart"])with tab_json:st.markdown("**Collaboration Plan JSON:**")plan_placeholder.json(update["data"])with tab_flow:import graphvizdot = graphviz.Digraph()for step in update["data"].get("steps", []):dot.node(step["step"], f"{step['step']} ({step['agent']})")for i in range(len(update["data"]["steps"]) - 1):dot.edge(update["data"]["steps"][i]["step"], update["data"]["steps"][i+1]["step"])st.graphviz_chart(dot)#plan_placeholder.json(update["data"])st.session_state.execution_results.append(update)elif update["type"] == "step_execution":step_key = update['step']if step_key not in step_placeholders:with steps_container:st.subheader(f"⚙️ Step Execution: {update['step']}")step_placeholders[step_key] = st.empty()with step_placeholders[step_key].container():st.markdown(f"**Agent**: `{update['agent']}`")st.markdown(f"**Result**:")st.markdown(update["data"])# Display screenshot if availableif "screenshot_path" in update and update["screenshot_path"]:st.markdown(f"**Screenshot**:")try:st.image(update["screenshot_path"], caption=f"Step {update['step']} Screenshot")except Exception as e:st.warning(f"Could not load screenshot: {str(e)}")st.session_state.execution_results.append(update)elif update["type"] == "evaluation":step_key = update['step']if step_key not in eval_placeholders:with steps_container:st.subheader(f"✅ Step Evaluation: {update['step']}")eval_placeholders[step_key] = st.empty()with eval_placeholders[step_key].container():st.markdown(update["data"])st.session_state.execution_results.append(update)elif update["type"] == "error":st.error(f"❌ Error: {update['data']}")st.session_state.messages.append({"role": "assistant", "content": f"Error occurred: {update['data']}"})st.session_state.is_running = Falsebreakelif update["type"] == "final_result":st.session_state.is_running = Falsest.session_state.agent_results = update["data"]with final_container:st.subheader("🎉 Final Result")st.markdown(update["data"])st.session_state.messages.append({"role": "assistant", "content": update["data"]})# Disable chat input while runningif st.session_state.is_running:st.chat_input("🔍 Enter your web task request", disabled=True, key="disabled_input")
Browser Automation System Demo
任务:请帮我查询禅道工作日志记录系统2025年7月17日工作日志的数据
- 业务系统操作知识检索结果:

- 任务规划结果
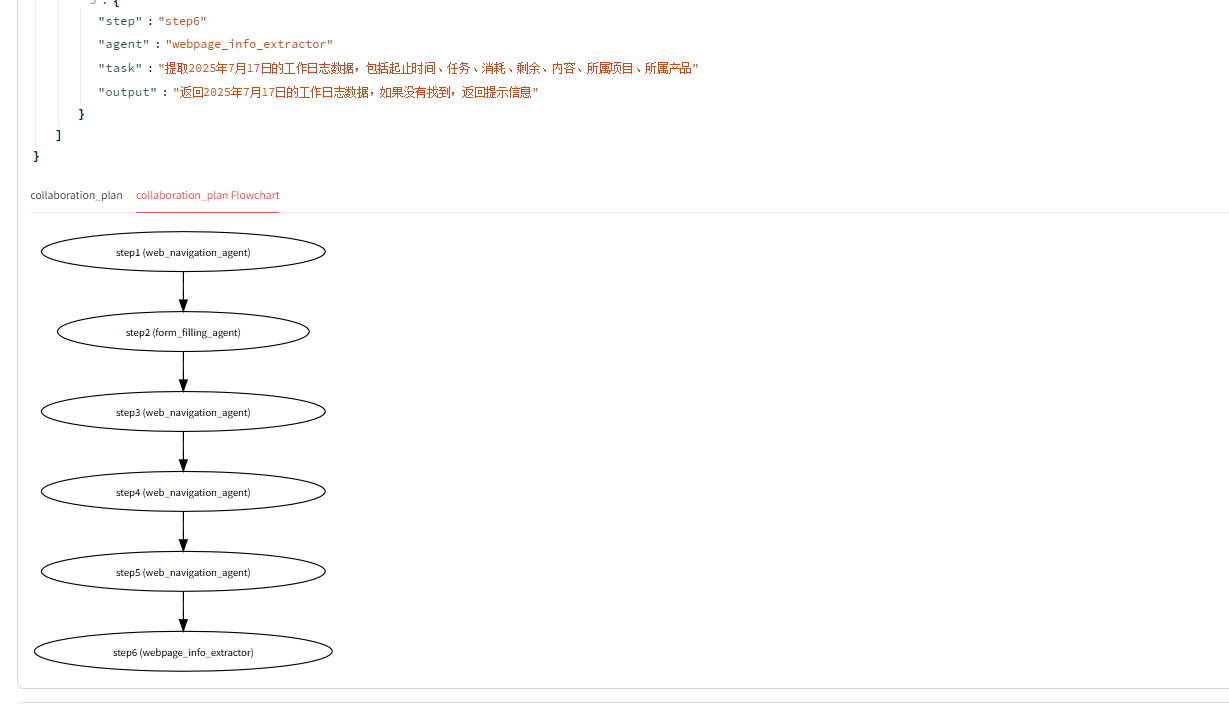
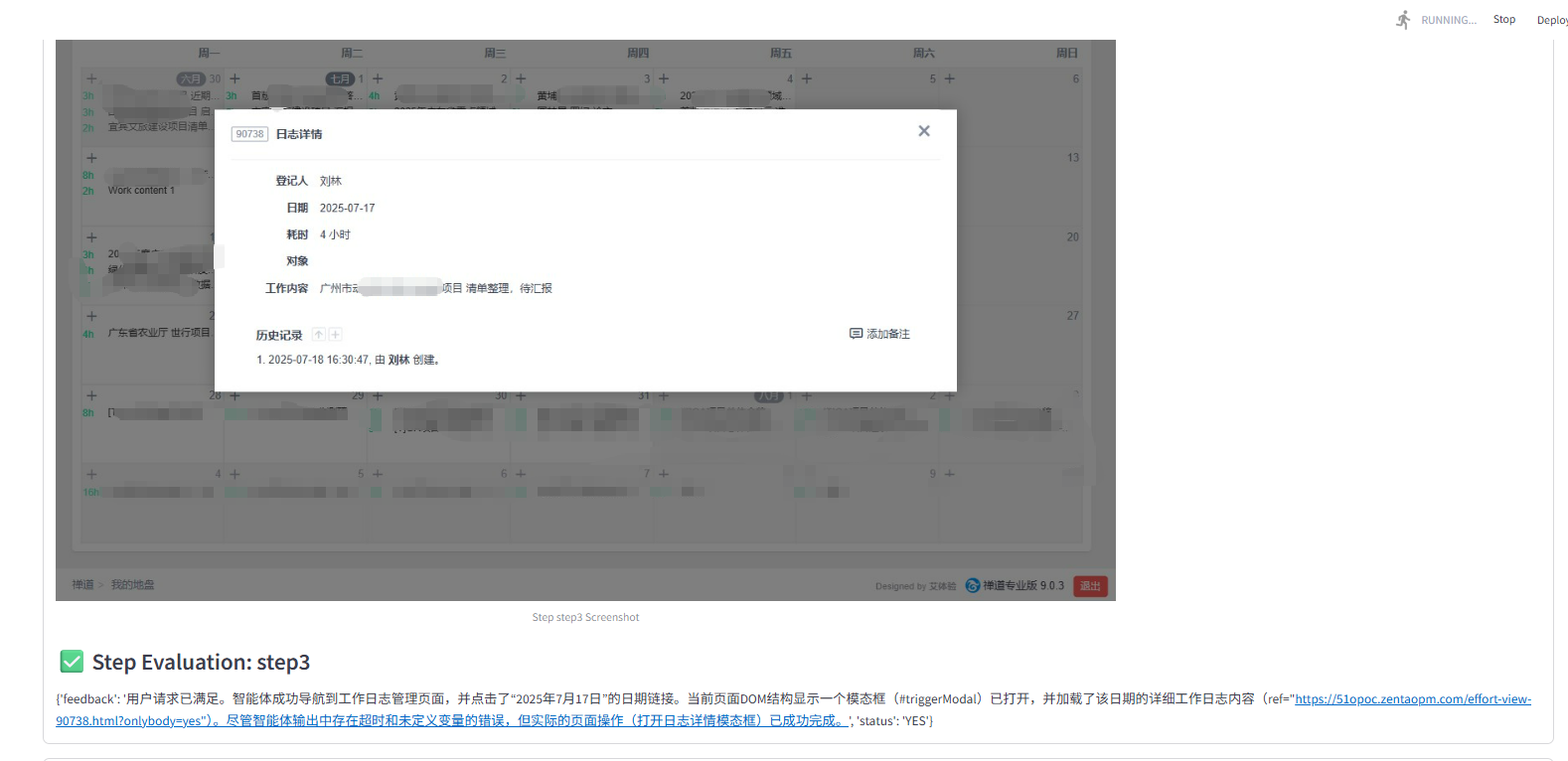
- 步骤执行结果及评估
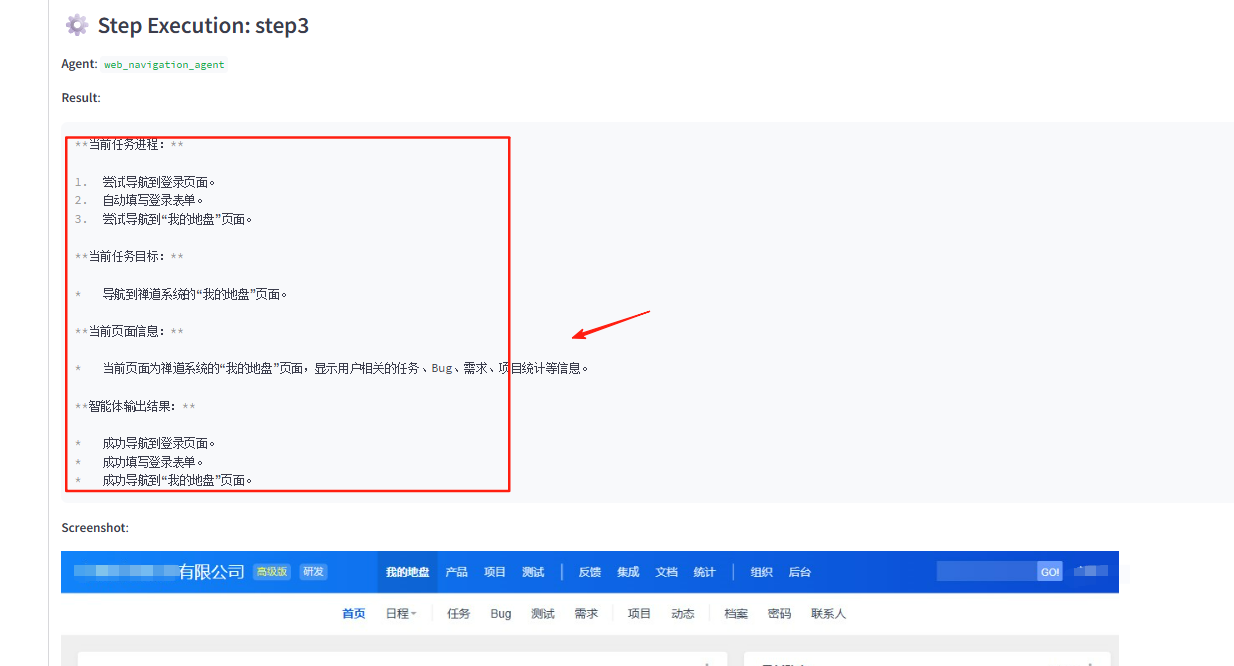
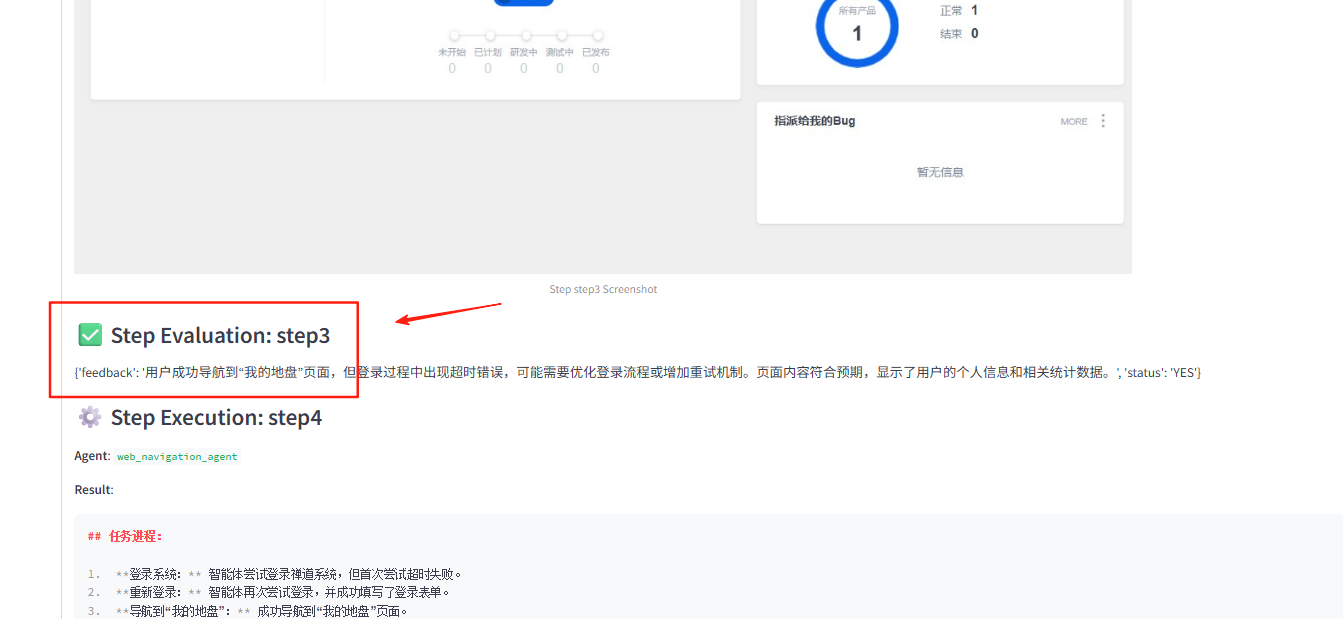
- 最终结果
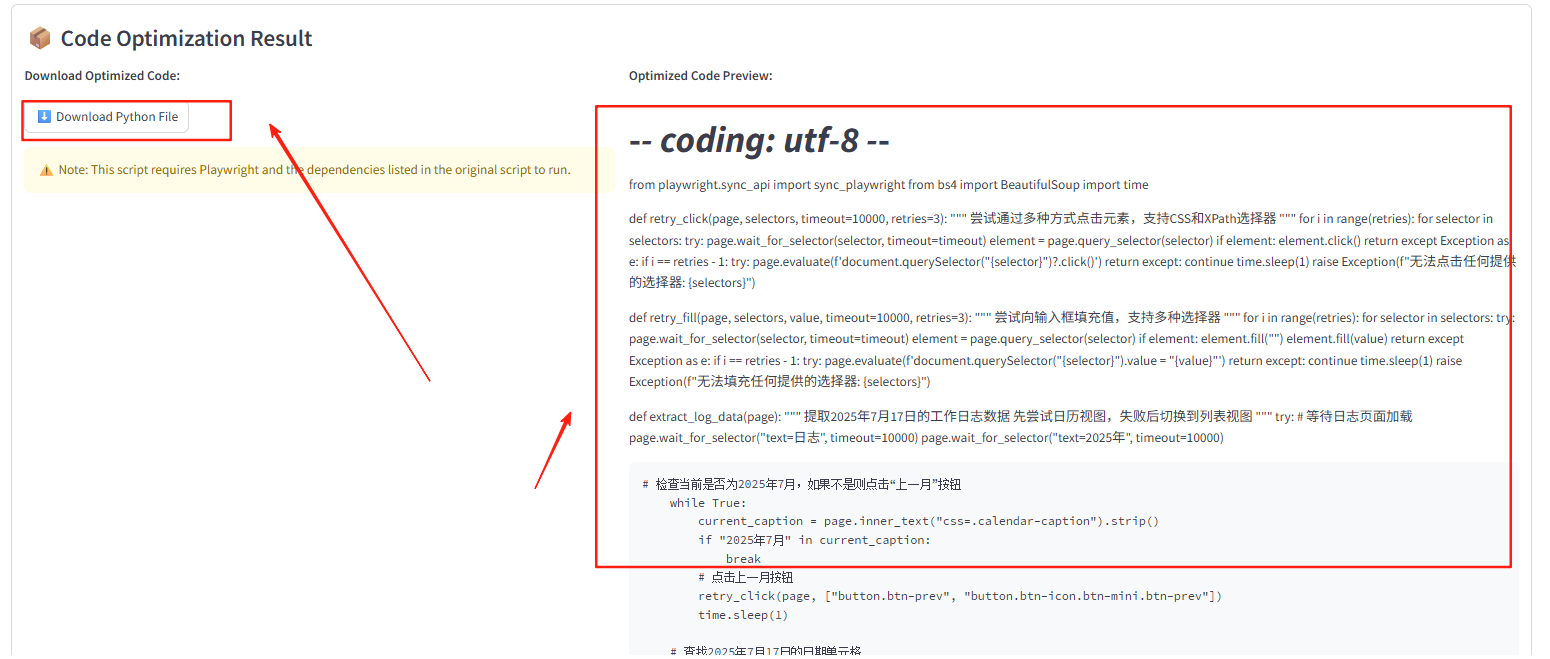
整体任务的多智能体生成代码
任务二:
任务规划:从arxiv中检索multi agents相关论文,并下载前五篇论文。
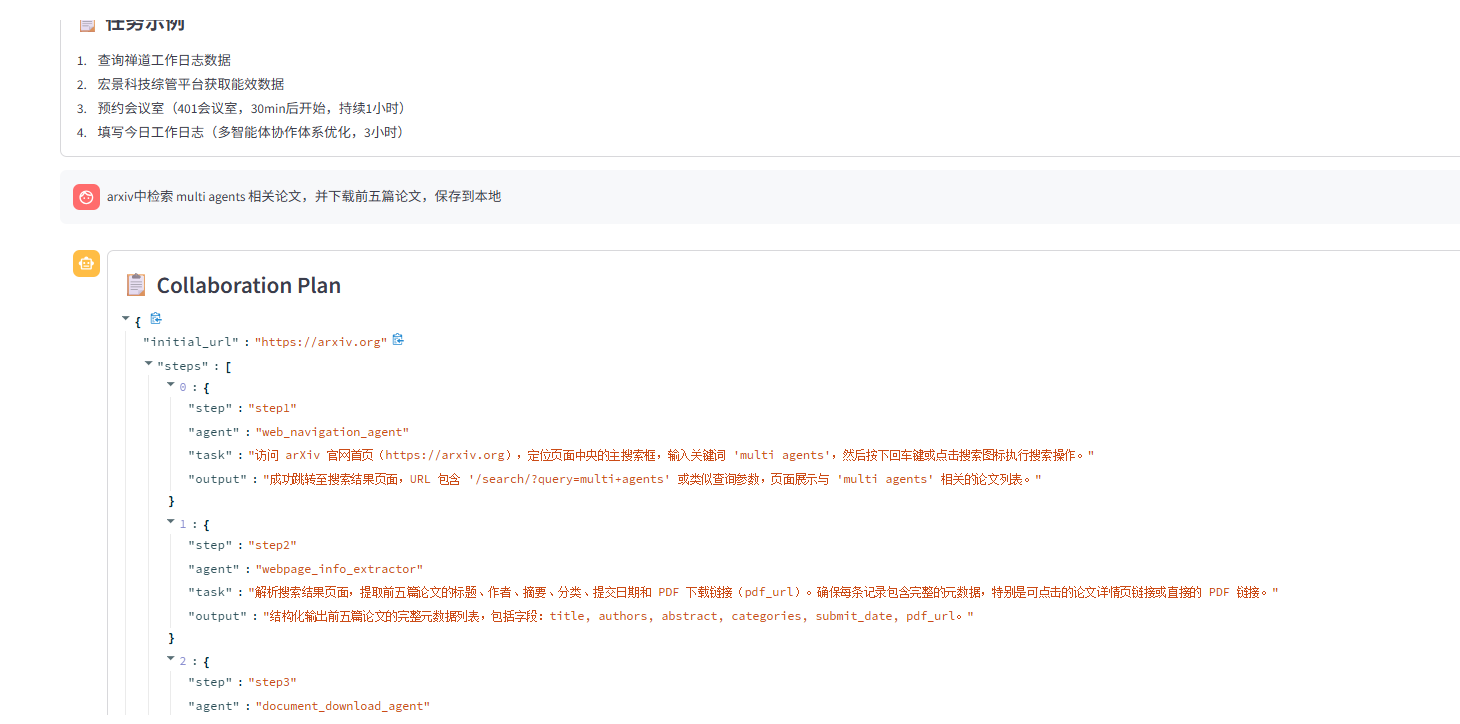
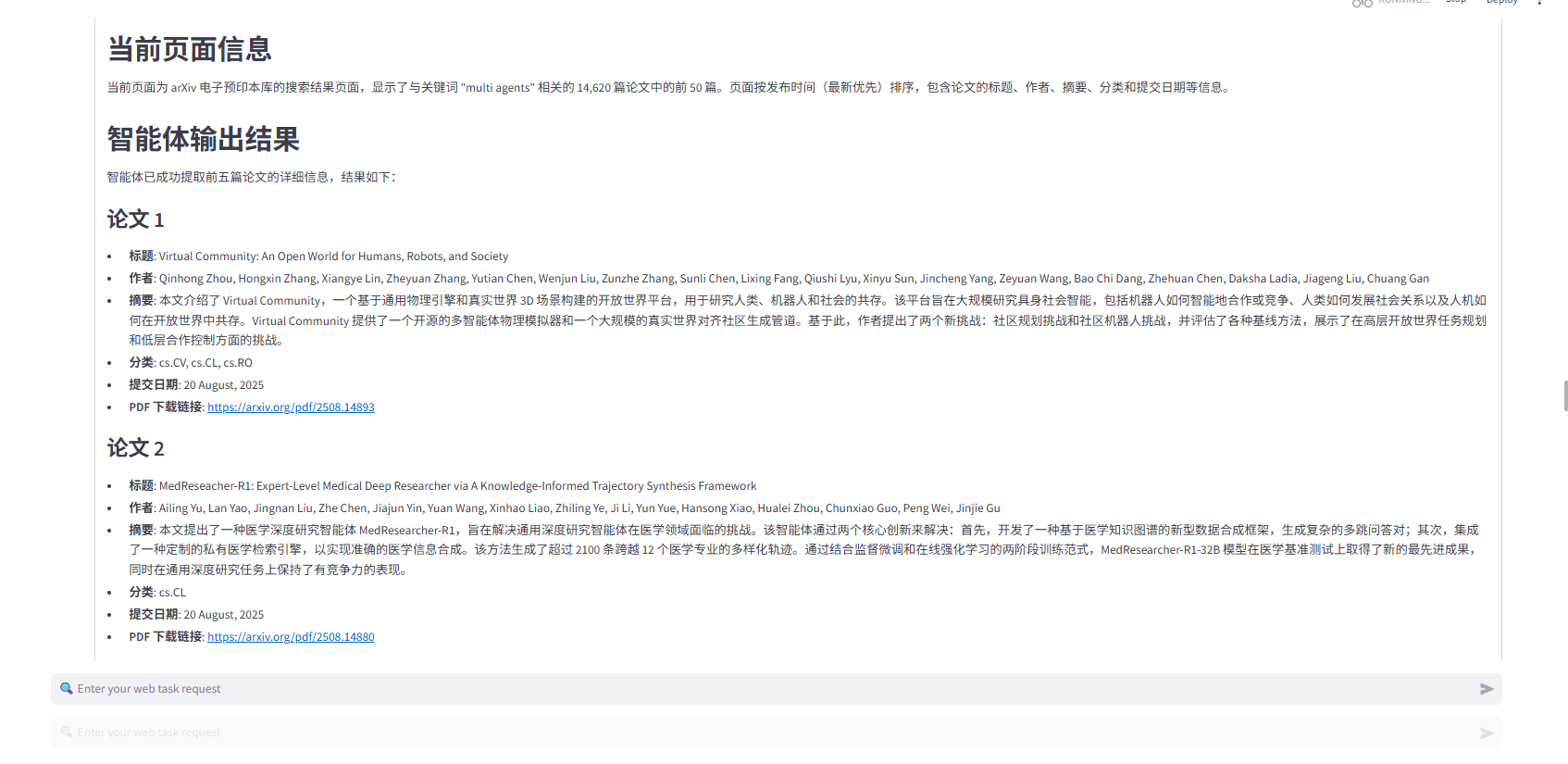
检索结果:
总结
Multi Agents Collaboration OS:Browser Automation System 展示了基于 大模型推理能力 与 多智能体协作机制 的浏览器自动化新范式。它将原本依赖人工的繁琐操作转化为自然语言驱动的自动化闭环,极大提升了业务系统的交互效率与智能化水平。随着大模型技术的快速发展,该系统在企业场景中拥有广阔的前景:无论是流程化操作、跨系统信息检索,还是复杂任务的自动执行,都能通过智能体协作实现更高效的业务支撑。
在优化方向上,该系统具备多维度提升空间:
- 性能优化:通过异步调度与智能缓存机制,减少浏览器操作的等待时间,提高大规模任务的执行吞吐量。
- Token 消耗优化:在大模型调用中引入上下文裁剪、知识摘要与多轮记忆管理,降低冗余对话带来的 Token 成本。
- 系统操作优化:通过更精细的 DOM 解析、错误恢复机制和操作回滚能力,进一步提升复杂页面场景下的稳定性与鲁棒性。
在产品化方向上,该系统可逐步演进为 浏览器插件形态。用户只需安装插件,即可在任意业务系统中通过对话式界面发出请求,插件会自动调用多智能体完成任务执行,并直接在浏览器中反馈结果。这不仅降低了部署与使用成本,还能更好地适配跨行业的业务需求,成为企业数字化转型的重要工具。
综上,本系统通过 智能体协作 + 知识检索 + 浏览器操作 的融合设计,奠定了“下一代业务交互操作系统”的基础,并具备向高性能、低成本、易部署方向演化的潜力。