【AI】算法环境-显卡、GPU、Cuda、NVCC和cuDNN的区别与联系
前言
近期的工作总是和AI领域的模型训练业务产生联系,对于算法同学的运行环境产生了一些疑问,特此记录一下。
正文
显卡(Graphics Card)
显卡(又称显示卡,显示器适配卡)是电脑主板上的一块可拆卸的板卡,是一个硬件设备,是一个图形处理模块,用来输出显示图形,如果电脑没有显卡,显示器是无法显示出画面的。
显卡分为集成显卡和独立显卡,集成显卡(简称集显)早期为直接焊接在电脑主板上的图形芯片,性能较弱,现已基本淘汰;经过“进化”之后,出现了一种核心显卡(简称核显),集成在CPU内部,与CPU共享资源,能效较高。集成显卡通常不自带显存,需要从系统内存中动态分配一部分作为显存使用,我们办公用的笔记本电脑一般都是核显(比如intel核显、高通骁龙核显)、集成显卡,通常用在续航时间长的轻薄笔记本中。

独立显卡(简称独显):具有独立的芯片、独立的显存和独立的散热系统。相对于集成显卡来说,有自己的显存模块,在性能上远超集成显卡,功耗相对较高,适用于高端游戏、图形设计、3D渲染、AI领域等高性能应用场景,通常用在台式机、高性能笔记本(游戏本、工作站)中。
最开始所说的显卡和后续提到的显卡,指独立显卡。如下所示,最外层壳体带有风扇等散热装备。
显卡的组成
- GPU(Graphics Processing Unit) 芯片,图形处理单元
- 显存
- 供电模块
- 接口(视频接口、PCIe接口等)
- 散热模块
- 电路板
GPU
显卡的核心,负责处理所有运算任务
显存
CPU运行需要内存,GPU运行也需要内存,即显存
接口
视频接口:GPU运算好的图像通过视频接口发送给显示器显示
PCle接口:GPU通过PCle接口与CPU、内存等交换数据

GPU(Graphic Processing Unit)
图像处理单元,GPU这个概念是由Nvidia(英伟达,显卡厂商)公司于1999年提出的。后面提到的CUDA、CUDA Toolkit、nvcc、cudnn都是Nvidia公司针对自身的GPU独家设计的东西。GPU是显卡上的一块芯片。最初用于图形渲染,后面扩展到用于处理并行计算任务。具有数千个计算核心,可以并行、高效地处理3D应用程序、渲染、AI计算、计算机游戏、视频编解码等工作负载。
大部分情况下,我们常说的GPU就指独立显卡,但实际上GPU是显卡的一个组成部分。

GPU 和 CPU的对比
CPU(Central Processing Unit): 中央处理器,作为计算机的“大脑”,负载计算机的运算与控制工作。
GPU(Graphics Processing Unit): 图形处理单元,专门处理图像、图形和视频的硬件。
| CPU | GPU | |
|---|---|---|
| 计算能力 | 串行处理,适合处理复杂的单一任务 | 并行处理,同时处理大量简单的任务 |
| 核心设计 | 较少的核心,但每个核心的计算能力都很强(好比教授的能力) | 大量的核心,每个核心的计算能力很一般(好比小学生的能力) |
| 延迟&吞吐量 | 低延迟,处理速度快 | 高吞吐量 |
| 代表产品 | Intel 酷睿 i9(16 核 32 线程)、Intel 至强 Platinum | NVIDIA RTX 4090(24GB VRAM(显存),2432 个 Tensor Core)、NVIDIA H100 |
核心数的对比:ALU(Arithmetic Logic Unit)即算术逻辑单元,两个图中的绿颜色格子即为格子的核心。
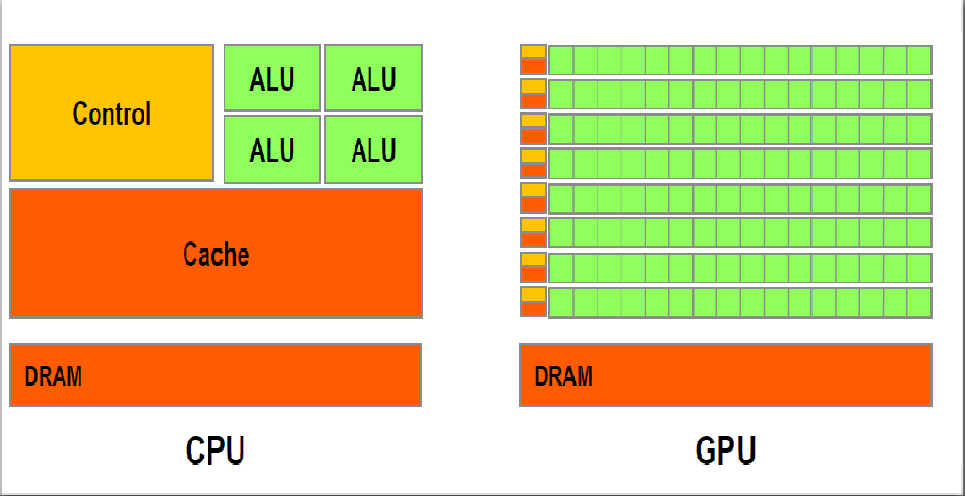
之前有一个视频(14年前,英伟达第一次向大众演示GPU和CPU的区别)中很直观的了解CPU和GPU的区别,在这个视频中,CPU 和 GPU 两种处理器在一场绘画对决中正面交锋。两种处理器先后连接到了一台发射彩弹来作画的机器上,通过射击到屏幕上的彩蛋来绘制图像。
CPU 需要整整 30 秒才能画出一个非常基本的笑脸:

然而,GPU 瞬间就能画出一幅蒙娜丽莎的图像

在没有GPU之前,基本上所有的任务都是由CPU处理的,有了GPU之后,GPU就来负责处理大规模的计算任务,CPU负责处理逻辑性强复杂的串行计算任务,来替CPU分担工作。
显卡驱动
显卡驱动是一种软件,连接操作系统和显卡硬件,大部分开发者说显卡就是指GPU,因此有时候说GPU驱动也是指显卡驱动;安装了显卡驱动,操作系统才能正常识别显卡,识别到GPU,将操作系统的指令和图形数据,转换为显卡能理解和执行的信号,显卡才能正常工作,在显示器上输出图像和视频内容。
显卡驱动由各大显卡供应商提供(比如NVIDIA显卡驱动、AMD显卡驱动、Intel显卡驱动分别对应NVIDIA系列显卡、AMD 系列显卡、Intel 系列显卡以及集成显卡),在linux服务器上安装显卡驱动时,可以选择离线安装或在线安装,离线安装方式可在显卡供应商的官网根据显卡型号和操作系统版本下载相应的显卡驱动。
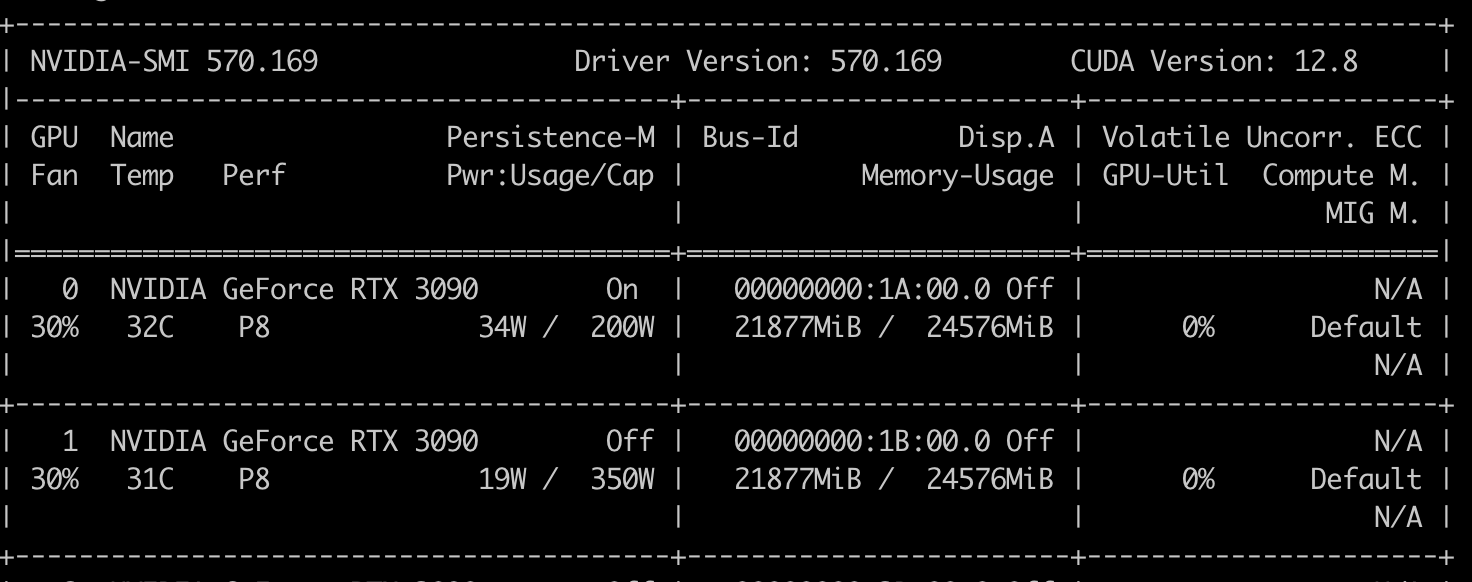
安装好了显卡驱动,在服务器上执行 nvidia-smi 出现显卡信息,说明驱动安装成功了,如下图所示,显卡(GPU)驱动(Driver Version)版本是 570.169 ,CUDA Version 表示当前GPU驱动支持的最高CUDA版本为12.8。
显卡驱动版本也可以通过执行cat /proc/driver/nvidia/version 来查看,输出如下:
NVRM version: NVIDIA UNIX x86_64 Kernel Module 570.169 Thu Jun 12 20:04:34 UTC 2025
GCC version: gcc version 11.4.0 (Ubuntu 11.4.0-1ubuntu1~22.04)
CUDA(Compute Unified Device Architecture,统一计算设备架构)
是Nvidia推出的通用并行计算平台和编程模型,允许开发者在NVIDIA的GPU上进行并行计算。包含CUDA指令集架构以及GPU内部的并行计算引擎,Cuda暴露了Nvidia开发的GPU的编程接口,NVIDIA开发人员可以使用C语言来CUDA上编写程序,所编写的程序可以在支持CUDA的处理器上以超高性能运行,从而处理计算密集型任务。
CUDA的出现使应用程序可以充分利用CPU和GPU的优点,使任务以更高效的方式执行。在CUDA编程中,一个需要GPU参与的任务(比如说计算密集型或高度并行的任务场景)的执行需要经历3个步骤:1. CPU接收应用程序的指令,将计算任务分配给GPU处理 ,同时CPU把数据从主机内存中拷贝到GPU的显存中 2. GPU中进行数据计算 3. 计算完成后,GPU将结果复制到CPU的内存中或者存储在显存中继续使用。所以说CUDA是一种让Python代码可以在CPU和GPU上同时运行的一个平台。
CUDA的体系结构如下图所示,CUDA指下图中绿色的部分,在CPU、GPU、应用程序之间起到了承上启下的作用。
CUDA:包含CUDA开发库(CUDA Libraries)、CUDA运行期环境(CUDA Runtime)、CUDA驱动(CUDA Driver)。
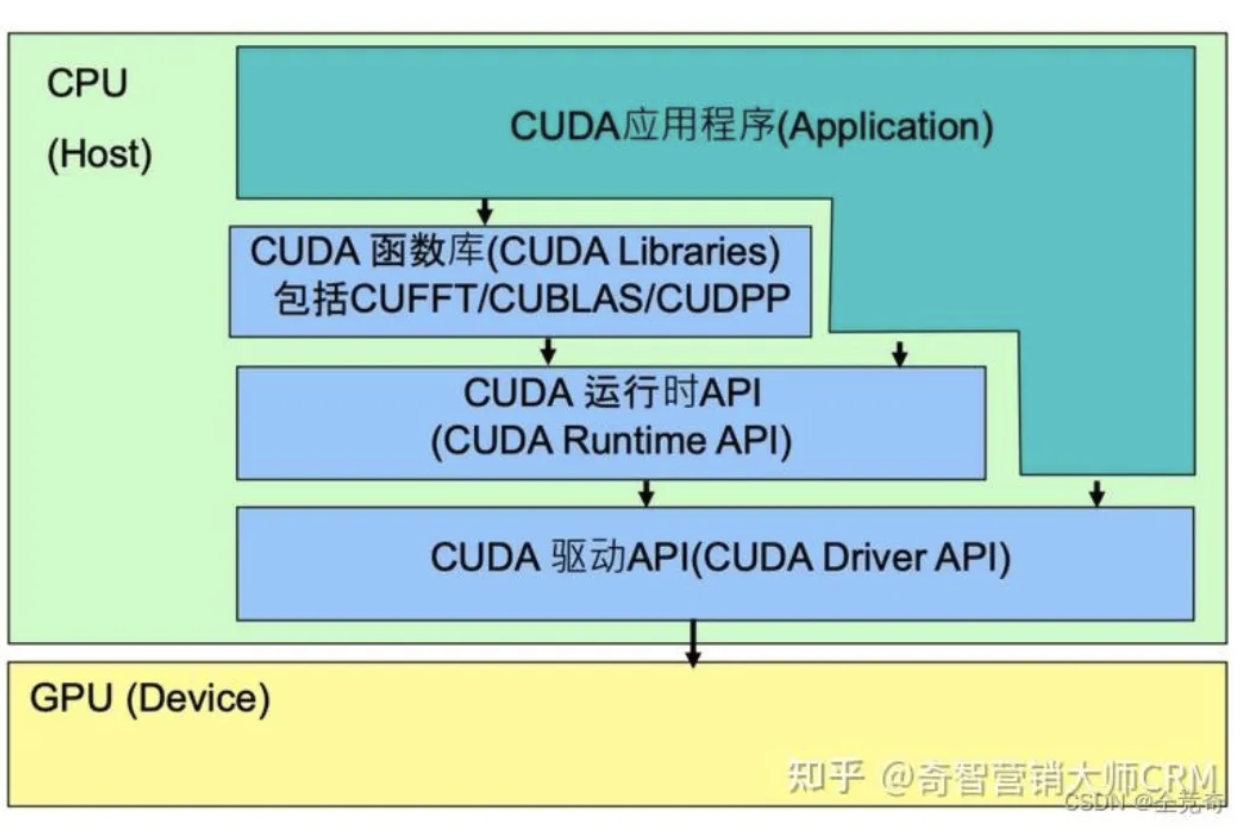
CUDA应用程序可调用CUDA Libraries或者CUDA Runtime API或者CUDA Driver API来实现功能,当调用CUDA Libraries时,CUDA Libraries会调用相应的CUDA Runtime API,CUDA Runtime API再调用CUDA Driver API,CUDA Driver API再操作GPU设备。
理解以上的架构图:
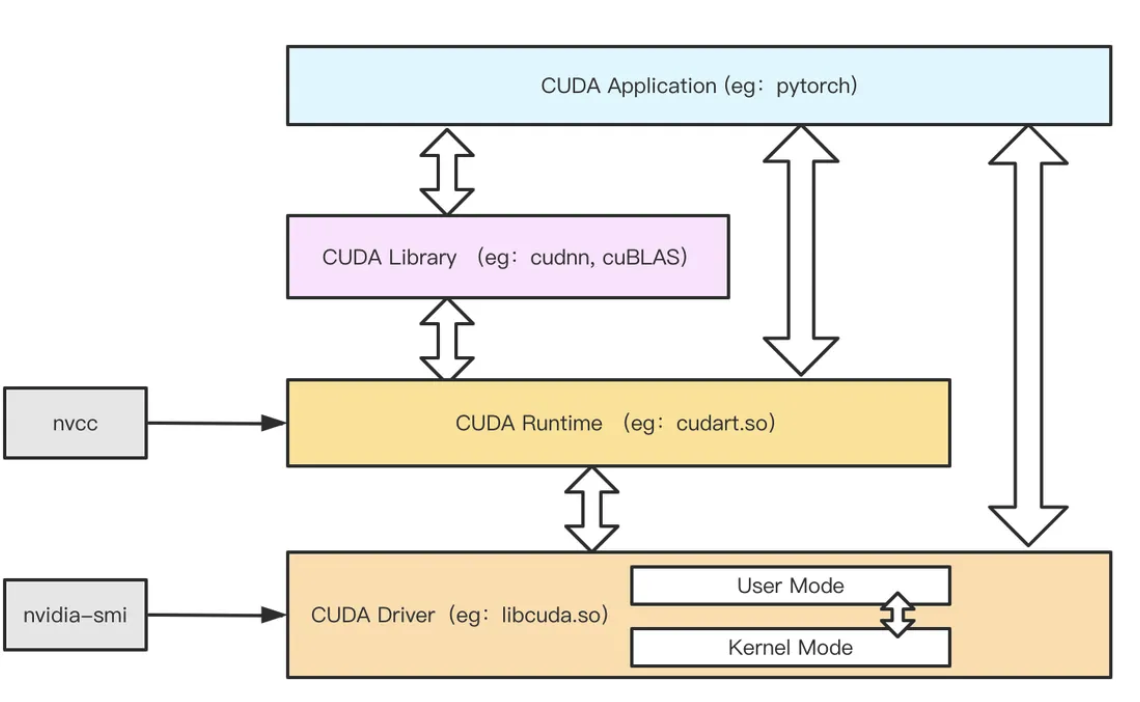
从最底层开始CUDA Driver(也就是常说的GPU驱动):可以认为是最底层的操作GPU的接口,作为直接与GPU设备打交道,其变成难度很大,但是性能更好。而CUDA Runtime(也就是常说的CUDA库):更多是面向CUDA应用开发人员,其API更加简化,可编程性更高,而基于CUDA Runtime接口再向上封装了更多的面向专用计算场景的库,例如专用于深度学习的cuDNN库等。最后,应用层可以使用CUDA Library或者直接使用CUDA Runtime API实现其功能。
CUDA Toolkit(Nvidia,CUDA编译环境)
实现CUDA的工具集,包含了编译器、库和调试工具,让开发者能够编写、编译和优化CUDA程序。包含下面几部分:
- 编译器 NVCC (编译CUDA代码)
- Tools (分析器、调试器等)
- Libraries 函数库 (科学库和实用程序库)
- CUDA Driver (cuda驱动,提供了与GPU硬件交互的接口)
- CUDA Samples (CUDA和library API的示例代码)
一般说的安装CUDA,实际上指安装CUDA Toolkit(Nvidia),CUDA版本通常指的是CUDA Toolkit(CUDA开发工具包)的版本;下图是Nvidia官网提供的CUDA Toolkit 下载方式。
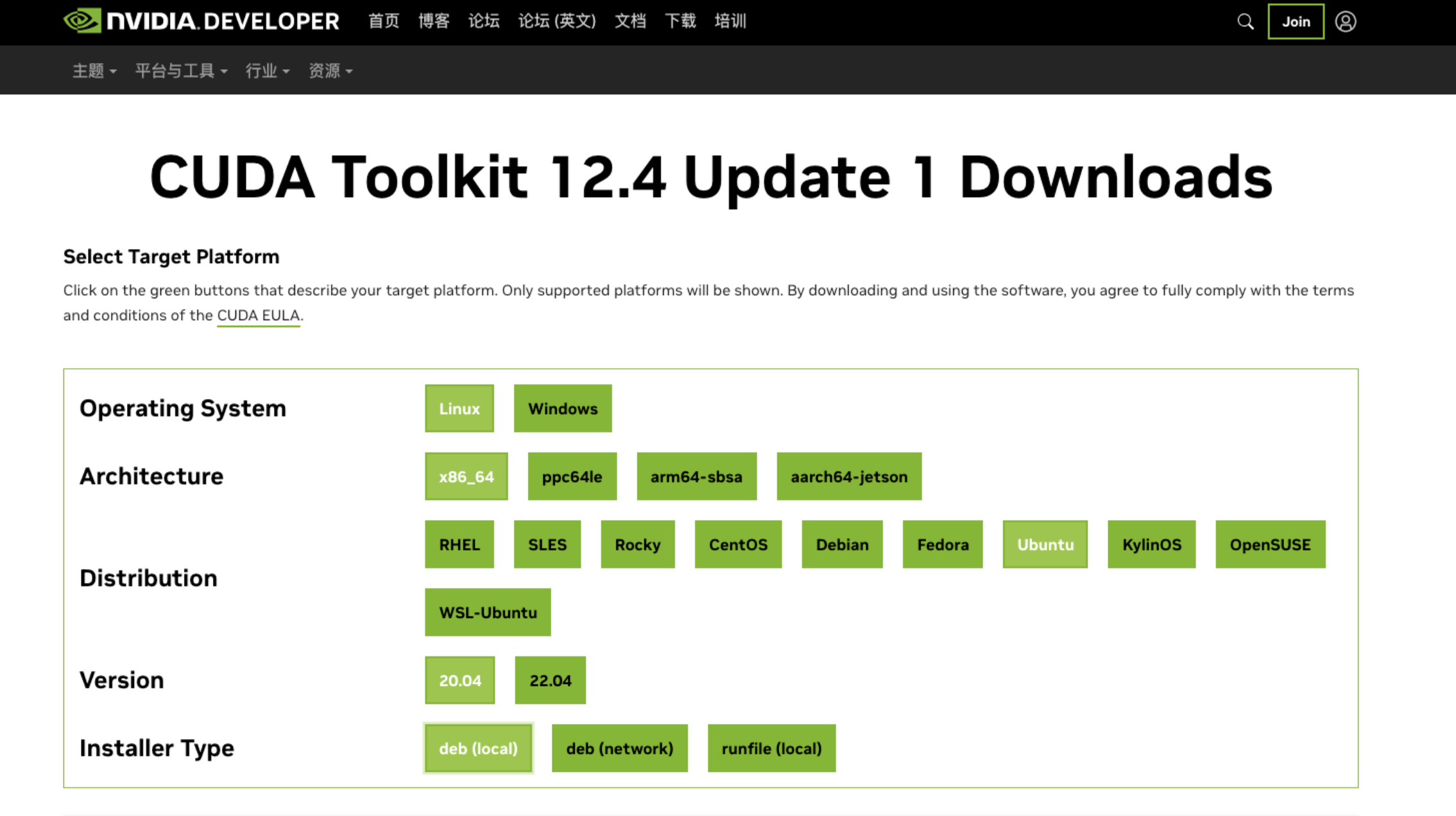
安装完了之后,可以通过执行nvcc -V来判断是否安装成功,下图中有版本信息等的输出,表示安装成功,版本为12.1。
nvcc: NVIDIA (R) Cuda compiler driver
Copyright (c) 2005-2023 NVIDIA Corporation
Built on Mon_Apr__3_17:16:06_PDT_2023
Cuda compilation tools, release 12.1, V12.1.105
Build cuda_12.1.r12.1/compiler.32688072_0
CUDA Driver (CUDA Runtime)
CUDA驱动, 集成在显卡驱动包中,安装显卡驱动时会一起安装了(是nvidia显卡的独有特性),主要用于运行编译后的CUDA程序,而不支持CUDA程序在开发阶段的调试和编译,这里说的CUDA Driver 为红框标出的部分:这里说的是执行nvidia-smi命令后支持的CUDA版本
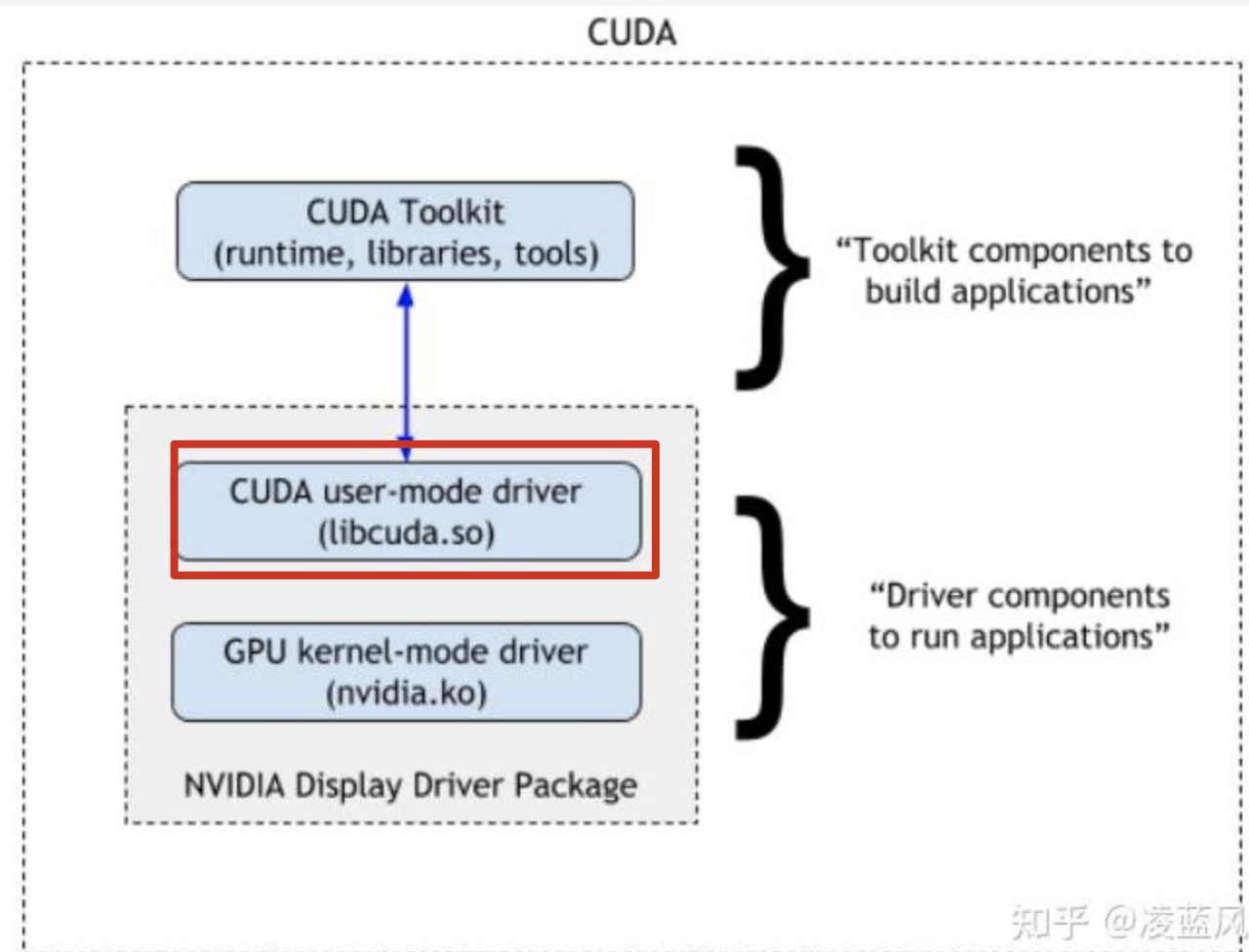
CUDA软件主要包括三部分:
- CUDA Toolkit : 库文件、运行环境 和 开发工具, 主要是面向开发者 CUDA编译环境。
- CUDA Driver: 用户驱动组建,用于运行 CUDA 程序,可以理解为 CUDA运行环境。
- Nvidia GPU 驱动 : 显卡核心驱动,就是 硬件驱动
这里要说明的是CUDA Toolkit中也有一个CUDA Driver , 为了方便用户,CUDA Driver 通常会随 CUDA Toolkit 一起安装。但是,这个驱动程序是为了开发目的而安装的。这意味着它主要用于开发和调试 CUDA 应用程序,以帮助开发人员在其工作站上进行开发和测试, 用户在安装 CUDA Toolkit 时,具体取决于操作系统和安装方式,可以选择是否安装 CUDA Driver,这里指的是Runtime CUDA。
所以CUDA会有两个API ,Driver API和Runtime API ,解释如下:
driver cuda version(nvidia-smi) >= toolkit cuda version(nvcc)

日常使用过程中,参考nvidia-smi 输出的cuda version作为最高版本,安装一个≤该版本的Cuda,可以对比上面提到的两个CUDA版本,执行nvidia-smi(cuda version:12.9),执行nvcc -V(cuda version: 12.1)。
NVCC (NVIDIA ® Cuda compiler driver)
用于将 CUDA C/C++ 代码编译为 GPU 可执行的二进制代码,属于上图中的runtime层,就像Java语言的Javac一样,用来将高级语言编译成机器(设备)看得懂的代码。
CUDA程序让应用程序可以在CPU和GPU上同时运行, 这就需要有两种代码来支持,一种是运行在CPU上的代码(Host端代码),一种是运行在GPU上的代码(Device端代码),NVCC编译器要保证两部分代码能够编译成二进制文件在不同端(CPU/GPU)运行。
cuDNN (CUDA Deep Neural Network library)
NVIDIA公司专门为深度学习任务而设计的加速库,是针对深度学习领域的特定优化,构建于CUDA之上,在使用cuDNN之前,必须先安装CUDA Toolkit,因为cuDNN需要CUDA Toolkit中的一些库和组件才能正常工作。许多流行的深度学习框架,如TensorFlow、PyTorch和Caffe等,都集成了对cuDNN的支持,以利用其优化的算法加速深度学习模型的计算。
在实际使用中,CUDA这个平台一开始并没有安装cuDNN库,当开发者们需要用到深度学习GPU加速时才安装cuDNN库,提供对深度学习任务的高效支持。
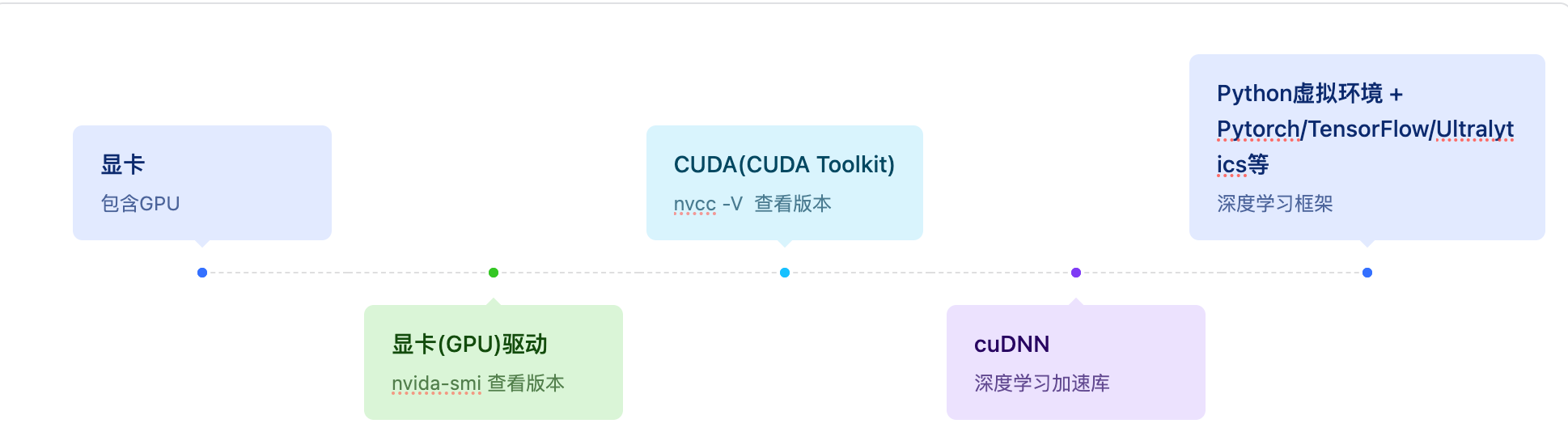
深度学习环境搭建流程
- 服务器
- 显卡
- 显卡驱动
- cuda
- cuda驱动
- cudnn
- Python虚拟环境,安装深度学习框架Pytorch /Tensorflow/Ultralytics
- 准备数据集、模型、训练代码等
下图以时间轴的形式展示了Cuda相关内容在安装时的先后顺序和依赖关系:
参考
https://cloud.tencent.com/developer/article/2442495
https://www.bilibili.com/video/BV1xE421j7Uv/?spm_id_from=333.1391.0.0&vd_source=dd84acac3abf9168080d4d6ebade201a
https://zhuanlan.zhihu.com/p/649509951
https://zhuanlan.zhihu.com/p/683431637
https://www.jianshu.com/p/0a97cf3e94d2
https://www.cnblogs.com/shuimuqingyang/p/15846584.html
https://www.zhihu.com/question/59184480/answer/2316965418
https://blog.csdn.net/weixin_43845924/article/details/138401249
总结
基本上搞清楚了算法环境的安装和配置流程,以后再也不会为算法环境头大了~