flink+clinkhouse安装部署
flink安装
1.上传并解压
tar -zxvf flink-1.14.0-bin-scala_2.12.tgz -C /opt/module/2.配置环境变量
vim /etc/profile.d/my_env.sh
#flink环境变量
export FLINK_HOME=/opt/module/flink-1.14.0
export PATH=$FLINK_HOME/bin:$PATH

3.修改配置文件
(1)配置flink-conf.yaml
进入conf目录
vim flink-conf.yaml
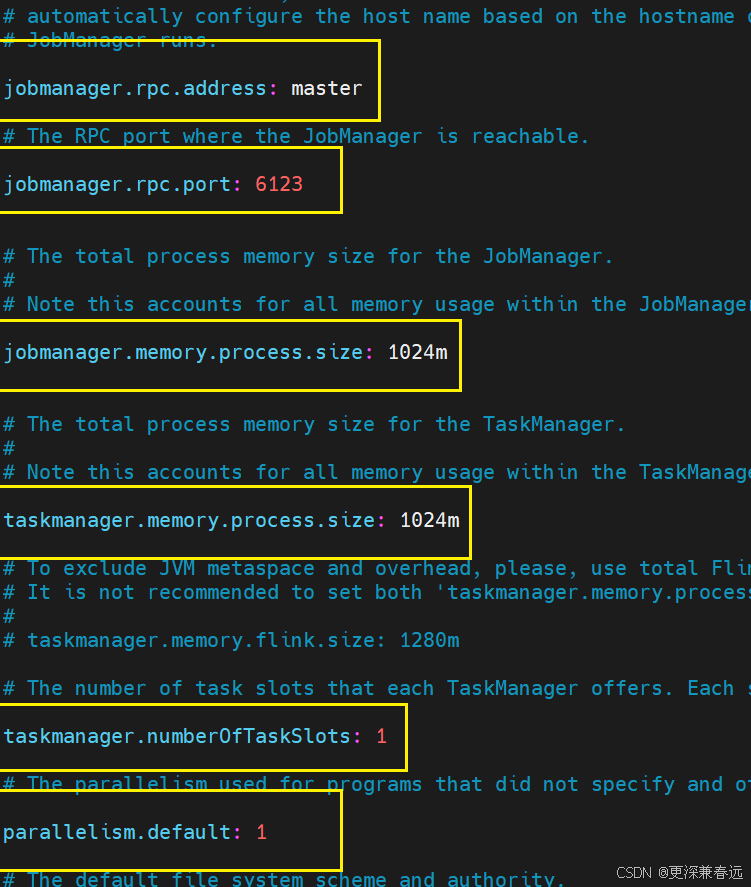
JobManager 是 Flink 集群的 “大脑”,负责协调作业执行、资源分配等。
jobmanager.rpc.address: master
- 定义 JobManager 的 RPC 通信地址。这里配置为
master,通常对应集群中 JobManager 节点的主机名。 - 作用:TaskManager、客户端等通过此地址与 JobManager 建立连接。
jobmanager.rpc.port: 6123
- 定义 JobManager 的 RPC 通信端口,默认值为 6123。
- 作用:用于 JobManager 与其他组件(如 TaskManager、客户端)的 RPC 通信,需确保端口未被占用且防火墙允许访问。
jobmanager.memory.process.size: 1024m
- 配置 JobManager 进程的总内存大小(包括 JVM 堆内存、元空间、直接内存及其他进程 overhead)。这里设置为 1024MB(1GB)。
- 注意:此参数包含 JobManager 运行所需的全部内存,无需额外配置 JVM 参数(Flink 会自动分配)。对于生产环境,若作业元数据较大(如复杂 DAG),可适当调大(如 2GB)。
TaskManager 是 Flink 的 “工作节点”,负责执行具体的计算任务(如算子、函数),是实际处理数据的组件。
taskmanager.memory.process.size: 1024m
- 配置单个 TaskManager 进程的总内存大小,包含 JVM 堆内存、堆外内存、元空间及进程 overhead 等,这里设置为 1GB
taskmanager.numberOfTaskSlots: 1
- 定义每个 TaskManager 的任务槽(Task Slot)数量,这里设置为 1。
- 任务槽是 Flink 的资源分配单位,每个槽可运行一个或多个并行任务(取决于作业并行度)。槽数量决定了 TaskManager 能并行执行的任务数。
parallelism.default: 1
- 定义 Flink 作业的默认并行度。若作业代码中未显式指定并行度,将使用此值(这里默认 1)。
(下一步,看是否需要,不需要不用配置)
如果你需要通过 Web UI 上传作业 JAR 包,web.upload.dir 必须配置为集群可访问的目录(否则上传会失败)。

web.upload.dir:/opt/module/flink-1.14.0/jars:指定 Flink Web UI 中上传作业 JAR 包的存储目录,用户通过 Web UI 上传的 JAR 会存到这里。env.ssh.opts: -p 22:配置与 SSH 相关的环境参数,这里指定 SSH 连接端口为 22,可能用于 Flink 集群跨节点操作(如任务提交、资源管理等涉及 SSH 通信场景 )。
(2)配置master
vim masters
(3)配置workers
vim workers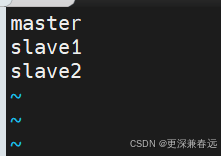
(4)配置start-cluster.sh
如果你的 Flink 作业需要与 Hadoop 生态交互(例如:
- 读取 / 写入 HDFS 上的数据
- 使用 YARN 作为资源管理器(Flink on YARN 模式)
- 操作 HBase、Hive 等 Hadoop 相关组件
此时必须配置这一行,否则 Flink 会因找不到 Hadoop 相关的类而报错(如 ClassNotFoundException)。这行配置的作用是让 Flink 进程加载 Hadoop 的类路径,确保能正常调用 Hadoop 相关 API。
进入bin目录下
vim start-cluster.sh添加的最佳位置是在脚本开头加载加载配置文件之前,确保环境变量在整个集群启动流程中生效。
原因说明:
- 生效时机:在加载
config.sh之前设置环境变量,能确保后续的启动逻辑(如启动 JobManager/TaskManager)都能继承该变量。 - 范围覆盖:该位置设置的变量会作用于整个脚本,包括通过
ssh远程启动的节点(如分布式集群中的其他机器),确保所有节点都能识别 Hadoop 类路径。 - 兼容性:不影响 Flink 原有逻辑,仅新增环境变量配置,对独立模式(不依赖 Hadoop)也无副作用。
添加后,重启集群时,Flink 进程会自动加载 Hadoop 相关的类,解决与 HDFS/YARN 集成时的类缺失问题
不是单元号,单引号在 Shell 中会将内容视为纯字符串,不会执行命令。报错
# 方式1:反引号(传统写法)
export HADOOP_CLASSPATH=`hadoop classpath`# 方式2:$()(现代推荐写法,可读性更好)
export HADOOP_CLASSPATH=$(hadoop classpath)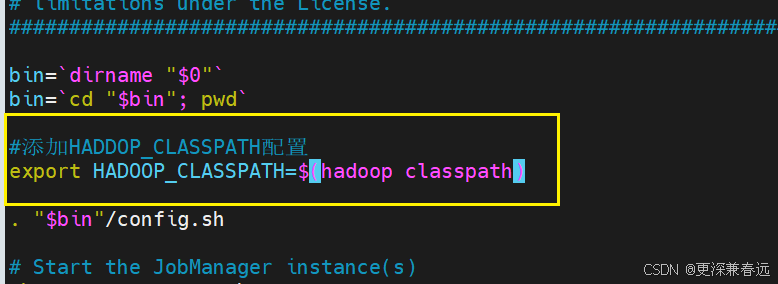
4.分发文件
![]()
scp -r flink-1.14.0/ slave1:/opt/module/
scp -r flink-1.14.0/ slave2:/opt/module/
scp -r /etc/profile.d/my_env.sh slave1:/etc/profile.d/
scp -r /etc/profile.d/my_env.sh slave2:/etc/profile.d/刷新环境变量
source /etc/profile5.启动flink

查看jps
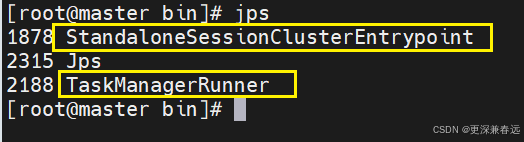
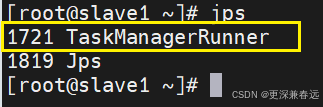
clinkhouse安装
1.上传并解压
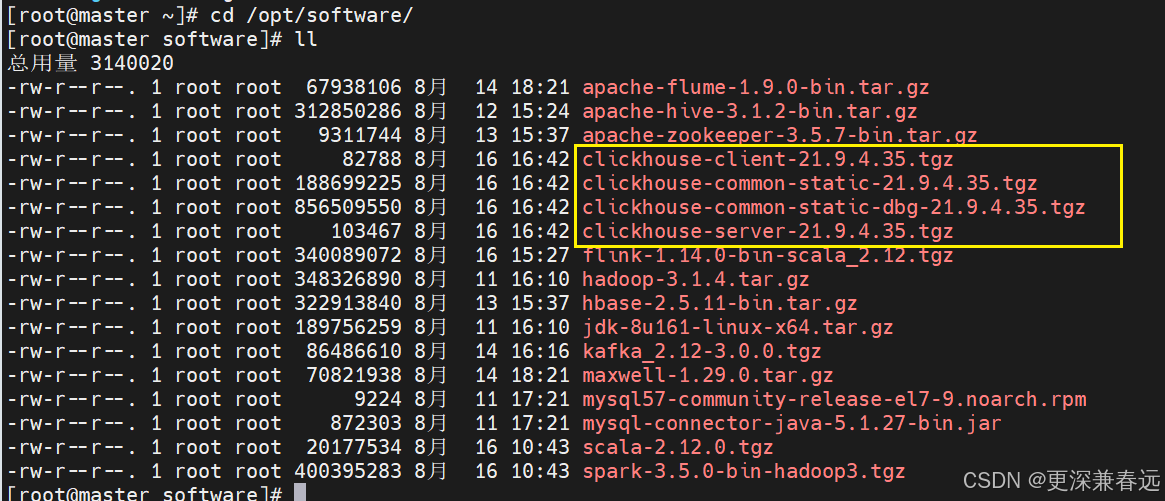
解压一个执行依次对应下方的命令
tar -zxvf clickhouse-common-static-21.9.4.35.tgz -C /opt/module/
#执行完第一个命令,就执行第二个命令
../module/clickhouse-common-static-21.9.4.35/install/doinst.sh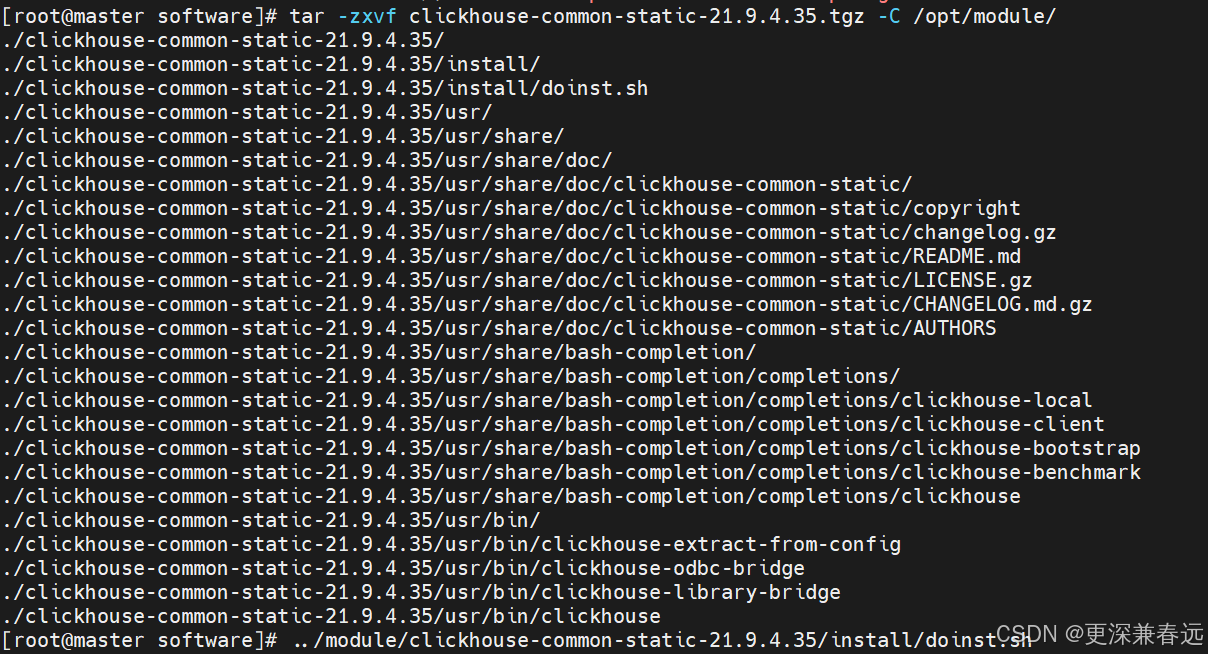
tar -zxvf clickhouse-common-static-dbg-21.9.4.35.tgz -C /opt/module/../module/clickhouse-common-static-dbg-21.9.4.35/install/doinst.sh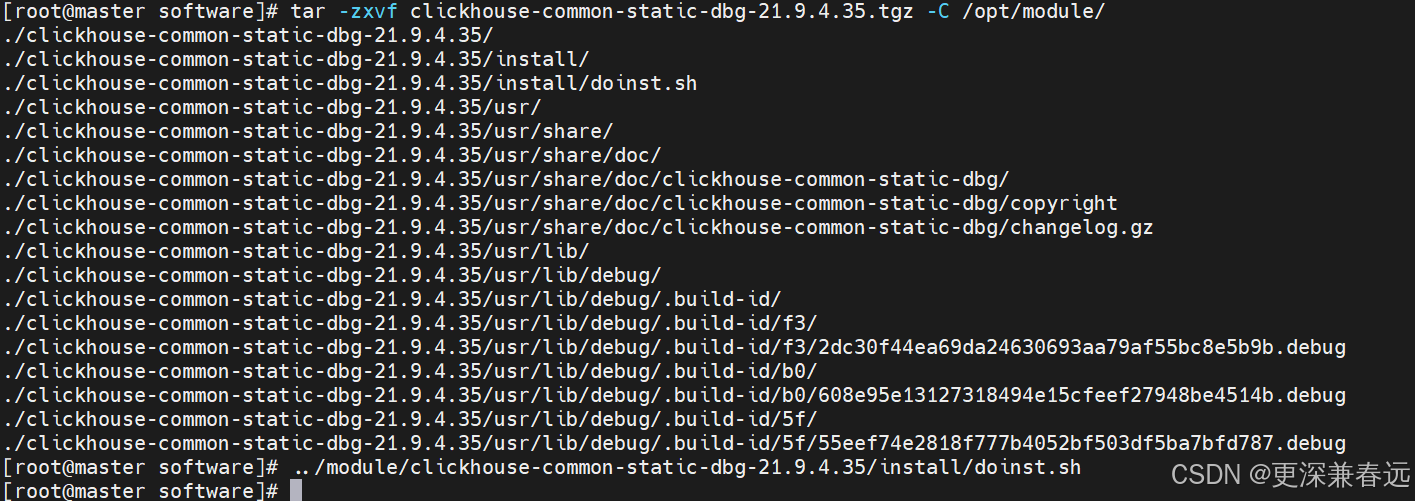
tar -zxvf clickhouse-server-21.9.4.35.tgz -C /opt/module/../module/clickhouse-server-21.9.4.35/install/doinst.sh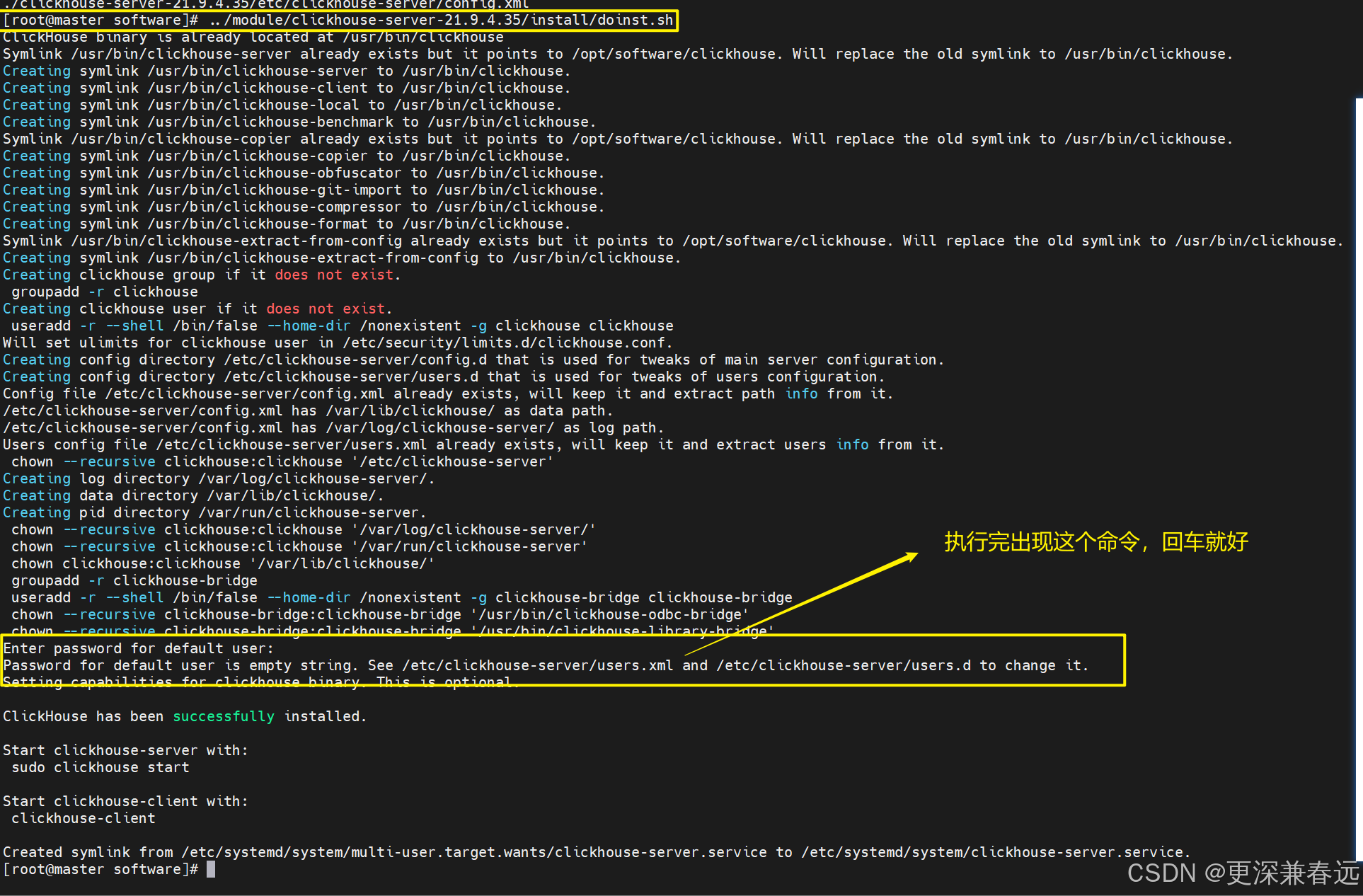
tar -zxvf clickhouse-server-21.9.4.35.tgz -C /opt/module/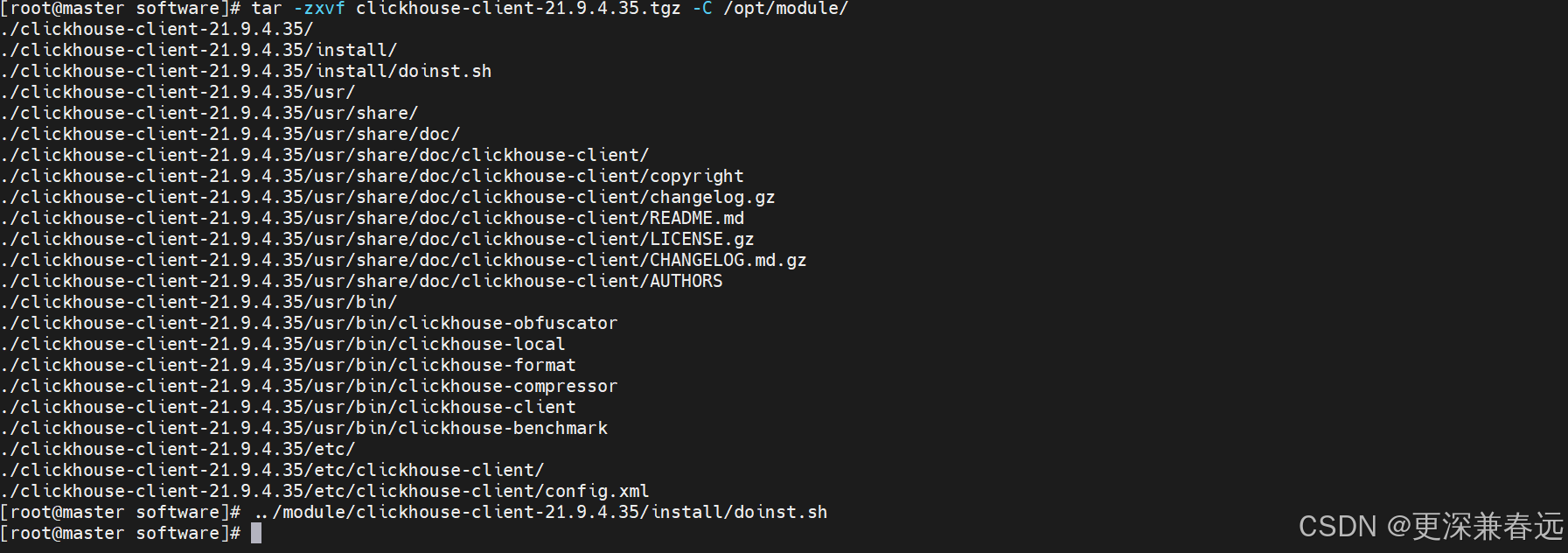
2.启动clinkhouse
启动
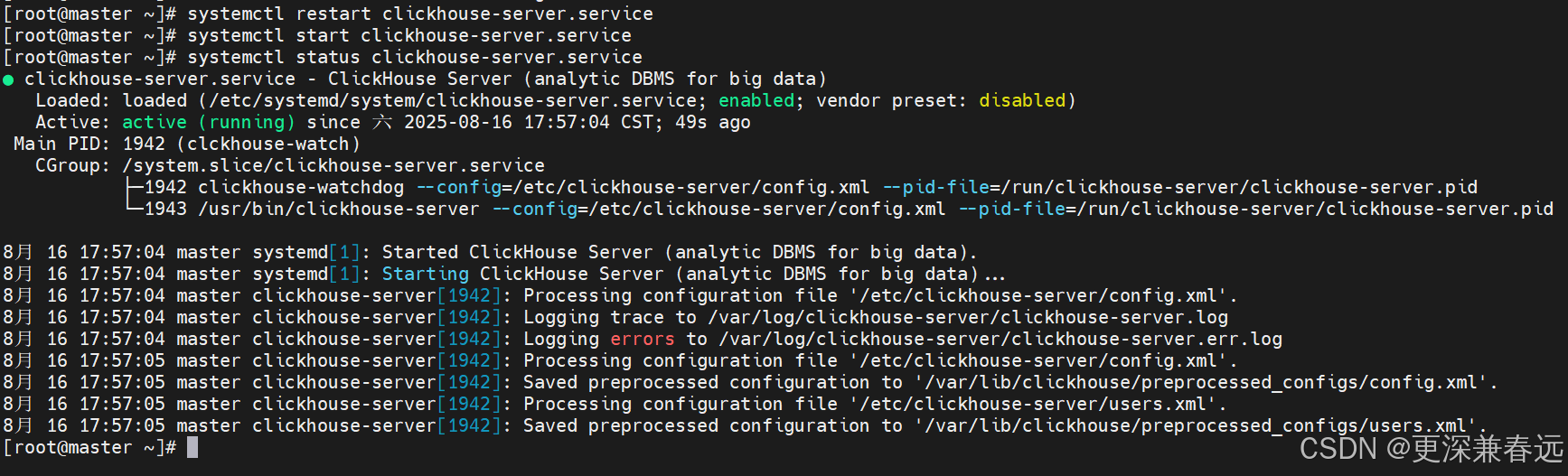
systemctl start clickhouse-server.service查看状态
systemctl status clickhouse-server.service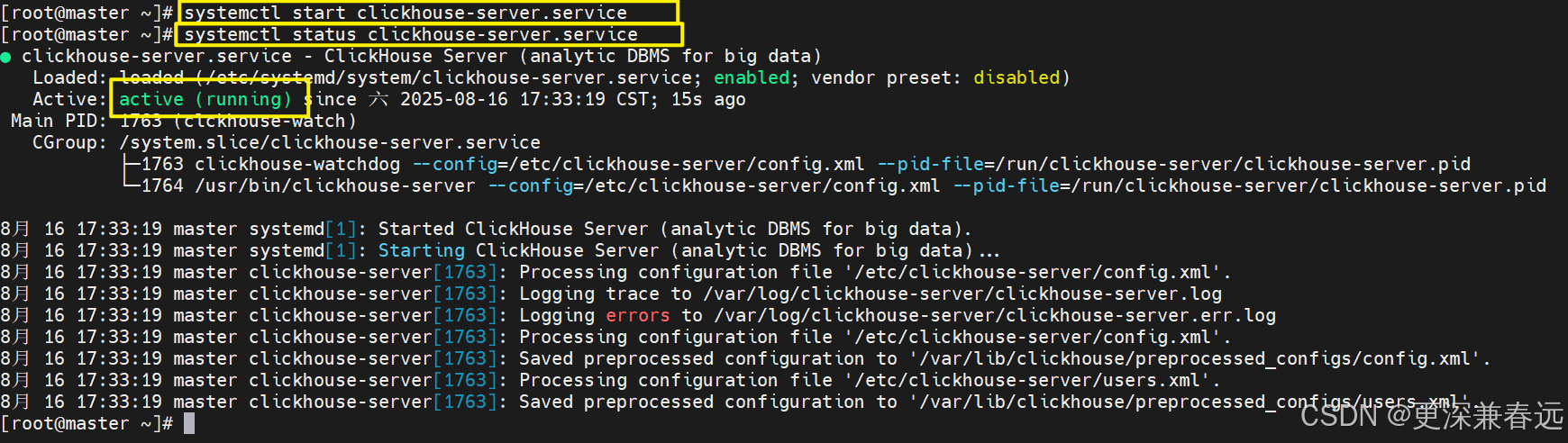
3.配置远程访问
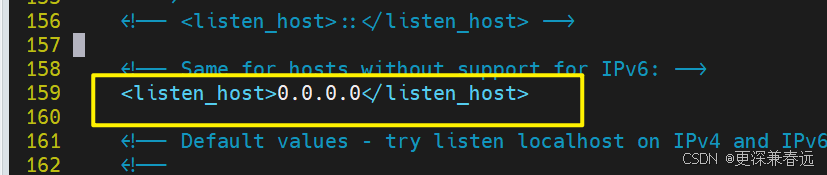
vim /etc/clickhouse-server/config.xml![]()
找到这个,解除注释。设置监听地址,0.0.0.0 表示允许所有 IP 访问
将文件中9000全部改为9001
在编辑器中,esc进入命令模式,输入
:%s/9000/9001/g%:表示作用于整个文件s:替换操作的标志9000:被替换的内容9001:替换后的内容g:全局替换(一行中所有匹配项,不加g则只替换每行第一个匹配项
端口冲突避免:如果服务器上已有其他服务占用 9000 端口,那么将 ClickHouse 的端口改为 9001 是很有必要的。比如,一些 Web 服务器默认也可能使用 9000 端口 ,不改端口会导致服务启动失败。
4.重启clinkhouse,并查看状态
systemctl restart clickhouse-server.service
systemctl start clickhouse-server.service
systemctl status clickhouse-server.service
systemctl stop clickhouse-server.service